Python入门一
目录:
- python基本操作
- python基本数据类型
- python字符串基本操作
- python的运算符
- python控制流-判断
- python控制流-循环
- python常用数据结构-列表
- python常用数据结构-元组
- python常用数据结构-集合
- python常用数据结构-字典
- python函数
- python函数进阶与参数处理
- pythonlambda表达式
- python面向对象概念
- python类与对象
- 学生信息管理系统
1.python基本操作
基本操作注意事项:
- 缩进与空格
- 编写规范
- 注释
- 符合规范性,命名要见名知意
- 不要用关键字命名
PEP8 编码规范
- 收藏了解
- https://www.python.org/dev/peps/pep-0008/
2.python基本数据类型
变量:
- 变量是一种存储数据的载体,计算机中的变量是实际存在的数据或者说是存储器中存储数据的一块内存空间
- 变量的值可以被读取和修改
变量命名规则:
- 变量名由字母(广义的 Unicode 字符,不包括特殊字符)、数字和下划线构成,数字不能开头
- 大小写敏感(大写的
A和小写的a是两个不同的变量) - 不要跟关键字(有特殊含义的单词)和系统保留字(如函数、模块等名字)冲突
数字:
- int
- 整形,没有小数点的,包括 1,100,0,-1,-100
- float
- 浮点型,带有小数点,包括 1.0,-1.0,-1.1
int_a = 1
print(int_a)
print(type(int_a))float_a = 1.0
print(float_a)
print(type(float_a))布尔:
- True
- False
bool_a = True
print(bool_a)
print(type(bool_a))bool_b = False
print(bool_b)
print(type(bool_b))字符串:
\转义符r忽略转义符的作业+多个字符串连接- 索引
- 切片
# `\` 转义符
str_a = "adb\\n123456"
print(str_a)
# `r` 忽略转义符的作业
str_b = r"adb\n123456"
print(str_b)
# `+` 多个字符串连接
str_c = str_a + str_b
print(str_c)字符串(索引+切片):
字符串:“abcdefg”
索引: 0123456
切片: start: stop: step
str_d = "abcdefg"
print(str_d[0])
# x>=1
print(str_d[1:])
# 前闭后开原则,1<=x<5
print(str_d[1:5])
# 步长,
print(str_d[1:5:2])
print(str_d[1::2])列表(List):
var_list = [1, 2, 3, 4, 5, "a", "b", "c", True]
print(var_list)
print(var_list[0])
print(var_list[-1])
print(var_list[2:-2])
print(var_list[2::2])3.python字符串基本操作
字符串操作的使用场景:
- 数据提取之后的通用格式
- 日志
- excel
- 第三方数据信息
字符串的定义:
# 单行
str_a = "this is a str"
print(str_a)# 多行
str_b = """
这是一段字符串
hello workld
"""
print(str_b)字符串常用特殊字符:
# 换行
print("hello \n world")
# 转义
print("hello \\n world")字符串格式化符号:
| 符号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %p | 用十六进制数格式化变量的地址 |
# world替换掉 %s 的位置
print("hello %s" % "world")字符串之字面量插值:
- “str”.format()
# 不设置指定位置,按默认顺序
print("{} {}".format("hello", "world"))
# 设置指定位置
print("{1} {0}".format("hello", "world"))
# 通过名称传递变量
print("{name}hello".format(name="world"))字符串之字面量插值:
- f”{变量}”
name = "Bob"
school = "hdc"
# 通过 f"{变量名}"
print(f"我的名字叫做{name}, 毕业于{school}")字符串常用API之join:
- join
- 列表转换为字符串
a = ["h", "e", "l", "l", "o"]
# 将列表中的每一个元素拼接起来
print("".join(a))
print("|".join(a))字符串常用API之split:
- split
- 数据切分操作
# 根据split内的内容将字符串进行切分
b="hello world"
print(b.split(" "))字符串常用API之replace:
- replace
- 将目标的字符串替换为想要的字符串
# 将原字符串中的 world 替换为 tom
print("hello world".replace("world", "tom"))字符串常用API之strip:
- strip
- 去掉首尾的空格
print(" hello world ".strip())4.python的运算符
运算符的作用
- Python 基础语法的内容
- 通常表示不同数据或变量之间的关系
算数运算符:
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取模 |
| ** | 幂 |
| // | 取整除 |
# 加
a = 1 + 1
print(a)# 减
b = 2 - 1
print(b)# 变量之间也可以做运算
c = 4
d = 3
e = c - d
print(e)# 乘
f = 1 * 2
print(f)# 除
g = 3 / 2
print(g)# 取模(取余)
h = 5 % 2
print(h)# 幂
i = 2 ** 3
print(i)# 取整除
j = 3 // 2
print(j)比较运算符:
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
a = 1
b = 2
print(a == b)
print(a != b)
print(a > b)
print(a < b)
print(a <= b)
print(a >= b)赋值运算符:
| = | 简单赋值运算符 |
| += | 加法赋值运算符 |
| -= | 减法赋值运算符 |
| *= | 乘法赋值运算符 |
| /= | 除法赋值运算符 |
| %= | 取模赋值运算符 |
| **= | 幂赋值运算符 |
| //= | 取整赋值运算符 |
# 简单赋值
a = 1
print(a)
# 多个变量赋值
a, b = 1, 2
print(a)
print(b)
# 加法运算
a = a + 1
print(a)
# 加法赋值运算
a += 1
print(a)逻辑运算符:
| 运算符 | 逻辑表达式 | 描述 |
| and | x and y | x、y 都为真才为真,有一个为假即为假 |
| or | x or y | x、y 有一个为真即为真,都为假为假 |
| not | not x | 如果 x 为假,则 not x 为真 |
a, b = True, False
print(a and b)
print(a or b)
print(not a)
print(not b)成员运算符:
| 运算符 | 描述 |
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 |
list_a = ["a", "b", "c"]
str_a = "abcde"
str_b = "bcde"print("a" in list_a)
print("a" not in list_a)
print("a" in str_a)
print("a" not in str_a)
print("a" in str_b)身份运算符:
| 运算符 | 描述 |
| is | is 是判断两个标识符是不是引用自一个对象 |
| is not | is not 是判断两个标识符是不是引用自不同对象 |
list_a = ["a", "b", "c"]
list_b = ["a", "b", "c"]# 使用id查看变量的内存地址
print(id(list_a))
print(id(list_b))
print(list_a is list_b)
print(list_a == list_b)5.python控制流-判断
什么是分支判断?
- 一条一条语句顺序执行叫做顺序结构
- 分支结构就是在某个判断条件后,选择一条分支去执行
if 条件判断:
bob = "teacher"
if bob == "teacher":print("老师")
else 判断语句:
bob = "student"
if bob == "teacher":print("老师")
else:print("student")elif 多重条件:
food = "apple"
if food == "apple":print("苹果")
elif food == "orange":print("橘子")
elif food == "banana":print("香蕉")
else:print("fruit")分支嵌套:
my_list = [1, 2, 3, 4, 5]if my_list:print("my_list 不为空")if my_list[0] == 3:print("my_list 中的第一个元素为 3")else:print("my_list 中的第一个元素不是 3")
else:print("my_list 为空")三目运算符:
# 正常的赋值操作和判断语句结合
a, b = 1, 2
if a > b:h = "变量1"
else:h = "变量2"
# 优化之后更简洁的写法
a, b = 1, 2;
h = "变量1" if a > b else "变量2"
print(h)6.python控制流-循环
什么是循环:
- 循环语句允许我们执行一个语句或语句组多次
- python提供了for循环和while循环
循环的作用:
- 封装重复操作
- Python最重要的基础语法之一
for-in循环:
- 使用场景:
- 明确的知道循环执行的次数或者要对一个容器进行迭代
range函数- range(101)可以产生一个0到100的整数序列。
- range(1, 100)可以产生一个1到99的整数序列。
- range(1, 100, 2)可以产生一个1到99的奇数序列,其中的2是步长。
# 使用for 循环遍历列表中的元素
for i in [1, 2, 3]:print(i)# for 循环结合 range函数
for i in range(1, 100, 2):print(i)while 循环:
- 满足条件,进入循环
- 需要设定好循环结束条件
count = 0
# while循环条件,满足条件执行循环体内代码
while count < 5:# count 变量+1,否则会进入死循环print(count)count += 1continue:跳出当前轮次循环:
count = 0while count < 5:print(count)if count == 3:count += 1.5continuecount += 1list_demo = [1, 2, 3, 4, 5, 6]
# 循环遍历列表
for i in list_demo:# 如果i 等于3,那么跳出当前这轮循环,不会再打印3if i == 3:continueprint(i)pass:
- 没有实质性含义,通常占位使用
- 不影响代码的执行逻辑
print("hdc")
pass
print("school")练习:
- 计算1~100 求和
- 使用分支结构实现1~100之间的偶数求和
- 不使用分支结构实现1~100之间的偶数求和
- 不使用分支结构实现1~100之间的奇数求和
- 使用while语句实现1~100之间的奇数求和
# 使用分支结构实现1~100之间的偶数求和
sum = 0
for i in range(1, 101):if i % 2 == 0:sum += i
print(sum)
# 不使用分支结构实现1~100之间的偶数求和
sum = 0
for i in range(0, 101, 2):sum += i
print(sum)
# 不使用分支结构实现1~100之间的奇数求和
sum = 0
for i in range(1, 101, 2):sum += i
print(sum)
# 使用while语句实现1~100之间的奇数求和
i, sum = 1, 0
while i < 101:if i % 2 == 1:sum += ii += 1
print(sum)- 猜数字游戏
- 计算机出一个1~100之间的随机数由人来猜
- 计算机根据人猜的数字分别
- 给出提示大一点/小一点/猜对了
import random# 生成随机数
number = random.randint(1, 100)# 初始化猜测次数和最大猜测次数
guesses = 0
max_guesses = 10# 提示用户开始猜测
print("我在想一个介于1到100之间的数字。你能猜出它是什么吗?")# 循环猜测,直到用户猜对或猜测次数用尽
while guesses < max_guesses:# 提示用户输入猜测的数字guess = int(input("输入你的猜测: "))guesses += 1# 判断猜测是否正确if guess == number:print("恭喜你!你猜对了号码一共猜了", guesses, "次.")breakelif guess < number:print("你猜测的数字太小了.")else:print("你猜测的数字太大了.")7.python常用数据结构-列表
列表定义:
-
列表是有序的可变元素的集合,使用中括号
[]包围,元素之间用逗号分隔 -
列表是动态的,可以随时扩展和收缩
-
列表是异构的,可以同时存放不同类型的对象
-
列表中允许出现重复元素
列表使用:创建:
# 1、通过构造函数创建
li1 = list() # 空列表
li2 = list('hello') # 字符串
li3 = list((1, 2, 3)) # 元组
li4 = list({4, 5, 6}) # 集合
li5 = list({'a': 7, 'b': 8}) # 字典
print(type(li1), li1)
print(type(li2), li2)
print(type(li3), li3)
print(type(li4), li4)
print(type(li5), li5)# 2、中括号创建并填充元素
li6 = [] # 空列表
li7 = [1, 2, 3] # 直接填充对象
print(type(li6), li6)
print(type(li7), li7)列表使用:索引
li = [1, 2, 3, 4, 5]# 1、正向索引
print(li[0]) # 打印1
print(li[3]) # 打印4# 2、反向索引
li = [1, 2, 3, 4, 5]
print(li[-1]) # 打印 5列表使用:切片
-
切片 [start: stop: step]
- start 值: 指示开始索引值,如果没有指定,则默认开始值为 0;
- stop 值: 指示到哪个索引值结束,但不包括这个结束索引值。如果没有指定,则取列表允许的最大索引值;
- step 值: 步长值指示每一步大小,如果没有指定,则默认步长值为 1。
- 三个值都是可选的,非必填
# 切片基本用法
li = ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
print(li[0:5:2])
print(li[2:4])
print(li[:4])
print(li[2:])
print(li[::2])
print(li[::-1])列表使用:运算符:
- 重复
- 使用
*运算符可以重复生成列表元素。
- 使用
- 合并
- 使用
+加号运算符,可以将两个列表合二为一。
- 使用
# 1、重复
li = [1] * 5
print(li) # 打印[1, 1, 1, 1, 1]# 2、合并
li1 = [1, 2, 3]
li2 = [99, 100]
print(li1 + li2) # 打印[1, 2, 3, 99, 100]列表使用:成员检测:
-
in:检查一个对象是否在列表中,如果在则返回 True,否则返回 False。
-
not in:检查一个列表是否不包含某个元素。如果不在返回 True,否则返回 False。
li = [1, 2, 3]# in
print(1 in li) # 返回True
print(100 in li) # 返回False# not in
print(1 not in li) # 返回False
print(100 not in li) # 返回True列表方法
- append()
- extend()
- insert()
- pop()
- remove()
- sort()
- reverse()
列表方法 append():
-
append(item):将一个对象 item 添加到列表的末尾。 -
入参:对象 item
-
返回:None
# 添加元素
li = []
li.append(1)
li.append(3.14)
li.append("hello world")
li.append([6, 6, 6])
li.append((1.2, 1.5))
li.append({'msg': "Hello"})print(li) # 打印列表
print(len(li)) # 获取列表元素个数列表方法 extend()
- extend(iterable):将一个可迭代对象的所有元素,添加到列表末尾。
- 入参:可迭代对象 iterable
- 返回:None
# extend()的用法
li = []
li.extend('helloworld') # 添加的是字符串的所有字母
li.extend([1, 2, 3]) # 接收列表的所有元素
li.extend((4, 5, 6)) # 接收元组的所有元素
li.extend({'a': 1, 'b': 2}) # 接收字典的所有key值
print(li)列表方法 insert()
-
insert(index, item):将一个对象插入到指定的索引位置 -
入参:索引值 index ,一个对象 item
-
返回:None
-
原索引位置及后面的元素后移一位
li = [0, 1, 2]
print("插入前: ", li) # 打印 [0, 1, 2]# 在索引0的位置插入元素
li.insert(0, 'hello world')
print("插入后: ", li) # 打印 ['hello world', 0, 1, 2]列表方法 pop()
-
pop(index) 或 pop() -
弹出并返回所指定索引的元素。
-
入参:索引值 index,可不传
-
返回:指定索引的元素
-
返回:未指定索引则返回末尾元素
-
如果索引值不正确,或者列表已经为空,则引发 IndexError 错误
letters = ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
print(letters)n1 = letters.pop(3)
print(n1)
print(letters)# 不传参数,默认弹出末尾元素
n2 = letters.pop()
print(n2)
print(letters)列表方法 remove()
-
remove(item) -
移除列表中第一个等于 item 的元素
-
入参:指定元素 item
-
返回:None
-
目标元素必须已存在,否则会报 ValueError
li = ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
print(len(li))# 1、删除指定元素'h'
li.remove('h')
print(li)
print(len(li))# 2、移除第一个2
li = [1, 2, 3, 2, 1]
li.remove(2)
print(li) # 打印 [1, 3, 2, 1]# 3、删除不存在的元素,会报ValueError错误
li = [1, 2, 3]
li.remove(100)列表方法 sort()
-
sort(key=None, reverse=False) -
对列表进行原地排序,只使用 < 来进行各项间比较。
-
入参:支持 2 个关键字参数:
key:指定带有一个参数的函数,用于从每个列表元素中提取比较键。reverse:默认值为 False 表示升序,为 True 表示降序
-
返回:None
nums = [2, 4, 3, 1, 5]# 1、不传参数,默认升序,数字从小到大排列
nums.sort()
print(nums) # 打印 [1, 2, 3, 4, 5]# 2、指定key=len,按元素的长度排序
words = ['Python', 'Java', 'R', 'Go']
words.sort(key=len,reverse=False)
print(words)
words.sort(key=len,reverse=True)
print(words) # 3、指定reverse=True,降序
nums = [2, 4, 3, 1, 5]
nums.sort(reverse=True)
print(nums) # 打印 [5, 4, 3, 2, 1]列表方法 reverse()
reverse():将列表中的元素顺序反转- 参数:无
- 返回:None
- 反转只是针对索引值,元素之间不相互比较。
# 反转顺序
nums = [8, 1, 5, 2, 77]
nums.reverse()
print(nums) # 打印[77, 2, 5, 1, 8]列表嵌套
- 嵌套列表是指在列表里存放列表
- 列表的常用方法都适用于嵌套列表
# 1、创建嵌套列表
li_2d = [['a', 'b', 'c'], [1, 2, 3]]
print(type(li_2d)) # 打印<class 'list'>
print(len(li_2d)) # 打印 2# 2、访问嵌套列表中的元素
print(li_2d[0][2]) # 打印 'c'
print(li_2d[1][0])列表推导式:
- 列表推导式是指循环创建列表,相当于for循环创建列表的简化版
- 语法∶[x for x in li if x...]
# 实例:将1-10中的所有偶数平方后组成新的列表
# 1、传统解决方案
result = []
for ele in range(1, 11):if ele % 2 == 0:result.append(ele ** 2)
print(result)# 2、使用列表推导式
result = [ele ** 2 for ele in range(1, 11) if ele % 2 == 0]
print(result)8.python常用数据结构-元组
元组定义:
- 元组是有序的不可变对象集合
- 元组使用小括号包围,各个对象之间使用逗号分隔
- 元组是异构的,可以包含多种数据类型
元组使用:创建:
- 创建
- 使用逗号分隔
- 通过小括号填充元素
- 通过构造方法 tuple(iterable)
# 1、直接使用逗号分隔
t5 = 1, 2, 3
print(type(t5))# 2、通过小括号填充元素
t3 = (1, 2, 3)
print(t3)
print(type(t3))t4 = ('a', 'b', 'c')
print(t4)
print(type(t4))# 3、通过构造函数tuple()
t1 = tuple()
print(type(t1))t2 = tuple([1, 2, 3])
print(t2)
print(type(t2))元组使用:索引
-
索引
-
可以通过索引值来访问对应的元素。
- 正向索引,默认编号从 0 开始
- 反向索引,默认编号从-1 开始
t = tuple(range(1, 6))
print(t)# 正向索引
print(t[2])# 反向索引
print(t[-1])元组使用:切片
-
切片 [start: stop: step]
- 三个值都是可选的,非必填
- start 值: 指示开始索引值,如果没有指定,则默认开始值为 0;
- stop 值:指示到哪个索引值结束,但不包括这个结束索引值。如果没有指定,则取元组允许的最大索引值;
- step 值:步长值指示每一步大小,如果没有指定,则默认步长值为 1。
# 切片的使用
t = (1, 2, 3, 4, 5, 6)print(t[:])
print(t[:-2])
print(t[2:4])
print(t[2:5:2])# 特殊的切片写法:逆序
print(t[::-1])元组常用方法
- index()
- count()
元组常用方法 index()
-
index(item) -
返回与目标元素相匹配的首个元素的索引。
-
目标必须在元组中存在的,否则会报错
t = (1, 3, 2, 3, 2)
print(t.index(3))t = ('h', 'e', 'l', 'l', 'o', 'r', 'w', 'o', 'r', 'l', 'd')
print(t.index('h'))元组常用方法 count()
-
count(item):返回某个元素出现的次数。 -
入参:对象 item
-
返回:次数
t = (1, 2, 2, 3, 3, 3, 3)
print(t.count(3))t = ('h', 'e', 'l', 'l', 'o', 'r', 'w', 'o', 'r', 'l', 'd')
print(t.count('h'))元组解包
- 元组解包:把一个可迭代对象里的元素,一并赋值到由对应的变量组成的元组中。
# 传统逐个赋值的方式
t = (1, 2, 3)
a = t[0]
b = t[1]
c = t[2]
print(a, b, c)# 使用元组解包,一气呵成
a, b, c = (1, 2, 3)
print(a, b, c)元组与列表对比
- 相同点
- 都是有序的
- 都是异构的,能够包含不同类型的对象
- 都支持索引和切片
- 区别
- 声明方式不同,元组使用
(),列表使用[] - 列表是可变的,元组是不可变的
- 声明方式不同,元组使用
9.python常用数据结构-集合
集合定义
- 无序的唯一对象集合
- 用大括号
{}包围,对象相互之间使用逗号分隔 - 集合是动态的,可以随时添加或删除元素
- 集合是异构的,可以包含不同类型的数据
集合使用:创建
- 创建
- 通过使用
{}填充元素 - 通过构造方法 set()
- 通过集合推导式
- 通过使用
"""创建集合"""
# 1、使用大括号{}填充元素
st4 = {1, 2, 3}
st5 = {'a', 'b', 'c'}# 2、使用构造方法创建集合
st1 = set() # 空集合
st2 = set('hello world')li = [1, 1, 2, 2, 3, 3]
st3 = set(li)
print(st3)
print(type(st3))# 3、使用集合推导式
st6 = {x for x in li}
print(st6)
# 注意:不要单独使用{ }来创建空集合
st7 = {} # 这是字典类型
print(type(st7))集合使用:成员检测:
- in
- 判断元素是否在集合中存在
- not in
- 判断元素是否在集合中不存在
"""集合使用:成员检测"""
st = {1, 2, 3, 4, 5}
# in
print(2 in st)# not in
print(99 not in st)集合方法
- add()
- update()
- remove()
- discard()
- pop()
- clear()
集合方法 add()
add(item):将单个对象添加到集合中- 入参:对象 item
- 返回:None
"""集合方法 add()"""
# 添加元素
st = {1, 2, 3}
st.add(99)
st.add('hello')
print(st)
print(type(st))集合方法 update()
-
update(iterable) -
批量添加来自可迭代对象中的所有元素
-
入参:可迭代对象 iterable
-
返回:None
"""集合方法 update()"""
li = [1, 2, 3]
tup = (2, 3, 4)
st = {'a', 'b', 'c'}# 1、批量添加列表中的元素
st1 = set()
st1.update(li)
print(st1)
# 2、批量添加元组中的元素
st1.update(tup)
print(st1)
# 3、批量添加集合中的元素
st1.update(st)
print(st1)集合方法 remove()
remove(item):从集合中移除指定元素 item。- 入参:指定元素值
- 返回:None
- 如果 item 不存在于集合中则会引发 KeyError
"""集合方法 remove()"""
# 1、删除已存在的元素
st = {1, 2, 3, 4, 5}
print(st)
st.remove(2)
print(st)# 2、删除不存在的元素
st.remove(1024) # KeyError集合方法 discard()
discard(item):从集合中移除指定对象 item。- 入参:指定对象值
- 返回:None
- 元素 item 不存在没影响,不会抛出 KeyError 错误。
"""集合方法 discard()"""
# 1、删除已存在的元素
st = {1, 2, 3, 4, 5}
print(st)
st.remove(2)
print(st)# 2、删除不存在的元素
st.discard(1024)
print(st)集合方法 pop()
pop():随机从集合中移除并返回一个元素。- 入参:无。
- 返回:被移除的元组。
- 如果集合为空则会引发 KeyError。
"""集合方法 pop()"""
# 1、随机删除某个对象
st = {1, 2, 3, 4, 5}
print(st)
item = st.pop()
print(item, st)# 2、集合本身为空会报错
st = set()
st.pop() # KeyError集合方法 clear()
clear():清空集合,移除所有元素- 入参:无
- 返回:None
"""集合方法 clear()"""
# 1、清空集合
st = {1, 2, 3, 4, 5}
print(st)
st.clear()
print(st)集合运算
- 交集运算
- 并集运算
- 差集运算
集合运算:交集
-
交集运算
-
intersection()
-
操作符:&
"""集合运算:交集"""
# 交集运算
set1 = {1, 3, 2}
set2 = {2, 4, 3}
print(set1.intersection(set2))
print(set1 & set2)集合运算:并集
-
并集运算
-
union()
-
操作符:|
"""集合运算:并集"""
# 求两个集合的并集
set1 = {1, 3, 2}
set2 = {2, 4, 3}
print(set1.union(set2))
print(set1 | set2)集合运算:差集
-
差集运算
-
difference()
-
操作符: -
"""集合运算:差集"""
# 集合求差集
set1 = {1, 3, 2}
set2 = {2, 4, 3}print(set1.difference(set2))
print(set1 - set2)集合推导式
- 类似列表推导式,同样集合支持集合推导式
- 语法:
{x for x in ... if ...}
st = set()
for s in "hold":if s in "hello world":st.add(s)
print(st)
print(type(st))# 使用推导式生成集合
"""集合推导式"""
# 使用推导式生成集合
# 实例:寻找 hold 与 hello world的共相同字母
st = {x for x in 'hold' if x in 'hello world'}
print(st)
print(type(st))10.python常用数据结构-字典
字典定义
- 字典是无序的键值对集合
- 字典用大括号
{}包围 - 每个键/值对之间用一个逗号分隔
- 各个键与值之间用一个冒号分隔
- 字典是动态的
字典使用:创建
- 创建字典
- 使用大括号填充键值对
- 通过构造方法 dict()
- 使用字典推导式
"""字典使用:创建"""
# 1、使用大括号填充键值对
dc = {'name': 'Harry Potter', 'age': 18}
print(type(dc), dc)# 2、使用字典构造方法
dc1 = dict() # 空字典
dc2 = dict(name="Harry Potter", age=18) # 关键字参数赋值
print(type(dc2), dc2)dc3 = dict([("name", "Harry Potter"), ("age", 18)])
print(type(dc3), dc3)# 3、使用字典推导式
dc4 = {k: v for k, v in [("name", "Harry Potter"), ("age", 18)]}
print(type(dc4), dc4)字典使用:访问元素
- 访问元素
- 与字典也支持中括号记法
[key]。 - 字典使用键来访问其关联的值。
- 访问时对应的 key 必须要存在
- 与字典也支持中括号记法
"""字典使用:访问元素"""
dc = {"name": "Harry Potter", "age": 18}
# 1、访问存在的key
print(dc["name"])
print(dc["age"])# 2、访问不存在的key,会报KeyError错误
print(dc['hobby'])字典使用:操作元素
- 语法:dict[key] = value
- 添加元素
- 键不存在
- 修改元素
- 键已经存在
"""字典使用:操作元素"""
dc = {"name": "Harry Potter", "age": 18}
# 1、修改年龄,改为20
dc['age'] = 20
print(dc)# 2、新增hobby字段
dc['hobby'] = 'Magic'
print(dc)字典使用:嵌套字典
-
嵌套字典
-
字典的值可以是字典对象
"""字典使用:嵌套字典"""
dc = {"name": "Harry Potter", "age": 18, "course": {"magic": 90, "python": 80}}
# 1、获取课程Magic的值
print(dc['course']['magic'])# 2、把python分数改成100分
dc['course']['python'] = 100
print(dc)字典方法
- keys()
- values()
- items()
- get()
- update()
- pop()
字典方法 keys()
-
keys() -
返回由字典键组成的一个新视图对象。
-
入参:无
"""字典方法 keys()"""
dc = {"name": "Harry Potter", "age": 18}
keys = dc.keys()
print(dc.keys())
print(dc.values())
print(dc.items())# 1、遍历查看所有的键
for key in keys:print(key)# 2、将视图对象转成列表
print(list(keys))
print(list(dc.values()))字典方法 values()
-
values() -
返回由字典值组成的一个新视图对象。
"""字典方法 values()"""
dc = {"name": "Harry Potter", "age": 18}
values = dc.values()
print(type(values), values)# 1、遍历查看所有的值
for value in values:print(value)# 2、将视图对象转成列表
print(list(values))字典方法 items()
-
items() -
返回由字典项 ((键, 值) 对) 组成的一个新视图对象。
"""字典方法 items()"""
dc = {"name": "Harry Potter", "age": 18}
items = dc.items()
print(type(items), items)# 1、遍历查看所有的项
for item in items:print(item)# 2、将视图对象转成列表
print(list(items))字典方法 get()
-
get(key) -
获取指定 key 关联的 value 值。
-
入参:
- key:字典的键,必传。
-
返回:
- 如果 key 存在于字典中,返回 key 关联的 value 值。
- 如果 key 不存在,则返回 None。
-
此方法的好处是无需担心 key 是否存在,永远都不会引发 KeyError 错误。
"""字典方法 get()"""
dc = {"name": "Harry Potter", "age": 18}# 1、访问存在的key
name = dc.get("name")
print(name)# 2、访问不存在的key
hobby = dc.get('hobby')
print(hobby)字典方法 update()
-
update(dict) -
使用来自 dict 的键/值对更新字典,覆盖原有的键和值。
-
入参:
- dc:字典对象,必传
-
返回:None
dc = {"name": "Harry Potter", "age": 18}
dc.update({"age": 20, "hobby": "magic"})
print(dc)字典方法 pop()
-
pop(key) -
删除指定 key 的键值对,并返回对应 value 值。
-
入参:
- key:必传
-
返回:
- 如果 key 存在于字典中,则将其移除并返回 value 值
- 如果 key 不存在于字典中,则会引发 KeyError。
"""字典方法 pop()"""
dc = {"name": "Harry Potter", "age": 18}# 1、弹出
item = dc.pop("age")
print(dc, item)# 2、删除不存在的key
dc.pop("hobby") # 报错keyError字典推导式
-
字典推导式:可以从任何以键值对作为元素的可迭代对象中构建出字典。
-
实例:给定一个字典对象
{'a': 1, 'b': 2, 'c': 3},找出其中所有大于 1 的键值对,同时 value 值进行平方运算。
# 未使用字典推导式的写法
dc = {'a': 1, 'b': 2, 'c': 3}
d_old = dict()
for k, v in dc.items():if v > 1:d_old[k] = v ** 2
print(d_old)# 使用字典推导式
d_new = {k: v ** 2 for k, v in dc.items() if v > 1}
print(d_new)练习:
# 给定一个字典对象,请使用字典推导式,将它的key和value分别进行交换。也就是key变成值,值变成key。
# 输入:{'a':1,'b':2,‘c':3}
# 输出:{1:'a',2:'b',3:'c'}dic = {'a': 1, 'b': 2, 'c': 3}
print(dic)
print({v: k for k, v in dic.items()})11.python函数
函数的作用
- 函数是组织好的,可重复使用的,用来实现单一或相关联功能的代码段
- 函数能提高应用的模块性和代码的重复利用率
- python 内置函数:https://docs.python.org/zh-cn/3.8/library/functions.html
函数定义
- def:函数定义关键词
- function_name:函数名称
- ():参数列表放置的位置,可以为空
- parameter_list:可选,指定向函数中传递的参数
- comments:可选,为函数指定注释
- function_body:可选,指定函数体
def function_name([parameter_list]):
[''' comments ''']
[function_body]
定义函数的注意事项
- 缩进:python 是通过严格的缩进来判断代码块儿
- 函数体和注释相对于 def 关键字必须保持一定的缩进,一般都是 4 个空格
- pycharm 自动格式化快捷键:
ctrl+alt+L
- 定义空函数
- 使用
pass语句占位 - 写函数注释 comments
- 使用
函数调用
function_name([parameter_value])
- function_name:函数名称
- parameter_value:可选,指定各个参数的值
参数传递
- 形式参数:定义函数时,函数名称后面括号中的参数
- 实际参数:调用函数时,函数名称后面括号中的参数
# a, b, c 为形式参数
def demo_func(a, b, c):print(a, b, c)# 1, 2, 3 为实际参数
demo_func(1, 2, 3)位置参数
- 数量必须与定义时一致
- 位置必须与定义时一致
def demo_func(a, b, c):print(a, b, c)# 1 赋值给 a, 2 赋值给 b, 3 赋值给 c
demo_func(1, 2, 3)关键字参数
- 使用形式参数的名字确定输入的参数值
- 不需要与形式参数的位置完全一致
def demo_func(a, b, c):print(a, b, c)demo_func(a=1, b=2, c=3)为参数设置默认值
- 定义函数时可以指定形式参数的默认值
- 指定默认值的形式参数必须放在所有参数的最后,否则会产生语法错误
param=default_value:可选,指定参数并且为该参数设置默认值为 default_value
def function_name(..., [param=default_value]):
[function_body]
函数返回值
- value:可选,指定要返回的值
def function_name([parameter_list]):[''' comments '''][function_body]return [value]
def sum(a, b):result = a + breturn resultret = sum(1, 3)
print(ret)12.python函数进阶与参数处理
可变参数
- 可变参数也称为不定长参数
- 传入函数中实际参数可以是任意多个
- 常见形式
*args**kwargs
*args
- 接收任意多个实际参数,并将其放到一个元组中
- 使用已经存在的列表或元组作为函数的可变参数,可以在列表的名称前加
*
def print_language(*args):print(args)print_language("python", "java", "php", "go")params = ["python", "java", "php", "go"]
print_language(*params)**kwargs
- 接收任意多个类似关键字参数一样显式赋值的实际参数,并将其放到一个字典中
- 使用已经存在字典作为函数的可变参数,可以在字典的名称前加
**
def print_info(**kwargs):print(kwargs)print_info(Tom=18, Jim=20, Lily=12)params = {'Tom': 18, 'Jim': 20, 'Lily': 12}
print_info(**params)13.pythonlambda表达式
匿名函数
- 没有名字的函数
- 用 lambda 表达式创建匿名函数
使用场景
- 需要一个函数,但是又不想费神去命名这个函数
- 通常在这个函数只使用一次的场景下
- 可以指定短小的回调函数
语法
- result:调用 lambda 表达式
- [arg1 [, arg2, …. , argn]]:可选,指定要传递的参数列表
- expression:必选,指定一个实现具体功能的表达式
result = lambda [arg1 [, arg2, .... , argn]]: expression
# 1.常规写法
def cricle_area(r):result = math.pi * r * rreturn resultr = 2
print(f"半径为{r}的圆的面积为{cricle_area(r)}")# 2.使用lambda表达实现
r = 2
result = lambda r: math.pi * r * r
print(f"半径为{r}的圆的面积为{result(r)}")
print(lambda r: math.pi * r * r)# 对获取到的信息进行排序
# #书籍信息
book_info = [("python零基础入门", 22.5), ("java 零基础入门", 20), ("软件测试零基础入门", 25)]
print(type(book_info))
print(book_info)# 指定规则进行排序
# 第一个x表示一个对象,比如("python零基础入门", 22.5)
# 第二个x表示对象的索引
book_info.sort(key=lambda x: (x[1]))
print(book_info)14.python面向对象概念
面向对象是什么?
- Python 是一门面向对象的语言
- 面向对象编程(
OOP):Object Oriented Programming
所谓的面向对象,就是在编程的时候尽可能的去模拟真实的现实世界,按照现实世界中的逻辑去处理问题,分析问题中参与其中的有哪些实体,这些实体应该有什么属性和方法,我们如何通过调用这些实体的属性和方法去解决问题。
两种编程思想
- 面向过程
- 一种以过程为中心的编程思想
- 首先分析解决问题所需要的步骤
- 然后用函数将这些步骤一步一步的实现
- 最后按顺序依次调用运行
- 面向对象
- 是一种更符合我们人类思维习惯的编程思想
- 面向对象开发就是不断的创建对象,使用对象,操作对象做事情
- 可以将复杂的事情简单化
类与对象
-
类(
class): 用来描述具有相同的属性和方法的对象的集合。它定义了集合中每个对象所共有的属性和方法。 -
对象(
object):也称为类的实例,是一个具体存在的实体。
15.python类与对象
类的定义
class关键字
# 语法
class 类名(父类名):
"""类的帮助信息"""
属性
方法
# 类的声明
class Human(object):"""人类"""# 定义属性(类属性)message = "这是类属性"# 通过类访问类属性
print(Human.message)类的方法
- 实例方法
- 构造方法
- 类方法
- 静态方法
构造方法与实例化
- 作用:实例化对象
- 语法:
def __init__(self, 参数列表) - 访问:
类名(参数列表)
class Human:# 定义属性(类属性)message = "这是类属性"# 构造方法def __init__(self, name, age):# 实例变量self.name = nameself.age = ageprint("这是构造方法")# 实例化对象
person = Human("哈利波特", 12)# 通过实例访问类属性
print(person.message)# 通过实例访问实例属性
print(person.name)
print(person.age)实例方法
- 作用:提供每个类的实例共享的方法
- 语法:
def 方法名(self, 参数列表) - 访问:
实例.方法名(参数列表)
class Human:# 实例方法def study(self, course):print(f"正在学习{course}")# 实例化
person = Human()# 通过实例访问实例方法
person.study("python")类方法
- 作用:可以操作类的详细信息
- 语法:
@classmethod - 访问:
类名.类方法名(参数列表)
class Human:# 类属性population = 0# 类方法@classmethoddef born(cls):print("这是类方法")cls.population += 1# 通过类名访问类方法
Human.born()
print(Human.population)静态方法
@staticmethod
class Human:# 静态方法@staticmethoddef grow_up():print("这是静态方法")# 通过类名访问静态方法
Human.grow_up()16.学生信息管理系统
-
编写学员实体类 Student,对应成员变量包含:学号 id、姓名 name、性别 sex;
-
编写学员管理类 StudentManagement ,实现添加学员方法 addStudent()。
-
编写StudentManagement的main方法进行学员信息的添加:
学号:1001,姓名:张三,性别:男。 学号:1002,姓名:莉丝,性别:女。 学号:1003,姓名:王武,性别:男。
class Student:def __init__(self, id, name, sex):self.id = idself.name = nameself.sex = sexclass StudentManagement:def __init__(self):passdef addStudent(self, id, name, sex):student = Student(id, name, sex)print(f"添加学员成功:{student.id}, {student.name}, {student.sex}")def main(self):# 添加学员1self.addStudent(1001, "张三", "男")# 添加学员2self.addStudent(1002, "莉丝", "女")# 添加学员3self.addStudent(1003, "王武", "男")stumg = StudentManagement()
stumg.main()运行结果:

相关文章:
Python入门一
目录: python基本操作python基本数据类型python字符串基本操作python的运算符python控制流-判断python控制流-循环python常用数据结构-列表python常用数据结构-元组python常用数据结构-集合python常用数据结构-字典python函数python函数进阶与参数处理pythonlambda…...

mysql_2.4——安装常见问题
1. 将MySQL添加到环境变量 将 mysql 的 bin 目录地址添加到 系统环境变量 --> PATH 中 2. 将MySQL添加到服务 以管理员的方式启动 cmd (命令提示窗口),使用命令进入到 [mysql]\bin ,执行如下命 令。 # mysqld --install (服务名) # 如: mysqld --…...
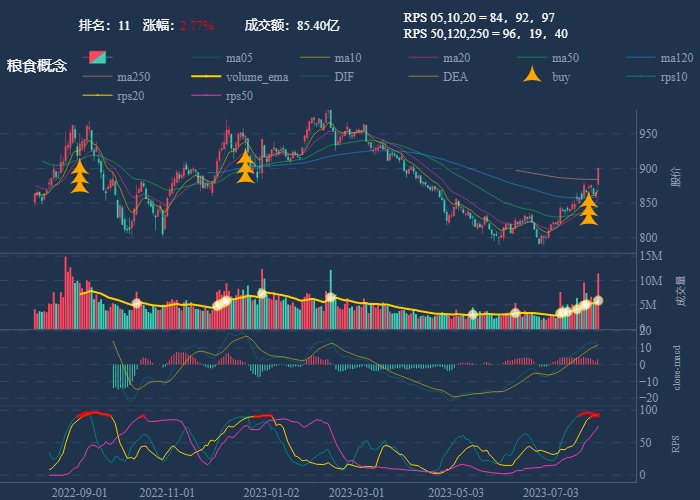
行业追踪,2023-07-31,板块多数都是指向消费
自动复盘 2023-07-31 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...
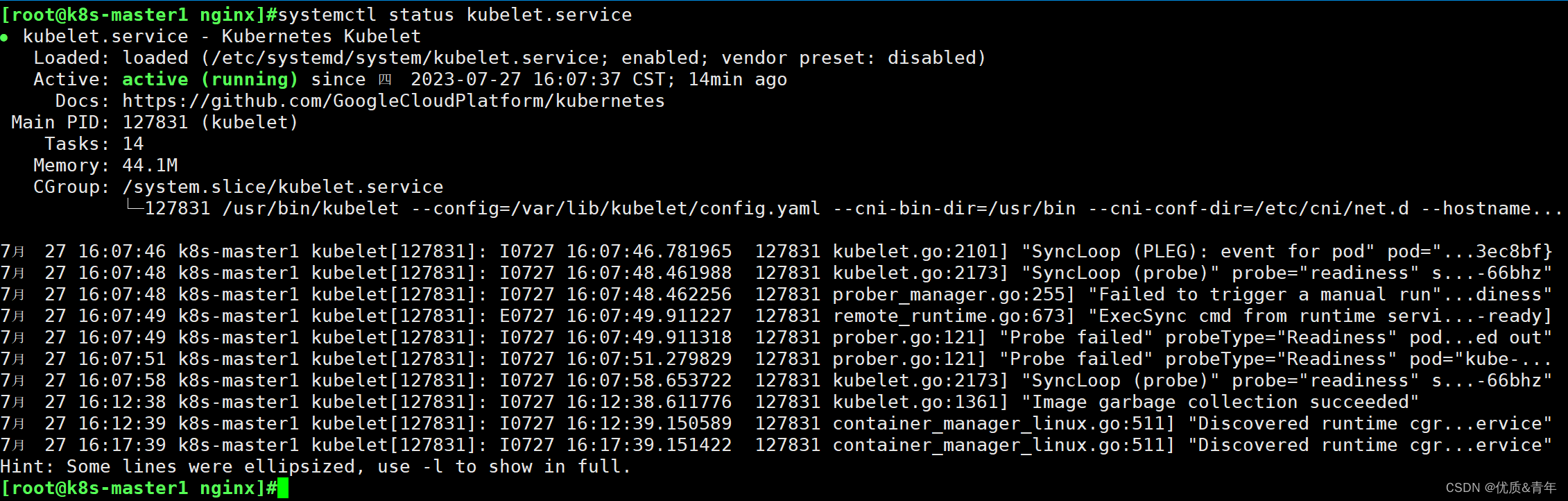
K8S故障排查
故障现象:部署pod时,报错没发调度到节点。 排查步骤: 1、查看集群的状态 [rootk8s-master1 nginx]#kubectl get nodes2、查看k8s组件的状态-kubelet,kube-apiservice 3、查看docker的Cgroup driver和k8s的Cgroup driver类型&…...
idea集成jrebel实现热部署
文章目录 idea集成jrebel实现热部署下载jrebel 插件包下载jrebel mybatisplus extensition 插件包基础配置信息情况一其次情况三情况四情况五情况六情况七 验证生效与否 Jrebel热部署不生效的解决办法 idea集成jrebel实现热部署 在平常开发项目中,我们通常是修改完…...

【Git系列】Git配置SSH免密登录
🐳Git配置SSH免密登录 🧊1.设置用户名和邮箱🧊2. 生成密钥🧊3.远程仓库配置密钥🧊2. 免密登录 在以上push操作过程中,我们第一次push时,是需要进行录入用户名和密码的,比较麻烦。而且…...
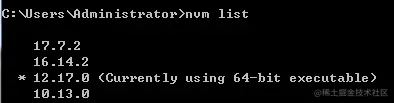
Node.js 安装与版本管理(nvm 的使用)
安装 Node.js Node.js 诞生于 2009 年 5 月,截至今天(2022 年 3 月 26 号)的最新版本为 16.14.2 LTS 和 17.8.0 Current,可以去官网下载合适的版本。 其中,LTS(Long Term Support) 是长期维护…...
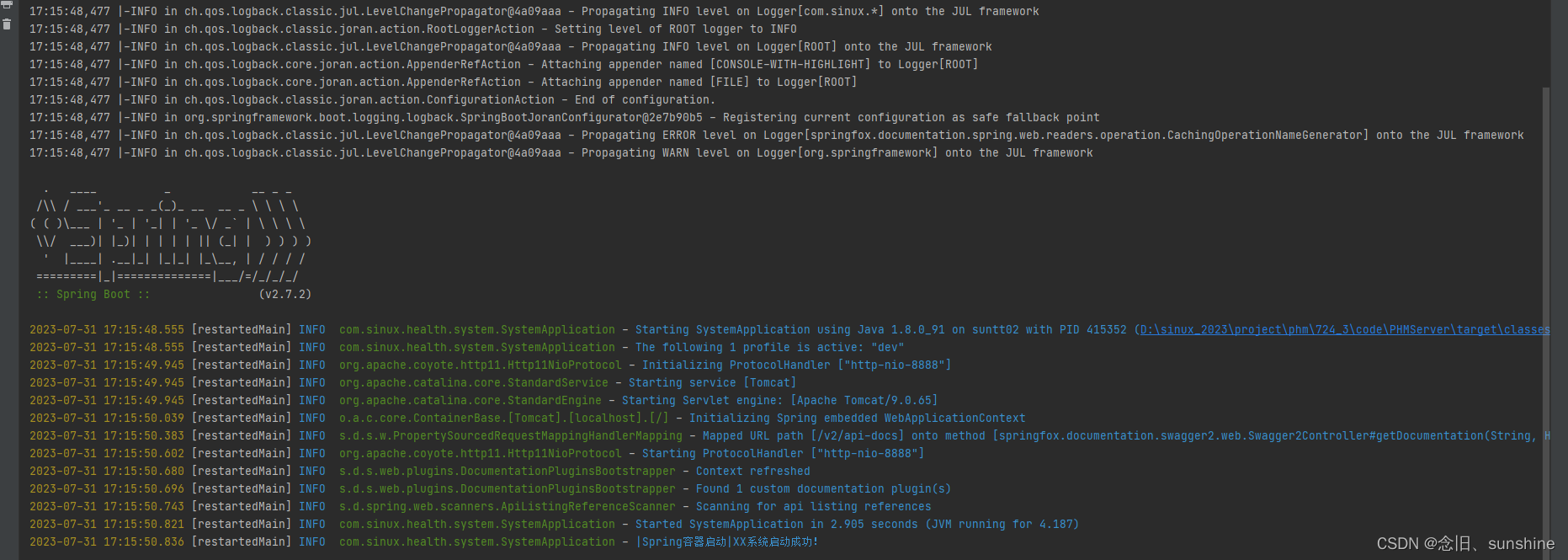
SpringBoot项目中使用Lombok插件中Slf4j日志框架
前言:idea需要安装lombok插件,因为该插件中添加了Slf4j注解,可以将Slf4j翻译成 private static final org.slf4j.Logger logger LoggerFactory.getLogger(this.XXX.class); springboot本身就内置了slf4j日志框架,所以不需要单独…...
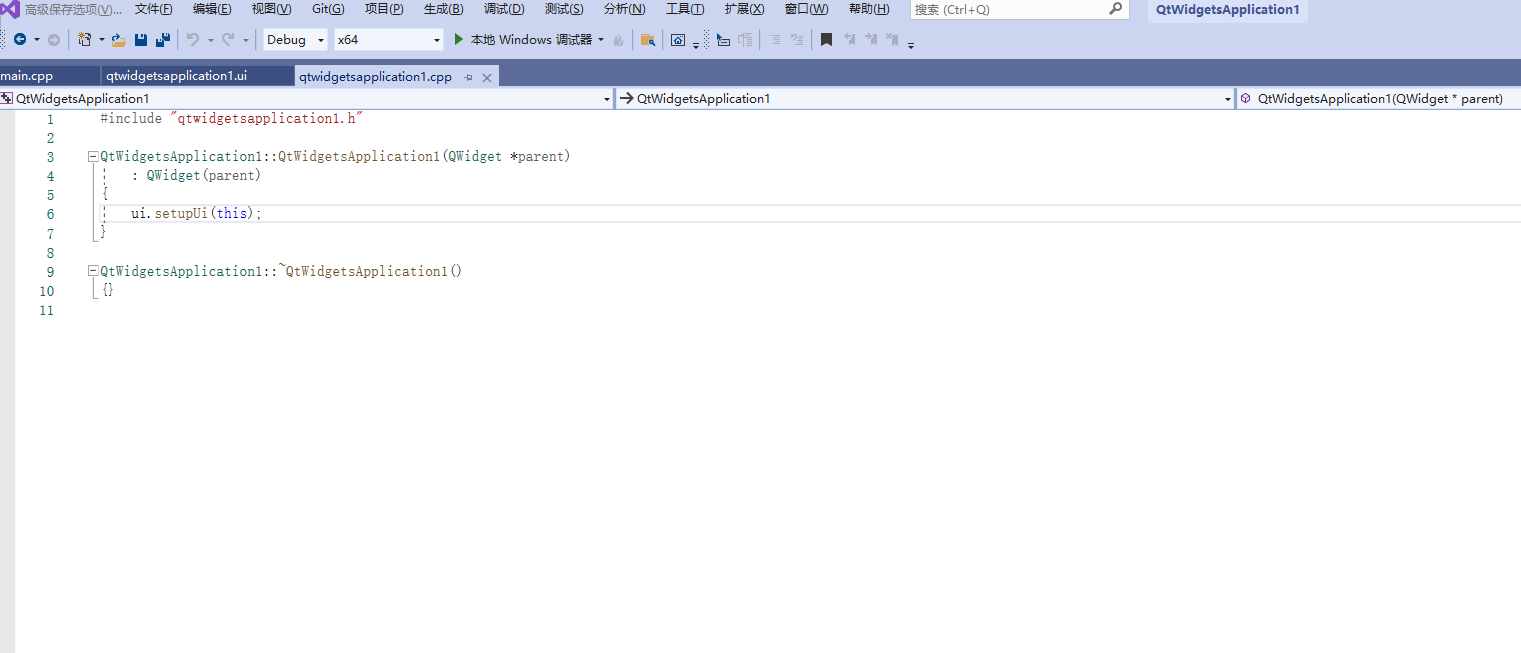
VS下开发Qt应用环境搭建
VS下开发Qt应用环境搭建 版本说明环境搭建步骤QT新增组件重新安装QTVS中的配置 版本说明 vs2019 QT5.14 我之前是按照QT基础组件的安装,但是这个安装只是最基础的组件,如果想要在VS中使用QT,还得安装其他组件,下面的安装流程、 …...
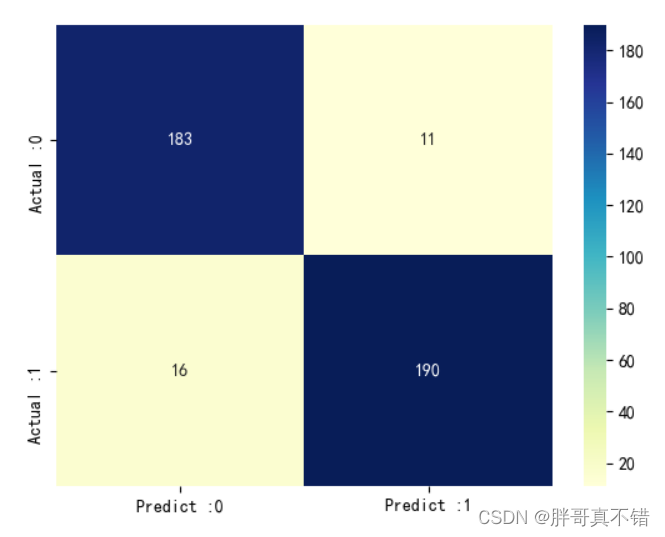
Python实现GA遗传算法优化循环神经网络分类模型(LSTM分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世…...

Spring源码:Spring运行环境Environment
Spring运行环境 Spring在创建容器时,会创建Environment环境对象,用于保存spring应用程序的运行环境相关的信息。在创建环境时,需要创建属性源属性解析器,会解析属性值中的占位符,并进行替换。 创建环境时,…...

SpringBoot使用PropertiesLauncher加载外部jar包
Springboot启动入口源码 默认是org.springframework.boot.loader.JarLauncher <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-loader</artifactId> </dependency>启用SpringBoot的PropertiesLaunche…...

骑行 - 出发前如何准备
现在路上经常见到武装完备的自行车骑手,一般是公路车,出来骑个几十公里是很正常的。出来骑车是个很快乐的事,但出发前还是有许多需要准备的。 最开始,要评估一下天气情况,出车前看下外面天气情况以及预报。提前几天计划…...
ssm员工管理系统
ssm员工管理系统 java员工管理系统 员工管理系统 运行环境: JAVA版本:JDK1.8 IDE类型:IDEA、Eclipse都可运行 数据库类型:MySql(8.x版本都可) 硬件环境:Windows 功能介绍: 1.用户…...
《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(16)-Fiddler如何充当第三者再识AutoResponder标签-上
1.简介 Fiddler充当第三者,主要是通过AutoResponder标签在客户端和服务端之间,Fiddler抓包,然后改包,最后发送。AutoResponder这个功能可以算的上是Fiddler最实用的功能,可以让我们修改服务器端返回的数据,…...
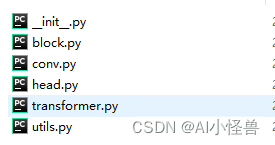
Yolov8新版本解读:优化点如何加入新版本,通过加入EMA注意力进行对比说明
本文目的: 最近yolov8进行了一次较大的更新,对一些优化点加在哪个位置上有些变动,因此本文主要通过具体案列进行对比和说明,以便在新版本上能够轻松上手。 老版本 ultralytics/nn 新版本更新为: modules文件夹下内容如下: 解读: 将modules.py拆分为 1.__init__.…...

NoSQL———Redis配置与优化
目录 一、关系数据库与非关系型数据库 1.1 关系型数据库 1.2 非关系型数据库 1.3 关系型数据库和非关系型数据库区别 1.3.1 非关系型数据库产生背景 二、Redis简介 2.1 redis优点: 三、Redis 安装部署 四、Redis 命令工具 4.1 redis-cli 命令行工具 …...

js,瀑布流
该方法仅满足,元素等宽,高度一般不同的瀑布流布局 计算元素宽度与浏览器宽度之比,得到布局列数;将未布局的元素依次布局至高度最小的那一列;页面滚动时继续加载数据,动态地渲染在页面上。 <div id&quo…...

“深入了解Spring Boot:从入门到精通“
标题:深入了解Spring Boot:从入门到精通 摘要:本文将介绍Spring Boot的基本概念、特性和优势,以及如何使用Spring Boot来开发Java应用程序。通过深入学习Spring Boot的核心组件和常用功能,读者将能够熟练运用Spring B…...
的一个坑)
记录时间计算bug getDay()的一个坑
最近在使用时间计算展示当天所在这一周的数据 不免要获取当前时间所在周 // 时间格式整理函数 function formatDate(date) {const year date.value.getFullYear(),month String(date.value.getMonth() 1).padStart(2, 0),day String(date.value.getDate()).padStart(2, 0)…...

城通网盘解析工具:3步获取高速直连下载地址的终极方案
城通网盘解析工具:3步获取高速直连下载地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否还在为城通网盘的蜗牛下载速度而烦恼?每次下载大文件都要经历漫长的…...

Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生
Real-ESRGAN-GUI 终极指南:免费AI图像增强工具如何让模糊照片重获高清新生 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 你是否曾为模糊的老照片感到无奈&a…...

Excel MCP Server终极指南:让AI成为你的Excel自动化助手
Excel MCP Server终极指南:让AI成为你的Excel自动化助手 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了重复的Excel操作&…...

终极解密指南:Windows平台NCM音频文件一键转换实战
终极解密指南:Windows平台NCM音频文件一键转换实战 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾因网易云音乐的NCM加密格式而烦恼&…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

MySQL 视图使用场景与限制
视图是把查询封装成「虚拟表」的方式,用对了简化查询,用错了性能爆炸。这篇说说视图的用法和注意事项。 什么是视图? -- 视图:保存好的 SQL 查询,像表一样使用 CREATE VIEW view_name AS SELECT column1, column2 FROM…...

深入解析go-containerregistry:无守护进程的容器镜像操作利器
1. 项目概述:容器镜像的“瑞士军刀”如果你在容器化这条路上已经走了一段时间,那么对“镜像”这个概念一定不会陌生。无论是 Docker Hub 上的nginx:latest,还是你公司私有仓库里的myapp:v1.2.3,这些镜像都是容器世界的基石。但你是…...

基于意图与技能解耦的智能对话系统构建指南
1. 项目概述:一个意图与技能驱动的AI对话引擎最近在折腾AI应用开发,特别是对话型AI助手时,发现一个核心痛点:如何让AI不仅能理解用户说了什么(意图识别),还能精准地调用相应的功能(技…...
:提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制)
【独家首发】ElevenLabs乌尔都语语音SDK逆向分析(v2.4.1):提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都语语音SDK逆向分析全景概览 ElevenLabs 官方未公开乌尔都语(ur-PK)的独立语音 SDK,但其 Web API 实际支持该语言的 TTS 合成。通过对官方 JS SDK&am…...