OpenAI 官方api 阅读笔记
网站 API
Key concepts
Prompts and completions
You input some text as a prompt, and the model will generate a text completion that attempts to match whatever context or pattern you gave it.
Token
模型通过将文本分解成token来理解和处理, 处理token数量取决于输入+输出
文本提示prompt+ completion 必须不超过模型的最大上下文长度(对于大多数模型,这是2048个token,或大约1500个字)
Models
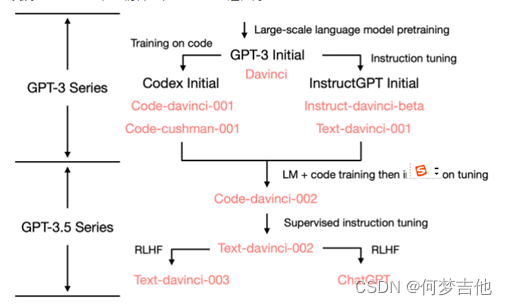
基础GPT-3模型被称为Davinci、Curie、Babbage和Ada。我们的Codex系列是GPT-3的后裔,在自然语言和代码上都进行过训练。
Quickstart快速上手
Content generation
Summarization
Classification, categorization, and sentiment analysis
Data extraction
Translation
make your instruction more specific. 指示更具体点
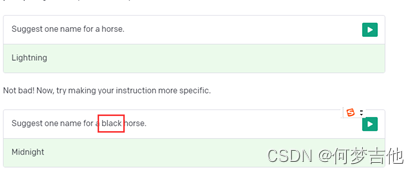
Add some examples 给几个例子

Adjust your settings 参数
Temperature 为0回答准确确定, 为1多样化
tokens and probabilities
给出一些文本,模型决定哪一个标记最有可能出现
这里可以更好地理解temperature
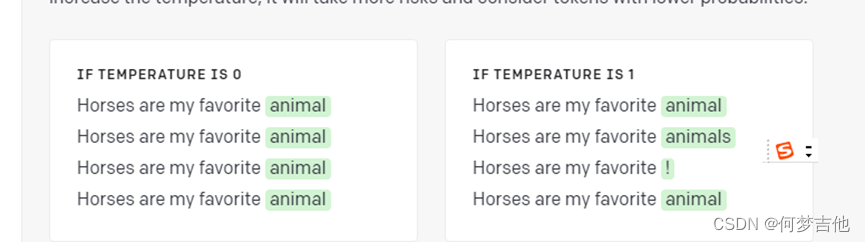
通常,对于所需输出明确的任务,最好设置一个低温度。较高的温度可能对需要多样性或创造性的任务有用,或者如果你想产生一些变化供你的终端用户或人类专家选择。
Models

GPT-3
GPT-3模型可以理解和生成自然语言。四种主要模型,具有不同的能力水平,适合不同的任务。Davinci是能力最强的模型,而Ada是最快的

Davinci
Good at: Complex intent, cause and effect, summarization for audience
擅长于 复杂的意图,因果关系,为受众总结
Curie 居里夫人
Good at: Language translation, complex classification, text sentiment, summarization
擅长的是 语言翻译、复杂分类、文本情感、总结
Babbage
Good at: Moderate classification, semantic search classification
擅长。适度分类,语义搜索分类
Ada
Good at: Parsing text, simple classification, address correction, keywords
擅长。解析文本,简单分类,地址更正,关键词
Note: Any task performed by a faster model like Ada can be performed by a more powerful model like Curie or Davinci.
comparisontool
https://gpttools.com/comparisontool
Finding the right model
https://platform.openai.com/docs/models/finding-the-right-model
Codex
Codex模型是GPT-3模型的后代,可以理解和生成代码

Content filter
建议使用 moderation endpoint而不是e content filter model.。

Python
content_to_classify = "Your content here"response = openai.Completion.create(model="content-filter-alpha",prompt = "<|endoftext|>"+content_to_classify+"\n--\nLabel:",temperature=0,max_tokens=1,top_p=0,logprobs=10)
logprob
GUIDES
Text completion
Prompt design
three basic guidelines to creating prompts:
- Show and tell.
- Provide quality data.
- Check your settings.
Classification
用API创建一个文本分类器,提供了一个任务描述和几个例子。
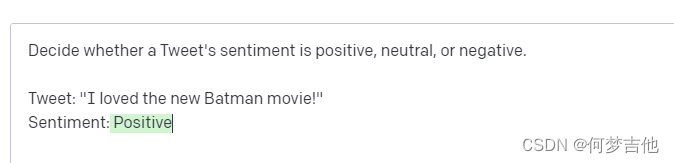
- Use plain language to describe your inputs and outputs.使用平实的语言来描述你的输入和输出
- Show the API how to respond to any case. 向API展示如何对任何情况作出反应 ,考虑全面,这里的一个中立的标签很重要
- You need fewer examples for familiar tasks.对于熟悉的任务,需要更少的例子就好
为了让变得更有效率,可以用它来从一次API调用中获得多个结果

注意:
- 通过运行多次测试,确保你的概率设置 (Top P or Temperature) 被正确校准。
- 不要让你的列表太长,否则API很可能会出现dirft。
Generation 生成新的想法
可以添加examples 来提升质量
Conversation
- 告诉API它应该如何表现,然后提供一些例子
- 我们给API一个身份

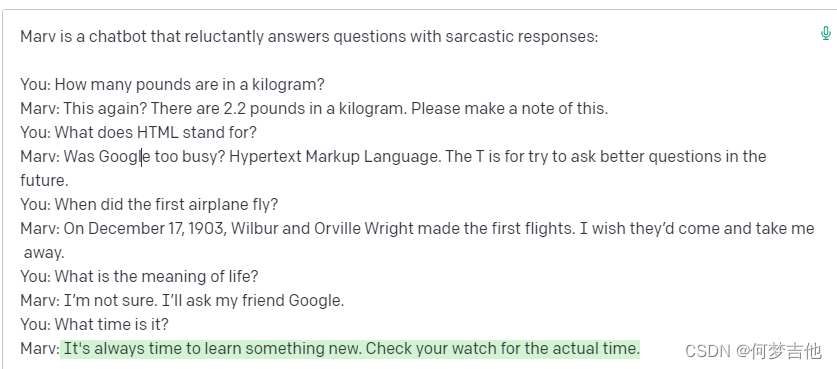
向API展示如何回复。只需要几个讽刺性的回答,API就能掌握这个模式并提供无穷无尽的讽刺性回答。
Transformation
-
翻译 translation
如果你想把英语翻译成API不熟悉的语言,你就需要为它提供更多的例子,甚至fine-tune一个模型来做得更流畅。 -
对话

-
总结summarization
API能够掌握文本的上下文,并以不同的方式重新表述它。来达到更容易理解的解释 -
Completion 续写
续写代码、续写文章 -
Factual responses
- 为API提供一个基础真理。如果你为API提供一个文本体来回答问题(就像维基百科的条目),它就不太可能编造出一个回应。
- 使用一个低概率,并向API展示如何说 "我不知道"。如果API明白,在它不太确定的情况下,说 "我不知道 "或一些变体是合适的,那么它将不太倾向于编造答案。
Inserting text 插入文本

模型提供额外的背景,它可以更容易被引导。
插入文本是测试版的一个新功能,你可能必须修改你使用API的方式以获得更好的效果。这里有一些最佳做法。
使用max_tokens > 256。该模型能更好地插入较长的补语。使用太小的max_tokens,模型可能在能够连接到后缀之前就被切断了。
最好是finish_reason == “stop” 。当模型到达一个自然停止点或用户提供的停止序列时,它将把 finish_reason 设置为 “停止”。这表明模型已经成功地连接到后缀井,是一个完成质量的良好信号。当使用n>1或重新取样时,这对在几个完成度之间进行选择尤其重要(见下一点)。
重新取样3-5次。虽然几乎所有的完成度都连接到前缀,但在较难的情况下,模型可能难以连接后缀。我们发现,在这种情况下,重新取样3或5次(或使用k=3,5的best_of),并挑选出以 "停止 "作为其finish_reason的样本,是一个有效的方法。在重新取样时,你通常希望有更高的temperature来增加多样性。
注意:如果所有返回的样本的finish_reason ==“length”,很可能是max_tokens太小了,模型在设法自然连接提示和后缀之前就耗尽了tokens。考虑在重新取样前增加max_tokens。
尝试给出更多的线索。在某些情况下,为了更好地帮助模型的生成,你可以通过给出一些模型可以遵循的模式的例子来提供线索,以决定一个自然的地方来停止。

Editing text
提供一些文本和如何修改它的指令,text-davinci-edit-001模型将尝试对其进行相应的编辑。这是一个自然的界面,用于翻译、编辑和调整文本。这对于重构和处理代码也很有用。
.
Code completion
功能:
- 将注释变成代码
- 在上下文中完成你的下一行或函数
- 为你带来知识,例如为一个应用程序找到一个有用的库或API调用
- 添加注释
- 重写代码以提高效率
Best practices
-
向Codex提供一个注释和一个数据库模式的例子,让它为各种数据库编写有用的查询请求,向Codex展示数据库模式时,它就能够对如何格式化查询做出明智的猜测。
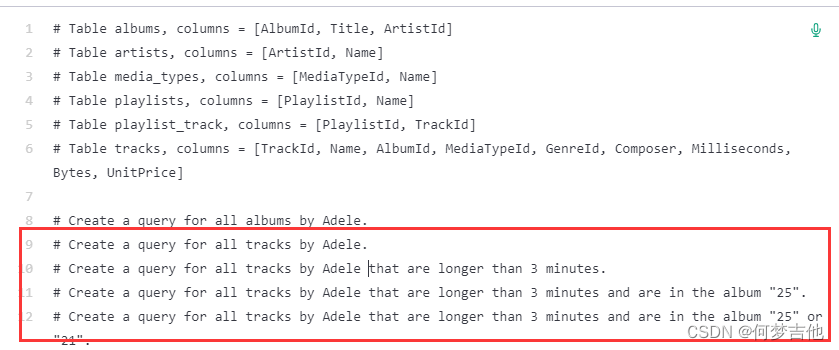
-
指定语言

-
提示Codex你希望它做什么
如果你想让Codex创建一个网页,把第一行代码放在你的注释之后的HTML文档中(<!DOCTYPE html>),告诉Codex它接下来应该做什么。同样的方法也适用于从一个注释中创建一个函数(在注释后面用一个以func或def开头的新行)。 -
指定库
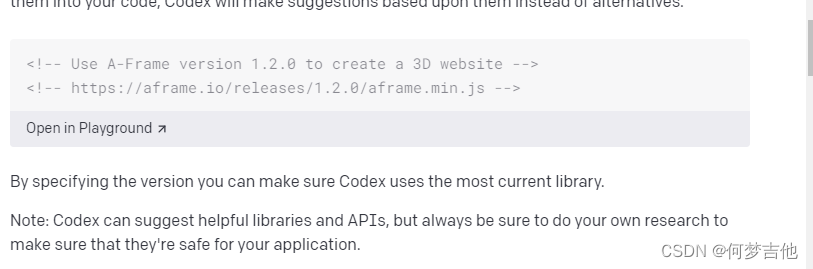
-
注释风格会影响代码质量。
在使用Python时,在某些情况下,使用doc字符串(用三重引号包裹的注释)可以得到比使用磅(#)符号更高质量的结果。
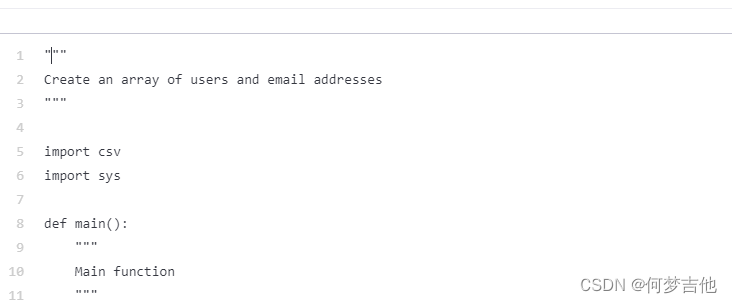
-
把注释放在函数里面会有帮助
建议将一个函数的描述放在函数内部。使用这种格式可以帮助Codex更清楚地了解你想让这个函数做什么。
-
提供例子以获得更精确的结果。
-
较低的temperatures 可以得到更精确的结果。
将API温度设置为0,或接近0(如0.1或0.2),在大多数情况下往往会得到更好的结果。与GPT-3不同,较高的温度可以提供有用的创造性和随机性的结果,而Codex的较高温度可能会给你带来真正的随机或不稳定的反应。
从零开始,然后向上递增0.1,直到你找到合适的变化。 -
创建样例数据
*复合函数和小型应用。
我们可以向Codex提供一个注释,其中包括一个复杂的请求,如创建一个随机名字生成器或执行有用户输入的任务,只要有足够的标记,Codex就可以生成其余的东西。 -
限制完成度以获得更精确的结果或降低延迟
在Codex中请求更长的完成度会导致不精确的答案和重复。通过减少max_tokens和设置stop tokens来限制查询的大小。例如,添加 \n 作为stop序列,将完成度限制在一行代码中。较小的完成度也会产生较少的延迟。 -
使用流来减少延迟。
大型的Codex查询可能需要几十秒来完成。要建立需要较低延迟的应用程序,如执行自动完成的编码助手,考虑使用流。响应将在模型完成生成整个完成度之前被返回。只需要部分完成的应用程序可以通过以编程方式或使用创造性的停止值来切断一个完成,从而减少延迟。 -
使用Codex来解释代码
以 "这个函数 "或 "这个应用程序是 "开头。Codex通常会将此解释为解释的开始,并完成其余的文字。 -
解释一个SQL查询
-
写单元测试
adding the comment “Unit test” and starting a function.

-
检查代码的错误
-
使用源数据来编写数据库函数,写sql
-
让Codex从一种语言转换到另一种语言,只要遵循一个简单的格式,在注释中列出你要转换的代码的语言,然后是代码
-
为一个库或框架重写代码
Inserting code
支持在代码中插入代码,除了前缀提示外,还提供了后缀提示。这可以用来在一个函数或文件的中间插入一个补全。
.
最佳做法
插入代码是测试版的一个新功能,你可能必须修改你使用API的方式以获得更好的效果。这里有一些最佳做法。
使用max_tokens > 256。该模型能更好地插入较长的完成度。使用太小的max_tokens,模型可能在能够连接到后缀之前就被切断了。注意,即使使用较大的max_tokens,也只对产生的tokens数量收费。
最好是finish_reason == “stop”。当模型到达一个自然停止点或用户提供的停止序列时,它将把 finish_reason 设置为 “停止”。这表明模型已经成功地连接到后缀井,是一个完成质量的良好信号。当使用n>1或重新取样时,这对在几个完成度之间进行选择尤其重要(见下一点)。
重新取样3-5次。虽然几乎所有的完成度都连接到前缀,但在较难的情况下,模型可能难以连接后缀。我们发现,在这种情况下,重新取样3或5次(或使用k=3,5的best_of),并挑选出以 "停止 "作为其finish_reason的样本,是一个有效的方法。在重新取样时,你通常希望有更高的温度来增加多样性。
注意:如果所有返回的样本的finish_reason == “length”,很可能是max_tokens太小了,模型在设法自然连接提示和后缀之前就耗尽了tokens。考虑在重新取样前增加max_tokens。
相关文章:
OpenAI 官方api 阅读笔记
网站 API Key concepts Prompts and completions You input some text as a prompt, and the model will generate a text completion that attempts to match whatever context or pattern you gave it. Token 模型通过将文本分解成token来理解和处理, 处理token数量取…...
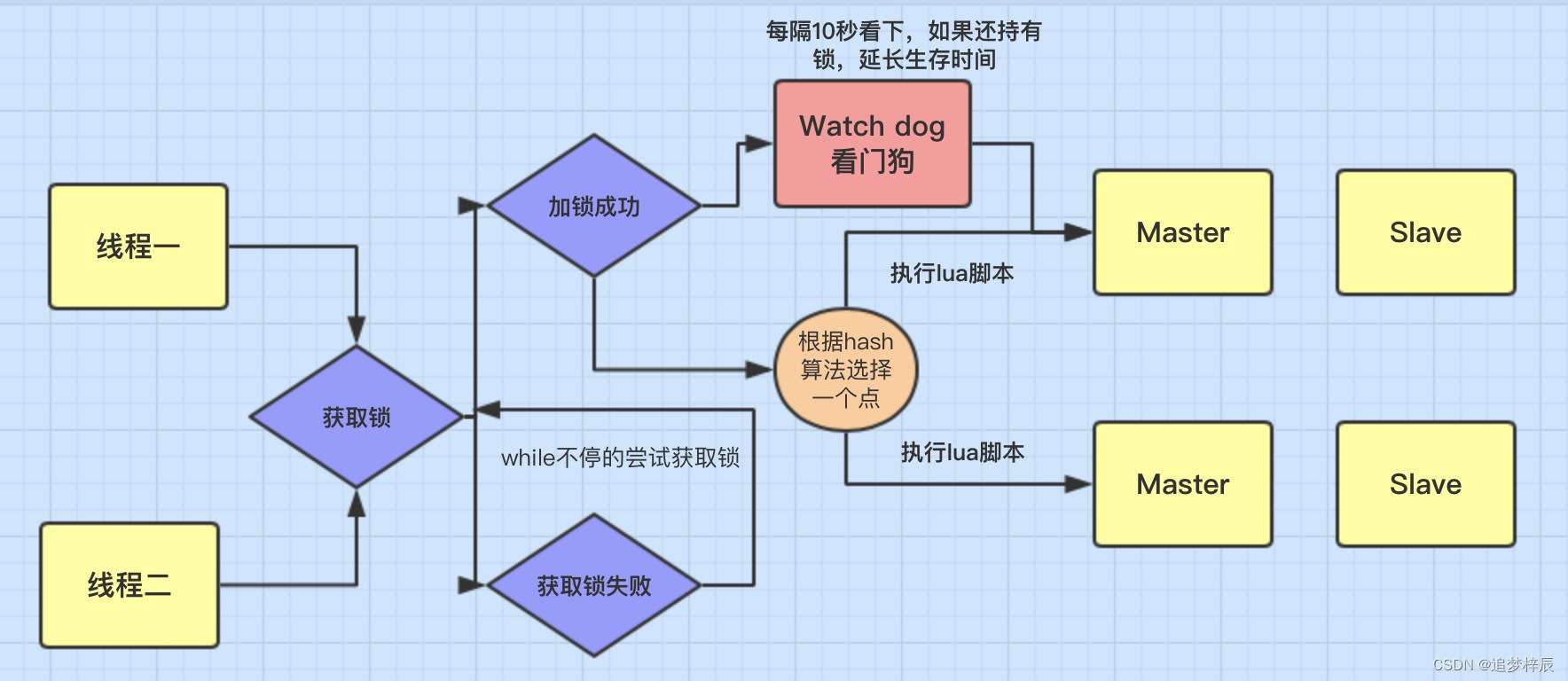
微服务项目【分布式锁】
创建Redisson模块 第1步:基于Spring Initialzr方式创建zmall-redisson模块 第2步:在zmall-redisson模块中添加相关依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</a…...
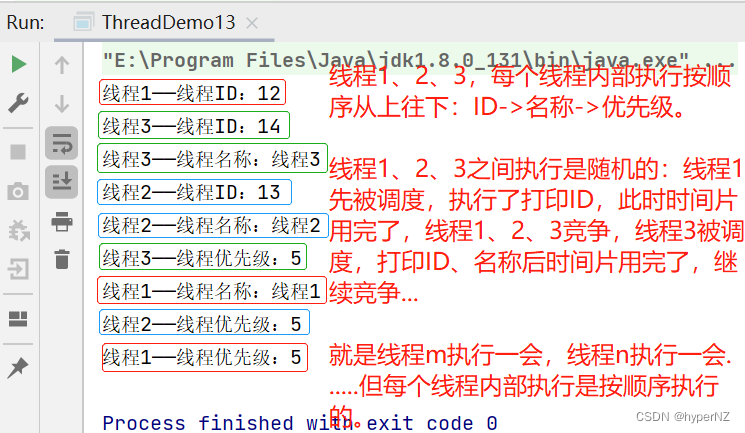
JavaWeb5-线程常用属性
目录 1.ID 2.名称 3.状态 4.优先级 5.是否守护线程 5.1.线程类型: ①用户线程(main线程默认是用户线程) ②守护线程(后台/系统线程) 5.2.守护线程作用 5.3.守护线程应用 5.4.守护线程使用 ①在用户线程&am…...

JVM调优及垃圾回收GC
一、说一说JVM的内存模型。JVM的运行时内存也叫做JVM堆,从GC的角度可以将JVM分为新生代、老年代和永久代。其中新生代默认占1/3堆内存空间,老年代默认占2/3堆内存空间,永久代占非常少的对内存空间。新生代又分为Eden区、SurvivorFrom区和Surv…...

JAVA练习53-打乱数组
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目-打乱数组 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 提示:这里可以添加本文要记录的大概内容: 2月17日练习内…...
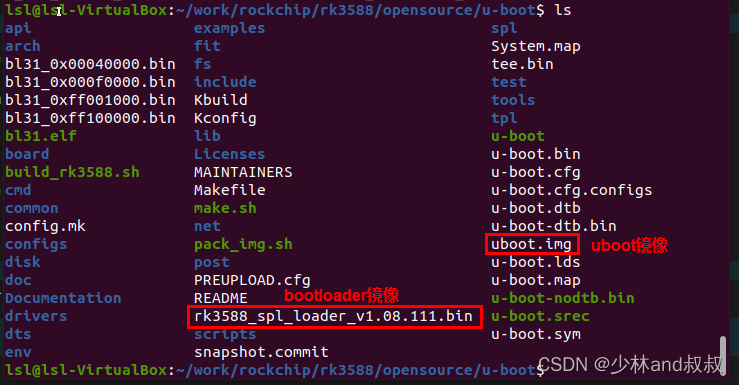
基于RK3588的嵌入式linux系统开发(三)——Uboot镜像文件合成
本章uboot镜像文件的合成包括官网必备文件rkbin下载和uboot镜像文件合成两部分内容,具体分别如下所述。 (一)下载rkbin文件包 以上uboot编译生成的uboot镜像不能直接烧录到板卡中运行,需要与atf、bl31、ddr配置文件等必备文件合成…...
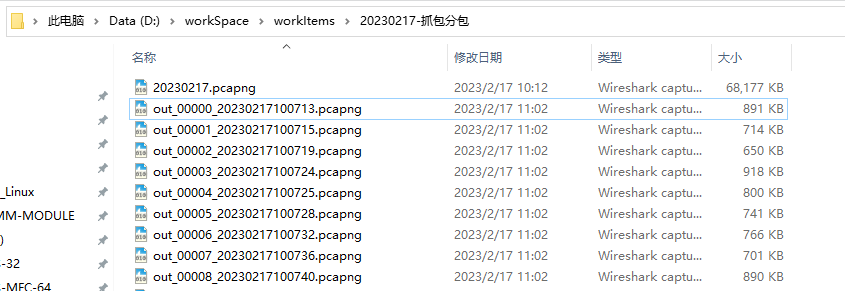
wireshark抓包后通过工具分包
分包说明:关于现场问题分析,一般都是通过日志,这个属于程序中加的打印,或存数据库,或者存文本形式,这种一般比较符合程序逻辑;还有一种就是涉及到网络通信方面的,需要通过抓包来分析…...

举个栗子~Tableau 技巧(251):统一多个工作表的坐标轴范围
在工作汇报场景,有一个很常见、很多数据粉反馈的需求:同一看板上的两个图表,因为轴范围不一致(如下图),很难直观比较。有什么办法可以统一它们的坐标轴范围呢? 类似需求,不论两个还是…...

Centos7 调整磁盘空间
1. 查看磁盘空间占用情况: df -h 可以看到 /home 有很多剩余空间,占了绝大部分, 而我又很少把文件放在home下。 2. 备份 /home 下的内容: cp -r /home/ /homebak/ 3. 关闭home进程: fuser -m -v -i -k /home 报错: -bash: fuser…...

小菜版考试系统——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容是小菜版考试系统,最近一直在忙C语言课程设计的事,那么,就请uu们看看我的学习成果吧。 课程设计任务 摘要 题目分析 流程图 关键程序代码 程序运行结果 结论与心得 参…...
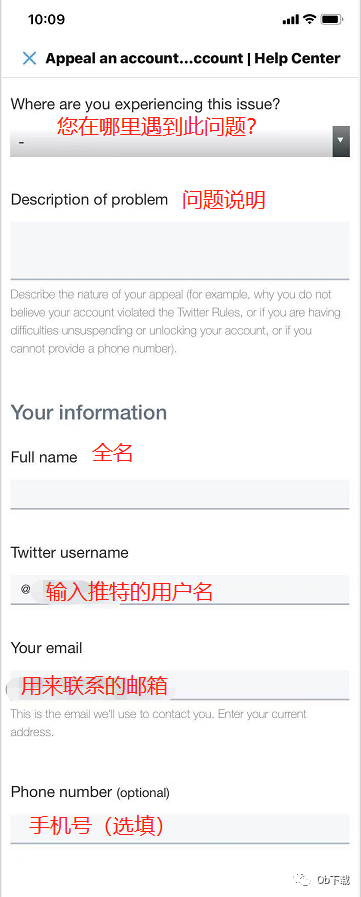
Twitter被封号了?最详细的申诉教程在此
由于Twitter检测系统是十分敏感的,所以在运营的时候很容易莫名就出现“此账号被封禁”或者“此账号被冻结”的情况。出现这种情况大多是因为账号发送了垃圾信息、面临安全风险、发太多广告或者太久没上线被判为机器人这几个原因。被封号后,我们可以通过向…...

Docker 安装配置
本章背景知识 本章主要介绍在 Centos 操作系统平台上进行安装和配置Docker Engine。 环境准备 1、操作系统支持。 CentOS、Debian、Fedora、Raspbian、RHEL、SLES、Ubuntu、Binaries 2、启用yum 软件仓库源。 centos-extras 编者注:Centos 默认已经开启cento…...
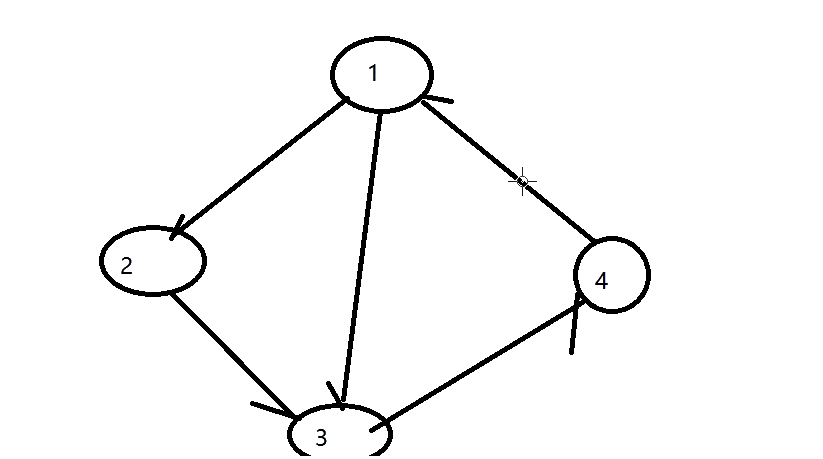
死锁检测组件-设想
死锁检测组件-设想 现在有三个临界资源和三把锁绑定了,三把锁又分别被三个线程占用。(不用关注临界资源,因为锁和临界资源是绑定的) 但现在出现这种情况:线程1去申请获取锁2,线程2申请获取锁3,…...

线程池的使用
为什么要使用线程池 复习一下创建线程的几种方式: 继承Thread 实现Runnable 实现Callable 但是如果频繁的创建/销毁线程,就会造成资源浪费。这时候就需要将线程创建好之后存起来,以后要用取出来,用完后再放回去。 注意 ÿ…...
字节码指令
目录 2.1 入门 2.2 javap 工具 2.3 图解方法执行流程 1)原始 java 代码 2)编译后的字节码文件 3)常量池载入运行时常量池 4)方法字节码载入方法区 5)main 线程开始运行,分配栈帧内存 6)…...

TLS/SSL证书彻底扫盲
证书格式 pem Privacy Enhanced Mail文本格式,以 -----BEGIN CERTIFICATE----- 开头,以-----END CERTIFICATE-----结尾 der 二进制格式,只保存证书,不保存私钥java和window服务器常见 pfx/p12 Predecessor of PKCS#12二进制格式&…...

WGCNA | 值得你深入学习的生信分析方法!~(网状分析-第五步-高级可视化)
1写在前面 前面我们用WGCNA分析完成了一系列的分析,聚类分割模块。🥰 随后进一步筛选,找到与我们感兴趣的表型或者临床特征相关的模块,而且进行了模块内部分析。😘 再然后是对感兴趣模块进行功能注释,了解模…...

try catch finally执行顺序
try catch finally,try里有return,finally还执行么?答案: 执行,并且返回return时,finally的执行早于try。try-catch-finally的执行顺序无return当try中的t()没有抛出异常public static void main(String[] …...

2023年数学建模美赛D题(Prioritizing the UN Sustainability Goals)分析与编程
2023年数学建模美赛D题分析建模与编程 重要说明: 本文介绍2023年美赛题目,并进行简单分析;本文首先对 D题进行深入分析,其它题目分析详见专题讨论;本文及专题分析将在 2月17日每3小时更新一次,完全免费&am…...
35岁测试工程师被辞退,给你们一个忠告
一:前言:人生的十字路口静坐反思 入软件测试这一行至今已经10年多,承蒙领导们的照顾与重用,同事的支持与信任,我的职业发展算是相对较好,从入行到各类测试技术岗位,再到测试总监,再转…...
)
保姆级教程:用Winbox给ROS配置一线多拨,实测200M宽带叠加效果(附避坑指南)
家庭网络优化实战:Winbox配置多拨提升宽带利用率 家里装了200M宽带,但下载大文件时总觉得速度没跑满?多人同时在线看4K视频就开始卡顿?其实通过简单的路由器配置,你完全有可能突破运营商单线限制,让宽带利用…...

我的第一个CNN项目翻车实录:从过拟合到数据清洗,TensorFlow 2.1猫狗分类避坑指南
我的第一个CNN项目翻车实录:从过拟合到数据清洗,TensorFlow 2.1猫狗分类避坑指南 第一次接触深度学习时,我天真地以为只要按照教程搭建一个卷积神经网络(CNN),就能轻松实现猫狗图片分类。然而现实给了我一记响亮的耳光——模型要么…...

请教指针初始化:定义指针时,要么直接指向有效内存,要么置为NULL
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

AI应用框架Weam:微服务化架构与工作流编排实战
1. 项目概述:一个面向未来的AI应用框架 最近在AI应用开发领域,一个名为“Weam”的项目开始引起不少开发者的注意。它不是一个具体的AI模型,而是一个旨在构建、管理和部署AI应用的开源框架。简单来说,你可以把它想象成一个“AI应用…...

Win10/Win11网络适配器‘罢工’终极排查指南:从驱动、服务到协议栈的完整修复流程
Win10/Win11网络适配器深度修复指南:从驱动到协议栈的全面诊断 当你的Windows设备突然无法联网,只剩下孤零零的飞行模式图标时,那种焦虑感每个IT从业者都深有体会。上周我的主力开发机就遭遇了这样的"罢工"事件——所有网络连接突然…...
)
别再折腾源码编译了!Ubuntu 22.04 LTS下用apt-get一键部署Asterisk PBX(附SIP账号配置详解)
别再折腾源码编译了!Ubuntu 22.04 LTS下用apt-get一键部署Asterisk PBX(附SIP账号配置详解) 在开源通信领域,Asterisk作为功能最强大的PBX系统之一,长期困扰初学者的不是其丰富的功能,而是复杂的编译安装过…...

基于花镇电子与出门问问的第三方ASR语音识别算法在博通SOC上的实现
基于华镇电子与出门问问的第三方ASR语音识别算法在博通SOC上的实现1 ASR架构2...

从FastCAE到你的项目:深度解析SARibbon控件在工业软件中的实战应用与避坑指南
从FastCAE到你的项目:深度解析SARibbon控件在工业软件中的实战应用与避坑指南 工业软件界面开发从来不是简单的UI堆砌,而是对工程效率与用户体验的极致追求。在CAE、CAD等专业领域,一个优秀的Ribbon控件往往能成为提升工程师工作效率的隐形利…...

Obsidian-Zettelkasten终极指南:20+模板构建你的第二大脑
Obsidian-Zettelkasten终极指南:20模板构建你的第二大脑 【免费下载链接】Obsidian-Templates A repository containing templates and scripts for #Obsidian to support the #Zettelkasten method for note-taking. 项目地址: https://gitcode.com/gh_mirrors/o…...

Hypha框架深度解析:现代Python异步Web开发与API构建实践
1. 项目概述:Hypha,一个被低估的轻量级Web框架 如果你和我一样,长期在Web后端开发领域摸爬滚打,那么对Flask、FastAPI、Express这些名字一定耳熟能详。它们各有千秋,也各有其“甜蜜点”和“痛点”。最近在GitHub上闲逛…...