[Pytorch]手写数字识别——真·手写!
Github网址:https://github.com/diaoquesang/pytorchTutorials/tree/main
本教程创建于2023/7/31,几乎所有代码都有对应的注释,帮助初学者理解dataset、dataloader、transform的封装,初步体验调参的过程,初步掌握opencv、pandas、os等库的使用,😋纯手撸手写数字识别项目(为减少代码量简化了部分数据集相关操作),全流程跑通Pytorch!❤️❤️❤️
This tutorial was created on 2023/7/31. Almost all the code has corresponding comments, to help beginners understand dataset, dataloader, transform packaging, preliminary experience of the process of tuning the parameters, the initial grasp of the use of libraries such as opencv, pandas, os, etc., 😋 and get involved in this handwritten digit recognition project (we simplified some dataset-related operations in order to reduce the amount of code). Enjoy the whole process of running Pytorch!❤️❤️❤️如果喜欢本项目的话,留下你的⭐吧!
Give me a ⭐ if you like this project!
一、train.py
import torch
import torchvisionfrom torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transformsimport os
import cv2 as cv
import pandas as pdclass myDataset(Dataset): # 定义数据集类def __init__(self, annotations_file, img_dir, transform=None,target_transform=None): # 传入参数(标签路径,图像路径,图像预处理方式,标签预处理方式)self.img_labels = pd.read_csv(annotations_file, sep=" ", header=None)# 从标签路径中读取标签,sep为划分间隔符,header为列标题的行位置self.img_dir = img_dir # 读取图像路径self.transform = transform # 读取图像预处理方式self.target_transform = target_transform # 读取标签预处理方式def __len__(self):return len(self.img_labels) # 读取标签数量作为数据集长度def __getitem__(self, idx): # 从数据集中取出数据img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])# 从标签对象中取出第idx行第0列(第0列为图像位置所在列)的值(numberImages\5.bmp),并与图像路径(numberImages)进行拼接image = cv.imread(img_path) # 用openCV的imread函数读取图像label = self.img_labels.iloc[idx, 1] # 从标签对象中取出第idx行第1列(第1列为图像标签所在列)的值(5)if self.transform:image = self.transform(image) # 图像预处理if self.target_transform:label = self.target_transform(label) # 标签预处理return image, label # 返回图像和标签class myTransformMethod1(): # Python3默认继承object类def __call__(self, img): # __call___,让类实例变成一个可以被调用的对象,像函数img = cv.resize(img, (28, 28)) # 改变图像大小img = cv.cvtColor(img, cv.COLOR_BGR2RGB) # 将BGR(openCV默认读取为BGR)改为RGBreturn img # 返回预处理后的图像# 测试函数
# print(pd.read_csv("annotations.txt", sep=" ", header=None))
# print(os.path.join("numberImages", pd.read_csv("annotations.txt", sep=" ", header=None).iloc[5, 0]))
# print(pd.read_csv("annotations.txt", sep=" ", header=None).iloc[5, 1])
# cv.imshow("1",cv.imread(os.path.join("numberImages", pd.read_csv("annotations.txt", sep=" ", header=None).iloc[5, 0])))
# cv.waitKey(0)class myNetwork(nn.Module): # 定义神经网络def __init__(self):super().__init__() # 继承nn.Module的构造器self.flatten = nn.Flatten(-3, -1)# 继承nn.Module的Flatten函数并改为flatten,考虑到推理时没有batch(CHW),若使用默认值(1,-1)会导致C没有被flatten,故使用(-3,-1)self.linear_relu_stack = nn.Sequential( # 定义前向传播序列nn.Linear(3 * 28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),)def forward(self, x): # 定义前向传播方法x = self.flatten(x)logits = self.linear_relu_stack(x)return logits# 设置运行环境,默认为cuda,若cuda不可用则改为mps,若mps也不可用则改为cpu
device = ("cuda"if torch.cuda.is_available()else "mps"if torch.backends.mps.is_available()else "cpu"
)
print(f"Using {device} device") # 输出运行环境model = myNetwork().to(device) # 创建神经网络模型实例# 设置超参数
learning_rate = 1e-5 # 学习率
batch_size = 8 # 每批数据数量
epochs = 3000 # 总轮数img_path = "./numberImages" # 设置图像路径
label_path = "./annotations.txt" # 设置标签路径myTransform = transforms.Compose([myTransformMethod1(), transforms.ToTensor()])
# 定义图像预处理组合,ToTensor()中Pytorch将HWC(openCV默认读取为height,width,channel)改为CHW,并将值[0,255]除以255进行归一化[0,1]myDataset = myDataset(label_path, img_path, myTransform) # 创建数据集实例myDataLoader = DataLoader(myDataset, batch_size=batch_size,shuffle=True)
# 创建数据读取器(可对训练集和测试集分别创建),batch_size为每批数据数量(一般为2的n次幂以提高运行速度),shuffle为随机打乱数据def train():# 根据epochs(总轮数)训练for epoch in range(epochs):totalLoss = 0# 分批读取数据for batch, (images, labels) in enumerate(myDataLoader):# 数据转换到对应运行环境images = images.to(device)labels = labels.to(device)pred = model(images) # 前向传播myLoss = nn.CrossEntropyLoss() # 定义损失函数(交叉熵)optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 定义优化器loss = myLoss(pred, labels) # 计算损失函数totalLoss += loss # 计入总损失函数loss.backward() # 反向传播optimizer.step() # 更新权重optimizer.zero_grad() # 清空梯度if batch % 1 == 0: # 每隔1个batch输出1次lossloss, current = loss.item(), min((batch + 1) * batch_size,len(myDataset))print(f"epoch: {epoch:>5d} loss: {loss:>7f} [{current:>5d}/{len(myDataset):>5d}]")if epoch == 0:minTotalLoss = totalLossif totalLoss < minTotalLoss:print("······························模型已保存······························")minTotalLoss = totalLosstorch.save(model, "./myModel.pth") # 保存性能最好的模型if __name__ == "__main__":model.train() # 设置训练模式train()二、eval.py
import torch
import torchvisionfrom torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transformsimport os
import cv2 as cv
import pandas as pdclass myTransformMethod1(): # Python3默认继承object类def __call__(self, img): # __call___,让类实例变成一个可以被调用的对象,像函数img = cv.resize(img, (28, 28)) # 改变图像大小img = cv.cvtColor(img, cv.COLOR_BGR2RGB) # 将BGR(openCV默认读取为BGR)改为RGBreturn img # 返回预处理后的图像class myNetwork(nn.Module): # 定义神经网络def __init__(self):super().__init__() # 继承nn.Module的构造器self.flatten = nn.Flatten(-3, -1)# 继承nn.Module的Flatten函数并改为flatten,考虑到推理时没有batch(CHW),若使用默认值(1,-1)会导致C没有被flatten,故使用(-3,-1)self.linear_relu_stack = nn.Sequential( # 定义前向传播序列nn.Linear(3 * 28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),)def forward(self, x): # 定义前向传播方法x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsif __name__ == "__main__":model = torch.load("./myModel.pth").to("cuda") # 载入模型model.eval() # 设置推理模式myTransform = transforms.Compose([myTransformMethod1(), transforms.ToTensor()])# 定义图像预处理组合,ToTensor()中Pytorch将HWC(openCV默认读取为height,width,channel)改为CHW,并将值[0,255]除以255进行归一化[0,1]for i in range(10):img = cv.imread("./numberImages/"+str(i)+".bmp") # 用openCV的imread函数读取图像img = myTransform(img).to("cuda") # 图像预处理print(torch.argmax(model(img)))
三、其余资料详见Github
相关文章:

[Pytorch]手写数字识别——真·手写!
Github网址:https://github.com/diaoquesang/pytorchTutorials/tree/main 本教程创建于2023/7/31,几乎所有代码都有对应的注释,帮助初学者理解dataset、dataloader、transform的封装,初步体验调参的过程,初步掌握openc…...
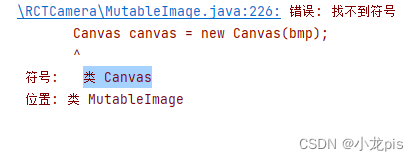
android studio 找不到符号类 Canvas 或者 错误: 程序包java.awt不存在
android studio开发提示 解决办法是: import android.graphics.Canvas; import android.graphics.Color; 而不是 //import java.awt.Canvas; //import java.awt.Color;...
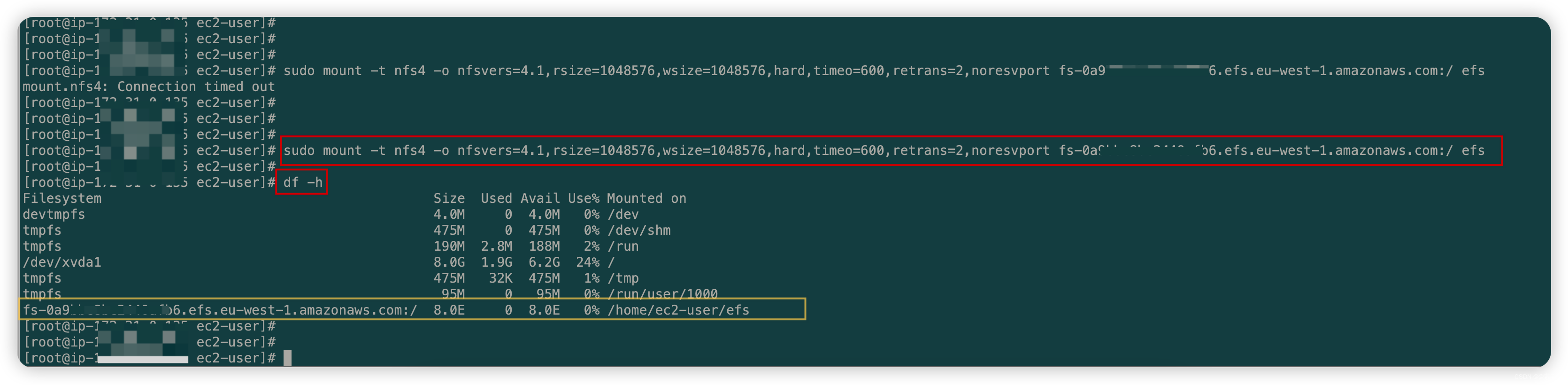
AWS——02篇(AWS之服务存储EFS在Amazon EC2上的挂载——针对EC2进行托管文件存储)
AWS——02篇(AWS之服务存储EFS在Amazon EC2上的挂载——针对EC2进行托管文件存储) 1. 前言2. 关于Amazon EFS2.1 Amazon EFS全称2.2 什么是Amazon EFS2.3 优点和功能2.4 参考官网 3. 创建文件系统3.1 创建 EC2 实例3.2 创建文件系统 4. 在Linux实例上挂载…...

FFmpeg 打包mediacodec 编码帧 MPEGTS
在Android平台上合成视频一般使用MediaCodec进行硬编码,使用MediaMuxer进行封装,但是因为MediaMuxer支持格式有限,一般会采用ffmpeg封装,比如监控一般使用mpeg2ts格式而非MP4,这是因为两者对帧时pts等信息封装差异导致应用场景不同…...

软件测试如何推进项目进度?
在软件研发中,有一种思想叫TDD,即测试驱动开发,TDD是敏捷方法中的一项核心实践,其原理是在开发功能代码之前,先编写单元测试用例代码,对要编写的函数或类明确测试方法后,再进行设计与编码。 本…...
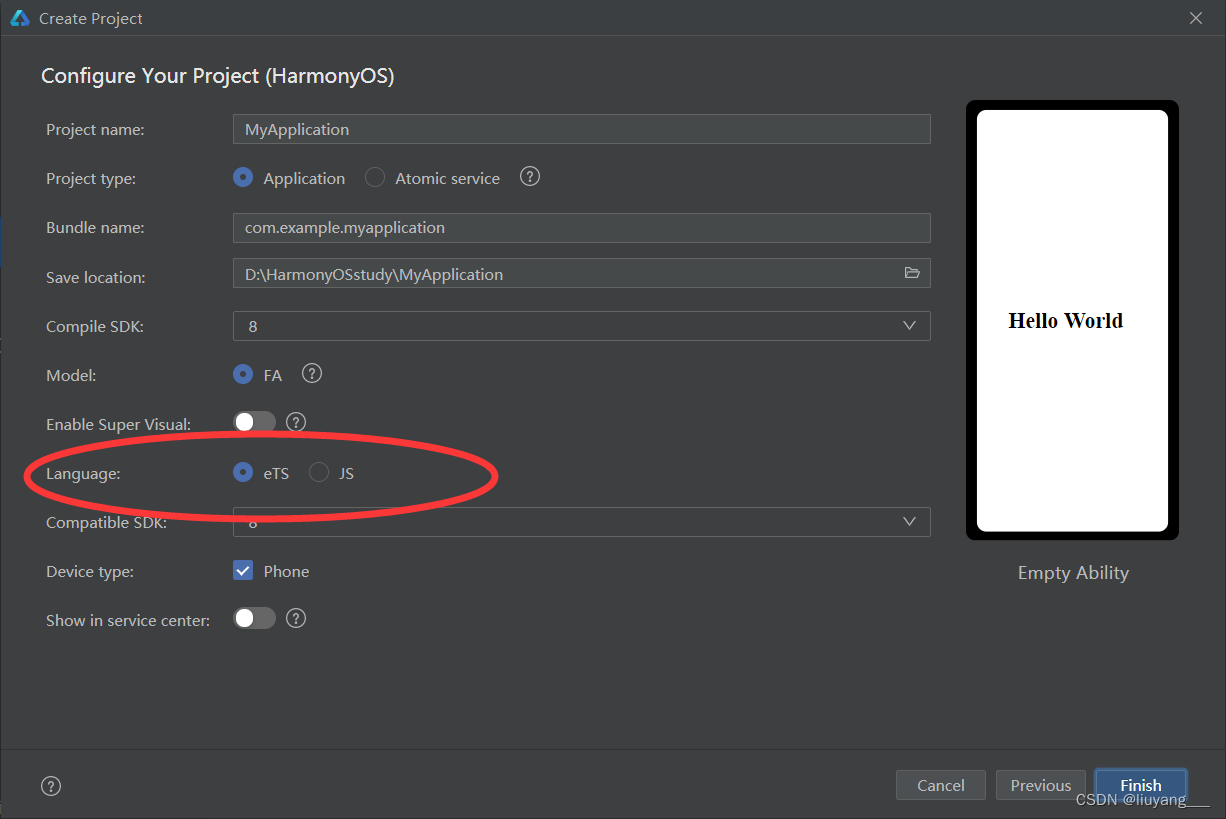
首次尝试鸿蒙开发!
今天是我第一次尝试鸿蒙开发,是因为身边的学长有搞这个的,而我也觉得我也该拓宽一下技术栈! 首先配置环境,唉~真的是非常心累,下载一个DevEco Studio 3.0.0.993,然后配置环境变量这些操作不用多说ÿ…...

前端面试题-react
1 React 中 keys 的作⽤是什么? Keys 是 React ⽤于追踪哪些列表中元素被修改、被添加或者被移除的辅助标识在开发过程中,我们需要保证某个元素的 key 在其同级元素中具有唯⼀性。在 React Diff 算法中 React 会借助元素的 Key 值来判断该元素是新近创建…...
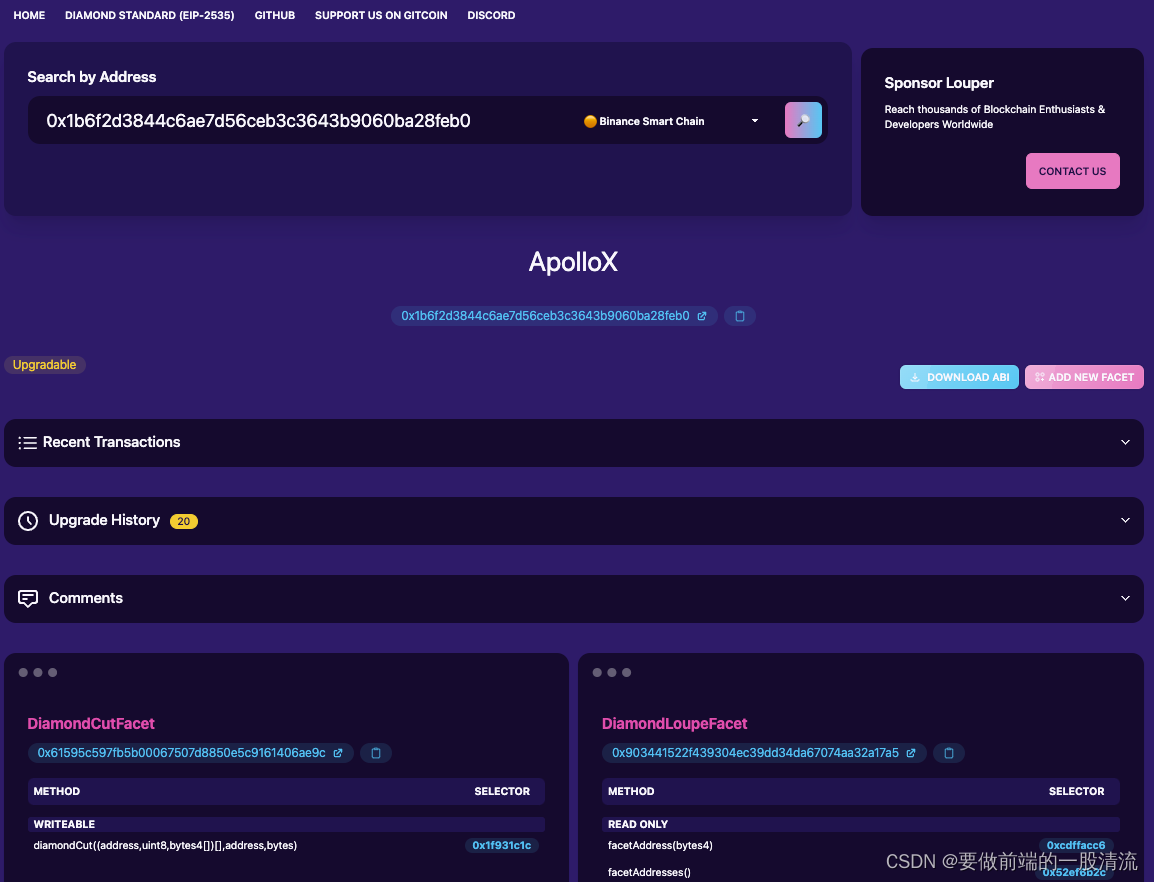
EIP-2535 Diamond standard 实用工具分享
前段时间工作对接到了这标准的协议,于是简单介绍下这个标准分享下方便前端er使用的调用工具 一、标准的诞生 在写复杂逻辑的solidity智能合约时,经常会碰到两个问题,升级和合约大小限制。 升级目前有几种proxy模式,通过delegateca…...
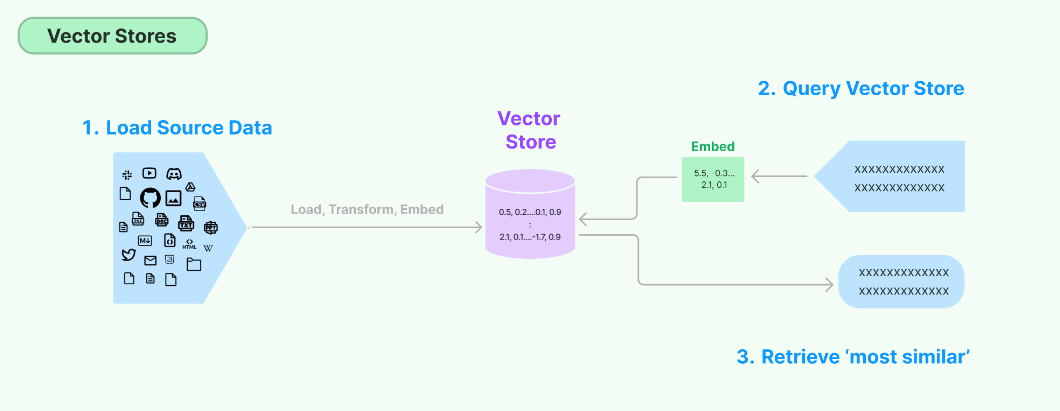
【LangChain】向量存储(Vector stores)
LangChain学习文档 【LangChain】向量存储(Vector stores)【LangChain】向量存储之FAISS 概要 存储和搜索非结构化数据的最常见方法之一是嵌入它并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。向量存储负责存储嵌入数…...
Debian/Ubuntu 安装 Chrome 和 Chrome Driver 并使用 selenium 自动化测试
截至目前,Chrome 仍是最好用的浏览器,没有之一。Chrome 不仅是日常使用的利器,通过 Chrome Driver 驱动和 selenium 等工具包,在执行自动任务中也是一绝。相信大家对 selenium 在 Windows 的配置使用已经有所了解了,下…...

[SQL挖掘机] - 窗口函数 - 合计: with rollup
介绍: 在sql中,with rollup 是一种用于在查询结果中生成小计和总计的选项。它可以与 group by 子句一起使用,用于在分组查询的结果中添加附加行。 with rollup 的作用是为每个指定的分组列生成小计,并在最后添加一行总计。这样,…...

远程控制平台一之推拉流的实现
确定框架 在选用推拉流框架的时候,有了解过nginx+rtmp/rtsp,Janus,以及其他开源的推拉流框架,要么是延迟严重(延迟一分多钟),要么配置复杂,而且这些框架对于只是转发远程画面这个简单需求来说,过于庞大了。机缘巧合之下,我了解到了一个简单易用的框架,就是ZeroMQ的…...
RTT(RT-Thread)线程管理(1.2W字详细讲解)
目录 RTT线程管理 线程管理特点 线程工作机制 线程控制块 线程属性 线程状态之间切换 线程相关操作 创建和删除线程 创建线程 删除线程 动态创建线程实例 启动线程 初始化和脱离线程 初始化线程 脱离线程 静态创建线程实例 线程辅助函数 获得当前线程 让出处…...
你真的会自动化吗?Web自动化测试-PO模式实战,一文通透...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 PO模式 Page Obj…...

C# 使用堆栈实现队列
232 使用堆栈实现队列 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(、、、):pushpoppeekempty 实现 类:MyQueue void push(int x)将元素 x 推到队列的末尾 int pop()从队列的开头移除并返回元素 in…...
git操作:修改本地的地址
Windows下git如何修改本地默认下载仓库地址 - 简书 (jianshu.com) 详细解释: 打开终端拉取git时,会默认在git安装的地方,也就是终端前面的地址。 需要将代码 拉取到D盘的话,现在D盘创建好需要安放代码的文件夹,然后…...
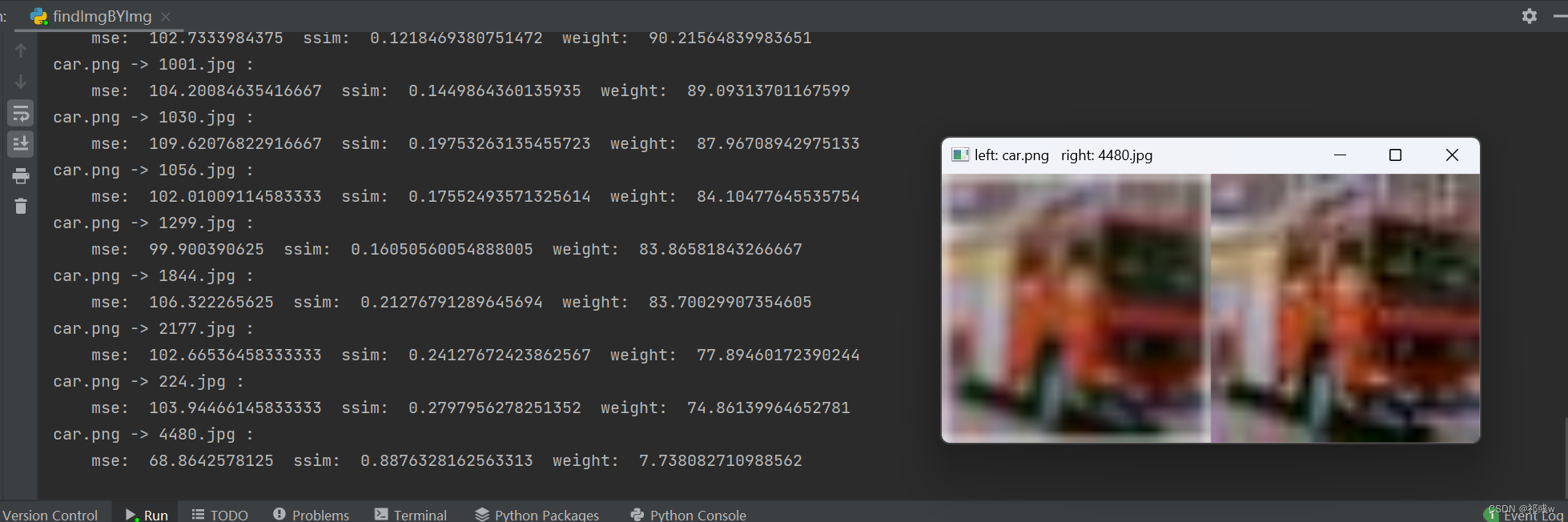
【以图搜图】Python实现根据图片批量匹配(查找)相似图片
目的:可以解决在本地实现根据图片查找相似图片的功能 背景:由于需要查找别人代码保存的图像的命名,但由于数据集是cifa10图像又小又多,所以直接找很费眼睛,所以实现用该代码根据图像查找图像,从而得到保存…...

【无标题】JSP--Java的服务器页面
jsp是什么? jsp的全称是Java server pages,翻译过来就是java的服务器页面。 jsp有什么作用? jsp的主要作用是代替Servlet程序回传html页面的数据,因为Servlet程序回传html页面数据是一件非常繁琐的事情,开发成本和维护成本都非常高…...
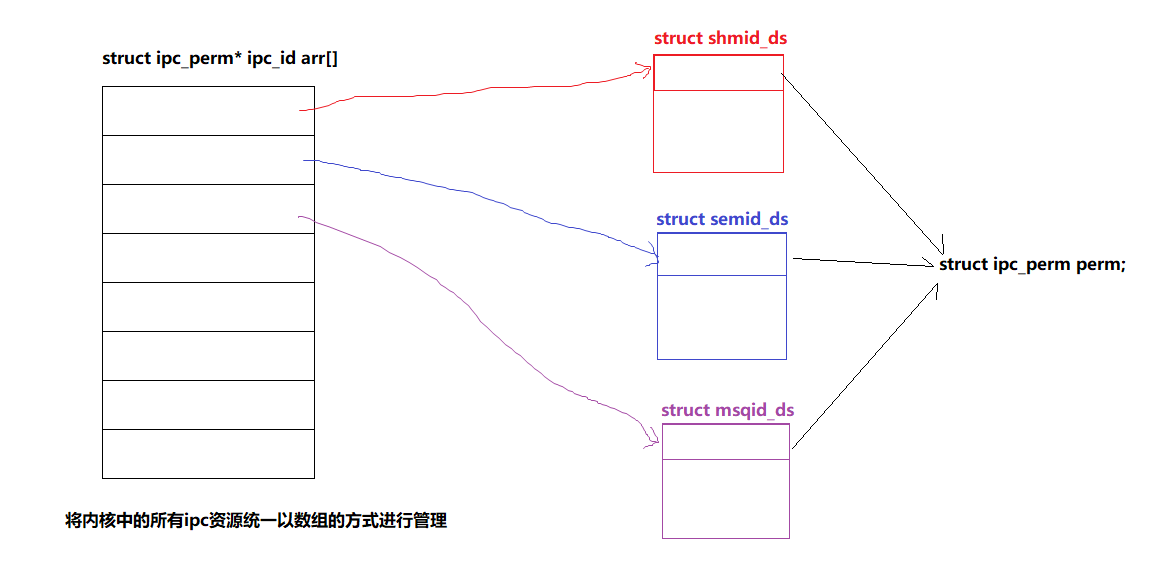
【Linux】进程间通信——system V共享内存 | 消息队列 | 信号量
文章目录 一、system V共享内存1. 共享内存的原理2. 共享内存相关函数3. 共享内存实现通信4. 共享内存的特点 二、system V消息队列(了解)三、system V信号量(信号量) 一、system V共享内存 1. 共享内存的原理 共享内存是一种在…...

CentOS实现html转pdf
CentOS使用实现html转PDF,需安装以下软件: yum install wkhtmltopdf # 转换工具,将HTML文件或网页转换为PDFyum install xorg-x11-server-Xvfb # 虚拟的X服务器,在无图形界面环境下运行图形应用程yum install wqy-zenhei-fonts #…...
)
别再死记硬背了!用一张时序图+五个核心状态,彻底搞懂5G NR入网(附RRC状态机详解)
5G NR入网流程:用状态机思维拆解终端与网络的第一次握手 当一部5G手机从关机状态按下电源键,到屏幕上显示"5G"信号图标,这短短几秒内发生了上百次信号交互。传统学习方式往往要求我们死记硬背每个步骤,但若能抓住五个核…...

在 Taotoken 上观测多模型 API 调用用量与成本明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 上观测多模型 API 调用用量与成本明细 对于使用多个大模型 API 的开发者而言,清晰、透明地掌握调用情况和…...

数字电路小白也能懂:用Logisim搞定LED计数电路,从真值表到封装测试保姆级教程
数字电路零基础实战:用Logisim构建LED计数器的完整指南 从困惑到清晰:为什么选择Logisim作为数字电路入门工具 第一次接触数字电路时,面对密密麻麻的逻辑门和抽象的真值表,大多数初学者都会感到无从下手。传统教材中复杂的公式推导…...

Rust Trait实现:引用类型自动继承与泛型解决方案
1. 项目概述:Rust Trait实现的“引用陷阱”与泛型解决方案在Rust开发中,我们经常需要为自定义类型实现各种Trait来定义其行为。一个看似理所当然的直觉是:如果类型T实现了TraitSpeaker,那么它的引用&T也应该自动实现Speaker。…...

如何快速上手网易游戏NPK文件解包工具:新手3步完整教程
如何快速上手网易游戏NPK文件解包工具:新手3步完整教程 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否对网易游戏如《阴阳师》、《魔法禁书目录》中的…...

不止Keil5:VSCode+GCC也能玩转GD32单片机?手把手教你搭建轻量级开发环境
超越Keil5:用VSCodeGCC打造高效GD32开发环境 在嵌入式开发领域,Keil MDK长期以来一直是ARM架构单片机开发的主流选择。然而,随着现代开发工具的演进,越来越多的开发者开始寻求更轻量、更灵活且完全免费的替代方案。本文将带你探索…...

Maple Mono字体终极配置指南:3步解决连字显示难题,开启高效编程体验
Maple Mono字体终极配置指南:3步解决连字显示难题,开启高效编程体验 【免费下载链接】maple-font Maple Mono: Open source monospace font with round corner, ligatures and Nerd-Font icons for IDE and terminal, fine-grained customization option…...

WinRAR隐藏技能:除了.rar和.zip,批处理还能压成啥?附参数避坑指南
WinRAR命令行进阶指南:解锁隐藏压缩格式与参数避坑实战 在大多数用户的认知里,WinRAR只是个能处理.rar和.zip文件的图形化工具。但它的命令行版本却隐藏着一个完全不同的世界——支持超过20种压缩格式转换、批量自动化处理、甚至能实现文件系统级操作。本…...

【DeepSeek MATH竞赛测试权威复盘】:20年AI评测专家独家拆解7大能力断层与提分临界点
更多请点击: https://intelliparadigm.com 第一章:DeepSeek MATH竞赛测试的评测定位与行业意义 DeepSeek MATH 是由深度求索(DeepSeek)团队构建的高难度数学推理基准,专为评估大语言模型在代数、微积分、组合数学、数…...

CPU Cache初始化:从硬件复位到软件使能的底层原理与工程实践
1. 项目概述:从开机到高速缓存就绪当按下电脑的电源键,屏幕上开始跑起一行行代码时,我们看到的通常是BIOS自检、操作系统加载的宏大叙事。但在这背后,有一个对性能影响巨大却又极其低调的“幕后英雄”正在悄然启动,它就…...