【论文阅读】通过解缠绕表示学习提升领域泛化能力用于主题感知的作文评分
摘要
- 本文工作聚焦于从领域泛化的视角提升AES模型的泛化能力,在该情况下,目标主题的数据在训练时不能被获得。
- 本文提出了一个主题感知的神经AES模型(PANN)来抽取用于作文评分的综合的表示,包括主题无关(prompt-invariant)和主题相关(prompt-specific)的特征。
- 为了提升表示的泛化能力,我们进一步提出了一个新的解缠绕表示学习框架(disentangled representation learning)。在这个框架中,设计了一个对比的模长-角度对齐策略(norm-angular alignment)和一个反事实自训练策略(counterfactual self-training)用于解开表示中主题无关和主题相关的特征信息。
引言
- 本文提出一个主题感知的神经AES模型,它能够基于一篇作文的编码器(比如说预训练的BERT)来抽取作文的质量特征,并且基于一个文本匹配模块来抽取主题遵循度特征。
- 存在两个问题:
- 从编码器中抽取到的作文质量特征,比如BERT,可能编码了质量和内容信息,并且它们在特征中是相互缠绕的。怎样从特征中解开独立的质量信息是第一个问题;
- 主题关联特征和作文质量特征都是基于作文抽取得到的。因此,从因果的角度看,作文是两种特征的混淆因素,导致主题关联度和作文质量间的有误导性的关联。比如,一篇作文可能有不同的主题关联性但是一样的质量,在不同的主题下。所以,怎样解开这种误导性的关联,使得这两种特征独立得贡献于最终的分数是第二个问题。
方法
- 解缠绕表示学习框架(DRL)是基于预训练和微调的范式进行设计的。
- 在预训练阶段,设计了一个对比的norm-angular对齐策略来预训练文章质量特征,目的是解绑特征中的质量和内容信息。
- 在微调阶段,应用了一个反事实自训练策略来微调整个PANN模型,目的是解绑文章质量特征和主题相关特征之间的误导性的关联。
- 最后,使用完全训练好的PANN来评分目标主题的作文。
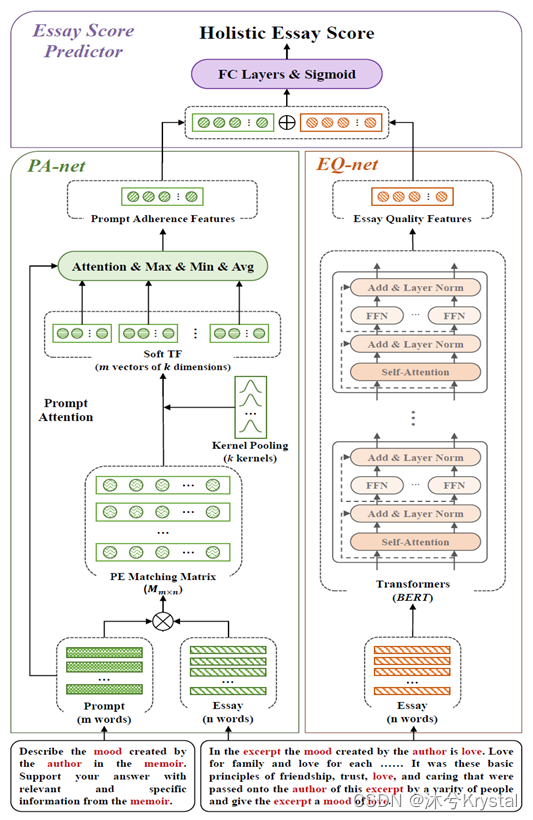
PANN的模型架构
-
三个主要组成:
- 作文质量网络(EQ-net):只把作文作为输入,抽取主题无关的作文质量特征。
- 主题关联网络(PA-net):把作文和主题都作为输入,抽取主题特定的主题遵循度特征。因为这样的基于交互的文本匹配模型能够只关注作文和主题的词级的相似度,它能够避免编码到和作文质量相关的信息,比如句法和内聚力,从而使得特征只特定于主题遵循度。
- 作文评分预测器(ESP):结合两种特征来预测整体分数。
解缠绕表示学习DRL
- EQ-net可能会编码主题无关的质量信息和主题相关的内容信息,并且内容信息会在不同主题间切换,它会阻止EQ-net的泛化能力。
- 并且,PA-net和EQ-net都把作文作为输入,这使得作文变成主题关联度特征和作文质量特征的混淆因素,导致他们之间具有误导性的关联。
质量-内容解缠(Quality-Content Disentanglement)
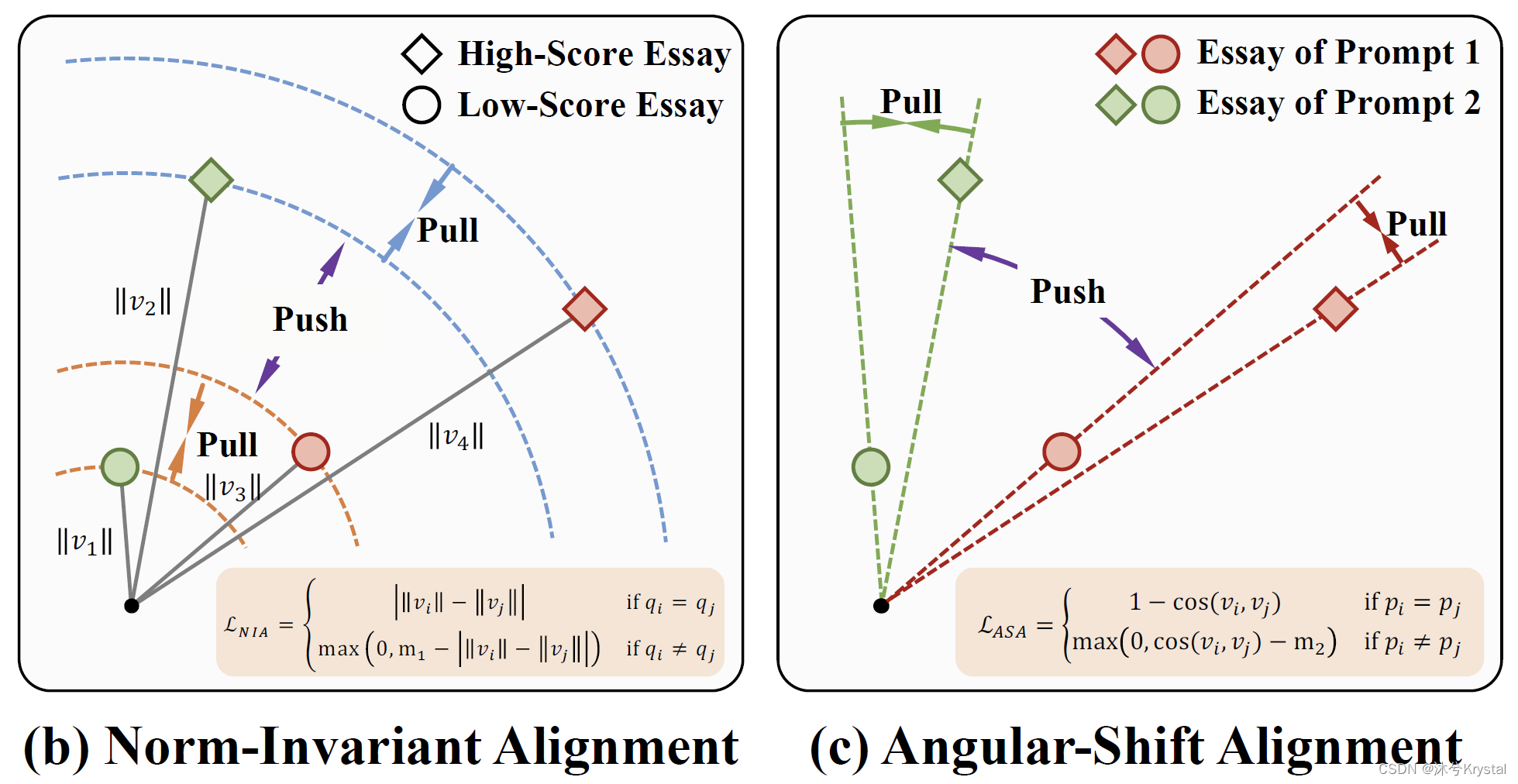
- 我们提出了一个对比的模长-角度对齐策略(Contrastive Norm-Angular Alignment,CNAA)来在作文质量特征中的质量和内容信息。
- 这个策略的设计是基于模长不变性(norm invariant)和角度切换(angular shift)的假设,它假设质量和内容信息能够通过分别对齐就模长和角度而言的特征来被解绑。
- 对于模长不变性,我们假设相似质量的作文能够本分布具有相似的模长,并且这些模长可能是各个主题都不变的。
- 对于角度切换,我们假设具有相似内容的作文(i.e.,主题)能够被分布具有相似的角度,但是这些角度应该在不同的主题上切换。
数据增强
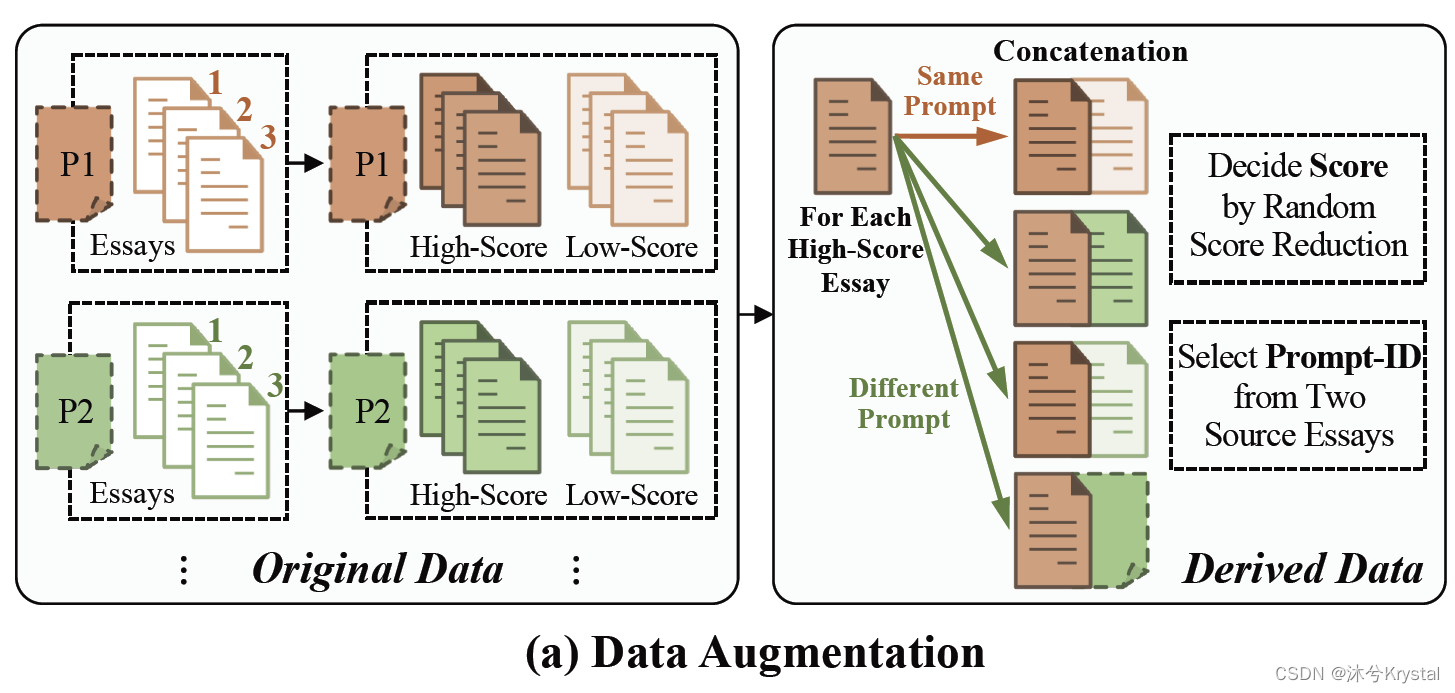
- 为了准备数据用于对比的模长-角度对齐,我们首先从训练集中抽取所有的高分和低分作文来组成原始数据 D o D_o Do。
- 通过两两拼接这些作文来构建衍生的数据 D d D_d Dd。
- 随机降低分数给拼接后的作文的原因是:
- 拼接两篇文章可能会降低那篇更高分数的作文的质量(比如,内聚力和组织)。
- 拼接来自不同主题的两篇文章可能会降低作文的主题遵循度(对两个主题都是)。
模长不变性&角度切换 对齐
- 基于成对的对比学习,包括模长不变的质量对齐和角度切换的内容对齐。
质量-遵循度解缠(Quality-Content Disentanglement)
- 本文尝试提出和回答以下问题:“如果一篇文章的质量保持不变,但它的题目符合度不同,那么最终得分会是多少?”
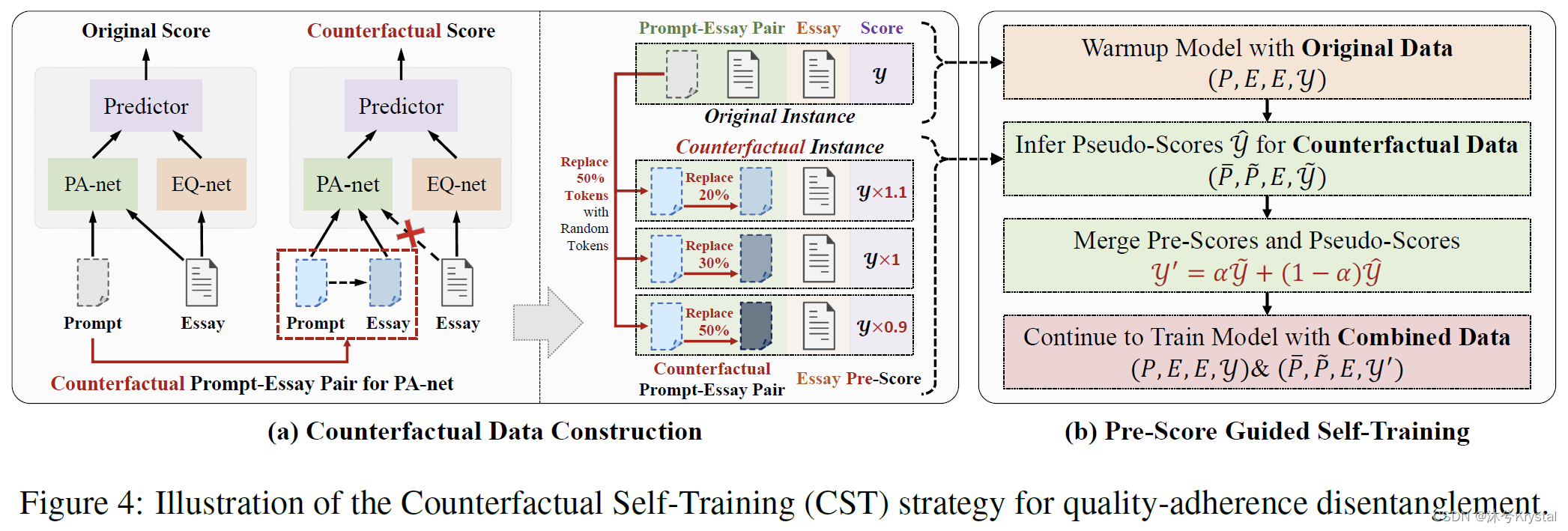
预评分指导的自训练
- 本文把每个反事实实例的预打好的预分数和模型预测的伪分数结合作为它的最终分数。以这种方式,在预分数中提供的先验知识和编码在伪分数中的模型知识能够被很好得融合。
实验
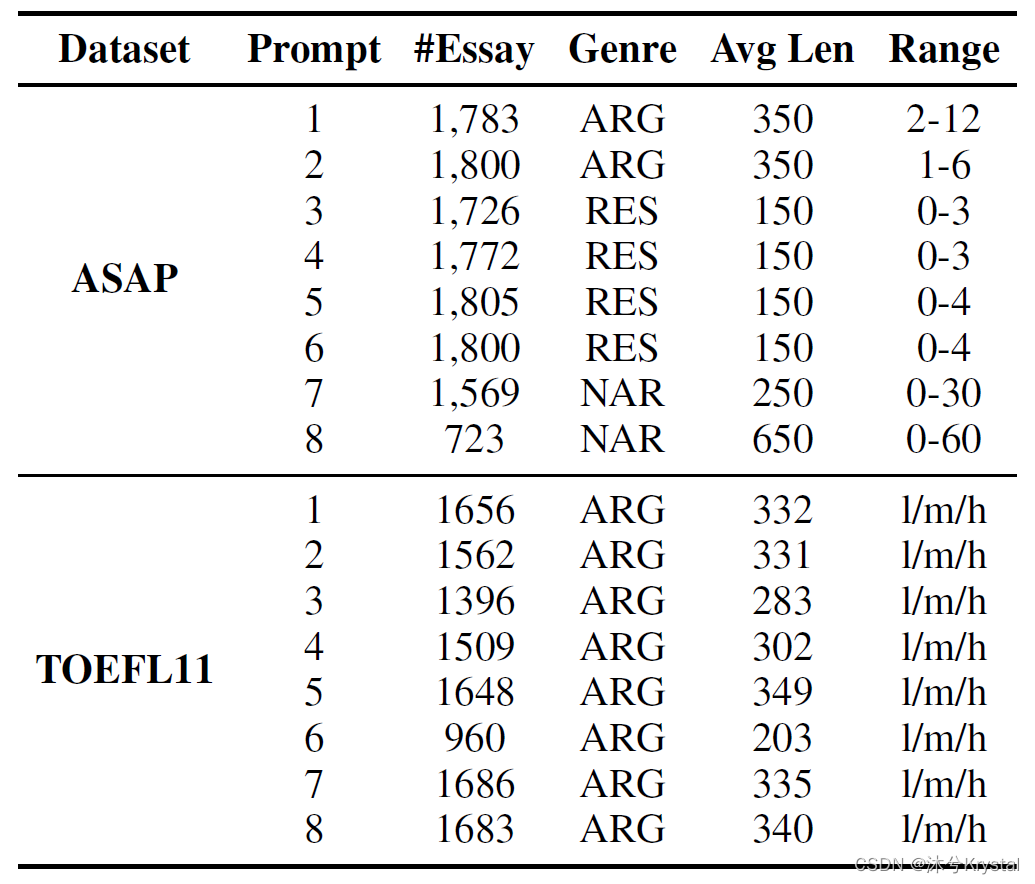
- ASAP数据集和TOEFL11数据集
实验结果
-
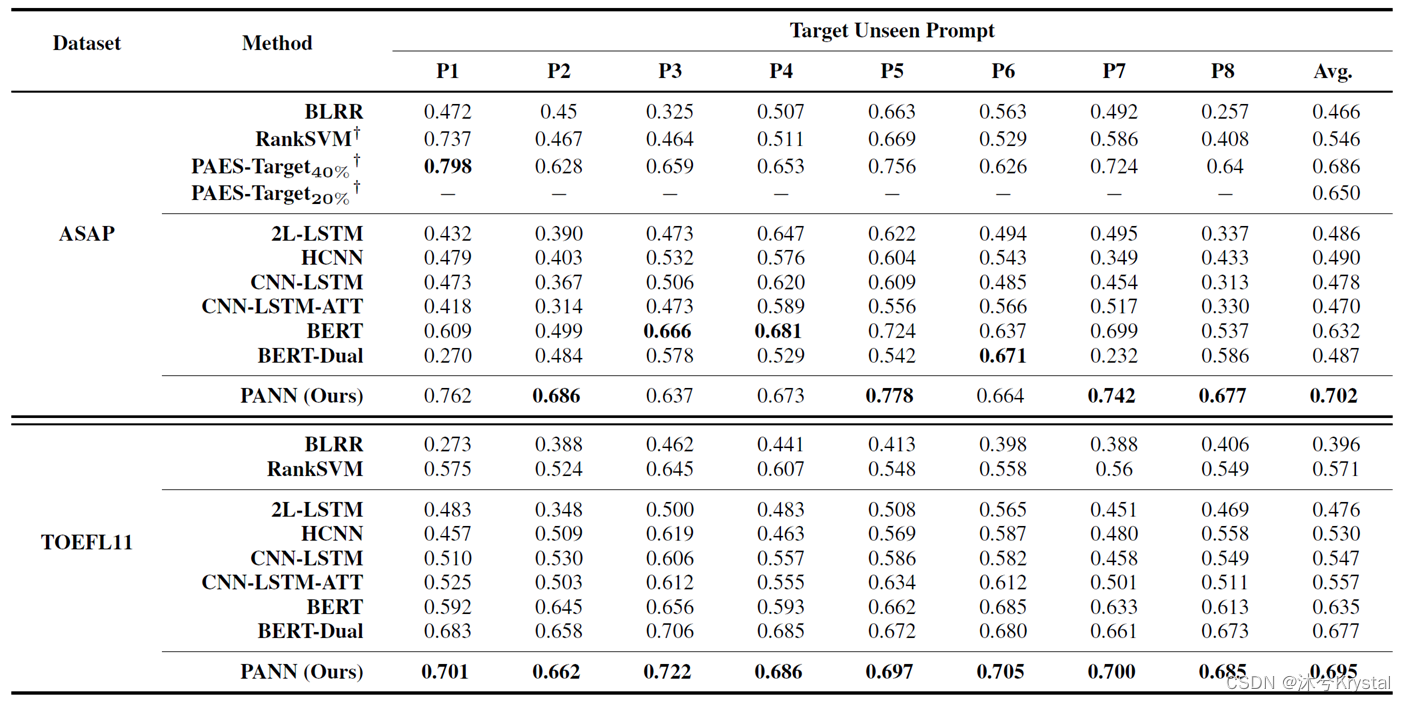
我们和主题泛化设置的方法进行比较,包括三类方法:基于手工特征的,基于神经网络的和混合的。
-
可以看到,我们的PANN模型能够超过大多数的基准方法,在两个数据集上都达到最好的整体性能。这表明我们的方法对于主题泛化的作文评分是有用的。
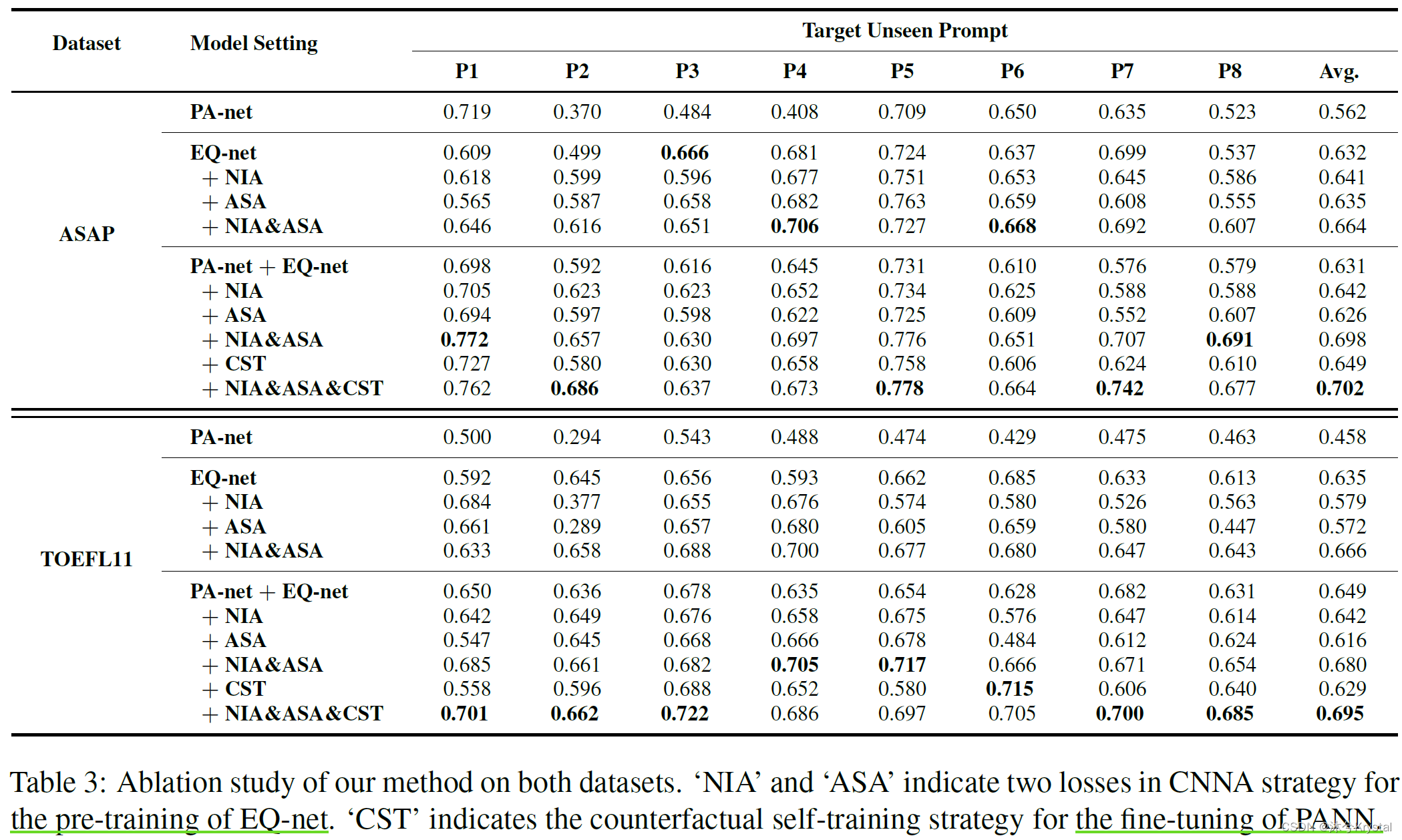
- 结合PA-net和EQ-net两个部分比单独的PA-net或者EQ-net的性能好。这表明PA-net和EQ-net都能够为作文评分提供有用的信息。
- 当EQ-net被用NIA和ASA预训练,EQ-net的性能被提升。但是当EQ-net被只有他们中的一个预训练的时候,在TOEFL11数据集上性能下降了。相似的现象也可以在PA-net+EQ-net上观察到。这可能是由于两个损失需要被同时使用来解开质量和内容信息的缠绕。
- 并且,CTS也需要和CNAA策略一起使用来获得更好的性能。
进一步分析
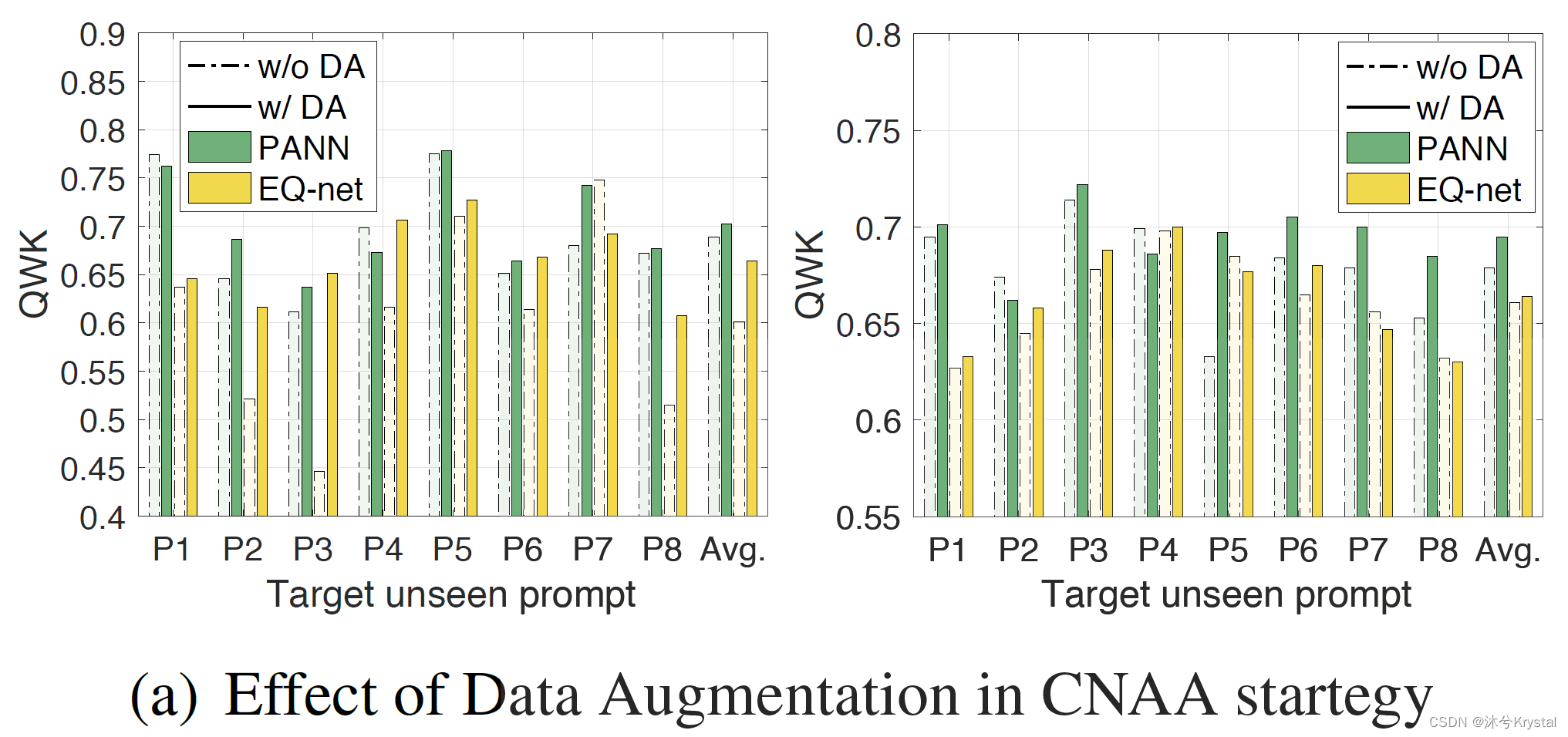
- 数据增强的影响:可以发现PANN和EQ-net能够从数据增强中受益,特别是在ASAP的P3上,和TOEFL11数据集的P5上。
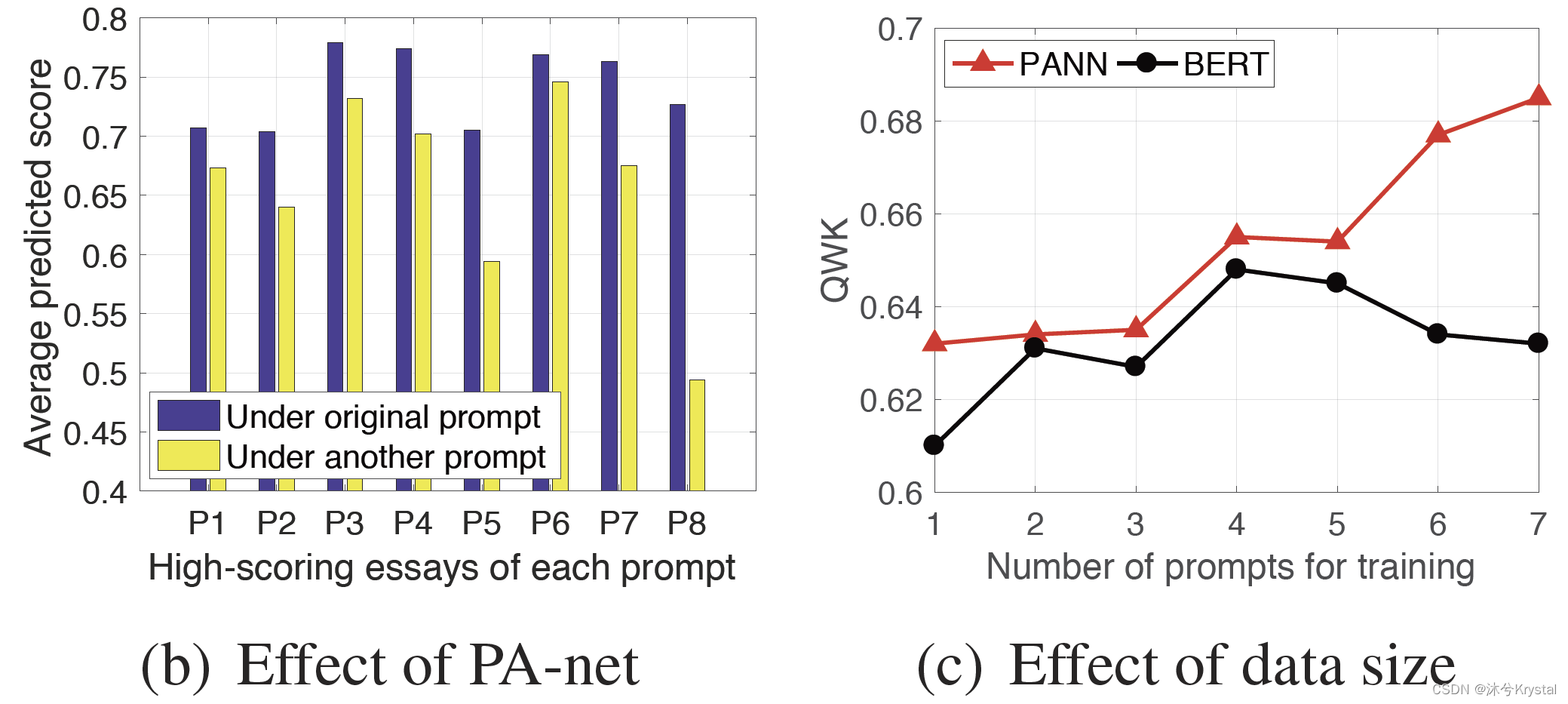
- PA-net的影响:是否PA-net能够独立的影响最终的分数预测。可以看到,PANN为在不匹配的主题下的高分作文预测了平均更低的分数;由于EQ-net在两种设置下输出的特征是不变的,所以PA-net能够感知主题上的变化,能够独立影响分数预测。
- 数据大小的影响:在数据大小增大时,我们的PANN的预测性能相应提升,但是BERT的性能先上升后下降。这表明我们的表示解缠绕策略能够处理主题个数增长时带来的缠绕的信息的问题,所以模型能够从数据增长中获益。
特征可视化
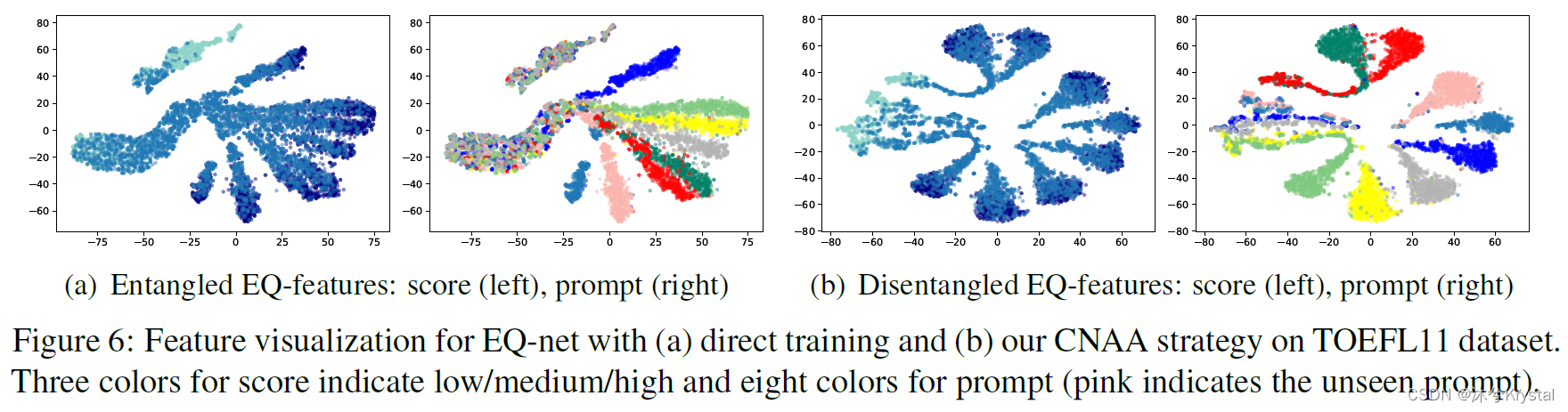
- 展示了EQ-net有和没有CNAA策略时的特征分布。
- (a)图三个等级的分数相对很好的分开了(left),但是不同主题的作文没有完全分开,特别时低分和中等分数的作文。
- (b)图中使用了本文的CNAA策略,分数能够很好的分开根据不同的模长,主题能够很好的分开根据不同的角的方向。
相关文章:
【论文阅读】通过解缠绕表示学习提升领域泛化能力用于主题感知的作文评分
摘要 本文工作聚焦于从领域泛化的视角提升AES模型的泛化能力,在该情况下,目标主题的数据在训练时不能被获得。本文提出了一个主题感知的神经AES模型(PANN)来抽取用于作文评分的综合的表示,包括主题无关(pr…...

二分查找P1873 [COCI2011-2012#5] EKO / 砍树
P1873 [COCI2011-2012#5] EKO / 砍树 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 这个题就是给新手练手的,在那个位置上在进行,寻找合适的砍树高度,下面在介绍一个二分查找的模板 int binarySearch(vector<int>& nums, int t…...

【BOOST程序库】正则表达式相关操作
基本概念这里不解释了,代码中详细解释了BOOST程序库中对于正则表达式常用方法的详细用法。 #include <iostream> #include <string>//正则表达式头文件 #include <boost/xpressive/xpressive.hpp>int main() {//声明正则:boost::pres…...

阿里云国际版在使用过程中应该注意什么呢?
为确保系统稳定性,用户不得进行以下操作。否则,阿里云可能无法解决由以下违规操作引起的问题: 1) Windows系统中的PV Drivers 程序不可删除 PV Drivers程序为服务器虚拟化驱动程序,请不要针对该程序进行任何操作,如果删…...

Flutter Provider 共享状态管理
在使用Provider的时候,我们主要关心三个概念: ChangeNotifier:真正数据(状态)存放的地方ChangeNotifierProvider:Widget树中提供数据(状态)的地方,会在其中创建对应的Ch…...

std vector 用法
使用vector,需添加头文件#include,要使用sort或find,则需要添加头文件#include。函数封装在命名空间std中,使用:using namespace std; 1、vector的初始化 std::vector<int> nVec; // 空对象 std::vecto…...

vue vite ts electron ipc addon-napi c arm64
初始化 因网络问题建议使用 cnpm 代替 npm npm init vue # 全选 yes npm i # 进入项目目录后使用 npm i electron electron-builder -D npm i commander -D # 额外组件electron 新建 plugins、src/electron 文件夹 添加 src/electron/background.ts 属于主进程 ipcMain.o…...

机器人科普--AGILOX 叉车
机器人科普--AGILOX 叉车 1 概述2 导航3 驱动轮组4 叉举参考 1 概述 AGILOX 叉车,不需要画地图路径,很厉害。 2 导航 中间路径自由导航,末端规划出轨迹路线,并使用优良的控制器做轨迹追踪。 AGILOX | 10 Min setu…...
Django的生命周期流程图(补充)、路由层urls.py文件、无名分组和有名分组、反向解析(无名反向解析、有名反向解析)、路由分发、伪静态
一、orm的增删改查方法(补充) 1. 查询resmodels.表名(类名).objects.all()[0]resmodels.表名(类名).objects.filter(usernameusername, passwordpassword).all()res models.表名(类名).objects.first() # 判断,判断数据是否有# res如果查询…...

selenium交互代码
一:selenium交互 用selenium打开网页后,也可以做一系列真人的操作,也就是利用selenium和浏览器进行交互,可利用以下几个函数进行操作: input.send_keys() 传递输入内容给某输入框button.click() 点击某按钮browser.e…...

下载远程服务器文件
业务需求:下载某云盘的视频文件存储到本地 测试代码 RequestMapping("testVideo")public String test() {try {SimpleDateFormat DATE_FORMAT new SimpleDateFormat("yyyy/MM/dd/");//组装本地保存地址StringBuilder filePath new StringBuilder(StoreP…...

[SQL挖掘机] - 索引
介绍: 当你在数据库中进行查询时,索引是一种用于提高查询性能的重要工具。索引是对表中的一列或多列进行排序的数据结构,它可以快速定位到满足特定条件的记录,从而减少了查询所需的时间和资源。 在数据库中使用索引的主要好处包括ÿ…...
C++STL库中的list
文章目录 list的介绍及使用 list的常用接口 list的模拟实现 list与vector的对比 一、list的介绍及使用 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向带头循环链表结构,双向带头循…...
【LeetCode 75】第十七题(1493)删掉一个元素以后全为1的最长子数组
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 给一个数组,求删除一个元素以后能得到的连续的最长的全是1的子数组。 我们可以先单独统计出连续为1的子数组分别长度…...
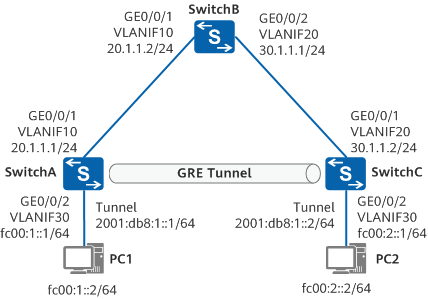
配置IPv6 over IPv4 GRE隧道示例
组网需求 如图1,两个IPv6网络分别通过SwitchA和SwitchC与IPv4公网中的SwitchB连接,客户希望两个IPv6网络中的PC1和PC2实现互通。 其中PC1和PC2上分别指定SwitchA和SwitchC为自己的缺省网关。 图1 配置IPv6 over IPv4 GRE隧道组网图 配置思路 要实现I…...
Google Earth Engine谷歌地球引擎提取多波段长期反射率数据后绘制折线图并导出为Excel
本文介绍在谷歌地球引擎GEE中,提取多年遥感影像多个不同波段的反射率数据,在GEE内绘制各波段的长时间序列走势曲线图,并将各波段的反射率数据与其对应的成像日期一起导出为.csv文件的方法。 本文是谷歌地球引擎(Google Earth Engi…...
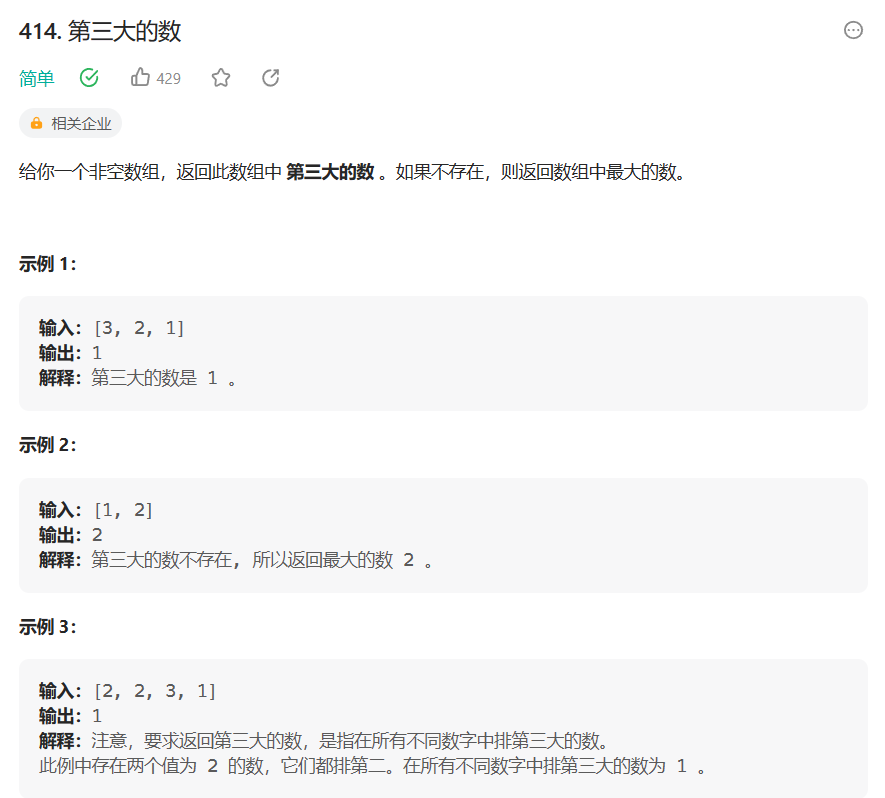
第三大的数
414、第三大的数 class Solution {public int thirdMax(int[] nums) {Arrays.sort(nums);int tempnums[0];int ansnums[0];int count 0;// if(nums.length<3){// return nums[nums.length-1];// }// else {for(int inums.length-1;i>0;i--){if (nums[i]>nums[i…...

正则表达式中的方括号[]有什么用?
在正则表达式中,方括号 [] 是用于定义字符集合的元字符。它在正则表达式中有以下作用: 匹配字符集合中的任意一个字符:方括号中列出的字符,表示在这个位置可以匹配这些字符中的任意一个。例如,[abc] 将匹配任意一个字符…...

SQL编写规范
文章目录 1.命名规范:2.库表设计:3.查询数据:4.修改数据:5.索引创建: 1.命名规范: 1.库名、表名、字段名,必须使用小写字母或数字,不得超过30个字符。 2.库名、表名、字段名&#…...
Azure pipeline自动化打包发布
pipeline自动化,提交代码后,就自动打包,打包成功后自动发布 第一步 pipeline提交代码后,自动打包。 1 在Repos,分支里选择要触发的分支,这里选择cn_china,对该分支设置分支策略 2 在生产验证中增加新的策略 3 在分支安…...
功能仿真)
在 Simulink 中实现并网双向 DC/AC 逆变器的无功补偿(SVG)功能仿真
目录 🛠️ 第一步:系统架构设计与模块搭建 ⚙️ 第二步:SVG 核心控制策略设计(双闭环控制) 📊 第三步:仿真运行与结果分析 手把手教你在 Simulink 中实现并网双向 DC/AC 逆变器的无功补偿(SVG)功能仿真。 在现代电力系统中,并网逆变器(如光伏、储能逆变器)不…...

如何快速实现文献元数据智能转换:Zotero插件终极指南
如何快速实现文献元数据智能转换:Zotero插件终极指南 【免费下载链接】zotero-format-metadata Linter for Zotero. A plugin for Zotero to format item metadata. Shortcut to set title rich text; set journal abbreviations, university places, and item lang…...

终极节点图绘制工具:Project Graph让你的思维可视化变得简单高效
终极节点图绘制工具:Project Graph让你的思维可视化变得简单高效 【免费下载链接】project-graph A node-based visual tool for organizing thoughts and notes in a non-linear way. 项目地址: https://gitcode.com/gh_mirrors/pr/project-graph 还在为复杂…...

如何在Windows平台上快速构建专业级词法语法分析器:WinFlexBison终极指南
如何在Windows平台上快速构建专业级词法语法分析器:WinFlexBison终极指南 【免费下载链接】winflexbison Main winflexbision repository 项目地址: https://gitcode.com/gh_mirrors/wi/winflexbison WinFlexBison是Windows平台上最专业的词法分析和语法解析…...

Ansys Mechanical|远程点Behavior设置:刚性与柔性选择背后的工程考量
1. 远程点Behavior设置的核心逻辑 在Ansys Mechanical中,远程点(Remote Point)的Behavior设置看似只是一个简单的下拉选项,实则直接影响整个仿真结果的准确性。我见过太多工程师在这里踩坑,包括我自己早期也犯过错误。…...

QMCDecode:轻松解锁QQ音乐加密音频的Mac专属神器
QMCDecode:轻松解锁QQ音乐加密音频的Mac专属神器 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结…...

从零到一:手把手完成Keil5 MDK环境搭建与ST-LINK驱动配置
1. 开发环境搭建前的准备工作 第一次接触STM32开发的朋友们,看到各种专业术语可能会有点懵。别担心,我刚开始也是这样。咱们先理清几个基本概念:Keil MDK是ARM公司推出的专业嵌入式开发工具,ST-LINK则是ST官方推出的调试下载器。…...

构建一个基于YOLOv8的打架检测系统,包括环境设置、数据准备、模型训练、评估和推理部署。Yolov8训练打架斗殴数据集
构建一个基于YOLOv8的打架检测系统,包括环境设置、数据准备、模型训练、评估和推理部署。Yolov8训练打架斗殴数据集 文章目录1. 环境设置2. 数据准备2.1 数据集结构2.2 类别映射3. 文件内容3.1 Config.py3.2 train.py3.3 detect_tools.py3.4 UIProgram/MainProgram.…...

Google发现的神级Prompt工程新技巧:重复Prompt提升效果
Google发现的神级Prompt工程新技巧:重复Prompt提升效果 关键词:Prompt工程、提示词优化、LLM技巧、GPT技巧、AI提问技巧、Prompt Repetition、提示词工程一、最近发现一个被低估的Prompt技巧 pdf地址 https://arxiv.org/pdf/2512.14982最近在看一篇 Goog…...

DLT Viewer:面向汽车电子系统的分布式日志诊断与实时监控技术方案
DLT Viewer:面向汽车电子系统的分布式日志诊断与实时监控技术方案 【免费下载链接】dlt-viewer Diagnostic Log and Trace viewing program 项目地址: https://gitcode.com/gh_mirrors/dl/dlt-viewer DLT Viewer是一款基于COVESA标准的专业诊断日志分析工具&…...