MySQL优化
目录
一. 优化 SQL 查询语句
1.1. 分析慢查询日志
1.2. 优化 SQL 查询语句的性能
1.2.1 优化查询中的索引
1.2.2 减少表的连接(join)
1.2.3 优化查询语句中的过滤条件
1.2.4 避免使用SELECT *
1.2.5 优化存储过程和函数
1.2.6 使用缓存
二. 优化表结构
2.1. 避免使用表过多
2.2. 选择正确的数据类型
2.2.1. 数据类型应该与数据特征相匹配。
2.2.2. 避免使用可变长度类型。
2.2.3. 对于经常被更新的字段,应该选择能够快速排序和搜索的数据类型。
2.2.4. 对于经常被检索的字段,应该选择能够节省空间的数据类型。
2.2.5. 对于计算字段,应该选择能够存储计算结果的数据类型。
2.2.6. 对于不需要进行计算的字段,应该选择能够最大程度地节省空间的数据类型。
2.2.7. 对于需要存储大量数据的字段,应该选择能够存储大量数据的数据类型。
2.3. 创建适当的索引
2.4. 避免创建大量“临时”表
2.5. 使用合适的存储引擎
2.6. 数据库架构
三. 增加硬件资源
四. 优化参数配置
4.1 降低磁盘的写入次数
4.1.1 增大 redo log,减少落盘次数
4.1.2 通用查询日志、慢查询日志可以不开 ,binlog 可开启。
4.1.3 写 redo log 策略 innodb_flush_log_at_trx_commit 设置为 0 或 2
4.2 系统调优参数
五. 优化并发访问
六. 使用缓存技术
前言:
MySQL 优化的重要性在于它可以提高数据库的性能,从而提升系统的整体性能。在处理大量数据或高并发请求时,MySQL 优化可以显著减少查询时间,提高系统的响应速度,从而提升用户体验。
1. 提高系统性能:MySQL 优化可以显著提高系统的性能,减少查询时间,提高系统的响应速度。
2. 减少资源消耗:MySQL 优化可以减少服务器资源消耗,如内存、CPU 和磁盘空间。
3. 提升系统稳定性:MySQL 优化可以减少系统崩溃和故障的概率,提高系统的稳定性。
4. 降低维护成本:MySQL 优化可以减少系统维护成本,降低服务器宕机的时间。
5. 提高业务效率:MySQL 优化可以提高业务效率,减少用户等待时间,提高用户体验。
总之,MySQL 优化对于一个大型的、高并发的网站来说是非常重要的,它能够显著提高系统的性能和稳定性,降低维护成本,提升业务效率。
一. 优化 SQL 查询语句
尽量减少查询数据量、减少 I/O 操作、使用索引、避免全表扫描等。可以通过阅读和理解 MySQL 的官方文档、查询性能分析工具、分析慢查询日志等方式来提高 SQL 查询的性能。
1.1. 分析慢查询日志
了解哪些查询需要优化以及问题的严重性。
1.2. 优化 SQL 查询语句的性能
1.2.1 优化查询中的索引:
合理地创建和维护索引是优化查询性能的关键。
①在创建索引时,应该包含查询中经常用来过滤数据的列。
②对经常作为查询条件的那些列设置索引。
③对联合主键进行索引。
④对经常出现在查询中的order by子句中的字段设置索引。
⑤对于group by和group by子句中的字段设置索引。
⑥在join语句中,尽量使用内联而不是子查询或临时表。
1.2.2 减少表的连接(join):
尽量减少表的连接,通过选择合适的连接类型(如INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等)来减少表的连接。
1.2.3 优化查询语句中的过滤条件:
合理地使用SELECT语句的WHERE子句,尽量避免全表扫描。
①使用索引
②减少 where 和 limit 的应用
③避免使用 `in` 和 `not in`
④避免使用` LIKE` 和 `前方引号`
1.2.4 避免使用SELECT *:
仅返回需要的列,避免使用SELECT *,因为这样会执行全表扫描,影响查询性能。
1.2.5 优化存储过程和函数:
尽量避免在存储过程和函数中使用复杂的查询,因为这样会影响存储过程和函数的性能。
1.2.6 使用缓存:
合理地使用缓存可以减少对数据库的访问次数,从而提高查询性能。
二. 优化表结构
合理规划表字段、使用适当的索引、设置表字段的数据类型和长度等,可以提高表查询和存储的性能。
2.1. 避免使用表过多:
过度建模或创建多余的表是常见的数据库设计问题。这会导致在查询和分析数据时引入额外的开销和复杂性。尽量合并不必要的表,以减少数据库的“肥胖症”。
2.2. 选择正确的数据类型:
为数据库中的每个列选择正确的数据类型非常重要,因为它会影响到数据的存储、检索和处理效率。例如,为数值列使用适当的数据类型(如Decimal或浮点数)比使用字符型列更高效。此外,避免为小数字量列分配过多的空间,因为这会导致插入和查询性能下降。
2.2.1. 数据类型应该与数据特征相匹配。
例如,如果字段存储日期,应该选择日期类型而不是字符串类型。
2.2.2. 避免使用可变长度类型。
例如,使用 VARCHAR 而不是 TEXT,因为 VARCHAR 可以更快地检索和更新数据。
2.2.3. 对于经常被更新的字段,应该选择能够快速排序和搜索的数据类型。
例如,对于一个用户 ID,应该选择整数类型而不是字符串类型。
2.2.4. 对于经常被检索的字段,应该选择能够节省空间的数据类型。
例如,对于一个地址,应该选择地理坐标类型而不是字符串类型。
2.2.5. 对于计算字段,应该选择能够存储计算结果的数据类型。
例如,对于一个总销售额,应该选择数字类型而不是文本类型。
2.2.6. 对于不需要进行计算的字段,应该选择能够最大程度地节省空间的数据类型。
例如,对于一个电话号码,应该选择整数类型而不是字符串类型。
2.2.7. 对于需要存储大量数据的字段,应该选择能够存储大量数据的数据类型。
例如,对于一个产品目录,应该选择能够存储大量图像和详细信息的字段类型。
2.3. 创建适当的索引:
索引可以大大提高查询性能。为经常用于查询和筛选数据的列创建索引,但请注意,索引也会影响插入和更新性能。
在数据库中创建适当的索引可以提高查询性能和减少查询时间。
2.3.1. 选择要创建索引的列:选择需要索引的列,这些列应该是经常用于查询的列。
2.3.2. 确定索引类型:选择适当的索引类型,例如 B-tree 索引、哈希索引、全文索引等。不同类型的索引适用于不同的查询类型和数据类型。
2.3.3. 创建索引:使用 SQL 语句创建索引。例如,使用 CREATE INDEX 语句创建 B-tree 索引: ```sql CREATE INDEX idx_name ON table_name (column_name); ```
2.3.4. 优化索引:在创建索引后,可以尝试优化索引以提高查询性能。例如,可以添加或删除索引列,或更改索引类型。
2.3.5. 维护索引:定期维护索引以保持其有效性。例如,可以定期更新索引以反映数据的变化。
总之,创建适当的索引可以提高查询性能和减少查询时间。因此,在创建索引时,应该选择适当的列、类型和优化索引。
2.4. 避免创建大量“临时”表:
这些表往往会积累大量未完成的数据。这些表可能会占用大量的磁盘空间,并导致性能下降。
2.5. 使用合适的存储引擎:
数据库的存储引擎影响数据库的性能和可扩展性。选择适合应用程序需求的存储引擎。例如,InnoDB引擎适合事务性应用程序,MyISAM引擎适合读取操作较多的应用程。
2.6. 数据库架构:
在数据库设计过程中,选择合适的架构非常重要。例如,水平拆分数据和缓存数据可以提高查询性能。根据应用程序需求,选择合适的架构,以优化数据库性能。 遵循这些建议,可以提高数据库的性能、可扩展性和可维护性。
三. 增加硬件资源
可以通过增加服务器内存、增加磁盘空间等方式,提高 MySQL 数据库服务器的性能。
硬件方面的优化可以有对磁盘进行扩容、将机械硬盘换为SSD,或是把CPU的核数往上提升一些,增强数据库的计算能力,或是把内存扩容了,让Buffer Pool能吃进更多数据, 等等。但这个优化手段成本最高,但见效最快。
四. 优化参数配置
通过对 MySQL 配置参数进行调整,可以提高 MySQL 数据库服务器的性能。例如,可以调整 MySQL 的缓冲区大小、最大连接数、线程数等参数。
4.1 降低磁盘的写入次数
4.1.1 增大 redo log,减少落盘次数:
redo log 是重做日志,用于保证数据的一致,减少落盘相当于减少了系统 IO 操作。
innodb_log_file_size 设置为 0.25 * innodb_buffer_pool_size
4.1.2 通用查询日志、慢查询日志可以不开 ,binlog 可开启。
通用查询和慢查询日志也是要落盘的,可以根据实际情况开启,如果不需要使用的话就可以关掉。binlog 用于恢复和主从复制,这个可以开启。
查看相关参数的命令:
# 慢查询日志
show variables like 'slow_query_log%'
# 通用查询日志
show variables like '%general%';
# 错误日志
show variables like '%log_error%'
# 二进制日志
show variables like '%binlog%';4.1.3 写 redo log 策略 innodb_flush_log_at_trx_commit 设置为 0 或 2
对于不需要强一致性的业务,可以设置为 0 或 2。
0:每隔 1 秒写日志文件和刷盘操作(写日志文件 LogBuffer --> OS cache,刷盘 OS cache --> 磁盘文件),最多丢失 1 秒数据
1:事务提交,立刻写日志文件和刷盘,数据不丢失,但是会频繁 IO 操作
2:事务提交,立刻写日志文件,每隔 1 秒钟进行刷盘操作
4.2 系统调优参数
(1)非缓存
back_log 默认50,改为500。 back_log=500
back_log 值可以指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。
也就是说,如果MySQL的连接数据达到 max_connections 时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。可以从默认的50升至500。
wait_timeout 由默认的8小时,修改为30分钟。 wait_timeout=1800
数据库连接闲置时间,闲置连接会占用内存资源。可以从默认的8小时减到半小时。
max_connections 默认151,改为3000。 max_connections=3000
MySql的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量。
max_user_connection 默认0,改为800。 max_user_connections=800
用户的最大连接,最大连接数,默认为0无上限,最好设一个合理上限。
thread_concurrency 并发线程数,设为CPU核数的两倍。
比如有一个双核的CPU, 那 thread_concurrency 的值应该为4; 2个双核的cpu, thread_concurrency 的值应为8。
(2)全局缓存
key_buffer_size
用于索引块的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),对MyISAM表性能影响最大的一个参数。
innodb_buffer_pool_size
缓存数据块和索引块,对InnoDB表性能影响最大。通过查询show status like 'Innodb_buffer_pool_read%',保证 (Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests越高越好。
innodb_additional_mem_pool_size
InnoDB 存储引擎用来存放数据字典信息以及一些内部数据结构的内存空间大小,当数据库对象非常多的时候,适当调整该参数的大小以确保所有数据都能存放在内存中提高访问效率,当过小的时候,MySQL会记录Warning信息到数据库的错误日志中,这时就需要该调整这个参数大小。
innodb_log_buffer_size
InnoDB 存储引擎的事务日志所使用的缓冲区,一般来说不建议超过32MB。
query_cache_size
缓存MySQL中的ResultSet,也就是一条SQL语句执行的结果集,所以仅仅只能针对select语句。当某个表的数据有任何变化,都会导致所有引用了该表的select语句在Query Cache中的缓存数据失效。所以,当我们数据变化非常频繁的情况下,使用Query Cache可能得不偿失。根据命中率(Qcache_hits/(Qcache_hits+Qcache_inserts)*100))进行调整,一般不建议太大,256MB可能已经差不多了,大型的配置型静态数据可适当调大。可以通过命令show status like 'Qcache_%'查看目前系统Query catch使用大小。
(3)局部缓存
read_buffer_size
MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。如果对表的顺序扫描请求非常频繁,可以通过增加该变量值以及内存缓冲区大小来提高其性能。
sort_buffer_size
MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。如果不能,可以尝试增加sort_buffer_size变量的大小。
read_rnd_buffer_size
MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
record_buffer
每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区。如果你做很多顺序扫描,可能想要增加该值。
thread_cache_size
保存当前没有与连接关联但是准备为后面新的连接服务的线程,可以快速响应连接的线程请求而无需创建新的。
五. 优化并发访问
合理配置连接数、使用数据库事务、使用数据库连接池等方式,可以提高 MySQL 数据库的并发访问性能。
六. 使用缓存技术
通过使用缓存技术,如 Redis、Memcached 等,可以减少数据库查询和存储的负担,提高数据库的性能。
相关文章:

MySQL优化
目录 一. 优化 SQL 查询语句 1.1. 分析慢查询日志 1.2. 优化 SQL 查询语句的性能 1.2.1 优化查询中的索引 1.2.2 减少表的连接(join) 1.2.3 优化查询语句中的过滤条件 1.2.4 避免使用SELECT * 1.2.5 优化存储过程和函数 1.2.6 使用缓存 二. 优化表结构…...
【C++】总结9
文章目录 C从源代码到可执行程序经过什么步骤静态链接和动态链接类的对象存储空间C的内存分区内存池在成员函数中调用delete this会出现什么问题?如果在类的析构函数中调用delete this,会发生什么? C从源代码到可执行程序经过什么步骤 预处理…...

C++报错 XX does not name a type;field `XX’ has incomplete type解决方案
C报错 XX does not name a type;field XX’ has incomplete type解决方案 两个C编译错误及解决办法–does not name a type和field XX’ has incomplete type 编译错误一:XX does not name a type 编译错误二:field XX’ has incomplete t…...

28.利用fminsearch、fminunc 求解最大利润问题(matlab程序)
1.简述 1.无约束(无条件)的最优化 fminunc函数 : - 可用于任意函数求最小值 - 统一求最小值问题 - 如求最大值问题: >对函数取相反数而变成求最小值问题,最后把函数值取反即为函数的最大值。 使用格式如下 1.必须预先把函数存…...

图像 检测 - FCOS: Fully Convolutional One-Stage Object Detection (ICCV 2019)
FCOS: Fully Convolutional One-Stage Object Detection - 全卷积一阶段目标检测(ICCV 2019) 摘要1. 引言2. 相关工作3. 我们的方法3.1 全卷积一阶目标检测器3.2 FCOS的FPN多级预测3.3 FCOS中心度 4. 实验4.1 消融研究4.1.1 FPN多级预测4.1.2 有无中心度…...
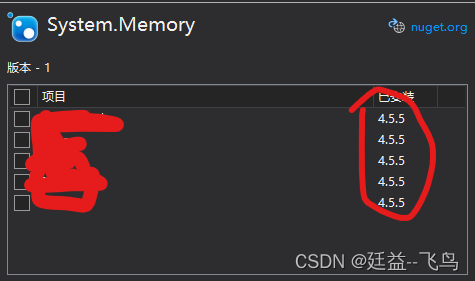
C# NDArray System.IO.FileLoadException报错原因分析
C# NDArray System.IO.FileLoadException 报错原因分析: 1.NuGet程序包版本有冲突 2.统一项目版本 1.打开解决方案NuGet程序包设置 2.查看是否有版本冲突 3.统一版本冲突...

快速响应,上门维修小程序让您享受无忧生活
随着科技的不断发展和智能手机的普及,上门维修小程序成为了现代人生活中越来越重要的一部分。上门维修小程序通过将维修服务与互联网相结合,为用户提供了更加便捷、高效的维修服务体验。下面将介绍上门维修小程序开发的优势。 提供便捷的预约方式&am…...
05、性能分析思路?
工具操作:包括压力工具、监控工具、剖析工具、调试工具。数值理解:包括上面工具中所有输出的数据。趋势分析、相关性分析、证据链分析:就是理解了工具产生的数值之后,还要把它们的逻辑关系想明白。这才是性能测试分析中最重要的一…...
【编程语言 · C语言 · calloc和realloc】
【编程语言 C语言 calloc和realloc】https://mp.weixin.qq.com/s?__bizMzg4NTE5MDAzOA&mid2247491544&idx1&sn72d8f9931cfa7ce7441a3248475ab619&chksmcfade321f8da6a374a5935bb46441a03a007c0589db6b8afa8c1991854d632a3201553e37b0b&payreadticketHGy…...

机器学习分布式框架ray运行pytorch实例
Ray是一个用于分布式计算的开源框架,它可以有效地实现并行化和分布式训练。下面是使用Ray来实现PyTorch的训练的概括性描述: 安装Ray:首先,需要在计算机上安装Ray。你可以通过pip或conda来安装Ray库。 准备数据:在使用…...
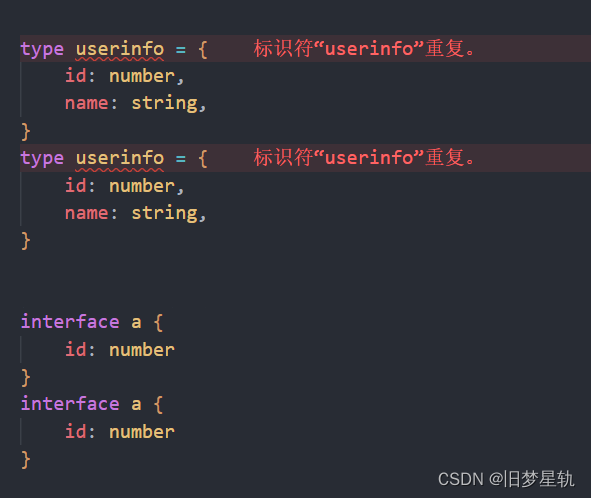
TypeScript 【type】关键字的进阶使用方式
导语: 在前面章节中,我们了解到 TS 中 type 这个关键字,常常被用作于,定义 类型别名,用来简化或复用复杂联合类型的时候使用。同时也了解到 为对象定义约束接口类型 的时候所使用的是 Interfaces。 其实对于前面&#…...
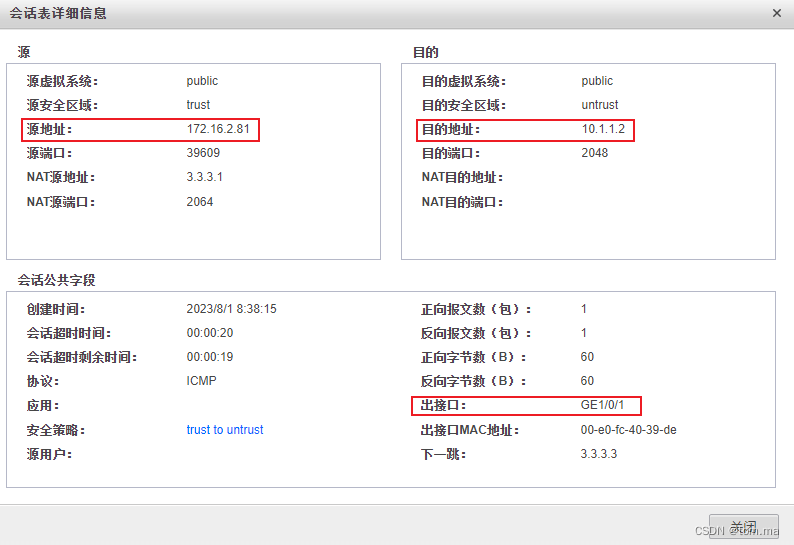
策略路由实现多ISP接入Internet
组网需求: 企业分别从ISP1和ISP2租用了一条链路 PC3用户上网访问Server1时走ISP1PC4用户上网访问Server1时走ISP2 拓扑图 一、ISP1 运营商 R1路由器 <Huawei>sys [Huawei]sys R1 [R1]un in en[R1]int g0/0/0 [R1-GigabitEthernet0/0/0]ip addr 2.2.2.2 2…...

Socket本质、实战演示两个进程建立TCP连接通信的过程
文章目录 Socket是什么引入面试题, 使你更深刻的理解四元组 Socket网络通信大体流程实战演示TCP连接建立过程需要用到的linux 查看网络的一些命令测试的程序一些准备工作启动服务端, 并没有调用accept启动客户端开启服务accept Socket是什么 通俗来说,Socket是套接字,是一种编…...

java学习路程之篇四、进阶知识、石头迷阵游戏、绘制界面、打乱石头方块、移动业务、游戏判定胜利、统计步数、重新游戏
文章目录 1、绘制界面2、打乱石头方块3、移动业务4、游戏判定胜利5、统计步数6、重新游戏7、完整代码 1、绘制界面 2、打乱石头方块 3、移动业务 4、游戏判定胜利 5、统计步数 6、重新游戏 7、完整代码 java之石头迷阵单击游戏、继承、接口、窗体、事件、组件、按钮、图片...
Git全栈体系(三)
第六章 GitHub 操作 一、创建远程仓库 二、远程仓库操作 命令名称作用git remote -v查看当前所有远程地址别名git remote add 别名 远程地址起别名git push 别名 分支推送本地分支上的内容到远程仓库git clone 远程地址将远程仓库的内容克隆到本地git pull 远程库地址别名 远…...
JMeter发送get请求并分析返回结果
在实际工作的过程中,我们通常需要模拟接口,来进行接口测试,我们可以通过JMeter、postman等多种工具来进行接口测试,但是工具的如何使用对于我们来说并不是最重要的部分,最重要的是设计接口测试用例的思路与分析结果的能…...

HTML笔记(1)
介绍 浏览器中内置了HTML的解析引擎,通过解析标记语言来展现网页;HTML标签都是预定义好的;Java工程师:后台代码的编写,和数据库打交道,把数据给网页前端的工程师;网页前端工程师:写H…...
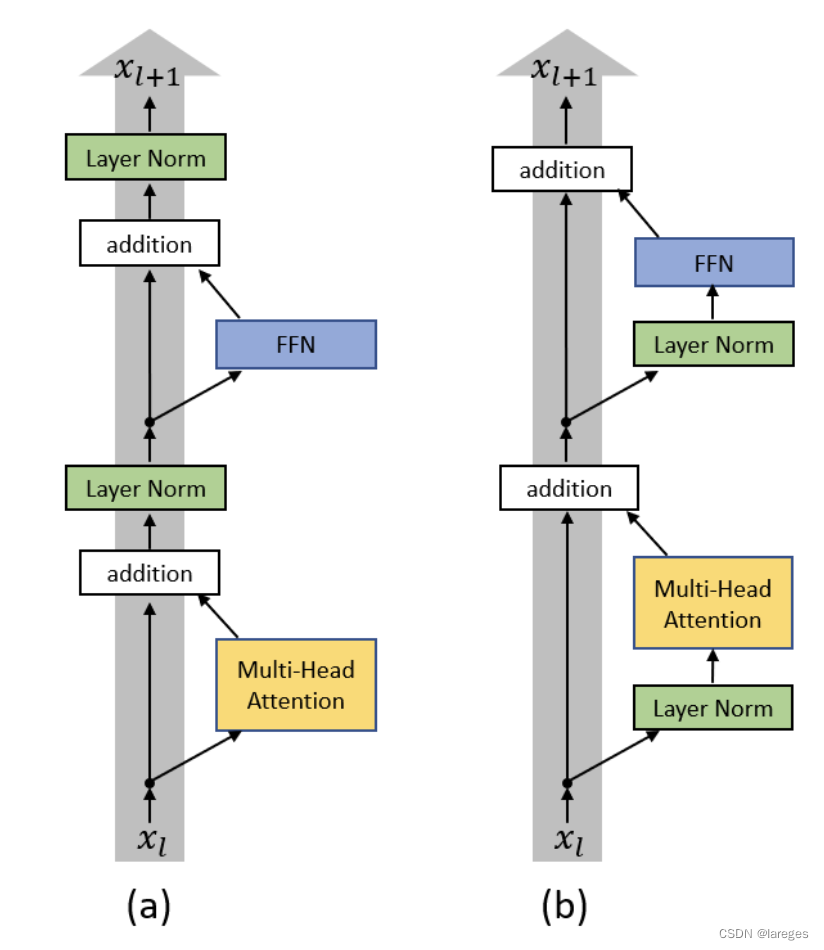
重新审视MHA与Transformer
本文将基于PyTorch源码重新审视MultiheadAttention与Transformer。事实上,早在一年前博主就已经分别介绍了两者:各种注意力机制的PyTorch实现、从零开始手写一个Transformer,但当时的实现大部分是基于d2l教程的,这次将基于PyTorch…...
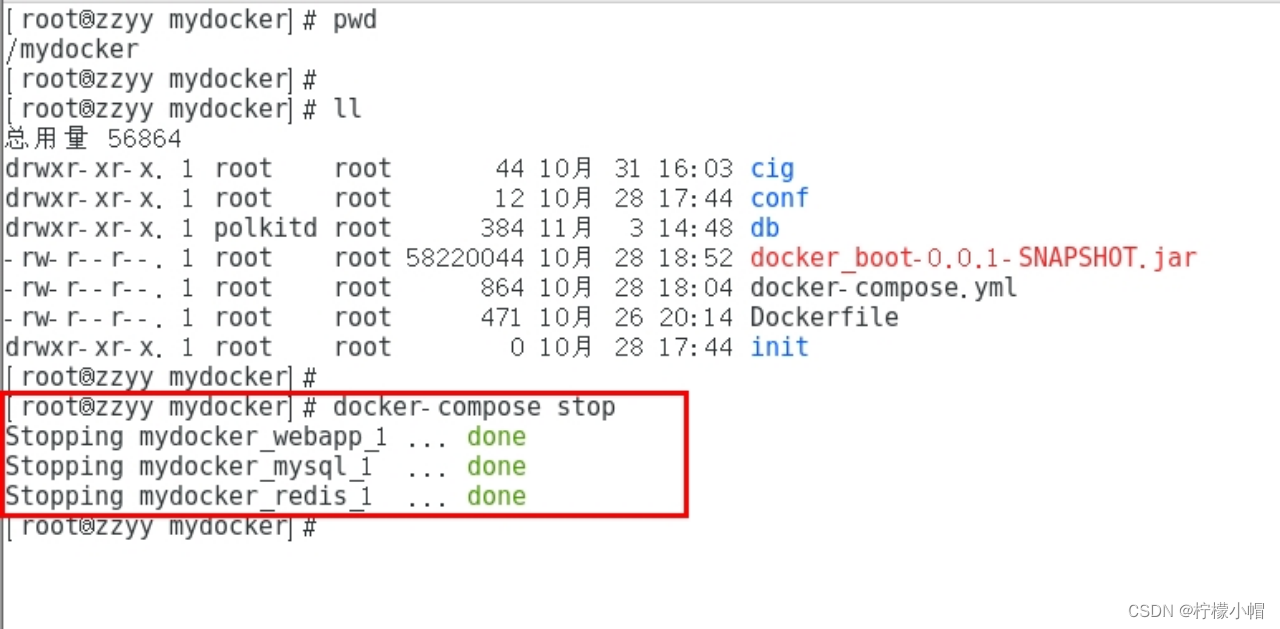
Docker 全栈体系(七)
Docker 体系(高级篇) 五、Docker-compose容器编排 1. 是什么 Compose 是 Docker 公司推出的一个工具软件,可以管理多个 Docker 容器组成一个应用。你需要定义一个 YAML 格式的配置文件docker-compose.yml,写好多个容器之间的调…...
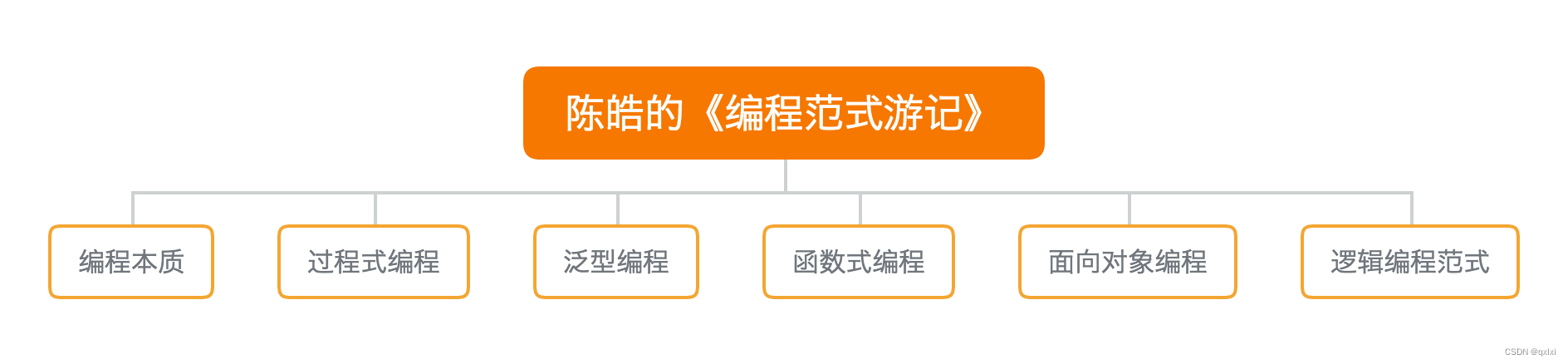
【编程范式】聊聊什么是数据类型和范式的本质
什么是编程范式 范式其实就是做事的方式,编程范式可以理解为如何编程,按照什么样的模式或者风格进行编程。 编程范式包含哪些 泛型编程函数式编程面向对象编程编程本质和逻辑编程 虽然有不同的编程范式,但是对于目的来说都是为了解决同一…...

i.MX8MP NPU实战:TensorFlow Lite模型移植与VSI-NPU优化全流程
1. 项目概述与核心价值最近在折腾一块基于NXP i.MX8M Plus的开发板,这块板子最大的亮点就是集成了一个专为边缘AI设计的神经处理单元(NPU)。官方文档里提了一嘴TensorFlow Lite的例程,但真上手去移植,发现坑是一个接一…...

API Key认证系统设计:企业级API开放平台实践
API Key认证系统设计:企业级API开放平台实践 摘要:当AI应用从内部工具转向对外开放时,如何确保接口安全、防止滥用并实现精细化权限控制?本文基于一个真实的跑步教练AI项目,详细解析如何构建一套生产级的API Key认证系…...

如何通过DLSS版本管理工具提升30%游戏性能:实战指南
如何通过DLSS版本管理工具提升30%游戏性能:实战指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款开源游戏性能优化工具,专门用于管理DLSS、FSR和XeSS动态库版本。你是否曾…...

解锁端侧智能:基于BigDL-LLM与Qwen-1.8B-Chat的CPU高效推理实践
1. 为什么要在CPU上部署大模型? 最近两年大模型技术发展迅猛,但大多数应用都依赖昂贵的GPU服务器。我在实际项目中发现,很多中小企业和个人开发者其实更需要能在普通电脑上运行的轻量化方案。这就是为什么基于CPU的大模型部署方案变得越来越…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...

单元体幕墙计算方法研究
单元体幕墙计算方法研究 一、单元板块计算 选择隔离的单个单元进行计算,不需要考虑周边单元的影响。 单元之间的相互影响,来自于左右立柱的变形不一致,在截面选择上反应的就是左右立柱的截面参数的不同。 所以,单元间的相互影响,可以通过控制左右立柱截面参数的相近而进…...

终极免费城通网盘直连解析工具:告别下载限速的完整指南
终极免费城通网盘直连解析工具:告别下载限速的完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载速度慢、等待时间长而烦恼吗?ctfileGet是一款专为城通…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导?
NS-USBLoader:Switch游戏管理终极指南 - 如何实现一键安装与系统引导? 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: ht…...

多模态AI实战:基于OpenGVLab/Ask-Anything构建视觉问答系统
1. 项目概述:当视觉大模型学会“看图说话”最近在折腾多模态AI应用,发现了一个挺有意思的开源项目,叫OpenGVLab/Ask-Anything。简单来说,它就像一个给AI装上了“眼睛”和“嘴巴”的系统,你给它一张图片或一段视频&…...