SQL项目实战:银行客户分析
大家好,本文将与大家分享一个SQL项目,即根据从数据集收集到的信息分析银行客户流失的可能性。这些洞察来自个人信息,如年龄、性别、收入和人口统计信息、银行卡类型、产品、客户信用评分以及客户在银行的服务时间长短等。对于银行而言,了解如何留住客户比寻找其他客户更有利。
客户流失是指客户或顾客的流失。公司通常将其作为关键业务指标之一,因为恢复的长期客户对公司的价值远远高于新招募的客户。客户流失有两种类型:自愿流失和非自愿流失。自愿流失是由于客户决定转向其他公司或服务提供商,而非自愿流失则是由于客户搬迁到长期护理机构、死亡或搬迁到较远的地方等情况造成的。
本文将集中讨论自愿流失,因为它可能是由于公司与客户关系中公司可以控制的因素造成的,例如如何处理账单互动或如何提供售后帮助。
数据集
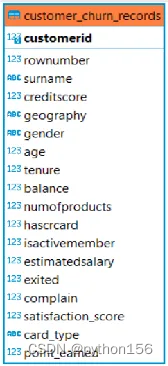
本文使用的是customer_churn_records表,该表包含多列,customerid是表的主键。
-
RowNumber:对应记录(行)编号
-
CustomerId:客户的ID编号
-
Surname:客户的姓氏
-
CreditScore:客户信用行为预测值
-
Geography:客户所在地
-
Gender:客户的性别信息
-
Age:客户的年龄信息
-
Tenure:客户在银行的使用年限
-
Balance:客户账户中的余额信息
-
NumOfProducts:客户购买的产品数量
-
HasCrCard:客户是否拥有信用卡
-
IsActiveMember:客户是否处于活跃状态
-
EstimatedSalary(估计工资):客户的估计工资金额
-
Exited:客户是否离开银行
-
Complain:客户是否有投诉
-
Satisfaction Score:客户对银行的满意度评分
-
Card Type:客户持有的银行卡类型
-
Points Earned:客户使用信用卡获得的积分
# 显示表中的列 = customer_churn_recordsq='''SELECT * FROM customer_churn_records'''df = pd.read_sql(q,engine_postgresql)
df.head()
查询客户流失率
导入软件包:
import psycopg2 # PostgreSQL数据库适配器
import pandas as pd # 用于分析数据
from sqlalchemy import create_engine # 促进Python程序与数据库之间的通信首先,本文根据已退出的列计算有多少客户流失。
# 统计是否流失/退出的客户总数q='''WITH temp_churn AS(SELECT exited,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,COUNT(exited) as TotalFROM temp_churnGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()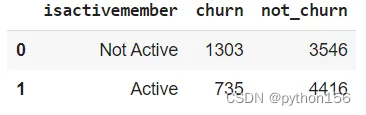
可以发现在10000名客户中,有近20%从银行退出或流失。尽管这个数字并不算很大,但如果现在还不能解决这个问题,它可能会增长得更多。
现在,本文将从活跃客户、性别、人口统计、年龄、临时工龄、信用分数、产品数量、满意度分数、投诉、是否有信用卡、卡类型、已获积分、预估薪资和余额等多个方面来检查客户流失状况的类型。
# 统计有多少活跃客户流失q=''' WITH temp_isactivemember AS(SELECT exited,CASE WHEN isactivemember = 1 THEN 'Active'ELSE 'Not Active'END AS isactivememberfrom customer_churn_records)SELECT isactivemember,COUNT (CASE WHEN exited = 1 THEN 1 END) AS Churn,COUNT (CASE WHEN exited = 0 THEN 1 END) AS Not_ChurnFROM temp_isactivememberGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df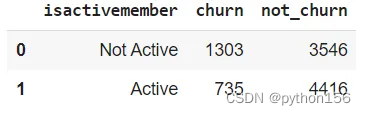
# 根据性别计算是否流失/退出的客户总数q='''SELECT gender,COUNT(gender) as Total,COUNT(case when exited = 1 then 1 end) as Churn,COUNT(case when exited = 0 then 1 end) as Not_churnFROM customer_churn_recordsGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()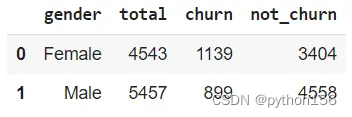
# 根据人口统计数据计算流失客户的数量q=''' SELECT geography,COUNT (CASE WHEN exited = 1 THEN 1 END) AS Churn,COUNT (CASE WHEN exited = 0 THEN 1 END) AS Not_ChurnFROM customer_churn_recordsGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df
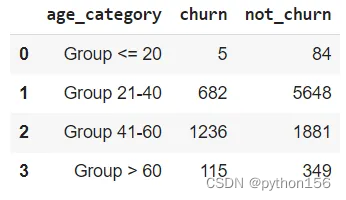
#根据年龄组计算流失客户的数量q=''' SELECT CASE WHEN age <= 20 THEN 'Group <= 20'WHEN age >= 21 AND age <= 40 THEN 'Group 21-40'WHEN age >= 41 AND age <= 60 THEN 'Group 41-60'ELSE 'Group > 60'END AS age_category,COUNT(CASE WHEN exited = 1 then 1 end) as Churn,COUNT(CASE WHEN exited = 0 then 1 end) as Not_ChurnFROM customer_churn_recordsGROUP BY 1ORDER BY 1'''df = pd.read_sql(q,engine_postgresql)
df
# 根据他们成为客户的时间计算是否流失/退出的客户总数q='''WITH temp_tenure AS(SELECT tenure,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,AVG(tenure) as Average_tenureFROM temp_tenureGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()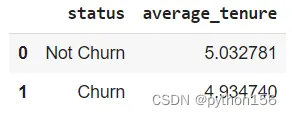
# 根据客户使用银行产品的数量,计算有多少客户流失q='''WITH temp_bankprod AS(SELECT numofproducts,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,AVG(numofproducts) as avg_numofproductsFROM temp_bankprodGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()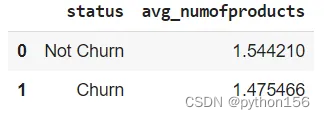
# 根据客户 对银行的满意度得分的平均得分,计算有多少客户流失q='''WITH temp_satisfaction AS(SELECT satisfaction_score,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,AVG(satisfaction_score) as satisfaction_levelFROM temp_satisfactionGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()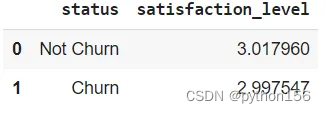
# 根据客户的投诉量,统计有多少客户流失q='''WITH temp_complain AS(SELECT complain,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,COUNT(complain) as complainFROM temp_complainGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()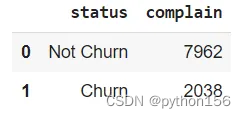
# 根据客户是否拥有信用卡计算有多少客户流失q=''' WITH temp_hascrcard AS(SELECT hascrcard,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,COUNT (CASE WHEN hascrcard = 1 THEN 1 END) AS has_creditcard,COUNT (CASE WHEN hascrcard = 0 THEN 1 END) AS no_creditcardFROM temp_hascrcardGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df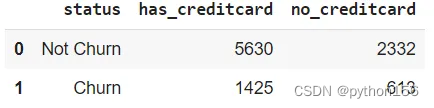
# 根据客户的预估工资计算有多少客户流失q='''WITH temp_salary AS(SELECT estimatedsalary,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,AVG(estimatedsalary) as avg_salary,MAX(estimatedsalary) as max_salary,MIN(estimatedsalary) as min_salaryFROM temp_salaryGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()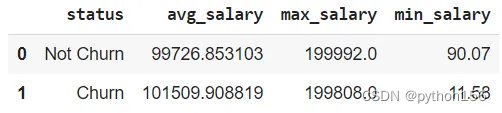
# 根据客户的银行存款余额计算有多少客户流失
#(平均、最高、最低)q='''WITH temp_balance AS(SELECT balance,CASE WHEN exited = 1 THEN 'Churn'ELSE 'Not Churn'END AS STATUSfrom customer_churn_records)SELECT STATUS,AVG(balance) as avg_balance,MAX(balance) as max_balance,MIN(balance) as min_balanceFROM temp_balanceGROUP BY 1'''df = pd.read_sql(q,engine_postgresql)
df.head()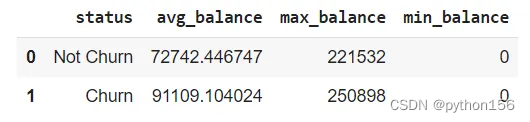
结论
根据上述问题,有一些类别可以帮助确定哪些方面会真正影响客户流失。不管客户在银行停留了多长时间,他们仍然有可能流失,或者说,客户的银行账户上有相当数量的存款,他们仍然有可能流失。
通过分析发现,41至60岁年龄段的客户比其他年龄段的客户更容易流失。为了解决这个问题,银行可以集中精力创造或提升产品和服务,以帮助吸引和维护特定年龄段的客户,比如为年龄较大的客户提供更流畅的服务和最短的排队时间。
持有信用卡的客户往往不会流失,而是会继续留在银行。银行最好通过各种促销活动说服更多的客户申请信用卡,这取决于客户细分,可根据客户的卡种(钻石卡、白金卡、金卡、银卡)、性别、年龄、支出和人口分布进行细分。
留存客户和流失客户的满意度得分有点令人担忧 [ 3.017960 / 2.997547 ],银行需要进行评估,以保持流失客户和留存客户之间的满意度得分差距,并保持活跃客户,因为活跃客户流失的可能性较低。
相关文章:
SQL项目实战:银行客户分析
大家好,本文将与大家分享一个SQL项目,即根据从数据集收集到的信息分析银行客户流失的可能性。这些洞察来自个人信息,如年龄、性别、收入和人口统计信息、银行卡类型、产品、客户信用评分以及客户在银行的服务时间长短等。对于银行而言&#x…...
)
【Redis深度专题】「核心技术提升」探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群指令分析—实战篇)
探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群指令分析—下篇) Cluster XX的集群指令(扩展)写入记录主节点和备节点切换-CLUSTER FAILOVER新加入master节点新加入slave节点为slave节点重新分配master分配哈希槽删除…...

ubuntu
安装 sudo apt-get update sudo apt-get install mysql-server mysql-client 设置root密码 cat /etc/mysql/debian.cnf 查看默认密码 mysql -u debian-sys-maint -p 连接输入密码 use mysql; select user,plugin from user; update user set pluginmysql_native_passwor…...
【芯片设计- RTL 数字逻辑设计入门 3- Verdi 常用使用命令】
文章目录 Verdi 全局显示Verdi 前导 0 的显示Verdi 数据笔数统计Verdi 波形数据dump Verdi 全局显示 bsubi -n 16 -J sam visualizer -tracedir ./veloce.wave/debug_waveform.stw 打开波形后,如果想要看到所有信号的数据,可以点击下图中红框中的按钮&a…...
python-pytorch基础之cifar10数据集使用图片分类
这里写目录标题 总体思路获取数据集下载cifar10数据解压包文件介绍加载图片数字化信息查看数据信息数据读取自定义dataset使用loader加载建模训练测试建测试数据的loader测试准确性测试一张图片读取一张图片加载模型预测图片类型创建一个预测函数随便来张马的图片结果其他打开一…...

华纳云:linux下磁盘管理与挂载硬盘方法是什么
在Linux下进行磁盘管理和挂载硬盘的方法如下: 磁盘管理: a. 查看已连接的磁盘:可以使用命令 fdisk -l 或 lsblk 查看系统中已连接的磁盘信息,包括硬盘和分区。 b. 创建分区:如果磁盘是全新的,需要使用 f…...

ChatGPT + Stable Diffusion + 百度AI + MoviePy 实现文字生成视频,小说转视频,自媒体神器!(一)
ChatGPT Stable Diffusion 百度AI MoviePy 实现文字生成视频,小说转视频,自媒体神器!(一) 前言 最近大模型频出,但是对于我们普通人来说,如何使用这些AI工具来辅助我们的工作呢,或者参与进入我们的生活…...

linux strcpy/strncpy/sprintf内存溢出问题
本文主要介绍strcpy/strncpy/sprintf都是不安全的,可能存在内存溢出的问题。下来进行实例分析。 strcpy代码: #include <stdio.h> #include <string.h> #include <stdlib.h> #include <stdbool.h>void test_func(char *str) {b…...
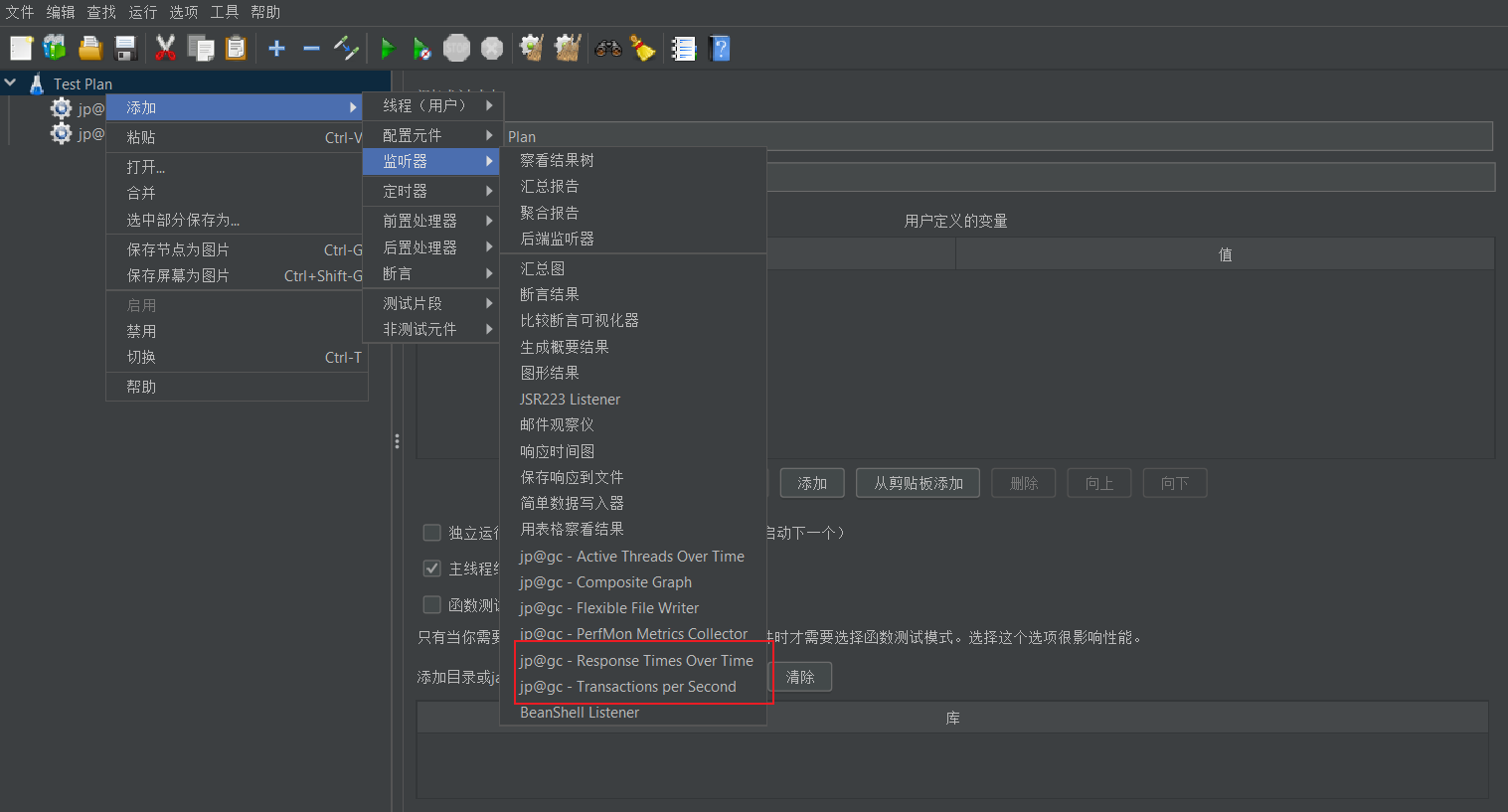
Jmeter如何添加插件
一、前言 在我们的工作中,我们可以利用一些插件来帮助我们更好的进行性能测试。今天我们来介绍下Jmeter怎么添加插件? 2023最新Jmeter接口测试从入门到精通(全套项目实战教程) 二、插件管理器 首先我们需要下载插件管理器j…...

flask---CBV使用和源码分析
1 cbv写法 -1 写个类,继承MethodView-2 在类中写跟请求方式同名的方法-3 注册路由:app.add_url_rule(/home, view_funcHome.as_view(home))#home是endpoint,就是路由别名#例子 class add(MethodView):def get(self):return holleapp.add_url…...

Qt 实现压缩文件、文件夹和解压缩操作zip
一、实现方式 通过Qt自带的库来实现,使用多线程方式,通过信号和槽来触发压缩与解压缩,并将压缩和解压缩结果回传过来。 使用的类: #include "QtGui/private/qzipreader_p.h" #include "QtGui/private/qzipwriter…...
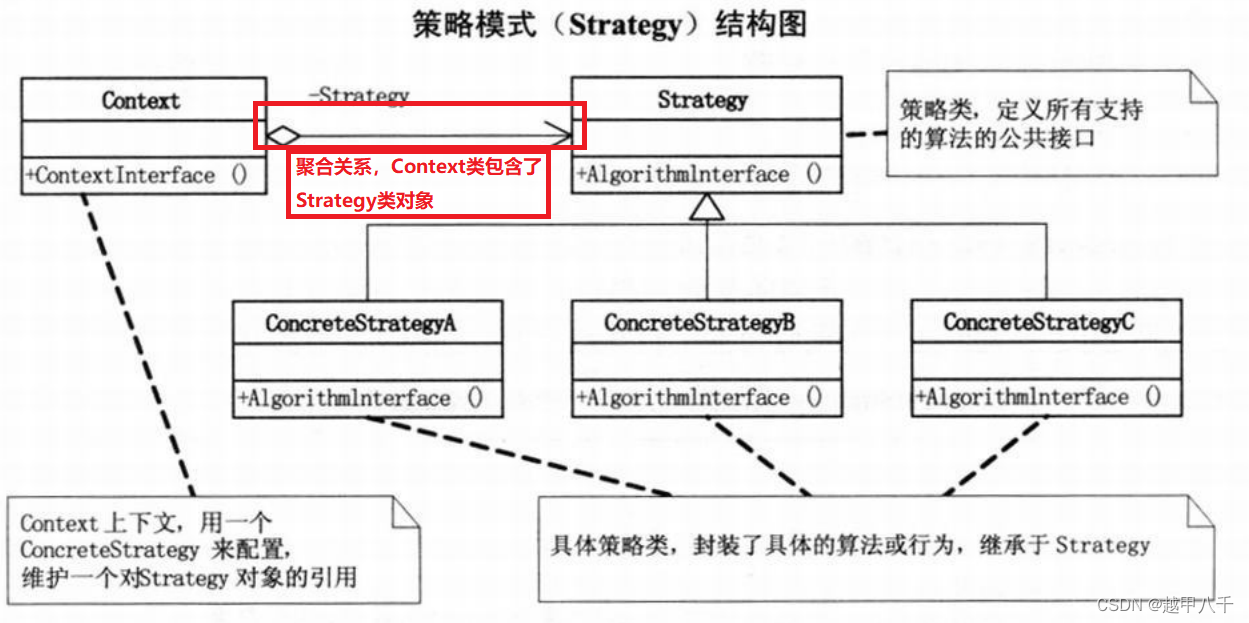
简单工厂模式VS策略模式
简单工厂模式VS策略模式 今天复习设计模式,由于简单工厂模式和策略模式太像了,重新整理梳理一下 简单工厂模式MUL图: 策略模式UML图: 1、简单工厂模式中只管创建实例,具体怎么使用工厂实例由调用方决定,…...
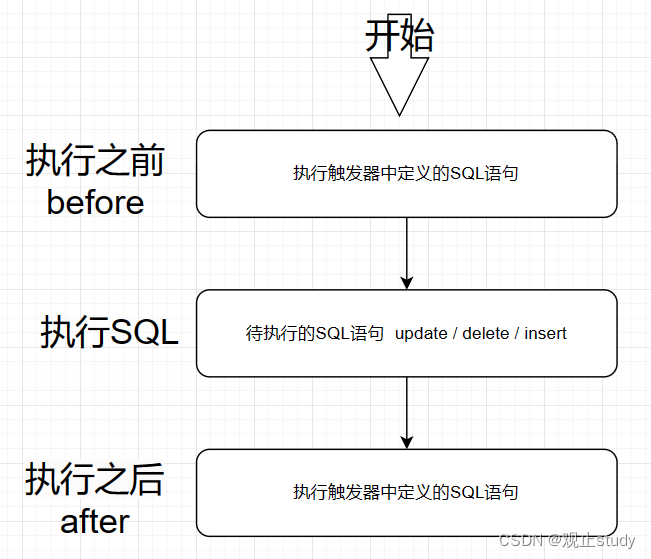
【MySQL】触发器 (十二)
🚗MySQL学习第十二站~ 🚩本文已收录至专栏:MySQL通关路 ❤️文末附全文思维导图,感谢各位点赞收藏支持~ 一.引入 触发器是与表有关的数据库对象,作用在insert/update/delete语句执行之前(BEFORE)或之后(AFTER),自动触发并执行触发器中定义的SQL语句集合。它可以协助应…...

听说 Spring Bean 的创建还有一条捷径?
文章目录 1. resolveBeforeInstantiation1.1 applyBeanPostProcessorsBeforeInstantiation1.2 applyBeanPostProcessorsAfterInitialization1.3 案例 2. 源码实践2.1 切面 Bean2.2 普通 Bean 在 Spring Bean 的创建方法中,有如下一段代码: AbstractAutow…...

大数据课程E6——Flume的Processor
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Processor的概念和配置参数; ⚪ 掌握Processor的使用方法; ⚪ 掌握Processor的Default Processo; ⚪ 掌握Processor的Load Balance Processo; 一、Failover Sink Processor 1. …...
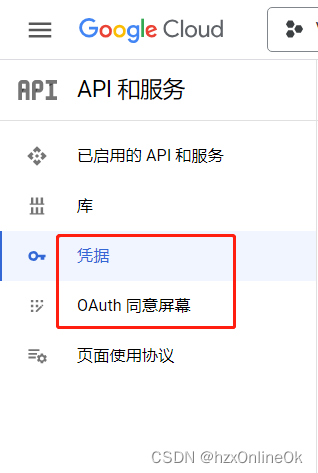
实现邮箱管理之gmail邮箱、office365(Azure)邮箱之披荆斩棘问题一览
要进行Office365邮箱的授权对接,你需要先申请一个应用,并获取授权访问令牌。 以下是一个简单的步骤: 登录 Azure 门户:https://portal.azure.com/创建一个新的应用程序,或者使用现有的应用程序。要创建新的应用程序&…...
多重背包问题 I,II)
(AcWing)多重背包问题 I,II
有 N 种物品和一个容量是 V 的背包。 第 i 种物品最多有 si 件,每件体积是 vi,价值是 wi。 求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。 输出最大价值。 输入格式 第一行两个整数 N,…...
如何把几个视频合并在一起?视频合并方法分享
当我们需要制作一个比较长的视频时,将多个视频进行合并可以使得整个过程更加高效。此外,合并视频还可以避免出现“剪辑断层”的情况,使得视频内容更加连贯,更加容易被观众理解和接受。再有,合并视频还可以减少视频文件…...
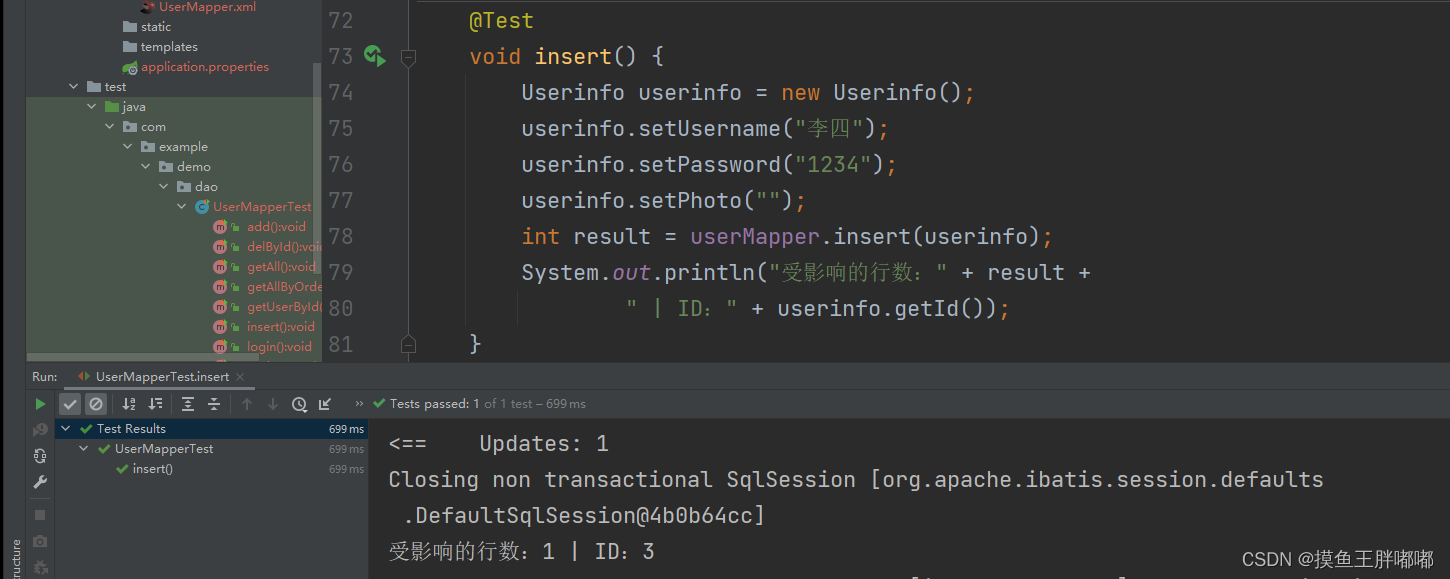
【MyBatis】初学MyBatis
目录 MyBatis 是什么?MyBatis框架搭建1.添加MyBatis框架2.设置MyBatis配置数据库的相关链接信息xml 保存路径和命名格式 根据MyBatis写法完成数据库的操作MyBatis插件MyBatis传递参数查询${} 和 #{} 有什么区别?SQL注入问题 MyBatis like查询MyBatis多表…...

深度学习训练营之DCGAN网络学习
深度学习训练营之DCGAN网络学习 原文链接环境介绍DCGAN简单介绍生成器(Generator)判别器(Discriminator)对抗训练 前置工作导入第三方库导入数据数据查看 定义模型初始化权重定义生成器generator定义判别器 模型训练定义参数模型训…...

如何快速实现无人机合规飞行:基于ESP32的完整远程识别解决方案
如何快速实现无人机合规飞行:基于ESP32的完整远程识别解决方案 【免费下载链接】ArduRemoteID RemoteID support using OpenDroneID 项目地址: https://gitcode.com/gh_mirrors/ar/ArduRemoteID 在FAA和欧盟无人机法规日益严格的背景下,远程识别已…...

企业级AI Agent安全治理:从“能用“到“敢用“的五维框
一、为什么企业需要Agent治理框架我们公司最近在帮一家制造业客户做AI Agent数字员工的落地项目。客户之前已经自己部署了一批Agent,分别处理品质查询、物料追踪、报表生成等业务。运行三个月后,IT部门发现了三个让人头疼的问题:有个Agent累计…...

Kimi推出超实用插件!让AI真正像你一样操作浏览器
月之暗面(Moonshot AI)正式推出了一款名为 Kimi WebBridge 的浏览器扩展插件。这款产品的核心理念是让AI Agent像你本人一样操作浏览器。它带着你的登录状态、你的Cookie、你的账号,去点击、滑动、输入,填写表单、提取信息、跨站点…...

如何快速找回遗忘的压缩包密码:开源工具的完整使用指南
如何快速找回遗忘的压缩包密码:开源工具的完整使用指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经为加密的压缩…...
)
软件工程师在智能体视觉时代的机遇(22)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Leetcode 思路-105.从前序与中序序列构造二叉树
105.从前序与中序序列构造二叉树给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。1.简单思路根据先序遍历根节点在前的特点,取到根节点后&a…...

贪吃蛇游戏设计-7.完整系统
7.完整系统 完整系统Snake代码太多,另有源码。 一个基于 HarmonyOS ArkTS 开发的经典贪吃蛇游戏,适合作为 ArkTS 开发的学习项目。 功能特性 🎮 经典贪吃蛇玩法 📊 实时分数显示 🏆 最高分记录 📝 玩家姓名输入与成绩保存 📋 排行榜展示 🗑️ 排行榜滑动删除功…...

ComfyUI Manager插件架构优化:5种高效部署方案与性能调优指南
ComfyUI Manager插件架构优化:5种高效部署方案与性能调优指南 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable variou…...

5分钟极速上手:免费B站视频转文字工具完整指南
5分钟极速上手:免费B站视频转文字工具完整指南 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为整理B站视频内容而烦恼吗?bili2t…...

从AT24C02 EEPROM的I2C时序出发,手把手调试你的蓝桥杯单片机存储模块
从AT24C02 EEPROM的I2C时序出发,手把手调试你的蓝桥杯单片机存储模块 在蓝桥杯单片机竞赛中,AT24C02 EEPROM存储模块的稳定读写是基本功,但真正的高手往往能在底层通信协议层面发现问题、解决问题。本文将带你从I2C时序的微观视角,…...