2023美国大学生数学建模竞赛C题思路解析(含代码+数据可视化)
以下为2023美国大学生数学建模竞赛C题思路解析(含代码+数据可视化)
规则:
猜词,字母猜对,位置不对为黄色,位置对为绿色,两者皆不对为灰色。
困难模式下的要求:对于猜对的字母(绿色和灰色),下一步必须使用
要求:
报告结果的数量每天都在变化。开发一个模型来解释这种变化,并使用您的模型为2023年3月1日报告的结果数量创建一个预测区间。单词的任何属性是否会影响在硬模式下播放的报告分数百分比?如果是,怎么办?如果没有,为什么不呢?
对于给定的未来解决方案单词,在未来的日期,开发一个模型,使您能够预测报告结果的分布。换句话说,预测未来日期(1,2,3,4,5,6,X)的相关百分比。你的模型和预测有哪些不确定性?举一个具体的例子,说明你对2023年3月1日EERIE一词的预测。你对模型的预测有多自信?
开发并总结一个模型,根据难度对解决方案单词进行分类。识别与每个分类相关的给定单词的属性。使用你的模型,EERIE这个词有多难?讨论分类模型的准确性。
列出并描述此数据集的一些其他有趣的功能。
最后,在给《纽约时报》拼图编辑的一到两页信中总结你的结果。
结果每天都在变化的原因:
是否工作日,人们尝试的意愿有多大
新增一列为是否为工作日,或者判断为周几
昨天或者前几天的难度对于游玩心态的影响
虽然尝试次数这里使用的是百分比,但是总分数与困难模式下的分数为具体的值,尝试的人的数量不同则总分不同。
单词的难度,包括长度,重复字母的数量,词性等 长度是固定的不需要考虑
存在的问题:对于同一个字母的多次使用,他是怎么进行显示的,比如我输入了全是A的情况,他显示的是除了对的位置是绿色,其他全是黄色还是其他的什么情况?
单词是否为常见词,或者和常见词的相似度
在此基础上就需要常见词库,以及单词相似度度量
需要预测的东西: 不同尝试次数的百分比分布,分数区间,困难的分数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetimeplt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题df = pd.read_excel('Problem_C_Data_Wordle.xlsx', header=1)
df=df[df.columns[1:]]
df.head()
预处理:
百分比之和可能不等于1,所以对其进行归一化
按照'Contest Number'对整个表进行升序排列
判断当前日期是否为周末,为周几
统计单词中字母个数,重复出现的字母算一次
对单词进行词性标注
df = pd.read_excel('Problem_C_Data_Wordle.xlsx', header=1)
df=df[df.columns[1:]]
# 对尝试次数进行归一化,使其结果和等于100
df = df.sort_values(by='Contest number', ignore_index=True)
percent = df[df.columns[5:]].sum(axis=1)
for column in df.columns[5:]:df[column]=df[column]/percent*100
# 判断当前日期为周几,周一为0,依次增加
df['week']=df['Date'].apply(lambda x:x.weekday())
df['is_weekend'] = df['week'].apply(lambda x:x>4)
# 统计单词中字母的个数
df['word_len'] = df['Word'].apply(lambda x:len(set(x)))
# 对单词进行词性标注
df['tag'] = df['Word'].apply(lambda x:nltk.pos_tag(nltk.word_tokenize(x))[0][1])
df.head() 
1 第一题
第一小问:
Q:报告结果的数量每天都在变化。开发一个模型来解释这种变化,并使用您的模型为2023年3月1日报告的结果数量创建一个预测区间。
首先判断是否与周几有关,如果有则将该参数加入模型中,如果没有则不加入
使用时间预测模型,或者二次函数训练,使用留一法等交叉验证方法得到关于模型准确率的描述。
第二小问:
Q:单词的任何属性是否会影响在硬模式下播放的报告分数百分比?如果是,怎么办?如果没有,为什么不呢?
A: 任何属性可以包括:唯一字母的数量,单词的词性,常见度,字母的词频
差异度分析,相关性分析
分析整体的星期几对得分均值的影响
plt.scatter(df['Contest number'], df['Number of reported results'])
plt.title('得分数-编号分布图')
plt.show()
weeks = []
for week in range(7):df1 = df[df['week']==week]weeks.append(df1['Number of reported results'].mean())
plt.scatter([i+1 for i in range(7)], weeks)
plt.plot([i+1 for i in range(7)], [df['Number of reported results'].mean() for i in range(7)])
plt.title('周一到周日每天得分均值与总均值图')
# 其中直线为总均值图,散点图为每天的
plt.show()
# 整体得分与星期几之间的相关性
np.corrcoef(df['week'], df['Number of reported results'])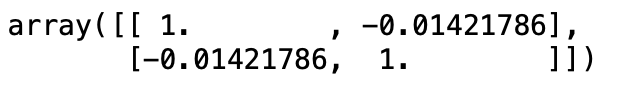
可以看到,在整个时间段中,星期几与得分情况的相关性不大,甚至可以说不相关。
取得分总体趋于稳定后的区域,判断星期几对得分的影响
以上仅为第一问小部分思路(后续完善),剩余部分思路和其他全网具体配套代码、参考论文,以及其他题目思路,可以点击文末群名片获取
相关文章:
2023美国大学生数学建模竞赛C题思路解析(含代码+数据可视化)
以下为2023美国大学生数学建模竞赛C题思路解析(含代码数据可视化)规则:猜词,字母猜对,位置不对为黄色,位置对为绿色,两者皆不对为灰色。困难模式下的要求:对于猜对的字母(…...
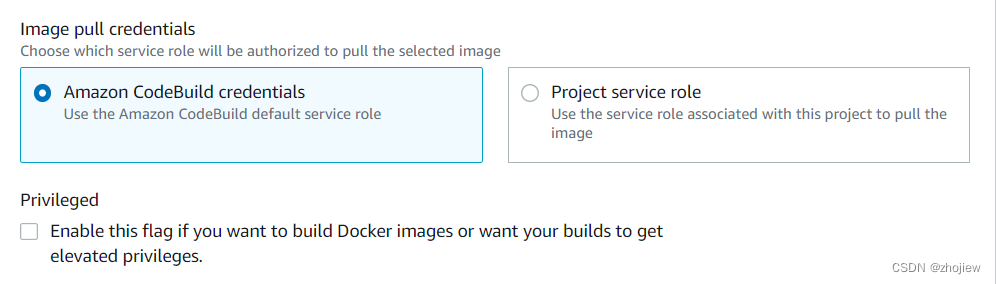
aws codebuild 自定义构建环境和本地构建
参考资料 Extending AWS CodeBuild with Custom Build Environments Docker in custom image sample for CodeBuild codebuild自定义构建环境 在创建codebuild项目的时候发现 构建环境是 Docker 映像,其中包含构建和测试项目所需的所有内容的完整文件系统 用ru…...
3年功能3年自动化,从8k到23k的学习过程
简单的先说一下,坐标杭州,14届本科毕业,算上年前在阿里巴巴的面试,一共有面试了有6家公司(因为不想请假,因此只是每个晚上去其他公司面试,所以面试的公司比较少)其中成功的有4家&…...

leaflet: 数据聚合,显示当前bounds区域中的点的名称列表(078)
第078个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+leaflet中实现数据聚合的功能 ,左边列出右边可视区域内的marker的名称。这里主要用到了可视区域的范围以及contains函数。 直接复制下面的 vue+leaflet源代码,操作2分钟即可运行实现效果 文章目录 示例效果配置方…...
XXL-JOB分布式任务调度框架(一)-基础入门
文章目录1.什么是任务调度2.常见定时任务方案2.1. 传统定时任务方案示例2.2. 缺点分析3.什么是分布式任务调度?3.1. 并行任务调度3.2. 高可用3.3. 弹性扩容3.4. 任务管理与监测4.市面上常见的分布式任务调度产品5.初识xxl-job6.xxl-job架构设计6.1.设计思想6.2.架构…...

基于CentOS 7 搭建Redis 7集群
我们的目标是使用2台(多台服务器类似)服务器搭建一个3主3从的redis集群。 我们为什么要使用redis 7呢?因为6、7的版本都做了大量优化,比如6引入了多线程(一些JAVA八股文面试还喜欢问redis为什么是单线程)&…...

Lesson5.3---Python 之 NumPy 统计函数、数据类型和文件操作
一、统计函数 NumPy 能方便地求出统计学常见的描述性统计量。最开始呢,我们还是先导入 numpy。 import numpy as np1. 求平均值 mean() mean() 是默认求出数组内所有元素的平均值。我们使用 np.arange(20).reshape((4,5)) 生成一个初始值默认为 0,终止…...
Puppeteer 爬虫学习
puppeteer简介: Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议 控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行, 但是可以通过修改配置文件运行“有头”模式。能作什么?: 生成…...
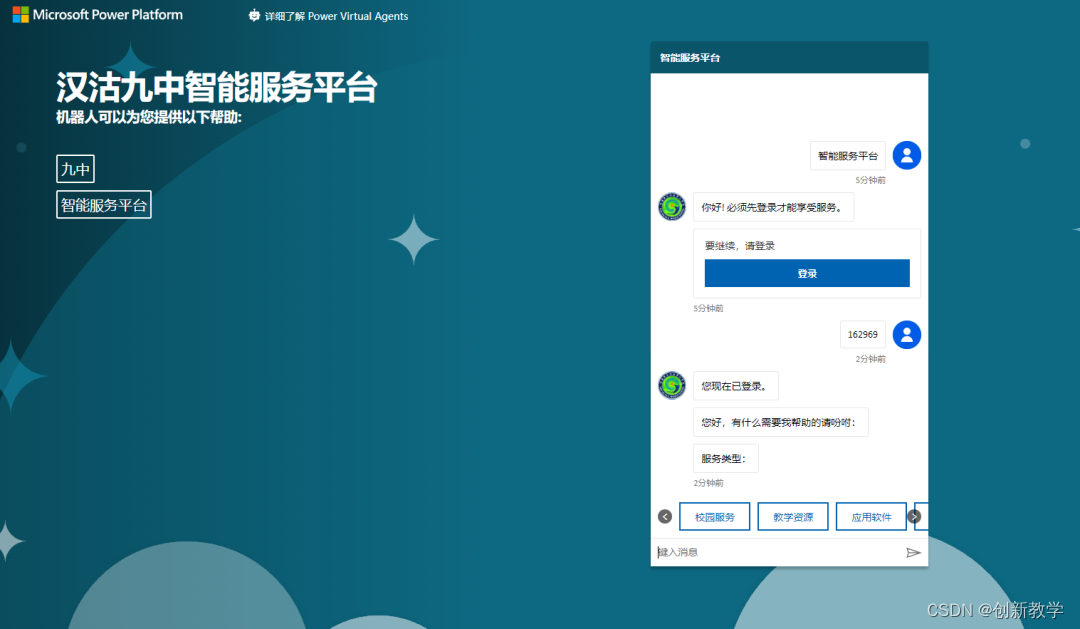
如何在Power Virtual Agents中实现身份验证
今天我们介绍一下如何通过身份验证的方式来使用Power Virtual Agents。首先进入“Microsoft 365-管理-Azure Active Directory管理中心”。 进入“Azure Active Directory管理中心”后选择“Azure Active Directory”中的“应用注册”-“新注册”。 输入新创建的应用程序名称后…...

金三银四必备软件测试必问面试题
初级软件测试必问面试题1、你的测试职业发展是什么?测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去。而且我也有初步的职业规划,前 3 年积累测试经验,按如何做好测试工程…...
Java反序列化漏洞——CommonsCollections6链分析
一、前因因为在jdk8u71之后的版本中,sun.reflect.annotation.AnnotationInvocationHandler#readObject的逻辑发生了变化,导致CC1中的两个链条都不能使用,所有我们需要找一个在高版本中也可用的链条。/* Gadget chain: java.io.ObjectInputStr…...

Selenium浏览器自动化测试框架
Selenium浏览器自动化测试框架 目录:导读 1、selenium简介 介绍 功能 优势 2、基本使用 3、获取单节点 4、获取多节点 5、节点交互 6、动作链 7、执行JavaScript代码 8、获取节点信息 9、切换frame 10、延时等待 11、前进和后退 12、cookies 13、选…...
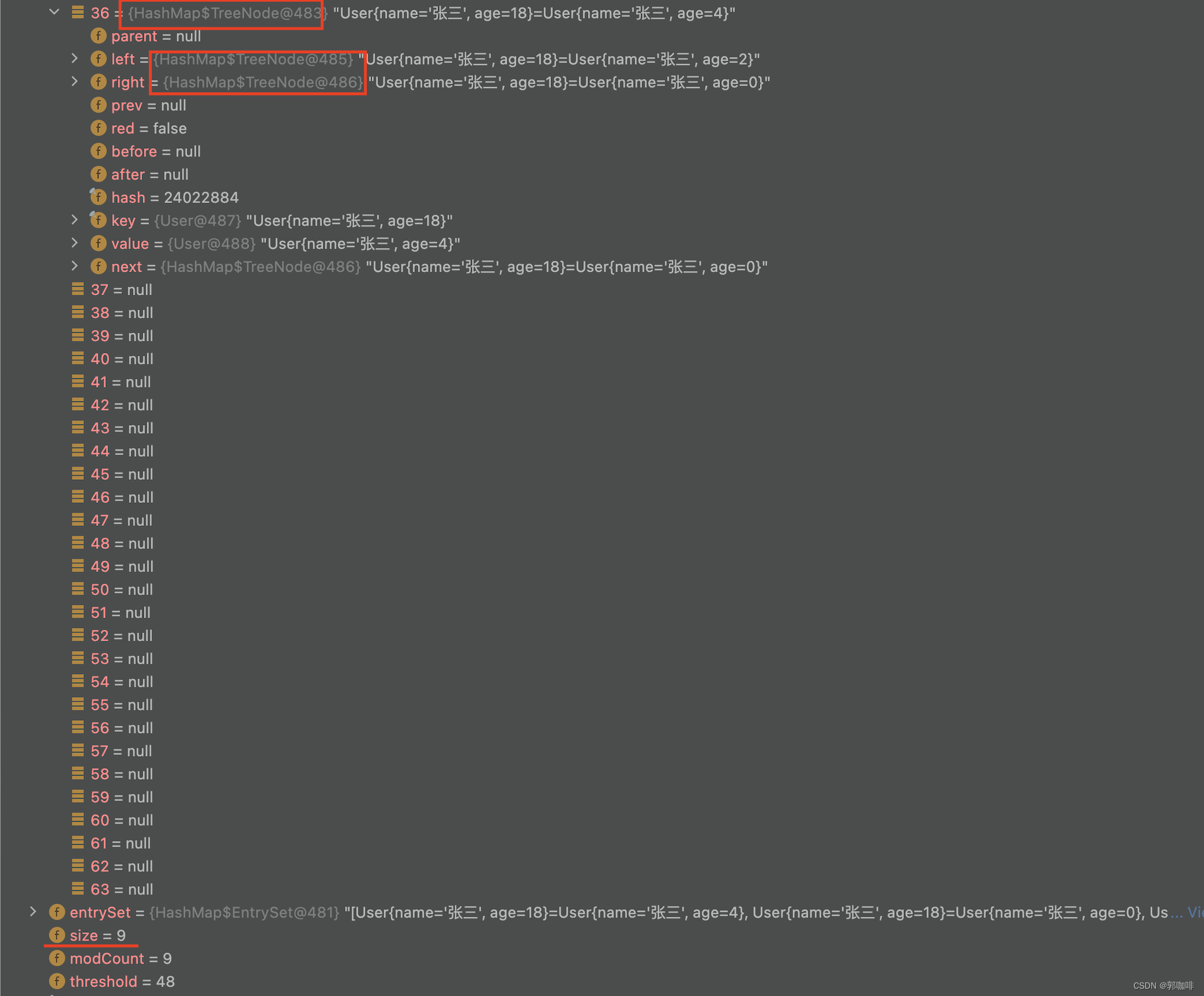
Hashmap链表长度大于8真的会变成红黑树吗?
1、本人博客《HashMap、HashSet底层原理分析》 2、本人博客《若debug时显示的Hashmap没有table、size等元素时,查看第19条》 结论 1、链表长度大于8时(插入第9条时),会触发树化(treeifyBin)方法,但是不一定会树化,若数组大小小于…...

关于接地:数字地、模拟地、信号地、交流地、直流地、屏蔽地、浮地
除了正确进行接地设计、安装,还要正确进行各种不同信号的接地处理。控制系统中,大致有以下几种地线: (1)数字地:也叫逻辑地,是各种开关量(数字量)信号的零电位。 (2&am…...

排序
一、数据流中的中位数题目描述:如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。…...
Android DataStore Proto存储接入流程详解与使用
一、介绍 通过前面的文字,我们已掌握了DataStore 的存储,但是留下一个尾巴,那就是Proto的接入。 Proto是什么? Protobuf,类似于json和xml,是一种序列化结构数据机制,可以用于数据通讯等场景&a…...

HiEV洞察 | 卖一台亏半台,激光雷达第一股禾赛隐忧仍在
作者 | 感知君Alex 编辑 | 王博2月9日晚,禾赛在万众瞩目下登陆纳斯达克,发行价19美元每股,首日涨超11%,市值超过Luminar,登顶全球市值最高的激光雷达公司。 随后两个交易日,其股价均有不同程度的涨幅&#…...
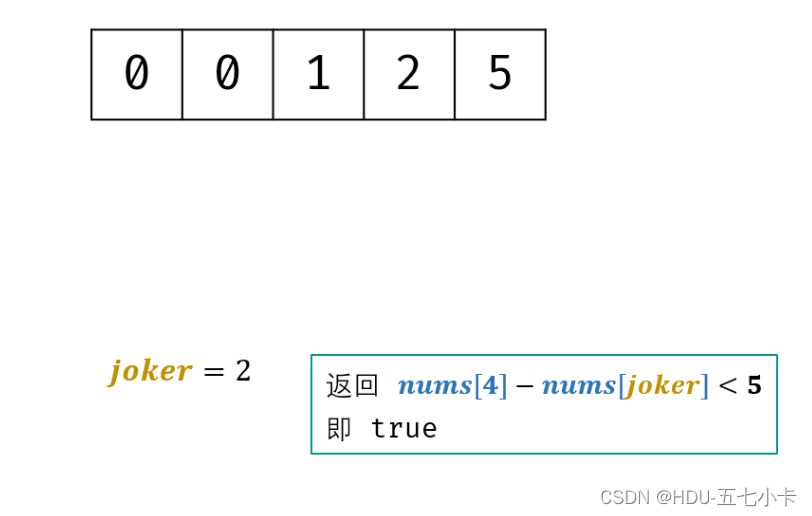
面试题61. 扑克牌中的顺子
题目 从若干副扑克牌中随机抽 5 张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视…...
有特别有创意的网站设计案例
有人说 UI 设计师集艺术性与科学性于一身,不仅需要对工具的使用熟练,更需要对美术艺术有一定的基础了解。如果想要成为优秀的 UI 设计师是一个需要磨砺的过程,需要不断的学习和积累,多看多练多感受,其中对于优质的设计…...

Python基础-数据类型之列表
一、列表的定义 name ["小明", "小红", "笑笑"] 二、列表的使用 除了序列中的操作,列表还有一些其他的操作。 (1)不使用列表方法对列表进行修改 1:通过索引修改列表中的值 name ["Kit…...

【Claude Code 源码解析教程】第33章:性能调优实战
本章深入解析 Claude Code 的性能优化策略,包括内存优化、响应速度优化、缓存策略和并发处理。性能优化是提升用户体验的关键。 目录 33.1 内存优化策略 33.1.1 慢操作监控 33.1.2 慢操作检测使用示例 33.1.3 内存管理策略 33.1.4 内存泄漏检测与修复 33.2 响应速度优化…...

D3KeyHelper:5个技巧让暗黑破坏神3操作效率翻倍的智能宏工具完全指南
D3KeyHelper:5个技巧让暗黑破坏神3操作效率翻倍的智能宏工具完全指南 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破…...

AI Agent沙箱环境部署指南:从Docker容器化到生产级运维
1. 项目概述:构建一个生产级的AI Agent沙箱环境最近在折腾一个挺有意思的项目,叫NemoClaw OpenClaw Sandbox。简单来说,它是一套完整的、开箱即用的部署方案,能帮你在自己的云服务器(VPS)上,快速…...

Ubuntu 24.04 + ROS2 Jazzy 开发环境避坑指南
️ 环境配置(仅需操作一次) 前提背景:Ubuntu 24.04 强制要求使用虚拟环境安装 pip 第三方库,而 ROS2 编译工具链(colcon, catkin_pkg)依赖系统全局 Python。为兼顾两者,需创建一个“能看见系统 …...

pip cache purge 清理下载缓存文件
如上图所示的这个目录是 Python 的包管理工具 pip 用来存储下载过的安装包(wheel 或源码包)的缓存。它的主要作用是在你下次安装同一个包时,可以直接从本地读取,而无需再次从网络下载,从而加快安装速度。 但是…...

UWB车内目标探测技术【附仿真】
✨ 长期致力于UWB雷达、活体、目标检测、生命体征、信号模型研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)UWB雷达生命体征信号建模与自适应杂波抑制…...

ARM PMU性能监控单元架构与PMEVTYPER寄存器详解
1. ARM PMU性能监控单元架构解析性能监控单元(Performance Monitoring Unit, PMU)是现代ARM处理器中用于硬件级性能分析的关键组件。作为芯片上的专用硬件计数器,PMU能够在不显著影响程序执行效率的前提下,实时捕获各类微架构事件。与软件层面的性能分析…...

终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽
终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 想为你的机械键盘打造一套独一无二的键帽吗?Cherr…...

新手避坑指南:用Simulink搭建48V开关电源仿真,从整流到反激电路完整流程
新手避坑指南:用Simulink搭建48V开关电源仿真全流程实战 电力电子领域的仿真实验常常让初学者望而生畏——参数设置不当可能导致虚拟元器件"烧毁",波形失真却找不到原因。本文将手把手带你用Simulink搭建从交流整流到DC-DC变换的完整48V电源系…...

如何用wxlivespy实现微信视频号直播数据实时抓取与分析
如何用wxlivespy实现微信视频号直播数据实时抓取与分析 【免费下载链接】wxlivespy 微信视频号直播间弹幕信息抓取工具 项目地址: https://gitcode.com/gh_mirrors/wx/wxlivespy wxlivespy是一款专业级的微信视频号直播间弹幕信息抓取工具,能够实时捕获弹幕、…...