【电网异物检测硕士论文摘抄记录】电力巡检图像中基于深度学习的异物检测方法研究
-
根据国家电力行业发展报告统计,截止到 2018 年,全国电网 35 千伏及以上的输电线路回路长度达到 189 万千米,220 千伏及以上输电线路回路长度达73 万千米。截止到 2015年,根据国家电网公司的统计 330 千伏及以上输电线路故障跳闸总数中外力破坏作为主要原因的事故占到了 15.8%,而其中由线上异物引发的事故占到外力破坏的55.4%。特别是一些异物的人眼辨识度不高,在颜色、形状和大小上非常接近输电线上的金具,更容易使得工作人员漏检,进而引发电力事故,或者加长了异物处理的周期。电网公司的巡检工作主要依靠人工完成,需要大量人力物力,且实时性较差。 湖北工业大学,范亚雷
-
通过网络进行特定样本的训练,使得计算机程序具有对某一类或某几类特征的高敏感度,进而替代人眼实现图像中某些指定目标的识别与定位。通过新型的巡检设备替代传统的人工徒步巡检方式,通过图像分类和检测技术来筛选并且定位架空输电线异物,从而保障电力系统的安全可靠平稳运行。输电线的断股、输电杆塔事故、绝缘子破裂、绝缘子掉串以及输电线异物等方向都可以归类作为输电线路关键部件故障的研究内容。
-
提出的图像形态学方式识别和检测异物的方法,其核心思路都是根据附着异物的输电线的形态特征,例如:线路区域的灰度值、线路区域的形状、线路区域的宽度等,与正常输电线有所区别,采取合适的办法提取并判断这些高区分度特征是否符合设定值来判断异物的存在。但是显而易见,这类异物检测方式往往依赖于巡检图像背景与前景的分离结果,作者凭借对图像处理任务的认知理解和先验知识,通过图片的纹理、颜色和灰度值来设计分离算法,然后对提取出的输电线路区域进行特征计算,从而确定异物是否存在。其检测结果受前景提取算法参数设定和异物特征计算结果的影响很大,这就导致了算法在一定程度上缺少泛化能力和在复杂背景下检测异物的能力。
-
采用的深度学习模型各有不同,但共同特点是测试数据集中的图像都是默认存在异物的图像,这就相当于在进行目标检测之前先人为分类了图像。事实上,巡检所返回的大量图像中无异物的线路图像占了大多数,因此文献中的实验与真实应用的场景存在差距。
-
2019 年,全国“两会”提出“三型两网,世界一流”的国家电网建设目标,其内涵是以建设枢纽型、平台型、共享型为特征,以坚强智能电网和泛在电力物联网为手段,打造世界一流能源互联网企业。用移动互联、人工智能等现代通信和信息技术对传统电力行业赋能。截止至 2019 年,南方电网已使用无人机作业超 50 万公里,已全面实现“机巡为主、人巡为辅”的协同巡检模式。目前,使用无人机进行线路巡检的主要挑战集中在自动驾驶、飞行时间和通信带宽等方面。
-
卷积核中的值叫做权重,输入图像的每个位置是被同一个卷积核扫描的,即卷积的时候所用的权重是一样的。这样对于每一个卷积核来说,需要训练的权值参数与卷积核扫过的位置无关,需要调整的参数也就被限制在一个卷积核大小的数量级内。图像识别的一般流程如下:获取图像数据→数据预处理→提取特征→确定特征量并进行匹配→输出识别结果
-
计算机视觉中,像素之间的相关性与像素之间的距离同样相关,可以理解为在图像中的某一块区域中,相关性强的像素间距离往往较近,相关性比较弱的像素间距离则较远。局部连接,即卷积层的节点仅仅与其前一层的部分节点相连接。在假设数量级为 1 0 5 10^5 105 的示例图像上,若采用全连接则最终的参数量级为 1 0 11 10^{11} 1011。而局部连接大大减少了参数的数量级,在10 × 10的卷积核上仅为 1 0 8 10^8 108 数量级。相比减少了 3 个数量级,使网络的计算速度更快。
-
深度学习方法优势的体现需要大量的训练数据作为支撑,缺乏合适的数据大概率会导致网络的过拟合,严重的还会造成网络无法收敛。对个人构建的数据集来说,数据量一般是无法达到公开数据集千万级别数据量规模的,针对数据匮乏的问题,需要对已有数据进行处理,从而实现扩大数据量的目的。图片亮度可以通过增减图像通道R、G、B的值来调节大小,值越大亮度越高。
-
L = R + B + G 3 b r i = k L = k ∗ R + B + G 3 L=\frac{R+B+G}{3}\\ bri=kL=k*\frac{R+B+G}{3} L=3R+B+Gbri=kL=k∗3R+B+G
-
其中,𝐿作为亮度变化系数,表示亮度的强弱。各通道按照一定规律统一增减即可改变图像的亮度。利用深度学习对摄像装置所采集的现场图像进行分析,执行目标检测任务,若发现威胁电网安全运行的隐患将及时通知工作人员。深度学习发挥其优势需要有效样本达到一定数量,包含隐患的真实样本较少,有些异物种类甚至没有合适的样本,往往不能满足深度学习算法的训练要求。扩充样本并不是简单的增加训练集的过程,训练集样本必须联系实际使用场景,才能够使训练所得模型的性能获得提升。盲目增加无关样本可能会使模型性能下降。
-
-
对于一个分类器来说,使用者更希望找到全部的分类目标,即TPR越高越好,但同时也不希望把分类目标以外的其他类别错分类,即FPR越低越好。综上可知,这两个指标存在着互相制约的关系。为了可以定量的分析一个分类器的好坏,引入曲线下面积(Area Under Curve, AUC)的概念,其被定义为ROC曲线下的面积。
-
接受者操作特性(Receiver Operating Characteristic, ROC)曲线就是将不同筛选阈值下的假阳性率和查全率交点绘制在同一个坐标系内所得到的曲线。ROC曲线的横坐标为假阳性率(False Positive Rate, FPR)。纵坐标为分类查全率,又称作真阳性率(True Positive Rate, TPR)。 AUC的值越大,当前的分类算法就越有可能对正样本进行排序,然后再对负样本进行排序,从而实现更好的分类。
-
T P R = T P c T P c + F N c F P R = F P c T P c + T N c A U C = ∫ 0 1 T P R d ( F P R ) TPR=\frac{TP_c}{TP_c+FN_c}\\ FPR=\frac{FP_c}{TP_c+TN_c}\\ AUC=\int_0^1TPRd(FPR) TPR=TPc+FNcTPcFPR=TPc+TNcFPcAUC=∫01TPRd(FPR)
-
其中,𝑇𝑃𝑐 表示分类样本中真阳性(True Positive),是分类器预测正确的正样本数。𝑇𝐹𝑐表示分类样本中真阴性(True Negative),是分类器预测正确的负样本数。𝐹𝑃𝑐表示分类样本中假阳性(False Positive),是分类器预测错误的负样本数。
-
-
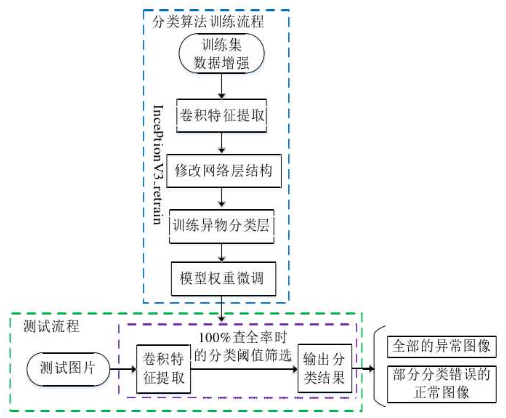
由于电力巡检任务的特殊性,输电线上异物的漏检危害比误检更大,因此本文侧重对分类器100%查全率指标的研究。本文选取InceptionV3-retrain模型作为输电线异物图像分类器的主要研究对象,其分类异物图像的总流程如下图所示。图中蓝色框的内容为算法的训练过程,本文通过训练集数据增强、修改网络结构和权重微调对模型进行训练。绿色框的内容为算法的测试流程。测试时,测试集中正常图像和异物图像共同作为分类器的输入,输出图像为全部的含有异物图像和部分分类错的正常图像。
-
在实际的巡检应用中,巡检图像承载着更为直观、丰富的巡检线路信息。红外影像和雷达成像等技术受环境影响较大,比如在停电情况下或者周围环境中存在其他电磁干扰与干扰热源时,其呈现的图像无法让工作人员直接判断现场情况,从而拖延事故处理速度。计算机视觉的核心之一是图像分类,特征描述及检测是其运用的普遍方式,对于一些简单的图像分类这类传统方法可能是有效的,但由于实际情况非常复杂,传统的分类方法不堪重负。卷积神经网络在经过大量数据训练后特征提取能力得到加强,目前主流的图像分类模型都是基于这种卷积结构。
-
输电线上异物检测作为智能电网和无人巡检系统中的重要组成部分,对于减少人力资源的浪费、提高巡线效率以及降低安全风险具有重要意义。基于深度学习的图像分类和目标检测技术在近年来取得了巨大的突破,但是该技术如何在输电线异物检测任务上进行运用仍是一个值得探索和研究的问题。
-
yolo数据集标注格式主要是 U版本[yolov5]项目需要用到。标签使用txt文本进行保存。yolo标注格式如下所示:
-
<object-class> <x> <y> <width> <height> # <object-class>:对象的标签索引 # x,y:目标的中心坐标,相对于图片的H和W做归一化。即x/W,y/H。 # width,height:目标(bbox)的宽和高,相对于图像的H和W做归一化。
-
-
VOC数据集由五个部分构成:JPEGImages,Annotations,ImageSets,SegmentationClass以及SegmentationObject.
-
JPEGImages:存放的是训练与测试的所有图片。
-
Annotations:里面存放的是每张图片打完标签所对应的XML文件。
-
ImageSets:ImageSets文件夹下本次讨论的只有Main文件夹,此文件夹中存放的主要又有四个文本文件test.txt、train.txt、trainval.txt、val.txt, 其中分别存放的是测试集图片的文件名、训练集图片的文件名、训练验证集图片的文件名、验证集图片的文件名。
-
SegmentationClass与SegmentationObject:存放的都是图片,且都是图像分割结果图,对目标检测任务来说没有用。class segmentation 标注出每一个像素的类别
-
object segmentation 标注出每一个像素属于哪一个物体。
-
-
voc数据集的标签主要以xml文件形式进行存放。xml文件的标注格式如下:
-
<annotation><folder>17</folder> # 图片所处文件夹<filename>77258.bmp</filename> # 图片名<path>~/frcnn-image/61/ADAS/image/frcnn-image/17/77258.bmp</path><source> #图片来源相关信息<database>Unknown</database> </source><size> #图片尺寸<width>640</width><height>480</height><depth>3</depth></size><segmented>0</segmented> #是否有分割label<object> 包含的物体<name>car</name> #物体类别<pose>Unspecified</pose> #物体的姿态<truncated>0</truncated> #物体是否被部分遮挡(>15%)<difficult>0</difficult> #是否为难以辨识的物体, 主要指要结体背景才能判断出类别的物体。虽有标注, 但一般忽略这类物体<bndbox> #物体的bound box<xmin>2</xmin> #左<ymin>156</ymin> #上<xmax>111</xmax> #右<ymax>259</ymax> #下</bndbox></object> </annotation>
-
-
自制VOC数据集,按照
VOC2007的数据集格式要求,分别创建文件夹VOCdevkit、VOC2007、Annotations、ImageSets、Main和JPEGImages,它们的层级结构如下所示-
└─VOCdevkit└─VOC2007├─Annotations├─ImageSets│ └─Main└─JPEGImages -
其中,
Annotations用来存放xml标注文件,JPEGImages用来存放图片文件,而ImageSets/Main存放几个txt文本文件,文件的内容是训练集、验证集和测试集中图片的名称(去掉扩展名),这几个文本文件是需要人为生成的。使用开源工具 [labelImg]对图片进行标注,导出的数据集格式为PASCAL VOC,待数据标注完成后,可以看到文件夹是下面这个样子的,标注文件xml和图片文件混在了一起。将images文件夹中的图片文件拷贝到JPEGImages文件夹中,将images文件中的xml标注文件拷贝到Annotations文件夹中。 -
接下来新建一个脚本,把它放在
VOCdevkit/VOC2007文件夹下 -
import os import random # 训练集和验证集的比例分配 trainval_percent = 0.1 train_percent = 0.9 # 标注文件的路径 xmlfilepath = 'Annotations' # 生成的txt文件存放路径 txtsavepath = 'ImageSets\Main' total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) ftrainval = open('ImageSets/Main/trainval.txt', 'w') ftest = open('ImageSets/Main/test.txt', 'w') ftrain = open('ImageSets/Main/train.txt', 'w') fval = open('ImageSets/Main/val.txt', 'w') for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftest.write(name)else:fval.write(name)else:ftrain.write(name)ftrainval.close() ftrain.close() fval.close() ftest.close() -
将需要训练、验证、测试的图片绝对路径写到对应的
txt文件中 -
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join # 原始脚本中包含了VOC2012,这里,把它删除 # sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')] sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] # classes也需要根据自己的实际情况修改 # classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] classes = ["class_one"] def convert(size, box):dw = 1./size[0]dh = 1./size[1]x = (box[0] + box[1])/2.0y = (box[2] + box[3])/2.0w = box[1] - box[0]h = box[3] - box[2]x = x*dww = w*dwy = y*dhh = h*dhreturn (x,y,w,h) def convert_annotation(year, image_id):in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')tree=ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))bb = convert((w,h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() for year, image_set in sets:if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):os.makedirs('VOCdevkit/VOC%s/labels/'%(year))image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()list_file = open('%s_%s.txt'%(year, image_set), 'w')for image_id in image_ids:list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))convert_annotation(year, image_id)list_file.close()
-
-
执行上述脚本后,在
VOCdevkit同级目录就会生成2007_train.txt、2007_val.txt、2007_test.txt。 -
准备转换脚本
voc2yolo.py,部分注释写在代码里.(将所有图片存放在images文件夹,xml标注文件放在Annotations文件夹,然后创建一个文件夹labels) -
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join # 根据自己情况修改 classes = ["class_one"] def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h) def convert_annotation(image_id):if not os.path.exists('Annotations/%s.xml' % (image_id)):returnin_file = open('annotations/%s.xml' % (image_id))out_file = open('labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') for image in os.listdir('images'):# 这里需要根据图片情况进行对应修改。比如图片名称是123.456.jpg,这里就会出错了。一般来讲,如果图片格式固定,如全都是jpg,那就image_id=image[:-4]处理就好了。总之,情况比较多,自己看着办,哈哈!image_id = image.split('.')[0]convert_annotation(image_id) -
执行上述脚本后,
labels文件夹就会生成txt格式的标注文件了,yolov5训练时使用的数据集结构是这样的 -
├─test │ ├─images │ └─labels ├─train │ ├─images │ └─labels └─valid├─images└─labels -
因此,还需要将图片文件和对应的
txt标签文件再进行一次划分,首先创建外层的train、valid、test文件夹,然后在每个文件夹底下都分别创建images和labels文件夹.接下来,可以使用下面的脚本,将图片和标签文件按照比例进行划分 -
import os import shutil import random # 训练集、验证集和测试集的比例分配 test_percent = 0.1 valid_percent = 0.2 train_percent = 0.7 # 标注文件的路径 image_path = 'images' label_path = 'labels' images_files_list = os.listdir(image_path) labels_files_list = os.listdir(label_path) print('images files: {}'.format(images_files_list)) print('labels files: {}'.format(labels_files_list)) total_num = len(images_files_list) print('total_num: {}'.format(total_num)) test_num = int(total_num * test_percent) valid_num = int(total_num * valid_percent) train_num = int(total_num * train_percent) # 对应文件的索引 test_image_index = random.sample(range(total_num), test_num) valid_image_index = random.sample(range(total_num), valid_num) train_image_index = random.sample(range(total_num), train_num) for i in range(total_num):print('src image: {}, i={}'.format(images_files_list[i], i))if i in test_image_index:# 将图片和标签文件拷贝到对应文件夹下shutil.copyfile('images/{}'.format(images_files_list[i]), 'test/images/{}'.format(images_files_list[i]))shutil.copyfile('labels/{}'.format(labels_files_list[i]), 'test/labels/{}'.format(labels_files_list[i]))elif i in valid_image_index:shutil.copyfile('images/{}'.format(images_files_list[i]), 'valid/images/{}'.format(images_files_list[i]))shutil.copyfile('labels/{}'.format(labels_files_list[i]), 'valid/labels/{}'.format(labels_files_list[i]))else:shutil.copyfile('images/{}'.format(images_files_list[i]), 'train/images/{}'.format(images_files_list[i]))shutil.copyfile('labels/{}'.format(labels_files_list[i]), 'train/labels/{}'.format(labels_files_list[i])) -
执行代码后,可以看到类似文件层级结构
-
─test │ ├─images │ │ aaa.jpg │ │ bbb.jpg │ │ │ └─labels │ aaa.txt │ bbb.txt │ ├─train │ ├─images │ │ xxx.jpg │ │ │ └─labels │ xxx.txt │ └─valid├─images│ 111.jpg│└─labels111.txt -
如果拿到了
txt的标注,但是需要使用VOC,也需要进行转换。看下面这个脚本,注释写在代码中 -
import os import xml.etree.ElementTree as ET from PIL import Image import numpy as np # 图片文件夹,后面的/不能省 img_path = 'images/' # txt文件夹,后面的/不能省 labels_path = 'labels/' # xml存放的文件夹,后面的/不能省 annotations_path = 'Annotations/' labels = os.listdir(labels_path) # 类别 classes = ["class_one"] # 图片的高度、宽度、深度 sh = sw = sd = 0 def write_xml(imgname, sw, sh, sd, filepath, labeldicts):'''imgname: 没有扩展名的图片名称'''# 创建Annotation根节点root = ET.Element('Annotation')# 创建filename子节点,无扩展名 ET.SubElement(root, 'filename').text = str(imgname) # 创建size子节点 sizes = ET.SubElement(root,'size') ET.SubElement(sizes, 'width').text = str(sw)ET.SubElement(sizes, 'height').text = str(sh)ET.SubElement(sizes, 'depth').text = str(sd) for labeldict in labeldicts:objects = ET.SubElement(root, 'object') ET.SubElement(objects, 'name').text = labeldict['name']ET.SubElement(objects, 'pose').text = 'Unspecified'ET.SubElement(objects, 'truncated').text = '0'ET.SubElement(objects, 'difficult').text = '0'bndbox = ET.SubElement(objects,'bndbox')ET.SubElement(bndbox, 'xmin').text = str(int(labeldict['xmin']))ET.SubElement(bndbox, 'ymin').text = str(int(labeldict['ymin']))ET.SubElement(bndbox, 'xmax').text = str(int(labeldict['xmax']))ET.SubElement(bndbox, 'ymax').text = str(int(labeldict['ymax']))tree = ET.ElementTree(root)tree.write(filepath, encoding='utf-8') for label in labels:with open(labels_path + label, 'r') as f:img_id = os.path.splitext(label)[0]contents = f.readlines()labeldicts = []for content in contents:# 这里要看图片格式了,这里是jpg,注意修改img = np.array(Image.open(img_path + label.strip('.txt') + '.jpg'))# 图片的高度和宽度sh, sw, sd = img.shape[0], img.shape[1], img.shape[2]content = content.strip('\n').split()x = float(content[1])*swy = float(content[2])*shw = float(content[3])*swh = float(content[4])*sh# 坐标的转换,x_center y_center width height -> xmin ymin xmax ymaxnew_dict = {'name': classes[int(content[0])],'difficult': '0','xmin': x+1-w/2, 'ymin': y+1-h/2,'xmax': x+1+w/2,'ymax': y+1+h/2}labeldicts.append(new_dict)write_xml(img_id, sw, sh, sd, annotations_path + label.strip('.txt') + '.xml', labeldicts)
相关文章:
【电网异物检测硕士论文摘抄记录】电力巡检图像中基于深度学习的异物检测方法研究
根据国家电力行业发展报告统计,截止到 2018 年,全国电网 35 千伏及以上的输电线路回路长度达到 189 万千米,220 千伏及以上输电线路回路长度达73 万千米。截止到 2015年,根据国家电网公司的统计 330 千伏及以上输电线路故障跳闸总…...
C++共享数据的保护
虽然数据隐藏保护了数据的安全性,但各种形式的数据共享却又不同程度地破坏了数据的安全。因此,对于既需要共享有需要防止改变的数据应该声明为常量。因为常量在程序运行期间不可改变,所以可以有效保护数据。 1.常对象 常对象:它…...

MyBatisPlus学习记录
MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在简化开发、提高效率 MyBatisPlus简介 入门案例 创建新模块,选择Spring初始化,并配置模块相关基础信息选择当前模块需要使用的技术集(仅选择MySQL …...
如何开启一个java微服务工程
安装idea IDEA常用配置和插件(包括导入导出) https://blog.csdn.net/qq_38586496/article/details/109382560安装配置maven 导入source创建项目 修改项目编码utf-8 File->Settings->Editor->File Encodings 修改项目的jdk maven import引入…...

libhv之hio_t分析
上一篇文章解析了fd是怎么与io模型关联。其中最主要的角色扮演者:hio_t 1. hio_t与hloop的关系 fd的值即hio_t所在loop ios变量中所在的index值。 hio_t ios[fd] struct hloop_s { ...// ios: with fd as array.index//io_array保存了和hloop关联的所有hio_t&…...
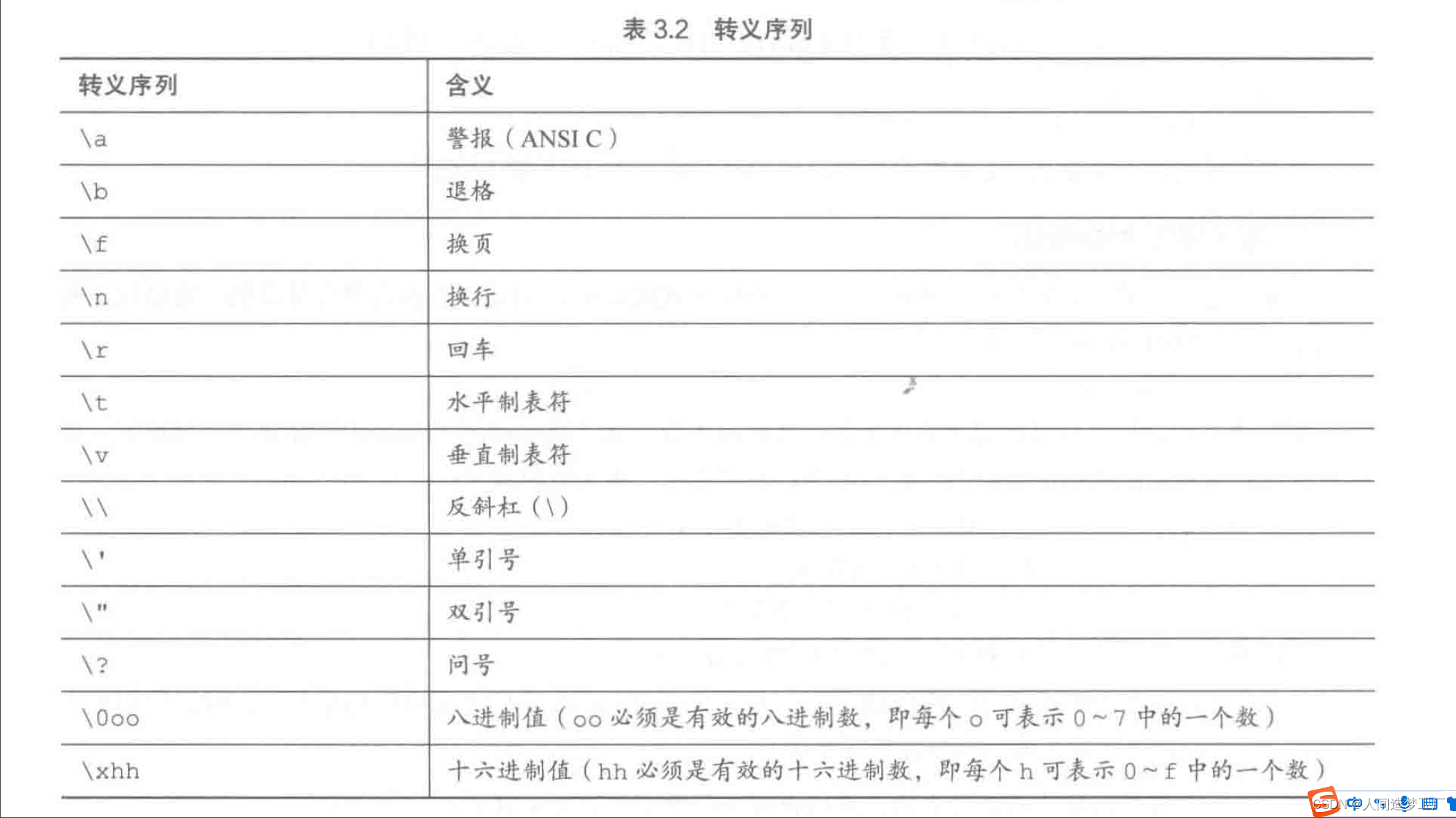
C语言的转义字符
转义字符也叫转移序列,包含如下: 转移序列 \0oo 和 \xhh 是 ASCII 码的特殊表示。 八进制数示例: 代码: #include<stdio.h> int main(void) {char beep\007;printf("%c\n",beep);return 0; }结果: …...
【腾讯云 Cloud Studio 实战训练营】CloudStudio体验真正的现代化开发方式,双手插兜不知道什么叫对手!
CloudStudio体验真正的现代化开发方式,双手插兜不知道什么叫对手! 文章目录 CloudStudio体验真正的现代化开发方式,双手插兜不知道什么叫对手!前言出现的背景一、CloudStudio 是什么?二、CloudStudio 的特点三、CloudS…...
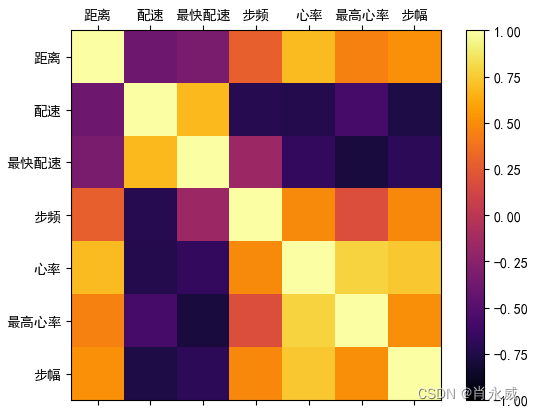
Pandas时序数据分析实践—时序数据集
1. 跑步运动为例,对运动进行时序分析 时序数据是指时间序列数据,是按照时间顺序排列的数据集合,每个数据点都与一个特定的时间戳相关联。在跑步活动中,我们可以将每次跑步的数据记录作为一个时序数据样本,每个样本都包…...

use strict 是什么意思?使用它区别是什么?
use strict 是什么意思?使用它区别是什么? use strict 代表开启严格模式,这种模式下使得 JavaScript 在更严格的条件下运行,实行更严格解析和错误处理。 开启“严格模式”的优点: 消除 JavaScript 语法的一些不合理…...
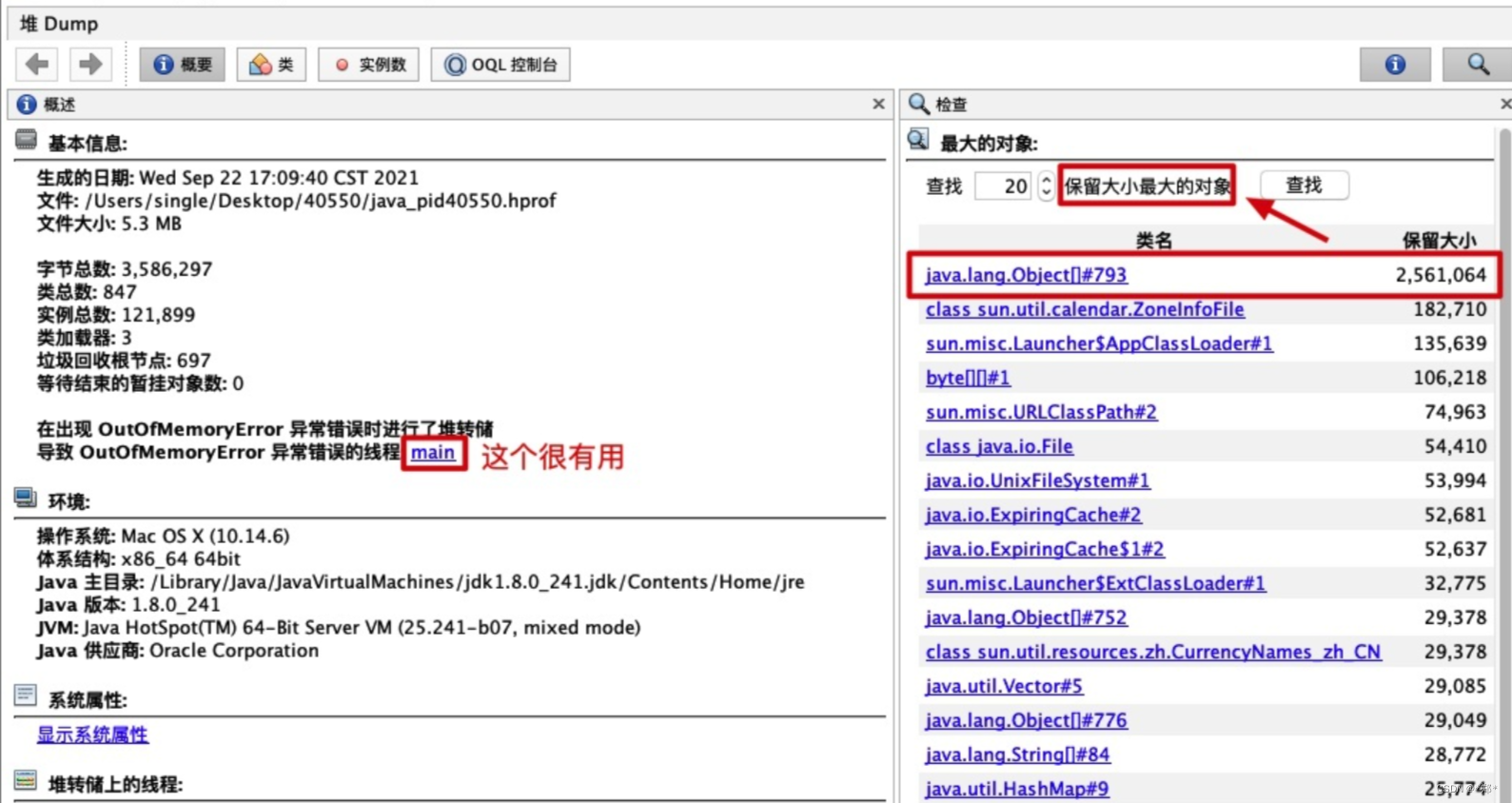
常见OOM异常分析排查
常见OOM异常分析排查 Java内存溢出Java堆溢出原因解决思路总结 Java内存溢出 java堆用于存储对象实例,如果不断地创建对象,并且保证GC Root到对象之间有可达路径,垃圾回收机制就不会清理这些对象,对象数量达到最大堆的容量限制后就会产生内存溢出异常. Java堆溢出原因 无法在…...

kubernetes网络之网络策略-Network Policies
Kubernetes 中,Network Policy(网络策略)定义了一组 Pod 是否允许相互通信,或者与网络中的其他端点 endpoint 通信。 NetworkPolicy 对象使用标签选择Pod,并定义规则指定选中的Pod可以执行什么样的网络通信࿰…...
交换机VLAN技术和实验(eNSP)
目录 一,交换机的演变 1.1,最小网络单元 1.2,中继器(物理层) 1.3,集线器(物理层) 1.4,网桥(数据链路层) 二,交换机的工作行为 2.…...
8.Winform界面打包成DLL提供给其他的项目使用
背景 希望集成一个Winform的框架,提供权限菜单,根据权限出现各个Winform子系统的菜单界面。不希望把所有的界面都放放在同一个解决方案下面。用各个子系统建立不同的解决方案,建立代码仓库,进行管理。 实现方式 将Winform的UI界…...

海量数据存储组件Hbase
hdfs hbase NoSQL数据库 支持海量数据的增删改查 基于Rowkey查询效率特别高 kudu 介于hdfs和hbase之间 hbase依赖hadoopzookeeper,同时整合框架phoenix(擅长读写),hive(分析数据) k,v 储存结构 稀疏的(为空的不存…...
(一)基于Spring Reactor框架响应式异步编程|道法术器
在执行程序时: 通常为了提供性能,处理器和编译器常常会对指令进行重排序。 从排序分为编译器重排序和处理器重排序两种 * (1)编译器重排序: 编译器保证不改变单线程执行结构的前提下,可以调整多线程语句执行顺序; * (2)处理器重排序: 如果不存在数据依赖…...

Vue3 让localstorage变响应式
Hook使用方式: import {useLocalStore} from "../js/hooks"const aauseLocalStore("aa",1) 需求一: 通过window.localStorage.setItem可以更改本地存储是,还可以更新aa的值 window.localStorage.setItem("aa&quo…...
【深度学习】InST,Inversion-Based Style Transfer with Diffusion Models,论文,风格迁移,实战
代码:https://github.com/zyxElsa/InST 论文:https://arxiv.org/abs/2211.13203 文章目录 AbstractIntroductionRelated WorkImage style transferText-to-image synthesisInversion of diffusion models MethodOverview ExperimentsComparison with Sty…...

【CSS】3D卡片效果
效果 index.html <!DOCTYPE html> <html><head><title> Document </title><link type"text/css" rel"styleSheet" href"index.css" /></head><body><div class"card"><img…...

OrderApplication
目录 1 OrderApplication 2 /// 查询订单 2.1.1 //补充商品单位 2.1.2 //补充门店名称 2.1.3 //补充门店名称 2.1.4 //订单售后 2.1.5 //订单项售后 OrderApplication...

如何在保健品行业运用IPD?
保健品是指能调节机体功能,不以治疗为目的,并且对人体不产生任何急性、亚急性或者慢性危害的产品。保健品是食品的一个种类,具有一般食品的共性,其含有一定量的功效成分,能调节人体的机能,具有特定的功效&a…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南
WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

AI算法工程师如何进行数据预处理?这5个步骤让你的数据更优质
在AI模型开发与测试的全流程中,数据质量直接决定了最终模型的效果上限——哪怕是最先进的大语言模型,用劣质数据训练出来也只能输出劣质结果。对于软件测试从业者来说,不管是参与AI模型的功能测试、性能测试,还是负责测试数据集的…...

Midjourney V6锐化失控?3步诊断+5组--sref/--stylize协同参数公式,立竿见影修复模糊与锯齿
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6锐化失控的本质归因 Midjourney V6 引入的全新扩散架构与隐式细节增强机制,导致图像生成过程中高频纹理被过度强化,其根本原因并非参数误配,而是模型在…...

量子机器学习多编码框架MEDQ:提升模型泛化能力与参数效率
1. 项目概述:为什么量子机器学习需要“多编码”?量子机器学习(QML)这几年火得不行,但真正上手做过的人都知道,它有个挺让人头疼的“怪病”:模型在某些数据集上表现神勇,换到另一个看…...