构建易于运维的 AI 训练平台:存储选型与最佳实践
伴随着公司业务的发展,数据量持续增长,存储平台面临新的挑战:大图片的高吞吐、超分辨率场景下数千万小文件的 IOPS 问题、运维复杂等问题。除了这些技术难题,我们基础团队的人员也比较紧张,负责存储层运维的仅有 1 名同事,因而组件的易用性,一直也是我们评估的重要维度。
我们尝试过文件系统包括有 NFS、GlusterFS、Lustre 和 CephFS,最终选择了JuiceFS。在这个案例中,我们将为大家介绍工业 AI 平台的存储层的挑战有哪些、 JuiceFS 的应用场景、大规模数据场景为什么使用 SeaweedFS?以及 JuiceFS CSI Driver 使用中遇到的问题。希望这些分享能给社区用户提供一些选型和运维方面的参考。
01 AI 训练平台的存储挑战
思谋科技的业务主要面向工业场景,涵盖工业质检、智能制造和流程优化等领域。我们的团队主要负责 AI 平台的训练场景,并为所有业务线提供训练平台支持。我们管理整个公司的 GPU 训练集群。平台中处理的数据有如下特点:
-
单个项目的数据量很小,缓存收益高,优选带缓存的文件系统。在工业场景中,与人脸识别或自然语言处理等场景相比,数据量小。一个客户可能只提供了几百张图像,我们需要利用这些图像来迭代出模型。项目图片少,就有利于我们做本地缓存,所以支持本地缓存的文件系统 JuiceFS,BeeGFS 等,在我们的首要选择列表里。
-
图像大小没有统一的规格,大小文件均存在。由于我们处于工业场景,不同的工厂、产线与相机产生的图片是千差万别的。例如,我们使用线扫描相机收集的图片、或者 BMP 格式的图像大小很大,几百MB甚至GB,而其他相机拍摄的视频或照片可能只有几k大小。所以我们既要面临大文件的吞吐问题,还要面临海量小文件的 IOPS 问题。
-
数据量与文件数增长速度非常快,元数据压力大。我们曾与产品经理进行容量预估,发现一个项目在短短一周内就需要处理几十T的数据务。另一个场景,超分辨率领域的数据集具有一个典型的特点,即将视频转化为图片。因此一个视频可能会生成上百万、上千万个文件,文件个数非常大。文件个数对于文件系统元数据压力也很大。因此,我们训练平台对存储平台的容量,以及元数据长时间临界状态的稳定性有很高的要求。
-
同时,由于我们是自建IDC,没有使用云,所以存储系统运维与扩容是否便捷,也是我们的首要考虑点。
02 存储选型:不只是功能与性能
为了解决上述问题,我们对一些文件系统进行了评估,包括 NFS、GlusterFS、Lustre 和 CephFS 等,最终选择了 JuiceFS。由于我们团队成员较少且需要快速支持业务上线,我们并没有足够的时间进行选型验证和上线周期的评估,我们对于新组件的测试和上线需要更高效快捷。
当进行产品选型时,不仅需要评估功能和性能,还需要考虑中长期成本、与业务方的沟通等因素,是一个很综合的复杂任务,因此,我们总结了一些选型经验和教训与大家分享:
-
首先是成本、可靠性和性能之间的权衡。除非公司有充足的资金,否则只能在成本、可靠性和性能之间尽可能满足其中两个因素,而不可能同时满足三个。在成本受限的情况下,我们建议将数据安全性放在高于性能的位置。
通过维护多个集群的经验,我们得出一个观点:性能达到可接受水平即可,不必追求过高的性能。我们对存储总体拥有成本(TCO)的理解是,并非只涉及购买容量和性能方面的价格,而是指越接近资源利用上限的使用,实际持有成本越低。花了大价钱,买了很高的性能,但是却用不上,其实也是一种浪费。
-
第二点,要尽早让内部的用户接入,因为技术和业务工程师之间存在信息差。举个例子,我们在上线第一套存储系统后遇到了大量用户的投诉。我们最初简单地理解离线训练任务,无论是训练任务还是处理大数据,都是为了实现高利用率和高吞吐。然而,实际情况是用户非常敏感于延迟。任务完成时间,可以参考网易云音乐AI 的这篇: 《网易云音乐机器学习平台实践》 。因此,我们建议需要尽早与用户沟通,了解他们的需求和反馈,以弥补这种信息差。
-
第三点做好平台一致性,不光是环境一致性,做好也要做到任务运行的一致性。举一个具体例子,大型图片任务在网络上占用了大部分带宽(大象流),从而影响了小型图片任务的完成时间。即使是相同配置的机器,小图片任务完成的时间也会加倍。用户会抱怨为什么在另一台机器上只需要3个小时,而在这台机器上需要6个小时。因此,最好对每个任务都进行 QOS 等机制的限制,以防止出现该种情况,对用户造成使用困扰。
-
除了以上三个要点外,还有一些小的注意事项。选择具备丰富配套工具和良好集成生态的产品,而不仅仅看文档的数量。我们测试了许多商业存储,但发现它们的文档与其版本也有不匹配的现象。因此,我们更倾向于选择周边工具多的产品,例如Debug工具,监控工具等,因为相比依赖于他人,自己掌握更为可靠。我们选择 JuiceFS 的原因之一是它是少数带有性能调试工具的文件系统——JuiceFS stats 与access log 功能。此外,JuiceFS 还对接了持续剖析平台 Pyroscope,提供持续查看垃圾回收时间以及占用内存较大的块的功能,这可能是许多人不常使用但非常实用的功能。
-
与用户进行沟通时,使用对方易懂的“用户语言”而非 “技术语言”。在我们交付产品时,我们提到在 IO Size 256k 的情况下,我们可以实现每秒 5GB 的带宽,跑满了网卡上限。然而,实际情况是算法用户并不清楚这个概念。当时我们不知道如何向用户解释。后来,是JuiceFS社区的一篇博客文章:《如何借助 JuiceFS 将 AI 模型训练速度提升 7 倍》,给我们带来了启发。在这篇博客中展示了在 JuiceFS 上使用 ResNet50 模型和 ImageNet 数据集进行训练的完成时间,并与其他文件系统进行了对比。这样的比较,让算法用户更容易理解和评估 JuiceFS 的性能。随后,我们告诉了用户我们新存储平台上,ResNet 50 配合 ImageNet 训练的一些数据。在我们提供了这个对比数据后,我们与内部用户的沟通变得非常顺利,因为算法同学也希望能够加速训练过程。更短的训练时长使他们能够调整更多参数、进行更多的尝试并生成更好的模型。
-
对于一个大平台,很难在测试场景下模拟所以的使用场景。我们需要先完成,再不断完善。例如上线后,我们发现用户的使用方式并不完全符合我们的预期,他们不仅仅存储数据集,还将anacond等环境安装在存储系统上。这些库都是小文件,而是对时延要求特别高,如果没有缓存到本地,运行性能是无法接受的。而这种场景,在我们测试过程中,是不会考虑到用户会将环境安装到存储里,因为在我们的思维里,大部分的环境都应该使用容器镜像。所以,一定要尽早的扩大测试范围,让更多的用户参与测试与实际使用,这样才能暴露更多的问题。
-
关于全内存元数据存储:如果元数据过大,意味着这台机器很可能无法完成混部。机器的持有成本非常高,同时一定要测试长时间临界状态下的稳定性。
03 为什么使用 SeaweedFS 作为 JuiceFS 的底层存储
在我们的存储层中,SeaweedFS 也是一个必不可少的重要组件,并且在以往的社区分享中,对于 SeaweedFS 的介绍比较少,因此在介绍 JuiceFS 的应用场景前,我们需要一些篇幅来介绍为什么会引入 SeaweedFS。
-
原因一:我们团队没有人具备 Ceph 背景。不同于一些社区案例,如中国电信选择的 ceph (电信案例:JuiceFS 在中国电信日均 PB 级数据场景的应用)。
-
原因二,当文件数量过亿,原有 MinIO + JuiceFS 出现性能下降。我们是在 2021 年开始使用 JuiceFS,当时底层使用的是 Miinio。但是在海量文件的情况下,在XFS 文件系统文件数量超过一亿时,性能开始下降,已经达不到新集群时的水平。我们进行了测试,至少有 30% 的性能损失。
-
第三点:我们需要一个简单的架构。当时团队只有不到10个人,需要支持各种项目与任务。因此,我们希望有一个简单的架构,以便我们进行运维工作,对于我们小团队来说,简单意味着安全感。我们测试了很多开源和商业存储方案,最终选择了 SeaweedFS。
关于 SeaweedFS是高性能分布式存储系统,用于存储块、对象、文件和数据湖,可制成数十亿文件。
-
选择 SeaweedFS,因为它各项功能都可以通过一个简单的命令启动。对于我们的团队来说,它没有屏蔽一些部署、架构等细节,同时我们的开发同学也能对其进行一些修改工作。
-
第二点, SeaweedFS 是类 Haystack 架构,它将随机写操作聚合成顺序写操作,具有对硬盘友好的特性。虽然现在 HDD 和 SSD 的价格差距不大,但该架构是在 2021 年完成的,当时因为炒币,硬盘价格处于高点。
-
第三点 Haystack 架构支持小文件合并。合并后的小文件不再受文件数量的限制,不会遇到像 MinIO 那样写入越多性能越差的情况。实际上,MinIO 对小文件有“负面优化”,将小文件拆分为数据文件和元数据文件。在这种情况下,如果再进行EC(纠删码),文件会被进一步拆分。因此,对于大量小文件的使用场景,我们不推荐使用 MinIO。
-
第四点,SeaweedFS 支持 S3 接入。支持S3就可以很方便的对接JuiceFS,我们当时看了很多案例博客,主要有两篇文章。一篇是 《同城旅行的对象存储》,他们就是改了 SeaweedFS ,给了我们一些信心。以及《京东登月平台》当时使用的小文件存储选择也是 SeaweedFS。
SeaweedFS 的一些不足之处是资料相对较少,文档不太丰富。如果想了解某些功能,需要直接查看源代码。另外,社区的维护相对薄弱,边缘功能存在一些使用问题。在我们的实际应用中,我们发现只有 IO 功能才能正常使用,例如副本机制是可行的,但副本转 EC 的机制无法正常的使用,目前还在持续研究中。另一个问题是多机房同步,想测试多机房同步与备份,在我们的测试中花费了很长时间也无法使其正常工作。此外,它还有冷热数据转换功能,我们也无法成功测试。这可能是由于我们的对其的了解有限,我们仍在努力解决这些问题。
我们在选择 SeaweedFS 时权衡了其优点和缺点。总而言之,在进行架构选型时不要过早下结论,尽可能推迟做出选择的时间,多做场景测试,多做小范围灰度测试,以便全面评估和考虑各种因素。做决定的时候,多考虑大局,不要局限于几个文件系统,而要考虑选择某个文件系统后,对团队后续的规划与建设是否有影响等。
04 JuiceFS 在思谋的使用场景
-
第一个场景:小容量存储,总容量仅为百万到千万文件,百TB级。在这种情况下,使用 SSD 的成本并不高, 所以我们采用了 Redis + MinIO(SSD) + JuiceFS。结合 MinIO 和 Redis,你会发现它非常好用,而且日常无需太多关注。我们使用的是单点的 Redis,稳定运行了一年多,从未发生过大型宕机,只要进行好内存监控即可,同时控制好文件个数。
-
第二个场景:大容量存储,数据规模达到 PB 级。这时候就会面临成本压力,我们必须选择 HDD。我们选择了 SeaweedFS(HDD) + TiKV+ JuiceFS 作为该场景下的解决方案。
-
第三,多套小集群管理。每个用户都部署了一套JuiceFS,但底层都是使用同一个SeaweedFS。我们当时选择这种方案有两个原因。首先是出于历史原因。我们从 JuiceFS v0.17 开始使用时,当时它并不支持目录限额功能。因此,一些算法工程师占用了大量的目录空间。我们需要限制目录限额,但等待功能更新或自己开发限额功能并不切实际。我们的团队主要负责云原生调度,并没有开发存储系统的经验。
因此,我们想出了一个解决办法,管理多套小集群。我们采用了基于一个 TiKV 和一个 SeaweedFS 的模式,为每个用户提供独立的元数据前缀,并管理多套小集群。这种做法有一个好处,在维护集群时,如果 TiKV 规模足够大,即使其中一半宕机也不会有太大影响。当进行用户 JuiceFS 维护时,实际上不会影响其他用户,但众多的文件系统数量,让这种做法的管理过程比较繁琐。
这种使用方式也给我们带来了一些问题,因为每个用户都拥有一个 JuiceFS 目录,所以在挂载 CSI 时,每个 Pod 都有自己的 CSI。而在容器场景下,容器的密度比物理机和虚拟机场景更高。
随着容器数量的不断增加,重客户端文件系统(JuiceFS 是一个典型的重客户端文件系统,所有逻辑都由客户端处理。)与工作负载之间就会争夺有限的资源(内存),这在我们集群已经成为常态问题。内存是无法压缩的资源,所以内存争抢问题可能导致客户投诉——为什么相同的代码在集群的 A 节点上可以运行,而在 B 节点上却会崩溃?用户会质疑为什么无法集群实现的环境一致性等诸多问题。去查看就会发现是 OOM(内存耗尽)的问题,因为 B 节点的资源竞争更为激烈。目前,我们还没有找到一个很好的解决方案。
在使用中,要注意不同存储组件在 Kubernetes 上的适配性。MinIO + Redis 在 Kubernetes上的适配性非常好,而 SeaweedFS + TiKV在 Kubernetes上的适配性就不太理想。目前,我们还没有找到一个很好的方法将 TiKV 部署在 Kubernetes 中,因为涉及到的事务较多且管理上有些宽泛。我们曾尝试使用 TiDB Operator 来部署 TiKV,但尝试后发现存在k8s版本不适配等许多小问题。
05 一些运维实践心得
存储组件
首先,Redis 和 TiKV 在非临界状态下的延迟几乎相当。如果没有进行测量,很难看出它们之间的性能差异。在 AI 场景中,当读取操作比写入操作多时,像元数据的 mkdir 和 rename 等操作的性能差距可能非常大,因为需要上锁。但在实际读多写少的场景中,我们在监控中发现 Redis 和 TiKV 的性能实际上差不多。
其次,有时我们需要根据情况做出选择和判断。Redis 的运维相对简单,但存在冗余度和高可用性风险。如果公司对 SLA 卡特别严格,实际上使用 TiKV 可能更合适,因为 Redis 并不是解决这个问题的最佳方案。
第三点,关于 TiKV 的文档。尽管 TiKV 是一个非常 Nice 的开源项目,但其文档也相对较少。文档与 TiDB 官网是一起的,官网会列出所有参数,但没有解释这些参数对系统的影响。你需要逐个尝试来了解它们。
第四点,关于 MinIO 和 SeaweedFS 的易用性。我们在实践中得出结论,MinIO 在易用性和数据冗余方面优于 SeaweedFS。在文件数量较少的情况下,我们强烈推荐使用 MinIO。事实上,我们的有些业务在一些实时性、可用性要求不强的环节中都采用了 Redis + MinIO 的组合。只有在数据量较大时,我们才切换到 TiKV+SeaweedFS 的组合。
JuiceFS CSI Driver
首先,当我们采用 CSI 动态配置时,无法关闭 SubPath 功能。我们的初衷是能够查看文件系统中的所有数据,因此我们当时通过修改 CSI 源代码来关闭 SubPath 功能。
其次,在将系统部署到预生产环境后,我们在短时间内创建了大量的持久卷声明(PVC)并进行挂载,导致系统卡死。经过定位,我们发现在 v0.17.1 版本的控制器中存在 Create/DeleteSubPath 操作,这导致了在控制器容器中同时挂载/卸载多个JuiceFS文件系统,从而导致控制器的容器资源不足并进入假死状态。我们及时通知了CSI的维护者,社区在下一个版本中进行了修复。
第三,就没有部署 TiDB 的 TiKV 集群而言,会导致 TiKV 中的数据没有进行垃圾回收(GC)。因此经常会看到人们在 TiKV 群里询问为什么 TiKV 的容量持续上升而不下降。但是实际上,我们并没有遇到这种情况,可能是因为我们使用了较高版本的TiKV。我注意到JuiceFS的最新版本中也添加了 GC 功能。在 JuiceFS v1.0.0 中,设置了上传/下载限制后,会出现大文件读写超时失败的问题,这导致我们的QOS设置遇到了问题,我们目前采用的还是从网络层面限制,后续会对这里进行优化。
在本次分享中, 并没有分享我们的架构。如果大家对我们的架构感兴趣,可以查看云之声的案例,大家的架构基本上都是相似的,AI 私有化存储方面的差异并不大。
06 未来展望
首先,处理一下重客户端与任务进行资源争抢的问题。因为如果遇到整机内存超售的情况,尤其是在大型节点和高压力任务下,往往容易导致任务宕机。在今年FAST 23,我们看到了阿里一个解决方案,Fisc: A Large-scale Cloud-native-oriented File System。但对于一般的公司来说,这种方法的实现成本确实非常高。
第二,适配 JuiceFS 的新版本 v1.1,原因是它解决了目录配额的问题。我们目前正在探索是否可以在不迁移的数据的情况下,将多个JuiceFS 合并为一个JuiceFS,并开启目录限额,以此来降低我们的运维压力。
第三,关于 Redis 和 TiKV 的延迟,在非临界状态下它们的延迟相近。然而,TiKV的部署运维非常复杂,鉴于我们在其他项目中使用了 CockroachDB,我们正在考虑是否可以将元数据切换到CockroachDB 上。我们的场景对元数据的性能要求并不是特别高,我们的业务主要是读取操作,写入操作的速度慢并不会影响后续读取操作。
如有帮助的话欢迎关注我们项目 Juicedata/JuiceFS 哟! (0ᴗ0✿)
相关文章:

构建易于运维的 AI 训练平台:存储选型与最佳实践
伴随着公司业务的发展,数据量持续增长,存储平台面临新的挑战:大图片的高吞吐、超分辨率场景下数千万小文件的 IOPS 问题、运维复杂等问题。除了这些技术难题,我们基础团队的人员也比较紧张,负责存储层运维的仅有 1 名同…...
)
前期自学Java的基础部分总结(二)
一. 抽象类 1.1 抽象类的概述 在java中,一个没有方法体的方法应该定义为抽象方法,而类中如果有抽象方法,该类必须被定义为抽象类 1.2 抽象类的特点 抽象类和抽象方法必须使用abstract关键字修饰 publice abstract class 类名{};public…...

Altova MissionKit 2023Crack
Altova MissionKit 2023Crack MissionKit是一套面向信息架构师和应用程序开发人员的企业级XML、JSON、SQL和UML工具的软件开发套件。MissionKit包括Altova XMLSpy、MapForce、StyleVision和其他市场领先的产品,用于构建当今的真实世界软件解决方案。 使用MissionKit…...

Linux CentOS上快速安装Docker并运行服务
在 CentOS 上快速安装 Docker,可以按照以下步骤进行: 1. 更新系统: sudo yum update 2. 安装 Docker: sudo yum install docker 3. 启动 Docker 服务: sudo systemctl start docker 4. 设置 Docker 开机自启动&…...
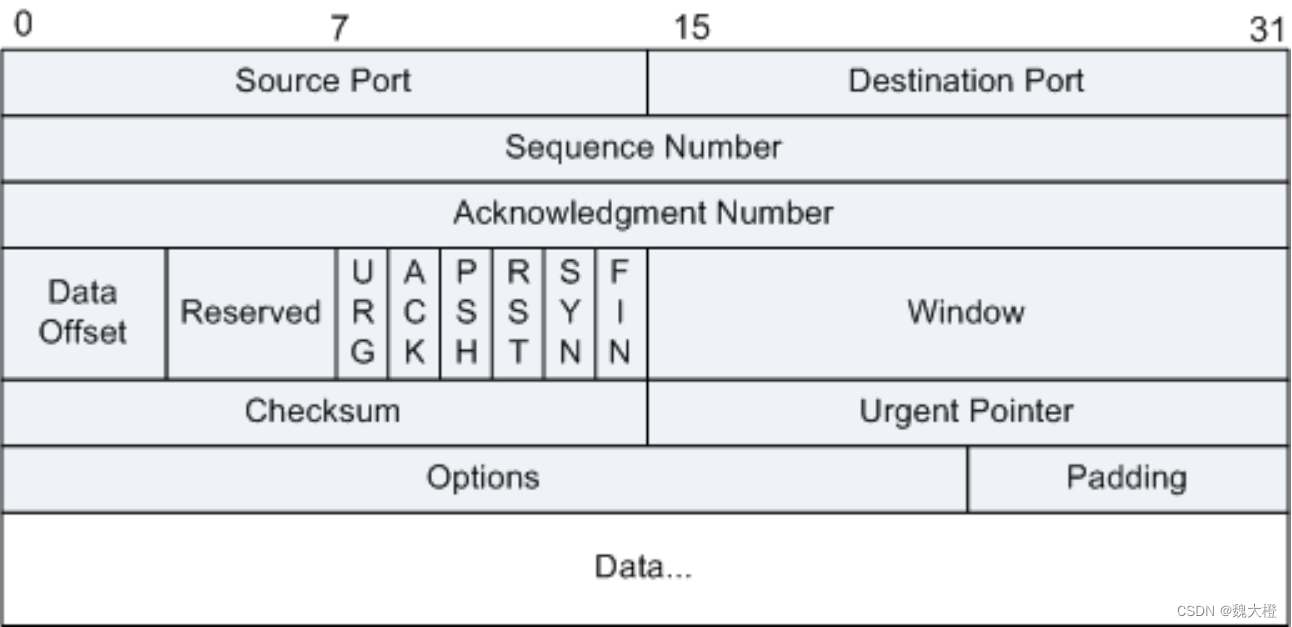
TCP三次握手与四次断开
TCP三次握手机制 三次握手是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。 1、客户端发送建立TCP连接的请求报文,其…...

关于前端与APP录音相关的笔记
文章目录 一、前言二、内容组成1、权限获取2、针对设备兼容3、内容类型转换4、传输存储 三、拓展内容自动播放部分 一、前言 主要针对前端适配录音能力的简要记录,针对默认的wav及其可能需要转换到特定的mp3之类格式以适配需求的问题。(这类通常是兼容tt…...

【Java】SpringBoot项目整合FreeMarker加快页面访问速度
文章目录 什么是FreeMarker?它的优点有那些?使用方式 什么是FreeMarker? Freemarker是一个模板引擎技术,它可以将数据和模板结合起来生成最终的输出。它是一种用于生成文本输出(如HTML、XML、JSON等)的通用…...

conda环境下安装opencv-python包
conda环境下安装opencv-python包 一、#查看环境 conda info --env# conda environments: # base D:\ProgramData\Anaconda3二、激活base环境 进入conda环境 conda init cmd.exe conda activate base三、根据版本号,下载对应的 python-opencv…...
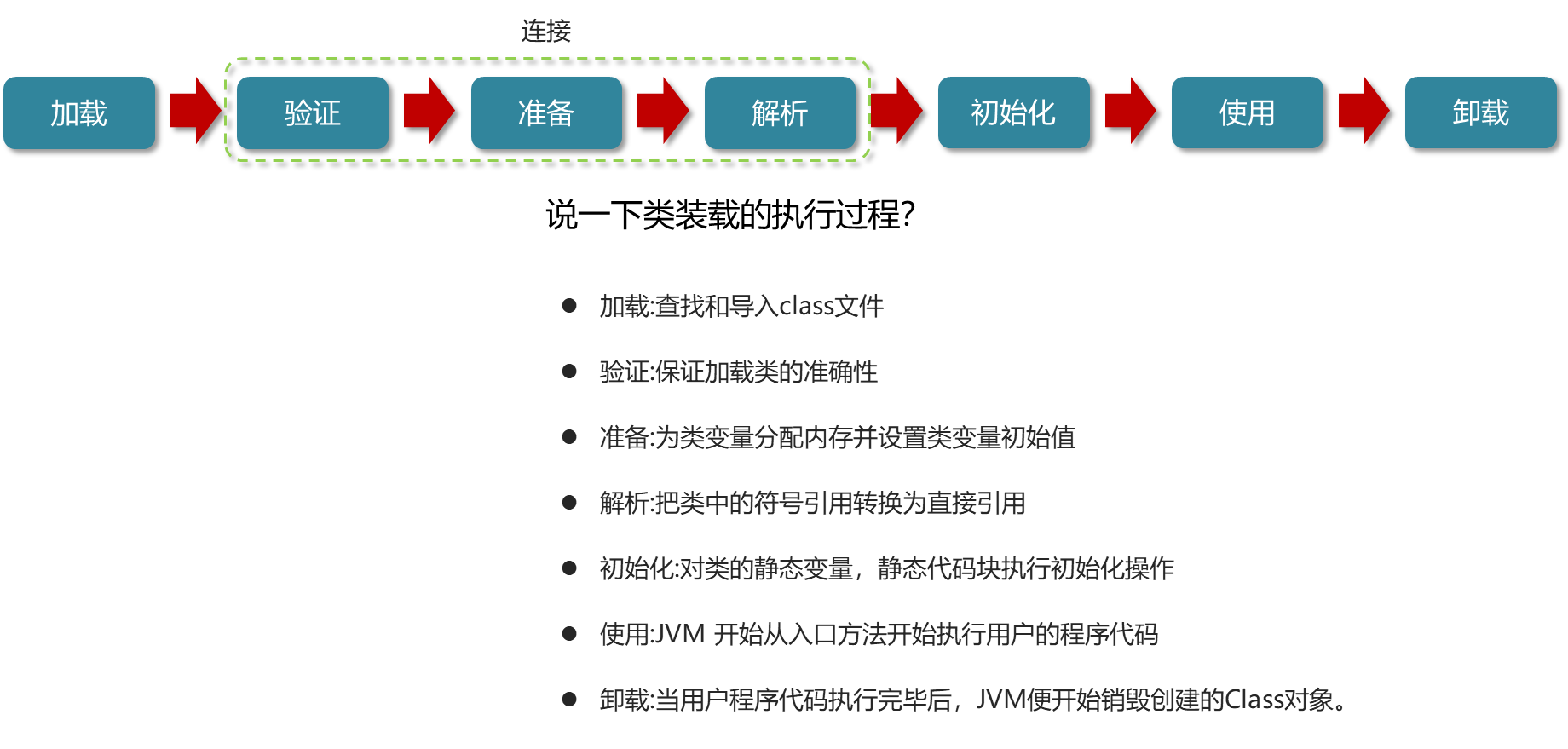
JVM面试题--类加载器
什么是类加载器,类加载器有哪些 类加载子系统,当java源代码编译为class文件之后,由他将字节码装载到运行时数据区 BootStrap ClassLoader 启动类加载器或者叫做引导类加载器,是用c实现的,嵌套在jvm内部,…...

js怎么计算当前一周的日期
你可以使用 JavaScript 的 Date 对象来计算当前一周的日期。首先,你需要获取当前日期,然后使用 Date 对象的 getDay 方法获取当前是星期几(星期日是 0,星期一是 1,以此类推)。然后,你可以根据当前是星期几来计算出本周…...

【图论】差分约束
一.情景导入 x1-x0<9 ; x2-x0<14 ; x3-x0<15 ; x2-x1<10 ; x3-x2<9; 求x3-x0的最大值; 二.数学解法 联立式子2和5,可得x3-x0<23;但式子3可得x3-x0<15。所以最大值为15; 三.图论 但式子多了我们就不好解了࿰…...

13 springboot项目——准备数据和dao类
13.1 静态资源下载 https://download.csdn.net/download/no996yes885/88151513 13.2 静态资源位置 css样式文件放在static的css目录下;static的img下放图片;template目录下放其余的html文件。 13.3 创建两个实体类 导入依赖:lombok <!…...

Java 基础进阶总结(一)反射机制学习总结
文章目录 一、初识反射机制1.1 反射机制概述1.2 反射机制概念1.3 Java反射机制提供的功能1.4 反射机制的优点和缺点 二、反射机制相关的 API 一、初识反射机制 1.1 反射机制概述 JAVA 语言是一门静态语言,对象的各种信息在程序运行时便已经确认下来了,内…...

ERROR: transport error 202: gethostbyname: unknown host报错解决方案
Java 9 syntax for remote debugger: -agentlib:jdwptransportdt_socket,servery,suspendn,address*:5005Java 8 不适用 *:port,应该使用: -agentlib:jdwptransportdt_socket,servery,suspendn,address5005参考 https://stackoverflow.com/questions/50344957/ja…...

PyTorch高级教程:自定义模型、数据加载及设备间数据移动
在深入理解了PyTorch的核心组件之后,我们将进一步学习一些高级主题,包括如何自定义模型、加载自定义数据集,以及如何在设备(例如CPU和GPU)之间移动数据。 一、自定义模型 虽然PyTorch提供了许多预构建的模型层&#…...

JavaEE——SpringMVC中的常用注解
目录 1、RestController (1)、Controller (2)、ResponseBody 2、RequestMappping (1)、定义 (2)、使用 【1】、修饰方法 【2】、修饰类 【3】、指定方法类型 【4】、简化版…...
【严重】Metabase 基于H2引擎的远程代码执行漏洞
漏洞描述 Metabase 是一个开源的数据分析和可视化工具。 由于 CVE-2023-38646 的补丁(从H2 JDBC连接字符串中删除INIT脚本以防止命令注入)修复不完全,Metabase 仍受到命令注入的影响。攻击者可使用 H2 作为数据库引擎,通过 /api/setup/validate 端点发…...
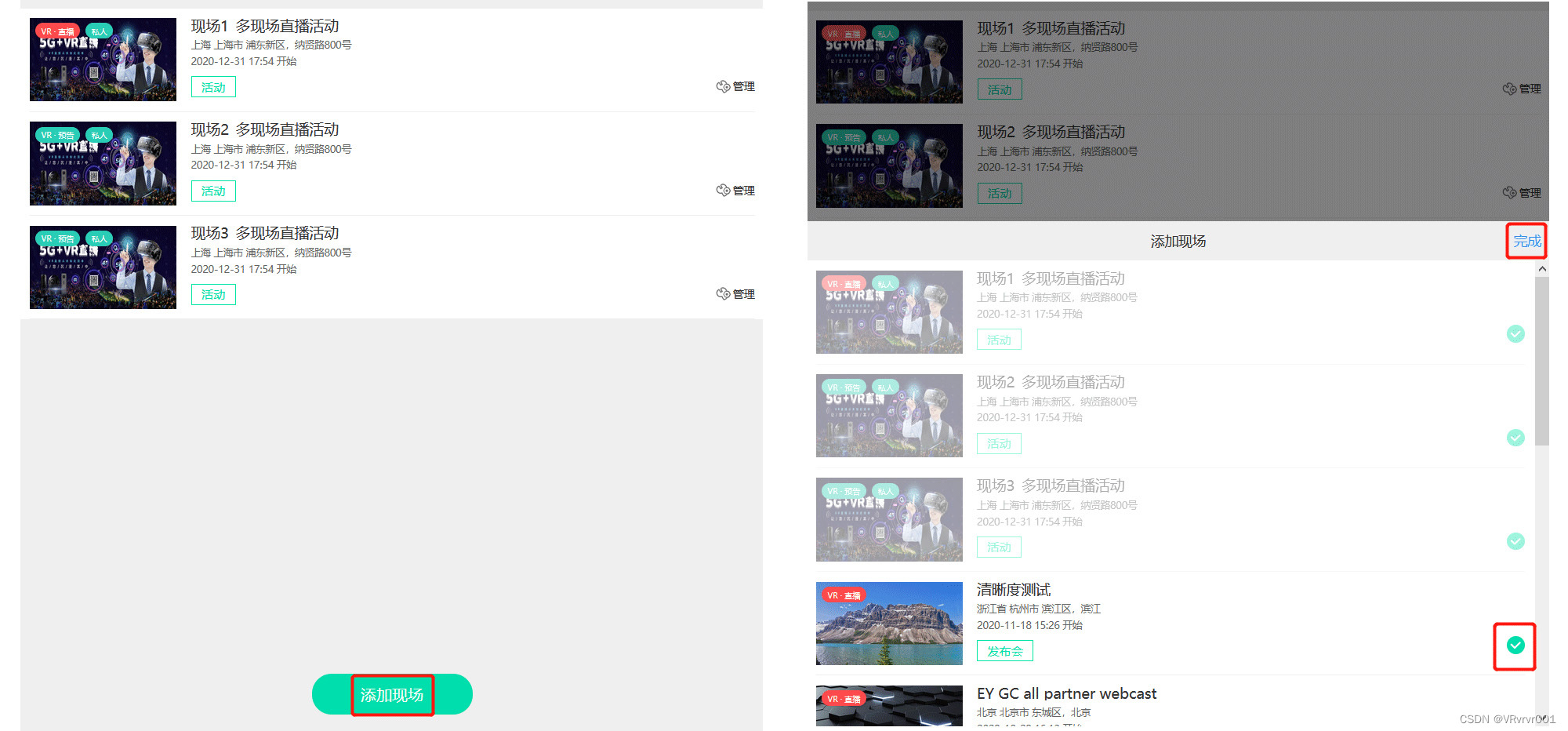
0基础学习VR全景平台篇 第75篇:多现场
多现场是指将多台设备的直播画面整合到一个直播活动链接里面,让用户自行选择切换要看哪个直播画面的功能。既可以是同一个活动的不同角度直播,也可以是异地的直播。多现场不需要导播台,并且可以同时支持平面直播和VR直播的混合切换。多现场仅…...

html:去除input/textarea标签的拼写检查
默认情况下,textarea 会启动拼写和语法检查,表现效果就是单词拼写错误会出现红色下划线提示 <textarea></textarea>效果 有时,我们并不需要拼写检查,可以通过配置属性spellcheck"false" 去除拼写和语法检…...
-[提示模板:创建自定义提示模板和含有Few-Shot示例的提示模板])
自然语言处理从入门到应用——LangChain:提示(Prompts)-[提示模板:创建自定义提示模板和含有Few-Shot示例的提示模板]
分类目录:《自然语言处理从入门到应用》总目录 创建自定义提示模板 假设我们希望LLM根据函数名称生成该函数的英文语言解释。为了实现这个任务,我们将创建一个自定义的提示模板,以函数名称作为输入,并格式化提示模板以提供函数的…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态
Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore LTSC-Add-MicrosoftStor…...

AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程
AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要让你的…...

ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术
ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI ncmdumpGUI是一款专为Windows平台设计…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...