MongoDB教程-7
正如在MongoDB关系的最后一章中所看到的,为了在MongoDB中实现规范化的数据库结构,我们使用了引用关系的概念,也被称为手动引用,在这个概念中,我们手动将被引用文档的id存储在其他文档中。然而,在一个文档包含来自不同集合的引用的情况下,我们可以使用MongoDB DBRefs。
DBRefs与手工引用
作为一个例子,我们将使用DBRefs而不是手动引用,考虑一个数据库,我们在不同的集合(address_home、address_office、address_mailing等)中存储不同类型的地址(家庭、办公室、邮件等)。现在,当一个用户集合的文档引用一个地址时,它也需要根据地址类型来指定查找哪个集合。在这种情况下,如果一个文档引用了许多集合的文档,我们应该使用DBRefs。
使用DBRefs
在 DBRefs 中有三个字段 --
$ref - 这个字段指定了被引用文档的集合
$id - 这个字段指定了被引用文档的_id字段
$db - 这是一个可选的字段,包含被引用文档所在的数据库的名称。
考虑一个具有DBRef字段地址的用户文档样本,如代码片段所示
{"_id":ObjectId("53402597d852426020000002"),"address": {"$ref": "address_home","$id": ObjectId("534009e4d852427820000002"),"$db": "tutorialspoint"},"contact": "987654321","dob": "01-01-1991","name": "Tom Benzamin"
}这里的地址DBRef字段指定引用的地址文件位于tutorialspoint数据库下的address_home集合中,其id为534009e4d852427820000002。
下面的代码动态地在$ref参数指定的集合(在我们的例子中是address_home)中寻找一个id为DBRef中$id参数指定的文档。
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})上述代码返回存在于address_home集合中的以下地址文件 -
{"_id" : ObjectId("534009e4d852427820000002"),"building" : "22 A, Indiana Apt","pincode" : 123456,"city" : "Los Angeles","state" : "California"
}什么是覆盖式查询?
根据MongoDB的官方文档,覆盖式查询是一个查询,其中
查询中的所有字段都是一个索引的一部分。
在查询中返回的所有字段都在同一个索引中。
由于查询中的所有字段都是索引的一部分,MongoDB会匹配查询条件,并使用相同的索引返回结果,而无需实际查看文档内部。由于索引存在于RAM中,从索引中获取数据要比通过扫描文档获取数据快得多。
使用覆盖式查询
为了测试覆盖式查询,请考虑用户集合中的以下文档
{"_id": ObjectId("53402597d852426020000003"),"contact": "987654321","dob": "01-01-1991","gender": "M","name": "Tom Benzamin","user_name": "tombenzamin"
}我们将首先使用下面的查询为用户集合的性别和用户名称字段创建一个复合索引------。
>db.users.createIndex({gender:1,user_name:1})
{"createdCollectionAutomatically" : false,"numIndexesBefore" : 1,"numIndexesAfter" : 2,"ok" : 1
}现在,这个索引将涵盖以下查询 --
>db.users.find({gender:"M"},{user_name:1,_id:0})
{ "user_name" : "tombenzamin" }
这就是说,对于上述查询,MongoDB不会去寻找数据库文件。相反,它将从索引数据中获取所需的数据,这是非常快的。
由于我们的索引不包括_id字段,我们已经明确地将它从我们的查询结果集中排除,因为MongoDB默认在每个查询中返回_id字段。所以下面的查询不会被包含在上面创建的索引中------。
>db.users.find({gender:"M"},{user_name:1})
{ "_id" : ObjectId("53402597d852426020000003"), "user_name" : "tombenzamin" }最后,请记住,一个索引不能覆盖一个查询,如果---。
任何被索引的字段是一个数组
任何一个被索引的字段是一个子文件
分析查询是衡量数据库和索引设计是否有效的一个非常重要的方面。我们将学习经常使用的$explain和$hint查询。
使用$explain
$explain操作符提供了关于查询、查询中使用的索引和其他统计数据的信息。在分析你的索引的优化程度时,它非常有用。
在上一章中,我们已经为用户集合中的字段gender和user_name创建了一个索引,使用的查询方式如下
>db.users.createIndex({gender:1,user_name:1})
{"numIndexesBefore" : 2,"numIndexesAfter" : 2,"note" : "all indexes already exist","ok" : 1
}
我们现在将在以下查询中使用$explain --
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()
上述 explain() 查询返回以下分析结果 -
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "mydb.users","indexFilterSet" : false,"parsedQuery" : {"gender" : {"$eq" : "M"}},"queryHash" : "B4037D3C","planCacheKey" : "DEAAE17C","winningPlan" : {"stage" : "PROJECTION_COVERED","transformBy" : {"user_name" : 1,"_id" : 0},"inputStage" : {"stage" : "IXSCAN","keyPattern" : {"gender" : 1,"user_name" : 1},"indexName" : "gender_1_user_name_1","isMultiKey" : false,"multiKeyPaths" : {"gender" : [ ],"user_name" : [ ]},"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"gender" : ["[\"M\", \"M\"]"],"user_name" : ["[MinKey, MaxKey]"]}}},"rejectedPlans" : [ ]},"serverInfo" : {"host" : "Krishna","port" : 27017,"version" : "4.2.1","gitVersion" : "edf6d45851c0b9ee15548f0f847df141764a317e"},"ok" : 1
}我们现在来看看这个结果集中的字段 -
indexOnly的真值表示这个查询使用了索引。
cursor字段指定了使用的游标类型。BTreeCursor类型表示使用了一个索引,并且给出了所使用的索引的名称。BasicCursor表示在没有使用任何索引的情况下进行了一次全扫描。
n表示返回的匹配文档的数量。
nscannedObjects表示扫描的文件总数。
nscanned表示扫描的文档或索引条目的总数。
使用$hint
$hint操作符强制查询优化器使用指定的索引来运行查询。当你想用不同的索引来测试一个查询的性能时,这特别有用。
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})
{ "user_name" : "tombenzamin" }为了分析上述查询,使用$explain -
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()
由此得出以下结果−
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "mydb.users","indexFilterSet" : false,"parsedQuery" : {"gender" : {"$eq" : "M"}},"queryHash" : "B4037D3C","planCacheKey" : "DEAAE17C","winningPlan" : {"stage" : "PROJECTION_COVERED","transformBy" : {"user_name" : 1,"_id" : 0},"inputStage" : {"stage" : "IXSCAN","keyPattern" : {"gender" : 1,"user_name" : 1},"indexName" : "gender_1_user_name_1","isMultiKey" : false,"multiKeyPaths" : {"gender" : [ ],"user_name" : [ ]},"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"gender" : ["[\"M\", \"M\"]"],"user_name" : ["[MinKey, MaxKey]"]}}},"rejectedPlans" : [ ]},"serverInfo" : {"host" : "Krishna","port" : 27017,"version" : "4.2.1",109"gitVersion" : "edf6d45851c0b9ee15548f0f847df141764a317e"},"ok" : 1
}原子操作的模型数据
推荐的维护原子性的方法是将所有相关的信息,经常更新的信息,使用嵌入式文件保存在一个文件中。这将确保单个文档的所有更新都是原子性的。
假设我们创建了一个名为productDetails的集合,并在其中插入了一个文档,如下所示
>db.createCollection("products")
{ "ok" : 1 }
> db.productDetails.insert({"_id":1,"product_name": "Samsung S3","category": "mobiles","product_total": 5,"product_available": 3,"product_bought_by": [{"customer": "john","date": "7-Jan-2014"},{"customer": "mark","date": "8-Jan-2014"}]}
)
WriteResult({ "nInserted" : 1 })
>在这份文件中,我们在product_bought_by字段中嵌入了购买产品的客户的信息。现在,每当有新客户购买产品时,我们将首先使用product_available字段检查该产品是否仍然可用。如果可用,我们将减少product_available字段的值,并在product_bought_by字段中插入新客户的嵌入式文档。我们将使用findAndModify命令来实现这一功能,因为它可以在同一时间内搜索和更新文档。
>db.products.findAndModify({ query:{_id:2,product_available:{$gt:0}}, update:{ $inc:{product_available:-1}, $push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}} }
})我们的嵌入式文档和使用findAndModify查询的方法确保了产品购买信息只有在产品可用时才会被更新。而整个交易都在同一个查询中,是原子性的。
与此相反,考虑一下这样的情况:我们可能把产品的可用性和谁购买了该产品的信息分开保存。在这种情况下,我们将首先使用第一个查询来检查产品是否可用。然后在第二个查询中,我们将更新购买信息。然而,有可能在这两个查询的执行过程中,有其他用户购买了该产品,而该产品已不再可用。在不知道这一点的情况下,我们的第二个查询将根据我们第一个查询的结果来更新购买信息。这将使数据库不一致,因为我们已经售出了一个不可用的产品。
高级索引
我们在名为用户的集合中插入了以下文件,如下图所示
db.users.insert({"address": {"city": "Los Angeles","state": "California","pincode": "123"},"tags": ["music","cricket","blogs"],"name": "Tom Benzamin"}
)上述文件包含一个地址子文件和一个标签阵列。
阵列字段的索引
假设我们想根据用户的标签来搜索用户文档。为此,我们将在集合中的标签数组上创建一个索引。
在数组上创建索引又会为其每个字段创建单独的索引条目。所以在我们的例子中,当我们在tags数组上创建索引时,将为其值music、cricket和blogs创建单独的索引。
要在tags数组上创建一个索引,请使用以下代码
>db.users.createIndex({"tags":1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"ok" : 1
}
>在创建索引之后,我们可以像这样在集合的tags字段上进行搜索
> db.users.find({tags:"cricket"}).pretty()
{"_id" : ObjectId("5dd7c927f1dd4583e7103fdf"),"address" : {"city" : "Los Angeles","state" : "California","pincode" : "123"},"tags" : ["music","cricket","blogs"],"name" : "Tom Benzamin"
}
>要验证是否使用了正确的索引,请使用以下解释命令−
>db.users.find({tags:"cricket"}).explain()
这将给出以下结果−
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "mydb.users","indexFilterSet" : false,"parsedQuery" : {"tags" : {"$eq" : "cricket"}},"queryHash" : "9D3B61A7","planCacheKey" : "04C9997B","winningPlan" : {"stage" : "FETCH","inputStage" : {"stage" : "IXSCAN","keyPattern" : {"tags" : 1},"indexName" : "tags_1","isMultiKey" : false,"multiKeyPaths" : {"tags" : [ ]},"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"tags" : ["[\"cricket\", \"cricket\"]"]}}},"rejectedPlans" : [ ]},"serverInfo" : {"host" : "Krishna","port" : 27017,"version" : "4.2.1","gitVersion" : "edf6d45851c0b9ee15548f0f847df141764a317e"},"ok" : 1
}
>上述命令的结果是 "cursor":"BtreeCursor tags_1",这证实了正确的索引被使用。
对子文档字段进行索引
假设我们想根据城市、州和平码字段来搜索文件。由于所有这些字段都是地址子文件字段的一部分,我们将在子文件的所有字段上创建一个索引。
为了在子文档的所有三个字段上创建索引,请使用以下代码
>db.users.createIndex({"address.city":1,"address.state":1,"address.pincode":1})
{"numIndexesBefore" : 4,"numIndexesAfter" : 4,"note" : "all indexes already exist","ok" : 1
}
>
一旦建立了索引,我们就可以利用这个索引来搜索任何一个子文件字段,如下所示
> db.users.find({"address.city":"Los Angeles"}).pretty()
{"_id" : ObjectId("5dd7c927f1dd4583e7103fdf"),"address" : {"city" : "Los Angeles","state" : "California","pincode" : "123"},"tags" : ["music","cricket","blogs"],"name" : "Tom Benzamin"
} 记住,查询表达式必须遵循指定的索引的顺序。因此,上面创建的索引将支持以下查询 -
>db.users.find({"address.city":"Los Angeles","address.state":"California"}).pretty()
{"_id" : ObjectId("5dd7c927f1dd4583e7103fdf"),"address" : {"city" : "Los Angeles","state" : "California","pincode" : "123"},"tags" : ["music","cricket","blogs"],"name" : "Tom Benzamin"
}
>索引的局限性
额外的开销
每个索引都会占用一些空间,并在每次插入、更新和删除时造成开销。因此,如果你很少使用你的集合进行读取操作,不使用索引是有意义的。
内存的使用
由于索引被存储在RAM中,你应该确保索引的总大小不超过RAM的限制。如果总大小增加了RAM的大小,它将开始删除一些索引,导致性能损失。
查询限制
索引不能用于使用--的查询。
正则表达式或否定运算符,如$nin, $not, 等。
算术运算符,如$mod,等等。
$where条款
因此,建议你总是检查你的查询的索引使用情况。
索引键的限制
从2.6版本开始,如果现有的索引字段的值超过了索引键的限制,MongoDB将不会创建一个索引。
插入超过索引键限制的文档
如果任何文档的索引字段值超过了索引键限制,MongoDB将不会将该文档插入到一个有索引的集合。mongorestore和mongoimport工具的情况也是如此。
最大范围
一个集合不能有超过64个索引。
索引名称的长度不能超过125个字符。
一个复合索引最多可以有31个字段的索引。
相关文章:

MongoDB教程-7
正如在MongoDB关系的最后一章中所看到的,为了在MongoDB中实现规范化的数据库结构,我们使用了引用关系的概念,也被称为手动引用,在这个概念中,我们手动将被引用文档的id存储在其他文档中。然而,在一个文档包…...

Redisson提供优秀的并发控制机制
1. JDK集合类 对于JDK的集合类,forEach方法其实并不能完全避免并发修改异常。 forEach本质上还是一个循环遍历,如果在循环体内直接对集合进行修改,仍然会产生ConcurrentModificationException。 例如: List<String> lis…...

Linux: 设置qmake的Qt版本
Qt开发,qmake会对应一个Qt版本,有时候需要切换这个版本,例如把qmake从Qt5.12切换到Qt5.9, 怎么操作呢? 案例如下: 银河麒麟V10系统,下载安装了Qt5.9.8,但是检查qmake发现它使用的是5.12.8&…...

使用LLM插件从命令行访问Llama 2
大家好,最近的一个大新闻是Meta AI推出了新的开源授权的大型语言模型Llama 2,这是一项非常重要的进展。Facebook最初的LLaMA模型于今年2月发布,掀起了开源LLM领域的创新浪潮——从微调变体到从零开始的再创造。 如果在Llama 2版本发布之日&a…...

gateway过滤器没生效,特殊原因
看这边文章的前提,你要会gateway,知道过滤器怎么配置? 直接来看过滤器,局部过滤器 再来看配置 请求路径 http://127.0.0.1:8080/appframework/services/catalog/catalogSpecials.json?pageindex1&pagesize10&pkidd98…...
长相思追剧小游戏
看效果图 Vue长相思 刚学Vue,正好在追剧,看到这个小案例觉得挺好玩的,第一天学,代码太简陋了 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name&qu…...

leetcode做题笔记51
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。 每一种…...

Windows同时安装两个版本的JDK并随时切换,以JDK6和JDK8为例,并解决相关存在的问题(亲测有效)
Windows同时安装两个版本的JDK并随时切换,以JDK6和JDK8为例,并解决相关存在的问题(亲测有效) 1.下载不同版本JDK 这里给出JDK6和JDK的百度网盘地址,具体安装过程,傻瓜式安装即可。 链接:http…...
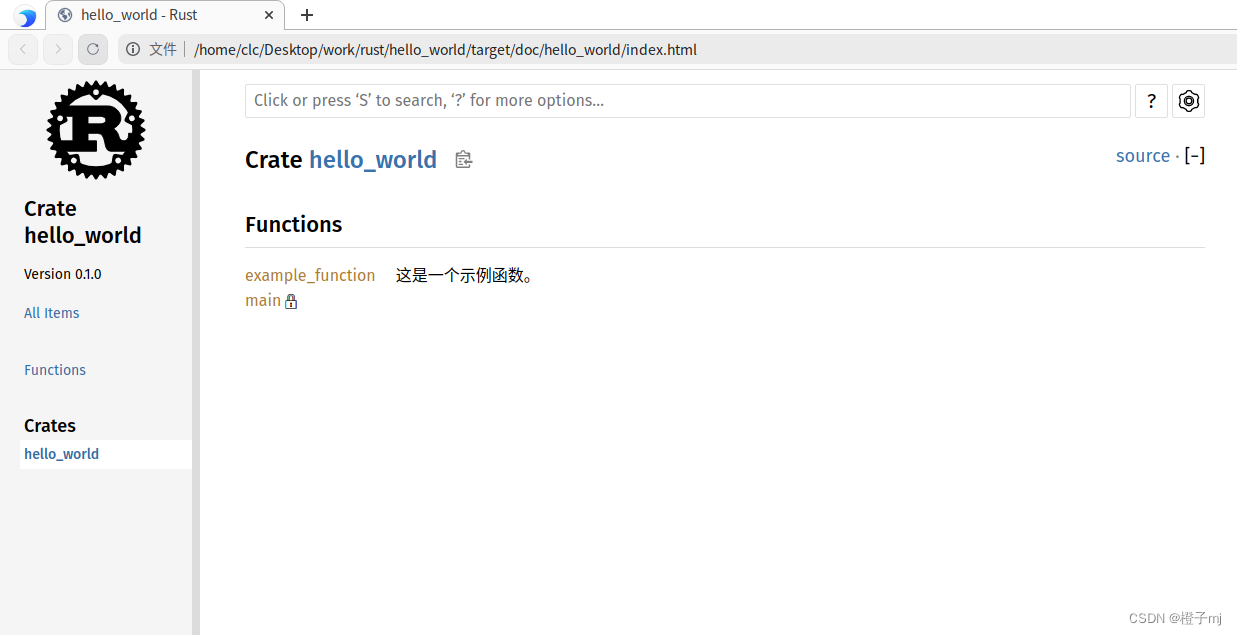
【ChatGPT辅助学Rust | 基础系列 | Cargo工具】Cargo介绍及使用
文章目录 前言一,Cargo介绍1,Cargo安装2,创建Rust项目2,编译项目:3,运行项目:4,测试项目:5,更新项目的依赖:6,生成项目的文档…...

全面了解CPU Profiler:解读CPU性能分析工具的核心功能与用法
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、使用3.1 通过调用系统API3.2 通过Android Stu…...

rust format!如何转义{},输出{}?
在Rust中,如果你想要在字符串中包含花括号 {} ,你需要使用双花括号 {{}} 来进行转义。这是因为单个花括号 {} 在字符串中表示占位符,用于格式化字符串。 以下是一个示例: fn main() {let text "这是一个示例: {…...
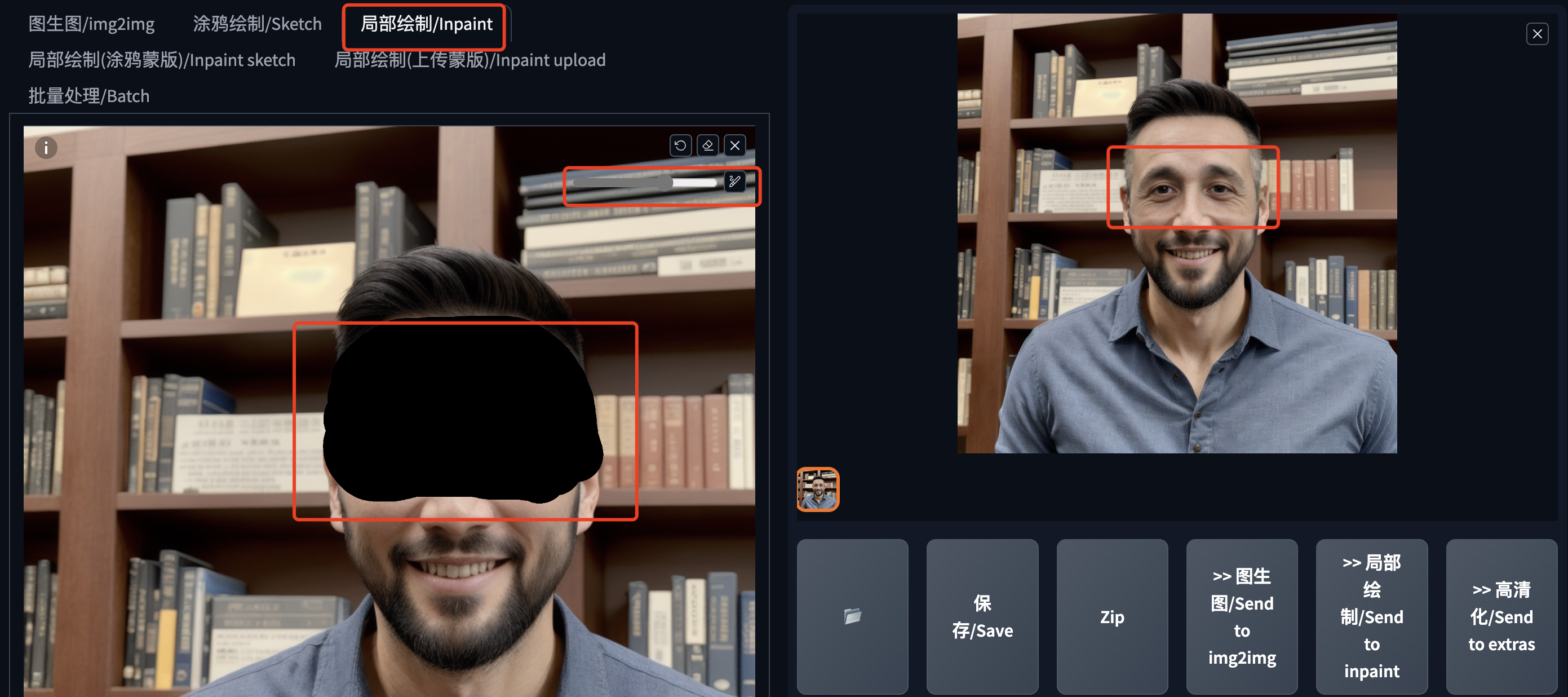
真人AI写真的制作方法-文生图换脸
AI写真最近火起来了,特别是某款现象级相机的出现,只需要上传自己的照片,就能生成漂亮的写真照,这一产品再次带火了AI绘画。今天我就来分享一个使用Stable Diffusion WebUI制作真人AI写真的方法,不用训练,快…...
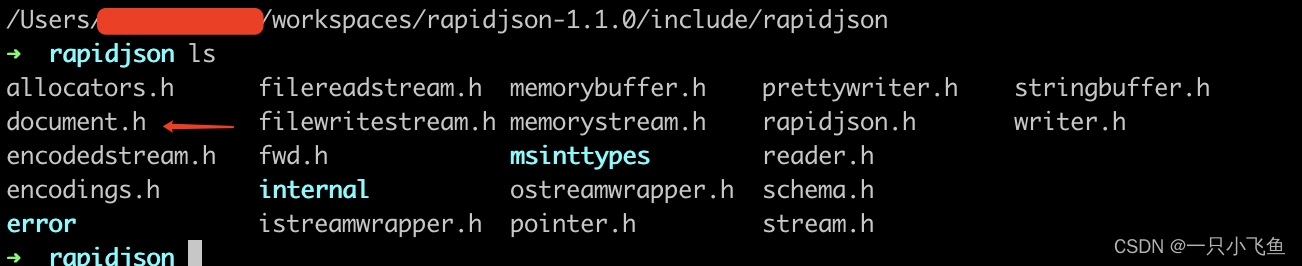
vscode如何包含第三方库
方法1:使用C Extension 在include 的 rapidjson的头文件时,vscode会提示找不到的问题 悬停,点击黄色提示 Edit "includePath" setting Include Path,输入rapidjson的include路径 /Users/xxx/workspaces/rapidjson-1.1.…...
【Docker】Docker安装Consul
文章目录 1. 什么是Consul2. Docker安装启动Consul 点击跳转:Docker安装MySQL、Redis、RabbitMQ、Elasticsearch、Nacos等常见服务全套(质量有保证,内容详情) 1. 什么是Consul Consul是HashiCorp公司推出的开源软件,提…...
《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(20)-Fiddler精选插件扩展安装让你的Fiddler开挂到你怀疑人生
1.简介 Fiddler本身的功能其实也已经很强大了,但是Fiddler官方还有很多其他扩展插件功能,可以更好地辅助Fiddler去帮助用户去开发、测试和管理项目上的任务。Fiddler已有的功能已经够我们日常工作中使用了,为了更好的扩展Fiddler,…...
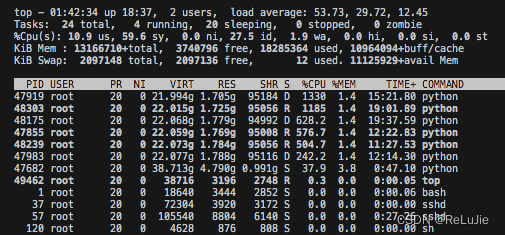
计算机top命令
top 快捷键 1 核心参数 1 1 参考资料 [1]. https://blog.csdn.net/weixin_45465395/article/details/115728520 [2].https://www.cnblogs.com/liushui-sky/p/13224762.html...
DevExpress WPF Tree List组件,让数据可视化程度更高!(二)
DevExpress WPF Tree List组件是一个功能齐全、数据感知的TreeView-ListView混合体,可以把数据信息显示为REE、GRID或两者的组合,在数据绑定或非绑定模式下,具有完整的数据编辑支持。 在上文中(点击这里回顾DevExpress WPF Tree …...

lc1074.元素和为目标值的子矩阵数量
创建二维前缀和数组 两个for循环,外循环表示子矩阵的左上角(x1,y1),内循环表示子矩阵的右下角(x2,y2) 两个for循环遍历,计算子矩阵的元素总和 四个变量,暴力破解的时间复杂度为O(…...

elementUi el-radio神奇的:label与label不能设置默认值
问题:最近项目遇到一个奇葩的问题:红框中列表的单选按钮无法根据需求设置默认选中,但是同样是设置开启状态的单选框可以设置默认状态 原因:开始同样是和开启/关闭状态一样也把红框中列表的默认值设置为数字模式,但是由…...

git仓库清理
关于git仓库的清理,主要就是清理git仓库里面的大的二进制文件。网上查了很多教程,很多都是用:git filter-branch.清理仓库中的大文件。 我尝试着本地测试了一下,发现是真慢呀。 方法一、git filter-branch step1:查…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...