【Linux】Kali Linux 渗透安全学习笔记(2) - OneForAll 简单应用
OneForAll (以下简称“OFA”)是一个非常好用的子域收集工具,可以通过一级域名找到旗下的所有层级域名,通过递归的方式我们很容易就能够知道此域名下的所有域名层级结构,对于进一步通过域名推测站点功能起到非常重要的作用。
声明:
- 本文测试的站点为自家站点仅做学习使用,不存在侵犯网络信息安全问题;
- 本文只介绍工具的使用并不鼓吹任何非法活动,请各位看官三思而后行一切后果自负;
- 本文测试中结果虽然是真实的,但涉及的敏感信息都将采用“化名”进行脱敏;
1. 安装 OneForAll
OFA 安装其实非常简单,我们只需到 github(或 gitee)中进行下载即可。
┌──(root💀b8ef6c2abc47)-[/home]
└─# git clone https://github.com/shmilylty/OneForAll.git
由于之前我们已经安装了 kali linux(以下简称“kali”)的 everything 版本,因此 python2 和 python3 都已经安装完成了,此时切换到 OFA 根目录就可以通过 python 命令执行。
注意:OFA 需要使用 python3 来运行。在运行过程中或许会出现“cannot import name ‘sre_parse’ from ‘re’”的错误,这是因为 kali 在安装 everything 的时候直接安装了高版本的 python3 了,在高版本中 sre_parse 模块已经被独立移出了,因此需要修改一下 exrex.py 文件,那这个 exrex.py 文件究竟在哪呢?
从报错信息我们可以找到是在“/usr/local/lib/python3.11/dist-packages/exrex.py”路径下,那么进去修改即可,如下图:
try:from future_builtins import map, range
except:pass
import sre_parse
from re import U
#from re import sre_parse, U
from itertools import tee
from random import choice, randint
from types import GeneratorType
还好要修改的部分还算是比较好找,如上图所示,将“from re import sre_parse, U”给注释掉,然后额外添加“import sre_parse”和“from re import U”就可以了。
2. 根据域名收集子域
在开始之前我们先找到目标域名,假设域名为“yzhcs.io”。接下来我们有两种方式可以将这个域名提供给 OFA 使用,
2.1 读取文件(适合多域名)
将域名写到一个 txt 文件里面(domain.txt,明名字随便起就可以),如下图:
┌──(root💀b8ef6c2abc47)-[/home/OneForAll]
└─# vim domain.txt┌──(root💀b8ef6c2abc47)-[/home/OneForAll]
└─# cat domain.txt
yzhcs.io
这里如果要扫描多个域名的情况下,可以在 txt 文档里面分多行来填写,每一行一个域名。接下来使用的时候只需要通过 --targets 参数将文件路径写上即可,如下图:
┌──(root💀b8ef6c2abc47)-[/home/OneForAll]
└─# python oneforall.py --targets domain.txt
2.2 直接提供(适合单域名)
除了文件方式,也可以通过 --target 参数直接将域名提供给 OFA,如下图:
┌──(root💀b8ef6c2abc47)-[/home/OneForAll]
└─# python oneforall.py --target yzhcs.io
2.3 执行扫描
除了提供域名外,我还使用了以下几个参数:
- –port:端口扫描范围,这里采用 large 参数代表大范围的端口扫描
- –alive:是否只导出存活子域
- –takeover:是否启用子域劫持测试
当然了,只需使用“python oneforall.py -h”命令就能查看帮助文档,更多的参数可以在里面找到。需要提一嘴的是,目前网上大部分关于 OFA 文章的参数已经不太适用于最新的 OFA 程序了,建议各位在使用之前先看看帮助文档。命令执行如下图所示:
┌──(root💀b8ef6c2abc47)-[/home/OneForAll]
└─# python oneforall.py --target yzhcs.io --port large --alive True --takeover True runOneForAll is a powerful subdomain integration tool___ _ _ ___ ___ ___| _|___ ___ ___| | | {v0.4.5 #dev}
| . | | -_| _| . | _| .'| | |
|___|_|_|___|_| |___|_| |__,|_|_| git.io/fjHT1OneForAll is under development, please update before each use![*] Starting OneForAll @ 2023-08-02 11:49:4411:49:44,634 [INFOR] utils:532 - Checking dependent environment
11:49:44,634 [INFOR] utils:544 - Checking network environment
11:50:12,250 [ERROR] utils:520 - (ReadTimeoutError("HTTPSConnectionPool(host='www.akamai.com', port=443): Read timed out. (read timeout=27)"),)
11:50:12,252 [ALERT] utils:521 - Unable to access Internet, retrying for the 1th time
11:50:14,102 [INFOR] utils:555 - Checking for the latest version
11:50:15,109 [INFOR] utils:579 - The current version v0.4.5 is already the latest version
11:50:15,113 [INFOR] oneforall:241 - Start running OneForAll
... 此处省略 1w 字
11:53:19,143 [ALERT] takeover:161 - Takeover module takes 0.1 seconds, There are 0 subdomains exists takeover
11:53:19,144 [INFOR] takeover:163 - Subdomain takeover results: /home/OneForAll/results/takeover_check_result_1690977199.csv
11:53:19,144 [INFOR] takeover:164 - Finished Takeover module
11:53:19,144 [INFOR] oneforall:255 - Finished OneForAll
扫描结果如下所示, app.yzhcs.io 域名是没有 SSL 保护且显示可以被爆破获取,这个是需要注意的。
| 访问地址 | 域名 | 是否有 CDN 加速 | 端口 | 扫描状态 | 扫描结果 | 扫描返回 | 证书供应商 |
|---|---|---|---|---|---|---|---|
| https://app.yzhcs.io | app.yzhcs.io | 有 | 443 | 200 | OK | Brute | |
| http://app.yzhcs.io | app.yzhcs.io | 有 | 80 | 200 | OK | Brute | |
| http://def.yzhcs.io | def.yzhcs.io | 无 | 80 | 401 | Unauthorized | ‘{“message”:“认证信息异常!”}’ | MySSLQuery |
| https://def.yzhcs.io | def.yzhcs.io | 无 | 443 | 401 | Unauthorized | ‘{“message”:“认证信息异常!”}’ | MySSLQuery |
另外,“/home/OneForAll/results/”路径下的 takeover_check_result_1690977199.csv 文件中并没有任何信息反馈,因此可以认定该域名下没有发现子域劫持漏洞。
3. 根据域名爆破收集子域
除了通过 python oneforall.py 的方式获取子域外,OFA 还提供了单独的 brute.py 脚本进行爆破获取。所谓“爆破”据我理解就是通过字典方式进行碰撞匹配,说白了就是多线程的穷举碰撞获取所有子域(没有看过源码瞎猜而已)。
值得注意的是 brute.py 脚本中以下几个参数的使用:
- –concurrent:此为并发数默认 2000,不要设置太高会影响到目标服务器的使用;
- –recursive:是否开启递归扫描模式,若设置为 True,这会根据 --depth 参数中提供的层级深度进行扫描。需要注意的是一旦扫描出错这不会继续扫描下去,譬如:depth 递归层级设置为 3 级,那么 yzhcs.io 域名就应该扫描到三级域名,若扫描到其中一个二级域名中出现 Error 后,之后的其他二级域名将不会被扫描,扫描程序也会停留在 Error 层级;
- –depth:递归深度,默认为 2 级;
- –word:是否启用单词模式生成词典;
至于其他的参数像 --fuzz 、–rule 等参数都比较少用,这里就不介绍了各位可以上网搜一下能够找到的。
由于 yzhcs.io 也最多只有二级域名,因此并不需要那么多参数参与扫描,执行结果如下图所示:
┌──(root💀b8ef6c2abc47)-[/home/OneForAll]
└─# python brute.py --target yzhcs.io --word True runProcessed queries: 1721
Received packets: 1721
Progress: 100.00% (00 h 00 min 03 sec / 00 h 00 min 03 sec)
Current incoming rate: 25 pps, average: 797 pps
Current success rate: 25 pps, average: 797 pps
Finished total: 1721, success: 1721 (100.00%)
Mismatched domains: 0 (0.00%), IDs: 0 (0.00%)
Failures: 0: 53.86%, 1: 33.12%, 2: 9.88%, 3: 2.91%, 4: 0.23%, 5: 0.00%, 6: 0.00%, 7: 0.00%, 8: 0.00%, 9: 0.00%, 10: 0.00%, 11: 0.00%, 12: 0.00%, 13: 0.00%, 14: 0.00%, 15: 0.00%,
Response: | Success: | Total:
Processed queries: 95247
Received packets: 95266
Progress: 100.00% (00 h 00 min 22 sec / 00 h 00 min 22 sec)
Current incoming rate: 2 pps, average: 4239 pps
Current success rate: 2 pps, average: 4239 pps
Finished total: 95247, success: 95247 (100.00%)
Mismatched domains: 19 (0.02%), IDs: 0 (0.00%)
Failures: 0: 61.23%, 1: 22.92%, 2: 9.18%, 3: 3.82%, 4: 1.60%, 5: 0.68%, 6: 0.31%, 7: 0.15%, 8: 0.05%, 9: 0.03%, 10: 0.01%, 11: 0.00%, 12: 0.00%, 13: 0.00%, 14: 0.00%, 15: 0.00%,
Response: | Success: | Total:
OK: | 2 ( 0.00%) | 2 ( 0.00%)
NXDOMAIN: | 68172 ( 71.57%) | 68174 ( 71.56%)
SERVFAIL: | 27073 ( 28.42%) | 27090 ( 28.44%)
REFUSED: | 0 ( 0.00%) | 0 ( 0.00%)
FORMERR: | 0 ( 0.00%) | 0 ( 0.00%)
11:21:59,613 [INFOR] brute:197 - Counting IP cname appear times
11:21:59,616 [INFOR] brute:238 - Processing result
11:21:59,618 [ALERT] brute:451 - Brute module takes 22.8 seconds, found 2 subdomains of yzhcs.io
11:21:59,649 [INFOR] brute:489 - Finished Brute module to brute yzhcs.io
11:21:59,655 [ALERT] export:66 - The subdomain result for yzhcs.io: /home/OneForAll/results/yzhcs.io.csv
| 访问地址 | 子域名 | 端口 | 爆破结果 | 证书来源 |
|---|---|---|---|---|
| http://app.yzhcs.io | app.yzhcs.io | 80 | OK | Brute |
| http://def.yzhcs.io | def.yzhcs.io | 80 | OK | Brute |
结果显示,app 和 def 两个域名都可以被爆破获取。
4. 修复建议
既然OFA 这类工具能够通过子域劫持(Subdomain Takeover)从 DNS 记录中找到第三方服务或托管平台从而接管子域,那么可以试试从源头 DNS 那边做一些防御措施:
- 设置 DNS 查询频率限制:在 DNS 服务器上设置查询频率限制,以防止过多的 DNS 查询。这可以阻止恶意用户使用暴力破解方式来获取子域信息;
- 使用 DNSSEC:使用 DNSSEC(Domain Name System Security Extensions)来增强 DNS 的安全性。DNSSEC 可以保护 DNS 解析过程,防止数据篡改和欺骗攻击;
- 限制子域查询权限:只允许授权用户或合作伙伴查询子域信息。使用访问控制列表(ACL)或防火墙来限制 DNS 查询的来源;
- 合理设置 DNS TTL:合理设置 DNS 记录的 Time-to-Live(TTL),较短的 TTL 可以更快地更新 DNS 记录,但会增加 DNS 查询的频率;
但一般人大多是租用云服务供应商的机器进行部署,基本不可能接触到基于网络层面的 DNS 防御,这时只能尽力而为:
- 使用 HTTPS:确保您的项目使用 HTTPS 加密协议来保护数据传输;
- 配置防火墙和安全组:在云服务器控制台中,配置防火墙规则和安全组,以限制对服务器的访问;
- 使用安全的数据库连接:可以的话使用加密连接和凭证管理去连接数据库;
相关文章:
 - OneForAll 简单应用)
【Linux】Kali Linux 渗透安全学习笔记(2) - OneForAll 简单应用
OneForAll (以下简称“OFA”)是一个非常好用的子域收集工具,可以通过一级域名找到旗下的所有层级域名,通过递归的方式我们很容易就能够知道此域名下的所有域名层级结构,对于进一步通过域名推测站点功能起到非常重要的作…...
DAY56:单调栈(二)下一个最大元素Ⅱ(环形数组处理思路)
文章目录 思路写法1完整版环形数组处理:i取模,遍历两遍写法2完整版(环形数组推荐写法)debug测试:逻辑运算符短路特性result数组在栈口取元素,是否会覆盖原有数值? 给定一个循环数组 nums &#…...

kafka简介
kafka是什么? Kafka最初采用Scala语言开发的一个多分区、多副本并且基于ZooKeeper协调的分布式消息系统。目前Kafka已经定位为一个分布式流式处理平台,它的特性有高吞吐、可持久化、可水平扩展、支持流处理。 Apache Kafka是一个分布式的发布-订阅消息系…...
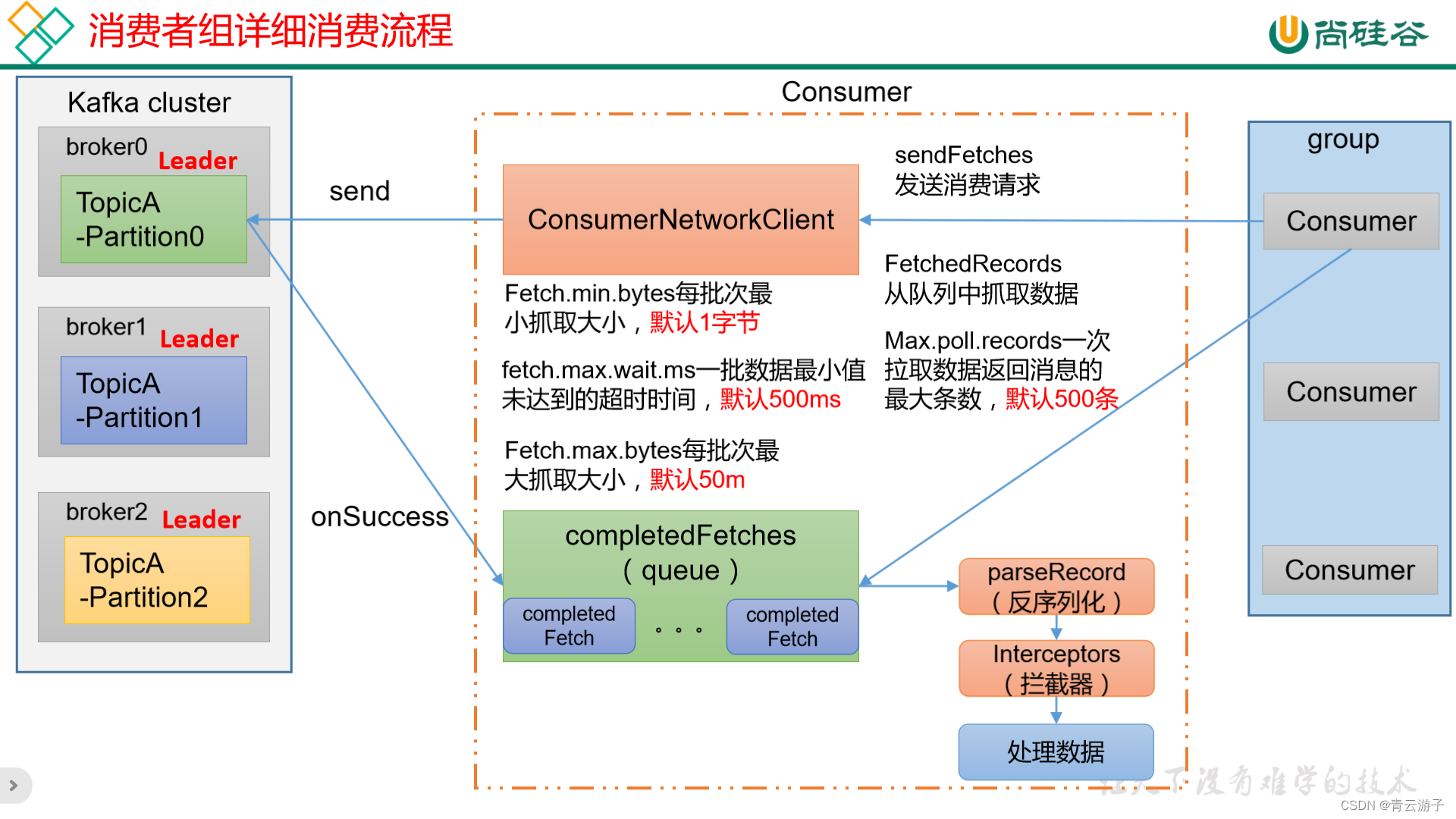
Kafka-消费者组消费流程
消费者向kafka集群发送消费请求,消费者客户端默认每次从kafka集群拉取50M数据,放到缓冲队列中,消费者从缓冲队列中每次拉取500条数据进行消费。...
FFmepg视频解码
1 前言 上一篇文章<FFmpeg下载安装及Windows开发环境设置>介绍了FFmpeg的下载安装及环境配置,本文介绍最简单的FFmpeg视频解码示例。 2 视频解码过程 本文只讨论视频解码。 FFmpeg视频解码的过程比较简单,实际就4步: 打开媒体流获取…...

SpringCloud深入理解 | 生产者、消费者
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! SpringCloud Spring Cloud是一组用于构建分布式系统和微服务架构的开源框架和工具集合。它是在Spring生态系统的基础上构建的,旨在简化开发人员构建分布式…...

web题型
0X01 命令执行 漏洞原理 没有对用户输入的内容进行一定过滤直接传给shell_exec、system一类函数执行 看一个具体例子 cmd1|cmd2:无论cmd1是否执行成功,cmd2将被执行 cmd1;cmd2:无论cmd1是否执行成功,cmd2将被执行 cmd1&cmd2:无论cmd1是否执行成…...
使用curl和postman调用Azure OpenAI Restful API
使用curl在cmd中调用时,注意:json大括号内的每一个双引号前需要加上\ curl https://xxxopenai.openai.azure.com/openai/deployments/Your_deployid/chat/completions?api-version2023-05-15 -H "Content-Type: application/json" -H "…...

草莓叶病害数据集
1.草莓数据集有两个文件夹 训练集 健康文件夹(2819张) 草莓叶焦病害(3327张) 数据集可以关注最后一行 import numpy as np import os import matplotlib.pyplot as plt import cv2import warnings warnings.filterwarnings(igno…...
安卓音视频多对多级联转发渲染
最近利用自己以前学习和用到的音视频知识和工程技能做了一个android的sdk,实现了本地流媒体ipc rtsp 拉流以及自带mip usb等camera audio节点产生的流媒体通过webrtc sfu的方式进行多对多级联发布共享,网状结构,p2p组网,支持实时渲染以及转推rtmp&#x…...
OpenART mini的代码移植到OpenMV)
2023年电赛---运动目标控制与自动追踪系统(E题)OpenART mini的代码移植到OpenMV
前言 (1)已经有不少同学根据我上一篇博客完成了前三问,恭喜恭喜。有很多同学卡在了第四问。 (2)我说了OpenART mini的代码是可行的。但是他们不会移植到OpenMV上,再次我讲移植之后的代码贴出来。 ÿ…...

SAP CAP篇十二:AppRouter 深入研究
本文目录 本系列文章理解现有程序app文件夹中的package.json理解approuter.js 修改现有程序修改package.json新建index.js在Approuter中显示额外的逻辑 添加一些额外的Logger对应代码及branch 本系列文章 SAP CAP篇一: 快速创建一个Service,基于Java的实现 SAP CAP…...

HDFS中数据迁移的使用场景和考量因素
HDFS中数据迁移的使用场景和考量因素 数据迁移使用场景数据迁移要素考量HDFS分布式拷贝工具-DistCpdistcp的优势性能命令 数据迁移使用场景 冷热集群数据同步、分类存储集群数据整体搬迁 当公司业务迅速的发展,导致的当前的服务器数量资源出现临时紧张的时候&#…...

科普 | 以太坊坎昆升级是什么
坎昆升级是什么 坎昆,是墨西哥一个著名的旅游城市,也是 Devcon 3 大会的举办地,按照以太坊升级命名的规律,以地名命名的升级,是针对以太坊执行层的升级。 之前同样命名的还有柏林升级、伦敦升级和这次的上海升级等。…...

C# 一些知识整理
C#反射和特性 反射Reflection Type 类型 Name NameSpace Assembly GetFields() GetProperties() GetMethods() 特性Attribute Obsolete弃用 Condit…...
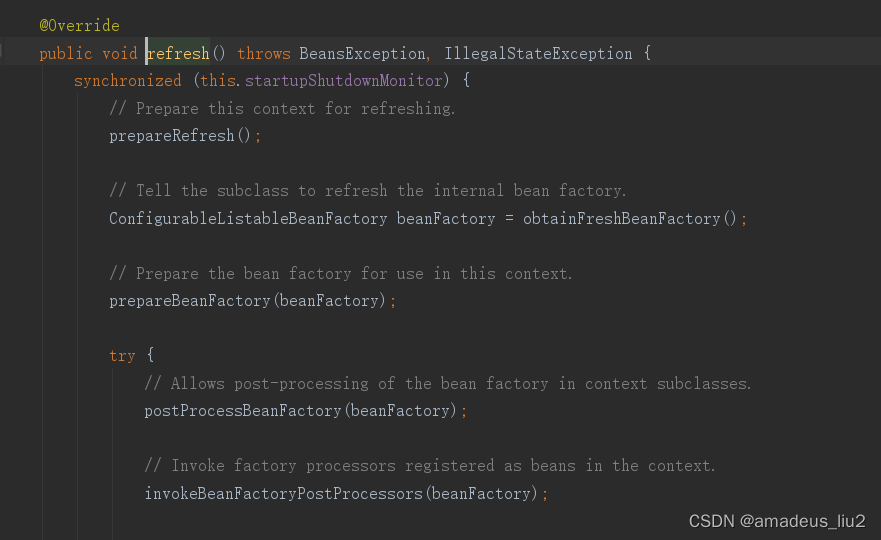
SpringBoot复习:(15)Spring容器的核心方法refresh是在哪里被调用的?
在SpringApplication的run方法: refreshContext代码如下: 其中调用的refresh方法代码如下: 其中调用的refresh方法代码如下: 其中调用的fresh方法代码如下: 其中调用了super.refresh();而这个super.refresh()就是…...

Android安卓实战项目(5)---完整的健身APP基于安卓(源码在文末)可用于比赛项目或者作业参考中
Android安卓实战项目(5)—完整的健身APP(源码在文末🐕🐕🐕)可用于比赛项目 一.项目运行介绍 1.大致浏览 【bilibili视频】 https://www.bilibili.com/video/BV1uX4y177iR/? (1&…...
11.2-存储处理与Block)
AutoSAR系列讲解(实践篇)11.2-存储处理与Block
目录 一、NVRAM Block NVRAM Block的类型 二、Fee Block 三、Ea Block 四、总结 同通信的PDU一样,存储功能也需要一些特殊的数据结构来存放和管理我们的NV数据(NV data) 一、NVRAM Block NVRAM Block的作用类似于IPDU,但它们两仅仅只是作用上相似,其功能实现是完全…...
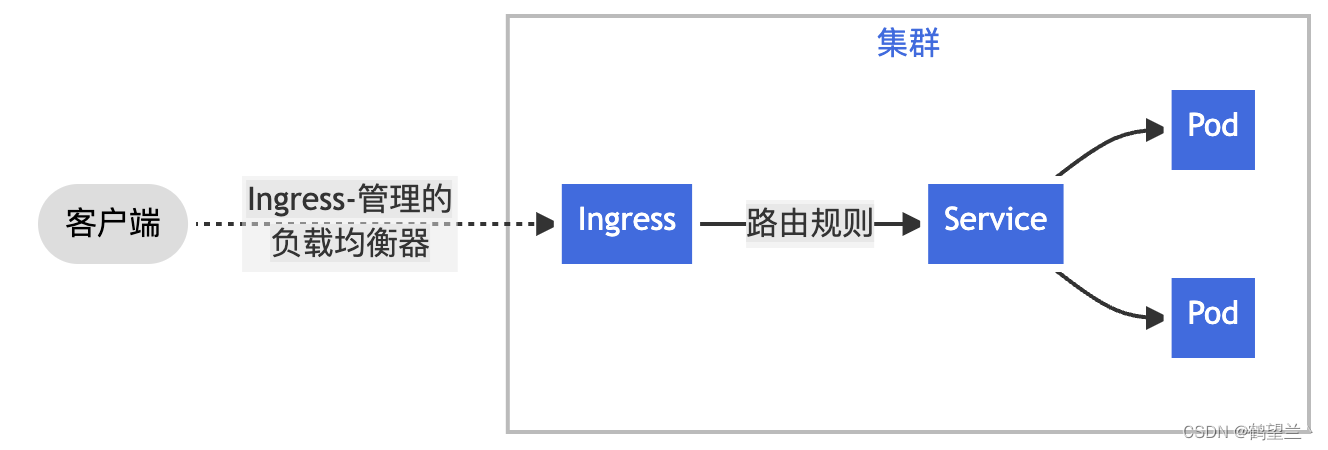
K8s总结
K8s 是什么 Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的机制…...
3.playbook剧本二
文章目录 playbook二Roles模块roles模式安装LNMP创建nginxfiles目录handlers目录tasks目录templates目录vars目录 创建mysqltasks目录 创建phpfiles目录handlers目录tasks目录templates目录vars目录 创建LNMP剧本文件 playbook二 Roles模块 角色的作用:把playbook…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

Armv9-A架构解析:SVE/SME与安全增强技术
1. Armv9-A架构演进与核心特性全景Armv9-A架构代表了Arm公司面向未来十年计算需求的设计哲学,其核心在于三个维度的突破:性能、安全与专用计算。作为长期从事Arm架构开发的工程师,我见证了从Armv7到Armv9的技术跃迁。与固定宽度向量指令的NEO…...

【Midjourney霓虹效果终极指南】:20年AI视觉工程师亲授5大参数组合+3类光源建模公式,97%新手一周内复刻赛博朋克海报
更多请点击: https://kaifayun.com 第一章:霓虹美学的视觉原理与Midjourney适配性解析 霓虹美学源于20世纪都市夜景中的荧光灯管、电子广告与赛博朋克文化,其核心视觉特征包括高饱和度冷暖对比、边缘辉光(glow)、深色…...