论文代码学习—HiFi-GAN(4)——模型训练函数train文件具体解析
文章目录
- 引言
- 正文
- 模型训练代码
- 整体训练过程
- 具体训练细节
- 具体运行流程
- 多GPU编程
- main函数(通用代码)
- 完整代码
- 总结
- 引用
引言
- 这里翻译了HiFi-GAN这篇论文的具体内容,具体链接。
- 这篇文章还是学到了很多东西,从整体上说,学到了生成对抗网络的构建思路,包括生成器和鉴定器。细化到具体实现的细节,如何 实现对于特定周期的数据处理?在细化,膨胀卷积是如何实现的?这些通过文章,仅仅是了解大概的实现原理,但是对于代码的实现细节并不是很了解。如果要加深印象,还是要结合代码来具体看一下实现的细节。
- 本文主要围绕具体的代码实现细节展开,对于相关原理,只会简单引用和讲解。因为官方代码使用的是pytorch,所以是通过pytorch展开的。
- 关于模型其他部分的介绍,链接如下
- 论文代码学习(1)—HiFi-GAN——生成器generator代码
- 论文代码学习—HiFi-GAN(2)——鉴别器discriminator代码
- 论文代码学习—HiFi-GAN(3)——模型loss函数解析
- 当前文章,主要是围绕模型的训练文件展开,训练文件也是调用整个模型,导入数据,进行训练并保存模型的主要文件,定义了前向传播,反向传播,loss计算过程等十分重要的内容。这里主要分模块讲解train文件的训练。
正文
- 整个train文件需要完成调用模型,加载数据进行训练和对训练结果进行记录等功能,是主要的运行程序。具体功能如下:
- 模型定义:定义生成器和判别器
- 指定优化器和学习率:指定AdamW优化器,并定义指数学习率调度器
- 数据加载:使用Dataloader加载训练和验证数据
- 定义训练过程:指定前向传播、loss计算和反向传播的过程
- 验证和日志记录:模型测试,并使用TensorBoard记录训练过程
- 整体的训练文件代码太多了,并且牵扯到很多分布式训练的过程,所以这里是先提出和模型相关的代码,然后在分布式训练的代码进行学习.
模型训练代码
-
这部分主要是按照模型一个模型具体的训练过程展开的,主要是按照如下步骤
- 创建模型的实例对象
- 定义模型训练优化器
- 定义学习率调度优化器(根据上一步进行定义)
- 加载训练数据
- 将模型定义为训练模式
- 遍历数据并移动到设备
- 梯度归零
- 前向传播
- 计算损失
- 反向传播和梯度更新
- 更新学习率调度器
-
但是实际上作者在训练的过程中,并不是严格按照这个步骤进行更新的,他是先训练了鉴定器,然后在训练生成器的过程中又重新对鉴定器进行了一次前向传播,使用鉴定器的结果输出,来反向传播影响生成器的权重.
整体训练过程
- 两次的计算图不一样哦,现实单独优化计算生成器,然后第二次是当作整体进行计算的,然后整体优化生成器的权重.
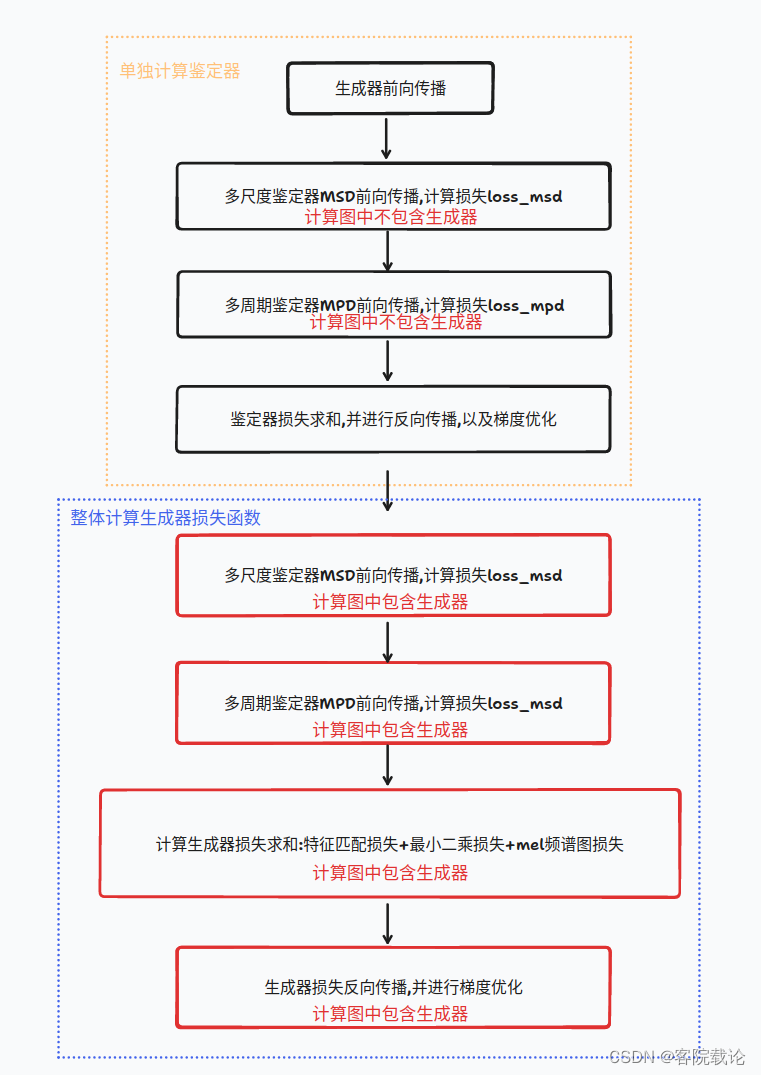
具体训练细节
- 1 创建模型实例对象
- 首先创建对应生成器,判别器的实例对象,并且将之放置到设备上
# 创建生成器和鉴定器,并将之放置在设备上generator = Generator(h).to(device)mpd = MultiPeriodDiscriminator().to(device)msd = MultiScaleDiscriminator().to(device)
- 2 定义模型训练优化器
- 指定鉴定器和生成器的优化器是AdamW
- AdamW是Adam的一种变体,是在Adam上引入了权重衰减的修正.
- 注意:在声明优化器时都需要传入需要影响的模型参数,对于鉴定器而言,这里就给优化器传入了两个模型的参数
optim_g = torch.optim.AdamW(generator.parameters(), h.learning_rate, betas=[h.adam_b1, h.adam_b2])
# 注意这里,判别器的优化器会影响多尺度判别器MSD和多周期判别器MPD
optim_d = torch.optim.AdamW(itertools.chain(msd.parameters(), mpd.parameters()),h.learning_rate, betas=[h.adam_b1, h.adam_b2])
- torch.optim.AdamW的参数说明

- 3 定义学习率调度器
- 在训练过程中,动态调整学习率,以便能够更好地训练模型.这两个调度器适用于生成器和判别器两个优化器,
- ExponentialLR:指数衰减学习率调度器,在每一个epoch后乘以一个给定的常数因子
- 调用学习率参数调度器时,需要指定模型对应的优化器
scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=h.lr_decay, last_epoch=last_epoch)
scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=h.lr_decay, last_epoch=last_epoch)
- 4 加载训练数据
- 项目中,并没有直接的mel频谱图,是将音频转换成mel频谱图的,所以具体步骤如下
- 读取音频文件,将音频文件转为mel频谱图,创建DataLoader数据加载对象
- 项目中,并没有直接的mel频谱图,是将音频转换成mel频谱图的,所以具体步骤如下
# 获取训练文件的列表training_filelist, validation_filelist = get_dataset_filelist(a)# 将音频文件转为mel频谱图trainset = MelDataset(training_filelist, h.segment_size, h.n_fft, h.num_mels,h.hop_size, h.win_size, h.sampling_rate, h.fmin, h.fmax, n_cache_reuse=0,shuffle=False if h.num_gpus > 1 else True, fmax_loss=h.fmax_for_loss, device=device,fine_tuning=a.fine_tuning, base_mels_path=a.input_mels_dir)# 创建DataLoader数据加载对象 train_loader = DataLoader(trainset, num_workers=h.num_workers, shuffle=False,sampler=train_sampler,batch_size=h.batch_size,pin_memory=True,drop_last=True)# 创建验证集的数据加载对象validset = MelDataset(validation_filelist, h.segment_size, h.n_fft, h.num_mels,h.hop_size, h.win_size, h.sampling_rate, h.fmin, h.fmax, False, False, n_cache_reuse=0,fmax_loss=h.fmax_for_loss, device=device, fine_tuning=a.fine_tuning,base_mels_path=a.input_mels_dir)validation_loader = DataLoader(validset, num_workers=1, shuffle=False,sampler=None,batch_size=1,pin_memory=True,drop_last=True)
- 5 将模型指定为训练模式
- pytorch中模型有两种模式,分别是训练模式(training model)和评估模式(evaluation mode)
- 训练模式 training mode:
- Dropout层会将一些神经元输出设置为0
- BatchNorm层会使用mini-batch的统计数据进行归一化
- 评估模式 evaluation mode
- Dropout层不会改变任何神经元的输出
- BatchNorm层会使用整个训练集的统计数据进行归一化
- 在这里,需要对模型进行训练,所以需要将模型的模式设置为train
# 设置模型为训练模式
generator.train()
mpd.train()
msd.train()
- 6 循环遍历数据并移动到设备
- 功能描述:
- 遍历数据中的每一个batch,然后将数据移动到设备上
- 知识补充:
- 在pytorch中,需要将数据封装成variable变量,才能放到设备上参与训练
- unsqueeze是将給数据在增加一个维度,使y和其他的数据维度一致
- 非阻塞模式:快速相应,某些操作没有完成,立刻返回,不会陷入阻塞等待
- 功能描述:
# 遍历数据批次
for i, batch in enumerate(train_loader):# 判定是否为主线程if rank == 0:start_b = time.time()# 从当前的批次中获取输入数据x,目标输出y,以及梅尔频谱图y_mel x, y, _, y_mel = batch# 将所有的数据封装为pytorch的变量Variable对象,并将之移动到指定的设备上x = torch.autograd.Variable(x.to(device, non_blocking=True))y = torch.autograd.Variable(y.to(device, non_blocking=True))y_mel = torch.autograd.Variable(y_mel.to(device, non_blocking=True))# 调整目标输出的维度,增加了目标输出y的维度,确保y和模型的输出y_hat的维度一致y = y.unsqueeze(1)
- 7 梯度清零
- 在每一次训练之前,都需要将模型梯度清零,避免梯度的累积
# 判别器梯度清零optim_d.zero_grad()# Generator# 生成器梯度清零optim_g.zero_grad()
- 8 前向传播
- 前向传播分为三个部分
- 生成器调用mel频谱图生成波形图y_g_hat
- 多周期判别器接受y_g_hat(生成器生成波形图),
- y_df_hat_r表示对于真实数据的判别结果,
- y_df_hat_g表示对于生成数据的判别结果
- 多尺度判别器接受y_g_hat(生成器生成波形图)
- y_ds_hat_r表示对于真实数据的判别结果,
- y_ds_hat_g表示对于生成数据的判别结果
- 前向传播分为三个部分
# 生成器生成结果
y_g_hat = generator(x)
# 多周期判别器生成结果
y_df_hat_r, y_df_hat_g, _, _ = mpd(y, y_g_hat.detach())
# 多尺度判别器生成结果
y_ds_hat_r, y_ds_hat_g, _, _ = msd(y, y_g_hat.detach())
- 9 计算损失
- 两部分损失
- 生成器损失:mel损失+特征匹配损失+最小二乘损失
- 注意,生成器的损失也是根据判别器进行确定,是两个判别器损失之和
- 判别器损失:msd多尺度判别器损失+mpd多周期判别器损失
- 生成器损失:mel损失+特征匹配损失+最小二乘损失
- 两部分损失
# 将生成器的生成的波形图y_g_hat生成为对应mel频谱图
y_g_hat_mel = mel_spectrogram(y_g_hat.squeeze(1), h.n_fft, h.num_mels, h.sampling_rate, h.hop_size, h.win_size,h.fmin, h.fmax_for_loss)
# L1 Mel-Spectrogram Loss
# 生成器的L1损失
loss_mel = F.l1_loss(y_mel, y_g_hat_mel) * 45# 计算两个判别器的损失
# loss_disc_f是多周期判别器的损失
# loss_disc_s是多尺度判别器的损失
# losses_disc_f_r, losses_disc_f_g分别是每一层的多周期鉴定器对于真实数据和生成数据判别结果
# losses_disc_s_r, losses_disc_s_g 分别是每一层的多尺度鉴定器对于真实数据和生成数据判别结果
loss_disc_f, losses_disc_f_r, losses_disc_f_g = discriminator_loss(y_df_hat_r, y_df_hat_g)
loss_disc_s, losses_disc_s_r, losses_disc_s_g = discriminator_loss(y_ds_hat_r, y_ds_hat_g)
loss_disc_all = loss_disc_s + loss_disc_f# 计算生成器损失,包括mel频谱图的L1损失\特征匹配损失和生成器损失
y_df_hat_r, y_df_hat_g, fmap_f_r, fmap_f_g = mpd(y, y_g_hat)
y_ds_hat_r, y_ds_hat_g, fmap_s_r, fmap_s_g = msd(y, y_g_hat)
loss_fm_f = feature_loss(fmap_f_r, fmap_f_g)
loss_fm_s = feature_loss(fmap_s_r, fmap_s_g)
loss_gen_f, losses_gen_f = generator_loss(y_df_hat_g)
loss_gen_s, losses_gen_s = generator_loss(y_ds_hat_g)
loss_gen_all = loss_gen_s + loss_gen_f + loss_fm_s + loss_fm_f + loss_mel
-
注意:
- 下面关于判别器前向传播的两次使用目的不同
- mpd(y, y_g_hat)和msd(y, y_g_hat)
- 上面的并没有将y_g_hat从计算图中剥离出来,是通过鉴定器的反馈来影响计算生成器的权重
- mpd(y, y_g_hat.detach())和msd(y, y_g_hat.detach())
- 上面将y_g_hat从计算图中剥离出来,是单纯训练鉴定器的权重参数
-
10 反向传播和梯度更新
- 计算完对应的权重之后,在进行反向传播,然后进行梯度更新
# 反向传播鉴别器的损失loss_disc_all.backward()# 梯度更新optim_d.step()# 反向传播生成器的损失loss_gen_all.backward()# 执行梯度优化optim_g.step()
- 11 更新学习率调度器
- 更新学习率
# 更新学习率调度器
scheduler_g.step()
scheduler_d.step()
具体运行流程
- 具体如下图,绿色的是专门用来对判别器的参数进行优化的,蓝色的是专门用来对生成器的参数进行优化的.
- 可以看到调用了两次msd判别器和mpd判别器对模型进行优化,但是效果不一样
- 第一次调用是绿框
- 分别对两个判别器进行了误差计算和反向传播,并且更新模型参数,但是传入y_g_hat时使用detach
- 在更新判别器的权重时,需要固定生成器的权重,防止相互影响
- 分别对两个判别器进行了误差计算和反向传播,并且更新模型参数,但是传入y_g_hat时使用detach
- 第二次调用是蓝框
- 仅仅是单纯调用了两个判别器进行前向传播**,并没有进行误差计算和反向传播**
- 根据两个判别器的反馈,来更新生成器的权重,需要计算与y_h_hat的梯度
- 仅仅是单纯调用了两个判别器进行前向传播**,并没有进行误差计算和反向传播**
- 第一次调用是绿框
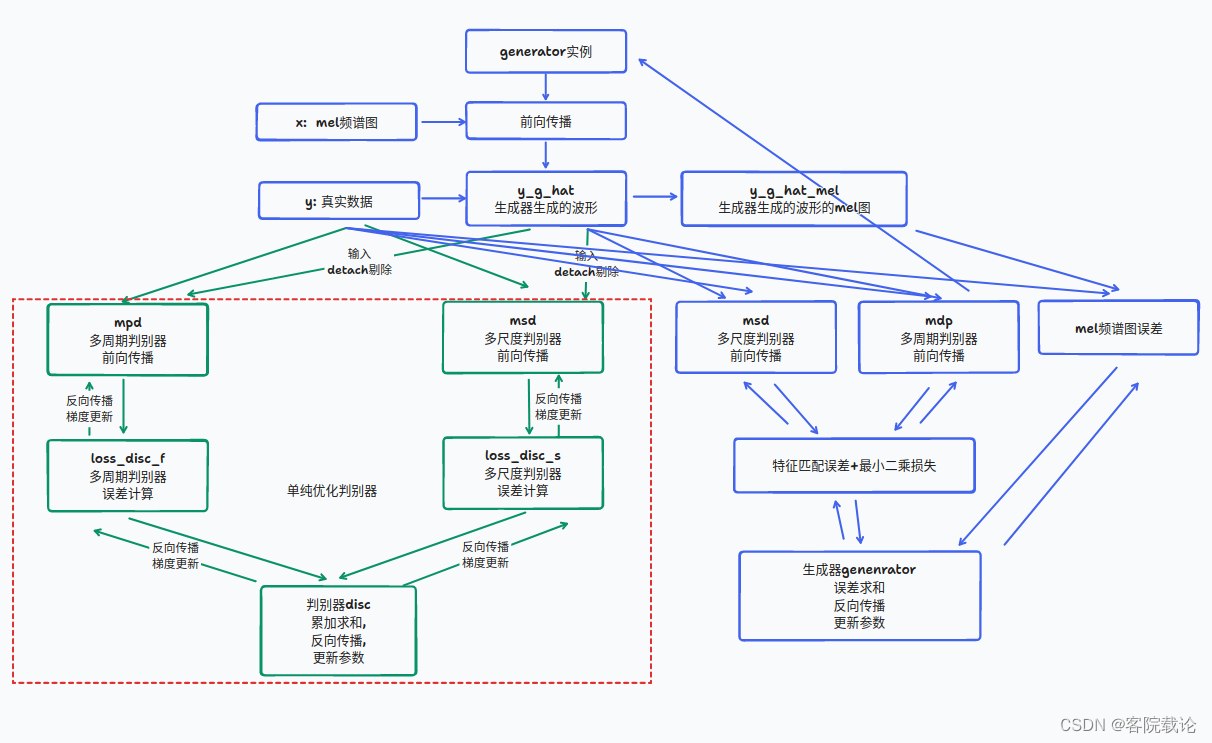
多GPU编程
-
在这个项目的代码中,写了多个GPU同时训练的代码,这里并不是重点,但是还是用来学习使用一下.
-
1 使用多线进程进行训练
- 可以使用torch.multiprocessing管理多进程的训练,具体使用如下
import torch.multiprocessing as mpdef train(rank):# 训练模型的代码if __name__ == '__main__':mp.spawn(train, nprocs=num_gpus)
- 2 实现数据的分布式并行训练
- DistributedDataParallel(DDP)实现了分布式数据并行训练。DDP通过分割mini-batch并将工作分配给多个设备来实现。
if h.num_gpus > 1:generator = DistributedDataParallel(generator, device_ids=[rank]).to(device)mpd = DistributedDataParallel(mpd, device_ids=[rank]).to(device)msd = DistributedDataParallel(msd, device_ids=[rank]).to(device)
-
3 多进程中的进程编号和分类
- 分布式训练中,每一个进程都有一个唯一的标识符,称为"秩",rank
- rank = 0;表示主进程,执行特殊人物,用于日志记录, 检查点保存 ,验证等. 其他进程只负责训练
- 通过检查rank == 0,代码确保某些操作(例如打印训练进度、保存模型检查点等)只在主进程中执行一次,而不是在每个进程中都执行。这有助于避免重复的日志记录和其他可能的冲突。
- 在分布式训练中,所有进程通常并行运行相同的代码,但通过使用秩,可以在不同的进程中实现不同的行为。这是一种常见的编程模式,用于确保分布式系统的协调和效率。
-
到此为止吧,这里暂时不做过多的解释,他的代码直接可以使用,因为那个代码包含了多GPU和单GPU训练的代码, 是兼容的.可以直接使用.
main函数(通用代码)
- 基本上在好多项目中,都看到了下面的代码,检测有几个GPU,然后进行多GPU的训练。加载参数进行训练,然后直接命令行调用。这样很高校,将所有的文件都集中在一个地方。
def main():print('Initializing Training Process..')parser = argparse.ArgumentParser()# 加载并解析参数# group_name表示分组名称parser.add_argument('--group_name', default=None)# input_wavs_dir表示输入的音频文件夹parser.add_argument('--input_wavs_dir', default='LJSpeech-1.1/wavs')# input_mels_dir表示输入的mel谱文件夹parser.add_argument('--input_mels_dir', default='ft_dataset')# input_training_file表示输入的训练文件parser.add_argument('--input_training_file', default='LJSpeech-1.1/training.txt')# input_validation_file表示输入的验证文件parser.add_argument('--input_validation_file', default='LJSpeech-1.1/validation.txt')# checkpoint_path表示检查点路径parser.add_argument('--checkpoint_path', default='cp_hifigan')# config表示配置文件parser.add_argument('--config', default='')# training_epoches训练的总周期数。默认值为3100。parser.add_argument('--training_epochs', default=3100, type=int)# stdout_interval: 标准输出日志的间隔步数。默认值为5。parser.add_argument('--stdout_interval', default=5, type=int)# checkpoint_interval: 检查点保存的间隔步数。默认值为5000。parser.add_argument('--checkpoint_interval', default=5000, type=int)# summary_interval: TensorBoard摘要记录的间隔步数。默认值为100。parser.add_argument('--summary_interval', default=100, type=int)# validation_interval: 验证的间隔步数。默认值为1000。parser.add_argument('--validation_interval', default=1000, type=int)# fine_tuning: 是否进行微调。默认值为False。parser.add_argument('--fine_tuning', default=False, type=bool)a = parser.parse_args()# 读取配置文件with open(a.config) as f:data = f.read()# 解析json文件json_config = json.loads(data)# 将json文件转换为字典h = AttrDict(json_config)# 根据配置文件创建对应文件build_env(a.config, 'config.json', a.checkpoint_path)# 设置随机种子,确保训练的可重复性torch.manual_seed(h.seed)# 检测GPU,如果多个GPU就同时训练if torch.cuda.is_available():torch.cuda.manual_seed(h.seed)h.num_gpus = torch.cuda.device_count()h.batch_size = int(h.batch_size / h.num_gpus)print('Batch size per GPU :', h.batch_size)else:passif h.num_gpus > 1:# 多个GPU的训练方式mp.spawn(train, nprocs=h.num_gpus, args=(a, h,))else:# 一个GPU的训练方式train(0, a, h)
完整代码
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import itertools
import os
import time
import argparse
import json
import torch
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DistributedSampler, DataLoader
import torch.multiprocessing as mp
from torch.distributed import init_process_group
from torch.nn.parallel import DistributedDataParallel
from env import AttrDict, build_env
from meldataset import MelDataset, mel_spectrogram, get_dataset_filelist
from models import Generator, MultiPeriodDiscriminator, MultiScaleDiscriminator, feature_loss, generator_loss,\discriminator_loss
from utils import plot_spectrogram, scan_checkpoint, load_checkpoint, save_checkpointtorch.backends.cudnn.benchmark = Truedef train(rank, a, h):# 基本步骤:多个GPU,则初始化分布训练组if h.num_gpus > 1:init_process_group(backend=h.dist_config['dist_backend'], init_method=h.dist_config['dist_url'],world_size=h.dist_config['world_size'] * h.num_gpus, rank=rank)# 基本步骤:初始化随机种子torch.cuda.manual_seed(h.seed)# 基本步骤:设备命名device = torch.device('cuda:{:d}'.format(rank))# 创建生成器和鉴定器,并将之放置在设备上generator = Generator(h).to(device)mpd = MultiPeriodDiscriminator().to(device)msd = MultiScaleDiscriminator().to(device)# 如果是主进程,就打印生成器并且创建检查点目录if rank == 0:print(generator)os.makedirs(a.checkpoint_path, exist_ok=True)print("checkpoints directory : ", a.checkpoint_path)# 检查是否存在检查点,如果存在则加载检查点??# 这里的加载检查点是什么意思??if os.path.isdir(a.checkpoint_path):cp_g = scan_checkpoint(a.checkpoint_path, 'g_')cp_do = scan_checkpoint(a.checkpoint_path, 'do_')steps = 0if cp_g is None or cp_do is None:state_dict_do = Nonelast_epoch = -1else:state_dict_g = load_checkpoint(cp_g, device)state_dict_do = load_checkpoint(cp_do, device)generator.load_state_dict(state_dict_g['generator'])mpd.load_state_dict(state_dict_do['mpd'])msd.load_state_dict(state_dict_do['msd'])steps = state_dict_do['steps'] + 1last_epoch = state_dict_do['epoch']# 如果有多个GPU,就是用分布式数据并行if h.num_gpus > 1:generator = DistributedDataParallel(generator, device_ids=[rank]).to(device)mpd = DistributedDataParallel(mpd, device_ids=[rank]).to(device)msd = DistributedDataParallel(msd, device_ids=[rank]).to(device)# 定义优化器optim_g = torch.optim.AdamW(generator.parameters(), h.learning_rate, betas=[h.adam_b1, h.adam_b2])optim_d = torch.optim.AdamW(itertools.chain(msd.parameters(), mpd.parameters()),h.learning_rate, betas=[h.adam_b1, h.adam_b2])# 如果存在检查点,就加载优化器的状态if state_dict_do is not None:optim_g.load_state_dict(state_dict_do['optim_g'])optim_d.load_state_dict(state_dict_do['optim_d'])# 定义学习率调度器scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=h.lr_decay, last_epoch=last_epoch)scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=h.lr_decay, last_epoch=last_epoch)training_filelist, validation_filelist = get_dataset_filelist(a)trainset = MelDataset(training_filelist, h.segment_size, h.n_fft, h.num_mels,h.hop_size, h.win_size, h.sampling_rate, h.fmin, h.fmax, n_cache_reuse=0,shuffle=False if h.num_gpus > 1 else True, fmax_loss=h.fmax_for_loss, device=device,fine_tuning=a.fine_tuning, base_mels_path=a.input_mels_dir)# 创建分布式采样器train_sampler = DistributedSampler(trainset) if h.num_gpus > 1 else Nonetrain_loader = DataLoader(trainset, num_workers=h.num_workers, shuffle=False,sampler=train_sampler,batch_size=h.batch_size,pin_memory=True,drop_last=True)if rank == 0:validset = MelDataset(validation_filelist, h.segment_size, h.n_fft, h.num_mels,h.hop_size, h.win_size, h.sampling_rate, h.fmin, h.fmax, False, False, n_cache_reuse=0,fmax_loss=h.fmax_for_loss, device=device, fine_tuning=a.fine_tuning,base_mels_path=a.input_mels_dir)validation_loader = DataLoader(validset, num_workers=1, shuffle=False,sampler=None,batch_size=1,pin_memory=True,drop_last=True)sw = SummaryWriter(os.path.join(a.checkpoint_path, 'logs'))# 设置模型为训练模式generator.train()mpd.train()msd.train()# 开始训练循环for epoch in range(max(0, last_epoch), a.training_epochs):if rank == 0:start = time.time()print("Epoch: {}".format(epoch+1))# 如果有多个GPU,就设置分布式数据并行的采样器if h.num_gpus > 1:train_sampler.set_epoch(epoch)# 遍历数据批次for i, batch in enumerate(train_loader):if rank == 0:start_b = time.time()# 从当前的批次中获取输入数据x,目标输出y,以及梅尔频谱图y_melx, y, _, y_mel = batch# 将所有的数据封装为pytorch的变量Variable对象,并将之移动到指定的设备上x = torch.autograd.Variable(x.to(device, non_blocking=True))y = torch.autograd.Variable(y.to(device, non_blocking=True))y_mel = torch.autograd.Variable(y_mel.to(device, non_blocking=True))# 调整目标输出的维度,增加了目标输出y的维度,确保y和模型的输出y_hat的维度一致y = y.unsqueeze(1)# 生成器生成y_g_hat = generator(x)y_g_hat_mel = mel_spectrogram(y_g_hat.squeeze(1), h.n_fft, h.num_mels, h.sampling_rate, h.hop_size, h.win_size,h.fmin, h.fmax_for_loss)# 判别器梯度清零optim_d.zero_grad()# MPD# 多周期判别器的损失y_df_hat_r, y_df_hat_g, _, _ = mpd(y, y_g_hat.detach())loss_disc_f, losses_disc_f_r, losses_disc_f_g = discriminator_loss(y_df_hat_r, y_df_hat_g)# MSD# 多尺度判别器生成的数据y_ds_hat_r, y_ds_hat_g, _, _ = msd(y, y_g_hat.detach())loss_disc_s, losses_disc_s_r, losses_disc_s_g = discriminator_loss(y_ds_hat_r, y_ds_hat_g)# 总的判别器损失loss_disc_all = loss_disc_s + loss_disc_f# 反向传播鉴别器的损失loss_disc_all.backward()optim_d.step()# Generator# 生成器梯度清零optim_g.zero_grad()# L1 Mel-Spectrogram Loss# 生成器的L1损失loss_mel = F.l1_loss(y_mel, y_g_hat_mel) * 45# 计算生成器损失,包括mel频谱图的L1损失\特征匹配损失和生成器损失y_df_hat_r, y_df_hat_g, fmap_f_r, fmap_f_g = mpd(y, y_g_hat)y_ds_hat_r, y_ds_hat_g, fmap_s_r, fmap_s_g = msd(y, y_g_hat)loss_fm_f = feature_loss(fmap_f_r, fmap_f_g)loss_fm_s = feature_loss(fmap_s_r, fmap_s_g)loss_gen_f, losses_gen_f = generator_loss(y_df_hat_g)loss_gen_s, losses_gen_s = generator_loss(y_ds_hat_g)loss_gen_all = loss_gen_s + loss_gen_f + loss_fm_s + loss_fm_f + loss_mel# 反向传播生成器的损失loss_gen_all.backward()# 执行梯度优化optim_g.step()# 如果是主进程,进行日志记录 检查点保存和验证if rank == 0:# STDOUT logging# 标准输出日志if steps % a.stdout_interval == 0:with torch.no_grad():mel_error = F.l1_loss(y_mel, y_g_hat_mel).item()print('Steps : {:d}, Gen Loss Total : {:4.3f}, Mel-Spec. Error : {:4.3f}, s/b : {:4.3f}'.format(steps, loss_gen_all, mel_error, time.time() - start_b))# checkpointing# 检查点保存if steps % a.checkpoint_interval == 0 and steps != 0:checkpoint_path = "{}/g_{:08d}".format(a.checkpoint_path, steps)save_checkpoint(checkpoint_path,{'generator': (generator.module if h.num_gpus > 1 else generator).state_dict()})checkpoint_path = "{}/do_{:08d}".format(a.checkpoint_path, steps)save_checkpoint(checkpoint_path, {'mpd': (mpd.module if h.num_gpus > 1else mpd).state_dict(),'msd': (msd.module if h.num_gpus > 1else msd).state_dict(),'optim_g': optim_g.state_dict(), 'optim_d': optim_d.state_dict(), 'steps': steps,'epoch': epoch})# Tensorboard summary logging# tensorboard摘要日志if steps % a.summary_interval == 0:sw.add_scalar("training/gen_loss_total", loss_gen_all, steps)sw.add_scalar("training/mel_spec_error", mel_error, steps)# Validation# 验证if steps % a.validation_interval == 0: # and steps != 0:generator.eval()torch.cuda.empty_cache()val_err_tot = 0with torch.no_grad():for j, batch in enumerate(validation_loader):x, y, _, y_mel = batchy_g_hat = generator(x.to(device))y_mel = torch.autograd.Variable(y_mel.to(device, non_blocking=True))y_g_hat_mel = mel_spectrogram(y_g_hat.squeeze(1), h.n_fft, h.num_mels, h.sampling_rate,h.hop_size, h.win_size,h.fmin, h.fmax_for_loss)val_err_tot += F.l1_loss(y_mel, y_g_hat_mel).item()# 保存音频和频谱图if j <= 4:if steps == 0:sw.add_audio('gt/y_{}'.format(j), y[0], steps, h.sampling_rate)sw.add_figure('gt/y_spec_{}'.format(j), plot_spectrogram(x[0]), steps)sw.add_audio('generated/y_hat_{}'.format(j), y_g_hat[0], steps, h.sampling_rate)y_hat_spec = mel_spectrogram(y_g_hat.squeeze(1), h.n_fft, h.num_mels,h.sampling_rate, h.hop_size, h.win_size,h.fmin, h.fmax)sw.add_figure('generated/y_hat_spec_{}'.format(j),plot_spectrogram(y_hat_spec.squeeze(0).cpu().numpy()), steps)val_err = val_err_tot / (j+1)sw.add_scalar("validation/mel_spec_error", val_err, steps)generator.train()steps += 1# 更新学习率调度器scheduler_g.step()scheduler_d.step()if rank == 0:print('Time taken for epoch {} is {} sec\n'.format(epoch + 1, int(time.time() - start)))def main():print('Initializing Training Process..')parser = argparse.ArgumentParser()# 加载并解析参数# group_name表示分组名称parser.add_argument('--group_name', default=None)# input_wavs_dir表示输入的音频文件夹parser.add_argument('--input_wavs_dir', default='LJSpeech-1.1/wavs')# input_mels_dir表示输入的mel谱文件夹parser.add_argument('--input_mels_dir', default='ft_dataset')# input_training_file表示输入的训练文件parser.add_argument('--input_training_file', default='LJSpeech-1.1/training.txt')# input_validation_file表示输入的验证文件parser.add_argument('--input_validation_file', default='LJSpeech-1.1/validation.txt')# checkpoint_path表示检查点路径parser.add_argument('--checkpoint_path', default='cp_hifigan')# config表示配置文件parser.add_argument('--config', default='')# training_epoches训练的总周期数。默认值为3100。parser.add_argument('--training_epochs', default=3100, type=int)# stdout_interval: 标准输出日志的间隔步数。默认值为5。parser.add_argument('--stdout_interval', default=5, type=int)# checkpoint_interval: 检查点保存的间隔步数。默认值为5000。parser.add_argument('--checkpoint_interval', default=5000, type=int)# summary_interval: TensorBoard摘要记录的间隔步数。默认值为100。parser.add_argument('--summary_interval', default=100, type=int)# validation_interval: 验证的间隔步数。默认值为1000。parser.add_argument('--validation_interval', default=1000, type=int)# fine_tuning: 是否进行微调。默认值为False。parser.add_argument('--fine_tuning', default=False, type=bool)a = parser.parse_args()# 读取配置文件with open(a.config) as f:data = f.read()# 解析json文件json_config = json.loads(data)# 将json文件转换为字典h = AttrDict(json_config)# 根据配置文件创建对应文件build_env(a.config, 'config.json', a.checkpoint_path)# 设置随机种子,确保训练的可重复性torch.manual_seed(h.seed)# 检测GPU,如果多个GPU就同时训练if torch.cuda.is_available():torch.cuda.manual_seed(h.seed)h.num_gpus = torch.cuda.device_count()h.batch_size = int(h.batch_size / h.num_gpus)print('Batch size per GPU :', h.batch_size)else:passif h.num_gpus > 1:# 多个GPU的训练方式mp.spawn(train, nprocs=h.num_gpus, args=(a, h,))else:# 一个GPU的训练方式train(0, a, h)if __name__ == '__main__':main()
总结
- 我觉得在训练过程中关于生成器和鉴定器的前向传播过程中的链接,十分重要,虽然很多东西都是分开算的,但是最终都会同意进行误差反向传播,并且梯度优化也是针对两个分别声明的变量.需要仔细留一下.
- 两次前向传播的计算图不一样,我觉得我现在仅仅是懂了代码框架,并没有懂代码背后的计算图是什么样的.如果有计算图,我应该会更好说明这两次前向传播的过程.
- 然后就是多个GPU同时训练的过程,需要好好学习一下,目前,大部分都是使用单个GPU进行训练学习,对于多个GPU的训练考虑到主线程和其余多个线程的协调关系,对然他已经给你封装好了,你还是需要学习一下,理解才行.
- 这个代码太长了,严重拉慢了我的进度,所以就挑重点阅读学习了一下,下次有空可以整体学习一下这个代码.
引用
- chatGPT-plus
- HiFi-GAN demo
- HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
相关文章:
论文代码学习—HiFi-GAN(4)——模型训练函数train文件具体解析
文章目录 引言正文模型训练代码整体训练过程具体训练细节具体运行流程 多GPU编程main函数(通用代码)完整代码 总结引用 引言 这里翻译了HiFi-GAN这篇论文的具体内容,具体链接。这篇文章还是学到了很多东西,从整体上说,…...
安防视频综合管理合平台EasyCVR可支持的视频播放协议有哪些?
EasyDarwin开源流媒体视频EasyCVR安防监控平台可提供视频监控直播、云端录像、云存储、录像检索与回看、智能告警、平台级联、云台控制、语音对讲、智能分析等能力。 视频监控综合管理平台EasyCVR具备视频融合能力,平台基于云边端一体化架构,具有强大的…...

一张表格讲明白white-space属性。html如何识别\n\r,让这些特殊换行符换行。
大多数标签在展示文本内容的时候都会默认把文本中的空白和换行符去掉,这的确大大的使得文本的排版更加美观了,也怎加了区域的利用率,可是就有一些需求是需要原原本本的展示出原汁原味的文本格式。那该如何展示出文本的内在格式呢?…...

【Linux】编写shell脚本将项目前一天打印的日志进行提取,并且单独保存
业务场景:又到了熟悉的业务场景环节,其实应用上有很多,我们为了方便提取日志中部分关键的内容,对接给其他人也好,方便自己统计也罢,都会比每次我们都去服务器上及时查看,或者下载全部日志再筛选…...

快速搭建单机RocketMQ服务(开发环境)
一、什么是RocketMQ RocketMQ是阿里巴巴开源的一个消息中间件,在阿里内部历经了双十一等很多高并发场景的考验,能够处理亿万级别的消息。2016年开源后捐赠给Apache,现在是Apache的一个顶级项目。 早期阿里使用ActiveMQ,…...
Centos7搭建Apache Storm 集群运行环境
文章目录 1. 安装 Java2. 下载并解压 Storm3. 配置环境变量4. 配置 ZooKeeper5. 配置 Stormstorm.yaml自定义 storm.yamlstorm-env.shlogback/cluster.xml 6. 启动 Storm 集群7. 验证 1. 安装 Java Storm 运行在 Java 平台上,因此需要先安装 Java。你可以使用以下命…...

C语言假期作业 DAY 12
一、选择题 1、请阅读以下程序,其运行结果是( ) int main() { char cA; if(0<c<9) printf("YES"); else printf("NO"); return 0; } A: YES B: NO C: YESNO D: 语句错误 答案解析 正确答案: A 0<c&l…...

2.4在运行时选择线程数量
在运行时选择线程数量 C标准库中对此有所帮助的特性是std::thread::hardware_currency()。这个函数返回一个对于给定程序执行时能够真正并发运行的线程数量的指示。例如,在多核系统上它可能是CPU 核心的数量。它仅仅是一个提示,如果该信息不可用则函数可…...

element-ui中Notification 通知自定义样式、按钮及点击事件
Notification 通知用于悬浮出现在页面角落,显示全局的通知提醒消息。 一、自定义html页面 element-ui官方文档中说明Notification 通知组件的message 属性支持传入 HTML 片段,但是示例只展示了简单的html片段,通常不能满足开发中的更深入需要…...

无头单向非循环单链表、带头双向循环链表
文章内容 1. 链表的概念及结构 2. 链表的分类 3.链表实现 4.代码 文章目录 1. 链表的概念及结构 概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表 中的指针链接次序实现的 。 现实中 数据结构中 链表和顺序表…...
)
UE4/5C++多线程插件制作(二十、源码)
目录 头文件 MultiThreadPlugins.uplugin MultiThreadPlugins.Build.cs MultiThreadPlugins.h MTPPlatform.h MTPManage.h RTPAgendy.h MTPThreadTaskManage.h...

构建稳健的PostgreSQL数据库:备份、恢复与灾难恢复策略
在当今数字化时代,数据成为企业最宝贵的资产之一。而数据库是存储、管理和保护这些数据的核心。PostgreSQL,作为一个强大的开源关系型数据库管理系统,被广泛用于各种企业和应用场景。然而,即使使用了最强大的数据库系统࿰…...
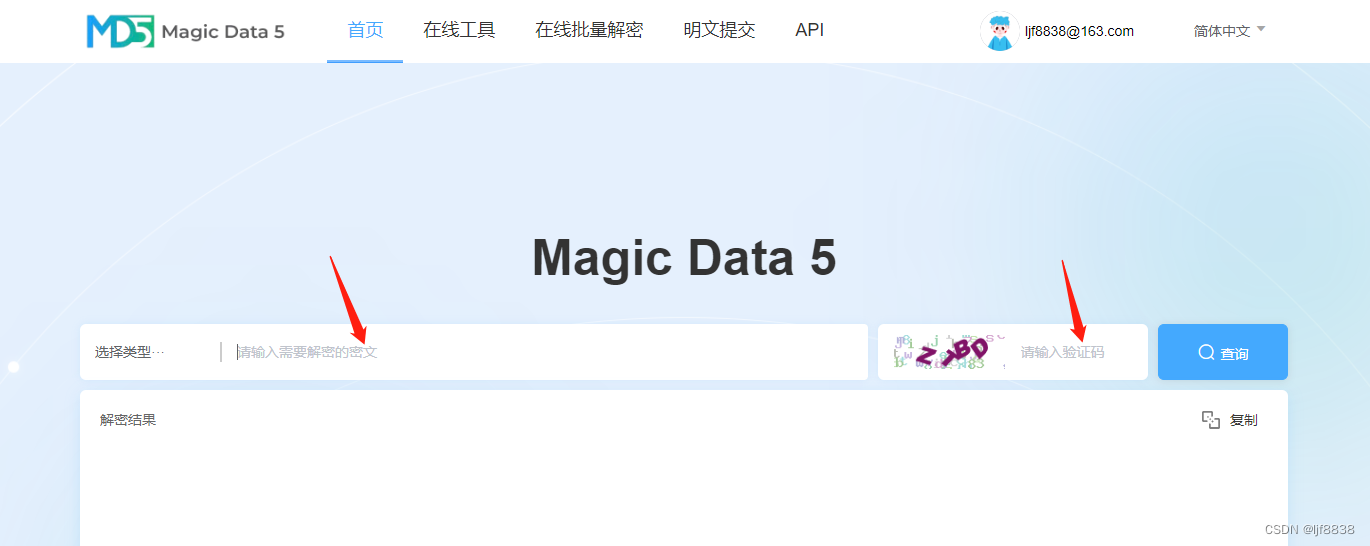
查看本地mysql账号密码
使用Navicat工具打开本地mysql,新建查询输入下面查询语句 SELECT user, authentication_string FROM mysql.user WHERE userroot将authentication_string 中的加密密码复制出来打开链接: Magic Data 5输入加密的密码,和验证码,点…...

数据结构:顺序表详解
数据结构:顺序表详解 一、 线性表二、 顺序表概念及结构1. 静态顺序表:使用定长数组存储元素。2. 动态顺序表:使用动态开辟的数组存储。三、接口实现1. 创建2. 初始化3. 扩容4. 打印5. 销毁6. 尾插7. 尾删8. 头插9. 头删10. 插入任意位置数据…...
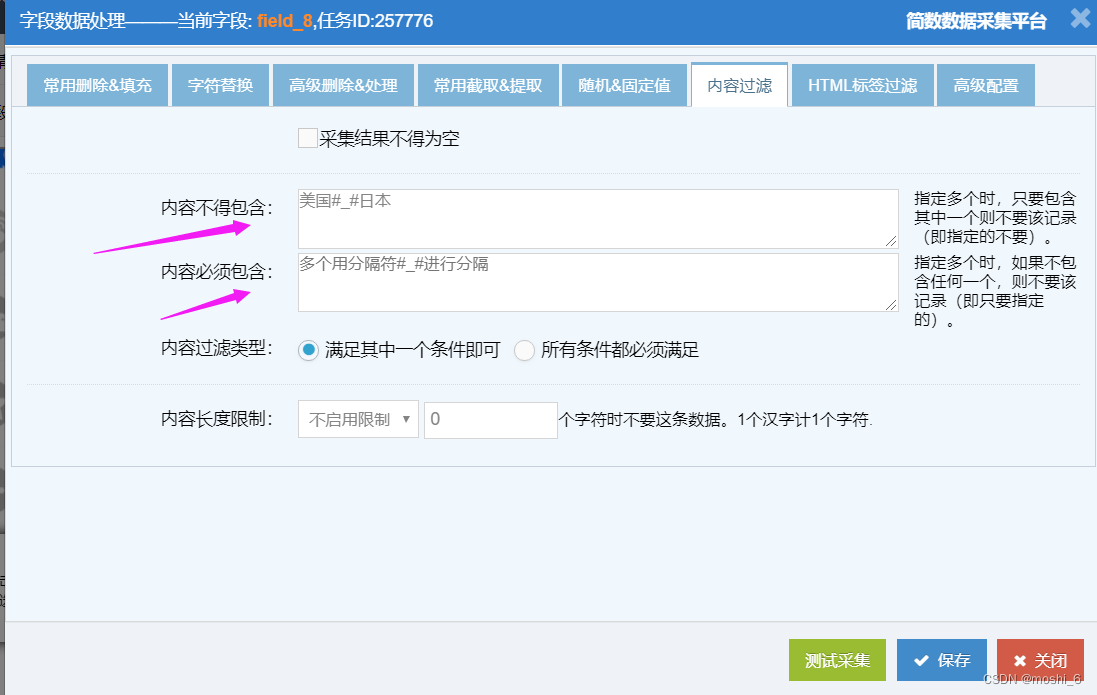
采集数据筛选-过滤不要数据或只保留指定数据
采集文章数据,有时候会遇到一些不需要采集的数据,或者只想采集一些特定的数据,可以使用简数采集器的内容过滤功能,对采集的数据进行筛选,只有符合的数据才采集保留。 可以用于过滤掉一些广告、专题、网站首页等无效数…...

RISC-V基础指令之shift移动指令slli、srli、srai、sll、srl、sra
RISC-V的shift指令是用于对一个寄存器或一个立即数进行位移运算,并将结果存放在另一个寄存器中的指令。位移运算就是把一个操作数的每一位向左或向右移动一定的位数,得到一个新的位。RISC-V的shift指令有以下几种: slli:左逻辑位…...
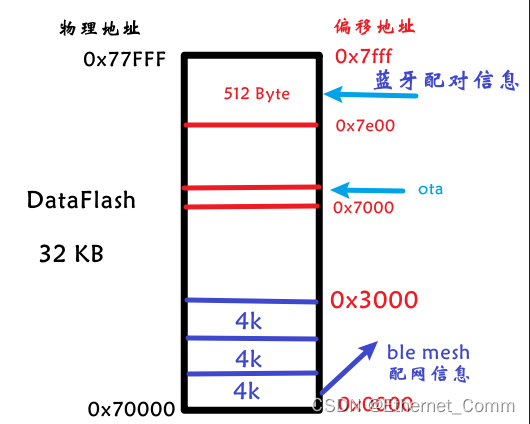
【沁恒蓝牙mesh】CH58x flash分区与数据存储管理
本文主要介绍了 沁恒蓝牙芯片 CH58x 的flash 分区与数据存储管理 📋 个人简介 💖 作者简介:大家好,我是喜欢记录零碎知识点的小菜鸟。😎📝 个人主页:欢迎访问我的 Ethernet_Comm 博客主页&…...
Ctfshow web入门 JWT篇 web345-web350 详细题解 全
CTFshow JWT web345 先看题目,提示admin。 抓个包看看看。 好吧我不装了,其实我知道是JWT。直接开做。 在jwt.io转换后,发现不存在第三部分的签证,也就不需要知道密钥。 全称是JSON Web Token。 通俗地说,JWT的本质…...

2023年国家留学基金委(CSC)青年骨干教师项目即将开始申报
国家留学基金委(以下简称CSC)的青年骨干教师出国研修项目(即高校合作项目),将于2023年9月10-25日进行网上报名及申请受理。知识人网小编特提醒申请者注意流程及政策,以防错过申报时间。 青年骨干教师项目&a…...

GC垃圾回收器【入门笔记】
GC:Garbage Collectors 垃圾回收器 C/C,手动回收内存;难调试、门槛高。忘记回收、多次回收等问题 Java、Golang等,有垃圾回收器:自动回收,技术门槛降低 一、如何定位垃圾? https://www.infoq.c…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...