python-网络爬虫.BS4
BS4
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库, 它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方 式。
Beautiful Soup 4
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
帮助手册:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
一、安装Beautiful Soup
命令行:pip3 install beautifulsoup4
或者:
File--》setting--》Project:xxx--》右侧 “+” ==》查找 Bs4 ==》左下角
install ==>apply ==>确定
二、安装解析器lxml (第三方的解析器,推荐用lxml,速度快,文档容错能 力强)
pip3 install lxml
三、使用
创建bs对象
# 打开本地HTML文件的方式来创建对象
soup = BeautifulSoup(open('xxxx.html')) # 创建Beautiful Sou对象
#打开网上在线HTML文件
url = 'https://jobs.51job.com/ruanjian/'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
其中
soup = BeautifulSoup(html, "lxml") # 指定lxml解析器
或者
soup = BeautifulSoup(url, 'html.parser') # 内置默认html解析器
格式化输出soup对象内容
print(soup.prettify())
四大对象:
Beautiful Soup将复杂HTML文档转换成一个不复杂的树形结构,
每个节点都是Python对象,所有对象可以归纳为4种:
Tag 标签 bs4.element.Tag
NavigableString 字符串 bs4.element.NavigableString BeautifulSoup 整体页面 bs4.BeautifulSoup
Comment 注释 bs4.element.Comment


Tag:是HTML 中的一个个标签

上面的 title a 等等 HTML 标签加上里面包括的内容就是 Tag。
一般标签都是成对出现,结尾的有 /标示
下面用 Beautiful Soup 来方便地获取 Tags print soup.title

对于 Tag,它有两个重要的属性,是 name 和 attrs
print soup.name
print soup.head.name
#[document]
#head
soup 对象本身比较特殊,它的 name 即为 [document],
对于其他内部标签,输出的值便为标签本身的名称。
print soup.p.attrs
#{'class': ['title'], 'name': 'dromouse'}
如果我们想要单独获取某个属性,可以这样,例如我们获取它的 class 叫什 么
print soup.p['class']
#['title']
还可以这样,利用get方法,传入属性的名称,二者是等价的
print soup.p.get('class')
#['title']
NavigableString: ##可以遍历的字符串
既然我们已经得到了标签的内容,那么问题来了,
我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,
例如:
print soup.p.string
#The Dormouse's story
检查一下它的类型
print type(soup.p.string)
![]()
BeautifulSoup ##表示的是一个文档的全部内容.大部分时候,
可以把它当作 Tag 对象,是一个特殊的 Tag
获取它的类型,名称,以及属性
print type(soup.name)
![]()
print soup.name
#[document]
print soup.attrs
#{} 空字典
Comment ##特殊类型的 NavigableString 对象,输出的内容仍然不包 括注释符号
print soup.a
print soup.a.string
print type(soup.a.string)
运行结果如下


其他操作: 遍历文档树 以head标签为例
![]()
# .content 属性可以将tag的子节点以列表的方式输出
print(soup.head.contents)
![]()
print(soup.head.contents[1]) # 获取列表中某一元素,0 是页面上的换行符 号,1才是真值
# .children 返回的是一个list生成器对象
print(soup.head.children)
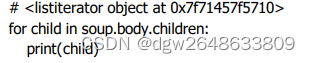
# .string 返回最里面的内容
print(soup.head.string)
print(soup.title.string) # 两个输出是一样的
搜索文档树 ==》find_all() select()
find_all(name, attrs, recursive, text, **kwargs)
# find用法相同,只返回一个
# name参数可以查找所有名字为 name 的tag,可以是字符串,正则表达 式,列表
print(soup.find_all('a'))
print(soup.find_all(["a" , "b"]))
#recursive 递归查找相同名称标签
# keyword参数直接匹配属性对应的值
print(soup.find_all(class_= "sister"))
# 因为class在python中已经有了,为了防止冲突,所以是class_
print(soup.find_all(id= 'link2'))
# text参数搜索文档中的字符串内容,与name参数的可选值一样,text参数 接受字符串,正则表达式,列表
print(soup.find_all(text= "Elsie")) #严格匹配
print(soup.find_all(text=["Tillie" , "Elsie" , "Lacie"])) #找多个
print(soup.find_all(text=re.compile("Dormouse"))) #正则查找
五:使用演练

以实际例子作说明:
1、定义一个html,并使用BeautifulSoup的lxml解析
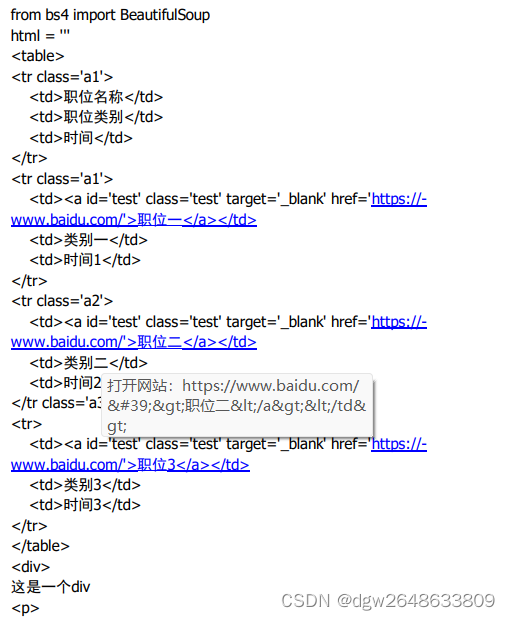

2、获取所有的tr标签
find 返回找到的第一个标签,find_all以list的形式返回找到的所有标签
trs = soup.find_all('tr') # 返回列表
n=1
for i in trs:
print('第{}个tr标签: '.format(n))
print(i)
n+=1
3、获取第二个tr标签
limit 可指定返回的标签数量
trs = soup.find_all('tr' ,limit=2)[1] # 从列表中获取第二个元素,limit 获取 标签个数
print(trs)
4、获取class= 'a1'的tr标签
a.方法一: class_
trs = soup.find_all('tr' ,class_= 'a1')
n=1
for i in trs:
print('第{}个class=''a1''的tr标签:'.format(n))
print(i)
n+=1
b.方法二:attrs 将标签属性放到一个字典中
trs = soup.find_all('tr',attrs={'class':'a1'})
n=1
for i in trs:
print('第{}个class=''a1''的tr标签:'.format(n))
print(i)
n+=1
5、提取所有id= 'test'且class= 'test'的a标签
方法一:class_
alist = soup.find_all('a' ,id= 'test' ,class_= 'test')
n=1
for i in alist:
print('第{}个id= ''test''且class= ''test''的a标签: '.format(n))
print(i)
n+=1
方法二:attrs
alist = soup.find_all('a' ,attrs={'id':'test' , 'class':'test'})
n=1
for i in alist:
print('第{}个id= ''test''且class= ''test''的a标签: '.format(n))
print(i)
n+=1
6、获取所有a标签的href属性
alist = soup.find_all('a')
#方法一:通过下标获取
for a in alist:
href = a['href']
print(href)
#方法二: 通过attrs获取
for a in alist:
href = a.attrs['href']
print(href)
7、获取所有的职位信息(所有文本信息)
string 获取标签下的非标签字符串(值), 返回字符串
注:第一个tr为标题信息,不获取。从第二个tr开始获取。
trs = soup.find_all('tr')[1:]
movies = []
for tr in trs:
move = {}
tds = tr.find_all('td')
move['td1'] = tds[0].string # string 取td的值
move['td2'] = tds[1].string
move['td3'] = tds[2].string
movies.append(move)
print(movies)
8、获取所有非标记性字符
strings 获取标签下的所有非标签字符串, 返回生成器。
trs = soup.find_all('tr')[1:]
for tr in trs:
infos = list(tr.strings) # 获取所有非标记性字符,包含换行、空格
print(infos
9、获取所有非空字符
stripped_strings 获取标签下的所有非标签字符串,并剔除空白字符,返回 生成器。
trs = soup.find_all('tr')[1:]
for tr in trs:
infos = list(tr.stripped_strings) # 获取所有非空字符,不包含换行、空 格
print(infos)
# stripped_strings 获取所有职位信息
trs = soup.find_all('tr')[1:]
movies = []
for tr in trs:
move = {}
infos = list(tr.stripped_strings)
move['职位'] = infos[0]
move['类别'] = infos[1]
move['时间'] = infos[2]
movies.append(move)
print(movies)
10、get_text 获取所有职位信息
get_text 获取标签下的所有非标签字符串,返回字符串格式
trs = soup.find_all('tr')[1]
text = trs.get_text() # 返回字符串格式
print(text)

14、提取所有a标签的href属性
# 方法一:
a = soup.select('a')
for i in a:
print(i['href'])
# 方法二:
a = soup.select('a')
for i in a:
print(i.attrs['href'])




相关文章:
python-网络爬虫.BS4
BS4 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库, 它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方 式。 Beautiful Soup 4 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 帮助手册&…...

C# 开发规范
控件命名规则 控件名简写 控件名简写LabellblTextBoxtxtButtonbtnLinkButtonlnkbtnImageButtonimgbtnDropDownListddlListBoxlstDataGriddgDataListdlCheckBoxchkCheckBoxListchklsRadioButtonrdoRadioButtonListrdoltImageimgPanelpnlCalendecldAdRotatorarTabletblRequiredF…...

【uniapp 样式】使用setStorageSync存储历史搜索记录
<template><view><view class"zhuangbox u-flex"><u--inputplaceholder"请输入关键字搜索"border"surround"shapecircleprefixIcon"search"prefixIconStyle"font-size: 22px;color: #909399"v-model&q…...

git remote add origin详解
git remote add origin详解_笔记大全_设计学院 一、git remote add origin的基础 使用“git remote add origin”指令,可以轻松地将本地项目连接到远程Git仓库 二、git remote add origin的用法 “git remote add origin”指令可以使用以下语法: git…...
附录1-将uni-app运行到微信开发者工具
目录 1 在manifest.json写入AppID 2 配置微信开发者工具的安装路径 3 微信开发者工具的安全设置 4 运行 5 修改一些配置项 1 在manifest.json写入AppID 2 配置微信开发者工具的安装路径 如果你忘了安装在哪里了,可以右键快捷方式看一下属性 在运行设置…...
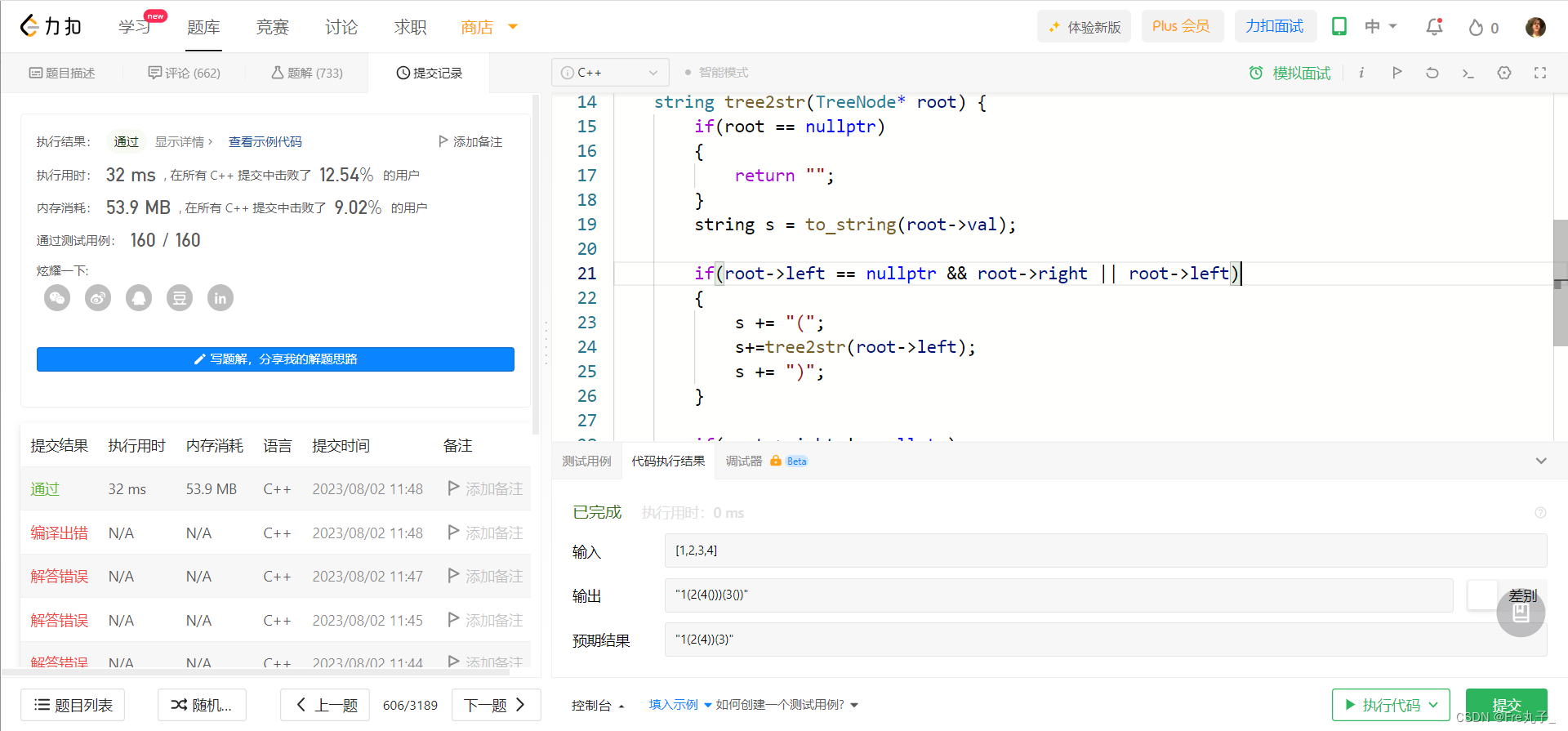
【LeetCode】根据二叉树创建字符串
根据二叉树创建字符串 题目描述算法分析编程代码 链接: 根据二叉树创建字符串 题目描述 算法分析 当单纯的按照前序遍历输出后,我们只要对()进行一些修改就好 编程代码 /*** Definition for a binary tree node.* struct TreeNode {* …...

【图论】强连通分量
一.定义 强连通分量(Strongly Connected Components,简称SCC)是图论中的一个概念,用于描述有向图中的一组顶点,其中任意两个顶点之间都存在一条有向路径。换句话说,对于图中的任意两个顶点u和v,…...

网络:VRP介绍
1. VRP 华为使用的通用路由平台,华为的交换机、防火墙、安全设备、无线和路由器的命令行几乎一样。 2. VRP分为用户视图、系统视图。 3. 用户视图 user view <Huawei>:其中<>代表的是用户视图,Huawei是设备的名称。命令比较少。…...
iOS - 解压ipa包中的Assert.car文件
项目在 Archive 打包后,生成ipa包 将 xxx.ipa文件修改为zip后缀即 xxx.zip ,然后再双击解压,会生成一个 Payload 文件夹,里面一个文件 如下图: 然后显示改文件的包内容: 解压 Assets.car 文件的方式&…...

【Jmeter】配置不同业务请求比例,应对综合场景压测
目录 前言 Jmeter5.0新特性 核心改进 其他变化 资料获取方法 前言 Jmeter 5.0这次的核心改进是在许多地方改进了对 Rest 的支持,此外还有调试功能、录制功能的增强、报告的改进等。 我也是因为迁移到了Mac,准备在Mac上安装Jmeter的时候发现它已经…...
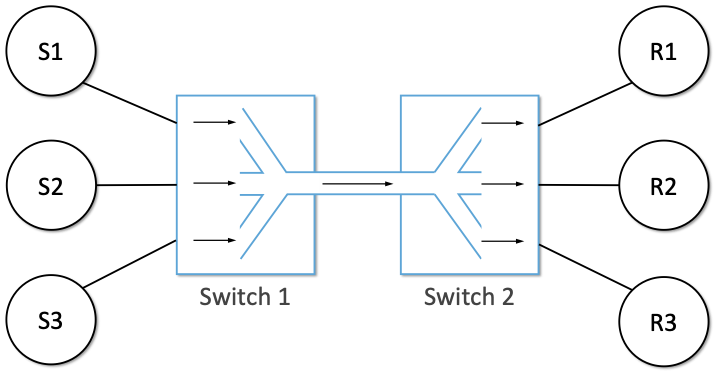
TCP拥塞控制详解 | 1. 概述
网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems …...

使用IPSEC VPN 在有防火墙的场景和有NAT转换的场景下实现隧道通信实验
目录 一、在有防火墙的场景 1、为所有设备配置对应ip地址: 2、进入两个防火墙实现公网互通 3、测试公网是否互通 4、进入SW1配置IPSEC VPN 5、进入SW2配置IPSEC VPN 6、配置策略方向ESP的流量 7、尝试使用PC1访问PC2 二、在有NAT地址转换的场景 1、为新增加…...

Go和Java实现适配器模式
Go和Java实现适配器模式 我们通过下面的实例来演示适配器模式的使用,其中,音频播放器设备只能播放 mp3 文件,通过使用一个更高级 的音频播放器来播放 vlc 和 mp4 文件。 1、适配器模式 适配器模式是作为两个不兼容的接口之间的桥梁。这种…...
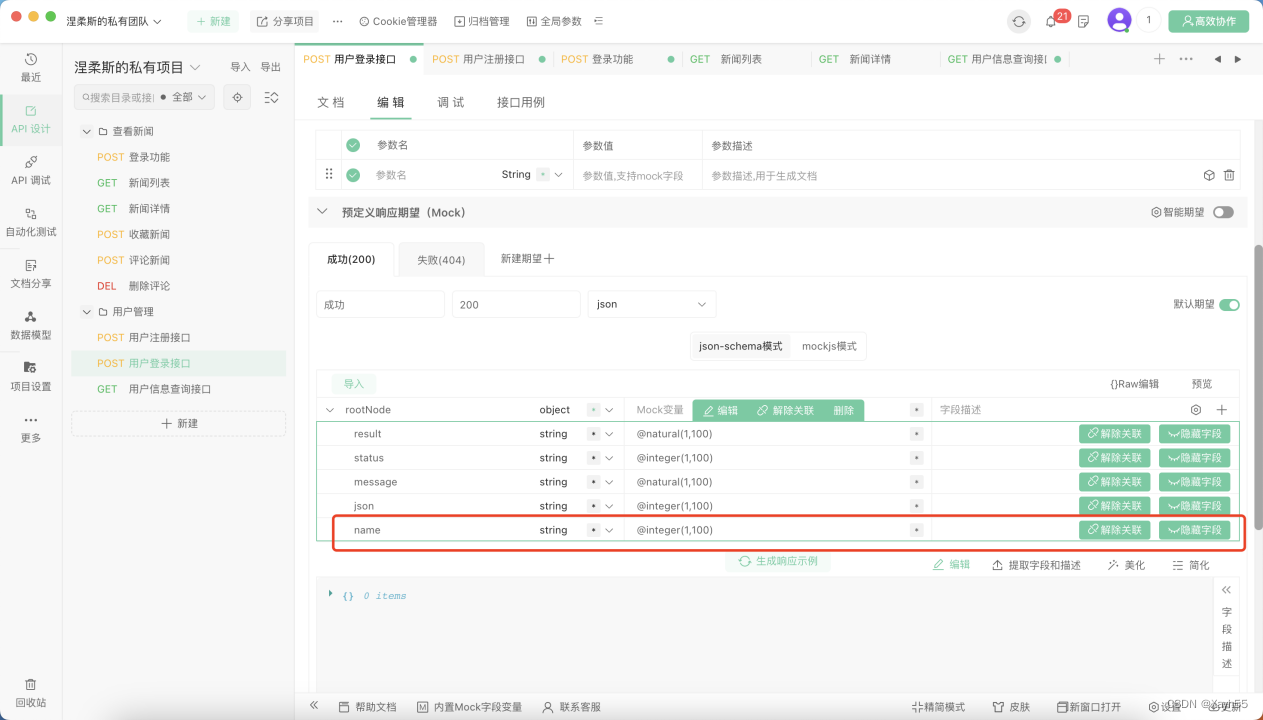
接口相似数据结构复用率高?Apipost这招搞定!
在API设计和开发过程中,存在许多瓶颈,其中一个主要问题是在遇到相似数据结构的API时会产生重复性较多的工作:在每个API中都编写相同的数据,这不仅浪费时间和精力,还容易出错并降低API的可维护性。 为了解决这个问题&a…...

【零基础学Rust | 基础系列 | Hello, Rust】编写并运行第一个Rust程序
文章目录 前言一,创建项目二,两种编译方式1. 使用rustc编译器编译2. 使用Cargo编译 总结 前言 在开始学习任何一门新的编程语言时,都会从编写一个简单的 “Hello, World!” 程序开始。在这一章节中,将会介绍如何在Rust中编写并运…...

代理模式.
前言: 为什么要学习代理模式,因为AOP的底层机制就是动态代理! 代理模式: 静态代理 动态代理 静态代理 抽象角色 : 一般使用接口或者抽象类来实现 真实角色 : 被代理的角色 代理角色 : 代理真实角色 ; 代理真实角色后 , 一…...
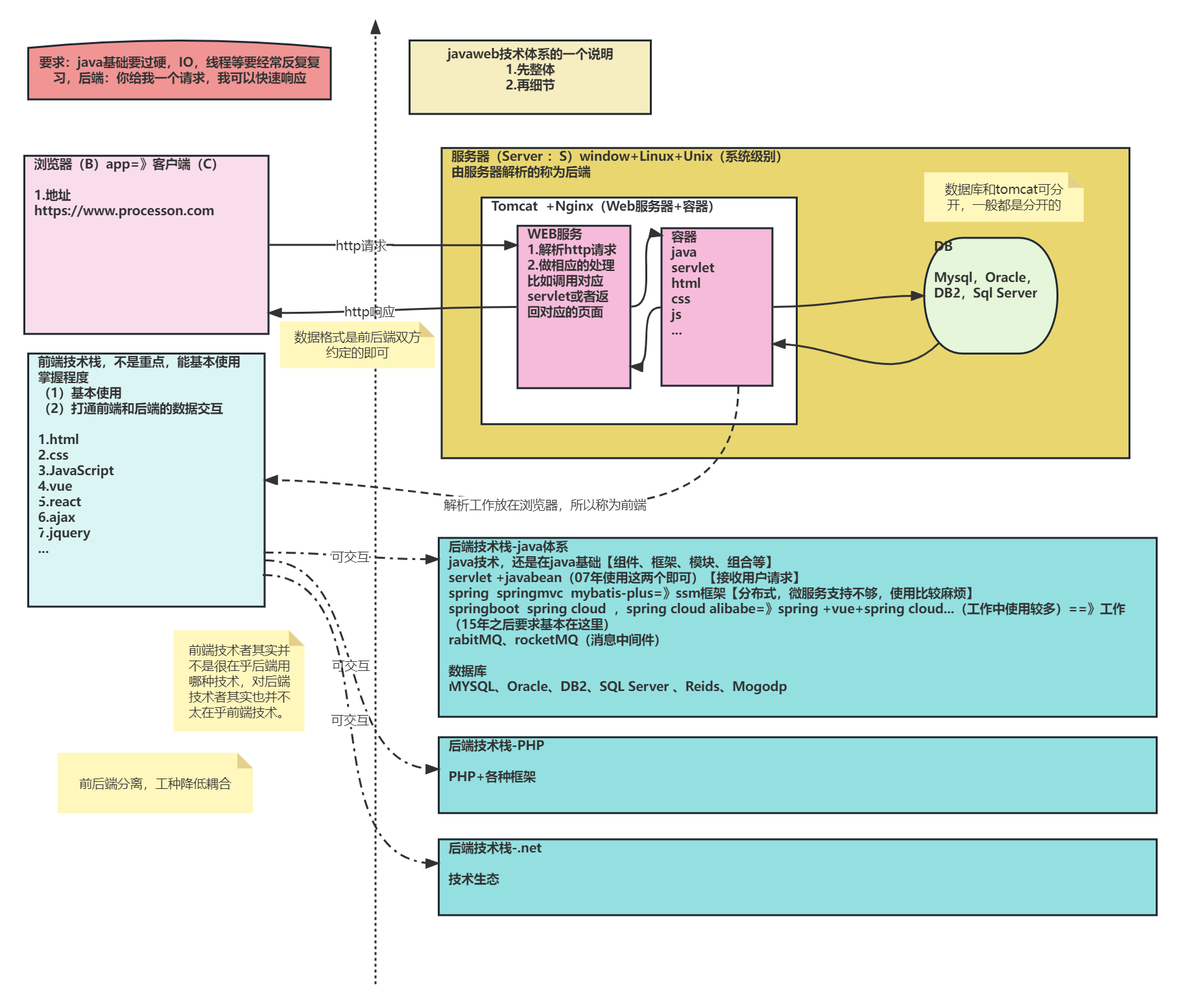
BS框架说明
B/S架构 1.B/S框架,意思是前端(Browser 浏览器,小程序、app、自己写的)和服务器端(Server)组成的系统的框架结构 2.B/S框架,也可理解为web架构,包含前端、后端、数据库三大组成部分…...

iOS——Block签名
首先来看block结构体对象Block_layout(等同于clang编译出来的__Block_byref_a_0) #define BLOCK_DESCRIPTOR_1 1 struct Block_descriptor_1 {uintptr_t reserved;uintptr_t size; };#define BLOCK_DESCRIPTOR_2 1 struct Block_descriptor_2 {// requi…...

Flutter 图片选取及裁剪
在开发项目里修改用户头像的功能,涉及到图片选取及裁剪,基本实现步骤如下: 1、pubspec.yaml 添加 image_picker: ^1.0.1 image_cropper: ^4.0.1: dependencies:image_picker: ^1.0.1image_cropper: ^4.0.1flutter:sdk: flutter…...
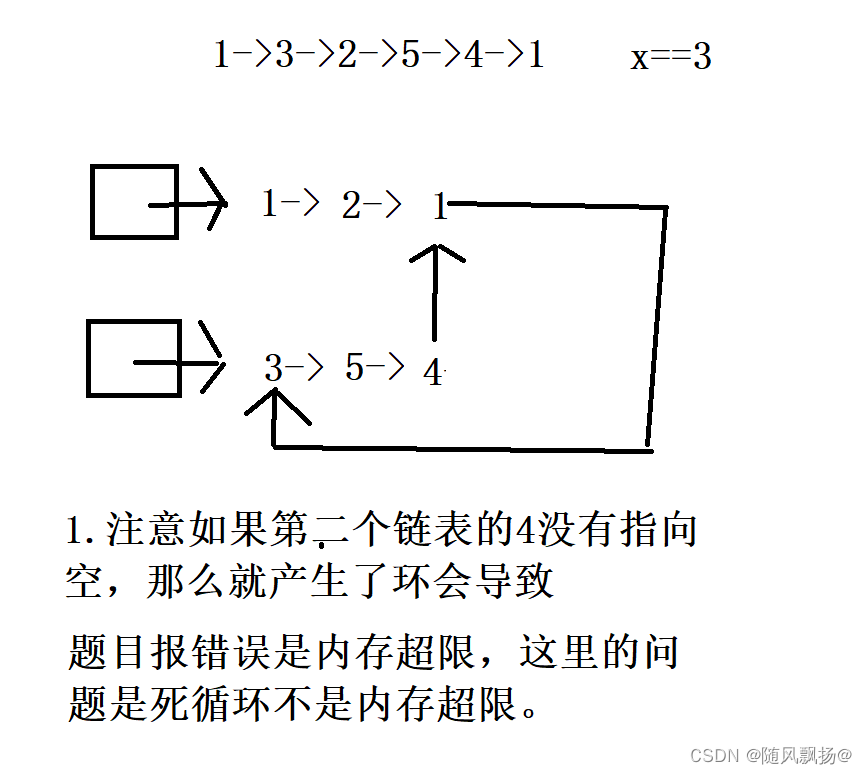
C语言每日一题:11.《数据结构》链表分割。
题目一: 题目链接: 思路一:使用带头链表 1.构建两个新的带头链表,头节点不存储数据。 2.循环遍历原来的链表。 3.小于x的尾插到第一个链表。 4.大于等于x尾插到第二个链表。 5.进行链表合并,注意第二个链表的尾的下一…...

解决tiktoken离线使用难题:手动下载cl100k_base.tiktoken并配置本地缓存的保姆级教程
突破网络限制:tiktoken离线部署全流程实战指南 在自然语言处理领域,token切分是模型处理文本的第一步关键操作。对于依赖GPT系列模型的开发者而言,tiktoken作为OpenAI官方推出的高效tokenizer,其重要性不言而喻。然而,…...

3大核心策略:构建高效抖音内容采集系统的技术实践
3大核心策略:构建高效抖音内容采集系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

低代码组件“看似简单,上线即崩”?20年专家拆解5个被90%团队忽略的线程安全与事务传播陷阱
第一章:低代码组件“看似简单,上线即崩”的真相低代码平台承诺“拖拽即交付”,但真实生产环境中,大量业务系统在上线后数小时内便出现表单提交失败、数据丢失、权限错乱或页面白屏等问题。这些故障并非源于复杂逻辑,而…...

Qwen3-0.6B-FP8与STM32开发联动:生成嵌入式系统控制逻辑伪代码
Qwen3-0.6B-FP8与STM32开发联动:生成嵌入式系统控制逻辑伪代码 1. 引言 如果你是一位嵌入式开发者,或者正在学习STM32,下面这个场景你一定不陌生:拿到一个传感器模块,比如温湿度传感器,想用它来控制一个风…...

Z-Image-Turbo模型在智能车领域的应用:仿真场景图像生成
Z-Image-Turbo模型在智能车领域的应用:仿真场景图像生成 最近和几个做自动驾驶算法的朋友聊天,他们都在为一个问题头疼:测试数据不够用。特别是那些罕见的极端场景,比如暴雨天、浓雾夜,或者刺眼的逆光路况,…...

AI辅助前端设计:让快马平台生成酷炫的滚动视差与3D交互效果代码
AI辅助前端设计:让快马平台生成酷炫的滚动视差与3D交互效果代码 最近在做一个科技公司的产品介绍页,想实现一些炫酷的交互效果来提升用户体验。传统方式需要手动编写大量CSS和JavaScript代码,调试起来也很耗时。不过现在有了AI辅助开发工具&…...

5分钟搞懂线结构光三维重建:从激光平面到深度信息的完整流程
线结构光三维重建:从激光平面到深度信息的实战解析 当你第一次看到激光线扫过物体表面时,可能不会想到这条细细的光线背后隐藏着精确测量物体三维形状的能力。线结构光三维重建技术正悄然改变着工业检测、逆向工程和医疗影像等领域——它不需要接触物体…...

5块钱的国产RISC-V芯片CH32V103能干啥?我用它复刻了一个STM32F103的小项目
5元国产RISC-V芯片实战:用CH32V103复刻STM32经典项目 在电子DIY领域,成本始终是创客们无法回避的现实问题。当我在某电商平台发现CH32V103这颗标价仅5元的RISC-V芯片时,第一反应是怀疑它的实用性——毕竟同级别的STM32F103C8T6价格通常在15-2…...

大厂Agent开发工程师亲授!这份核心技术学习路线助你轻松拿下高薪Offer!
结合个人实际的工作内容和招聘市场对于Agent开发的能力要求(阅读汇总了大量大厂的Agent开发招聘面经),我总结了一份核心技术学习路线。 这个学习路线由浅到深,基本覆盖了现在大厂对于Agent开发的技术要求,技术栈完全可…...

2026年高压电磁阀制造厂大比拼:哪家更值得信赖?
在工业领域,高压电磁阀是许多关键系统的核心部件,其性能和可靠性直接关系到整个系统的稳定性和安全性。随着技术的不断进步和市场需求的多样化,选择一家值得信赖的高压电磁阀制造厂变得尤为重要。本文将从多个维度对比分析几家主流高压电磁阀…...