新一代开源流数据湖平台Apache Paimon入门实操-上
文章目录
- 概述
- 定义
- 核心功能
- 适用场景
- 架构原理
- 总体架构
- 统一存储
- 基本概念
- 文件布局
- 部署
- 环境准备
- 环境部署
- 实战
- Catalog
- 文件系统
- Hive Catalog
- 创建表
- 创建Catalog管理表
- 查询创建表(CTAS)
- 创建外部表
- 创建临时表
- 修改表
- 修改表
- 修改列
- 修改水印
概述
定义
Apache Paimon 官网 https://paimon.apache.org/ 最新稳定版本为0.4.0-incubating,0.5-SNAPSHOT正在开发
Apache Paimon 文档地址 https://paimon.apache.org/docs/master/
Apache Paimon 源码地址 https://github.com/apache/incubator-paimon/
Apache Paimon (incubating) 目前属于Apache 软件基金会 (ASF) 的孵化项目,其原项目为由Flink官方维护的Flink Table Store;其设计为一个开源流数据湖平台,包揽Streaming实时计算能力和LakeHouse架构优势,统一了存储,具有高速数据摄取,变更日志跟踪和高效的实时分析强大能力。
Apache Paimon 采用开放的数据格式和技术理念,不仅支持Flink SQL编写和本地查询,还可以与其他诸多业界主流计算引擎进行对接。
核心功能
- 统一批处理和流处理:Paimon支持批写和批读,以及流式写更改和流式读表更改日志。
- 数据湖:Paimon具有成本低、可靠性高、元数据可扩展等优点,具有数据湖存储的所有优势。
- 合并引擎:Paimon支持丰富的合并引擎。缺省情况下,保留主键的最后一项记录,可以“部分更新”或“聚合”。
- 变更日志生成:Paimon支持丰富的Changelog producer例如“lookup”和“full-compaction”,可以从任何数据源生成正确且完整的变更日志从而简化流管道的构建。
- 丰富的表类型: 除了主键表,Paimon还支持append-only只追加表,自动压缩小文件,并提供有序的流读取来替换消息队列。
- 模式演化:支持完整的模式演化,例如可以重新命名列和重新排序。
适用场景
Apache Paimon 适用于需要在流数据上进行实时查询和分析的场景。它可以帮助用户更容易地构建流式数据湖,实现高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。例如在金融、电子商务、物联网等行业中,可以使用 Apache Paimon 来实现实时推荐、欺诈检测、异常检测等应用。
架构原理
总体架构
Paimon 创新的结合了湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力

-
读/写:Paimon支持多种方式来读/写数据和执行OLAP查询。
- 对于读取,它支持从历史快照(批处理模式)、从最新偏移量(流模式)中读取数据,或者以混合方式读取增量快照。
- 对于写操作,它支持从数据库变更日志(CDC)进行流同步,或者从离线数据进行批量插入/覆盖。
-
生态系统:除了Apache Flink, Paimon还支持其他计算引擎的读取,如Apache Hive、Apache Spark、Presto和Trino。
-
内部:在底层,Paimon将列文件存储在文件系统/对象存储中,并使用LSM树结构来支持大量数据更新和高性能查询。
统一存储
对于像Apache Flink这样的流媒体引擎,通常有三种类型的连接器:
- 消息队列,比如Apache Kafka,它在这个管道的源和中间阶段都被使用,以保证延迟保持在秒内。
- OLAP系统,如ClickHouse,它以流方式接收处理过的数据,并为用户的特别查询提供服务。
- 批处理存储,如Apache Hive,它支持传统批处理的各种操作,包括INSERT OVERWRITE。
Paimon提供表抽象。它的使用方式与传统数据库没有什么不同:
- 在批处理执行模式下,它就像一个Hive表,支持批处理SQL的各种操作。查询最新快照。
- 在流式执行模式下,它的作用类似于消息队列。查询它的行为类似于从历史数据永远不会过期的消息队列查询流更改日志。
基本概念
- 快照:快照捕获表在某个时间点的状态。用户可以通过最新的快照访问表的最新数据。通过时间旅行,用户还可以通过较早的快照访问表的先前状态。
- 分区
- Paimon采用与Apache Hive相同的分区概念来分离数据。
- 分区是一种可选的方法,可以根据特定列(如日期、城市和部门)的值将表划分为相关部分。每个表可以有一个或多个分区键来标识一个特定的分区。
- 通过分区,用户可以有效地操作表中的记录切片。如果定义了主键,分区键必须是主键的子集。
- 桶
- 未分区的表或分区表中的分区被细分为桶,为数据提供额外的结构,可用于更有效的查询。
- bucket的范围由记录中一个或多个列的哈希值决定。用户可以通过提供bucket-key选项来指定bucket列。如果没有指定桶键选项,则使用主键(如果定义了)或完整记录作为桶键。
- bucket是用于读写的最小存储单元,因此bucket的数量限制了最大的处理并行性。但是,这个数字不应该太大,因为它将导致大量小文件和低读取性能。一般情况下,建议每个bucket中的数据大小为1GB左右。
- 一致性保证
- Paimon编写器使用两阶段提交协议自动将一批记录提交到表中。每次提交在提交时最多产生两个快照。
- 对于任何两个同时修改一个表的写入器,只要他们没有修改同一个桶,他们的提交就是可序列化的。如果修改的是同一个桶,则只保证快照隔离。也就是说,最终的表状态可能是两次提交的混合状态,但不会丢失任何更改。
文件布局
表的所有文件都存储在一个基本目录下。Paimon文件以分层的方式组织。下图说明了文件布局。从快照文件开始,Paimon读取器可以递归地访问表中的所有记录。

- 快照文件:所有快照文件都保存在快照目录下。快照文件是一个JSON文件,其中包含有关该快照的信息,包括架构文件使用包含此快照的所有更改的清单列表。
- Manifest文件:所有清单列表和清单文件都存储在manifest目录中。清单列表是清单文件名的列表,清单文件是包含有关LSM数据文件和更改日志文件的更改的文件。例如在相应的快照中创建了哪个LSM数据文件,删除了哪个文件。
- 数据文件:数据文件按分区和桶分组。每个桶目录包含一个LSM树及其变更日志文件。目前,Paimon支持使用orc(默认)、parquet和avro作为数据文件格式。
- LSM树:Paimon采用LSM树(日志结构的合并树)作为文件存储的数据结构。数据文件中的记录按其主键排序;在Sorted Runs中,数据文件的主键范围从不重叠。不同Sorted Runs可能有重叠的主键范围,甚至可能包含相同的主键。在查询LSM树时,必须将所有Sorted Runs组合起来,并且必须根据用户指定的合并引擎和每条记录的时间戳合并具有相同主键的所有记录。写入LSM树的新记录将首先在内存中进行缓冲。当内存缓冲区已满时,将对内存中的所有记录进行排序并刷新到磁盘。得益于
LSM数据结构的追加写能力,Paimon 在大规模的更新数据输入的场景中提供了出色的性能。

- 合并:当越来越多的记录写入LSM树时,Sorted Runs次数将会增加。因为查询LSM树需要将所有Sorted Runs组合在一起,太多的Sorted Runs将导致查询性能差,甚至导致内存不足。为了限制排序运行的次数,必须偶尔将几个Sorted Runs合并为一个大的Sorted Runs,这个过程称为合并或压缩,合并是一个资源密集型过程,它会消耗一定的CPU时间和磁盘IO,因此过于频繁的压缩可能会导致写速度变慢。这是查询性能和写性能之间的权衡。目前,Paimon采用了一种与Rocksdb的通用压实类似的压实策略。默认情况下,当Paimon将记录追加到LSM树时,它还将根据需要执行压缩,还可以选择在专用压缩作业中执行所有压缩。
部署
环境准备
官方提供对应引擎的版本支持如下

环境部署
# 这里选择下载最新版本Flink1.17.1
wget https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
# 解压文件
tar -xvf flink-1.17.1-bin-scala_2.12.tgz
# 进入flink目录
cd flink-1.17.1
配置环境变量,修改flink-conf.yaml配置文件
# 如果是Flink17版本以下env.java.opts.all则需改为env.java.opts
env.java.opts.all: "-Dfile.encoding=UTF-8"
classloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4
execution.checkpointing.interval: 10s
# 用于存储和检查点状态
state.backend: rocksdb
# 存储检查点的数据文件和元数据的默认目录
state.checkpoints.dir: hdfs://myns/flink/myns
# savepoints 的默认目标目录(可选)
state.savepoints.dir: hdfs://myns/flink/savepoints
# 用于启用/禁用增量 checkpoints 的标志
state.backend.incremental: true
使用paimon非常简单,和其他数据湖产品一样,都是将jar包放在引擎的目录下
# 解决依赖问题,将hadoop的hadoop-mapreduce-client-core-3.3.4.jar拷贝到flink
cp /opt/module/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.4.jar ./lib/
# 下载最新版的paimon,目前0.5属于快照版本,,可以先进入lib目录,然后下载到当前lib,也可以通过其他地方下载然后上传拷贝到flink的lib目录下
cd lib/
wget https://repository.apache.org/content/groups/snapshots/org/apache/paimon/paimon-flink-1.17/0.5-SNAPSHOT/paimon-flink-1.17-0.5-20230802.034234-105.jar
# 由于后续会使用到其他连接器,这里先下载安装好,后面直接使用即可,先下载flink-sql-connector-hive连接器
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.3_2.12/1.17.1/flink-sql-connector-hive-3.1.3_2.12-1.17.1.jar
# 下载flink-sql-connector-mysql-cdc连接器
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.4.1/flink-sql-connector-mysql-cdc-2.4.1.jar
# 下载flink-sql-connector-kafka连接器
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.17.1/flink-sql-connector-kafka-1.17.1.jar
# 重新回到flink的根目录
cd ../
# 先保证hadoop环境,通过yarn启动flink集群
./bin/yarn-session.sh -d
# 以提交yarn-session方式启动sql客户端
./bin/sql-client.sh -s yarn-session
测试环境是否可用
set 'sql-client.execution.result-mode' = 'tableau';
show databases;
show tables;
select 1;

通过yarn管理页面可以看到有 Flink session cluster运行job,点击该记录的ApplicationMaster跳转到flink管理页面,也可以看到刚才job已经完成,环境准备完毕。
实战
Catalog
Paimon Catalog可以持久化元数据,当前支持两种类型的metastore
- 文件系统(默认):将元数据和表文件存储在文件系统中。
- hive:在hive metastore存储元数据,用户可以直接从hive访问表。
文件系统
下面的Flink SQL注册并使用一个名为fs_catalog的Paimon编目。元数据和表文件存放在hdfs://myns/paimon/fs下。
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://myns/paimon/fs'
);show catalogs;

Hive Catalog
使用Hive Catalog前需要先启动hive元数据服务
nohup hive --service metastore &
通过使用Paimon Hive catalog,对catalog的更改将直接影响到相应的Hive metastore。使用Hive catalog,数据库名、表名和字段名应该是小写的。
CREATE CATALOG hive_catalog WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://hadoop2:9083','hive-conf-dir' = '/home/commons/apache-hive-3.1.3-bin/conf/', 'warehouse' = 'hdfs://myns/paimon/hive'
);
show catalogs;

USE CATALOG hive_catalog;
CREATE TABLE test1 (id BIGINT,a INT,b STRING,dt STRING COMMENT 'timestamp string in format yyyyMMdd',PRIMARY KEY(id, dt) NOT ENFORCED
) PARTITIONED BY (dt);
在指定的Catalog中创建表

关闭重新进入sql-client后,只剩下默认的default_catalog,因此可以在启动客户端时执行指定创建catalog语句,vim conf/sql-client-init.sql
set 'sql-client.execution.result-mode' = 'tableau'; CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://myns/paimon/fs'
);CREATE CATALOG hive_catalog WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://hadoop2:9083','hive-conf-dir' = '/home/commons/apache-hive-3.1.3-bin/conf/', 'warehouse' = 'hdfs://myns/paimon/hive'
);USE CATALOG hive_catalog;
通过-i参数启动执行sql文件,启动后就可以看到hive_catalog之前已创建的表了
./bin/sql-client.sh -s yarn-session -i conf/sql-client-init.sql

创建表
创建Catalog管理表
在Paimon Catalog中创建的表由Catalog管理也就是管理表。当表从目录中删除时,它的表文件也将被删除,与hive内部表相似。
- 带主键表
CREATE TABLE user_behavior1 (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);
在删除表之前,应该停止在表上插入作业,否则不能完全删除表文件。
- 分区表
CREATE TABLE user_behavior2 (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);
-
指定统计模式:Paimon将自动收集数据文件的统计信息,以加快查询过程。支持四种模式:
- Full:收集完整指标:null_count, min, Max。
- Truncate (length):长度可以是任何正数,默认模式是Truncate(16),这意味着收集null计数,min/max值,截断长度为16。这主要是为了避免太大的列,将扩大清单文件。
- 计数:只收集空计数。
- None:关闭元数据采集。
-
字段默认值:Paimon表目前支持为表属性中的字段设置默认值,注意不能指定分区字段和主键字段。
CREATE TABLE user_behavior2 (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh)
with('fields.item_id.deafult-value'='0'
);
查询创建表(CTAS)
表可以通过查询结果创建或填充,简单创建表。
CREATE TABLE items1 (user_id BIGINT,item_id BIGINT
);
CREATE TABLE items2 AS SELECT * FROM items1;

/* 分区表 */
CREATE TABLE user_behavior_p1 (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING
) PARTITIONED BY (dt, hh);
CREATE TABLE user_behavior_p2 WITH ('partition' = 'dt') AS SELECT * FROM user_behavior_p1;/* change options */
CREATE TABLE user_behavior_3 (user_id BIGINT,item_id BIGINT
) WITH ('file.format' = 'orc');
CREATE TABLE user_behavior_4 WITH ('file.format' = 'parquet') AS SELECT * FROM user_behavior_3;/* 主键 */
CREATE TABLE user_behavior_5 (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) ;
CREATE TABLE user_behavior_6 WITH ('primary-key' = 'dt,hh') AS SELECT * FROM user_behavior_5;/* 主键 + 分区 */
CREATE TABLE user_behavior_all (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);
CREATE TABLE user_behavior_all_as WITH ('primary-key' = 'dt,hh', 'partition' = 'dt') AS SELECT * FROM user_behavior_all;
- CREATE TABLE LIKE
CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) ;CREATE TABLE user_behavior_like LIKE user_behavior;
- 表属性
CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh) WITH ('bucket' = '2','bucket-key' = 'user_id'
);
创建外部表
外部表由Catalog记录,但不由Catalog管理。如果删除外部表,则不会删除其表文件。可以在任何目录中使用Paimon外部表。如果不想创建Paimon目录,而只想读/写表,那么可以考虑使用外部表。Flink SQL支持读写外部表;外部Paimon表是通过指定连接器和路径表属性创建的。
use catalog default_catalog;
CREATE TABLE user_behavior_external (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) WITH ('connector' = 'paimon','path' = 'hdfs://myns/paimon/external','auto-create' = 'true' -- 如果表路径不存在,此table属性将为空表创建表文件目前仅支持Flink
);

创建临时表
临时表仅由Flink支持。与外部表一样,临时表只是记录,而不是由当前Flink SQL会话管理。如果临时表被删除,它的资源不会被删除。当Flink SQL会话关闭时,也会删除临时表。如果希望将Paimon Catalog与其他表一起使用,但又不希望将它们存储在其他Catalog中,则可以创建一个临时表。
USE CATALOG hive_catalog;
CREATE TEMPORARY TABLE temp_table (k INT,v STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs://myns/paimon/temp/temp_table.csv','format' = 'csv'
);# 可以使用临时表和其他表进行关联查询
SELECT my_table.k, my_table.v, temp_table.v FROM my_table JOIN temp_table ON my_table.k = temp_table.k;

修改表
修改表
CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);
# 修改表属性
ALTER TABLE my_table SET ('write-buffer-size' = '256 MB'
);
# 修改表名
ALTER TABLE my_table RENAME TO my_table_new;
# 删除表的属性
ALTER TABLE my_table RESET ('write-buffer-size');
修改列
# 填写列
ALTER TABLE my_table ADD (c1 INT, c2 STRING);
# 重命名列
ALTER TABLE my_table RENAME c0 TO c1;
# 删除列
ALTER TABLE my_table DROP (c1, c2);
# 更改列的空属性
CREATE TABLE my_table (id INT PRIMARY KEY NOT ENFORCED, coupon_info FLOAT NOT NULL);
-- 将列' coupon_info '从NOT NULL更改为可空
ALTER TABLE my_table MODIFY coupon_info FLOAT;
-- 将列' coupon_info '从可空改为NOT NULL如果已经有NULL值,设置如下表选项,在修改表之前静默删除这些记录。
SET 'table.exec.sink.not-null-enforcer' = 'DROP';
ALTER TABLE my_table MODIFY coupon_info FLOAT NOT NULL;
# 更改列注释
ALTER TABLE my_table MODIFY buy_count BIGINT COMMENT 'buy count'
# 添加列位置
ALTER TABLE my_table ADD c INT FIRST;
ALTER TABLE my_table ADD c INT AFTER b;
# 改变列位置
ALTER TABLE my_table MODIFY col_a DOUBLE FIRST;
ALTER TABLE my_table MODIFY col_a DOUBLE AFTER col_b;
# 修改列类型
ALTER TABLE my_table MODIFY col_a DOUBLE;
修改水印
# 添加WATERMARK,下面的SQL从现有的列log_ts中添加一个计算列ts,并在列ts上添加一个策略为ts - INTERVAL '1' HOUR的水印,该水印被标记为表my_table的事件时间属性。
CREATE TABLE my_test_wm (id BIGINT,name STRING,log_ts BIGINT
);
ALTER TABLE my_test_wm ADD (ts AS TO_TIMESTAMP_LTZ(log_ts,3),WATERMARK FOR ts AS ts - INTERVAL '1' HOUR
);
# 修改WATERMARK
ALTER TABLE my_test_wm MODIFY WATERMARK FOR ts AS ts - INTERVAL '2' HOUR
# 删除WATERMARK
ALTER TABLE my_test_wm DROP WATERMARK

- 本人博客网站IT小神 www.itxiaoshen.com
相关文章:
新一代开源流数据湖平台Apache Paimon入门实操-上
文章目录 概述定义核心功能适用场景架构原理总体架构统一存储基本概念文件布局 部署环境准备环境部署 实战Catalog文件系统Hive Catalog 创建表创建Catalog管理表查询创建表(CTAS)创建外部表创建临时表 修改表修改表修改列修改水印 概述 定义 Apache Pa…...
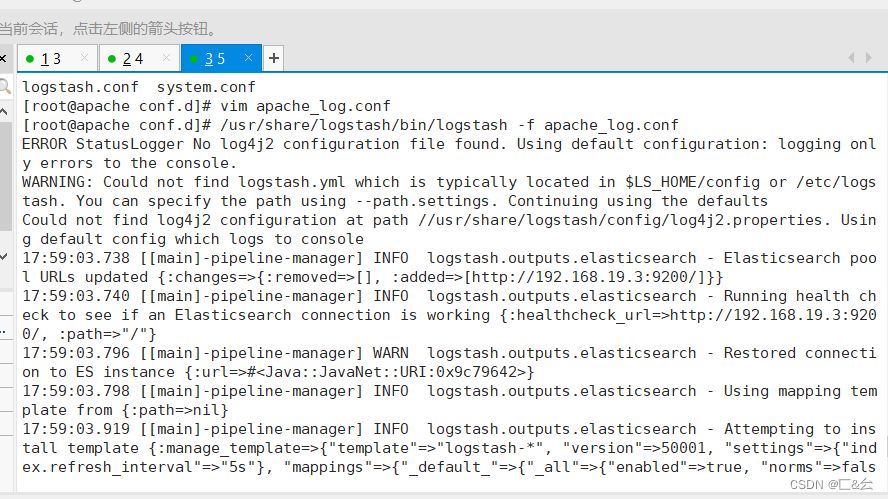
ELK 企业级日志分析系统(一)
目录 一、ELK 简介 1.1 组件说明 1.2 为什么要使用ELK 1.3 完整日志系统的基本特征 1.4 ELK工作原理 二、Elasticsearch的介绍 2.1 Elasticsearch的核心: 三、Logstash 3.1 Logstash简介 四、Kibana 五、部署ELK日志分析系统 5.1 服务器配置 5.2 ELK Elasticse…...

2023-08-01力扣今日二题-Hard-DPLIS优先队列-好题
链接: 354. 俄罗斯套娃信封问题 题意: 一个信封有长宽,如果一个信封的长宽均严格大于另一个信封,那么大的这个信封可以装下小的这个信封 求最多能套娃几个信封 解: 类似普通的最长上升子序列,但是信封…...

并发 如何创建线程 多线程
进程:一个程序的执行过程 线程:一个方法就是一个线程 并发:多个线程抢夺一个资源 操作同一个对象 创建线程方法1 //创建线程方法1 继承Thread类 重写润方法 调用start开启线程 public class TestThead extends Thread{Overridepublic voi…...

亚马逊鲲鹏系统是怎么引流的?
亚马逊鲲鹏系统有三种引流方式,可设置通过亚马逊站点搜索、站外引流、直接访问产品页面进入到相关产品页面进行操作。 1、通过亚马逊站点搜索 正常的登录到我们的亚马逊主页,然后通过设置关键词及asin,最后进入你指定的产品,进行…...
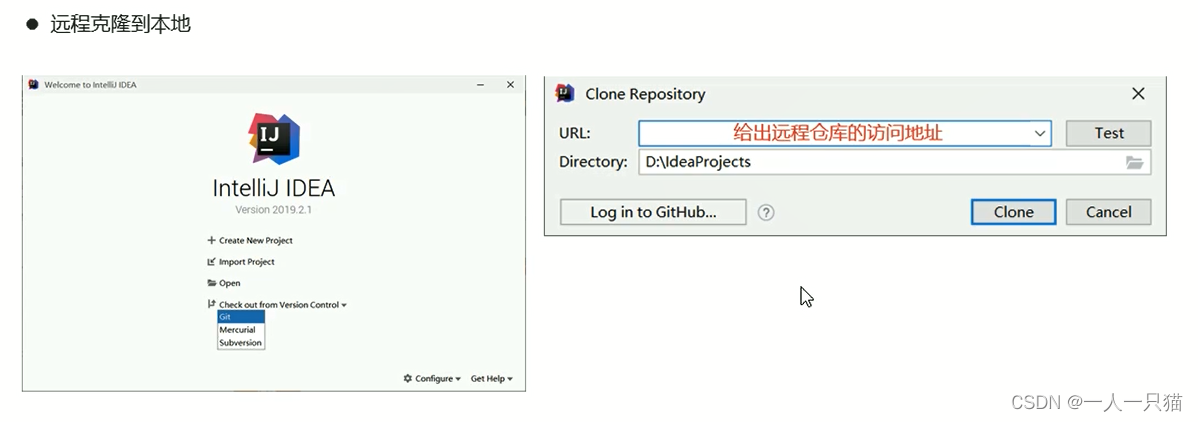
第五章 Git
5-1、Git的安装 1、为什么要使用代码版本控制系统 【1】版本控制 【2】开发中存在的麻烦 2、Git和SVN的对比 【1】Git和SVN对比 (1)SVN (2)Git 3、Git下载和安装 【1】下载 【2】安装 一路下一步就好了,更换安装…...

无涯教程-Lua - 变量声明
变量的名称可以由字母,数字和下划线字符组成。它必须以字母或下划线开头,由于Lua区分大小写,因此大写和小写字母是不同的。 在Lua中,尽管无涯教程没有变量数据类型,但是根据变量的范围有三种类型。 全局变量(Global) …...

vue3学习-组件基础、深入组件
组件 基本概述 单独的 .vue文件 单文件组件(SFC)(single file component) 使用子组件 导入,无需注册,直接使用编译时,区分大小写可使用 />关闭标签 传递 props 需要再组件上声明注册 def…...
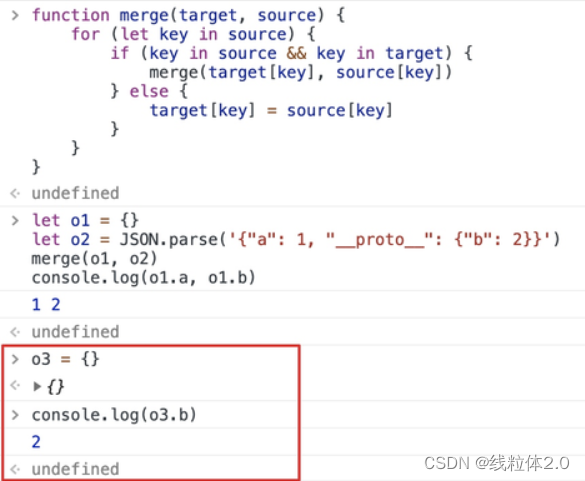
原型链污染分析
原型链污染问题 原型链原型的继承原型链污染 原型链 原型的继承 先创建一个对象,查看一下属性 const obj { prop1: 111, prop2: 222,} 这里的Object.prototype就是对象的原型。 原型里面有许多的属性,这里面的constructor是我们需要着重关注的。 除此…...

RF PCB的9条改进型建议
1.小功率的RF的PCB设计中,主要使用标准的FR4材料(绝缘特性好、材质均匀、介电常数ε=4,10%)。主要使用4层~6层板,在成本非常敏感的情况下可以使用厚度在1mm以下的双面板,要保证反面是一个完整的地层,同时由于双面板的厚度在1mm以上,使得地层和信号层之间的FR4介质较厚,…...
网络安全(黑客)自学就业
前段时间,遇到网友提问,说为什么我信息安全专业的找不到工作? 造成这个结果主要是有两大方面的原因。 第一个原因,求职者本身的学习背景问题。那这些问题就包括学历、学校学到的知识是否扎实,是否具备较强的攻防实战…...

uni-app选择器( uni-data-picker)选择任意级别
背景说明 uni-app 官方的插件市场有数据驱动选择器,可以用作多级分类的场景。引入插件后,发现做不到只选择年级,不选择班级(似乎,只能到最后子节点了)。 需求中,有可能选择的不是叶子。比如&a…...

网络入侵探测器Pi.Alert
什么是 Pi.Alert ? Pi.Alert 是 WIFI/LAN 入侵探测器。通过扫描连接到您的 WIFI/LAN 的设备,提醒您未知设备的连接。它还警告断开“始终连接”的设备。 Pi.Alert 使用了三种扫描方式 方式1:arp-scan。arp扫描系统实用程序用于使用 arp 帧搜索…...
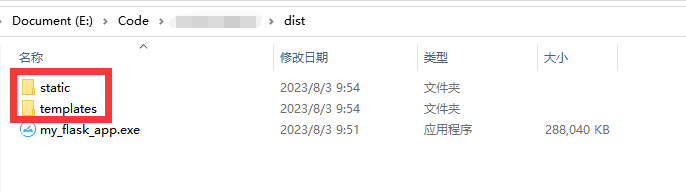
Flask项目打包为exe(附带项目资源,静态文件)
1.在项目根目录创建my_app.spec文件,内容如下: # -*- mode: python ; coding: utf-8 -*-block_cipher Nonea Analysis([server.py], # flask入口pathex[],binaries[], datas[("E:/**/templates","/templates"),("E:/**/s…...

无代码开发(BIP旗舰版-YonBuilder)
目录 我的应用 新建领域 菜单管理 应用构建 新建应用 对象建模 新增业务对象 新增业务实体 页面建模 新增页面 编辑页面 发布管理 我的应用 角色管理 yonbuilder开发平台,提供标准服务和专业开发服务; 本篇文章只演示标准服务的可视化应用…...
誉天程序员-瀑布模型-敏捷开发模型-DevOps模型比较
文章目录 2. 项目开发-开发方式2.1. 瀑布开发模型2.2. 敏捷开发模型2.3. DevOps开发模型2.4. 区别 自增主键策略1、数据库支持主键自增自增和uuid方案优缺点 2. 项目开发-开发方式 由传统的瀑布开发模型、敏捷开发模型,一跃升级到DevOps开发运维一体化开发模型。 …...

flutter:占位视图(骨架屏、shimmer)
前言 有时候打开美团,在刚加载数据时会显示一个占位视图,如下: 那么这个是如何实现的呢?我们可以使用shimmer来开发该功能 实现 官方文档 https://pub-web.flutter-io.cn/packages/shimmer 安装 flutter pub add shimmer示例…...

【雕爷学编程】MicroPython动手做(30)——物联网之Blynk 4
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...

python-网络爬虫.BS4
BS4 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库, 它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方 式。 Beautiful Soup 4 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 帮助手册&…...

C# 开发规范
控件命名规则 控件名简写 控件名简写LabellblTextBoxtxtButtonbtnLinkButtonlnkbtnImageButtonimgbtnDropDownListddlListBoxlstDataGriddgDataListdlCheckBoxchkCheckBoxListchklsRadioButtonrdoRadioButtonListrdoltImageimgPanelpnlCalendecldAdRotatorarTabletblRequiredF…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...