[C++项目] Boost文档 站内搜索引擎(3): 建立文档及其关键字的正排 倒排索引、jieba库的安装与使用...

之前的两篇文章:
- 第一篇文章介绍了本项目的背景, 获取了
Boost库文档
🫦[C++项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍…- 第二篇文章 分析实现了
parser模块. 此模块的作用是 对所有文档html文件, 进行清理并汇总
🫦[C++项目] Boost文档 站内搜索引擎(2): 文档文本解析模块parser的实现、如何对文档文件去标签、如何获取文档标题…
至此, 搜索引擎建立索引的4个步骤:
- 爬虫程序爬取网络上的内容, 获取网页等数据
- 对爬取的内容进行解析、去标签, 提取文本、链接、媒体内容等信息
- 对提取的文本进行分词、处理, 得到词条
- 根据词条生成索引, 包括正排索引、倒排索引等
已经完成了前两个
本篇文章完成后两步中, 索引建立的相关接口.
索引
之前做的工作, 已经将所有的文档有效内容写入了data/output/raw文件中
接下来要实现的就是索引的建立.
本项目中, 需要根据raw文件的内容, 分别建立 正排索引 和 倒排索引
- 正排索引, 是从文档
id找到 文件内容 的索引 - 倒排索引, 是从关键字 找到 关键字所在文档
id的索引
而首先要做的是 搭建索引建立的代码结构
建立索引 基本代码结构
本项目要实现的检索索引的流程是:
- 先 通过关键字 检索倒排索引, 获取包含关键字的文档的
id - 然后 通过文档
id检索正排索引, 获取文档内容 - 最后通过文档内容 建立搜索结果的网页
也就是说, 正排索引中需要存储 文档id 和 对应的文档内容, 倒排索引中需要存储 关键字 和 所有包含关键字的文档的id
正排索引和倒排索引的建立都需要获取文档id, 那么 文档id 要在什么时候设置呢? 再建立正排索引时设置还是在建立倒排索引时建立呢?
答案很明显, 要先对文档建立正排索引, 并在 正排索引建立时设置文档id. 因为正排索引的建立 需要 文档id与文档内容 一一对应. 而 倒排索引的建立只是通过 关键字 映射到 包含关键字的文档的id. 没有对应关系也不能与文档本身建立联系.
正排索引结构
暂且不提文档id. 文档内容该怎样存储到正派索引中呢? 直接使用一个string吗?
当然不是, 正排索引中存储的文档内容, 实际是文档的相关信息: title 去标签后的content 官网对应的url
所以, 可以使用结构体(docInfo)来存储文档内容
那么文档id呢? 文档id是索引中文档内容的唯一标识. 文档id该如何设置呢?
当然是使用 数组下标. 如果将每个文档的内容存储在vector中, 那么对应的下标不就天然是文档id吗?
那么, 正排索引 的结构就是 vector<docInfo_t>
倒排索引结构
倒排索引 需要 通过关键字 找到包含关键字的文档id
由于多个文档可能包含相同的关键字, 这意味着在倒排索引中 通过关键字检索 需要可以 获取到一系列数据
这也意味着 本项目中的 倒排索引更适合key:value结构存储. 所以 可以使用unordered_map, 并且value的类型 可以是存储着文档id的vector.
我们将通过关键字 在倒排索引中检索到的 存储有相关文档id的vector, 称为 倒排拉链
而且需要注意的是, 倒排索引是通过关键字 搜索文档的索引. 而搜索引擎, 也是通过关键字来搜索的.
也就是说 搜索引擎搜索到的文档, 就是倒排索引中相关关键字映射到的文档
而 搜索引擎搜索到的结果, 在网页中的显示是需要有一定的顺序的. 也就是 与关键字 高相关的显示在上面, 低相关的显示在后面.
正排索引是文档id到文档内容的索引, 很明显与网页的显示顺序是没有关系的.
而 倒排索引是关键字与相关文档id的映射索引, 所以 设置显示顺序的相关数据也需要在倒排索引中体现. 可以通过 关键字在相关文档中的出现次数, 来简单的判断关键字与文档的相关性(也可以说是关键字在不同文档中的权重).
那么就可以将 关键字相关的文档id 与 关键字在文档中的权重 存储到一个结构体 中. 将此结构体变量存储在 倒排拉链中. 这样 通过关键字检索到文档id的同时, 也检索到了 关键字与此文档的相关度. 可以将这个结构体定义为invertedElem倒排元素
这样 倒排索引 的结构就是 unordered_map<string, vector<invertedElem>>
建立索引 基本结构代码
#pragma once#include <iostream>
#include <fstream>
#include <utility>
#include <vector>
#include <string>
#include <unordered_map>
#include "util.hpp"namespace ns_index {// 用于正排索引中 存储文档内容typedef struct docInfo {std::string _title; // 文档标题std::string _content; // 文档去标签之后的内容std::string _url; // 文档对应官网urlstd::size_t _docId; // 文档id} docInfo_t;// 用于倒排索引中 记录关键字对应的文档id和权重typedef struct invertedElem {std::size_t _docId; // 文档idstd::string _keyword; // 关键字std::uint64_t _weight; // 搜索此关键字, 此文档id 所占权重invertedElem() // 权重初始化为0: _weight(0) {}} invertedElem_t;// 倒排拉链typedef std::vector<invertedElem_t> invertedList_t;class index {private:// 正排索引使用vector, 下标天然是 文档idstd::vector<docInfo_t> forwardIndex;// 倒排索引 使用 哈希表, 因为倒排索引 一定是 一个key 对应一组 invertedElem拉链std::unordered_map<std::string, invertedList_t> invertedIndex;public:// 通过关键字 检索倒排索引, 获取对应的 倒排拉链invertedList_t* getInvertedList(const std::string& keyword) {return nullptr;}// 通过倒排拉链中 每个倒排元素中存储的 文档id, 检索正排索引, 获取对应文档内容docInfo_t* getForwardIndex(std::size_t docId) {return nullptr;}// 建立索引 input 为 ./data/output/rawbool buildIndex(const std::string& input) {return true;}private:// 对一个文档建立正排索引, 获取文档结构体docInfo_t* buildForwardIndex(const std::string& file) {return nullptr;}// 对一个文档建立倒排索引bool buildInvertedIndex(const docInfo_t& doc) {return true;}};
}
1. getInvertedList()接口 实现
getInvertedList()接口的功能非常的简单. 只需要通过关键字检索倒排索引, 获取关键字对应的倒排拉链就可以了
我们已经将倒排索引的结构设置成了unordered_map, 所以这个接口非常容易实现:
// 通过关键字 检索倒排索引, 获取对应的 倒排拉链
invertedList_t* getInvertedList(const std::string& keyword) {// 先找 关键字 所在迭代器auto iter = invertedIndex.find(keyword);if (iter == invertedIndex.end()) {std::cerr << keyword << " have no invertedList!" << std::endl;return nullptr;}// 找到之后return &(iter->second);
}
直接通过unrodered_map的find()接口找到对应关键字的迭代器.
再通过迭代器 返回对应的倒排拉链
2. getForwardIndex()接口 实现
getForwardIndex()接口同样非常简单, 要获取正排索引中的对应docId的文档内容.
实际就是返回vector中docId下标的数据:
// 通过倒排拉链中 每个倒排元素中存储的 文档id, 检索正排索引, 获取对应文档内容
docInfo_t* getForwardIndex(std::size_t docId) {if (docId >= forwardIndex.size()) {std::cerr << "docId out range, error!" << std::endl;return nullptr;}return &forwardIndex[docId];
}
3. buildIndex()接口 实现
buildIndex()接口需要实现的功能是: 将parser模块处理过的 所有文档的信息, 建立 正排索引和倒排索引
可以直接打开对应的文本文件, 按行完整地读取到每个文档的内容.
然后根据文档的内容, 先对其建立正排索引, 再建立倒排索引.
// 提取文档信息, 建立 正排索引和倒排索引
// input 为 ./data/output/raw
bool buildIndex(const std::string& input) {// 先以读取方式打开文件std::ifstream in(input, std::ios::in);if (!in.is_open()) {std::cerr << "Failed to open " << input << std::endl;return false;}std::string line;while (std::getline(in, line)) {// 按照parser模块的处理, getline 一次读取到的数据, 就是一个文档的: title\3content\3url\ndocInfo_t* doc = buildForwardIndex(line); // 将一个文档的数据 建立到索引中if (nullptr == doc) {std::cerr << "Failed to buildForwardIndex for " << line << std::endl;continue;}// 文档建立正排索引成功, 接着就通过 doc 建立倒排索引if (!buildInvertedIndex(*doc)) {std::cerr << "Failed to buildInvertedIndex for " << line << std::endl;continue;}}return true;
}
这里执行
std::getline()按行读取文件内容, 每一次都可以直接读取到一整个文档的信息.因为,
parser模块处理时, 按'\n'将每个文档的信息分隔开了
读取到之后, 就对文档建立正排索引 和 倒排索引:

buildForwardIndex()接口 实现
buildForwardIndex()接口需要实现的功能是:
接收一行完整的文档信息. 然后将文档信息提取成: title content url 并构成结构体docInfo, 并将结构体存储到forwardIndex(一个vector)中. 并设置下标为docInfo中的docId
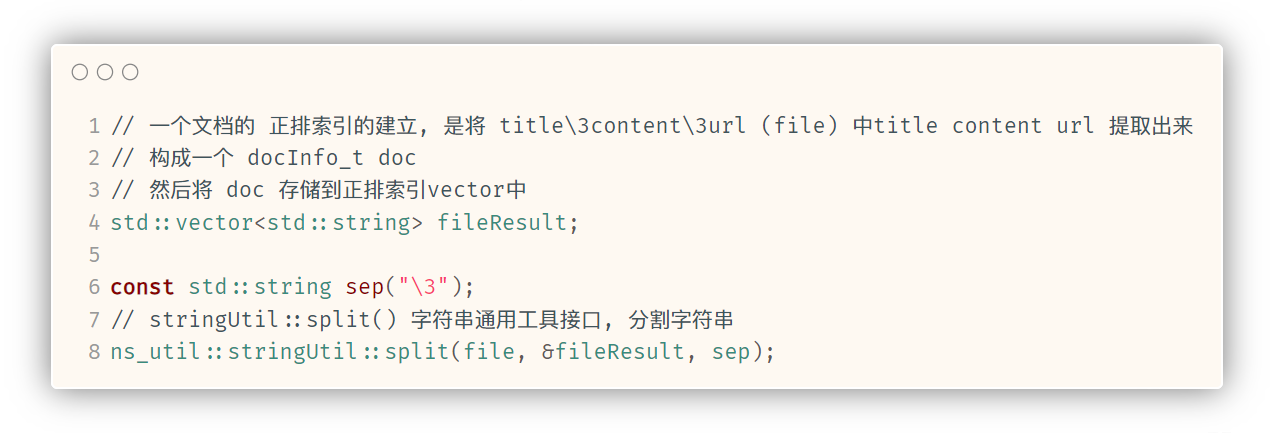
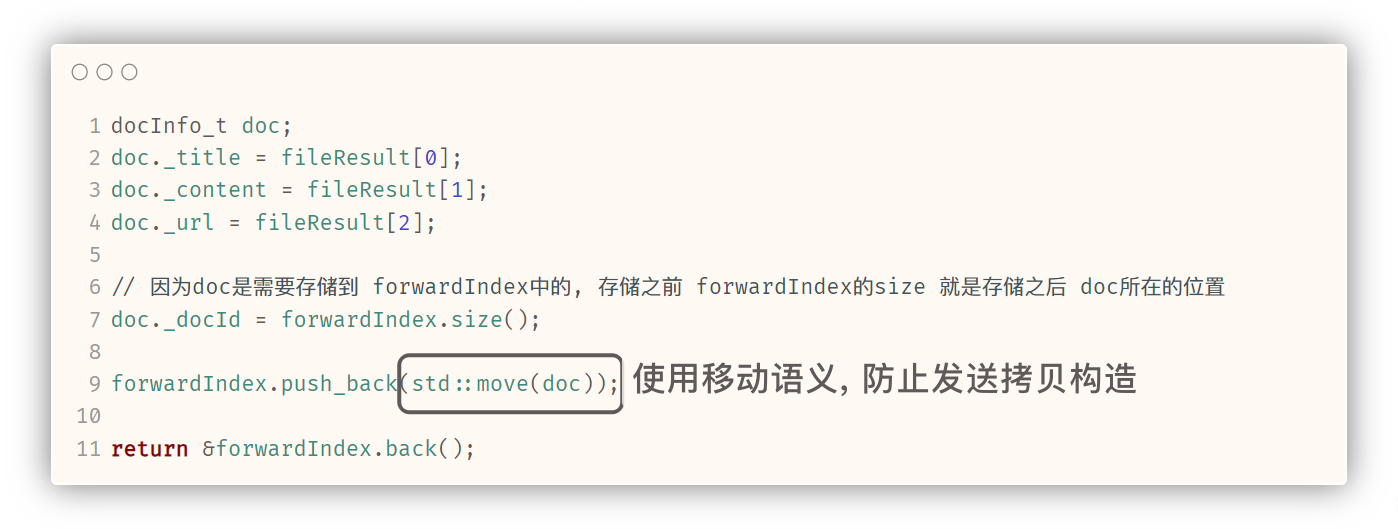
// 对一个文档建立正排索引
docInfo_t* buildForwardIndex(const std::string& file) {// 一个文档的 正排索引的建立, 是将 title\3content\3url (file) 中title content url 提取出来// 构成一个 docInfo_t doc// 然后将 doc 存储到正排索引vector中std::vector<std::string> fileResult;const std::string sep("\3");// stringUtil::split() 字符串通用工具接口, 分割字符串ns_util::stringUtil::split(file, &fileResult, sep);docInfo_t doc;doc._title = fileResult[0];doc._content = fileResult[1];doc._url = fileResult[2];// 因为doc是需要存储到 forwardIndex中的, 存储之前 forwardIndex的size 就是存储之后 doc所在的位置doc._docId = forwardIndex.size();forwardIndex.push_back(std::move(doc));return &forwardIndex.back();
}
本函数接收到完整的一行文档信息file之后, 先通过boost::split()接口以'\3'为分隔符将title content url分隔开. 并按顺序存储到fileResult(一个vector)中
然后, 定义docInfo结构体 并根据fileResult的元素值 填充结构体成员. 填充完毕之后, 将doc存储到forwardIndex中. 并返回正排索引中的当前文档信息.
正排索引的实现相对简单
boost::split()分割字符串接口的使用
buildForwardIndex()函数中, 分割file字符串, 调用了ns_util::stringUtil::split(file, &fileResult, sep)
这是定义在util.hpp中的一个接口:
namespace ns_util {class stringUtil {public:static bool split(const std::string& file, std::vector<std::string>* fileResult, const std::string& sep) {// 使用 boost库中的split接口, 可以将 string 以指定的分割符分割, 并存储到vector<string>输出型参数中boost::split(*fileResult, file, boost::is_any_of(sep), boost::algorithm::token_compress_on);// boost::algorithm::token_compress_on 表示压缩连续的分割符if (fileResult->empty()) {return false;}return true;}};
}
此接口内调用了boost::split()接口
boost::split()是boost库提供的一个 以特定的分割符 分割字符串的接口.
官方文档中, 关于它的描述是这样的:

官方的演示中, split( SplitVec, str1, is_any_of("-*"), token_compress_on ); 将 ("hello abc-*-ABC-*-aBc goodbye"); 分割成了 "hello abc" "ABC" "aBc goodbye" 按顺序存储到了SplitVec中
最后一个框框中的描述 翻译是这样的:
第二个示例使用
split()将字符串str1由字符“-”或“*”分隔的部分 拆分. 然后将这些部分放入SplitVec中. 可以指定相邻分隔符是否连接并且提到, 更多信息可以看
boost/algorithm/string/split.hpp
boost/algorithm/string/split.hpp中, 关于split()的描述是:
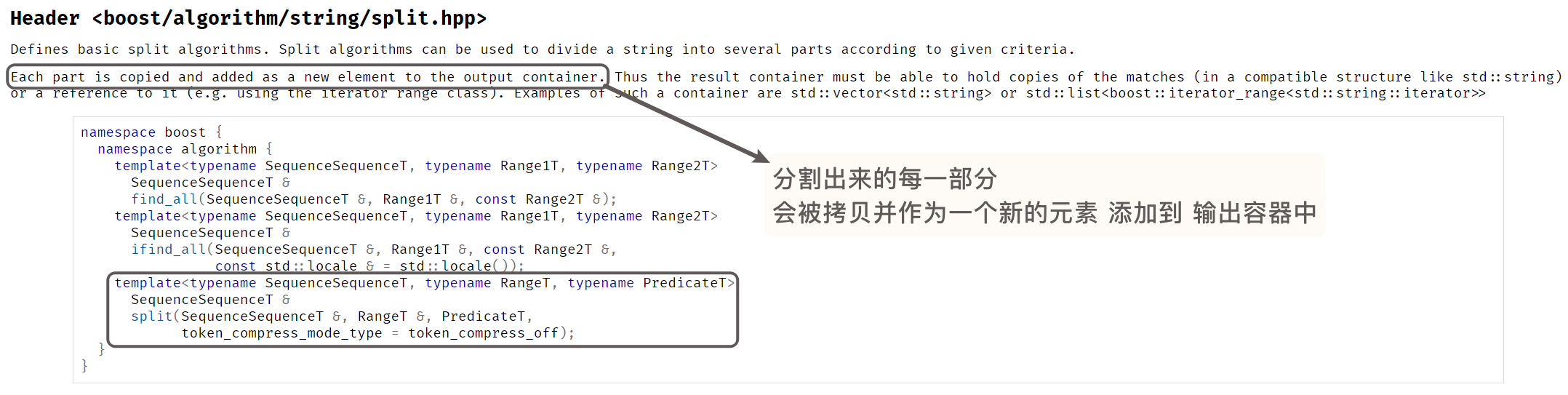
我们根据执行的结果其实已经可以了解到boost::split()的前三个参数是什么了:
boost::split(接收分割出来的字符串的容器, 需要被分割的字符串, boost::is_any_of(分割符字符串), 第四个参数)
boost::split()会将 指定字符串 以分隔符字符串中的任意字符 分割开 并存储到指定的容器中
不过, 第四个参数有什么用呢?
文档中对boost::split()的描述有这样一句话: It is possible to specify if adjacent separators are concatenated or not.(可以指定相邻分隔符是否连接)
什么是相邻分隔符是否连接呢?
可以举一个例子来试验一下:
#include <iostream>
#include <string>
#include <vector>
#include <boost/algorithm/string.hpp>int main() {std::string str = "asdasdasd\3\3\3\3\3\3\3\3\3\3qwdasdasdasda";std::vector<std::string> strV;boost::split(strV, str, boost::is_any_of("\3"), boost::algorithm::token_compress_on);//boost::split(strV, str, boost::is_any_of("\3"), boost::algorithm::token_compress_off);for (auto& e : strV) {std::cout << e << std::endl;}return 0;
}

第四个参数设置为boost::algorithm::token_compress_on时的结果是这样的.
如果设置为boost::algorithm::token_compress_off:

在分割出来的两个字符串之间, 还存在9个空行.
这就是 设置相邻分隔符不连接 的情况.
相邻分隔符连接的意思是, 将相邻的分隔符压缩成一个分隔符. 比如: \3\3\3\3\3\3\3\3\3\3 会被压缩成\3
如果 设置相邻分隔符不连接, 那么 两个分隔符之间会被看作有一个空字符串. 这个空字符串也会被存储到输出型容器中: \3\3两个分隔符之间有一个空字符串"", 被添加到strV中.
如果, 在打印strV内容的时候不换行:

可以看到, 中间是没有任何数据的.
buildInvertedIndex()接口 实现
buildInvertedIndex()接口针对文档信息, 创建倒排索引的接口.
倒排索引是 从关键字 到 相关文档id和权重 的索引. 所以首先要做的就是 针对文档标题和文档内容进行分词
本项目中使用cppjieba开源库分词.
准备: 在项目中安装cppjieba中文分词库
此开源库的安装非常简单.
首先找一个目录执行这两个命令:
git clone https://github.com/yanyiwu/cppjieba.git
git clone https://github.com/yanyiwu/limonp.git
先看一看cppjieba/deps/limonp目录下有没有内容:

# 如果cppjieba/deps/limonp没有内容, 执行下面的命令
cp -r limonp/include/limonp cppjieba/include/cppjieba/.
# 如果cppjieba/deps/limonp有内容, 执行下面的命令
cp -r cppjieba/deps/limonp cppjieba/include/cppjieba/.
然后查看cppjieba/include/cppjieba/limonp目录下 应该是有内容的:

然后, 将cppjieba/include/cppjieba和cppjieba/dict拷贝到项目目录下:
# 博主的项目路径是 /home/July/gitCode/github/Boost-Doc-Searcher
# 注意自己的项目路径
# ❯ pwd
# /home/July/jieba
cp -r cppjieba/include/cppjieba /home/July/gitCode/github/Boost-Doc-Searcher/.
cp -r cppjieba/dict /home/July/gitCode/github/Boost-Doc-Searcher/.
然后查看项目路径下:
这样就把cppjieba库和dict分词库都安装到项目中了
这里博主将
dict目录重命名为cppjiebaDict
关于cppjieba的使用
git clone下来的cppjieba中, 提供了一个简单的cppjieba/test/demo.cpp测试文件:
可以也将其临时拷贝到项目目录下, 然后打开补全 并修正 头文件:
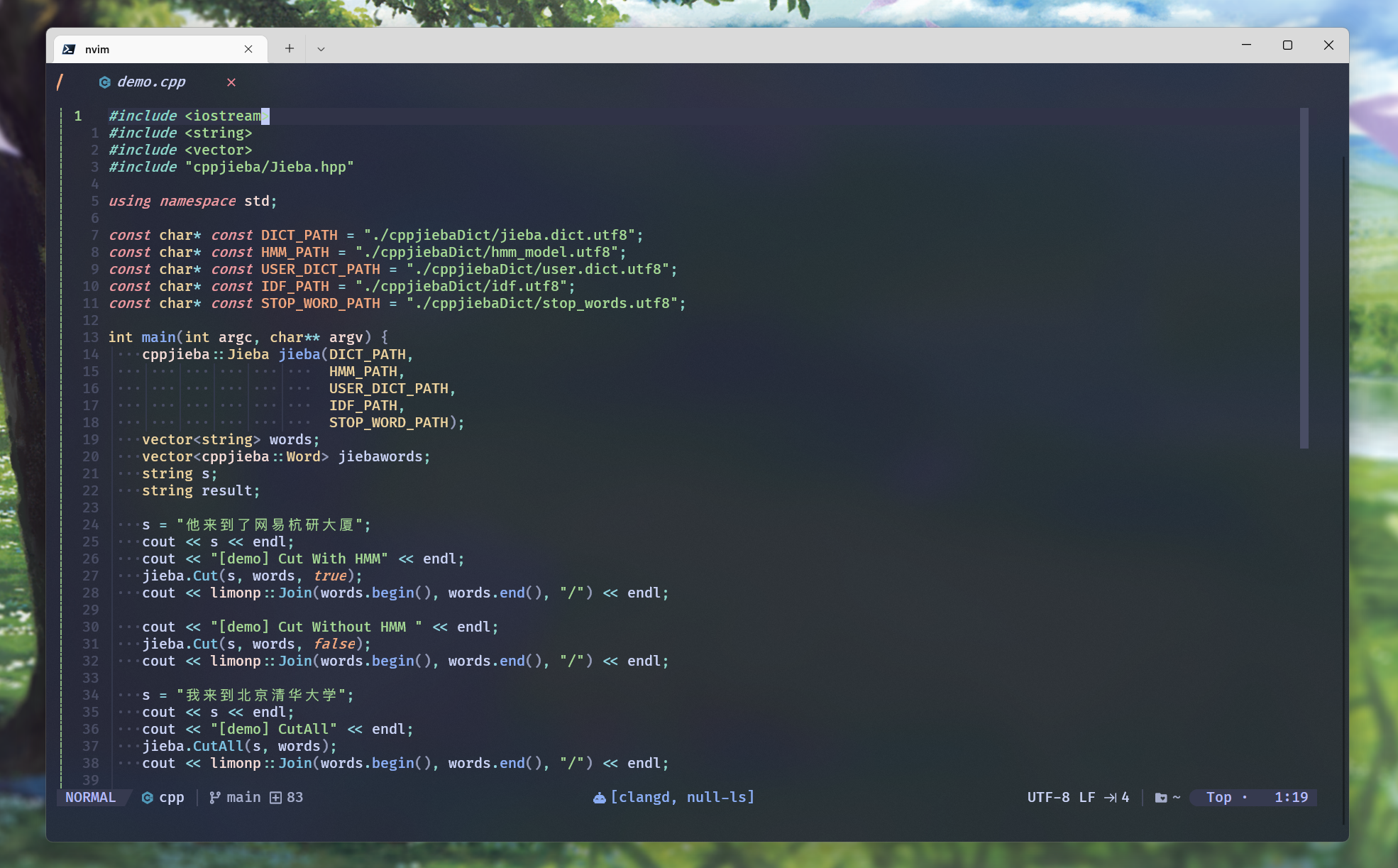
然后编译, 运行可以执行程序:

可以看到有许多的分词方式, 我们选择CutForSearch:

cppjieba的使用是先根据各种分词库, 创建一个Jieba对象. 然后调用Jieba对象中的相应的接口, 来实现分词.
jieba.CutForSearch()是按照搜索的风格分词分词的, 第一个参数是需要分词的字符串, 第二个参数是需要记录分词的vector

开始: 实现buildInvertedIndex()接口
倒排索引是用来通过关键词定位文档的.
倒排索引的结构是 std::unordered_map<std::string, invertedList_t> invertedIndex;
unordered_map的key值就是关键字, value值则是关键字所映射到的文档的倒排拉链
对一个文档建立倒排索引的原理是:
-
首先对文档的标题 和 内容进行分词, 并记录分词
-
分别统计整理 标题分词的词频 和 内容分词的词频
统计词频是为了可以大概表示关键字在文档中的 相关性. 在本项目中, 可以简单的认为关键词在文档中出现的频率, 代表了此文档内容与关键词的相关性. 当然这是非常肤浅的联系, 一般来说相关性的判断都是非常复杂的. 因为涉及到词义 语义等相关分析.
每个关键字 在标题中出现的频率 和 在内容中出现的频率, 可以记录在一个结构体
(keywordCnt)中. 此结构体就表示关键字的词频这里可以直接使用
unordered_map<std::string, keywordCnt_t>容器, 并使用[]重载来记录关键字以及词频 -
通过遍历 记录关键字与词频的
unordered_map, 构建invertedElem:_docId,_keyword,_weight -
构建了关键字的
invertedElem之后, 再将关键词的invertedElem添加到在invertedIndex中 关键词的倒排拉链invertedList中
要实现搜索引擎不区分大小写, 可以将分词出来的所有的 关键字, 在倒排索引中均以小写的形式映射. 在搜索时 同样将 搜索请求分词出的关键字小写化, 在进行检索. 就可以实现搜索不区分大小写.
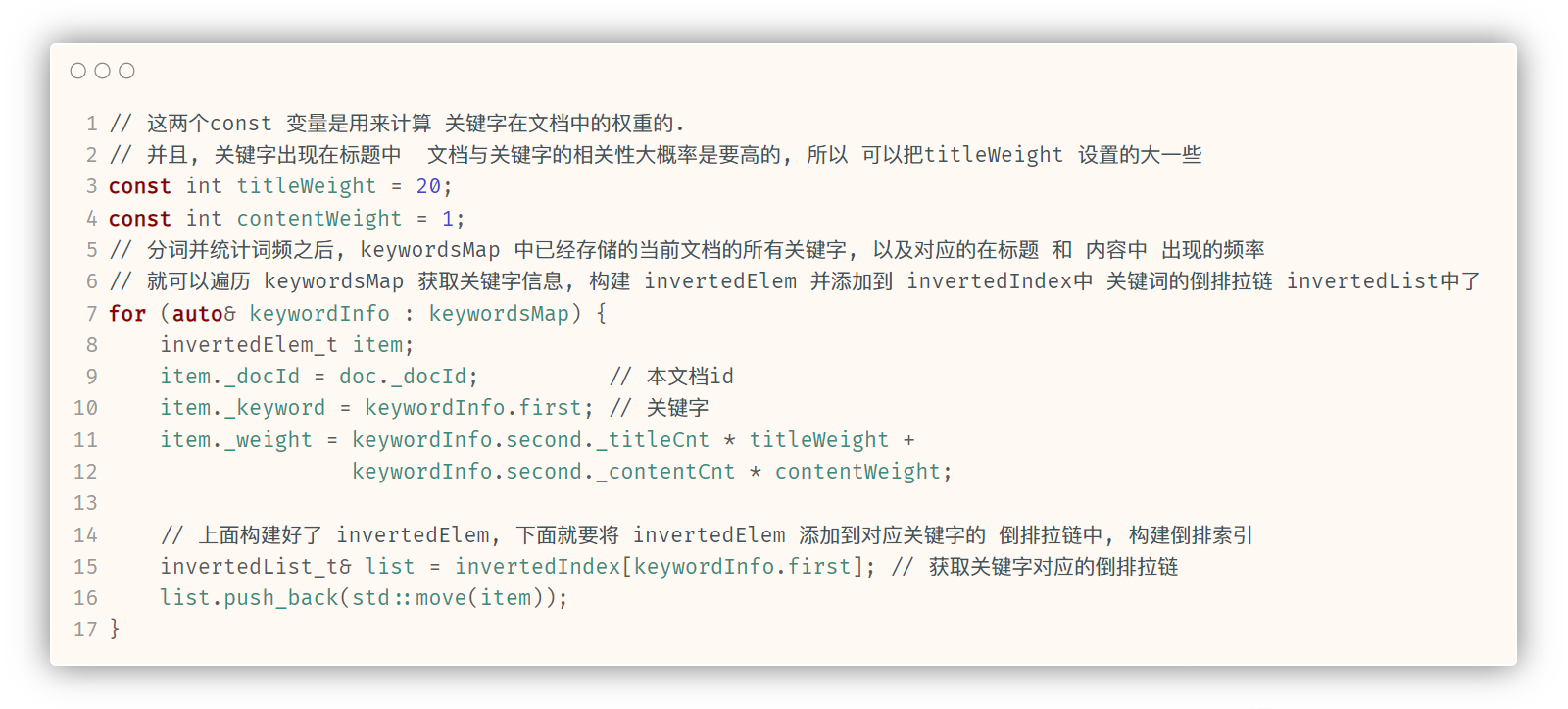
bool buildInvertedIndex(const docInfo_t& doc) {// 用来映射关键字 和 关键字的词频std::unordered_map<std::string, keywordCnt_t> keywordsMap;// 标题分词std::vector<std::string> titleKeywords;ns_util::jiebaUtil::cutString(doc._title, &titleKeywords);// 标题词频统计 与 转换 记录for (auto keyword : titleKeywords) {boost::to_lower(keyword); // 关键字转小写keywordsMap[keyword]._titleCnt++; // 记录关键字 并统计标题中词频// unordered_map 的 [], 是用来通过keyword值 访问value的. // 如果keyword值已经存在, 则返回对应的value, 如果keyword值不存在, 则会插入keyword并创建对应的value}// 内容分词std::vector<std::string> contentKeywords;ns_util::jiebaUtil::cutString(doc._content, &contentKeywords);// 内容词频统计 与 转换 记录for (auto keyword : contentKeywords) {boost::to_lower(keyword); // 关键字转小写keywordsMap[keyword]._contentCnt++; // 记录关键字 并统计内容中词频}// 这两个const 变量是用来计算 关键字在文档中的权重的.// 并且, 关键字出现在标题中 文档与关键字的相关性大概率是要高的, 所以 可以把titleWeight 设置的大一些const int titleWeight = 20;const int contentWeight = 1;// 分词并统计词频之后, keywordsMap 中已经存储的当前文档的所有关键字, 以及对应的在标题 和 内容中 出现的频率// 就可以遍历 keywordsMap 获取关键字信息, 构建 invertedElem 并添加到 invertedIndex中 关键词的倒排拉链 invertedList中了for (auto& keywordInfo : keywordsMap) {invertedElem_t item;item._docId = doc._docId; // 本文档iditem._keyword = keywordInfo.first; // 关键字item._weight = keywordInfo.second._titleCnt * titleWeight + keywordInfo.second._contentCnt * contentWeight;// 上面构建好了 invertedElem, 下面就要将 invertedElem 添加到对应关键字的 倒排拉链中, 构建倒排索引invertedList_t& list = invertedIndex[keywordInfo.first]; // 获取关键字对应的倒排拉链list.push_back(std::move(item));}return true;
}
首先, 分别针对title和content进行分词.
然后分别遍历 标题分词 和 内容分词, 并将当前分词转换为全小写, 然后通过unordered_map::operator[]()来记录分词和分词的词频

最终, 将 标题和内容 的所有分词 以及对应出现在标题的频率和内容的频率, 都记录在了keywordsMap中
然后, 遍历keywordsMap根据当前的关键字以及词频, 构建invertedElem结构体 并填充数据.
填充完之后, 获取对应关键词在invertedIndex中的倒排拉链, 将invertedElem添加到倒排拉链中, 完成对文档的倒排索引建立
ns_util::jiebaUtil::cutString()接口 实现
Jieba::CutForSearch()不仅构建索引时需要使用, 在搜索输入字符串时, 同样需要对输入的字符串以相同的算法分词.
而且, 由于CutForSearch()是Jieba类内成员函数. 所以是需要通过Jieba对象调用的. 如果每次分词都需要先实例化一个Jieba对象, 这未免太麻烦了
所以将可以将Jieba::CutForSearch()在util.hpp中, 实现为一个通用工具函数:
namespace ns_util{const char* const DICT_PATH = "./cppjiebaDict/jieba.dict.utf8";const char* const HMM_PATH = "./cppjiebaDict/hmm_model.utf8";const char* const USER_DICT_PATH = "./cppjiebaDict/user.dict.utf8";const char* const IDF_PATH = "./cppjiebaDict/idf.utf8";const char* const STOP_WORD_PATH = "./cppjiebaDict/stop_words.utf8";class jiebaUtil {private:static cppjieba::Jieba jieba;public:static void cutString(const std::string& src, std::vector<std::string>* out) {// 以用于搜索的方式 分词jieba.CutForSearch(src, *out);}};cppjieba::Jieba jiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
}
在jiebaUtil类内, 定义一个static cppjieba::Jieba jieba. 通过这个静态的Jieba对象 调用CutForSearch(), 并将其封装为一个static函数.
就可以实现非常方便的分词函数.
建立索引代码接口 整合
只包括本篇文章新增的代码, 不包括之前的代码
util.hpp:
#pragma once#include <iostream>
#include <vector>
#include <string>
#include <fstream>
#include <boost/algorithm/string.hpp>
#include "cppjieba/Jieba.hpp"namespace ns_util {class stringUtil {public:static bool split(const std::string& file, std::vector<std::string>* fileResult, const std::string& sep) {// 使用 boost库中的split接口, 可以将 string 以指定的分割符分割, 并存储到vector<string>输出型参数中boost::split(*fileResult, file, boost::is_any_of(sep), boost::algorithm::token_compress_on);// boost::algorithm::token_compress_on 表示压缩连续的分割符if (fileResult->empty()) {return false;}return true;}};const char* const DICT_PATH = "./cppjiebaDict/jieba.dict.utf8";const char* const HMM_PATH = "./cppjiebaDict/hmm_model.utf8";const char* const USER_DICT_PATH = "./cppjiebaDict/user.dict.utf8";const char* const IDF_PATH = "./cppjiebaDict/idf.utf8";const char* const STOP_WORD_PATH = "./cppjiebaDict/stop_words.utf8";class jiebaUtil {private:static cppjieba::Jieba jieba;public:static void cutString(const std::string& src, std::vector<std::string>* out) {// 以用于搜索的方式 分词jieba.CutForSearch(src, *out);}};cppjieba::Jieba jiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
} // namespace ns_util
index.hpp:
#pragma once#include <iostream>
#include <fstream>
#include <utility>
#include <vector>
#include <string>
#include <unordered_map>
#include "util.hpp"namespace ns_index {// 用于正排索引中 存储文档内容typedef struct docInfo {std::string _title; // 文档标题std::string _content; // 文档去标签之后的内容std::string _url; // 文档对应官网urlstd::size_t _docId; // 文档id} docInfo_t;// 用于倒排索引中 记录关键字对应的文档id和权重typedef struct invertedElem {std::size_t _docId; // 文档idstd::string _keyword; // 关键字std::uint64_t _weight; // 搜索此关键字, 此文档id 所占权重invertedElem() // 权重初始化为0: _weight(0) {}} invertedElem_t;// 关键字的词频typedef struct keywordCnt {std::size_t _titleCnt; // 关键字在标题中出现的次数std::size_t _contentCnt; // 关键字在内容中出现的次数keywordCnt(): _titleCnt(0), _contentCnt(0) {}} keywordCnt_t;// 倒排拉链typedef std::vector<invertedElem_t> invertedList_t;class index {private:// 正排索引使用vector, 下标天然是 文档idstd::vector<docInfo_t> forwardIndex;// 倒排索引 使用 哈希表, 因为倒排索引 一定是 一个keyword 对应一组 invertedElem拉链std::unordered_map<std::string, invertedList_t> invertedIndex;public:// 通过关键字 检索倒排索引, 获取对应的 倒排拉链invertedList_t* getInvertedList(const std::string& keyword) {// 先找 关键字 所在迭代器auto iter = invertedIndex.find(keyword);if (iter == invertedIndex.end()) {std::cerr << keyword << " have no invertedList!" << std::endl;return nullptr;}// 找到之后return &(iter->second);}// 通过倒排拉链中 每个倒排元素中存储的 文档id, 检索正排索引, 获取对应文档内容docInfo_t* getForwardIndex(std::size_t docId) {if (docId >= forwardIndex.size()) {std::cerr << "docId out range, error!" << std::endl;return nullptr;}return &forwardIndex[docId];}// 根据parser模块处理过的 所有文档的信息// 提取文档信息, 建立 正排索引和倒排索引// input 为 ./data/output/rawbool buildIndex(const std::string& input) {// 先以读取方式打开文件std::ifstream in(input, std::ios::in);if (!in.is_open()) {std::cerr << "Failed to open " << input << std::endl;return false;}std::string line;while (std::getline(in, line)) {// 按照parser模块的处理, getline 一次读取到的数据, 就是一个文档的: title\3content\3url\ndocInfo_t* doc = buildForwardIndex(line); // 将一个文档的数据 建立到索引中if (nullptr == doc) {std::cerr << "Failed to buildForwardIndex for " << line << std::endl;continue;}// 文档建立正排索引成功, 接着就通过 doc 建立倒排索引if (!buildInvertedIndex(*doc)) {std::cerr << "Failed to buildInvertedIndex for " << line << std::endl;continue;}}return true;}private:// 对一个文档建立正排索引docInfo_t* buildForwardIndex(const std::string& file) {// 一个文档的 正排索引的建立, 是将 title\3content\3url (file) 中title content url 提取出来// 构成一个 docInfo_t doc// 然后将 doc 存储到正排索引vector中std::vector<std::string> fileResult;const std::string sep("\3");// stringUtil::split() 字符串通用工具接口, 分割字符串ns_util::stringUtil::split(file, &fileResult, sep);docInfo_t doc;doc._title = fileResult[0];doc._content = fileResult[1];doc._url = fileResult[2];// 因为doc是需要存储到 forwardIndex中的, 存储之前 forwardIndex的size 就是存储之后 doc所在的位置doc._docId = forwardIndex.size();forwardIndex.push_back(std::move(doc));return &forwardIndex.back();}// 对一个文档建立倒排索引// 倒排索引是用来通过关键词定位文档的.// 倒排索引的结构是 std::unordered_map<std::string, invertedList_t> invertedIndex;// keyword值就是关键字, value值则是关键字所映射到的文档的倒排拉链// 对一个文档建立倒排索引的原理是:// 1. 首先对文档的标题 和 内容进行分词, 并记录分词// 2. 分别统计整理标题分析的词频 和 内容分词的词频// 统计词频是为了可以大概表示关键字在文档中的 相关性.// 在本项目中, 可以简单的认为关键词在文档中出现的频率, 代表了此文档内容与关键词的相关性. 当然这是非常肤浅的联系, 一般来说相关性的判断都是非常复杂的. 因为涉及到词义 语义等相关分析.// 每个关键字 在标题中出现的频率 和 在内容中出现的频率, 可以记录在一个结构体中. 此结构体就表示关键字的词频// 3. 使用 unordered_map<std::string, wordCnt_t> 记录关键字与其词频// 4. 通过遍历记录关键字与词频的 unordered_map, 构建 invertedElem: _docId, _keyword, _weight// 5. 构建了关键字的invertedElem 之后, 再将关键词的invertedElem 添加到在 invertedIndex中 关键词的倒排拉链 invertedList中// 注意, 搜索引擎一般不区分大小写, 所以可以将分词出来的所有的关键字, 在倒排索引中均以小写的形式映射. 在搜索时 同样将搜索请求分词出的关键字小写化, 在进行检索. 就可以实现搜索不区分大小写.// 关于分词 使用 cppjieba 中文分词库bool buildInvertedIndex(const docInfo_t& doc) {// 用来映射关键字 和 关键字的词频std::unordered_map<std::string, keywordCnt_t> keywordsMap;// 标题分词std::vector<std::string> titleKeywords;ns_util::jiebaUtil::cutString(doc._title, &titleKeywords);// 标题词频统计 与 转换 记录for (auto keyword : titleKeywords) {boost::to_lower(keyword); // 关键字转小写keywordsMap[keyword]._titleCnt++; // 记录关键字 并统计标题中词频// unordered_map 的 [], 是用来通过keyword值 访问value的. 如果keyword值已经存在, 则返回对应的value, 如果keyword值不存在, 则会插入keyword并创建对应的value}// 内容分词std::vector<std::string> contentKeywords;ns_util::jiebaUtil::cutString(doc._content, &contentKeywords);// 内容词频统计 与 转换 记录for (auto keyword : contentKeywords) {boost::to_lower(keyword); // 关键字转小写keywordsMap[keyword]._contentCnt++; // 记录关键字 并统计内容中词频}// 这两个const 变量是用来计算 关键字在文档中的权重的.// 并且, 关键字出现在标题中 文档与关键字的相关性大概率是要高的, 所以 可以把titleWeight 设置的大一些const int titleWeight = 20;const int contentWeight = 1;// 分词并统计词频之后, keywordsMap 中已经存储的当前文档的所有关键字, 以及对应的在标题 和 内容中 出现的频率// 就可以遍历 keywordsMap 获取关键字信息, 构建 invertedElem 并添加到 invertedIndex中 关键词的倒排拉链 invertedList中了for (auto& keywordInfo : keywordsMap) {invertedElem_t item;item._docId = doc._docId; // 本文档iditem._keyword = keywordInfo.first; // 关键字item._weight = keywordInfo.second._titleCnt * titleWeight + keywordInfo.second._contentCnt * contentWeight;// 上面构建好了 invertedElem, 下面就要将 invertedElem 添加到对应关键字的 倒排拉链中, 构建倒排索引invertedList_t& list = invertedIndex[keywordInfo.first]; // 获取关键字对应的倒排拉链list.push_back(std::move(item));}return true;}};
} // namespace ns_index
OK了, 首版关于索引建立的相关接口就完成了
感谢阅读~
相关文章:
[C++项目] Boost文档 站内搜索引擎(3): 建立文档及其关键字的正排 倒排索引、jieba库的安装与使用...
之前的两篇文章: 第一篇文章介绍了本项目的背景, 获取了Boost库文档 🫦[C项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍…第二篇文章 分析实现了parser模块. 此模块的作用是 对所有文档html文件, 进行清理并汇总 🫦[C项目] …...

el-date-picker回显问题解决记录
el-date-picker回显问题记录 组件结构 <el-date-pickerv-model"time"type"datetimerange"range-separator"至"start-placeholder"开始日期"end-placeholder"结束日期"value-format"yyyy-MM-dd HH:mm:ss":defau…...
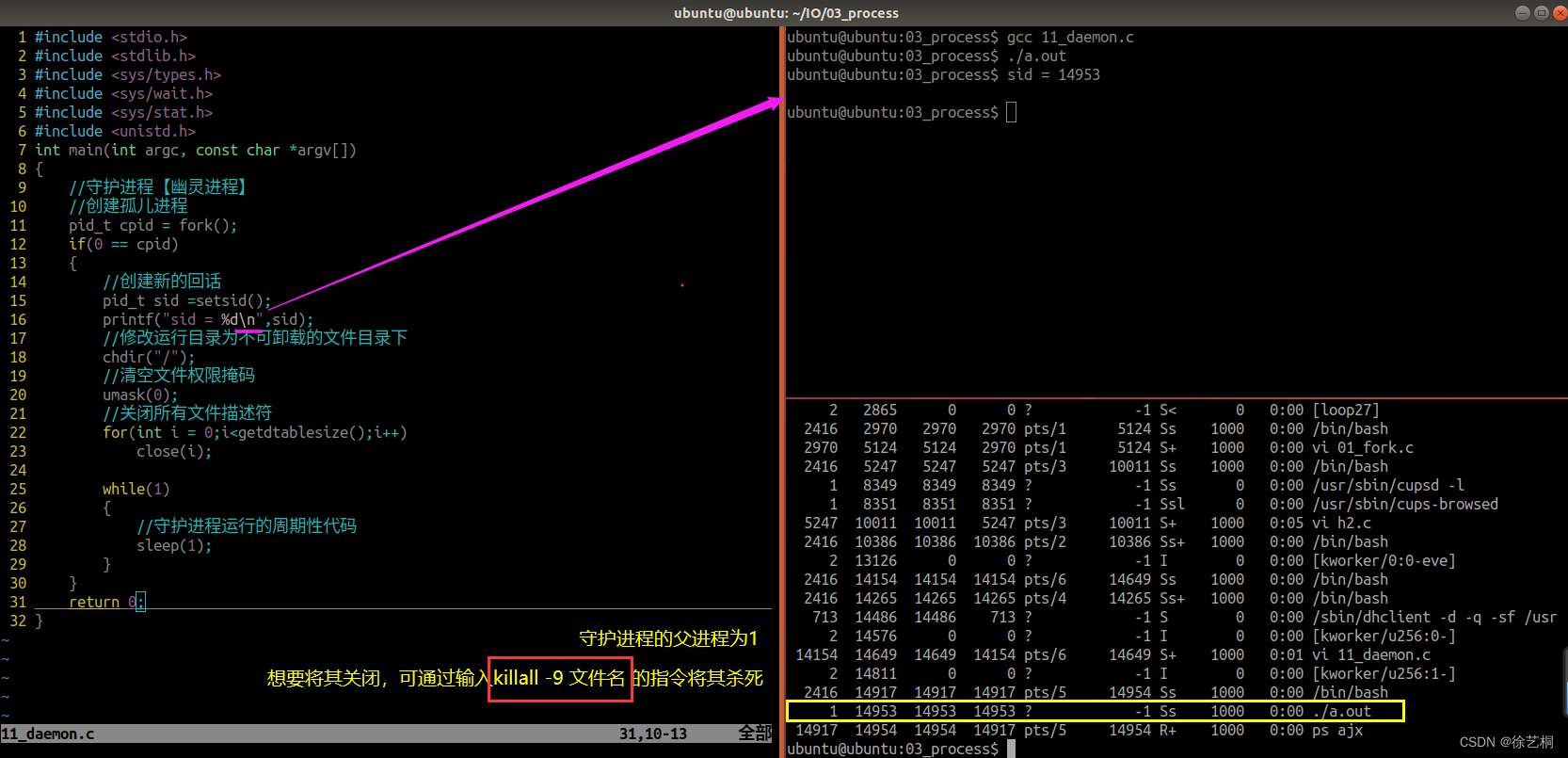
Linux中的特殊进程(孤儿进程、僵尸进程、守护进程)
一、孤儿进程 1)父进程退出,子进程不退出,此时子进程被1号(init)进程收养,变成孤儿进程。 2)孤儿进程会脱离终端控制,且运行在后端,不能用ctrlc杀死后端进程,…...
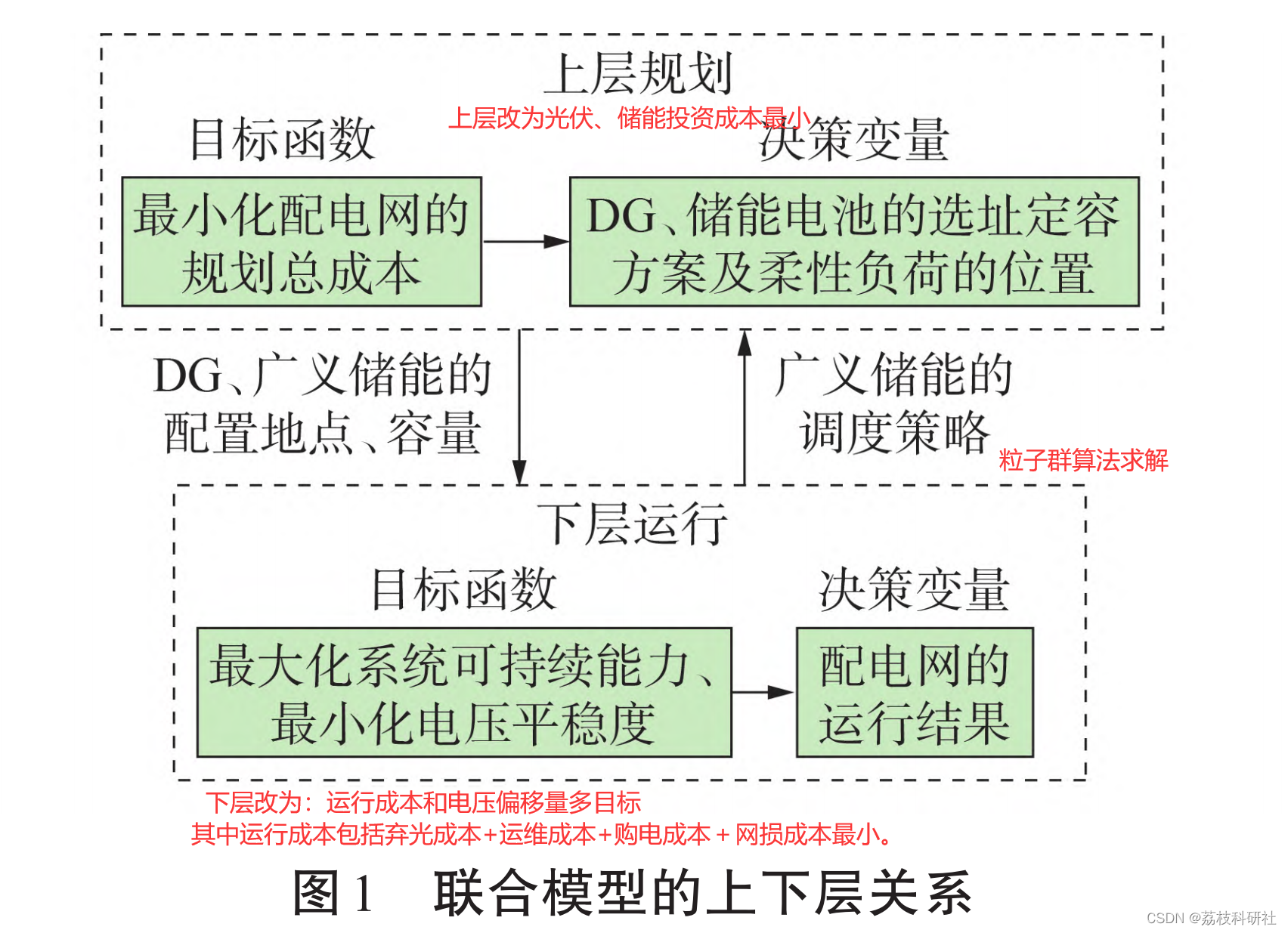
【分布式能源选址与定容】光伏、储能双层优化配置接入配电网研究(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 🌈4 Matlab代码、数据、讲解 💥1 概述 由于能源的日益匮乏,电力需求的不断增长等,配电网中分布式能源渗透率不断提高,且逐渐向主动配电网方…...
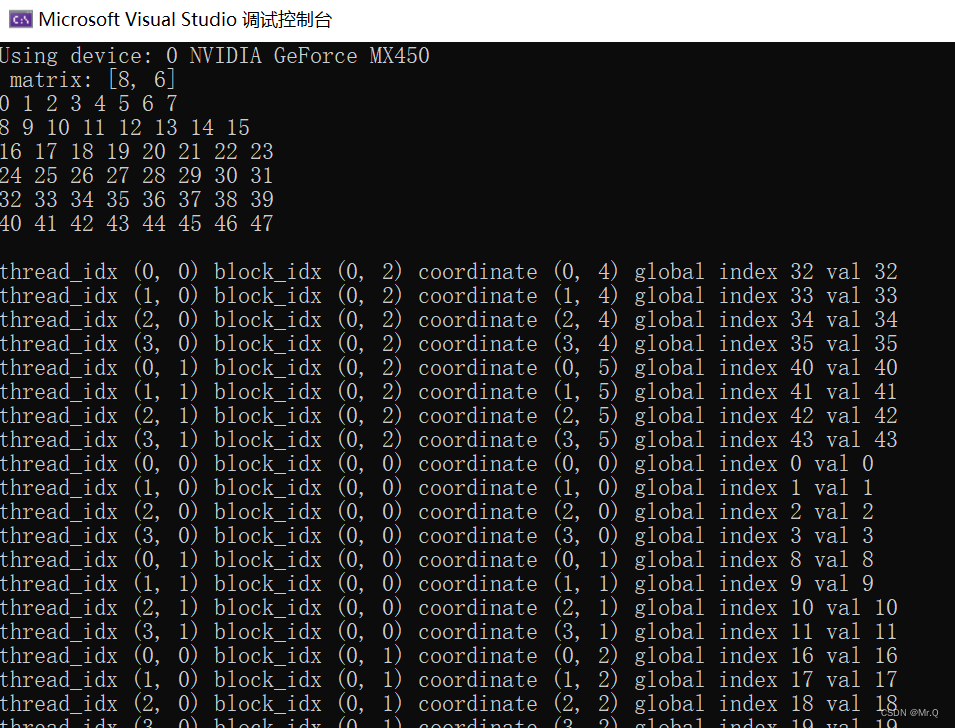
《cuda c编程权威指南》04 - 使用块和线程索引映射矩阵索引
目录 1. 解决的问题 2. 分析 3. 方法 4. 代码示例 1. 解决的问题 利用块和线程索引,从全局内存中访问指定的数据。 2. 分析 通常情况下,矩阵是用行优先的方法在全局内存中线性存储的。如下。 8列6行矩阵(nx,ny)(…...
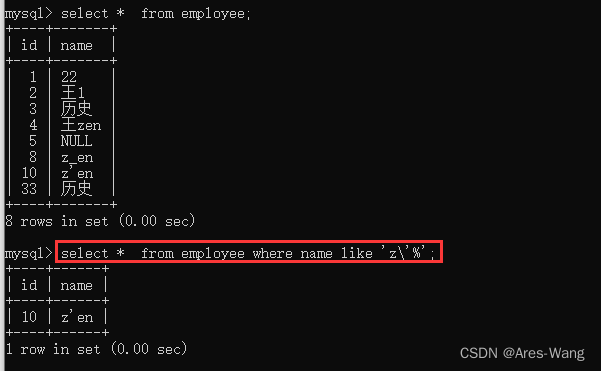
mysql 、sql server 常见的区别
NULL 处理 MySQL IFNULL(col , val) SQL Server ISNULL(col,val) 表名、列名等 一般不推荐用保留字 ,如果非要保留字 MySQL 用用着重号,即 反引号 包括 select col from GROUP SQL Server 用用着重号…...
)
查找特定元素——C++ 算法库(std::find_if)
std::find_if函数在C++中的实际使用案例非常广泛,以下是一些常见的用法示例: 1、在容器中查找满足特定条件的元素: #include <iostream> #include <vector> #include <algorithm>bool isOdd(int num) {...

D3JS教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 D3是Data-Driven Documents的缩写,D3.js是一个基于数据管理文档的资源JavaScript库。 D3 是最有效的数据可视化框架之一。它允许开发人员在 HTML、CSS 和 SVG 的帮助下在浏览器中创建动态的交互式数据可视化。数据可视化是将过滤后的数据以图片和图形的形…...
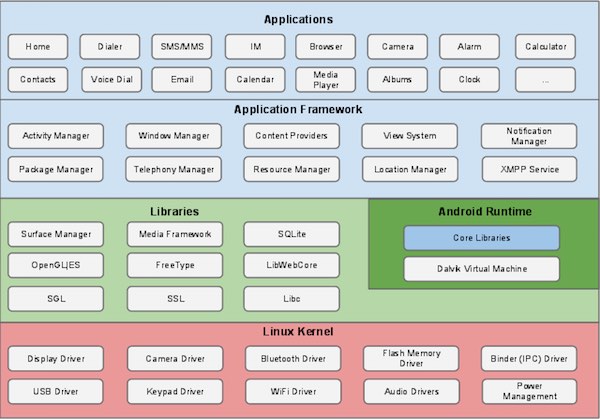
Android入门教程||Android 架构||Android 应用程序组件
Android 架构 Android 操作系统是一个软件组件的栈,在架构图中它大致可以分为五个部分和四个主要层。 Linux内核 在所有层的最底下是 Linux - 包括大约115个补丁的 Linux 3.6。它提供了基本的系统功能,比如进程管理,内存管理,设…...

C语言二进制数据和16进制字符串互转
知识点:结构体中的“伸缩型数组成员”(C99新增) C99新增了一个特性:伸缩型数组成员(flexible array member),利用这项特性声明的结构,其最后一个数组成员具有一些特性。第1个特性是,该数组不会…...
技术复盘(5)--git
技术复盘--git 资料地址原理图安装配置基本命令分支命令对接gitee练习:远程仓库操作 资料地址 学习地址-B站黑马:https://www.bilibili.com/video/BV1MU4y1Y7h5 git官方:https://git-scm.com/ gitee官网:https://gitee.com/ 原理图 说明&am…...
 Spatial Reference System篇 OGRSpatialReference类)
GDAL C++ API 学习之路 (5) Spatial Reference System篇 OGRSpatialReference类
class OGRSpatialReference #include <ogr_spatialref.h> OGRSpatialReference 是 GDAL/OGR 库中的一个重要类,用于管理和操作地理空间数据的空间参考系统(Spatial Reference System,SRS)。它提供了一系列功能&…...
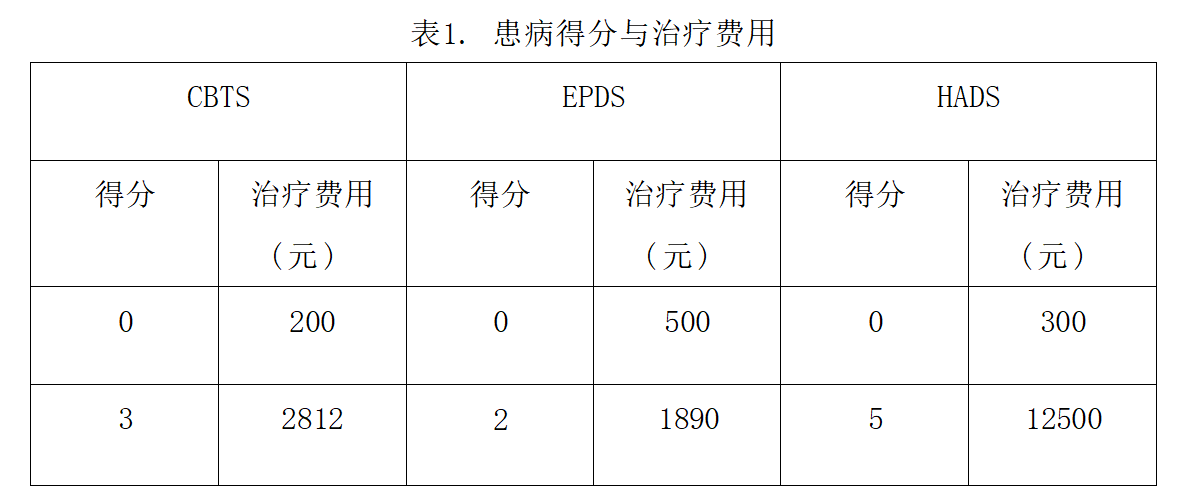
2023年华数杯数学建模C题思路代码分析 - 母亲身心健康对婴儿成长的影响
# 1 赛题 C 题 母亲身心健康对婴儿成长的影响 母亲是婴儿生命中最重要的人之一,她不仅为婴儿提供营养物质和身体保护, 还为婴儿提供情感支持和安全感。母亲心理健康状态的不良状况,如抑郁、焦虑、 压力等,可能会对婴儿的认知、情…...

WebAgent-基于大型语言模型的代理程序
大型语言模型(LLM)可以解决多种自然语言任务,例如算术、常识、逻辑推理、问答、文本生成、交互式决策任务。最近,LLM在自主网络导航方面也取得了巨大成功,代理程序助HTML理解和多步推理的能力,通过控制计算…...

智慧~经典开源项目数字孪生智慧商场——开源工程及源码
深圳南山某商场的工程和源码免费赠送,助您打造智慧商场。立即获取,提升商场管理效能! 项目介绍 凤凰商场作为南山地区的繁华商业中心,提供多样化的购物和娱乐体验。通过此项目,凤凰商场将迈向更智能的商业模式。 本项目…...
LeetCode--剑指Offer75(1)
目录 题目描述:剑指 Offer 05. 替换空格(简单)题目接口解题思路1代码解题思路2代码 PS: 题目描述:剑指 Offer 05. 替换空格(简单) 请实现一个函数,把字符串 s 中的每个空格替换成"%20&quo…...

C++ 关于大端模式和小端模式的简析
大端及小端的简析 序言环境概念理解可能有问题的地方一般情况下需要注意的大小端情况关于大小端相关的实用函数/代码判断自身大小端的代码大小端转换函数 序言 我记得我已经查过4次了,最近回想一下发现我竟然又忘了!所以特以此文来记录一下。 环境 Qt…...
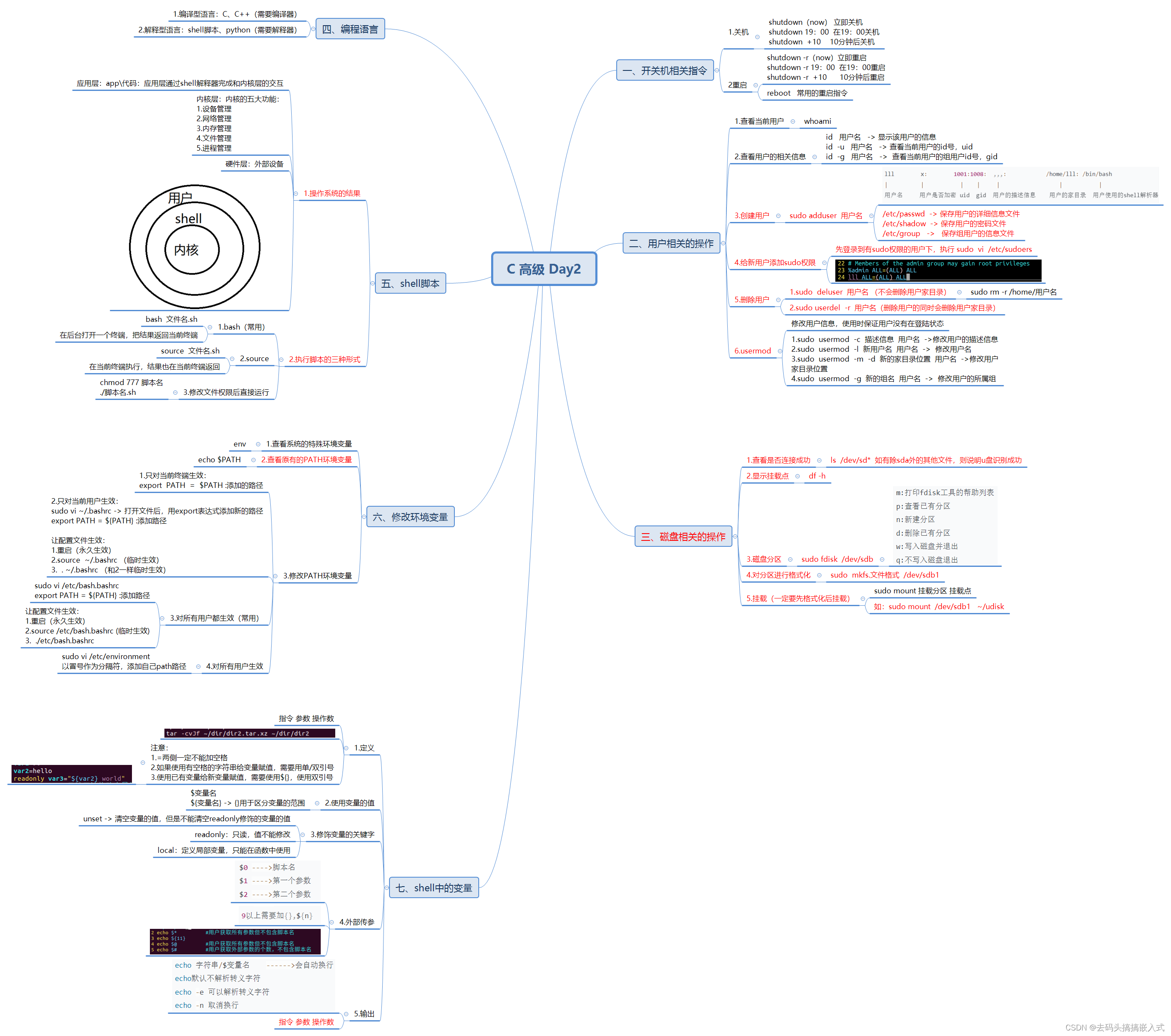
嵌入式:C高级 Day2
一、递归实现,输入一个数,输出这个数的每一位 二、递归实现,输入一个数字,输出这个数的二进制 三、写一个脚本,包含以下内容 1.显示/etc/group文件中第五行的内容 2.创建目录/home/ubuntu/copy 3.切换工作路径到此目录…...

iPhone 7透明屏的显示效果怎么样?
iPhone 7是苹果公司于2016年推出的一款智能手机,它采用了4.7英寸的Retina HD显示屏,分辨率为1334x750像素。 虽然iPhone 7的屏幕并不是透明的,但是苹果公司在设计上采用了一些技术,使得用户在使用iPhone 7时可以有一种透明的感觉…...

【C++】—— 多态常见的笔试和面试问题
序言: 在上期,我们对多态进行了详细的讲解。本期,我给大家带来的是关于有关多态常见的笔试和面试问题,帮助大家理解记忆相关知识点。 目录 (一)概念查考 (二)问答题 1、简述一下…...
)
CPS实战:如何用树莓派+传感器搭建你的第一个信息物理系统(附代码)
CPS实战:如何用树莓派传感器搭建你的第一个信息物理系统(附代码) 信息物理系统(CPS)听起来像是高科技实验室里的复杂装置,但实际上,你完全可以用手边的树莓派和几十元的传感器搭建一个功能完整的…...

EasyAnimateV5-7b-zh-InP模型在微信小程序中的应用:短视频生成功能实现
EasyAnimateV5-7b-zh-InP模型在微信小程序中的应用:短视频生成功能实现 1. 为什么要在微信小程序里集成视频生成能力 最近帮几个做社交内容的小团队做技术咨询,发现一个特别有意思的现象:用户发朋友圈、发群聊、发公众号时,对短…...

Windows系统安装OpenClaw详解:千问3.5-9B模型联调避坑指南
Windows系统安装OpenClaw详解:千问3.5-9B模型联调避坑指南 1. 为什么选择OpenClaw千问3.5-9B组合 去年我在尝试自动化办公流程时,发现市面上的RPA工具要么功能臃肿,要么需要将敏感数据上传到云端。直到遇到OpenClaw这个开源框架,…...

终极指南:gradle-retrolambda在大型项目中的性能优化与稳定性保障策略
终极指南:gradle-retrolambda在大型项目中的性能优化与稳定性保障策略 【免费下载链接】gradle-retrolambda evant/gradle-retrolambda: gradle-retrolambda 插件允许开发者在 Android 项目中使用 Java 8 的 Lambda 表达式和其他现代语言特性,并通过 Ret…...

C++编程中堆与栈内存的差异解析
C编程中堆与栈内存的差异解析 在C编程的世界里,内存管理是一个核心且至关重要的概念。其中,堆(Heap)与栈(Stack)作为两种主要的内存分配区域,各自扮演着不同的角色,理解它们之间的区…...

OpenClaw模型微调集成:Qwen3-14b_int4_awq领域适配实战
OpenClaw模型微调集成:Qwen3-14b_int4_awq领域适配实战 1. 为什么需要领域专用模型 去年我在处理法律合同自动化生成项目时,发现通用大模型在专业术语和条款逻辑上总是差强人意。模型要么生成过于笼统的表述,要么在引用法律条文时出现事实性…...

OpenClaw配置优化:Qwen3-4B模型参数调优实战
OpenClaw配置优化:Qwen3-4B模型参数调优实战 1. 为什么需要调优Qwen3-4B模型参数 去年夏天,当我第一次在OpenClaw中接入Qwen3-4B模型时,发现同样的提示词在不同任务下表现差异巨大。有时它给出的回答过于保守,像在背诵教科书&am…...

用IDM抓取网页动态资源
动态资源抓取的基本原理动态资源通常由JavaScript异步加载或通过API接口返回,传统爬虫难以直接获取。IDM(Internet Download Manager)通过监控浏览器网络请求,可捕获这些动态生成的资源链接。配置IDM捕获动态资源启用IDM的浏览器集…...

单相光伏电池并网:扰动观测法实现最大功率输出与直流母线电压恒定策略
单相光伏电池并网 1.光伏采用扰动观测法实现最大功率输出 2.逆变器采用直流母线电压恒定策略 3.实现光伏的最大功率输出,直流母线电压维持在恒定值,总谐波畸变率满足并网条件光伏板在阳台上晒得发烫的时候,我最喜欢蹲在配电箱旁边观察电流表指…...
探索基于BKA - Transformer - LSTM的数据回归预测
基于BKA-Transformer-LSTM的数据回归预测 模型结合Transformer的全局注意力机制和LSTM的短期记忆及序列处理能力 首先,采用Transformer自注意力机制捕捉数据的全局依赖性,并输出一个经过全局上下文编码的表示;然后,采用2024年最新…...