前端面试的游览器部分(5)每篇10题
41.什么是浏览器的同步和异步加载脚本的区别?你更倾向于使用哪种方式,并解释原因。
浏览器的同步和异步加载脚本是两种不同的脚本加载方式,它们的主要区别在于加载脚本时是否阻塞页面的解析和渲染。
- 同步加载脚本:
同步加载脚本是指在加载脚本时,会阻塞页面的解析和渲染。也就是说,浏览器会等待脚本下载并执行完成后,才会继续解析和渲染后续的页面内容。如果有多个同步脚本,它们会按照它们在 HTML 中出现的顺序依次加载和执行。
示例:
<!DOCTYPE html>
<html>
<head><title>同步加载脚本示例</title><script src="script1.js" async="false"></script><script src="script2.js" async="false"></script>
</head>
<body><!-- 页面内容 -->
</body>
</html>- 异步加载脚本:
异步加载脚本是指在加载脚本时,不会阻塞页面的解析和渲染。浏览器会继续解析和渲染后续的页面内容,同时并行加载异步脚本。当脚本下载完成后,会暂停页面的解析,执行该脚本,然后再继续解析和渲染后续的页面内容。异步脚本的执行顺序和下载顺序不一定相同,取决于脚本下载完成的时间。
示例:
<!DOCTYPE html>
<html>
<head><title>异步加载脚本示例</title><script src="script1.js" async></script><script src="script2.js" async></script>
</head>
<body><!-- 页面内容 -->
</body>
</html>推荐的加载方式和原因:
在实际开发中,推荐使用异步加载脚本的方式,因为异步加载脚本有以下优势:
- 更好的页面性能:异步加载脚本不会阻塞页面的解析和渲染,可以加快页面的加载速度和渲染时间,提升用户体验。
- 并行加载:异步加载脚本可以并行加载多个脚本,从而更快地下载和执行脚本,减少页面加载时间。
- 减少阻塞时间:如果某个脚本在加载过程中出现问题,同步加载会阻塞后续脚本的下载和页面解析,而异步加载则不会影响其他脚本的下载和页面解析。
- 更好的兼容性:异步加载脚本可以更好地适应不同网络环境和不同浏览器的情况,提高页面的兼容性。
需要注意的是,虽然异步加载脚本有很多优势,但在某些情况下,如果脚本之间存在依赖关系,或者需要确保某些脚本在页面加载完毕前先执行,同步加载脚本可能更合适。因此,在选择加载方式时,需要根据具体的业务需求和脚本之间的依赖关系来进行选择。
42.如何使用浏览器的开发者工具进行网络请求的监控和性能分析?
浏览器的开发者工具提供了强大的功能来监控网络请求和进行性能分析。以下是使用Chrome浏览器的开发者工具进行网络请求监控和性能分析的步骤:
- 打开开发者工具:
在Chrome浏览器中,可以通过以下几种方式打开开发者工具:
- 点击右上角菜单,选择"更多工具",然后选择"开发者工具"。
- 使用快捷键:F12 或 Ctrl + Shift + I(Windows/Linux)或 Cmd + Opt + I(Mac)。
- 切换到Network(网络)面板:
在开发者工具中,点击顶部导航栏的"Network"选项卡,即可进入网络面板。 - 开始监控网络请求:
在Network面板中,默认情况下,已经开始监控网络请求。如果没有开始,可以点击左上角的圆形按钮,或者按 F5 键,刷新页面后开始监控。 - 查看网络请求列表:
在Network面板中,您将看到页面加载时发起的所有网络请求。每个请求都会显示请求的URL、请求方法、状态码、响应时间等信息。 - 查看请求详情:
点击列表中的任意请求,右侧面板将显示有关该请求的更多详细信息,如请求和响应头部、请求和响应的内容、发起请求的时间线等。 - 进行性能分析:
除了监控网络请求,开发者工具还提供了其他功能,如Performance(性能)面板。在Performance面板中,您可以记录和分析页面的性能情况,包括加载时间、渲染性能、CPU使用情况等。 - 过滤和搜索:
Network面板还提供了过滤和搜索功能,可以根据请求类型、域名、状态码等进行筛选和搜索,以便更快地找到感兴趣的请求。 - 导出数据:
如果需要将网络请求数据导出或分享给其他人,可以使用Network面板右键菜单中的"Save as HAR with Content"选项来导出数据为HAR文件。
通过使用开发者工具的网络面板和性能面板,您可以详细了解页面的网络请求情况和性能表现,从而优化网页加载速度和用户体验。请注意,不同浏览器的开发者工具可能有细微的差异,但基本功能和使用方法类似。
43.如何在浏览器中处理页面的国际化(Internationalization)和本地化(Localization)?
处理页面的国际化(Internationalization,简称为i18n)和本地化(Localization,简称为l10n)是为了使网站或应用能够适应不同地区、不同语言和文化背景的用户。国际化是指将网站或应用设计成能够支持不同的语言和地区,而本地化是指根据特定地区和语言的需求,将页面内容和界面翻译成相应的语言和文化。
以下是在浏览器中处理页面的国际化和本地化的一般步骤:
- 使用合适的字符编码:
确保网页使用UTF-8等适合国际化的字符编码,以支持各种语言的文字和特殊字符。
<meta charset="UTF-8">- 分离文本和代码:
在网页中,将所有文本内容(如提示、按钮文本等)和代码分离开来。不要将文本硬编码到代码中,而是将文本放到专门的资源文件中,便于后续的翻译和本地化。 - 使用国际化的API或库:
在编写代码时,使用国际化的API或库来处理本地化文本的显示。比如在JavaScript中,可以使用Intl对象来处理日期、数字、货币等的本地化显示。
const number = 1234567.89;
console.log(new Intl.NumberFormat('en-US').format(number)); // Output: "1,234,567.89"
console.log(new Intl.NumberFormat('de-DE').format(number)); // Output: "1.234.567,89"- 使用翻译文件:
将页面的所有文本内容提取到一个翻译文件中,这个文件包含了所有需要翻译的文本,每个文本对应着不同语言的翻译。可以使用JSON或XML格式来存储翻译文件。
// en.json
{"welcome": "Welcome to our website!","hello": "Hello, {name}!"
}// de.json
{"welcome": "Willkommen auf unserer Website!","hello": "Hallo, {name}!"
}- 根据用户的语言和地区设置,加载对应的翻译文件:
在页面加载时,根据用户的语言和地区设置,动态加载对应的翻译文件,然后将页面文本替换为对应的翻译文本。 - 提供用户手动选择语言的选项:
为用户提供手动选择语言的选项,以便他们能够根据自己的偏好选择显示的语言。
总结来说,国际化和本地化需要将页面文本和代码进行分离,并使用国际化的API或库来处理本地化文本的显示。同时,需要提供翻译文件和用户语言选择选项,以便为用户提供多语言支持,从而适应不同地区和语言的用户需求。
44.如何使用浏览器的Web Storage API进行本地数据存储?它与Cookie有何不同?
浏览器的 Web Storage API 是一种在客户端(浏览器)上进行本地数据存储的机制,它提供了两种存储方式:localStorage 和 sessionStorage。Web Storage API 与 Cookie 有以下不同点:
- 存储大小限制:
- Cookie:每个 Cookie 的大小限制通常为 4KB,每个域名下的 Cookie 总大小限制通常为 20个或50个,具体取决于浏览器。
- Web Storage API:localStorage 和 sessionStorage 的大小限制通常为 5MB 或更大(具体取决于浏览器),远远大于 Cookie 的存储容量。
- 存储位置:
- Cookie:Cookie 存储在客户端和服务器之间进行数据交换,每次请求都会将相应的 Cookie 附加在 HTTP 头部中,会增加网络请求的数据量。
- Web Storage API:localStorage 和 sessionStorage 存储在客户端浏览器中,不会随着每次请求发送到服务器,只在客户端使用。
- 有效期限制:
- Cookie:可以设置 Cookie 的有效期,可以是会话级别(浏览器关闭后过期)或持久性(指定过期时间)的。
- Web Storage API:localStorage 永久保存在浏览器中,除非用户主动删除或网站清除,否则不会过期;sessionStorage 存储的数据只在当前会话期间有效,当用户关闭浏览器选项卡或浏览器时会被清除。
- 数据与服务器交互:
- Cookie:每次请求都会将相应的 Cookie 附加在 HTTP 头部中,会随着请求发送到服务器,服务器可以操作和修改 Cookie。
- Web Storage API:localStorage 和 sessionStorage 数据不会自动发送到服务器,只在客户端浏览器中使用,无法被服务器操作和修改。
使用 Web Storage API 进行本地数据存储的示例:
<!DOCTYPE html>
<html>
<head><title>Web Storage API 示例</title>
</head>
<body><input type="text" id="inputText"><button onclick="saveData()">保存数据</button><div id="displayData"></div><script>// 保存数据到 localStoragefunction saveData() {const inputText = document.getElementById('inputText').value;localStorage.setItem('data', inputText);displayData();}// 显示保存的数据function displayData() {const data = localStorage.getItem('data');document.getElementById('displayData').innerText = data;}// 页面加载时显示已保存的数据window.onload = function() {displayData();};</script>
</body>
</html>在上述示例中,我们使用 localStorage 存储用户输入的文本数据,并在页面加载时显示已保存的数据。通过 Web Storage API,我们可以方便地在客户端进行数据的存储和读取,而不需要与服务器进行交互,从而提高了性能和用户体验。
45.请解释浏览器的缓存清理策略,以及如何优雅地处理缓存失效问题。
浏览器的缓存清理策略是指浏览器如何管理和清理缓存数据,以确保缓存不会无限增长并导致存储空间的浪费。浏览器的缓存清理策略主要包括以下几个方面:
- 缓存容量限制:
浏览器会对缓存的总大小设置一个上限,通常是浏览器的一部分存储空间或系统的可用存储空间。当缓存达到这个上限时,浏览器会根据一定的算法(例如LRU,最近最少使用)来清理一部分缓存数据,以释放空间供新的缓存数据使用。 - 缓存过期时间:
缓存的资源通常会被标记有一个过期时间,即资源的有效期。当资源过期后,浏览器会认为这些缓存数据已经失效,下次请求时会重新向服务器请求新的资源,并将新的资源缓存起来。 - 缓存验证:
有些资源可能会被标记为可重新验证(cache validation),这意味着即使资源没有过期,浏览器在使用缓存之前仍会向服务器发起请求,检查该资源是否已经发生变化。如果资源未发生变化,则可以继续使用缓存,否则浏览器将获取新的资源并更新缓存。
优雅处理缓存失效问题的方法:
- 使用版本号或哈希值:
为静态资源(例如CSS、JS、图片等)的文件名添加版本号或哈希值,当静态资源发生变化时,文件名会改变,从而强制浏览器重新加载新的资源。
<link rel="stylesheet" href="styles.css?v=1.0">
<script src="app.js?v=1.0"></script>- 设置合理的缓存过期时间:
针对不同类型的资源,设置合理的缓存过期时间,以确保浏览器在资源过期后及时获取最新的资源。
<!-- 设置图片资源过期时间为一周 -->
<img src="example.jpg" alt="Example" expires="604800">- 使用 Cache-Control 头部:
服务器可以通过设置 Cache-Control 头部来控制缓存策略,如max-age(缓存过期时间)、no-cache(强制重新验证缓存)、no-store(禁用缓存)等。 - Service Worker 管理缓存:
使用 Service Worker 来拦截和管理缓存,可以更灵活地控制缓存策略,使得离线访问和缓存管理更加高效。
总结来说,处理缓存失效问题可以通过设置版本号或哈希值、合理设置缓存过期时间、使用 Cache-Control 头部以及使用 Service Worker 等方法,从而使得缓存的数据能够正确失效和更新,提供更好的用户体验和性能。
46.如何使用浏览器的CSS动画和过渡来实现页面动态效果?
使用浏览器的CSS动画和过渡可以实现页面的动态效果,让页面元素在不同状态之间平滑过渡或产生动画效果。下面分别介绍CSS过渡和动画的基本用法:
- 使用CSS过渡(CSS Transitions):
过渡是一种元素从一种状态到另一种状态的平滑过渡效果。通过设置过渡的属性和持续时间,当元素的属性发生改变时,将会以平滑动画的形式过渡到新的状态。
<!DOCTYPE html>
<html>
<head><title>CSS过渡示例</title><style>.box {width: 100px;height: 100px;background-color: red;transition: width 1s, height 1s, background-color 1s; /* 定义过渡的属性和持续时间 */}.box:hover {width: 200px;height: 200px;background-color: blue;}</style>
</head>
<body><div class="box"></div>
</body>
</html>在上述示例中,当鼠标悬停在 .box 元素上时,它的宽度、高度和背景颜色将在1秒的时间内平滑地从原始状态过渡到新的状态。
- 使用CSS动画(CSS Animations):
动画是一种通过关键帧来定义元素的动态效果。通过在 @keyframes 中定义动画的关键帧状态和持续时间,然后通过 animation 属性将动画应用到元素上。
<!DOCTYPE html>
<html>
<head><title>CSS动画示例</title><style>.box {width: 100px;height: 100px;background-color: red;animation: scaleAnimation 2s infinite; /* 应用动画,持续时间2秒,无限循环 */}@keyframes scaleAnimation {0% {transform: scale(1);}50% {transform: scale(1.2);}100% {transform: scale(1);}}</style>
</head>
<body><div class="box"></div>
</body>
</html>在上述示例中,.box 元素将不断以2秒的时间在 0%、50%、100% 这三个关键帧状态之间进行缩放动画,从原始大小到放大再回到原始大小,形成无限循环的动画效果。
无论是过渡还是动画,都可以通过调整CSS样式、关键帧的状态和持续时间来实现各种不同的动态效果。使用CSS动画和过渡,可以在不依赖JavaScript的情况下,实现简单到复杂的动态效果,提升页面的交互体验。
47.请解释浏览器的预加载(Preloading)和预渲染(Prerendering)技术,以及它们的优势和限制。
浏览器的预加载(Preloading)和预渲染(Prerendering)是两种优化技术,用于提前获取和处理网页资源,以提高页面加载速度和用户体验。
- 预加载(Preloading):
预加载是一种在页面加载前提前获取页面所需的资源(如脚本、样式、图片等),从而在用户需要访问时能够更快地呈现页面内容。预加载可以通过<link>标签的rel属性来实现。
<!DOCTYPE html>
<html>
<head><title>预加载示例</title><link rel="preload" href="script.js" as="script"><link rel="preload" href="style.css" as="style">
</head>
<body><!-- 页面内容 -->
</body>
</html>优势:
- 提高页面加载速度:预加载使得资源在实际使用之前就被加载到浏览器的缓存中,从而能够更快地渲染页面内容。
- 减少延迟:当用户需要访问某个资源时,预加载使得该资源能够立即从缓存中获取,减少了网络延迟。
限制:
- 资源浪费:预加载可能会提前加载一些用户可能不会访问的资源,导致不必要的资源浪费。
- 可能会影响其他页面的加载:预加载的资源会占用网络带宽,可能会影响其他页面的加载速度。
- 预渲染(Prerendering):
预渲染是一种在后台预先渲染网页的技术,即使用户并未实际打开该页面,浏览器也会将该页面渲染出来。预渲染可以通过<link>标签的rel属性来实现。
<!DOCTYPE html>
<html>
<head><title>预渲染示例</title><link rel="prerender" href="<https://www.example.com/page-to-prerender.html>">
</head>
<body><!-- 页面内容 -->
</body>
</html>优势:
- 提高页面打开速度:当用户实际访问该页面时,预渲染使得页面内容能够立即显示,提高了页面的打开速度和响应性。
- 改善用户体验:用户在点击链接时,页面能够快速加载和显示,减少了等待时间,提升用户体验。
限制:
- 资源浪费:预渲染会提前渲染页面,可能会占用额外的系统资源和网络带宽,如果用户最终并没有实际打开该页面,可能会造成资源浪费。
需要注意的是,预加载和预渲染可以用来优化网页的加载性能和用户体验,但也需要谨慎使用,避免不必要的资源浪费。在实际应用中,可以根据具体的场景和需求来选择使用这些优化技术。
48.什么是浏览器的垃圾回收(Garbage Collection)?如何避免内存泄漏?
浏览器的垃圾回收(Garbage Collection)是一种自动管理内存的机制。在JavaScript中,当变量不再被引用或不再可访问时,垃圾回收机制会自动回收这些不再使用的内存,以便将内存重新分配给其他变量或对象使用,从而减少内存占用和优化性能。
垃圾回收的主要工作原理是标记和清除。当一个对象不再被引用时,垃圾回收器会标记这个对象,并在后续的垃圾回收周期中将这些被标记的对象清除,释放其占用的内存。
避免内存泄漏的一些常见方法:
- 明确的释放引用:
确保在不需要使用对象时,将对象引用设置为null。这样可以告诉垃圾回收器该对象不再需要,可以进行回收。
let obj = { /* ... */ };
// 使用obj
obj = null; // 明确释放obj的引用,便于垃圾回收- 定时释放:
对于一些长期运行的应用,可以在合适的时机设置定时器,定时释放不再需要的对象引用。 - 使用闭包时注意:
当使用闭包时,需要注意不要在闭包中引用不再需要的对象,以免造成内存泄漏。 - 合理使用事件监听器:
确保在不需要使用的时候,及时移除事件监听器,以避免事件对象和相关资源无法被回收。 - 使用Chrome DevTools进行内存分析:
使用浏览器的开发者工具(比如Chrome DevTools)进行内存分析,定位可能导致内存泄漏的代码,进行修复。 - 优化DOM操作:
避免频繁的DOM操作和重复创建DOM元素,可以使用缓存和批量处理等方法优化DOM操作,减少内存占用。 - 使用节流和防抖:
在事件处理函数中使用节流和防抖机制,避免频繁执行函数,减少不必要的内存占用。
总结来说,避免内存泄漏的关键是在代码中明确释放不再需要的对象引用,以及避免引用不必要的对象。合理地管理内存,能够提高应用的性能和稳定性。使用浏览器的开发者工具进行内存分析,对于定位和解决内存泄漏问题也非常有帮助。
49.请解释浏览器的事件机制和事件流(Event Bubbling和Event Capturing)。
浏览器的事件机制是一种用于处理用户交互和操作的机制,它允许页面元素对用户事件(例如点击、鼠标移动、键盘按键等)作出响应。事件机制包括两个重要的概念:事件流(Event Flow)和事件冒泡(Event Bubbling)。
- 事件流(Event Flow):
事件流描述的是事件在页面中传播和触发的顺序。事件流有两种模式:事件捕获(Event Capturing)和事件冒泡(Event Bubbling)。 - 事件捕获(Event Capturing):
事件捕获是从外向内的传播方式。当事件发生在某个页面元素上时,首先从最外层的父元素开始,逐级向下传播至目标元素,然后再触发目标元素上的事件处理程序。这意味着事件在捕获阶段经历了所有祖先元素,直到达到目标元素。 - 事件冒泡(Event Bubbling):
事件冒泡是从内向外的传播方式。当事件发生在某个页面元素上时,首先触发目标元素上的事件处理程序,然后事件会沿着DOM树向上传播,经历目标元素的所有祖先元素,直到达到最外层的父元素。
事件捕获和事件冒泡构成了事件流的完整过程。在现代浏览器中,事件流的默认行为是事件冒泡,即事件从目标元素开始,向上冒泡至父元素。但可以通过事件处理程序的第三个参数(布尔值)来控制事件的传播方式:
<!DOCTYPE html>
<html>
<head><title>事件流示例</title>
</head>
<body><div id="outer"><div id="inner"><button id="btn">Click Me</button></div></div><script>const outer = document.getElementById('outer');const inner = document.getElementById('inner');const btn = document.getElementById('btn');outer.addEventListener('click', () => console.log('Outer clicked'), true); // 事件捕获阶段inner.addEventListener('click', () => console.log('Inner clicked'), true); // 事件捕获阶段btn.addEventListener('click', () => console.log('Button clicked')); // 默认是事件冒泡阶段</script>
</body>
</html>在上述示例中,当点击按钮时,事件触发的顺序是:Outer clicked -> Inner clicked -> Button clicked,先捕获再冒泡。
总结来说,浏览器的事件机制是通过事件流实现的,事件流包括事件捕获和事件冒泡两种传播方式。默认情况下,事件采用事件冒泡传播,从目标元素开始向外传播至最外层的父元素。但可以通过事件处理程序的第三个参数来控制事件的传播方式,从而实现事件捕获。
50.什么是WebRTC(Web Real-Time Communication)?它有什么用途?
WebRTC(Web Real-Time Communication)是一种开放标准和技术,用于在Web浏览器中实现实时通信和数据传输,包括音频、视频和数据的传输。WebRTC 使得网页应用能够直接进行点对点的实时通信,无需安装插件或其他第三方软件。
WebRTC 的主要用途包括:
-
实时音视频通话:WebRTC 可以实现浏览器之间的音视频通话,包括语音呼叫、视频聊天等。通过WebRTC,开发者可以轻松构建在线会议、视频通话应用、远程教学等应用。
-
数据传输:WebRTC 不仅可以传输音视频数据,还可以传输任意的数据。这使得开发者可以构建基于浏览器的实时文件传输、游戏、共享屏幕等应用。
-
网络游戏:WebRTC 的实时通信功能使得开发者能够构建基于Web浏览器的多人网络游戏,实现玩家之间的实时互动。
-
视频直播:借助WebRTC,开发者可以实现浏览器中的实时视频直播,实时向观众传输视频内容。
-
服务与支持:WebRTC 还可以用于构建在线客服和远程支持应用,实现客服人员与用户之间的实时交流。
WebRTC 的优势在于无需安装插件或其他外部软件即可实现实时通信和数据传输,用户只需打开支持WebRTC 的现代浏览器即可使用。它对于实现实时互动、协作和通信功能的Web应用提供了强大的支持,为Web平台带来了更丰富、更实用的功能。
相关文章:
每篇10题)
前端面试的游览器部分(5)每篇10题
41.什么是浏览器的同步和异步加载脚本的区别?你更倾向于使用哪种方式,并解释原因。 浏览器的同步和异步加载脚本是两种不同的脚本加载方式,它们的主要区别在于加载脚本时是否阻塞页面的解析和渲染。 同步加载脚本: 同步加载脚本…...

数据挖掘七种常用的方法汇总
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。这个定义包括几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户…...
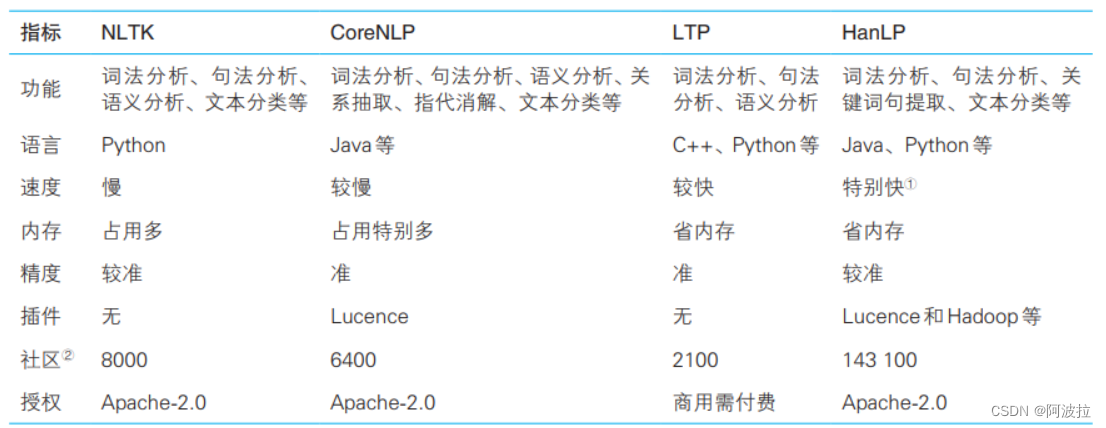
自然语言处理学习笔记(二)————语料库与开源工具
目录 1.语料库 2.语料库建设 (1)规范制定 (2)人员培训 (3)人工标注 3.中文处理中的常见语料库 (1)中文分词语料库 (2)词性标注语料库 (3…...

Rust dyn - 动态分发 trait 对象
dyn - 动态分发 trait 对象 dyn是关键字,用于指示一个类型是动态分发(dynamic dispatch),也就是说,它是通过trait object实现的。这意味着这个类型在编译期间不确定,只有在运行时才能确定。 practice tr…...

uniapp 中过滤获得数组中某个对象里id:1的数据
// 假设studentData是包含多个学生信息的数组 const studentData [{id: 1, name: 小明, age: 18},{id: 2, name: 小红, age: 20},{id: 3, name: 小刚, age: 19},{id: 4, name: 小李, age: 22}, ]; // 过滤获取id为1的学生信息 const result studentData.filter(item > ite…...

Django系列之Channels
1. Channels 介绍 Django 中的 HTTP 请求是建立在请求和响应的简单概念之上的。浏览器发出请求,Django服务调用相应的视图函数,并返回响应内容给浏览器渲染。但是没有办法做到 服务器主动推送消息给浏览器。 因此,WebSocket 就应运而生了。…...
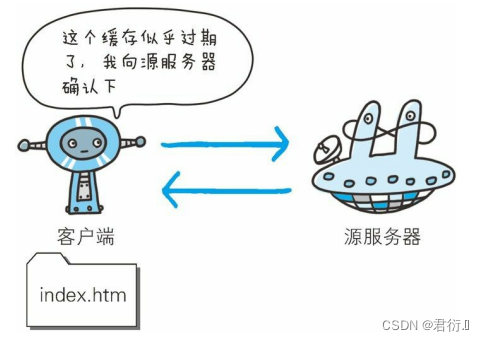
HTTP——五、与HTTP协作的Web服务器
HTTP 一、用单台虚拟主机实现多个域名二、通信数据转发程序 :代理、网关、隧道1、代理2、网关3、隧道 三、保存资源的缓存1、缓存的有效期限2、客户端的缓存 一台 Web 服务器可搭建多个独立域名的 Web 网站,也可作为通信路径上的中转服务器提升传输效率。…...

pyspark笔记 Timestamp 类型的比较
最近写pyspark遇到的一个小问题。 假设我们有一个pyspark DataFrame叫做dart 首先将dart里面timestamp这一列转化成Timestamp类型 dartdart.withColumn(timestamp,col(timestamp).cast(TimestampType()))查看timestamp的前5个元素 dart.select(timestamp).show(5,truncateFal…...
SpringBoot 集成 Redis
本地Java连接Redis常见问题: bind配置请注释掉保护模式设置为noLinux系统的防火墙设置redis服务器的IP地址和密码是否正确忘记写访问redis的服务端口号和auth密码 集成Jedis jedis是什么 Jedis Client是Redis官网推荐的一个面向java客户端,库文件实现…...
黑客学习笔记(网络安全)
一、首先,什么是黑客? 黑客泛指IT技术主攻渗透窃取攻击技术的电脑高手,现阶段黑客所需要掌握的远远不止这些。 以前是完全涉及黑灰产业的反派角色,现在大体指精通各种网络技术的程序人员 二、为什么要学习黑客技术?…...
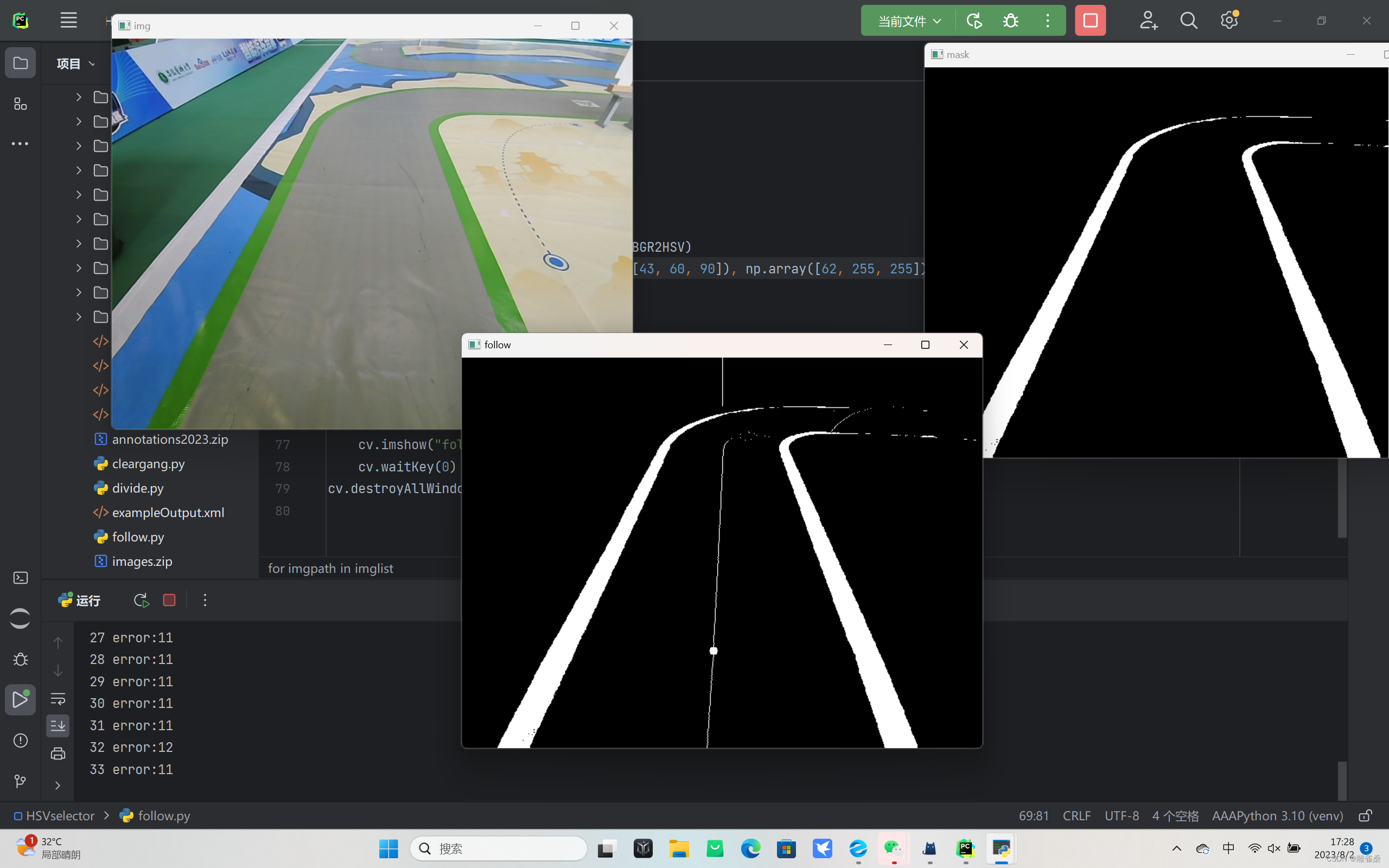
[openCV]基于拟合中线的智能车巡线方案V1
import cv2 as cv import os import numpy as np# 遍历文件夹函数 def getFileList(dir, Filelist, extNone):"""获取文件夹及其子文件夹中文件列表输入 dir:文件夹根目录输入 ext: 扩展名返回: 文件路径列表"""newDir d…...
MyBatis-Plus 和达梦数据库实现高效数据持久化
一、添加依赖 首先,我们需要在项目的 pom.xml 文件中添加 MyBatis-Plus 和达梦数据库的依赖: <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifac…...

已注销【888】
元神密码 - 飞书云文档 (feishu.cn)...

Ceph错误汇总
title: “Ceph错误汇总” date: “2020-05-14” categories: - “技术” tags: - “Ceph” - “错误汇总” toc: false original: true draft: true Ceph错误汇总 1、执行ceph-deploy报错 1.1、错误信息 ➜ ceph-deploy Traceback (most recent call last):File "/us…...

DataTable过滤某些数据
要过滤DataTable中的某些数据,可以使用以下方法: 使用Select方法:可以使用DataTable的Select方法来筛选满足指定条件的数据行。该方法接受一个字符串参数作为过滤条件,返回一个符合条件的数据行数组。 DataTable filteredTable …...
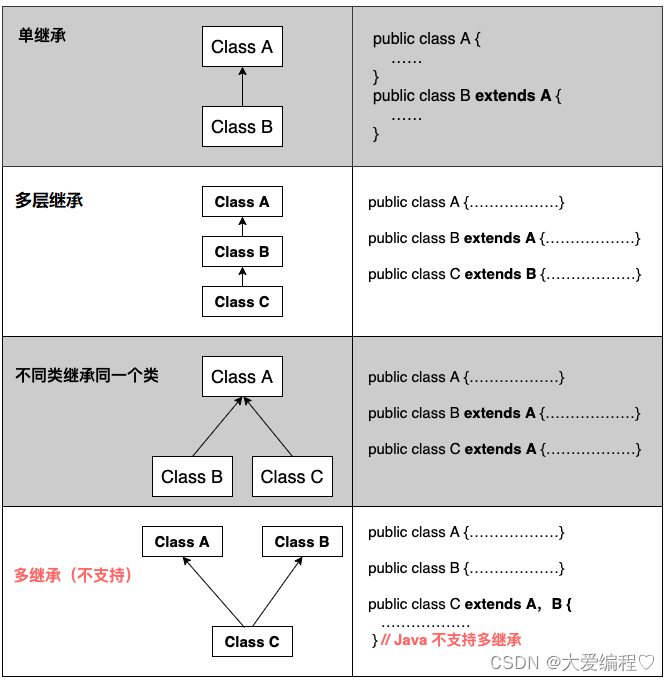
JAVASE---继承和多态
继承 比如,狗和猫,它们都是一个动物,有共同的特征,我们就可以把这种特征抽取出来。 像这样把相同的可以重新放到一个类里面,进行调用,这就是继承。 概念 继承(inheritance)机制:是面向对象程…...

Centos7升级gcc、g++版本(转载)
Centos7默认的 gcc版本是 4.8.5 默认使用yum install gcc安装出来的gcc版本也是是4.8.5。 1.首先查看自己的 gcc 版本 gcc -v g -v如果出现:bash: g: 未找到命令... 则安装g:遇到暂停时,输入y继续安装 yum install gcc-c然后输入…...

第一章:继承
系列文章目录 文章目录 系列文章目录前言继承的概念及定义继承的概念继承定义定义格式继承关系和访问限定符继承基类成员访问方式的变化 基类和派生类对象赋值转换(公有继承)继承中的作用域派生类的默认成员函数继承与友元继承与静态成员不能被继承的类复…...
git面试题
文章目录 git经常用哪些指令git出现代码冲突怎么解决你们团队是怎么管理git分支的如何实现Git的免密操作 git经常用哪些指令 产生代码库 新建一个git代码库 git init下载远程项目和它的整个代码历史 git clone 远程仓库地址配置 显示配置 git config --list [--global]编辑配置…...

Github Copilot在JetBrains软件中登录Github失败的解决方案
背景 我在成功通过了Github Copilot的学生认证之后,在VS Code和PyCharm中安装了Github Copilot插件,但在PyCharm中插件出现了问题,在登录Github时会一直Retrieving Github Device Code,最终登录失败。 我尝试了网上修改DNS&…...
)
别再重启了!Surface Pro蓝牙失灵,试试这个PowerShell命令(Win10/Win11通用)
Surface Pro蓝牙失灵急救指南:5条PowerShell命令快速恢复连接 每次打开Surface Pro发现蓝牙图标神秘消失时,那种焦躁感我深有体会。作为常年携带Surface Pro出差的设计师,我经历过太多次演示前鼠标突然断连的尴尬。经过两年反复试验ÿ…...

▲D2D通信中基于Qlearning强化学习算法的联合资源分配与功率控制算法matlab仿真
目录 📶1.引言 🧠2.系统模型 2.1 网络拓扑 2.2 信号与干扰模型 2.3 容量与吞吐量 2.4 优化目标 ✅3.基于Q学习的联合资源分配与功率控制算法原理 3.1 状态空间定义 3.2 动作空间定义 3.3 奖励函数设计 3.4 Q值更新规则 📚4.MATLA…...

Abaqus 2023保姆级教程:用Python脚本一键搞定悬臂梁的静力与动力分析
Abaqus 2023自动化实战:Python脚本驱动悬臂梁仿真全流程解析 在工程仿真领域,效率提升的关键往往不在于硬件性能的极限压榨,而在于工作流程的智能化改造。当我们反复执行相似的仿真任务时,GUI操作不仅耗时费力,更难以保…...

mysql备份期间如何监控系统负载_使用iostat与top命令
iostat -x 1重点看%util、await、svctm:若%util持续>90%且await>50ms,磁盘成瓶颈;SSD需结合r/s、w/s、吞吐量判断;物理备份写NAS时await高多因网络延迟。备份时磁盘 I/O 突增,iostat 怎么看关键指标MySQL 备份&a…...

【WinCC V7.5 实战:从零搭建污水处理监控系统】
1. 污水处理监控系统与WinCC V7.5的完美结合 污水处理是现代工业中不可或缺的一环,而监控系统则是确保处理过程稳定运行的关键。WinCC V7.5作为西门子经典的SCADA系统,在工业自动化领域有着广泛的应用。对于初学者来说,从零开始搭建一个完整的…...
)
保姆级教程:在Ubuntu 20.04上为全志T507构建Qt5.12.5交叉编译环境(含GPU加速配置)
全志T507 Qt5.12.5交叉编译实战:从环境搭建到GPU加速配置 在嵌入式开发领域,全志T507/T7处理器凭借其出色的性能和丰富的接口资源,成为工业控制、智能终端等场景的热门选择。而Qt框架作为跨平台应用开发的利器,其5.12.5 LTS版本在…...

Go语言中 与 - 操作符的语义解析:地址取值与指针解引用
本文深入讲解 Go 中取地址符 & 和解引用符 * 的本质区别、使用场景及常见误区,结合 json.Decode 等典型用例,帮助开发者准确理解指针机制,避免因混淆操作符导致的编译错误或运行时 panic。 本文深入讲解 go 中取地址符 & 和解引用符 …...

模拟社会:在虚拟环境中训练AI Agent
模拟社会:在虚拟环境中训练AI Agent 关键词:多智能体强化学习(MARL)、社会模拟引擎、认知架构涌现、通用人工智能(AGI)预训练、社会契约理论AI化、零样本社会能力迁移、仿真伦理对齐 摘要 从AlphaGo在棋盘上的单一博弈胜利,到GPT系列在语言符号上的通用能力涌现,人工…...

Spring Data 2027 动态查询:灵活构建数据访问层
Spring Data 2027 动态查询:灵活构建数据访问层 在现代 Java 应用开发中,数据访问层的灵活性和可扩展性是构建高质量应用的关键因素。Spring Data 2027 为开发者提供了更加强大和灵活的动态查询能力,使我们能够根据运行时条件构建复杂的查询…...

从零搭建智能小车:基于A4950与Arduino的直流减速电机PID速度闭环实战
1. 硬件选型与电路搭建 搞智能小车的第一步,就是把硬件给凑齐了。我刚开始玩的时候,最头疼的就是选配件,市面上电机驱动模块五花八门,后来发现A4950特别适合新手。这个芯片自带过流保护,发热量小,最关键的是…...