Nginx 高性能内存池 ----【学习笔记】
跟着这篇文章学习:
c++代码实现一个高性能内存池(超详细版本)_c++ 内存池库_linux大本营的博客-CSDN博客![]() https://blog.csdn.net/qq_40989769/article/details/130874660以及这个视频学习:
https://blog.csdn.net/qq_40989769/article/details/130874660以及这个视频学习:
nginx的内存池_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1WV4y1u7eM/?spm_id_from=333.337.search-card.all.click&vd_source=a934d7fc6f47698a29dac90a922ba5a3小编跟着这篇文章和这个视频学习收获匪浅,也提炼一些自己觉得关键的地方出来。
https://www.bilibili.com/video/BV1WV4y1u7eM/?spm_id_from=333.337.search-card.all.click&vd_source=a934d7fc6f47698a29dac90a922ba5a3小编跟着这篇文章和这个视频学习收获匪浅,也提炼一些自己觉得关键的地方出来。
(一)内存池的应用场景
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
DESCRIPTIONbrk() and sbrk() change the location of the program break, which defines the end of the process's datasegment (i.e., the program break is the first location after the end of the uninitialized data segment).Increasing the program break has the effect of allocating memory to the process; decreasing the breakdeallocates memory.brk() sets the end of the data segment to the value specified by addr, when that value is reasonable,the system has enough memory, and the process does not exceed its maximum data size (see setrlimit(2)).sbrk() increments the program's data space by increment bytes. Calling sbrk() with an increment of 0can be used to find the current location of the program break.描述:brk()和sbrk()改变程序断点的位置,它定义了进程数据的结束段(即,程序断点是未初始化数据段结束后的第一个位置)。增加程序断点的效果是为进程分配内存;减少断裂重新分配内存。brk()将数据段的结束设置为addr指定的值,如果该值是合理的。系统有足够的内存,并且进程没有超过其最大数据大小(参见setrlimit(2))。sbrk()以增量字节增加程序的数据空间。以0的增量调用sbrk(),可用于查找程序断点的当前位置。为什么我们需要内存池?
(1)sbrk不是系统调用,是C库函数。系统调用通常提供一种最小功能,而库函数通常提供比较复杂的功能。在Linux系统上,程序被载入内存时,内核为用户进程地址空间建立了代码段、数据段和堆栈段,在数据段与堆栈段之间的空闲区域用于动态内存分配。C语言的动态内存分配基本函数是malloc(),在Linux上的基本实现是通过内核的brk系统调用。malloc分配的内存是位于堆中的,并且没有初始化内存的内容,因此基本上malloc之后,调用函数memset来初始化这部分的内存空间.这段文字截取自以下文章:
Linux中brk()系统调用,sbrk(),mmap(),malloc(),calloc()的异同【转】_mob604756ff20da的技术博客_51CTO博客![]() https://blog.51cto.com/u_15127651/4611036(2)频繁地malloc 和 free会消耗系统资源
https://blog.51cto.com/u_15127651/4611036(2)频繁地malloc 和 free会消耗系统资源
malloc() 并不是系统调用,也不是运算符,而是 C 库里的函数,用于动态分配内存。
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存:
方式一:通过 brk() 系统调用从堆分配内存
方式二:通过 mmap() 系统调用在文件映射区域分配内存;
深入linux操作系统-malloc到底如何分配内存? - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/581863694
https://zhuanlan.zhihu.com/p/581863694
(3)预先在用户态创建一个缓存空间,作为内存池。申请内存的时候,不走系统调用,可实现超级加速内存管理。
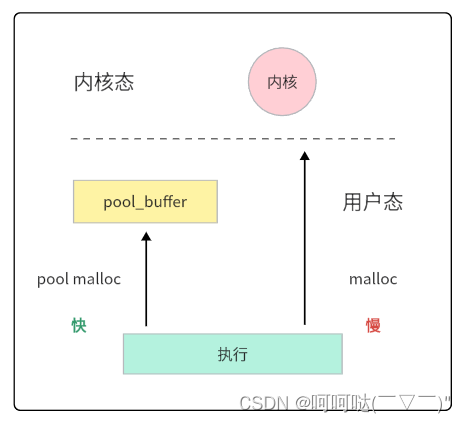
(4)频繁地malloc和free,由于malloc的地址是不确定的,容易产生内存碎片
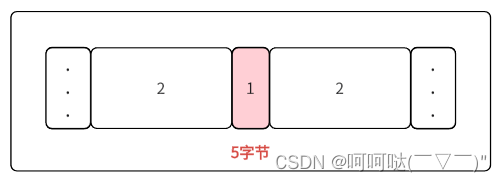
例如:需要4个字节的空间,却因为malloc得到位置随机分配的位置很尴尬,就导致有2+2的空间无法使用。
(二)Nginx内存池的特点
线程池、连接池:核心思想都是对系统的资源调度起一个缓冲的作用。实现大同小异,基本是两队列+中枢的架构。
内存池:可灵活变通,根本原因是面向的实际业务不同。
在Nginx的服务器中,每当有新的客户端连接,就为其创建一个内存池,用于recv和send的缓冲区buffer。
Nginx的内存池的特点概括:
① 有两种内存分配方式,分别是大内存和小内存。可用不同的数据结构来存储。为了适应客户端不同的请求,如果只是一些简单的表单,就用小内存,如果是上传下载大文件,就用大内存。
② 不像线程池会回收利用所有线程,Nginx的内存池不回收小内存的buffer,只回收大内存的buffer。
针对Nginx内存池在实际业务中应用分析:
① 每个内存池都对应一个客户,那么一个客户端产生的小内存碎片自然不会太多,即使不会收,也不会有太大的代价。
② Nginx是典型的将不同客户端分发到多进程的网络模型。
③ tcp本身就有keep-alive机制,超过一定时间就会断开。如果因此连接断开,进程结束,从而对应的内存池会释放,相当于一次性回收所有的大小内存。
④ Nginx很有必要回收连接中大内存,因为其占用空间大。
(三)底层数据结构
(1)实现核心的,小内存
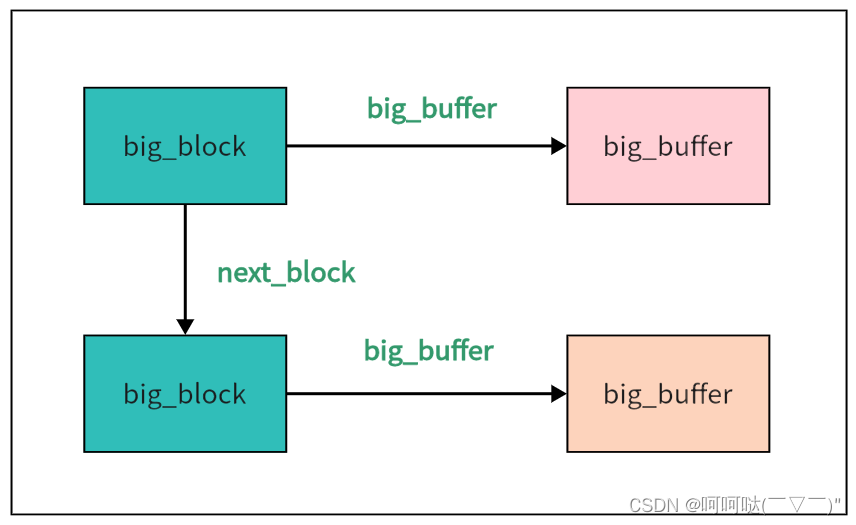
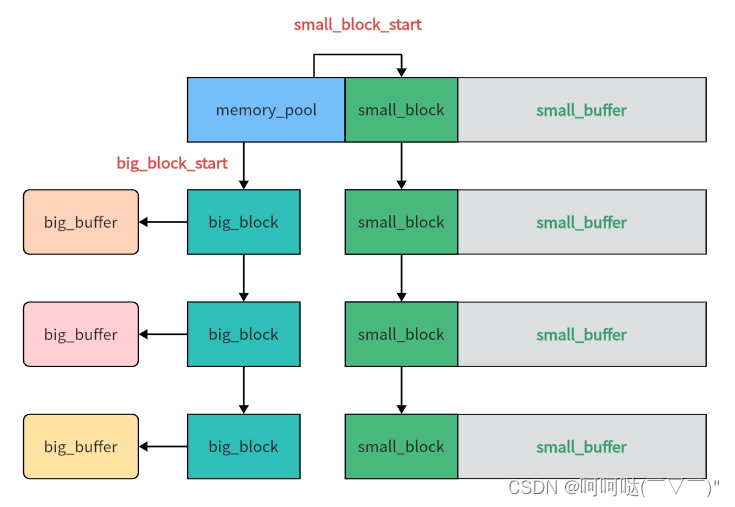
首先整个内存池pool中有两条链,一条是big block链,一条是small block链
small block 数据结构如下:
class small_block{
public:char* cur_usable_buffer; // 指向该block的可用buffer的首地址char* buffer_end; // 指向该block的buffer的结尾地址small_block* next_block; // 指向block链的下一个small blockint no_enough_times; // 每次分配内存,都要顺着small block链,找链中的每个小缓冲区,看是否有足够分配的内存,如果在该block没找到,就会将该值+1,代表没有足够空间命中的次数
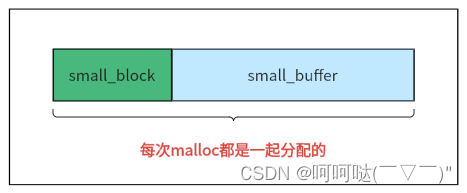
};对于small block,它很特殊,不同于单独的block对象,其后面跟着的buffer,r,当链中所有的小缓冲区都不够位置分配到新的空间时,就会一次性创建空间大小为small_block + buffer_capacity 的新的small block。
为何不先malloc一个small_block,再malloc一个small_buffer呢?
那样会产生两块随机地址,如果一次性创建空间大小为small_block + buffer_capacity 的新的small block,可以让small_block和small_buffer连在一起形成一个整块,方便内存管理。
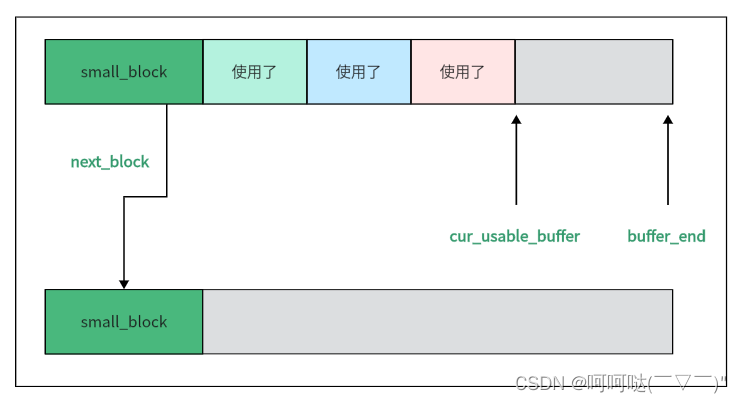
如何拿到small_buffer的首地址指针呢?
只要有了small_block的指针,自然也就可以拿到buffer的首地址指针。
即:buffer_head_ptr = (char*)small_block + sizeof(small_block);
small_block中各指针的指向:
然后是整个内存池pool的数据结构
class memory_pool{
public:/*对于Nginx的内存池,每个small buffer的大小都是一样的,所以该值代表了small buffer的容量,在创建内存池的时候作为参数确定*/size_t small_buffer_capacity;/*每次要分配小内存的时候,并不会从头开始找合适的空间。而是从这个指针指向的small_block开始找。*/small_block* cur_usable_small_block;/*big block链的链头*/big_block* big_block_start;/*small block的链头*/small_block small_block_start[0];static memory_pool *createPool(size_t capacity);static void destroyPool(memory_pool *pool);static char* createNewSmallBlock(memory_pool* pool,size_t size);static char* mallocBigBlock(memory_pool* pool,size_t size);static void* poolMalloc(memory_pool* pool,size_t size);static void freeBigBlock(memory_pool* pool,char* buffer_ptr);
};【注意】:该类的最后一个成员small_block_start,其为一个长度为0的数组。
柔性数组链接教程:【C语言】柔性数组_南木_N的博客-CSDN博客![]() https://blog.csdn.net/Zhuang_N/article/details/128863104
https://blog.csdn.net/Zhuang_N/article/details/128863104
(2)实现大内存
big block的数据结构如下:
class big_block{
public:char* big_buffer; // 大内存buffer的首地址big_block* next_block; // 因为big block也是链式结构,指向下一个big block
};big block最简单,其big_block和big_buffer的地址就是分开的,不会连在一起的。
注意:big_block本身算是一个小内存,那就不应该还是用随机地址,应该保存在内存池内部的空间。而big block是分配在小内存池中的,所以在之后会讲到的销毁池子中可以和小内存一并free掉。
(四)相关api细节
(1)创建线程池 createPool:
为何Nginx要使用柔性数组:small_block_start?
【原因】Nginx希望创建内存池pool的时候,就创建第一个small_block,且同步建立一个small_buffer,让这三个对象的内存连起来。柔性数组的意义在于:不想通过上文提到的指针加法来找到small_block的首地址,可以利用柔性数组在memory_pool保留一个指针锚点来指向第一个small_block。
如何让柔性数组作为锚点? 使用一个0长度的数组作为锚点
【优点】这样malloc整段内存,small_block就会接在memory_pool的后面,且在small_block_start的形式成为pool的成员,实际上small_block_start长度为0是不占pool的内存空间的。
【注意】为什么使用静态成员函数也是这个原因,使用柔性数组必须保证其位置定义在整个类的内存空间的末尾,静态函数虽然在类中声明,但是实际会存放在静态区中保存,不占用类的内存。
//-创建内存池并初始化,api以静态成员(工厂)的方式模拟C风格函数实现
//-capacity是buffer的容量,在初始化的时候确定,后续所有小块的buffer都是这个大小。
memory_pool* memory_pool::createPool(size_t capacity) {//-我们先分配一大段连续内存,该内存可以想象成这段内存由pool+small_block_buffers三个部分组成,//-为什么要把三个部分(可以理解为三个对象)用连续内存来存,因为这样整个池看起来比较优雅,各部分地址不会天女散花地落在内存的各个角落。size_t total_size = sizeof(memory_pool) + sizeof(small_block) + capacity;void* temp = malloc(total_size);memset(temp,0,total_size);memory_pool* pool = (memory_pool*)temp;fprintf(stdout,"pool address:%p\n",pool);//-此时temp是pool的指针,先来初始化pool对象pool->small_buffer_capacity = capacity;pool->big_block_start = nullptr;pool->cur_usable_small_block = (small_block*)(pool->small_block_start);//-pool+1的1是整个memory_pool的步长,别弄错了,此时sbp是small_blcok的指针small_block* sbp = (small_block*)(pool + 1);fprintf(stdout,"first small block address:%p\n",sbp);//-初始化small_block对象sbp->cur_usable_buffer = (char*)(sbp + 1);fprintf(stdout,"first small block buffer address:%p\n",sbp->cur_usable_buffer);sbp->buffer_end = sbp->cur_usable_buffer + capacity;//-第一个可用的buffer就是开头,所以end=开头+capacitysbp->next_block = nullptr;sbp->no_enough_times = 0;return pool;
};(2)代替malloc的分配内存的接口:poolMalloc
根据申请内存的size,判断需要申请的内存是一个大内存还是小内存
① 大内存就走mallocBigBlock这个api
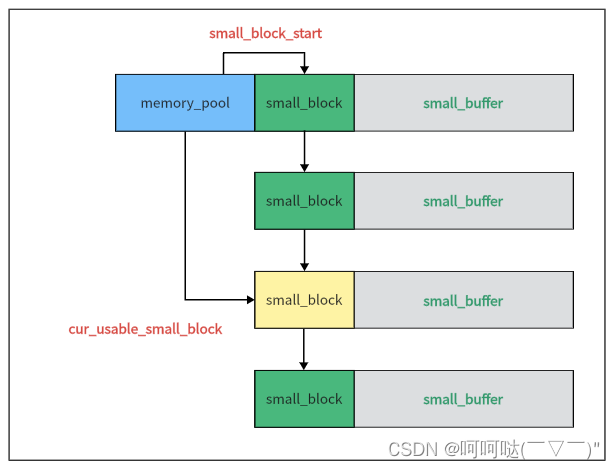
② 小内存,就从cur_usable_small_block这个small block开始找足够的空间去分配内存。
为什么不是从small block链的开头开始寻找?
【原因】因为大概率cur_usable_small_block之前的所有small block都已经分配完了,所以为了提高命中效率,需要这样一个指针指向寻找的开始。
对于每个small_block,如何判断其是否能够分配?
small buffer的剩余容量 = buffer_end - cur_usble_buffer,用这个值和size对比,判断是否能够分配。
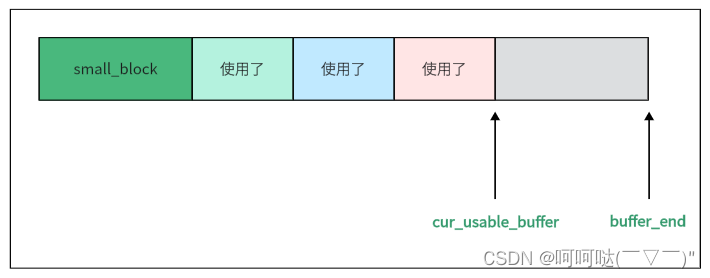
剩余空间分配会出现两种情况:
情况一:足够空间能够被分配,从cur_usable_buffer开始分配size大小的空间,并返回这段空间的首地址,同时更新cur_usable_buffer指向新的剩余空间。
情况二:一直找到链的末尾都没有足够的size大小的空间,那就需要创建新的small block,走createNewSmallBlock 这个api。
//-分配内存
void* memory_pool::poolMalloc(memory_pool* pool,size_t size) {//-先判断要malloc的是大内存还是小内存if(size < pool->small_buffer_capacity) {//-如果是小内存//-从cur small block开始寻找small_block* temp = pool->cur_usable_small_block;do {//-判断当前small block的buffer够不够分配//-如果够分配,直接返回if(temp->buffer_end - temp->cur_usable_buffer > size) {char* res = temp->cur_usable_buffer;temp->cur_usable_buffer = temp->cur_usable_buffer + size;return res;}temp = temp->next_block;}while(temp);//-如果最后一个small block都不够分配,则创建新的small block;//-该small block在创建后,直接预先分配size大小的空间,所以返回即可return createNewSmallBlock(pool,size);}//-分配大内存return mallocBigBlock(pool,size);
}(3)创建新的小内存块:createNewSmallBlock
创建一个smallblock和连带的buffer
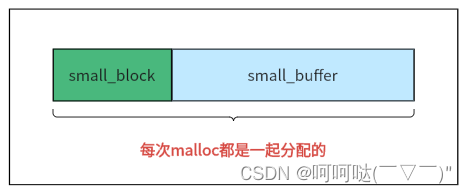
这样创建的目的:为了分配size空间,所以初始化后,便预留size大小的buffer,对cur_usable_buffer进行更新。
【注意】每次到了创建新的small block的环节,就意味着目前链上的small buffer空间已经分配得差不多了,可能需要更新cur_usable_small_block,这就需要用到small block的no_enough_times成员,将cur_usable_small_block开始的每个small block的该值++,Nginx设置的经验值阈值是4,超过4,意味着该block不适合再成为寻找的开始了,需要往后继续尝试。
(4)分配大内存空间:mallocBigBlock
如果size超过了预设的capacity,就需要分配大内存空间,可以走mallocBigBlock 这个api
同样也是一个链式查找的过程,只不过比查找small block更快更粗暴
【注意】
① big block 链没有类似cur_usable_small_blcok这样的节点,
② big block 链只要从头开始遍历,如果有空buffer就返回该block,如果超过3个还没找到(同样是Nginx的经验值)就直接不找了,创建新的big block。
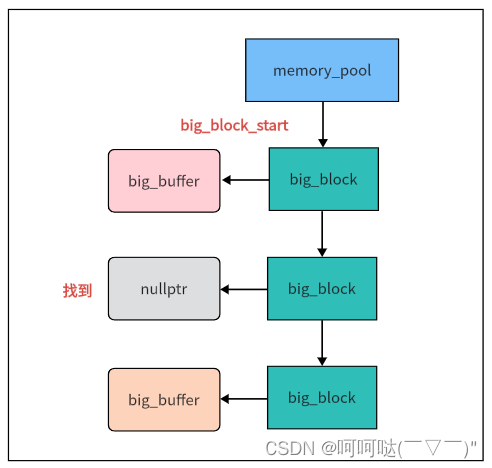
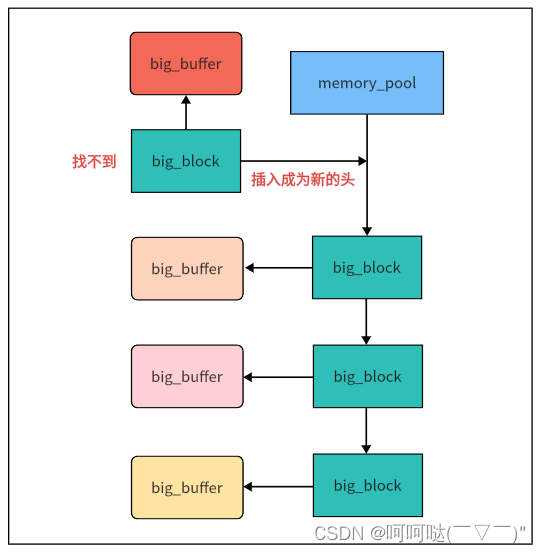
【注意】
① big_buffer是个大内存,所以其是个malloc的随机地址
② big_block本身是一个小内存,那就不应该还是用随机地址,应该保存在内存池内部的空间。方便回收。
③ 套娃的内存池 poolMalloc 操作,用来分配big_blcok的空间
//-分配大块的内存
char *memory_pool::mallocBigBlock(memory_pool* pool,size_t size) {//-先分配size大小的空间void* temp = malloc(size);memset(temp,0,size);//-从big_block_start开始寻找,注意big_block是一个栈式链,插入新元素是插入到头结点的位置big_block* bbp = pool->big_block_start;int i = 0;while (bbp) {if(bbp->big_buffer == nullptr) {bbp->big_buffer = (char *)temp;return bbp->big_buffer;}if(i > 3) {break;//-为了保证效率,如果找三轮还没找到有空buffer的big_block,就直接建立新的big_block}bbp = bbp->next_block;++i;}//-创建新的big_block,这里比较难懂的点,就是Nginx觉得big_block的buffer虽然是一个随机地址的大内存//-但是big_block本身算是一个小内存,那就不应该还是用随机地址,应该保存在内存池内部的空间。//-所以这里有个套娃的内存池malloc操作big_block* new_bbp = (big_block*)memory_pool::poolMalloc(pool,sizeof(big_block));//-初始化new_bbp->big_buffer = (char*)temp;new_bbp->next_block = pool->big_block_start;pool->big_block_start = new_bbp;//-返回分配内存的首地址return new_bbp->big_buffer;
}(5)释放大内存:freeBigBlock:
big block是一个链式结构,可以从这个链的开头进行遍历,一直到找到对应的buffer位置,并free掉。
//~释放大内存的buffer,由于是一个链表,所以,确实,这是一个效率最低的api了
void memory_pool::freeBigBlock(memory_pool* pool,char* buffer_ptr) {big_block* bbp = pool->big_block_start;while (bbp){if(bbp->big_buffer == buffer_ptr) {free(bbp->big_buffer);bbp->big_buffer = nullptr;return;}bbp = bbp->next_block;}}(6)销毁池子:destroyPool:
整个内存池pool中有两条链,一条是big block链,一条是small block链分别沿着这两条链去free掉内存即可。
【注意】
① 大内存的buffer和big block不是一起malloc的,所以只需要free掉buffer。
② big block是分配在小内存池中,之后free掉小内存的时候会顺带一起free掉。
③ small链的free不是从第一个small block开始的,而是从第二个small block。
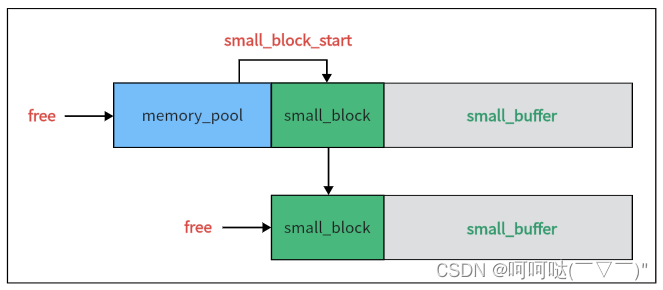
如图所示,第一个small block的空间是和pool一起malloc出来的,不需要free,只要最后的时候free pool就会一起释放掉。
//-销毁内存池
void memory_pool::destroyPool(memory_pool * pool){//-销毁大内存big_block * bbp = pool->big_block_start;while(bbp){if(bbp->big_buffer){free(bbp->big_buffer);bbp->big_buffer = nullptr;}bbp = bbp->next_block;}//-为什么不删除big_block节点?因为big_block在小内存池中,等会就和小内存池一起销毁了//-销毁小内存small_block * temp = pool -> small_block_start->next_block;while(temp){small_block * next = temp -> next_block;free(temp);temp = next;}free(pool);
}(7)测试代码
int main(){memory_pool * pool = memory_pool::createPool(1024);//-分配小内存char*p1 = (char*)memory_pool::poolMalloc(pool,2);fprintf(stdout,"little malloc1:%p\n",p1);char*p2 = (char*)memory_pool::poolMalloc(pool,4);fprintf(stdout,"little malloc2:%p\n",p2);char*p3 = (char*)memory_pool::poolMalloc(pool,8);fprintf(stdout,"little malloc3:%p\n",p3);char*p4 = (char*)memory_pool::poolMalloc(pool,256);fprintf(stdout,"little malloc4:%p\n",p4);char*p5 = (char*)memory_pool::poolMalloc(pool,512);fprintf(stdout,"little malloc5:%p\n",p5);//-测试分配不足开辟新的small blockchar*p6 = (char*)memory_pool::poolMalloc(pool,512);fprintf(stdout,"little malloc6:%p\n",p6);//-测试分配大内存char*p7 = (char*)memory_pool::poolMalloc(pool,2048);fprintf(stdout,"big malloc1:%p\n",p7);char*p8 = (char*)memory_pool::poolMalloc(pool,4096);fprintf(stdout,"big malloc2:%p\n",p8);//-测试free大内存memory_pool::freeBigBlock(pool, p8);//-测试再次分配大内存(我这里测试结果和p8一样)char*p9 = (char*)memory_pool::poolMalloc(pool,2048);fprintf(stdout,"big malloc3:%p\n",p9);//-销毁内存池memory_pool::destroyPool(pool);exit(EXIT_SUCCESS);
}(8)常见的两个问题
- 不用考虑多线程加锁么?
【原因】为了保证高可靠性和可用性,Nginx不是多线程模型,而是多进程,这个池只给一个连接独享,如果是多线程,把池子做成无锁队列即可
- 为什么Nginx不回收小内存?
【原因】① 若创建一个链表pool_freelist专门存这些回收的小内存,从pool_freelist找因为回归顺序不定,内存大小不一,想找到适合自己的大小的块就要一直遍历整个链表,效率就不佳。
【原因】② Nginx 可能觉得小内存本身并不怎么占空间,而且回收还影响速度,再加上它又不是在主进程用的内存池,而且在子进程给每个连接配的内存池,等连接断开,大小内存都回归了,也不会内存泄漏,会更合理。
(9)完整代码
#include <iostream>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>using namespace std;class small_block{
public:char* cur_usable_buffer; // 指向该block的可用buffer的首地址char* buffer_end; // 指向该block的buffer的结尾地址small_block* next_block; // 指向block链的下一个small blockint no_enough_times; // 每次分配内存,都要顺着small block链,找链中的每个小缓冲区,看是否有足够分配的内存,如果在该block没找到,就会将该值+1,代表没有足够空间命中的次数
};class big_block{
public:char* big_buffer; // 大内存buffer的首地址big_block* next_block; // 因为big block也是链式结构,指向下一个big block
};class memory_pool{
public:/*对于Nginx的内存池,每个small buffer的大小都是一样的,所以该值代表了small buffer的容量,在创建内存池的时候作为参数确定*/size_t small_buffer_capacity;/*每次要分配小内存的时候,并不会从头开始找合适的空间。而是从这个指针指向的small_block开始找。*/small_block* cur_usable_small_block;/*big block链的链头*/big_block* big_block_start;/*small block的链头*/small_block small_block_start[0];static memory_pool *createPool(size_t capacity);static void destroyPool(memory_pool *pool);static char* createNewSmallBlock(memory_pool* pool,size_t size);static char* mallocBigBlock(memory_pool* pool,size_t size);static void* poolMalloc(memory_pool* pool,size_t size);static void freeBigBlock(memory_pool* pool,char* buffer_ptr);
};//-创建内存池并初始化,api以静态成员(工厂)的方式模拟C风格函数实现
//-capacity是buffer的容量,在初始化的时候确定,后续所有小块的buffer都是这个大小。
memory_pool* memory_pool::createPool(size_t capacity) {//-我们先分配一大段连续内存,该内存可以想象成这段内存由pool+small_block_buffers三个部分组成,//-为什么要把三个部分(可以理解为三个对象)用连续内存来存,因为这样整个池看起来比较优雅,各部分地址不会天女散花地落在内存的各个角落。size_t total_size = sizeof(memory_pool) + sizeof(small_block) + capacity;void* temp = malloc(total_size);memset(temp,0,total_size);memory_pool* pool = (memory_pool*)temp;fprintf(stdout,"pool address:%p\n",pool);//-此时temp是pool的指针,先来初始化pool对象pool->small_buffer_capacity = capacity;pool->big_block_start = nullptr;pool->cur_usable_small_block = (small_block*)(pool->small_block_start);//-pool+1的1是整个memory_pool的步长,别弄错了,此时sbp是small_blcok的指针small_block* sbp = (small_block*)(pool + 1);fprintf(stdout,"first small block address:%p\n",sbp);//-初始化small_block对象sbp->cur_usable_buffer = (char*)(sbp + 1);fprintf(stdout,"first small block buffer address:%p\n",sbp->cur_usable_buffer);sbp->buffer_end = sbp->cur_usable_buffer + capacity;//-第一个可用的buffer就是开头,所以end=开头+capacitysbp->next_block = nullptr;sbp->no_enough_times = 0;return pool;
};//-销毁内存池
void memory_pool::destroyPool(memory_pool* pool) {//-销毁大内存big_block* bbp = pool->big_block_start;while (bbp) {if(bbp->big_buffer) {free(bbp->big_buffer);bbp->big_buffer = nullptr;}bbp = bbp->next_block;}//-为什么不删除big_block节点?因为big_block在小内存池中,等会就和小内存池一起销毁了//-销毁小内存small_block* temp = pool->small_block_start->next_block;while (temp) {small_block* next = temp -> next_block;free(temp);temp = next;}free(pool);
}//-当所有small block都没有足够空间分配,则创建新的small block并分配size空间,返回分配空间的首指针
char* memory_pool::createNewSmallBlock(memory_pool* pool,size_t size) {//-先创建新的small block,注意还有buffersize_t malloc_size = sizeof(small_block) + pool->small_buffer_capacity;void* temp = malloc(malloc_size);memset(temp,0,malloc_size);//-初始化新的small blocksmall_block* sbp = (small_block*)temp;fprintf(stdout,"new small block address:%p\n",sbp);sbp->cur_usable_buffer = (char*)(sbp + 1);//-跨越一个small_block的步长fprintf(stdout,"new small block buffer address:%p\n",sbp->cur_usable_buffer);sbp->buffer_end = (char*)temp + malloc_size;sbp->next_block = nullptr;sbp->no_enough_times = 0;//-预留size空间给新分配的内存char* res = sbp->cur_usable_buffer;//-存在个副本作为返回值sbp->cur_usable_buffer = res + size;//-因为目前得到所有small_block都没有足够的空间了。//-意味着可能需要更新内存池的cur_usable_small_block,也就是寻找的起点small_block* p = pool->cur_usable_small_block;while (p->next_block) {if(p->no_enough_times > 4) {pool->cur_usable_small_block = p->next_block;}++(p->no_enough_times);p = p->next_block;}//-此时p正好指向当前pool中最后一个small_block,将新节点接上去p->next_block = sbp;//-因为最后一个block有可能no_enough_time > 4 导致 cur_usable_small_block更新成nullptr//-所以还需要判断一下if(pool->cur_usable_small_block == nullptr) {pool->cur_usable_small_block = sbp;}return res;//-返回新分配内存的首地址
}//-分配大块的内存
char *memory_pool::mallocBigBlock(memory_pool* pool,size_t size) {//-先分配size大小的空间void* temp = malloc(size);memset(temp,0,size);//-从big_block_start开始寻找,注意big_block是一个栈式链,插入新元素是插入到头结点的位置big_block* bbp = pool->big_block_start;int i = 0;while (bbp) {if(bbp->big_buffer == nullptr) {bbp->big_buffer = (char *)temp;return bbp->big_buffer;}if(i > 3) {break;//-为了保证效率,如果找三轮还没找到有空buffer的big_block,就直接建立新的big_block}bbp = bbp->next_block;++i;}//-创建新的big_block,这里比较难懂的点,就是Nginx觉得big_block的buffer虽然是一个随机地址的大内存//-但是big_block本身算是一个小内存,那就不应该还是用随机地址,应该保存在内存池内部的空间。//-所以这里有个套娃的内存池malloc操作big_block* new_bbp = (big_block*)memory_pool::poolMalloc(pool,sizeof(big_block));//-初始化new_bbp->big_buffer = (char*)temp;new_bbp->next_block = pool->big_block_start;pool->big_block_start = new_bbp;//-返回分配内存的首地址return new_bbp->big_buffer;
}//-分配内存
void* memory_pool::poolMalloc(memory_pool* pool,size_t size) {//-先判断要malloc的是大内存还是小内存if(size < pool->small_buffer_capacity) {//-如果是小内存//-从cur small block开始寻找small_block* temp = pool->cur_usable_small_block;do {//-判断当前small block的buffer够不够分配//-如果够分配,直接返回if(temp->buffer_end - temp->cur_usable_buffer > size) {char* res = temp->cur_usable_buffer;temp->cur_usable_buffer = temp->cur_usable_buffer + size;return res;}temp = temp->next_block;}while(temp);//-如果最后一个small block都不够分配,则创建新的small block;//-该small block在创建后,直接预先分配size大小的空间,所以返回即可return createNewSmallBlock(pool,size);}//-分配大内存return mallocBigBlock(pool,size);
}//~释放大内存的buffer,由于是一个链表,所以,确实,这是一个效率最低的api了
void memory_pool::freeBigBlock(memory_pool* pool,char* buffer_ptr) {big_block* bbp = pool->big_block_start;while (bbp){if(bbp->big_buffer == buffer_ptr) {free(bbp->big_buffer);bbp->big_buffer = nullptr;return;}bbp = bbp->next_block;}}int main() {memory_pool* pool = memory_pool::createPool(1024);//-分配小内存char* p1 = (char*)memory_pool::poolMalloc(pool,2);fprintf(stdout,"little malloc1:%p\n",p1);char* p2 = (char*)memory_pool::poolMalloc(pool,4);fprintf(stdout,"little malloc2:%p\n",p2);char* p3 = (char*)memory_pool::poolMalloc(pool,8);fprintf(stdout,"little malloc3:%p\n",p3);char* p4 = (char*)memory_pool::poolMalloc(pool,256);fprintf(stdout,"little malloc4:%p\n",p4);char* p5 = (char*)memory_pool::poolMalloc(pool,512);fprintf(stdout,"little malloc5:%p\n",p5);//~测试分配不足开辟新的small blockchar* p6 = (char*)memory_pool::poolMalloc(pool,512);fprintf(stdout,"little malloc6:%p\n",p6);//~测试分配大内存char* p7 = (char*)memory_pool::poolMalloc(pool,2048);fprintf(stdout,"big malloc1:%p\n",p7);char* p8 = (char*)memory_pool::poolMalloc(pool,4096);fprintf(stdout,"big malloc2:%p\n",p8);//~测试free大内存memory_pool::freeBigBlock(pool,p8);//~测试再次分配大内存(我这里测试结果和p8一样)char* p9 = (char*)memory_pool::poolMalloc(pool,2048);fprintf(stdout,"big malloc3:%p\n",p9);//~销毁内存池memory_pool::destroyPool(pool);exit(EXIT_SUCCESS);
};/*malloc栈内是比堆内存快
*/运行效果:
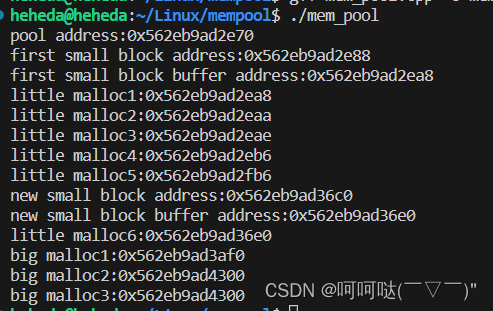
相关文章:
Nginx 高性能内存池 ----【学习笔记】
跟着这篇文章学习: c代码实现一个高性能内存池(超详细版本)_c 内存池库_linux大本营的博客-CSDN博客https://blog.csdn.net/qq_40989769/article/details/130874660以及这个视频学习: nginx的内存池_哔哩哔哩_bilibilihttps://w…...
iOS--frame和bounds
坐标系 首先,我们来看一下iOS特有的坐标系,在iOS坐标系中以左上角为坐标原点,往右为X正方向,往下是Y正方向如下图: bounds和frame都是属于CGRect类型的结构体,系统的定义如下,包含一个CGPoint…...
docker logs 使用说明
docker logs 可以查看某个容器内的日志情况。 前置参数说明 c_name容器名称 / 容器ID logs 获取容器的日志 , 命令如下: docker logs [options] c_name option参数: -n 查看最近多少条记录:docker logs -n 5 c_name--tail与-n 一样 &#…...
)
Ceph入门到精通-Ceph PG状态详细介绍(全)
本文主要介绍PG的各个状态,以及ceph故障过程中PG状态的转变。 Placement Group States(PG状态) creating Ceph is still creating the placement group. Ceph 仍在创建PG。activating The placement group is peered but not yet active.…...
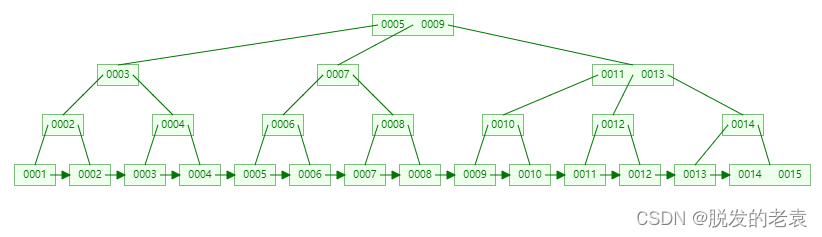
【数据结构】二叉树、二叉搜索树、平衡二叉树、红黑树、B树、B+树
概述 二叉树(Binary Tree):每个节点最多有两个子节点(左子节点和右子节点),没有限制节点的顺序。特点是简单直观,易于实现,但查找效率较低。 二叉搜索树(Binary Search…...

【JVM】(二)深入理解Java类加载机制与双亲委派模型
文章目录 前言一、类加载过程1.1 加载(Loading)1.2 验证(Verification)1.3 准备(Preparation)1.4 解析(Resolution)1.5 初始化(Initialization) 二、双亲委派…...
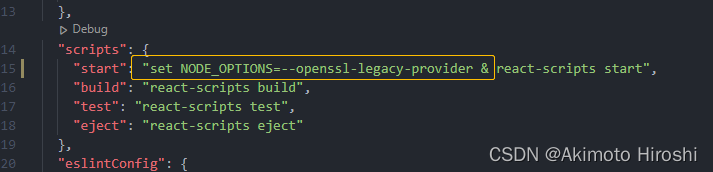
npm i 报错项目启动不了解决方法
1.场景 在另一台电脑低版本node环境跑的react项目,换到另一台电脑node18环境执行npm i时候报错 2.解决方法 脚本前加上set NODE_OPTIONS--openssl-legacy-provider...

【从零开始学习JAVA | 第三十七篇】初识多线程
目录 前言: 编辑 引入: 多线程: 什么是多线程: 多线程的意义: 多线程的应用场景: 总结: 前言: 本章节我们将开始学习多线程,多线程是一个很重要的知识点ÿ…...
微信新功能,你都知道吗?
近日iOS 微信8.0.40正式版来了,一起来看看有哪些变化? 1、朋友圈置顶 几个月前微信开始内测「朋友圈置顶」功能,从网友们的反馈来看,iOS 微信 8.0.40 似乎扩大了内测范围,更多用户可以体验到该功能了。 大家可以去自己…...
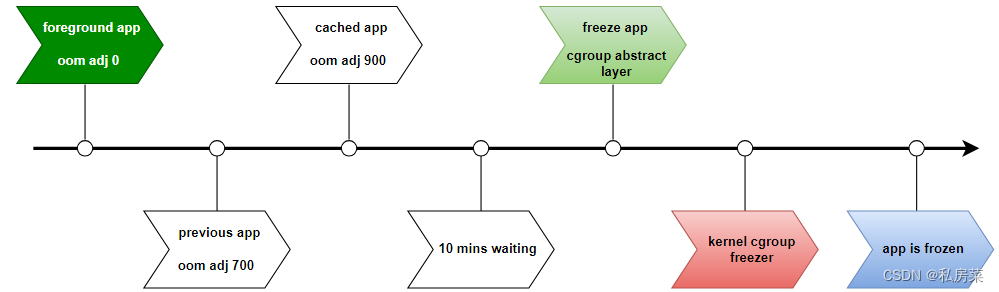
Android 中 app freezer 原理详解(二):S 版本
基于版本:Android S 0. 前言 在之前的两篇博文《Android 中app内存回收优化(一)》和 《Android 中app内存回收优化(二)》中详细剖析了 Android 中 app 内存优化的流程。这个机制的管理通过 CachedAppOptimizer 类管理,为什么叫这个名字,而不…...

Vue3_04_ref 函数和 reactive 函数
ref 函数 声明变量时,赋值的值要写在 ref() 函数中修改变量时,变量名.value xxx在模板中使用时可以省略掉 .value,直接使用变量名即可 <template><h1>一个人的信息</h1><h2>姓名:{{name}}</h2><…...
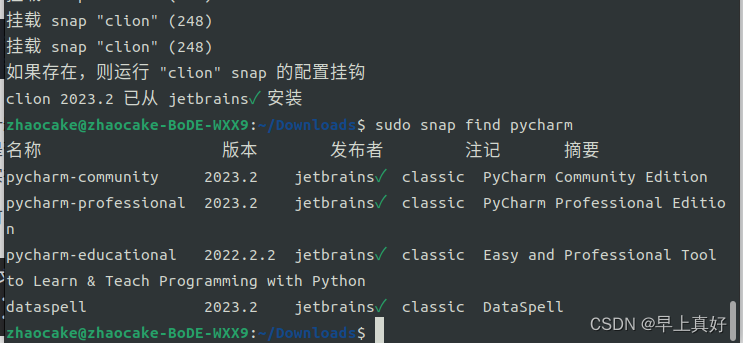
05 Ubuntu下安装.deb安装包方式安装vscode,snap安装Jetbrains产品等常用软件
使用deb包安装类型 deb包指的其实就是debian系统,ubuntu系统是基于debian系统的发行版。 一般我们会到需要的软件官网下载deb安装包,然后你既可以采用使用“软件安装”打开的方法来进行安装,也可以使用命令行进行安装。我推荐后者ÿ…...

性能测试jmeter连接数据库jdbc(sql server举例)
一、下载第三方工具包驱动数据库 1. 因为JMeter本身没有提供链接数据库的功能,所以我们需要借助第三方的工具包来实现。 (有这个jar包之后,jmeter可以发起jdbc请求,没有这个jar包,也有jdbc取样器,但不能发起…...
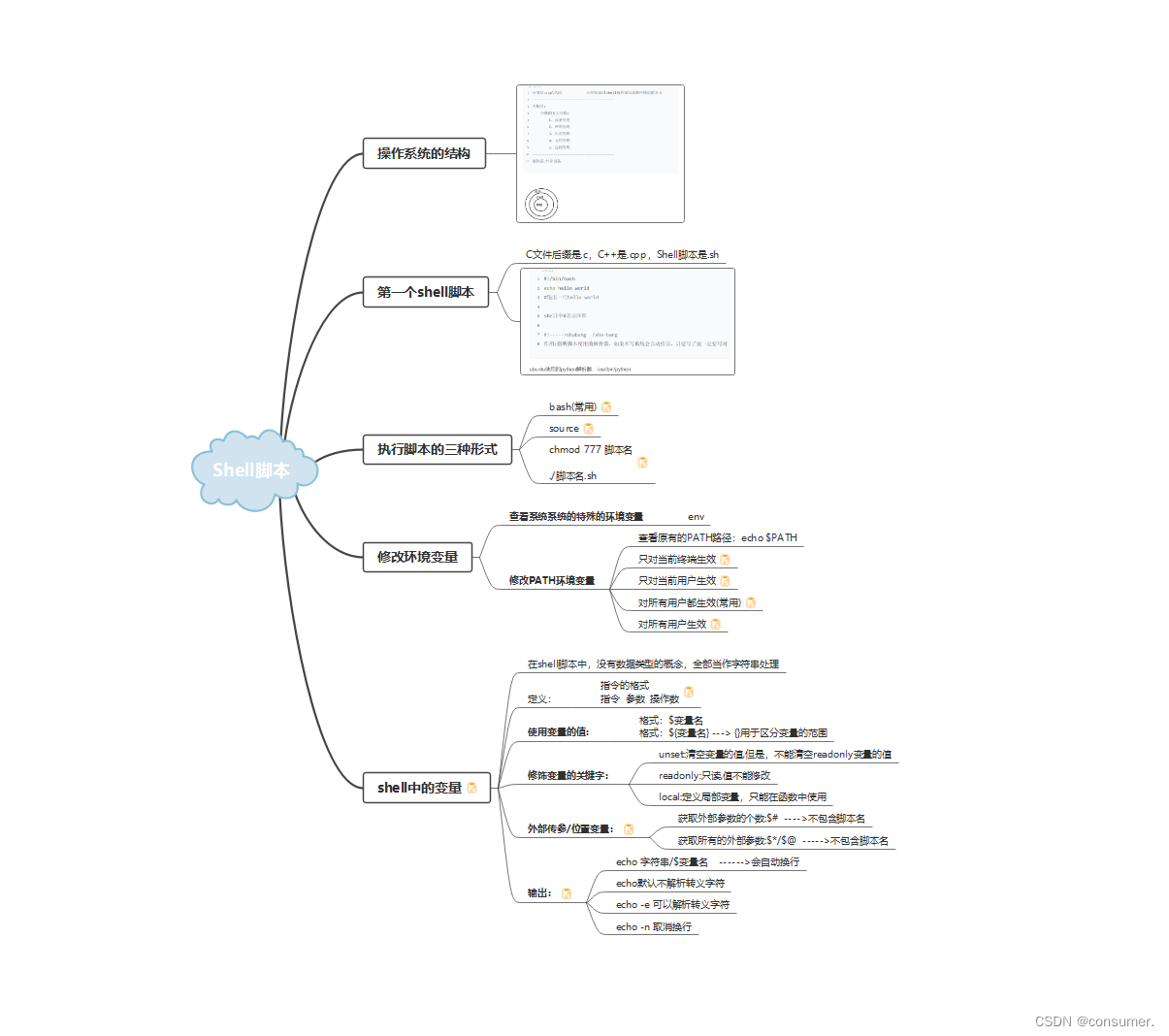
8.3 C高级 Shell脚本
写一个脚本,包含以下内容: 显示/etc/group文件中第五行的内容创建目录/home/ubuntu/copy切换工作路径到此目录赋值/etc/shadow到此目录,并重命名为test将当前目录中test的所属用户改为root将test中其他用户的权限改为没有任何权限 #!/bin/b…...

2023年华数杯A题
A 题 隔热材料的结构优化控制研究 新型隔热材料 A 具有优良的隔热特性,在航天、军工、石化、建筑、交通等 高科技领域中有着广泛的应用。 目前,由单根隔热材料 A 纤维编织成的织物,其热导率可以直接测出;但是 单根隔热材料 A 纤维…...

【零基础学Rust | 基础系列 | 函数,语句和表达式】函数的定义,使用和特性
文章标题 简介一,函数1,函数的定义2,函数的调用3,函数的参数4,函数的返回值 二,语句和表达式1,语句2,表达式 总结: 简介 在Rust编程中,函数,语句…...

加解密算法+压缩工具
sha256 工具类 package com.fanghui.vota.packages.util;import org.slf4j.Logger; import org.slf4j.LoggerFactory;import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.math.BigInteger…...

FeignClient接口的几种方式总结
FeignClient这个注解,已经封装了远程调用协议。在springboot的开发,或者微服务的开发过程中,我们需要跨服务调用,或者调用外部的接口,我们都可以使用FeignClient。 一、FeignClient介绍 FeignClient 注解是 Spring Cl…...
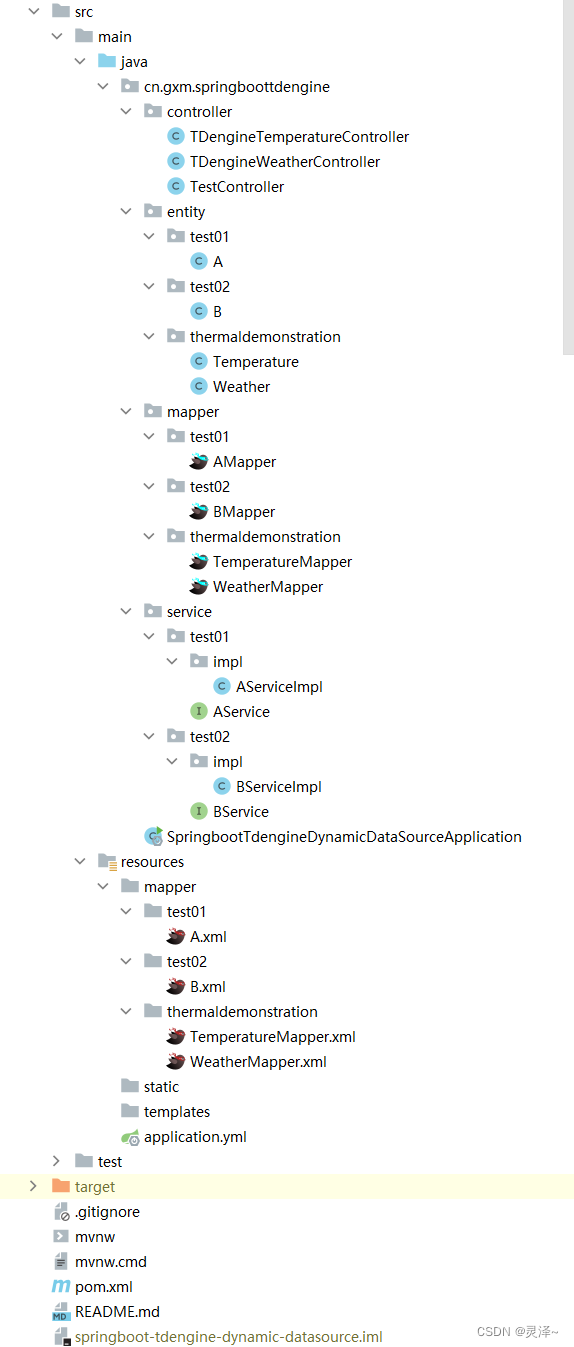
springBoot多数据源使用tdengine(3.0.7.1)+MySQL+mybatisPlus+druid连接池
一、安装部署 1、我这里使用的 3.0.7.1版本,因为我看3.x版本已经发布了一年了,增加了很多新的功能,而且3.x官方推荐,对于2.x的版本,官网都已经推荐进行升级到3.x,所以考虑到项目以后的发展,决定…...

剑指Offer 05.替换空格
剑指Offer 05.替换空格 目录 剑指Offer 05.替换空格05.替换空格题目代码(容易想到的)利用库函数的方法题解(时间复杂度更低)面试:为什么java中String类型是不可变的 05.替换空格 题目 官网题目地址 代码(…...

NVIDIA Profile Inspector 2.4.0.1:解锁NVIDIA显卡隐藏性能的终极指南
NVIDIA Profile Inspector 2.4.0.1:解锁NVIDIA显卡隐藏性能的终极指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾经觉得NVIDIA显卡的控制面板功能太有限?是否想要更…...

Phi-4-mini-reasoning 3.8B 智能文档处理:Typora风格Markdown内容自动生成
Phi-4-mini-reasoning 3.8B 智能文档处理:Typora风格Markdown内容自动生成 1. 场景痛点:Markdown写作的效率瓶颈 对于技术写作者、博客作者和文档工程师来说,Markdown已经成为事实上的标准写作格式。而Typora以其简洁优雅的所见即所得体验&…...

【实战指南】在Vue+Element-UI项目中深度定制vue-quill-editor富文本编辑器
1. 为什么选择vue-quill-editor 在Vue项目中集成富文本编辑器时,我们通常会面临几个选择:UEditor、wangEditor、TinyMCE等。但为什么我最终选择了vue-quill-editor呢?这里有几个关键原因: 首先,vue-quill-editor是基于…...

fake2db社区贡献指南:如何为开源项目添加新的数据库支持
fake2db社区贡献指南:如何为开源项目添加新的数据库支持 【免费下载链接】fake2db create custom test databases that are populated with fake data 项目地址: https://gitcode.com/gh_mirrors/fa/fake2db fake2db是一个强大的开源工具,能够帮助…...

Python调试神器:Pdb命令速查手册
Pdb 调试命令速查表 基础命令 查看代码 l # 显示当前位置附近的代码(11行) ll # 显示当前函数的完整代码 w # 显示调用栈(where) list 10, 20 # 显示第10-20行…...

Depix实战手记:从原理到踩坑,一次不完美的马赛克破解尝试
1. Depix初体验:当马赛克遇上逆向工程 第一次听说Depix这个项目时,我正在帮朋友处理一张被打满马赛克的图片。那画面简直就像被泼了一桶油漆,完全看不出原貌。正当我准备放弃时,突然想起在技术论坛上看到过关于Depix的讨论——这个…...

ITE 联阳半导体推出新一代 IT6115:集成分路器与信号放大器的 MIPI 全能转换方案
随着 AR/VR、折叠屏及智能座舱等高端影像市场的爆发,MIPI 接口在带宽、传输距離以及协议兼容性上正面临前所未有的挑战 。联阳半导体(ITE)顺势推出了高度集成的 MIPI D-PHY / C-PHY 双模转换核心——IT6115 。IT6115 并非简单的桥接芯片&…...
)
告别网络依赖!手把手教你下载并本地部署Mermaid.js(附完整HTML模板)
彻底告别网络依赖:零基础实现Mermaid.js本地化部署实战指南 在技术文档撰写、系统架构设计或项目汇报的场景中,可视化图表的重要性不言而喻。Mermaid作为一款基于文本描述的图表生成工具,凭借其简洁的语法和丰富的图表类型,已经成…...
)
Unity学习90天-第7天-学习委托与事件(简化版)
欢迎回来! 今天我们来搞定理解委托和事件的核心概念,用"受伤、得分、游戏结束"三个游戏场景掌握解耦思路!一、为什么要用事件?先看"耦合"的痛点假设玩家受伤时,需要同时做三件事:、玩家…...

【Gartner 2024 DevOps趋势验证】:已上线智能代码生成的团队,MTTR缩短61%,但89%未启用变更影响分析——你的流水线安全吗?
第一章:智能代码生成与DevOps流水线整合 2026奇点智能技术大会(https://ml-summit.org) 现代软件交付已从“人工驱动”转向“AI协同驱动”,智能代码生成不再仅限于IDE插件中的单点辅助,而是深度嵌入CI/CD流水线各阶段,实现从需求…...