Resnet与Pytorch花图像分类
1、介绍
1.1数据集介绍
flower_data├── train│ └── 1-102(102个文件夹)│ └── XXX.jpg(每个文件夹含若干张图像)├── valid│ └── 1-102(102个文件夹)└── ─── └── XXX.jpg(每个文件夹含若干张图像) cat_to_name.json:每一类花朵的"名称-编号"对应关系
1.2 任务介绍
实现102种花朵的分类任务,即通过训练train数据集后,从valid数据集中选取某一花朵图像,能准确判别其属于哪一类花朵
1.3Resnet介绍
在ResNet网络中有如下两个亮点:
- 提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)
- 使用Batch Normalization加速训练(丢弃dropout)
在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题:
- 梯度消失或梯度爆炸
- 退化问题(degradation problem)
2、数据预处理
2.1引入头文件
import os
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
from torchvision import transforms,models,datasets
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image2.2数据读取
#数据读取与预处理操作
data_dir = './flower_data/'
# 训练集
train_dir = data_dir + '/train'
#验证集
valid_ir = data_dir + '/valid'2.3制作数据源
#制作数据源
data_transfroms = {'train':transforms.Compose([transforms.RandomRotation(45), #随机旋转(-45~45)transforms.CenterCrop(224), #从中心开始裁剪transforms.RandomHorizontalFlip(p = 0.5), #随机水平翻转transforms.RandomVerticalFlip(p = 0.5), #随机垂直翻转transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue = 0.1),transforms.RandomGrayscale(p = 0.025), #概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),'valid':transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),
}2.4batch数据制作
#batch数据制作
batch_size = 8
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir,x),data_transfroms[x]) for x in ['train','valid']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x],batch_size = batch_size,shuffle = True) for x in ['train','valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train','valid']}
class_names = image_datasets['train'].classes2.5读取数据标签
#读取标签对应的实际名字
with open('cat_to_name.json','r') as f:cat_to_name = json.load(f)查看cat_to_name.json文件:
{'21': 'fire lily','3': 'canterbury bells','45': 'bolero deep blue','1': 'pink primrose','34': 'mexican aster','27': 'prince of wales feathers','7': 'moon orchid','16': 'globe-flower','25': 'grape hyacinth','26': 'corn poppy','79': 'toad lily','39': 'siam tulip','24': 'red ginger','67': 'spring crocus','35': 'alpine sea holly','32': 'garden phlox','10': 'globe thistle','6': 'tiger lily','93': 'ball moss','33': 'love in the mist','9': 'monkshood','102': 'blackberry lily','14': 'spear thistle','19': 'balloon flower','100': 'blanket flower','13': 'king protea','49': 'oxeye daisy','15': 'yellow iris','61': 'cautleya spicata','31': 'carnation','64': 'silverbush','68': 'bearded iris','63': 'black-eyed susan','69': 'windflower','62': 'japanese anemone','20': 'giant white arum lily','38': 'great masterwort','4': 'sweet pea','86': 'tree mallow','101': 'trumpet creeper','42': 'daffodil','22': 'pincushion flower','2': 'hard-leaved pocket orchid','54': 'sunflower','66': 'osteospermum','70': 'tree poppy','85': 'desert-rose','99': 'bromelia','87': 'magnolia','5': 'english marigold','92': 'bee balm','28': 'stemless gentian','97': 'mallow','57': 'gaura','40': 'lenten rose','47': 'marigold','59': 'orange dahlia','48': 'buttercup','55': 'pelargonium','36': 'ruby-lipped cattleya','91': 'hippeastrum','29': 'artichoke','71': 'gazania','90': 'canna lily','18': 'peruvian lily','98': 'mexican petunia','8': 'bird of paradise','30': 'sweet william','17': 'purple coneflower','52': 'wild pansy','84': 'columbine','12': "colt's foot",'11': 'snapdragon','96': 'camellia','23': 'fritillary','50': 'common dandelion','44': 'poinsettia','53': 'primula','72': 'azalea','65': 'californian poppy','80': 'anthurium','76': 'morning glory','37': 'cape flower','56': 'bishop of llandaff','60': 'pink-yellow dahlia','82': 'clematis','58': 'geranium','75': 'thorn apple','41': 'barbeton daisy','95': 'bougainvillea','43': 'sword lily','83': 'hibiscus','78': 'lotus lotus','88': 'cyclamen','94': 'foxglove','81': 'frangipani','74': 'rose','89': 'watercress','73': 'water lily','46': 'wallflower','77': 'passion flower','51': 'petunia'}
3、数据展示
3.1图像处理函数
#展示数据
def im_convert(tensor):image = tensor.to("cpu").clone().detach()image = image.numpy().squeeze()image = image.transpose(1,2,0)image = image * np.array((0.229,0.224,0.225)) + np.array((0.485,0.456,0.406))image = image.clip(0.1)return image
3.2展示图像
fig=plt.figure(figsize=(20, 12))
columns = 4
rows = 2dataiter = iter(dataloaders['valid'])
inputs, classes = dataiter.next()for idx in range (columns*rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))])plt.imshow(im_convert(inputs[idx]))
plt.show()
4、进行迁移学习
迁移学习的关键点:
- 研究可以用哪些知识在不同的领域或者任务中进行迁移学习,即不同领域之间有哪些共有知识可以迁移
- 研究在找到了迁移对象之后,针对具体问题所采用哪种迁移学习的特定算法,即如何设计出合适的算法来提取和迁移共有知识
- 研究什么情况下适合迁移,迁移技巧是否适合具体应用,其中涉及到负迁移的问题。
4.1训练全连接层
加载models中提供的模型,并且直接用训练好的权重当做初始化参数
下载链接:https://download.pytorch.org/models/resnet152-394f9c45.pth
选择resnet网络
model_name = 'resnet' #可选的有: ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']#是否用官方训练好的特征来做
feature_extract = True
设置用GPU训练
#是否用GPU来训练
train_on_gpu = torch.cuda.is_available()if not train_on_gpu:print('cuda is not available. Training on CPU')
else:print('cuda is available. Training on GPU')device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")屏蔽预训练模型的权重,只训练全连接层的权重:
def set_parameter_requires_grad(model,feature_extracting):if feature_extracting:for param in model.parameter():param.requires_grad = False选择resnet152网络
model_ft = models.resnet152()设置优化器:
#优化器设置
optimizer_ft = optim.Adam(params_to_update,lr = 1e-2)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft,step_size=7,gamma=0.1) #学习率每7个epoch衰减成原来的1/10
criterion = nn.NLLLoss()定义训练模块:
# 训练模块
def train_model(model,dataloaders,criterion,optimizer,num_epochs=25,is_inception=False,filename = filename):since = time.time()best_acc = 0model.to(device)val_acc_history = []train_acc_history = []train_losses = []valid_losses = []LRs = [optimizer.param_groups[0]['lr']]best_model_wts = copy.deepcopy(model.state_dict())for epoch in range(num_epochs):print('Epoch {} / {}'.format(epoch,num_epochs - 1))print('-' * 10)#训练与验证for phase in ['train','valid']:if phase == 'train':model.train() #训练else:model.eval() #验证running_loss = 0.0running_corrects = 0#把数据取个遍for inputs,labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)#清零optimizer.zero_grad()#只有训练的时候计算与更新梯度with torch.set_grad_enabled(phase == 'train'):if is_inception and phase == 'train':outputs,aux_outputs = model(inputs)loss1 = criterion(outputs,labels)loss2 = criterion(aux_outputs,labels)loss = loss1 + 0.4 * loss2else: #resnet执行的是这里outputs = model(inputs)loss = criterion(outputs,labels)_, preds = torch.max(outputs,1)if phase == 'train':loss.backward()optimizer.step()#计算损失running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / len(dataloaders[phase].dataset)epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)time_elapsed = time.time() - sinceprint('Time elapsed {:.0f}m {:.0f}f'.format(time_elapsed // 60,time_elapsed % 60))print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase,epoch_loss,epoch_acc))#得到最好的模型if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())state = {'state_dict': model.state_dict(),'best_acc': best_acc,'optimizer':optimizer.state_dict(),}torch.save(state,filename)if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)scheduler.step(epoch_loss)if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))LRs.append(optimizer.param_groups[0]['lr'])print()time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed //60,time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))#训练完后用最好的一次当做模型最终的结果model.load_state_dict(best_model_wts)return model,val_acc_history,train_acc_history.valid_losses,train_losses,LRs
开始训练:
# 开始训练
model_ft,val_acc_history,train_acc_history,valid_lossea,train_losses,LRs = train_model(model_ft,dataloaders,criterion,optimizer_ft,num_epochs=20,is_inception=(model_name == 'inception'))
4.2训练所有层
我们从上次训练好最优的那个全连接层的参数开始,以此为基础训练所有层,设置param.requires_grad = True表明接下来训练全部网络,之后把学习率调小一点,衰减函数为每7次衰减为原来的1/10,损失函数不变
再继续训练所有层
for param in model_ft.parameters():param.requires_grad = True#再继续训练所有的参数,学习率调小一点(lr)
optimizer = optim.Adam(params_to_update,lr = 1e-4)
#衰减函数(每七次衰减为原来的七分之一)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft,step_size=7,gamma=0.1)#损失函数
criterion = nn.NLLLoss()导入之前的最优结果并开始训练:
#在之前训练得到最好的模型的基础上继续训练
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])model_ft,val_acc_history,train_acc_history,valid_lossea,train_losses,LRs = train_model(model_ft,dataloaders,criterion,optimizer_ft,num_epochs=10,is_inception=(model_name == 'inception'))
5、测试网络效果
5.1测试数据预处理
首先将新训练好的checkpoint.pth重命名为serious.pth,之后加载训练好的模型:
#加载训练好的模型
model_ft,input_size = initialize_model(model_name,102,feature_extract,use_pretrained=True)#GPU模型
model_ft = model_ft.to(device)
#保存文件的名字
filename = 'serious.pth'
#加载模型
checkpoint = torch.load(filename)
best_acc = checkpoint['beat_acc']
model_ft.load_state_dict(checkpoint['state_dict'])定义图像处理函数:
def process_image(image_path):img = Image.open(image_path)#Resize,thumbnail方法只能进行缩小,所以进行判断if img.size[0] > img.size[1]:img.thumbnail((10000,256))else:img.thumbnail((256,10000))#Crop操作left_margin = (img.width-224)/2bottom_margin = (img.height-224)/2right_margin = (left_margin) + 224top_margin = bottom_margin + 224img = img.crop(left_margin,bottom_margin,right_margin,top_margin)#相同的预处理方法img = np.array(img)/255mean = np.array([0.485,0.456,0.406])std = np.array([0.229,0.224,0.225])img = (img - mean)/std#注意颜色通道应该放在第一个位置img = img.transpose((2,0,1))return img定义图像展示函数:
#展示数据
def imshow(image,ax = None,title = None):if ax is None:fig,ax = plt.subplots()#颜色通道还原image = np.array(image).transpose((1,2,0))#预处理还原mean = np.array([0.485,0.456,0.406])std = np.array([0.229,0.224,0.225])image = std * image + meanimage = np.clip(image,0.1)ax.imshow(image)ax.set_title(title)return ax展示一个数据:
image_path = 'image_06621.jpg'
img = process_image(image_path)
imshow(img) 
得到一个batch测试数据:
#测试一个batch数据
dataiter = iter(dataloaders['valid'])
images,labels = dataiter.next()model_ft.eval()if train_on_gpu:output = model_ft(images.cuda())
else:output = model_ft(images)利用torch.max()函数计算标签值:
#得到属于类别的八个编号
_,preds_tensor = torch.ax(output,1)
preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())5.2结果可视化
#展示预测结果
fig = plt.figure(figsize=(20,20))
columns = 4
rows = 2for idx in range(columns * rows):ax = fig.add_subplot(rows,columns,idx+1,xticks=[],yticks=[])plt.imshow(im_convert(images[idx]))ax.set_title("{} {}".format(cat_to_name[str(preds[idx])],cat_to_name[str(labels[idx].item())]),color = ("green" if cat_to_name[str(preds[idx])] == cat_to_name[str(labels[idx].item())] else "red"))
plt.show()结果如下(绿色标题代表识别成功,红色标题代表识别失败,括号里面为真实值,括号外为预测值)

相关文章:
Resnet与Pytorch花图像分类
1、介绍 1.1数据集介绍 flower_data├── train│ └── 1-102(102个文件夹)│ └── XXX.jpg(每个文件夹含若干张图像)├── valid│ └── 1-102(102个文件夹)└── ─── └── XXX.jp…...
)
【NLP概念源和流】 03-基于计数的嵌入,GloVe(第 3/20 部分)
接续上文 【NLP概念源和流】 02-稠密文档表示(第 2/20 部分)...

【React】关于组件之间的通讯
🌟组件化:把一个项目拆成一个一个的组件,为了便与开发与维护 组件之间互相独立且封闭,一般而言,每个组件只能使用自己的数据(组件状态私有)。 如果组件之间相互传参怎么办? 那么就要…...
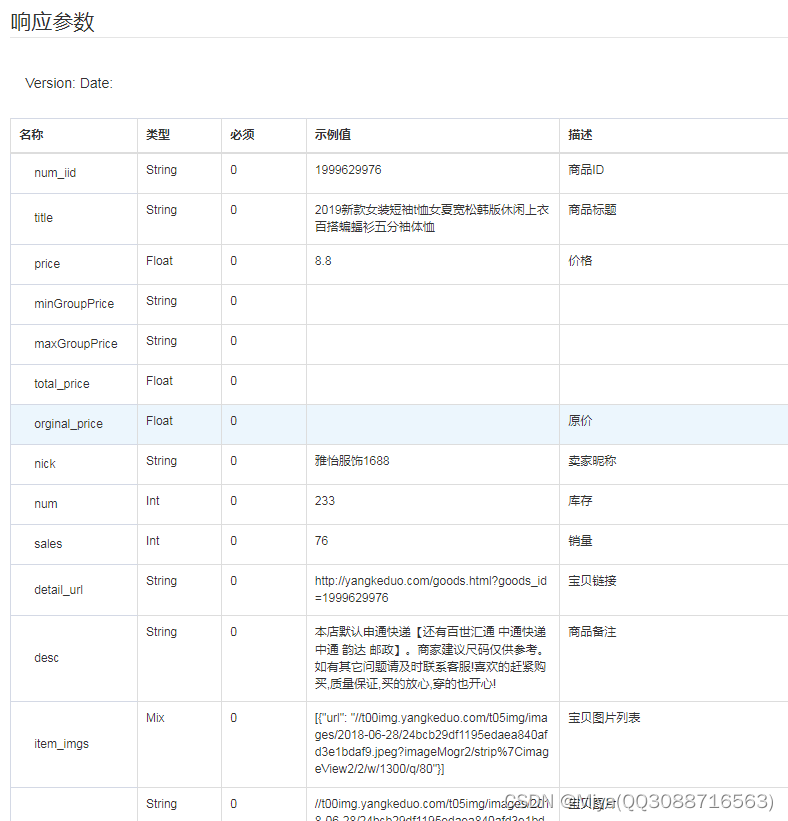
item_get-小红薯-商品详情
一、接口参数说明: smallredbook.item_get,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/smallredbook/item_get 名称类型必须描述keyString是调用key(http://o0…...
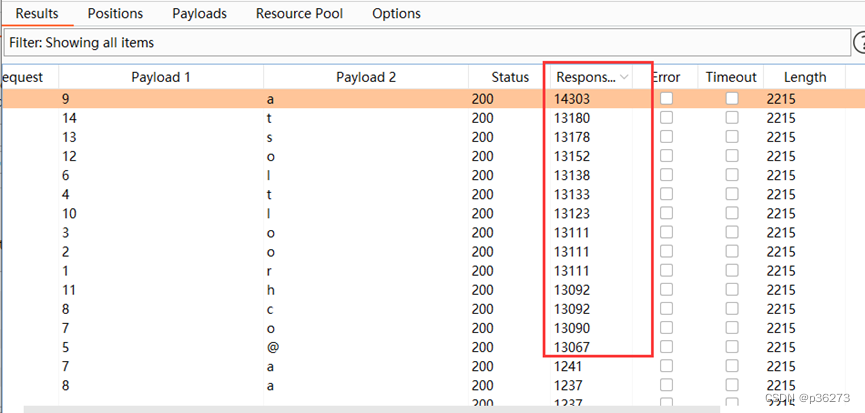
网络安全进阶学习第十课——MySQL手工注入
文章目录 一、MYSQL数据库常用函数二、MYSQL默认的4个系统数据库以及重点库和表三、判断数据库类型四、联合查询注入1、具体步骤(靶场演示):1)首先判断注入点2)判断是数字型还是字符型3)要判断注入点的列数…...

2.3 网络安全协议
数据参考:CISP官方 目录 OSI七层模型TCP/IP体系架构TCP/IP安全架构 一、OSI七层模型 简介 开放系统互连模型(Open System Interconnection Reference Model,OSI)是国际标准化组织(ISO)于1977年发布的…...

Apache Flink概述
Flink 是构建在数据流之上的一款有状态的流计算框架,通常被人们称为第三代大数据分析方案 第一代大数据处理方案:基于Hadoop的MapReduce 静态批处理 | Storm 实时流计算 ,两套独立的计算引擎,难度大(2014年9月&#x…...
django使用mysql数据库
Django开 发操作数据库比使用pymysql操作更简单,内部提供了ORM框架。 下面是pymysql 和orm操作数据库的示意图,pymysql就是mysql的驱动,代码直接操作pymysql ,需要自己写增删改查的语句 django 就是也可以使用pymysql、mysqlclient作为驱动&a…...

MongoDB文档--基本概念
阿丹: 不断拓展自己的技术栈,不断学习新技术。 基本概念 MongoDB中文手册|官方文档中文版 - MongoDB-CN-Manual mongdb是文档数据库 MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。MongoDB文档类似于JSON对象。字段的值可以包…...

【TypeScript】TS入门及基础学习(一)
【TypeScript】TS入门及基础学习(一) 【TypeScript】TS入门及基础学习(一)一、前言二、基本概念1.强类型语言和弱类型语言2.动态语言和静态语言 三、TypeScript与JavaScript的区别四、环境搭建及演练准备4.1 安装到本地4.2 在线运…...
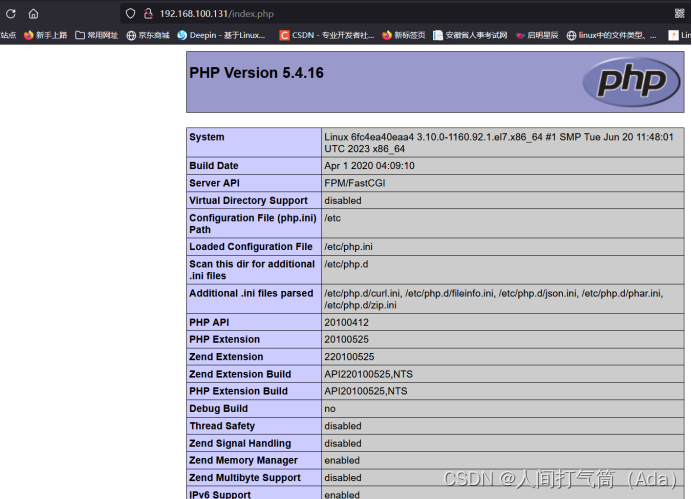
Dockerfile构建LNMP镜像(yum方式)
目录 Dockerfile构建LNMP镜像 1、建立工作目录 2、编写Dockerfile文件 3、构建镜像 4、测试容器 5、浏览器访问测试: Dockerfile构建LNMP镜像 1、建立工作目录 [roothuyang1 ~]# mkdir lnmp/ [roothuyang1 ~]# cd lnmp/ 2、编写Dockerfile文件 [roothuyang1 …...
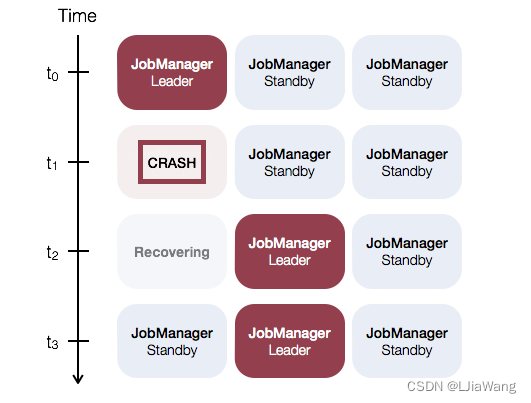
Flink Windows(窗口)详解
Windows(窗口) Windows是流计算的核心。Windows将流分成有限大小的“buckets”,我们可以在其上应用聚合计算(ProcessWindowFunction,ReduceFunction,AggregateFunction或FoldFunction)等。在Fl…...
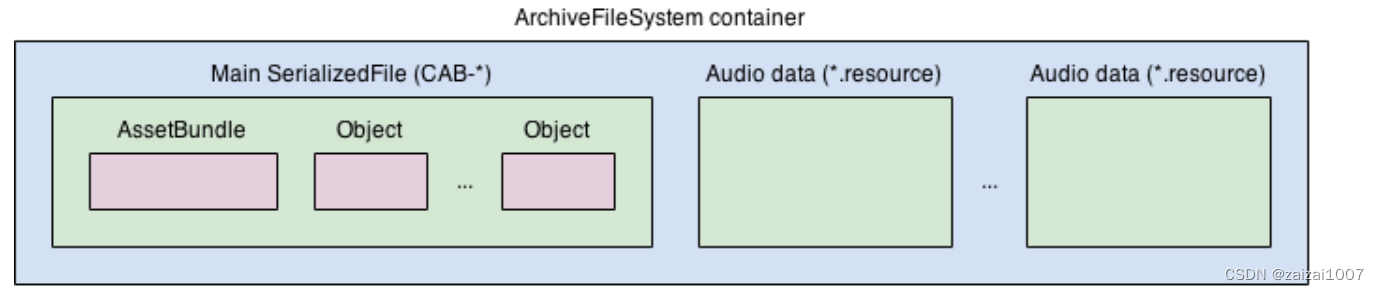
AssetBundle学习
官方文档:AssetBundle 工作流程 - Unity 手册 (unity3d.com) 之前写的博客:AssetBundle学习_zaizai1007的博客-CSDN博客 使用流程图: 1,指定资源的AssetBundle属性 (xxxa/xxx)这里xxxa会生成目录&…...
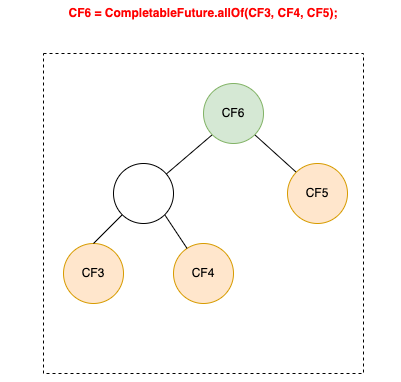
CompletableFuture原理与实践
文章目录 1 为何需要并行加载2 并行加载的实现方式2.1 同步模型2.2 NIO异步模型2.3 为什么会选择CompletableFuture? 3 CompletableFuture使用与原理3.1 CompletableFuture的背景和定义3.1.1 CompletableFuture解决的问题3.1.2 CompletableFuture的定义 3.2 Complet…...

8.3 作业
整理思维导图 2. 递归实现,输入一个数,输出这个数的每一位 #include <myhead.h> void fun(int t) {if(t 0) return;fun(t/10);printf("%d\n",t%10); } int main(int argc,const char *argv[]) {int t1623809; fun(t);return 0; } 3.递…...

c# COM组件原理
COM(Component Object Model)是一种微软的软件组件技术,用于实现软件组件之间的互操作性。它是一种二进制接口标准,允许不同的软件组件在不同的进程中进行通信。COM组件可以用多种编程语言编写,并且可以在多个应用程序…...

Java POI 百万规模数据的导入和导出
目录 1、百万数据导入1.1 需求分析1.2 思路分析1.3 代码实现1.3.1 步骤分析1.3.2 自定义处理器1.3.3 自定义解析1.3.4 测试 2、百万数据导出2.1、概述2.2、解决方案分析2.3、原理分析2.4、百万数据的导出2.4.1、模拟数据2.4.2、思路分析2.4.3、代码实现2.4.4、测试结果 1、百万…...

如何快速用PHP取短信验证码
要用PHP获取短信验证码,通常需要连接到一个短信服务提供商的API,并通过该API发送请求来获取验证码。由于不同的短信服务提供商可能具有不同的API和授权方式,我将以一个简单的示例介绍如何使用Go语言来获取短信验证码。 在这个示例中ÿ…...

CloudStack 的 AsyncJobManagerImpl
在 CloudStack 的 AsyncJobManagerImpl 类中,下列方法的作用如下: getConfigComponentName(): 返回配置组件的名称。 getConfigKeys(): 返回与异步任务管理器相关的配置键列表。 getAsyncJob(): 根据异步任务的 ID 获取相应的异步任务对象。 findInst…...

OAuth机制_web站点接入微软azure账号进行三方登录
文章目录 ⭐前言⭐微软三方登录流程💖 web站点获取微软账号流程💖 node封装微软登录接口💖 webapp 自定义code换token💖 调用 Microsoft Graph API💖 前端唤醒authlink进行登录回调逻辑 ⭐结束 ⭐前言 大家好…...

Qwen3-Reranker应用案例:AI编程助手中的代码片段语义重排序实践
Qwen3-Reranker应用案例:AI编程助手中的代码片段语义重排序实践 1. 引言:代码搜索的痛点与解决方案 在日常编程工作中,我们经常遇到这样的场景:你需要实现一个特定功能,比如"用Python发送HTTP请求并处理JSON响应…...
独占设备 → 虚拟共享设备)
SPOOLing 技术(假脱机技术)独占设备 → 虚拟共享设备
一、基础定义与核心定位 SPOOLing 全称:Simultaneous Peripheral Operations On-Line 中文:假脱机技术 一句话核心: 在联机状态下,用软件模拟实现脱机I/O的效果,将低速独占设备虚拟成高速共享设备,让 CPU 与…...

ComfyUI API图生图实战:从自定义节点到Web接口的完整搭建
1. ComfyUI图生图实战:香水瓶设计案例解析 第一次接触ComfyUI的API开发时,我被它灵活的节点式工作流深深吸引。作为一个长期从事AI产品开发的工程师,我发现很多团队在使用Stable Diffusion时都面临一个共同问题:如何将AI生图能力快…...
)
智能代码生成错误检测与修复(工业级误报率<0.8%的闭环系统大公开)
第一章:智能代码生成错误检测与修复 2026奇点智能技术大会(https://ml-summit.org) 现代大语言模型驱动的代码生成工具(如Copilot、CodeWhisperer)在提升开发效率的同时,也引入了新型语义错误、上下文不一致及安全漏洞等隐蔽缺陷…...

网易云音乐NCM文件转换终极指南:3分钟解锁你的音乐收藏
网易云音乐NCM文件转换终极指南:3分钟解锁你的音乐收藏 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的NCM文件无法在其他播…...

嵌入式Linux驱动新选择:基于TinyDRM为ST7789V TFT屏幕编写现代化显示驱动
1. 为什么选择TinyDRM替代传统fbtft驱动 第一次接触ST7789V这类SPI接口的TFT屏幕时,大多数开发者都会选择fbtft驱动方案。我也不例外,当时在树莓派上折腾了好几天终于让屏幕亮起来。但随着项目深入,逐渐发现fbtft在嵌入式Linux上的局限性——…...
)
当LLM开始“编译”你的Prompt:从AST解析视角重构智能代码生成工作流(含Python/TypeScript双语言Prompt IR中间表示规范)
第一章:智能代码生成Prompt工程指南 2026奇点智能技术大会(https://ml-summit.org) 高质量Prompt是驱动智能代码生成模型产出可运行、可维护、符合上下文语义的关键杠杆。与通用文本生成不同,代码生成对结构精确性、语法合法性、边界条件覆盖及API兼容…...

同样的招聘工作,别人 AI 一周筛选千份简历,你的 HR 要加班一个月:2026企业级实在Agent深度实践
在2026年的春招赛道上,企业间的竞争早已从“人才争夺”演变为“筛选效率”的降维打击。 根据最新的行业观察,头部企业通过部署智能体(Agent)技术,已实现从简历抓取、逻辑初筛到面试预约的全链路自动化。 相比之下&…...

Feko里算RCS,MLFMM、ACA、PO这些算法到底该怎么选?一张图给你讲明白
Feko电磁仿真中RCS计算算法的实战选择指南 在电磁仿真领域,Feko作为一款专业工具,其算法选择直接决定了计算效率和精度。面对MLFMM、ACA、PO等多种算法,工程师们常常陷入选择困境——是追求速度牺牲精度,还是为了准确度忍受漫长的…...

VMware安装kali的常见问题及解决方案
1. VMware安装Kali Linux前的准备工作 在开始安装Kali Linux之前,有几个关键点需要注意。首先确保你的电脑硬件配置足够强大,建议至少8GB内存和100GB硬盘空间。我遇到过很多新手因为硬件不足导致安装失败的情况,这点特别重要。 VMware版本选…...