2023年第四届“华数杯”数学建模思路 - 案例:随机森林
## 0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 什么是随机森林?
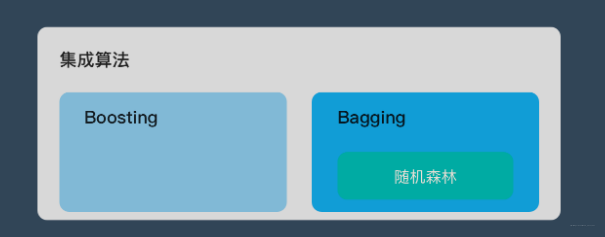
随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。如果用图来表示他们之间的关系如下:
决策树 – Decision Tree
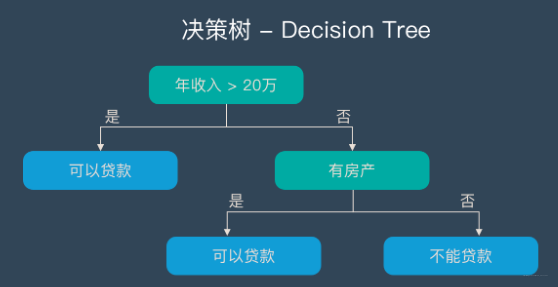
在解释随机森林前,需要先提一下决策树。决策树是一种很简单的算法,他的解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法,上面的图片可以直观的表达决策树的逻辑。
随机森林 – Random Forest | RF
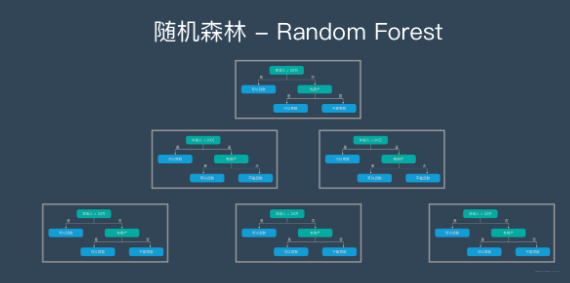
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
2 随机深林构造流程

-
- 一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
-
- 当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
-
- 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
-
- 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
3 随机森林的优缺点
3.1 优点
- 它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 不容易过拟合
- 训练速度比较快,容易做成并行方法
- 实现起来比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
3.2 缺点
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
4 随机深林算法实现
数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/
import csv
from random import seed
from random import randrange
from math import sqrtdef loadCSV(filename):#加载数据,一行行的存入列表dataSet = []with open(filename, 'r') as file:csvReader = csv.reader(file)for line in csvReader:dataSet.append(line)return dataSet# 除了标签列,其他列都转换为float类型
def column_to_float(dataSet):featLen = len(dataSet[0]) - 1for data in dataSet:for column in range(featLen):data[column] = float(data[column].strip())# 将数据集随机分成N块,方便交叉验证,其中一块是测试集,其他四块是训练集
def spiltDataSet(dataSet, n_folds):fold_size = int(len(dataSet) / n_folds)dataSet_copy = list(dataSet)dataSet_spilt = []for i in range(n_folds):fold = []while len(fold) < fold_size: # 这里不能用if,if只是在第一次判断时起作用,while执行循环,直到条件不成立index = randrange(len(dataSet_copy))fold.append(dataSet_copy.pop(index)) # pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。dataSet_spilt.append(fold)return dataSet_spilt# 构造数据子集
def get_subsample(dataSet, ratio):subdataSet = []lenSubdata = round(len(dataSet) * ratio)#返回浮点数while len(subdataSet) < lenSubdata:index = randrange(len(dataSet) - 1)subdataSet.append(dataSet[index])# print len(subdataSet)return subdataSet# 分割数据集
def data_spilt(dataSet, index, value):left = []right = []for row in dataSet:if row[index] < value:left.append(row)else:right.append(row)return left, right# 计算分割代价
def spilt_loss(left, right, class_values):loss = 0.0for class_value in class_values:left_size = len(left)if left_size != 0: # 防止除数为零prop = [row[-1] for row in left].count(class_value) / float(left_size)loss += (prop * (1.0 - prop))right_size = len(right)if right_size != 0:prop = [row[-1] for row in right].count(class_value) / float(right_size)loss += (prop * (1.0 - prop))return loss# 选取任意的n个特征,在这n个特征中,选取分割时的最优特征
def get_best_spilt(dataSet, n_features):features = []class_values = list(set(row[-1] for row in dataSet))b_index, b_value, b_loss, b_left, b_right = 999, 999, 999, None, Nonewhile len(features) < n_features:index = randrange(len(dataSet[0]) - 1)if index not in features:features.append(index)# print 'features:',featuresfor index in features:#找到列的最适合做节点的索引,(损失最小)for row in dataSet:left, right = data_spilt(dataSet, index, row[index])#以它为节点的,左右分支loss = spilt_loss(left, right, class_values)if loss < b_loss:#寻找最小分割代价b_index, b_value, b_loss, b_left, b_right = index, row[index], loss, left, right# print b_loss# print type(b_index)return {'index': b_index, 'value': b_value, 'left': b_left, 'right': b_right}# 决定输出标签
def decide_label(data):output = [row[-1] for row in data]return max(set(output), key=output.count)# 子分割,不断地构建叶节点的过程对对对
def sub_spilt(root, n_features, max_depth, min_size, depth):left = root['left']# print leftright = root['right']del (root['left'])del (root['right'])# print depthif not left or not right:root['left'] = root['right'] = decide_label(left + right)# print 'testing'returnif depth > max_depth:root['left'] = decide_label(left)root['right'] = decide_label(right)returnif len(left) < min_size:root['left'] = decide_label(left)else:root['left'] = get_best_spilt(left, n_features)# print 'testing_left'sub_spilt(root['left'], n_features, max_depth, min_size, depth + 1)if len(right) < min_size:root['right'] = decide_label(right)else:root['right'] = get_best_spilt(right, n_features)# print 'testing_right'sub_spilt(root['right'], n_features, max_depth, min_size, depth + 1)# 构造决策树
def build_tree(dataSet, n_features, max_depth, min_size):root = get_best_spilt(dataSet, n_features)sub_spilt(root, n_features, max_depth, min_size, 1)return root
# 预测测试集结果
def predict(tree, row):predictions = []if row[tree['index']] < tree['value']:if isinstance(tree['left'], dict):return predict(tree['left'], row)else:return tree['left']else:if isinstance(tree['right'], dict):return predict(tree['right'], row)else:return tree['right']# predictions=set(predictions)
def bagging_predict(trees, row):predictions = [predict(tree, row) for tree in trees]return max(set(predictions), key=predictions.count)
# 创建随机森林
def random_forest(train, test, ratio, n_feature, max_depth, min_size, n_trees):trees = []for i in range(n_trees):train = get_subsample(train, ratio)#从切割的数据集中选取子集tree = build_tree(train, n_features, max_depth, min_size)# print 'tree %d: '%i,treetrees.append(tree)# predict_values = [predict(trees,row) for row in test]predict_values = [bagging_predict(trees, row) for row in test]return predict_values
# 计算准确率
def accuracy(predict_values, actual):correct = 0for i in range(len(actual)):if actual[i] == predict_values[i]:correct += 1return correct / float(len(actual))if __name__ == '__main__':seed(1) dataSet = loadCSV('sonar-all-data.csv')column_to_float(dataSet)#dataSetn_folds = 5max_depth = 15min_size = 1ratio = 1.0# n_features=sqrt(len(dataSet)-1)n_features = 15n_trees = 10folds = spiltDataSet(dataSet, n_folds)#先是切割数据集scores = []for fold in folds:train_set = folds[:] # 此处不能简单地用train_set=folds,这样用属于引用,那么当train_set的值改变的时候,folds的值也会改变,所以要用复制的形式。(L[:])能够复制序列,D.copy() 能够复制字典,list能够生成拷贝 list(L)train_set.remove(fold)#选好训练集# print len(folds)train_set = sum(train_set, []) # 将多个fold列表组合成一个train_set列表# print len(train_set)test_set = []for row in fold:row_copy = list(row)row_copy[-1] = Nonetest_set.append(row_copy)# for row in test_set:# print row[-1]actual = [row[-1] for row in fold]predict_values = random_forest(train_set, test_set, ratio, n_features, max_depth, min_size, n_trees)accur = accuracy(predict_values, actual)scores.append(accur)print ('Trees is %d' % n_trees)print ('scores:%s' % scores)print ('mean score:%s' % (sum(scores) / float(len(scores))))
相关文章:
2023年第四届“华数杯”数学建模思路 - 案例:随机森林
## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 什么是随机森林? 随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。如果用图来表示他们之…...

Redis中缓存穿透、击穿、雪崩以及解决方案
Redis中缓存穿透、击穿、雪崩以及解决方案 Redis作为一个高效的内存数据库,提供了缓存能力使得我们能够快速访问数据。然而,在使用Redis作为缓存时,我们可能会面临缓存穿透、缓存击穿和缓存雪崩的问题。接下来,我将详细解释这些现…...
系统架构设计师-软件架构设计(6)
目录 一、物联网分层架构 二、大数据分层架构 三、基于服务的架构(SOA) 1、SOA的特征 2、服务构件与传统构件的区别 四、Web Service(WEB服务) 1、Web Services 和 SOA的关系 五、REST(表述性状态转移) 六、ESB(…...
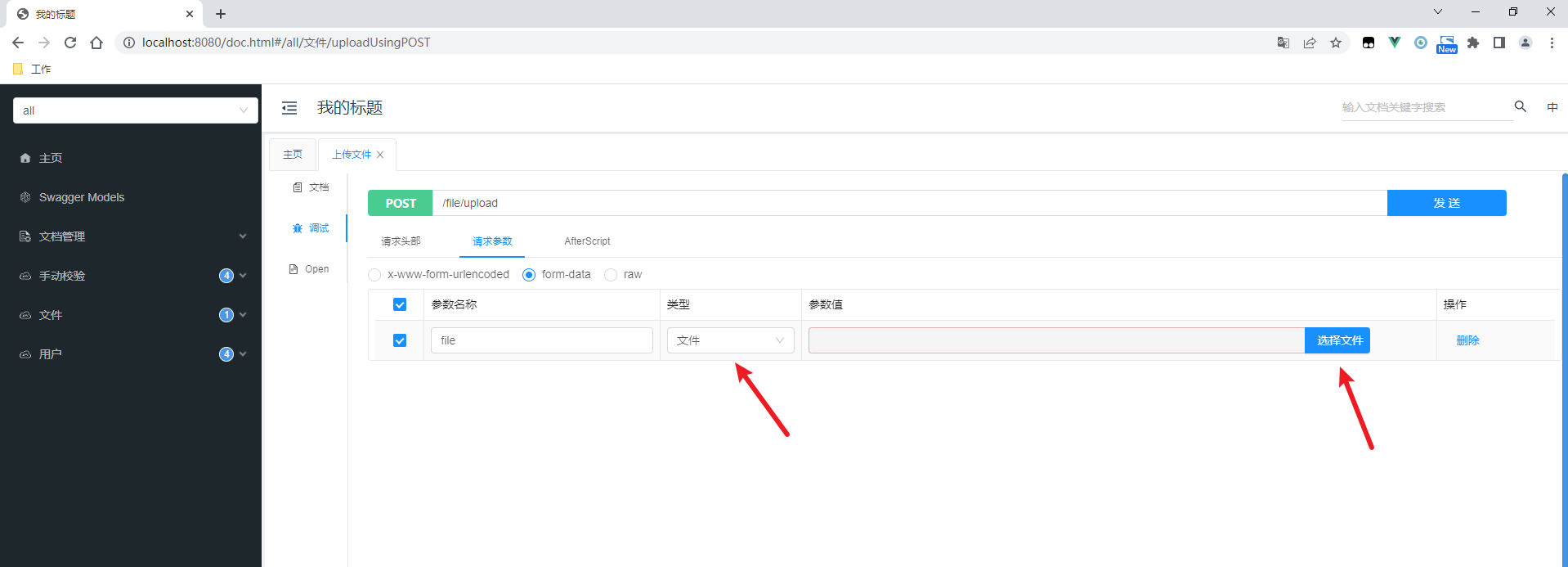
Knife4j系列--解决不显示文件上传的问题
原文网址:Knife4j系列--解决不显示文件上传的问题_IT利刃出鞘的博客-CSDN博客 简介 本文介绍使用Knife4j时无法上传文件的问题。 问题复现 依赖 <dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-…...

深入学习Mysql引擎InnoDB、MylSAM
目录 一、什么是MySQL 二、什么是InnoDB 三、什么是MyISAM 四、MySQL不同引擎有什么区别 一、什么是MySQL MySQL是一种广泛使用的开源关系型数据库管理系统(RDBMS),它是由瑞典MySQL AB公司开发并推广,后来被Sun Microsystems收…...

第七章:SpringMVC中
第七章:SpringMVC中 7.1:SpringMVC的视图 SpringMVC中的视图是View接口,视图的作用渲染数据,将模型Model中的数据展示给用户SpringMVC视图的种类很多,默认有转发视图和重定向视图。 当工程引入jstl的依赖&…...
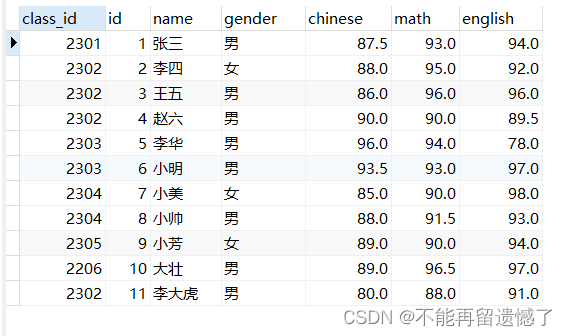
MySQL数据库——DQL操作——基本查询
文章目录 前言事前准备——测试数据整表查询指定列查找别名查询MySQL运算符条件查询模糊查询排序查询聚合查询分组查询分组之后的条件筛选 分页查询将整张表的数据插入到另一张表中 前言 MySQL数据库常见的操作是增删查改,而其中数据的查询是使用最多,也…...
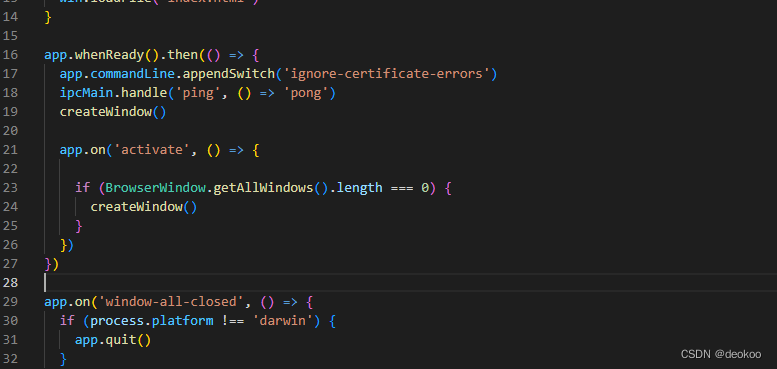
Electron 开发,报handshake failed; returned -1, SSL error code 1,错误
代码说明 在preload.js代码中,暴露参数给渲染线程renderer.js访问, renderer.js 报:ERROR:ssl_client_socket_impl.cc(978)] failed; returned -1, SSL error code 1,错误 问题原因 如题所说,跨进程传递消息,这意味…...
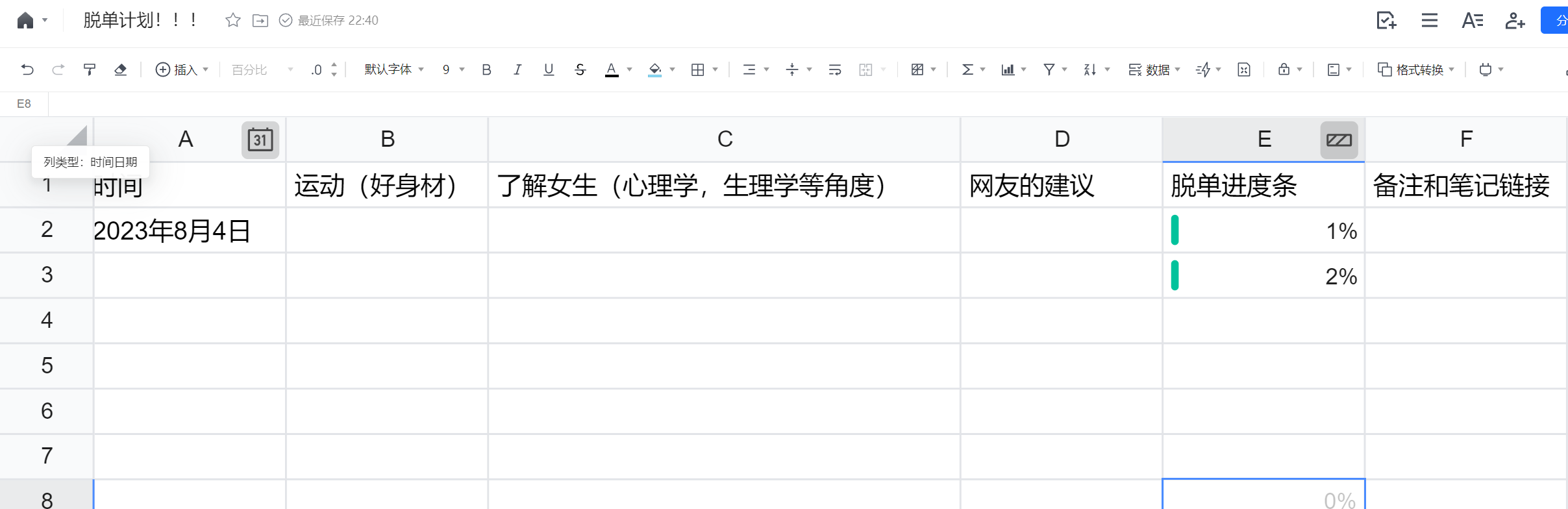
知识区博主转型——兼做知识区和改造区博主!!!!!
想脱单的进来,一起交流如何能脱单!!! 为什么——我太羡慕有对象的人了哭死!!!!!! 你是不是很羡慕别人怎么都有女朋友 别人家的女朋友怎么都那么好ÿ…...

Resnet与Pytorch花图像分类
1、介绍 1.1数据集介绍 flower_data├── train│ └── 1-102(102个文件夹)│ └── XXX.jpg(每个文件夹含若干张图像)├── valid│ └── 1-102(102个文件夹)└── ─── └── XXX.jp…...
)
【NLP概念源和流】 03-基于计数的嵌入,GloVe(第 3/20 部分)
接续上文 【NLP概念源和流】 02-稠密文档表示(第 2/20 部分)...

【React】关于组件之间的通讯
🌟组件化:把一个项目拆成一个一个的组件,为了便与开发与维护 组件之间互相独立且封闭,一般而言,每个组件只能使用自己的数据(组件状态私有)。 如果组件之间相互传参怎么办? 那么就要…...
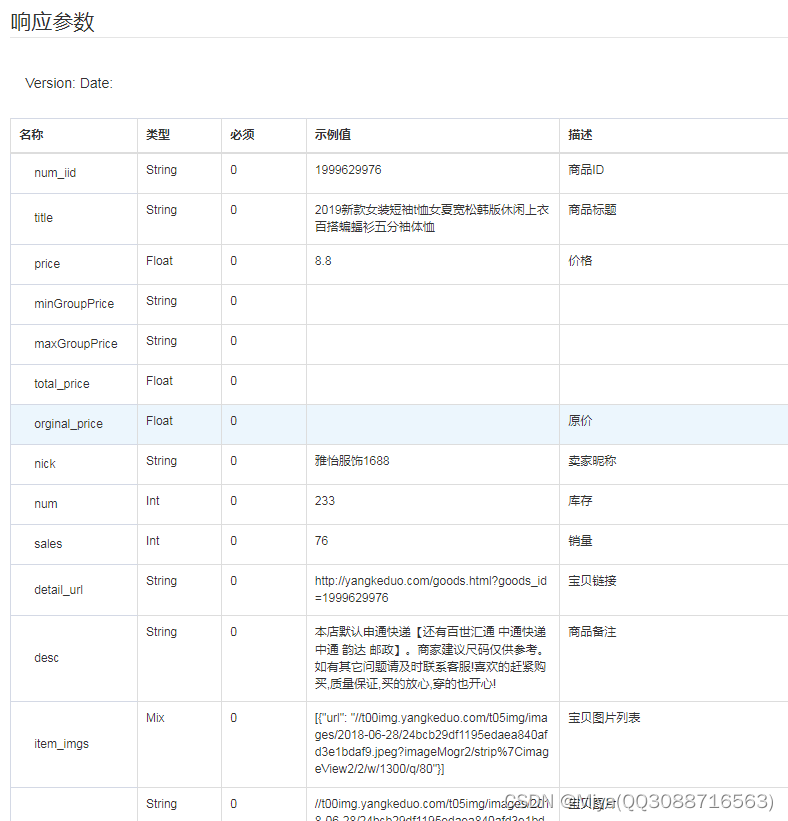
item_get-小红薯-商品详情
一、接口参数说明: smallredbook.item_get,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/smallredbook/item_get 名称类型必须描述keyString是调用key(http://o0…...
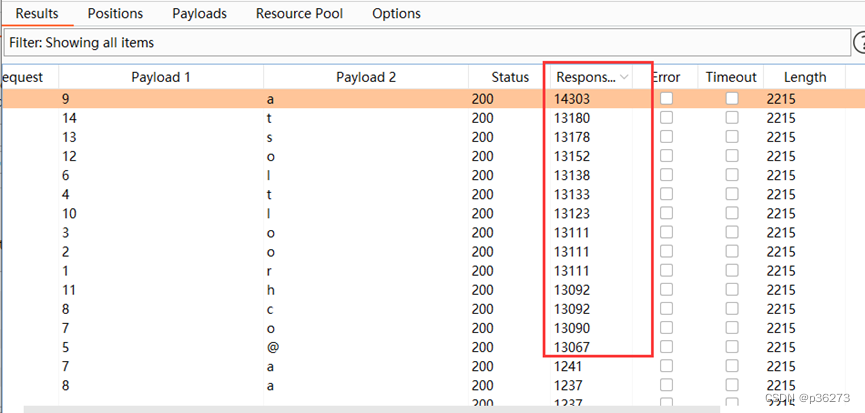
网络安全进阶学习第十课——MySQL手工注入
文章目录 一、MYSQL数据库常用函数二、MYSQL默认的4个系统数据库以及重点库和表三、判断数据库类型四、联合查询注入1、具体步骤(靶场演示):1)首先判断注入点2)判断是数字型还是字符型3)要判断注入点的列数…...

2.3 网络安全协议
数据参考:CISP官方 目录 OSI七层模型TCP/IP体系架构TCP/IP安全架构 一、OSI七层模型 简介 开放系统互连模型(Open System Interconnection Reference Model,OSI)是国际标准化组织(ISO)于1977年发布的…...

Apache Flink概述
Flink 是构建在数据流之上的一款有状态的流计算框架,通常被人们称为第三代大数据分析方案 第一代大数据处理方案:基于Hadoop的MapReduce 静态批处理 | Storm 实时流计算 ,两套独立的计算引擎,难度大(2014年9月&#x…...
django使用mysql数据库
Django开 发操作数据库比使用pymysql操作更简单,内部提供了ORM框架。 下面是pymysql 和orm操作数据库的示意图,pymysql就是mysql的驱动,代码直接操作pymysql ,需要自己写增删改查的语句 django 就是也可以使用pymysql、mysqlclient作为驱动&a…...

MongoDB文档--基本概念
阿丹: 不断拓展自己的技术栈,不断学习新技术。 基本概念 MongoDB中文手册|官方文档中文版 - MongoDB-CN-Manual mongdb是文档数据库 MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。MongoDB文档类似于JSON对象。字段的值可以包…...

【TypeScript】TS入门及基础学习(一)
【TypeScript】TS入门及基础学习(一) 【TypeScript】TS入门及基础学习(一)一、前言二、基本概念1.强类型语言和弱类型语言2.动态语言和静态语言 三、TypeScript与JavaScript的区别四、环境搭建及演练准备4.1 安装到本地4.2 在线运…...
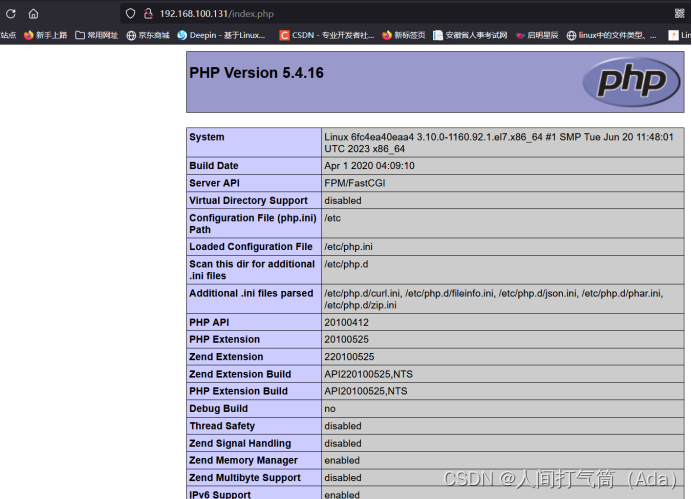
Dockerfile构建LNMP镜像(yum方式)
目录 Dockerfile构建LNMP镜像 1、建立工作目录 2、编写Dockerfile文件 3、构建镜像 4、测试容器 5、浏览器访问测试: Dockerfile构建LNMP镜像 1、建立工作目录 [roothuyang1 ~]# mkdir lnmp/ [roothuyang1 ~]# cd lnmp/ 2、编写Dockerfile文件 [roothuyang1 …...

Linux-RGMII PHY 88E1512 双模式驱动适配与调试实战
1. 认识88E1512 PHY芯片与RGMII接口 第一次接触88E1512这颗PHY芯片是在一个工业网关项目上,当时我们需要在AM5728平台上实现双网口功能。Marvell的88E1512确实是个很有意思的芯片,它支持RGMII-to-Copper和RGMII-to-SGMII两种工作模式,相当于一…...

千问3.5-2B图文理解实操手册:清晰图/模糊图/反光图/低对比度图四类适配策略
千问3.5-2B图文理解实操手册:清晰图/模糊图/反光图/低对比度图四类适配策略 1. 模型能力概述 千问3.5-2B是Qwen系列中的小型视觉语言模型,专为图片理解与文本生成任务设计。这个开箱即用的解决方案已经完成本地部署,无需额外安装依赖&#…...

nginx常见问题记录
之前学习了nginx的基本配置后 个人项目运用过 正好最近公司的项目需要将手上的工作独立拆分出来 于是就需要我这独立配置一套新的nginx 在过程中也发现了不少之前没注意到的问题 (所以说实践还是检验问题的唯一方法啊 汗(lll¬ω¬) ÿ…...

MicMute:如何通过一键操作解决Windows麦克风静音难题
MicMute:如何通过一键操作解决Windows麦克风静音难题 【免费下载链接】MicMute Mute default mic clicking tray icon or shortcut 项目地址: https://gitcode.com/gh_mirrors/mi/MicMute MicMute是一款专为Windows系统设计的轻量级麦克风静音管理工具&#…...

python python-semantic-release
# 关于Python Semantic Release的一些个人看法 平时做项目,版本号管理是个挺麻烦的事情。一开始可能觉得简单,手动改改__version__就行,但随着项目规模变大、协作的人变多,这个问题就复杂起来了。什么时候该升主版本号?…...

2025届必备的十大降重复率助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 通过降低AIGC率,也就是要减少文本里能被认定成是人工智能生成内容的一些特征。这…...

ITE 联阳半导体推出新一代 IT6115:集成分路器与信号放大器的 MIPI 全能转换方案
随着 AR/VR、折叠屏及智能座舱等高端影像市场的爆发,MIPI 接口在带宽、传输距離以及协议兼容性上正面临前所未有的挑战 。联阳半导体(ITE)顺势推出了高度集成的 MIPI D-PHY / C-PHY 双模转换核心——IT6115 。IT6115 并非简单的桥接芯片&…...

龙迅 LT8775 Type‑C/DP1.4/eDP1.4 转双 MIPI DSI+LVDS 桥接芯片详解
最近做车载中控、便携 4K 屏、VR 双显方案,用到龙迅 LT8775,整理完整参数、应用与调试要点,分享给大家。 一、芯片定位与核心规格 LT8775 是龙迅高性能 Type‑C/DP1.4/eDP1.4 转双 MIPI DSI LVDS 视频桥接芯片,内置 MCUEDID/HDCP…...
)
SpringBoot 实战必备:AOP + ThreadLocal 核心知识点(附实战代码)
在 SpringBoot 项目开发中,AOP(面向切面编程)和 ThreadLocal 是高频实用技术,尤其在日志记录、用户上下文传递等场景中不可或缺。本文结合实际项目代码(操作日志切面 登录用户ID存储),整理两者…...

51单片机I/O口驱动LED的正确姿势:灌电流 vs 拉电流实战对比
51单片机I/O口驱动LED的正确姿势:灌电流 vs 拉电流实战对比 在嵌入式系统开发中,LED驱动是最基础却最容易出错的环节。很多初学者在使用51单片机时,常常遇到LED亮度不足、系统功耗异常甚至芯片发热等问题,根源往往在于对I/O口电流…...