[C++项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍...

项目背景
Boost库是C++中一个非常重要的开源库. 它实现了许多C++标准库中没有涉及的特性和功能, 一度成为了C++标准库的拓展库. C++新标准的内容, 很大一部分脱胎于Boost库中.
Boost库的高质量代码 以及 提供了更多实用方便的C++组件, 使得Boost库在C++开发中会被高频使用
为方便开发者学习使用, Boost库官网(boost.org)也提供了不同版本库组件的相关介绍文档, 但是Boost库的官网在相当长一段时间都是没有站内搜索的. 应该是近两个月左右才 实现了站内搜索 的功能:

但是, Boost库官网实现的站内搜索是全局的搜索, 很多时候大部分开发者只需要查看某个组件的文档用以学习.
此时 使用Boost官方提供的站内搜索也是很不方便的, 而且也不支持选择版本来获取相关文档:
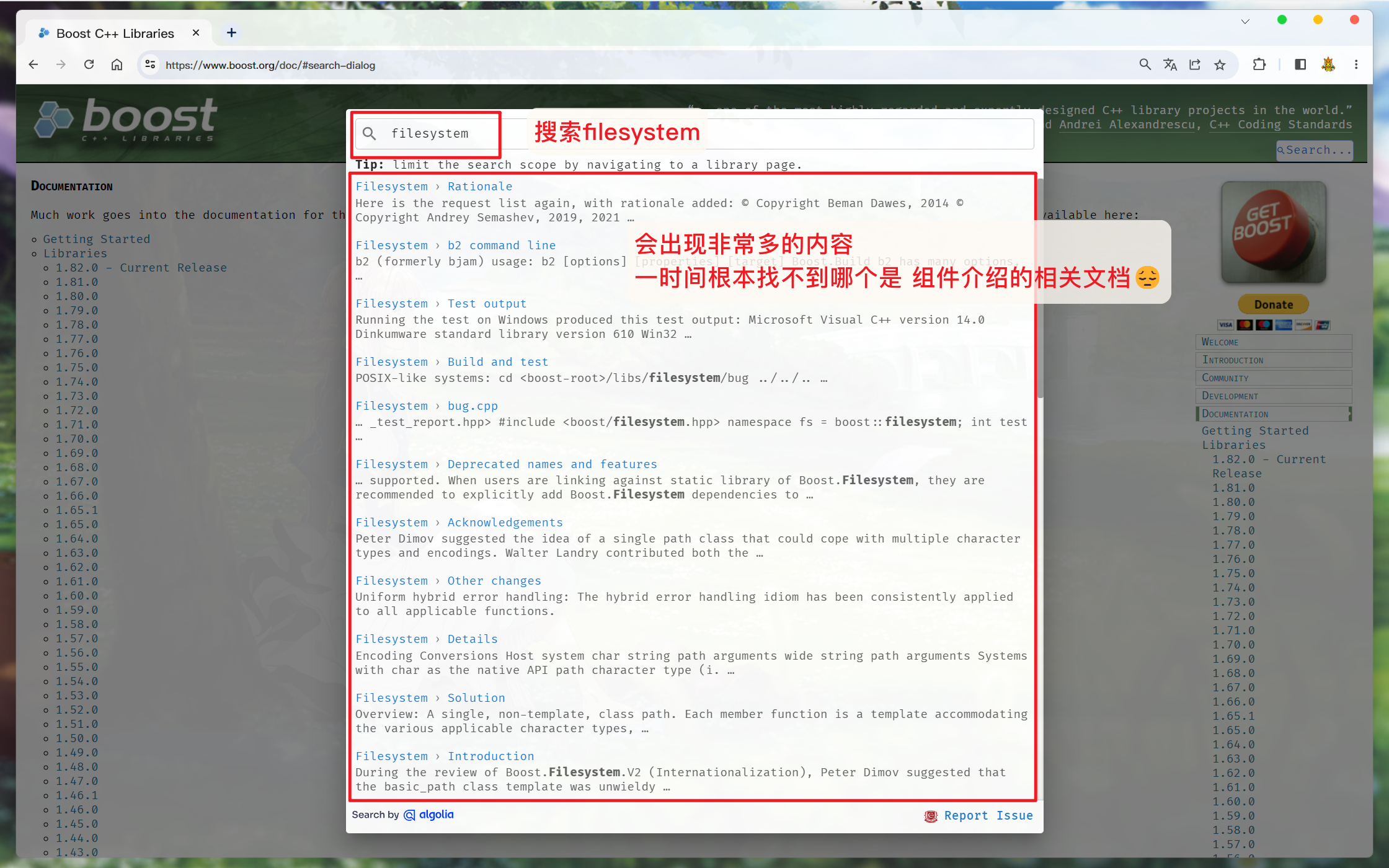
所以就有了本项目的出现, 为Boost库指定版本提供文档的站内搜索
搜索引擎相关宏观原理
我们每个人一定都使用过搜索引擎, 一般人常用的一定有: Bing、百度、Google…
使用搜索引擎搜索一定的内容, 出现的页面一般是这样的:
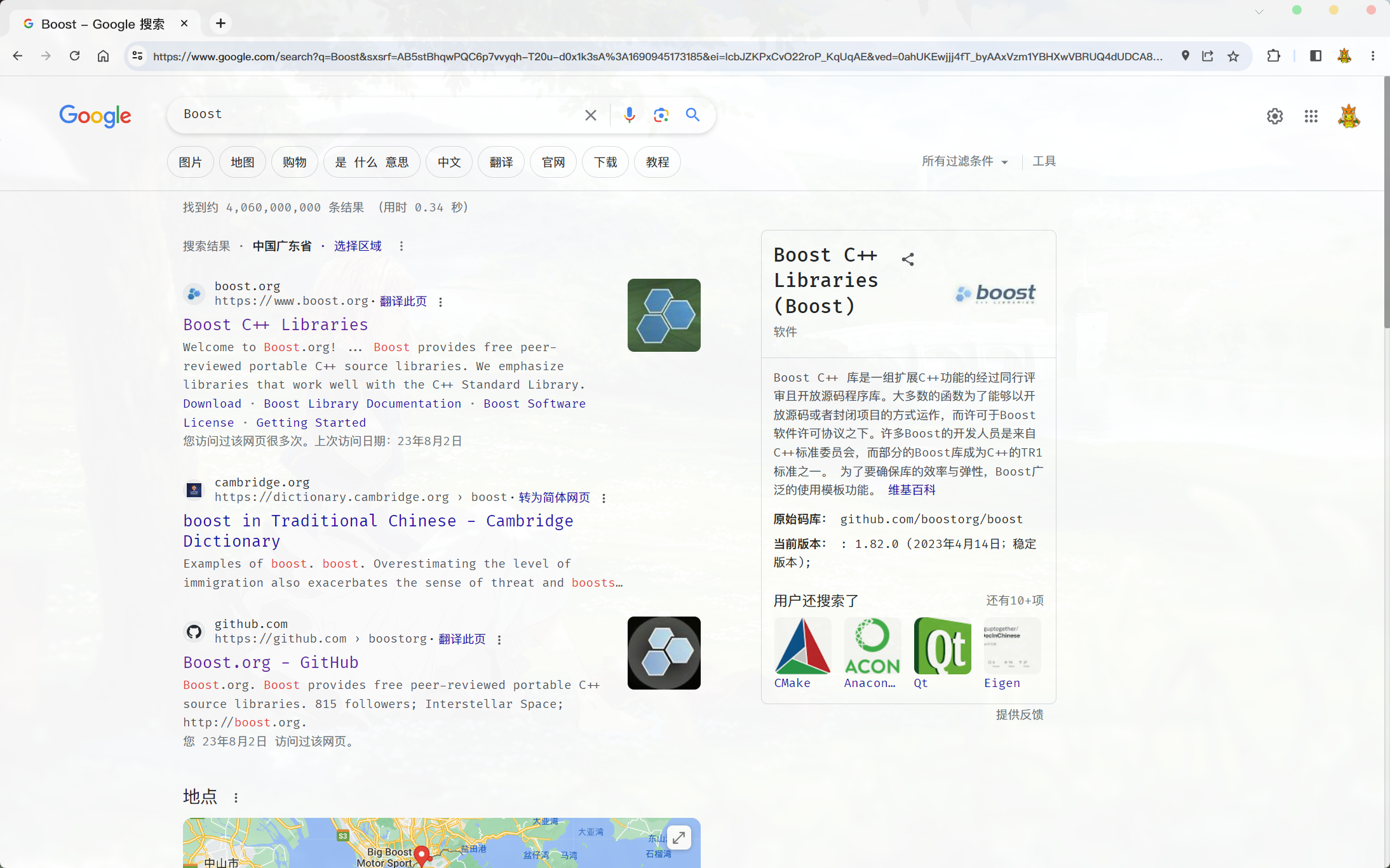
其中最主要的部分是这样的:

搜索引擎通常会将搜索到的内容, 以: 网页的标题(title)、网页的简单摘要(Content)、即将跳转到的网页的网址(url) 为一个单元的形式展现出来. 并且, 包含的搜索的 关键字会被高亮显示
其他搜索引擎也是大同小异:

那么, 搜索引擎是如何做这整个过程的呢?
首先要明白, 输入关键字 点击搜索的这个行为, 其实是在创建并向服务器发送http/https请求的行为.
在客户端输入关键词, 点击搜索. 创建请求, 携带关键词向服务器发送请求.
服务器接收到请求之后, 根据关键词 在服务器检索索引 获取所有相关的html的内容, 然后 将获取到的多个网页内容(title、content、url), 拼接构建成一个新的网页 响应回客户端.
整个过程中最重要的过程在于: 检索索引
关于索引, 实际是一个帮助快速查找数据的数据结构. 根据关键词 检索索引, 就是在数据结构中查找关键词相关的数据.
索引, 是在 搜索引擎服务启动之前 服务器提前建立好的. 搜索引擎服务启动之后, 可以直接通过索引来检索数据.
搜索引擎索引的建立步骤一般是这样的:
- 爬虫程序爬取网络上的内容, 获取网页等数据
- 对爬取的内容进行解析、去标签, 提取文本、链接、媒体内容等信息
- 对提取的文本进行分词、处理, 得到词条
- 根据词条生成索引, 包括正排索引、倒排索引等
建立好索引之后, 搜索引擎服务就可以根据关键词 检索索引 获取相关数据.
这一整个流程, 即为 搜索引擎的相关宏观原理
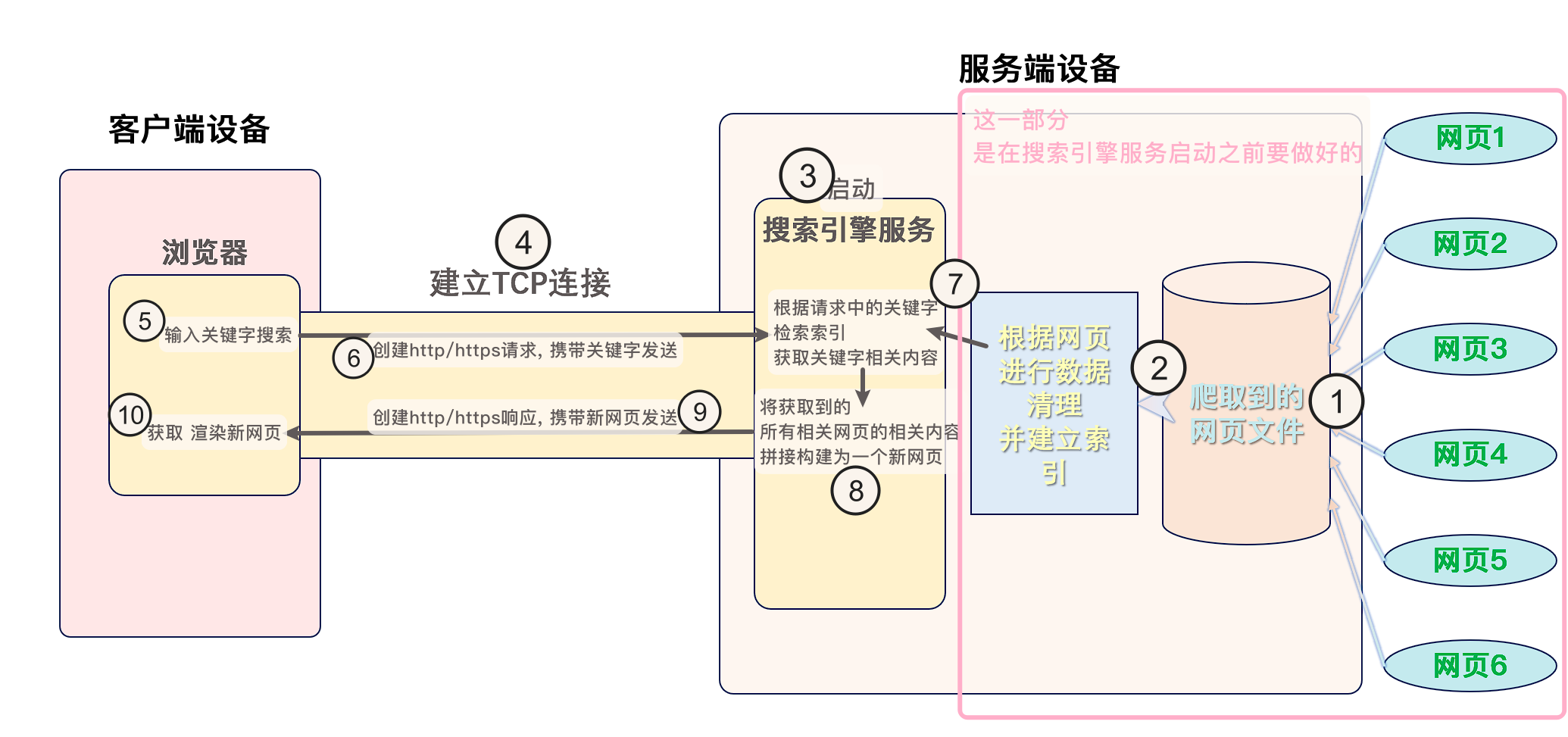
大致的流程 以及 宏观原理图, 可以根据这一张图来理解
服务端需要做的第一个工作是爬取网页.
但是本项目中不需要, 因为是站内文档搜索, 官方提供的也有Boost库的相关源码文件, 其中就包括了Boost库的文档html文件.
Boost库源码下载
https://boostorg.jfrog.io/artifactory/main/release/
这是Boost库的源码发布页. 我们可以直接找到指定版本获取下载链接, 将文件下载到服务器中:
wget https://boostorg.jfrog.io/artifactory/main/release/1.82.0/source/boost_1_82_0.tar.gz
获取到源码压缩文件之后, 执行tar -zxvf boost_1_82_0.tar.gz解压
然后就获取了Boost库源码:

其中, 所有的文档html文件都在 doc//html/目录下:

统计了一下, 此目录下(包括子目录) 一共有8563个html文件, 这些都是Boost库提供的文档
Boost库站内文档搜索 所需技术栈 以及 项目环境
技术栈:
- 后端:
C/C++C++11STLBoost库Jsoncppcppjiebacpp-httplib - 前端:
htmlcssjsjQueryAjax
项目环境:
Centos 7云服务器neovimgcc(g++)makefile
清理 分词 和 索引
实现一个搜索引擎, 最重要的地方在于 建立索引
建立索引, 就是建立 文档与关键词之间的的映射
清理文档文件
所以在建立索引之前, 要 先清理文档中对搜索无用的无效数据. 在html文件中, 无效数据就是html的各种标签:
<!-- 各种成对的标签 -->
<html></html>
<head></head>
<body></body>
<div></div>
<!-- 各种单独的标签 -->
<link>
<meta>
<img>

标签中, <和>之间的内容都是对搜索来说无效的内容. 而对于成对的标签来说 >和<之间的内容则是有效的内容.
简单点来说, 标签内部的数据 是对搜索无效的数据, 标签外的数据是对搜索有效的数据.
简单的举例子:
<div><p class="copyright">Copyright © 2005, 2006 Eric Niebler</p></div>
<div class="toc">
<p><b>Table of Contents</b></p>
其中有效的数据是: Copyright © 2005, 2006 Eric Niebler 和 Table of Contents
其他的都属于标签内的数据, 都是对搜索无效的, 因为浏览器不会将标签内的数据值渲染出来, 那是一些属性.
分词
清理完文档中对搜索无用的无效数据之后, 就可以对文档的内容 进行分词.
分词, 就是将一句话中可用作关键字的词语分割开, 比如:
-
博主买了一些小米和南瓜
分词就可能会分为:
博主买一些小米南瓜小米和南瓜 -
博主做了小米南瓜粥吗
分词就可能会分为:
博主做小米南瓜南瓜粥小米南瓜粥
将可用作关键词的词汇组合或分开并汇总, 停止词不考虑, 就是分词.
停止词, 就是搜索中没有明显作用的词:
了 的 吗 呢 a the ...
索引
每个文件都有文件名 也就是文件ID, 文件内容包含了关键词. 将文件名和关键词之间建立映射关系, 就是建立索引.
以下以两个文件为例
-
文件1: 博主买了一些小米和南瓜
-
文件2: 博主做了小米南瓜粥吗
正排索引
正排索引, 是 从文件ID找到文件关键词:
| 文件ID | 内容关键词 |
|---|---|
| 文件1 | 博主 买 一些 小米 南瓜 小米和南瓜 |
| 文件2 | 博主 做 小米 南瓜 南瓜粥 小米南瓜粥 |
可以看作, 文件ID是Key 用于查找, 内容关键词是Value 是被找到的内容. 建立正排索引可以不对文件内容做分词
此项目中, 建立正派索引时不对文件内容做分词处理
倒排索引
与正排索引相反.
倒排索引, 是 从文件关键词找到文件ID. 并且, 会将所有文档中的关键词进行汇总去重:
| 关键词(唯一) | 涉及的文件ID(文件权重) |
|---|---|
博主 | 文件1、文件2 |
买 | 文件1 |
一些 | 文件1 |
小米 | 文件1、文件2 |
南瓜 | 文件1、文件2 |
小米和南瓜 | 文件1 |
做 | 文件2 |
南瓜粥 | 文件2 |
小米南瓜粥 | 文件2 |
可以看作, 关键词是Key 用于查找, 文件ID是Value 是被找到的内容.
项目中, 正排索引和倒排索引都需要建立并使用.
模拟整个查找到检索索引再到响应的流程:
输入关键词 --> “博主” --> 先在倒排索引检索 --> 获取"文件1""文件2"文件ID --> 再根据获取的文件ID在正排索引中检索 --> 检索到相关文件的文件内容(title、content、url) --> 根据内容构建新网页 --> 响应新网页
本片文章介绍了项目背景, 从下一篇文章开始开始编写项目代码
感谢阅读~
相关文章:
[C++项目] Boost文档 站内搜索引擎(1): 项目背景介绍、相关技术栈、相关概念介绍...
项目背景 Boost库是C中一个非常重要的开源库. 它实现了许多C标准库中没有涉及的特性和功能, 一度成为了C标准库的拓展库. C新标准的内容, 很大一部分脱胎于Boost库中. Boost库的高质量代码 以及 提供了更多实用方便的C组件, 使得Boost库在C开发中会被高频使用 为方便开发者学…...

opencv-32 图像平滑处理-高斯滤波cv2.GaussianBlur()
在进行均值滤波和方框滤波时,其邻域内每个像素的权重是相等的。在高斯滤波中,会将中心点的权重值加大,远离中心点的权重值减小,在此基础上计算邻域内各个像素值不同权重 的和。 基本原理 在高斯滤波中,卷积核中的值不…...

Windows 环境Kubernetes安装
目录 前言 安装 Docker 安装 Kubernetes Windows 安装 kubectl 介绍 安装 开启 Kubernetes 前言 Docker作为当前最流行的容器化平台,为Kubernetes提供了强大的容器化技术基础。Kubernetes与Docker的结合,使得容器化应用程序在大规模集群中得以简…...
自建类ChatGPT服务:本地化部署与远程访问教程
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

常用SQL语句总结
SQL语句 文章目录 SQL语句1 SQL语句简介2 DQL(数据查询语句)3 DML(数据操纵语句)4 DDL(数据定义语句)5 DCL(数据控制语句)6 TCL(事务控制语句) 1 SQL语句简介…...
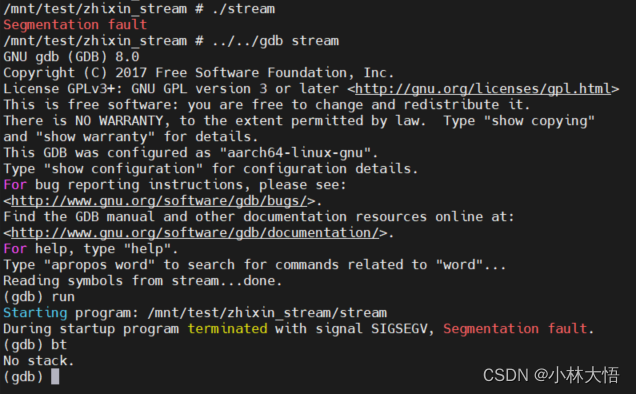
arm交叉编译lmbench
一、下载lmbench www.bitmover.com/lmbench 官网下载,http://www.bitmover.com/lmbench/lmbench3.tar.gz 我没有下载下来,找的别人的百度云下载 链接: https://pan.baidu.com/s/1tGo1clCqY-jQPN8G1eWSsg 提取码: f6jd 二、修改makefile 修改三个文件…...
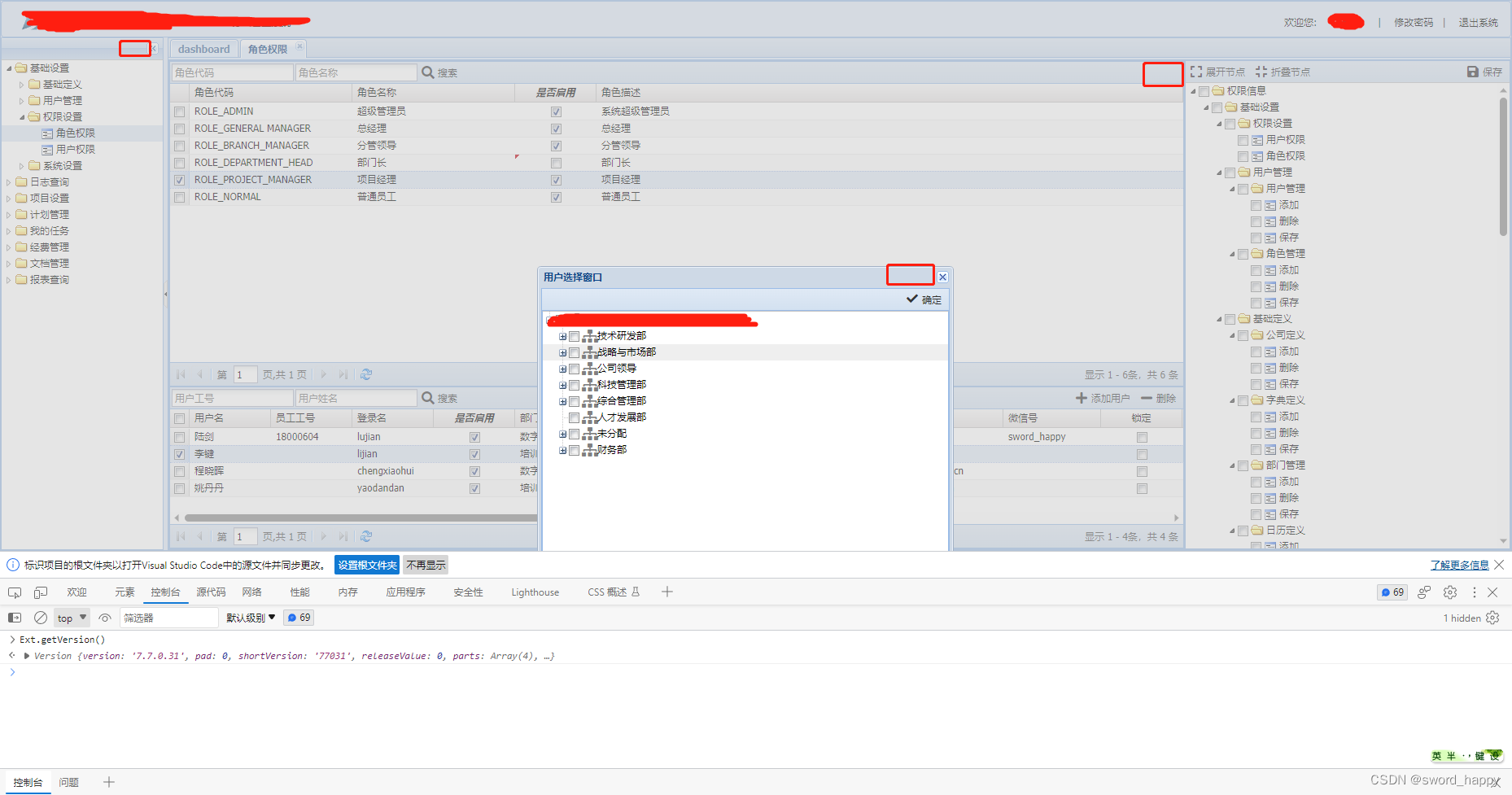
ExtJs 7.7.0 下载方法与去除trial水印
背景 最近发现Sencha ExtJs发布了ExtJs7.7.0版本,立刻下载了SDK包,许多朋友不知如何下载,如何去除右上角的trial水印。本文讲下相关下载技巧与方法。 下载SDK 首先需要申请试用,申请地址如下,需要注意可能需要梯子&…...

Android11开发规划
文章目录 规划总结规划 提示:这里可以添加本文要记录的大概内容: 从本文开始,会介绍如何移植瑞芯微提供的Android11源码到自己的RK3568的板子上 下面是整个Android开发的规划: 包括以下部分: … 一、移植部分 下载编译瑞芯微提供的源码 瑞芯微原厂源码目录介绍...

活动隔断在现在酒店运用的方式
活动隔断是一种在酒店内部划分空间的方式,用于实现不同活动的隔离和隐私。现代酒店常用的活动隔断方式有以下几种: 1. 固定隔断:使用墙体、固定屏风或者板材等材料,将空间划分为不同的房间或区域。这种方式常用于划分客房、会议室…...
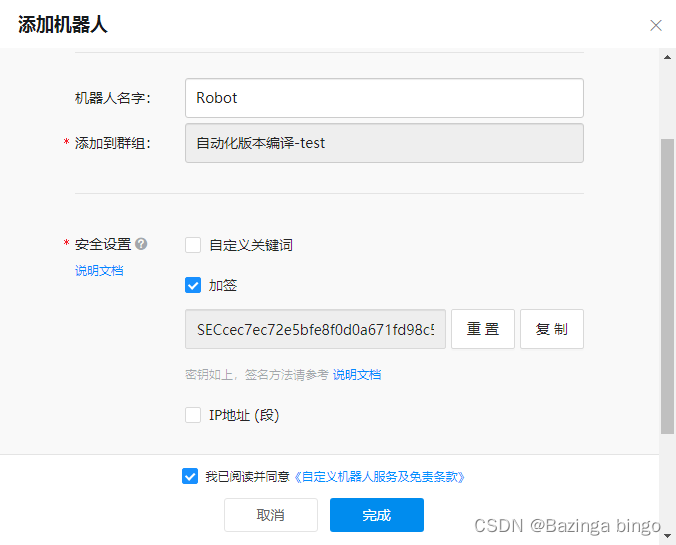
Jenkins工具系列 —— 插件 钉钉发送消息
文章目录 安装插件 Ding TalkJenkins 配置钉钉机器人钉钉APP配置项目中启动钉钉通知功能 安装插件 Ding Talk 点击 左侧的 Manage Jenkins —> Plugins ——> 左侧的 Available plugins Jenkins 配置钉钉机器人 点击 左侧的 Manage Jenkins ,拉到最后 钉…...

LeetCode 26 题:删除有序数组的重复项
思路 在写这一个题时,我突然想到了Python中的 set()函数可能会有大用处,便选择了用Python写。 set()函数可以将列表转化为集合,集合会保证元素的单一性,所以会自动删去相同字符。 …...
)
优雅地切换node版本(windows)
文章目录 1、下载并安装nvm2、nvm的使用3、处理npm版本与nodejs版本不匹配问题(通常不会有这个问题) 1、下载并安装nvm 卸载已安装的node:控制面板-程序-找到node并卸载 通常在控制面板中卸载后,nodejs目录、环境变量、注册表就自…...

反诈:吴明军、黄亮领导的WIN生活资金盘,大家警惕防范此类诈骗
消息已经证实!“米粒”无法变现,数以万计的会员深套“315万民商城”,维权艰难,血汗钱无法讨回。 其实这一点笔者并不感到太意外,因为万民商城资金传销盘的定性之前就已经发文揭露过,并反复提醒大家小心警惕…...
)
shell、bash的关系及bash的特性(一)
一、概念 shell是壳,是运行在终端中的文本互动程序。Shell相当于是一个翻译,把我们在计算机上的操作命令,翻译为计算机可识别的二进制命令,传递给内核,以便调用计算机硬件执行相关的操作;同时,计…...
【问题随记】
ubuntu 14.04源更新(sources.list) deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-update…...

Stable Diffusion AI绘画学习指南【常用模型,采样器介绍】
常用采样器、目前有20个采样步骤越多每个步之间的降噪越小,减少采样过程中的截断误差,结果越好 学微分方程求解器 Euler(最简单的采样器,采样过程中不加随机噪声,根据采样计划来执行每个步骤中的噪声,并使…...

pycharm——漏斗图
import pyecharts.options as opts from pyecharts.charts import Funnel""" Gallery 使用 pyecharts 1.1.0 参考地址: https://echarts.apache.org/examples/editor.html?cfunnel目前无法实现的功能:1、暂时无法对漏斗图的长宽等范围操作进行修改 ""…...

RISC-V基础之浮点指令(包含实例)
RISC-V体系结构定义了可选的浮点扩展,分别称为RVF、RVD和RVQ,用于操作单精度、双精度和四倍精度的浮点数。RVF/D/Q定义了32个浮点寄存器,f0到f31,它们的宽度分别为32位、64位或128位。当一个处理器实现了多个浮点扩展时࿰…...

前端生成图片验证码怎么做?
##题记:我们实现一个功能首先想一下我们需要做哪些工作,比如我们需要生成一个随机的图片验证码,我们需要一个就是点击事件获取验证码,通过接口我们去获取图片路径进行渲染就行,这里边还要牵扯一件事情就是获取一个随机…...
【Java】springboot框架 粮油质量溯源MES生产加工管理系统源码
粮油质量溯源MES生产加工管理系统源码,实现一物一码,全程追溯,正向追踪,逆向溯源。技术架构:spring bootmybatiseasyuimysql 。 粮油生产质量追溯系统实现种植主体、种植基地、生产计划、压榨、精炼、包装、销售、物料…...

nRF24L01P轻量级SPI驱动库:嵌入式教学与工业遥控实践
1. nRF24L01P驱动库技术解析:面向嵌入式教学与工业遥控场景的轻量级SPI通信实现1.1 库定位与工程背景该nRF24L01P驱动库源自法国尼斯大学IUT(University Institute of Technology)2019年TelecoBots教学项目,专为嵌入式遥控机器人平…...

SAR成像中的几何畸变:成因解析与典型类型剖析
1. 从斜拍到正片:SAR成像为何天生"变形"? 第一次接触SAR图像时,很多人都会困惑:为什么山体会出现"叠罗汉"的奇怪效果?为什么平坦的农田在图像上像被挤压过的弹簧?这其实源于SAR与生俱来…...

ADC128D818系统监控设计:高集成8通道12位ADC应用指南
1. ADC128D818芯片概述与系统定位ADC128D818是德州仪器(TI)推出的一款高集成度、低功耗的12位8通道模数转换器,专为嵌入式系统监控场景设计。其核心价值不在于通用数据采集,而在于为MCU提供一套完整、可靠、即插即用的“系统健康感…...
,错过再无官方授权分发)
【最后72小时解锁】SITS2026联邦学习工作坊原始代码包+训练轨迹可视化Dashboard(含PyTorch/FedNLP/SecureAgg三框架适配版),错过再无官方授权分发
第一章:SITS2026演讲:大模型联邦学习应用 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026主会场,来自MIT与华为诺亚方舟实验室的联合团队展示了基于LLaMA-3架构的大模型联邦学习新范式——FedLLM。该方案突破传统参数平均&#x…...

TCP连接管理实战:从CLOSE_WAIT与TIME_WAIT的根源到系统级调优
1. 从线上故障说起:当端口耗尽成为压测拦路虎 去年双十一大促前,我们团队在对核心交易系统做全链路压测时,突然发现服务端出现大量"Address already in use"错误。监控面板上TCP连接数曲线像坐了火箭一样直线上升,短短1…...

Phi-4-Reasoning-Vision实战案例:电商商品图深度分析+隐藏线索识别
Phi-4-Reasoning-Vision实战案例:电商商品图深度分析隐藏线索识别 1. 工具介绍 Phi-4-Reasoning-Vision是一款基于微软Phi-4-reasoning-vision-15B多模态大模型开发的高性能推理工具。它专为双卡4090环境优化,能够对图片进行深度分析并识别隐藏线索&am…...

告别卡顿:如何让Mac外接鼠标获得原生触控板的顺滑滚动体验
告别卡顿:如何让Mac外接鼠标获得原生触控板的顺滑滚动体验 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independent…...

TensorRT 8.2.5 部署实战:从环境配置到模型推理的完整指南
1. 环境准备:搭建TensorRT 8.2.5的温床 在Ubuntu 20.04上部署TensorRT就像给赛车装配高性能引擎,首先要确保车库(系统环境)符合标准。我遇到过不少开发者卡在环境配置这一步,往往是因为CUDA版本不匹配这类"低级错…...

MT4跟单系统高频交易优化:如何用Pumping模式降低服务器负载50%
MT4跟单系统高频交易优化:Pumping模式实战解析与性能提升方案 外汇交易市场瞬息万变,对于专业交易团队而言,毫秒级的延迟可能意味着巨大的利润差异。在MT4跟单系统中,传统轮询方式在高频交易场景下往往成为性能瓶颈,导…...

如何在Mac上原生读写NTFS硬盘?终极指南与免费工具推荐
如何在Mac上原生读写NTFS硬盘?终极指南与免费工具推荐 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management fo…...