Embedding入门介绍以及为什么Embedding在大语言模型中很重要
Embeddings技术简介及其历史概要
在机器学习和自然语言处理中,embedding是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。embedding向量通常是一个由实数构成的向量,它将输入的数据表示成一个连续的数值空间中的点。
简单来说,embedding就是一个N维的实值向量,它几乎可以用来表示任何事情,如文本、音乐、视频等。在这里,我们也主要是关注文本的embedding。
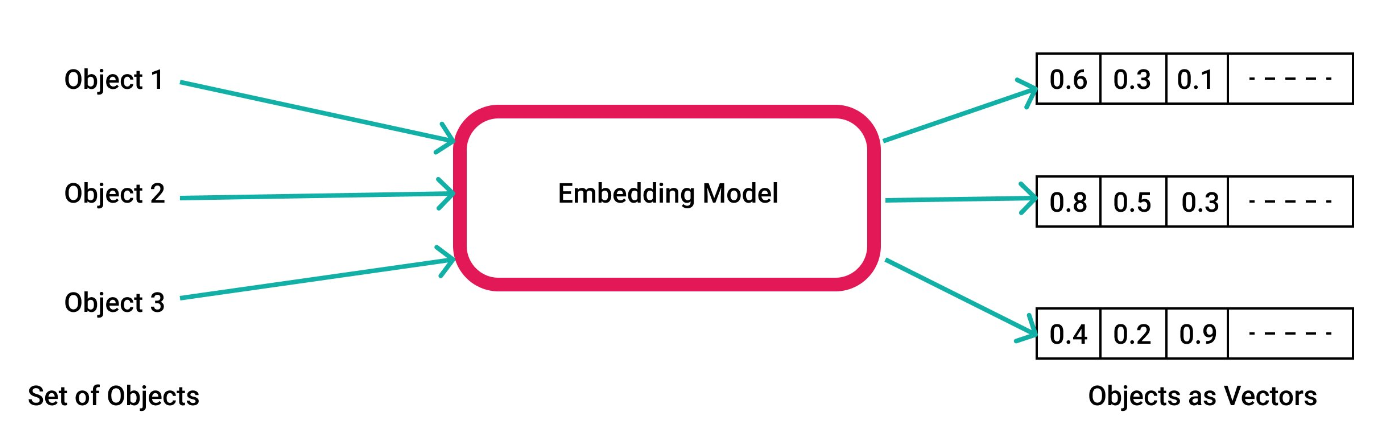
而embedding重要的原因在于它可以表示单词或者语句的语义。实值向量的embedding可以表示单词的语义,主要是因为这些embedding向量是根据单词在语言上下文中的出现模式进行学习的。例如,如果一个单词在一些上下文中经常与另一个单词一起出现,那么这两个单词的嵌入向量在向量空间中就会有相似的位置。这意味着它们有相似的含义和语义。
embedding技术的发展可以追溯到20世纪50年代和60年代的语言学研究,其中最著名的是Harris在1954年提出的分布式语义理论(distributional semantic theory)。这个理论认为,单词的语义可以通过它们在上下文中的分布来表示,也就是说,单词的含义可以从其周围的词语中推断出来。
在计算机科学领域,最早的embedding技术可以追溯到20世纪80年代和90年代的神经网络研究。在那个时候,人们开始尝试使用神经网络来学习单词的embedding表示。其中最著名的是Bengio在2003年提出的神经语言模型(neural language model),它可以根据单词的上下文来预测下一个单词,并且可以使用这个模型来生成单词的embedding表示。
自从2010年左右以来,随着深度学习技术的发展,embedding技术得到了广泛的应用和研究。在这个时期,出现了一些重要的嵌入算法,例如Word2Vec、GloVe和FastText等。这些算法可以通过训练神经网络或使用矩阵分解等技术来学习单词的嵌入表示。这些算法被广泛用于各种自然语言处理任务中,例如文本分类、机器翻译、情感分析等。
近年来,随着深度学习和自然语言处理技术的快速发展,embedding技术得到了进一步的改进和发展。例如,BERT、ELMo和GPT等大型语言模型可以生成上下文相关的embedding表示,这些embedding可以更好地捕捉单词的语义和上下文信息。
Embedding的主要价值在哪里?
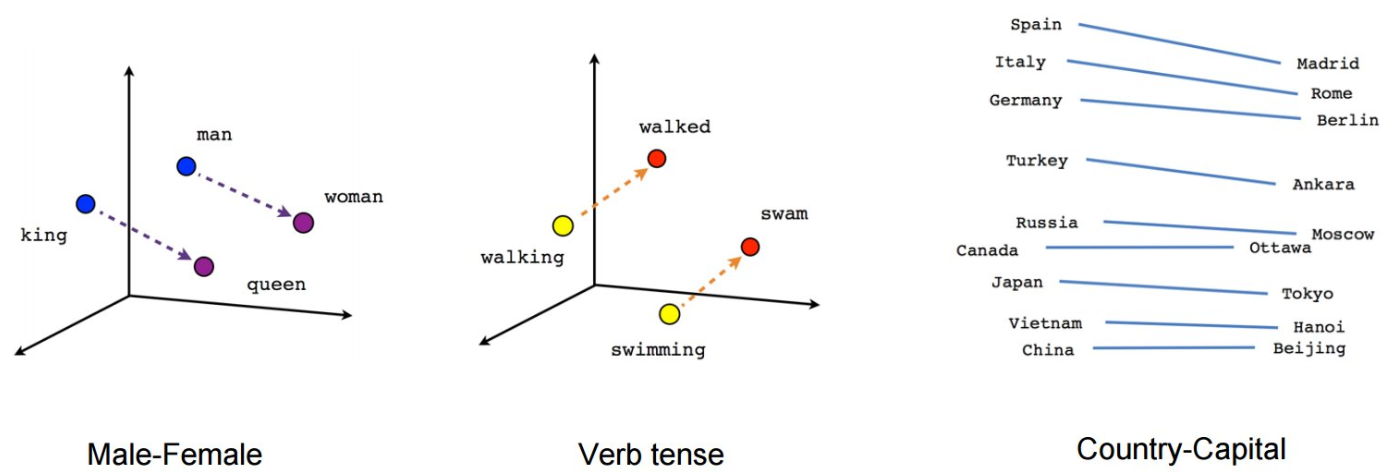
如前所述,embedding向量是包含语义信息的。也就是含义相近的单词,embedding向量在空间中有相似的位置,但是,除此之外,embedding也有其它优点。
例如,实值向量表示的embedding可以进行向量运算。例如,通过对embedding向量执行向量加法和减法操作,可以推断出单词之间的语义关系。例如,对于embedding向量表示的“king”和“man”,执行“queen = king - man + woman”操作可以得到一个向量表示“queen”,这个向量与实际的“queen”向量在向量空间中非常接近。
此外,实值向量embedding还可以在多个自然语言处理任务中进行共享和迁移。例如,在训练一个情感分析模型时,可以使用在句子分类任务中训练的嵌入向量,这些向量已经学习到了单词的语义和上下文信息,从而可以提高模型的准确性和泛化能力。
综上所述,实值向量embedding可以通过从大量的语言数据中学习单词的语义和上下文信息,从而能够表示单词的语义,并且可以进行向量运算和在不同自然语言处理任务中共享和迁移。
Embedding在大模型中的价值
前面说的其实都是Embedding在之前的价值。但是,大语言模型时代,例如ChatGPT这样的模型流行之后,大家发现embedding有了新的价值,即解决大模型的输入限制。
此前,OpenAI官方也发布了一个案例,即如何使用embedding来解决长文本输入问题,我们DataLearner官方博客也介绍了这个教程:OpenAI官方教程:如何使用基于embeddings检索来解决GPT无法处理长文本和最新数据的问题。
像 GPT-3 这样的语言模型有一个限制,即它们可以处理的输入文本量有限。这个限制通常在几千到数万个tokens之间,具体取决于模型架构和可用的硬件资源。
这意味着对于更长的文本,例如整本书或长文章,可能无法一次将所有文本输入到语言模型中。在这种情况下,文本必须被分成较小的块或“片段”,可以由语言模型单独处理。但是,这种分段可能会导致输出的上下文连贯性和整体连贯性问题,从而降低生成文本的质量。
这就是Embedding的重要性所在。通过将单词和短语表示为高维向量,Embedding允许语言模型以紧凑高效的方式编码输入文本的上下文信息。然后,模型可以使用这些上下文信息来生成更连贯和上下文适当的输出文本,即使输入文本被分成多个片段。
此外,可以在大量文本数据上预训练Embedding,然后在小型数据集上进行微调,这有助于提高语言模型在各种自然语言处理应用程序中的准确性和效率。
如何基于Embedding让大模型解决长文本(如PDF)的输入问题?
这里我们给一个案例来说明如何用Embedding来让ChatGPT回答超长文本中的问题。
如前所述,大多数大语言模型都无法处理过长的文本。除非是GPT-4-32K,否则大多数模型如ChatGPT的输入都很有限。假设此时你有一个很长的PDF,那么,你该如何让大模型“读懂”这个PDF呢?
首先,你可以基于这个PDF来创建向量embedding,并在数据库中存储(当前已经有一些很不错的向量数据库了,如Pinecone)。
接下来,假设你想问个问题“这个文档中关于xxx是如何讨论的?”。那么,此时你有2个向量embedding了,一个是你的问题embedding,一个是之前PDF的embedding。此时,你应该基于你的问题embedding,去向量数据库中搜索PDF中与问题embedding最相似的embedding。然后,把你的问题embedding和检索的得到的最相似的embedding一起给ChatGPT,然后让ChatGPT来回答。
当然,你也可以针对问题和检索得到的embedding做一些提示工程,来优化ChatGPT的回答。
如何生成和存储Embedding
其实,生成Embedding的方法有很多。这里列举几个比较经典的方法和库:
-
Word2Vec:是一种基于神经网络的模型,用于将单词映射到向量空间中。Word2Vec包括两种架构:CBOW (Continuous Bag-of-Words) 和 Skip-gram。CBOW 通过上下文预测中心单词,而 Skip-gram 通过中心单词预测上下文单词。这些预测任务训练出来的神经网络权重可以用作单词的嵌入。
-
GloVe:全称为 Global Vectors for Word Representation,是一种基于共现矩阵的模型。该模型使用统计方法来计算单词之间的关联性,然后通过奇异值分解(SVD)来生成嵌入。GloVe 的特点是在计算上比 Word2Vec 更快,并且可以扩展到更大的数据集。
-
FastText:是由 Facebook AI Research 开发的一种模型,它在 Word2Vec 的基础上添加了一个字符级别的 n-gram 特征。这使得 FastText 可以将未知单词的嵌入表示为已知字符级别 n-gram 特征的平均值。FastText 在处理不规则单词和罕见单词时表现出色。
-
OpenAI的Embeddings:这是OpenAI官方发布的Embeddings的API接口。目前有2代产品。目前主要是第二代模型:
text-embedding-ada-002。它最长的输入是8191个tokens,输出的维度是1536。
这些方法都有各自的优点和适用场景,选择最适合特定应用程序的嵌入生成方法需要根据具体情况进行评估和测试。不过,有人测试过,OpenAI应该是目前最好的。不过,收费哦~但是很便宜,1000个tokens只要0.0004美元,也就是1美元大约可以返回3000页的内容。获取之后直接保存就行。
目前,embedding的保存可以考虑使用向量数据库。例如,
- Pinecone的产品,最近刚以10亿美元的估值融资了1亿美金。Shopify, Brex, Hubspot都是它产品的用户。
- Milvus是一个开源的向量数据库。
- Anthropic VDB,这是Anthropic公司开发的安全性高的向量数据库,能够对向量数据进行改变、删除、替换等操作,同时保证数据库完整性。
总结
embedding在word2vec发布的时候很火。这几年似乎没那么热,但是随着大语言模型的长输入限制越来越明显,embedding技术重新被大家所重视。
相关文章:
Embedding入门介绍以及为什么Embedding在大语言模型中很重要
Embeddings技术简介及其历史概要 在机器学习和自然语言处理中,embedding是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。embedding向量通常是一个由实数构成的向量,它将输入的数据表示成一个连续的数值空间中…...

暑假刷题第20天--8/3
B-序列的与和_2023河南萌新联赛第(四)场:河南大学 (nowcoder.com)(dfs) #include<iostream> #include<string> using namespace std; #define ull unsigned long long int n,k; ull a[21]; ull ans0; int…...

docker容器内的django启动celery任务队列
问题1: celery任务队列一般要使用redis,但是容器内的django要访问本机的redis是十分麻烦的 解决2: 在容器内安装redis,或者单独启动一个redis的容器,我是单独启动一个redis容器 安装redis镜像docker pull redis启动…...
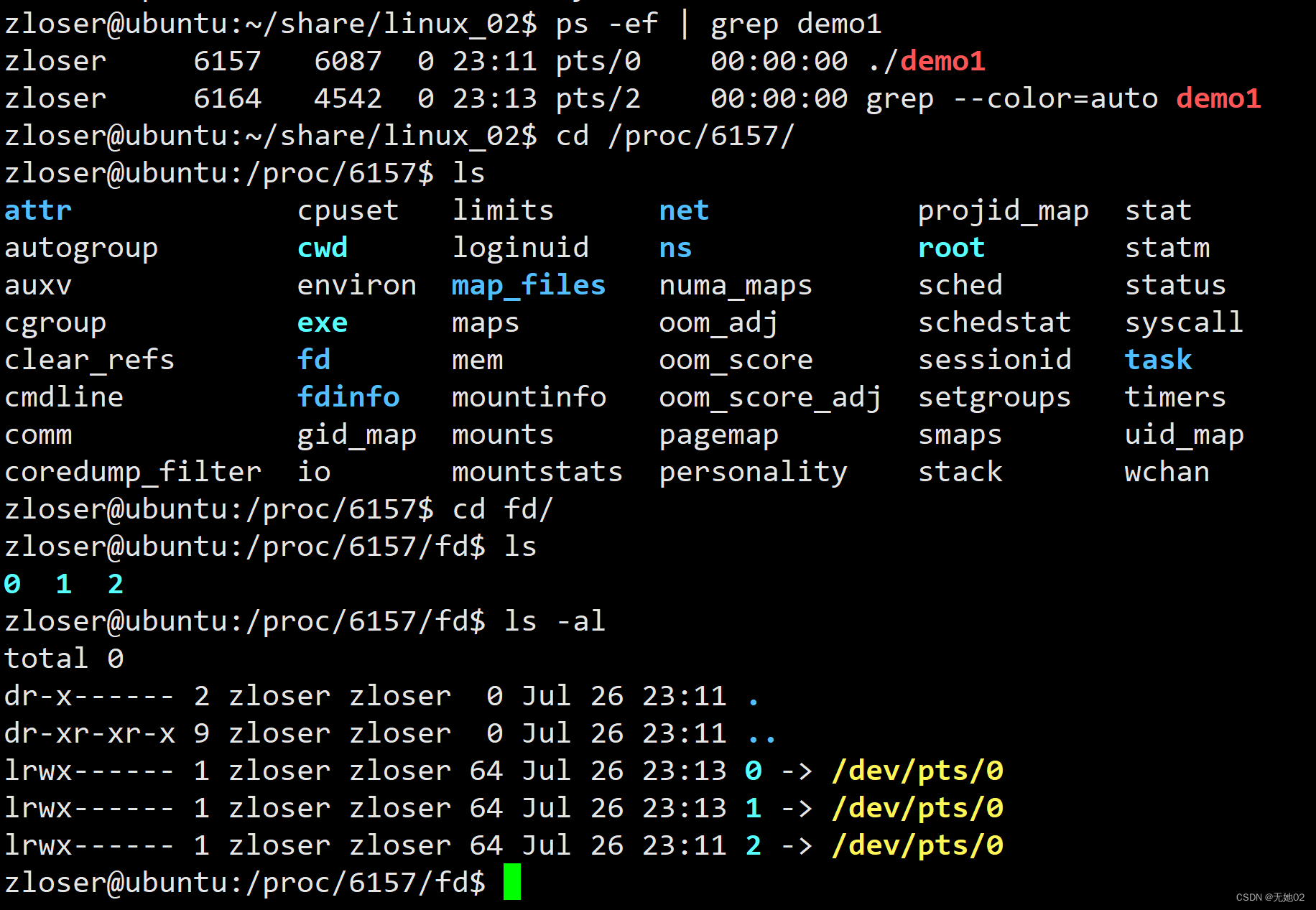
linux文件描述符fd
文件描述符 fd是一个>0 的整数 每打开一个文件,就创建一个文件描述符,通过文件描述符来操作文件 预定义的文件描述符: 0:标准输入,对应于已打开的标准输入设备(键盘) 1:标准输出,对应于已打开的标准输出设备(控制台) 2.标准错误…...

【深度学习】各个开源库总结及实战-总目录
前言 此专栏主要是用MMCV和PaddlePaddle,它们都是优秀的开源库,用于计算机视觉和深度学习任务。MMCV提供了丰富的计算机视觉工具和算法,基于PyTorch框架,适合对PyTorch熟悉的用户。PaddlePaddle是百度开发的深度学习平台,提供易用且高性能的深度学习框架。 此专栏主要包括…...

Unity Shader:闪烁
还是一样的分为UI闪烁和物体闪烁,其中具体可分为:UI闪烁、物体闪烁与半透明闪烁 1,UI闪烁 对于UI 还是一样的,改写UI本身的shader: Shader "UI/YydUIShanShder" {Properties{[PerRendererData] _MainTex(…...

c++开发模式桥接模式
将抽象部分与它的实现部分分离,使它们都可以独立地变化。它是一种对象结构型模式,又称为柄体(Handle and Body)模式或接口(Interface)模式。 #include <iostream> using namespace std;// Abstractionclass Abstraction { public:virtual void Op…...

javaScript 树形结构 递归查询方法。
1. 函数递归定义 程序调用自身的编程技巧称为递归( recursion)。 2.使用条件 1.存在限制条件,当满足这个限制条件的时候,递归便不再继续。 2.每次递归调用之后越来越接近这个限制条件。 3.既然是自己调用自己,那么整个…...

MySQL语法2
DQL语句介绍 DQL是数据查询语言,用来查询数据库中表的记录 DQL-基本查询语句 SELECT 字段列表 FROM 表名列表 WHERE 条件列表 GROUP BY 分组字段列表 HAVIMG 分组后条件列表 ORDER BY 排列字段列表 LIMIT 分页参数 讲解过程:基本查询、条件查询…...

Mysql on duplicate key update用法及优缺点
在实际应用中,经常碰到导入数据的功能,当导入的数据不存在时则进行添加,有修改时则进行更新, 在刚碰到的时候,一般思路是将其实现分为两块,分别是判断增加,判断更新,后来发现在mysql…...

【Linux】-进程概念之进程优先级(如何去进行调度以及进程切换),还不进来看看??
💖作者:小树苗渴望变成参天大树🎈 🎉作者宣言:认真写好每一篇博客💤 🎊作者gitee:gitee✨ 💞作者专栏:C语言,数据结构初阶,Linux,C 动态规划算法🎄 如 果 你 …...

《在细雨中呼喊》阅读笔记
《在细雨中呼喊》阅读笔记 2023年2月5号在家读完,本书就是以作者者回忆的形式来写,男一号叫孙光林,有一个哥哥孙光平,一个弟弟叫孙光明,父亲叫孙光才。书中写了四篇故事。 第一篇写的就是作者对于老家生活的回忆 小的时…...
01-1 搭建 pytorch 虚拟环境
pytorch 管网:PyTorch 一 进入 Anaconda 二 创建虚拟环境 conda create -n pytorch python3.9注意要注意断 VPN切换镜像: 移除原来的镜像 # 查看当前配置 conda config --show channels conda config --show-sources# 移除之前的镜像 conda config --…...
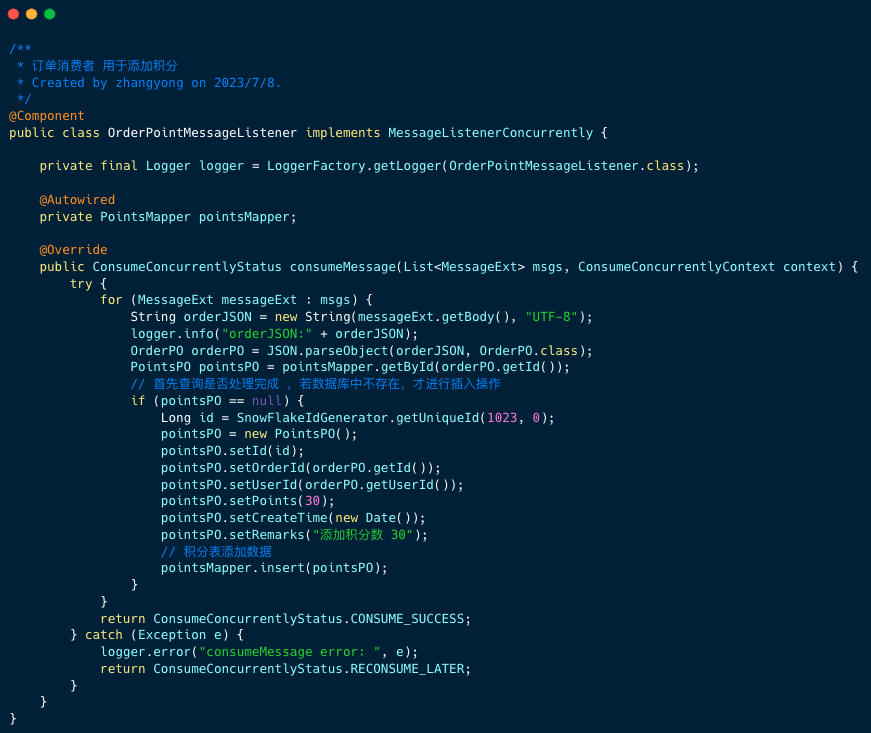
RocketMQ 事务消息
事务消息是 RocketMQ 的高级特性之一 。这篇文章,笔者会从应用场景、功能原理、实战例子三个模块慢慢为你揭开事务消息的神秘面纱。 1 应用场景 举一个电商场景的例子:用户购物车结算时,系统会创建支付订单。 用户支付成功后支付订单的状态…...

Windows安装ElasticSearch
安装环境:java环境。新版本需要安装高版本的java,所有本次安装的为 7.x版本的ElasticSearch 。所以要java11 1、安装java11 2、下载 Elasticsearch 安装包 官网地址:(https://www.elastic.co/cn/) 安装包下载地址:https://www…...

【深度学习】SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking,论文
论文:https://arxiv.org/abs/2211.08824 代码:https://github.com/WWangYuHsiang/SMILEtrack 文章目录 AbstractIntroductionRelated WorkTracking-by-DetectionDetection methodData association method Tracking-by-Attention Methodology架构概述外观…...

【Kubernetes】Kubernetes之二进制部署
kubernetes 一、Kubernetes 的安装部署1. 常见的安装部署方式1.1 Minikube1.2 Kubeadm1.3 二进制安装部署2. K8S 部署 二进制与高可用的区别2.1 二进制部署2.2 kubeadm 部署二、Kubernetes 二进制部署过程1. 服务器相关设置以及架构2. 操作系统初始化配置3. 部署 etcd 集群4. 部…...
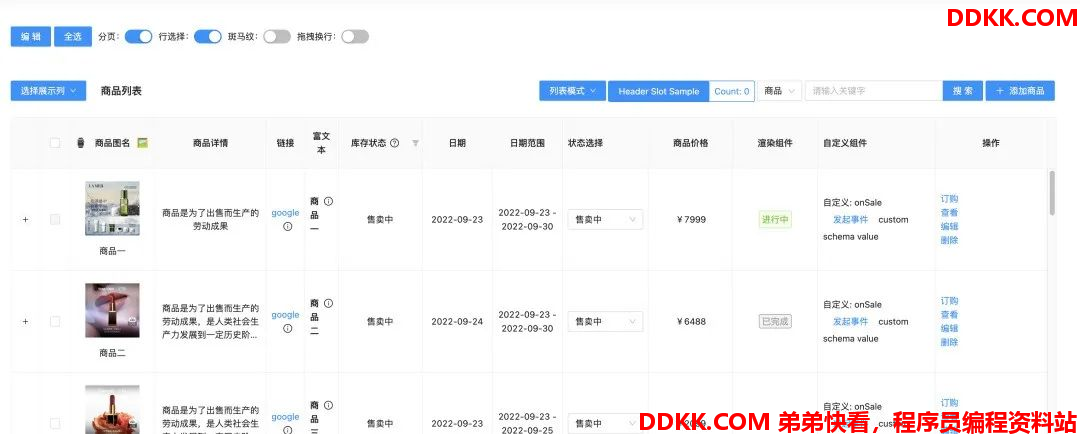
京东开源的、高效的企业级表格可视化搭建解决方案:DripTable
DripTable 是京东零售推出的一款用于企业级中后台的动态列表解决方案,项目基于 React 和 JSON Schema,旨在通过简单配置快速生成页面动态列表来降低列表开发难度、提高工作效率。 DripTable 目前包含以下子项目:drip-table、drip-table-gene…...
STL C++学习背景
STL C学习背景 背景知识 背景知识 STL前置知识 STL,英文全称 standard template library,中文可译为标准模板库或者泛型库,其包含有大量的模板类和模板函数,是 C 提供的一个基础模板的集合,用于完成诸如输入/输出、数…...

C#踩坑:谨慎在XML数据列上绑定鼠标事件!
按照计划,昨天晚上就完成最后的公式自动计算,程序的流程就算完整了,可以正常运行了,一般情况下,是可以完成的。 10点开始干,窗体上放置一个Treeview,然后针对XML对Treeview进行数据绑定…...
【轨迹预测】MTR:基于全局意图定位与局部运动精化的Transformer架构解析
1. MTR框架的核心设计思想 想象一下你正在开车,前方十字路口突然出现一辆犹豫不决的自行车。人类司机能瞬间判断出多种可能性:它可能直行、左转或突然刹车。这正是MTR(Motion Transformer)要解决的挑战——让AI像人类一样预测复杂…...

单细胞注释进阶指南-利用AddModuleScore精准定位细胞亚群
1. 为什么单细胞注释需要进阶方法? 做单细胞分析的朋友们都知道,注释细胞亚群就像是在玩一个高难度的"找不同"游戏。传统方法就像是用放大镜一个个对比特征,而AddModuleScore则像是给了我们一个智能识别器。我在分析NK/T细胞亚群时…...

终极硬件控制指南:如何用OmenSuperHub完全掌控惠普暗影精灵性能
终极硬件控制指南:如何用OmenSuperHub完全掌控惠普暗影精灵性能 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 厌倦了官方软件Omen Gaming Hu…...

OpenResty终极优化:引入L1本地缓存,实现微秒级响应
在上一篇文章中,我们实现了OpenResty查询Redis的架构。虽然Redis很快,但它毕竟是一个远程服务,每次查询都需要经过网络I/O(即使是本地回环网络,也有协议解析和上下文切换的开销)。在超高并发场景下…...

别再只盯着理论了!用LTspice仿真施密特触发器,5分钟搞定传输特性分析
别再只盯着理论了!用LTspice仿真施密特触发器,5分钟搞定传输特性分析 在电子电路设计中,施密特触发器因其独特的迟滞特性而广受欢迎,它能有效消除噪声干扰,提高信号稳定性。然而,传统的理论分析往往让初学者…...

LabVIEW网络通讯:TCP连接三菱PLC FX3U ENET-ADP的MC协议网络通讯与程序开发
LabVIEW网络网口TCP通讯三菱PLC FX3U ENET-ADP,MC协议网络通讯FX3U网络通讯。 官方MC协议,报文读取,安全稳定。 程序代开发,代写程序。 通讯配置,辅助测试。 FX3U无程序网络通讯实现。 常用功能一网打尽。 1.命令帧读写…...
)
2026奇点智能技术大会核心技术解密(AI原生研发全链路SOP首次公开)
第一章:2026奇点智能技术大会:AI原生研发全流程拆解 2026奇点智能技术大会(https://ml-summit.org) 在2026奇点智能技术大会上,AI原生研发不再停留于模型微调与API调用,而是贯穿从需求建模、数据契约定义、可验证推理生成&#x…...

PHP零起点入门:适合普通学习者的极简教程
PHP从零开始:手把手入门指南与实战教程 PHP是一门专门用于Web开发的服务器端脚本语言,最大特点是能嵌入HTML,上手简单且就业需求大。本文避开复杂术语,用“操作步骤实际代码”带你从0学会PHP,每个例子都能直接复制运行…...

C++高性能编程技巧:Phi-4-mini-reasoning解读内存管理与并发模型
C高性能编程技巧:Phi-4-mini-reasoning解读内存管理与并发模型 1. 核心能力概览 Phi-4-mini-reasoning作为新一代代码理解模型,在C高性能编程领域展现出令人印象深刻的分析能力。它能准确识别现代C中的复杂编程范式,特别是对以下关键技术的…...

XUnity.AutoTranslator:如何为Unity游戏实现免费实时翻译的完整指南
XUnity.AutoTranslator:如何为Unity游戏实现免费实时翻译的完整指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而无法享受优秀的Unity游戏?XUnity.Aut…...