【IDEA+Spark Streaming 3.4.1+Dstream监控套接字流统计WordCount保存至MySQL8】
【IDEA+Spark Streaming 3.4.1+Dstream监控套接字流统计WordCount保存至MySQL8】
把DStream写入到MySQL数据库中
- Spark 3.4.1
- MySQL 8.0.30
- sbt 1.9.2
文章目录
- 【IDEA+Spark Streaming 3.4.1+Dstream监控套接字流统计WordCount保存至MySQL8】
- 前言
- 一、背景说明
- 二、使用步骤
- 1.引入库
- 2.开发代码
- 运行测试
- 总结
前言
需要基于Spark Streaming 将实时监控的套接字流统计WordCount结果保存至MySQL
提示:本项目通过sbt控制依赖
一、背景说明
在Spark应用中,外部系统经常需要使用到Spark DStream处理后的数据,因此,需要采用输出操作把DStream的数据输出到数据库或者文件系统中
Spark Streaming是一个基于Spark的实时计算框架,它可以从多种数据源消费数据,并对数据进行高效、可扩展、容错的处理。Spark Streaming的工作原理有以下几个步骤:
- 数据接收:Spark Streaming可以从各种输入源接收数据,如Kafka、Flume、Twitter、Kinesis等,然后将数据分发到Spark集群中的不同节点上。每个节点上有一个接收器(Receiver)负责接收数据,并将数据存储在内存或磁盘中。
- 数据划分:Spark Streaming将连续的数据流划分为一系列小批量(Batch)的数据,每个批次包含一定时间间隔内的数据。这个时间间隔称为批处理间隔(Batch Interval),可以根据应用的需求进行设置。每个批次的数据都被封装成一个RDD,RDD是Spark的核心数据结构,表示一个不可变的分布式数据集。
- 数据处理:Spark Streaming对每个批次的RDD进行转换和输出操作,实现对流数据的处理和分析。转换操作可以使用Spark Core提供的各种函数,如map、reduce、join等,也可以使用Spark Streaming提供的一些特殊函数,如window、updateStateByKey等。输出操作可以将处理结果保存到外部系统中,如HDFS、数据库等。
- 数据输出:Spark Streaming将处理结果以DStream的形式输出,DStream是一系列连续的RDD组成的序列,表示一个离散化的数据流。DStream可以被进一步转换或输出到其他系统中。
DStream有状态转换操作是指在Spark Streaming中,对DStream进行一些基于历史数据或中间结果的转换,从而得到一个新的DStream。
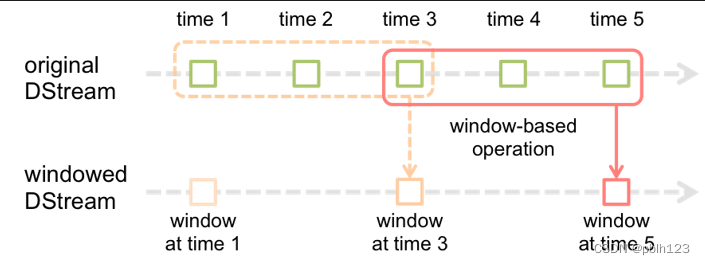
二、使用步骤
1.引入库
ThisBuild / version := "0.1.0-SNAPSHOT"ThisBuild / scalaVersion := "2.13.11"lazy val root = (project in file(".")).settings(name := "SparkLearning",idePackagePrefix := Some("cn.lh.spark"),libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.1",libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.1",libraryDependencies += "org.apache.hadoop" % "hadoop-auth" % "3.3.6",libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.4.1",libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.4.1",libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.4.1" % "provided",libraryDependencies += "mysql" % "mysql-connector-java" % "8.0.30"
)2.开发代码
为了实现通过spark Streaming 监控控制台输入,需要开发两个代码:
- NetworkWordCountStatefultoMysql.scala
- StreamingSaveMySQL8.scala
NetworkWordCountStatefultoMysql.scala
package cn.lh.spark import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} object NetworkWordCountStatefultoMysql { def main(args: Array[String]): Unit = { // 定义状态更新函数 val updateFunc = (values: Seq[Int], state: Option[Int]) => { val currentCount = values.foldLeft(0)(_ + _) val previousCount = state.getOrElse(0) Some(currentCount + previousCount) } // 设置log4j日志级别 StreamingExamples.setStreamingLogLevels() val conf: SparkConf = new SparkConf().setAppName("NetworkCountStateful").setMaster("local[2]") val scc: StreamingContext = new StreamingContext(conf, Seconds(5)) // 设置检查点,具有容错机制 scc.checkpoint("F:\\niit\\2023\\2023_2\\Spark\\codes\\checkpoint") val lines: ReceiverInputDStream[String] = scc.socketTextStream("192.168.137.110", 9999) val words: DStream[String] = lines.flatMap(_.split(" ")) val wordDstream: DStream[(String, Int)] = words.map(x => (x, 1)) val stateDstream: DStream[(String, Int)] = wordDstream.updateStateByKey[Int](updateFunc) // 打印出状态 stateDstream.print() // 将统计结果保存到MySQL中 stateDstream.foreachRDD(rdd =>{ val repartitionedRDD = rdd.repartition(3) repartitionedRDD.foreachPartition(StreamingSaveMySQL8.writeToMySQL) }) scc.start() scc.awaitTermination() scc.stop() } }
StreamingSaveMySQL8.scala
package cn.lh.spark import java.sql.DriverManager object StreamingSaveMySQL8 { // 定义写入 MySQL 的函数 def writeToMySQL(iter: Iterator[(String,Int)]): Unit = { // 保存到MySQL val ip = "192.168.137.110" val port = "3306" val db = "sparklearning" val username = "lh" val pwd = "Lh123456!" val jdbcurl = s"jdbc:mysql://$ip:$port/$db" val conn = DriverManager.getConnection(jdbcurl, username, pwd) val statement = conn.prepareStatement("INSERT INTO wordcount (word,count) VALUES (?,?)") try { // 写入数据 iter.foreach { wc => statement.setString(1, wc._1.trim) statement.setInt(2, wc._2.toInt) statement.executeUpdate() } } catch { case e:Exception => e.printStackTrace() } finally { if(statement != null){ statement.close() } if(conn!=null){ conn.close() } } } }运行测试
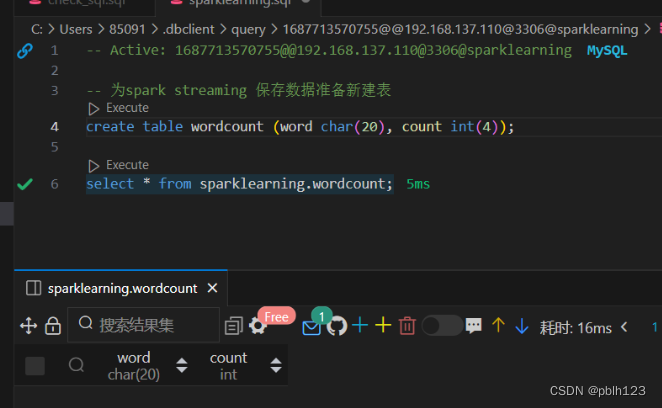
准备工作:
-
提前在mysql中新建数据表保存Spark Streaming写入的数据
-
启动nc -lk 9999

-
启动 NetworkWordCountStatefultoMysql.scala
![[Pasted image 20230804214904.png]]
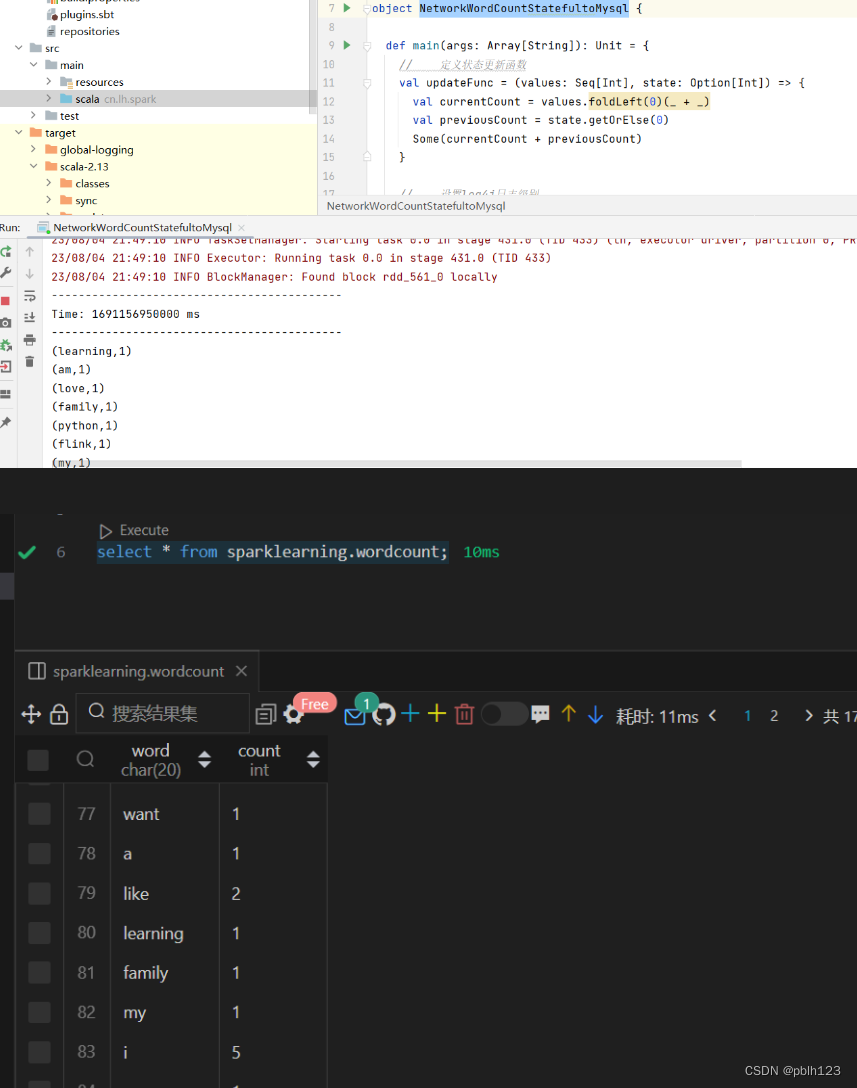
-
在nc端口输入字符,再分别到idea控制台和MySQL检查结果
总结
本次实验通过IDEA基于Spark Streaming 3.4.1开发程序监控套接字流,并统计字符串,实现实时统计单词出现的数量。试验成功,相对简单。
后期改善点如下:
- 通过配置文件读取mysql数据库相应的配置信息,不要写死在代码里
- 写入数据时,sql语句【插入的表信息】,可以在调用方法时,当作参数输入
- iter: Iterator[(String,Int)] 应用泛型
- 插入表时,自动保存插入时间
欢迎各位开发者一同改进代码,有问题有疑问提出来交流。谢谢!
相关文章:
【IDEA+Spark Streaming 3.4.1+Dstream监控套接字流统计WordCount保存至MySQL8】
【IDEASpark Streaming 3.4.1Dstream监控套接字流统计WordCount保存至MySQL8】 把DStream写入到MySQL数据库中 Spark 3.4.1MySQL 8.0.30sbt 1.9.2 文章目录 【IDEASpark Streaming 3.4.1Dstream监控套接字流统计WordCount保存至MySQL8】前言一、背景说明二、使用步骤1.引入库2…...

Dcat Admin 入门应用指南
在现代的网络应用开发中,管理后台是不可或缺的一部分。它为开发者提供了一个方便管理和监控应用数据的界面。而 Dcat Admin 是一个强大的管理后台框架,它基于 Laravel 框架开发,提供了丰富的功能和灵活的扩展性。本文将带您深入了解 Dcat Adm…...

计算机视觉:替换万物Inpaint Anything
目录 1 Inpaint Anything介绍 1.1 为什么我们需要Inpaint Anything 1.2 Inpaint Anything工作原理 1.3 Inpaint Anything的功能是什么 1.4 Segment Anything模型(SAM) 1.5 Inpaint Anything 1.5.1 移除任何物体 1.5.2 填充任意内容 1.5.3 替换任…...
AWS——01篇(AWS入门 以及 AWS之EC2实例及简单实用)
AWS——01篇(AWS入门 以及 AWS之EC2实例及简单实用) 1. 前言2. 创建AWS账户3. EC23.1 启动 EC2 新实例3.1.1 入口3.1.2 设置名称 选择服务3.1.3 创建密钥对3.1.4 网络设置——安全组3.1.4.1 初始设置3.1.4.2 添加安全组规则(开放新端口&…...
Clickhouse 优势与部署
一、clickhouse简介 1.1clickhouse介绍 ClickHouse的背后研发团队是俄罗斯的Yandex公司,2011年在纳斯达克上市,它的核心产品是搜索引擎。我们知道,做搜索引擎的公司营收非常依赖流量和在线广告,所以做搜索引擎的公司一般会并行推…...

全球数据泄露事件增加近三倍
网络安全公司 Surfshark 的最新研究显示,2023 年第二季度共有 1.108 亿个账户遭到泄露,其中美国排名第一,几乎占 4 月至 6 月所有泄露事件的一半。 俄罗斯排名第二,西班牙排名第三,其次是法国和土耳其。 与 2023 年…...

【雕爷学编程】 MicroPython动手做(38)——控制触摸屏2
MixPY——让爱(AI)触手可及 MixPY布局 主控芯片:K210(64位双核带硬件FPU和卷积加速器的 RISC-V CPU) 显示屏:LCD_2.8寸 320*240分辨率,支持电阻触摸 摄像头:OV2640,200W像素 扬声器&#…...
钉钉微应用
钉钉微应用 在做钉钉微应用开发的时候,遇到了一些相关性的问题,特此记录下,有遇到其他问题的,欢迎一起讨论 调试工具 当我们基于钉钉开发微应用时,难免会遇到调用钉钉api后的调试,这个时候可以安装eruda…...

【 SpringSecurity】第三方认证方法级别安全
文章目录 SpringSecurity 第三方认证实现方法级别的安全 SpringSecurity 第三方认证 在登录网页时,时常有用其他账号登录的方式,它们能够让用户避免在Web站点特定的登录页上自己输入凭证信息。这样的Web站点提供了一种通过其他网站(如Facebo…...
达梦数据库在windows上的安装
前言 简单记录达梦数据库DM7在windows10上的安装过程 1 下载并安装安装包 官网登录后才能下载,建议先注册账户。 下载地址:产品下载-达梦数据 ,CPU选择x86,操作系统选择win64即可。解压安装包后,一路安装下去即可。…...
新手Vite打包工具的使用并解决yarn create vite报错
一、手动创建 1.创建vite-Demo文件夹 2.初始化 yarn init -y 3.安装vite yarn add -D vite 4.打包准备 说明:不需要在src下面创建,在vite-Demo文件夹创建 4.1index.js文件 document.body.insertAdjacentHTML("beforeend","<h1>…...
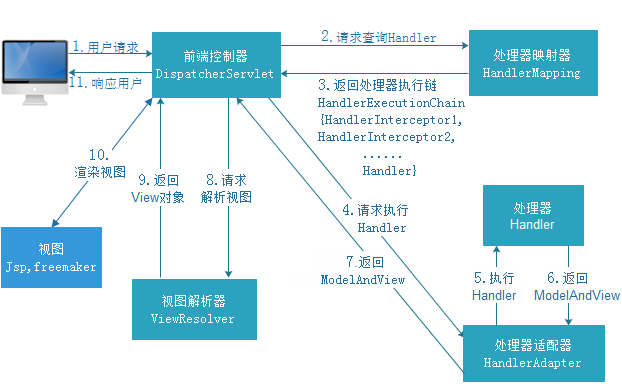
SpringMVC框架——First Day
目录 三层架构 MVC模型 SpringMVC 快速入门案例 SpringMVC的概述(了解) SpringMVC在三层架构的位置 SpringMVC的优势(了解) 创建SpringMVC的Maven项目 1.在pom.xml中添加所需要的jar包 2.在工程的web.xml中配置核心Spring…...

基于C++雪花算法工具类Snowflake -来自chatGPT
#include <iostream> #include <chrono> #include <stdexcept>class Snowflake { private:// 雪花算法的各个参数static constexpr int64_t workerIdBits 5;static constexpr int64_t datacenterIdBits 5;static constexpr int64_t sequenceBits 12;stati…...

若依打印sql
官方issue 自动生成的代码,sql日志怎么没有打印 在ruoyi-admin中的application.yml配置如下。 # 日志配置,默认 logging:level:com.ruoyi: debugorg.springframework: warn#添加配置com.ying: debug输出sql...

Camunda BPM Run下载(7.20)
官网地址: https://camunda.com/ 中文站点:http://camunda-cn.shaochenfeng.com https://downloads.camunda.cloud/release/camunda-bpm/run/7.20/https://downloads.camunda.cloud/release/camunda-bpm/run/7.20/camunda-bpm-run-7.20.0-alpha3.ziphttps://downloads.camunda…...

【Ubuntu】Ubuntu 22.04 升级 OpenSSH 9.3p2 修复CVE-2023-38408
升级原因 近日Openssh暴露出一个安全漏洞CVE-2023-38408,以下是相关资讯: 一、漏洞详情 OpenSSH是一个用于安全远程登录和文件传输的开源软件套件。它提供了一系列的客户端和服务器程序,包括 ssh、scp、sftp等,用于在网络上进行…...

【知网检索】2023年金融,贸易和商业管理国际学术会议(FTBM2023)
随着经济全球化,贸易自由化的进程加快,我国经济对外开放程度不断加深,正在加快融入世界经济一体化当中。当今世界各国竞争过程中,金融、贸易以及商业形态已成为其关键与焦点竞争内容。 2023年金融、贸易和商业管理国际学术会议(F…...
数据可视化:Matplotlib详解及实战
1 Matplotlib介绍 Matplotlib是Python中最常用的可视化工具之一,可以非常方便地创建海量类型的2D图表和一些基本的3D图表。 Matplotlib提供了一个套面向绘图对象编程的API接口,能够很轻松地实现各种图像的绘制,并且它可以配合Python GUI工具(…...

Flutter flutter_boost 集成
刚开始接触使用flutter boost路由的心得体会记录如下: Fltter项目部分: 第一步 在Flutter项目的 pubspec.yaml文件中添加如下信息: flutter_boost:git:url: https://github.com/alibaba/flutter_boost.gitref: 4.3.0之后在flutter工程下运…...

Stable Diffusion中人物生成相关的negative prompts
下面是常用的negative prompt,在使用stable Diffusion webui等工具生成时可以填入。 bad anatomy, bad proportions, blurry, cloned face, deformed, disfigured, duplicate, extra arms, extra fingers, extra limbs, extra legs, fused fingers, gross proporti…...

JIT启用后CPU飙升200%?PHP 8.9生产环境避坑指南,含8类典型误配置清单
第一章:PHP 8.9 JIT 的核心机制与性能悖论PHP 8.9 并非官方发布的正式版本(截至 PHP 官方最新稳定版为 8.3),该标题中的 “8.9” 是一个假设性技术前瞻设定,用于探讨 JIT 编译器在 PHP 生态中持续演进所引发的底层机制…...

一文吃透 TDengine:对比主流时序库、核心语法与避坑指南
前言在物联网、工业监控、车联网、能源等场景,时序数据(时间戳 指标 标签)的规模动辄亿级测点、万亿行数据,传统数据库与通用时序库往往陷入 “写不动、查不动、存不起” 的困境。TDengine(涛思数据库)凭…...

高速数字电路中的信号抖动与眼图优化
1. 信号抖动与眼图基础解析在高速数字电路设计中,信号完整性问题往往表现为"信号抖动"和"眼图劣化"这两个直观现象。信号抖动(Jitter)本质上是指数字信号边沿相对于理想时序位置的偏差,这种时间上的不确定性会…...

OpenClaw低代码开发:Qwen3-32B镜像+RTX4090D快速原型设计
OpenClaw低代码开发:Qwen3-32B镜像RTX4090D快速原型设计 1. 为什么选择这个技术组合? 去年冬天的一个深夜,我盯着屏幕上重复执行的测试脚本,突然意识到自己正在把宝贵的时间浪费在机械操作上。作为独立开发者,我们常…...

Qwen3-14B实际作品集展示:技术文档生成、营销文案创作、教学问答案例
Qwen3-14B实际作品集展示:技术文档生成、营销文案创作、教学问答案例 1. 开篇介绍 今天我要带大家看看Qwen3-14B这个强大的AI模型在实际工作中的表现。这个模型经过专门优化,可以轻松部署在RTX 4090D显卡上,24GB显存让它运行起来特别流畅。…...

Docker 容器中运行 AI CLI 工具:用户隔离与持久化卷实战指南暗
环境安装 pip install keystone-engine capstone unicorn 这3个工具用法极其简单,下面通过示例来演示其用法。 Keystone 示例 from keystone import * CODE b"INC ECX; ADD EDX, ECX" try:ks Ks(KS_ARCH_X86, KS_MODE_64)encoding, count ks.asm(CODE)…...
——资深SRE连夜重写配置手册)
PHP AI校验配置被低估的致命细节(内存泄漏触发点、AST解析偏差、Token限流阈值)——资深SRE连夜重写配置手册
第一章:PHP AI校验配置的全局认知与风险图谱PHP AI校验配置并非孤立的技术模块,而是横跨应用层、中间件、模型服务与基础设施的复合型安全控制面。其核心目标是在AI能力注入业务流程的同时,确保输入合法性、输出可控性、行为可审计及策略可收…...

Google 迎来「DeepSeek 时刻」:TurboQuant算法实现bit无损、×加速、×压缩、零预处理范
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...

从0到1构建一个ClaudeAgent-工具与执行-Agent循环
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

OpCore Simplify:黑苹果EFI配置效率提升80%的自动化方案 | 全层次用户指南
OpCore Simplify:黑苹果EFI配置效率提升80%的自动化方案 | 全层次用户指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 问题࿱…...