Flink 系列四 Flink 运行时架构
目录
前言
介绍
1、程序结构
1.1、Source
1.2、Transformation
1.3、Sink
1.4、数据流
2、Flink运行时组件
2.1、Dispatcher
2.2、JobManager
2.3、TaskManager
2.4、ResourceManager
3、任务提交流程
3.1、standalone 模式
3.2、yarn 模式
4、任务调度原理
4.1、并行度
4.1.1、概念
4.4.2、Flink中的并行度设置
4.2、TaskManager 与 Slots
4.2.1、概念
4.2.2、Slot
4.2.3、Slot与TaskManager关系
4.2.4、并行度和Slot的关系
4.3、执行图
4.3.1、Flink执行图
4.3.2、数据传输形式
4.3.3、任务链

前言
Flink 是一个用于流处理和批处理的开源分布式计算框架。它的运行时架构包括以下几个关键组件:
-
JobManager:JobManager 是 Flink 的控制节点,负责接收、解析并编排用户提交的作业。它负责作业的调度、容错和资源管理等任务。
-
TaskManager:TaskManager 是 Flink 的工作节点,负责执行作业中的任务。每个 TaskManager 可以运行一个或多个任务,一个任务由一个或多个线程组成。TaskManager 与 JobManager 之间通过消息传递进行通信。
-
JobGraph:JobGraph 是用户提交的作业被解析后的内部表示,它描述了作业的拓扑结构、任务之间的依赖关系和转换操作。
-
TaskSlots:TaskSlots 是 TaskManager 的执行资源,用于并行执行作业的任务。每个 TaskManager 拥有一定数量的 TaskSlots,可以在不同的作业任务之间共享。
-
DataStream 和 DataSet:Flink 支持两种不同的计算模型,即 DataStream 和 DataSet。DataStream 是无边界的连续数据流模型,适用于实时流处理;DataSet 是有边界的离散数据集模型,适用于批处理。
-
State Backend:State Backend管理Flink应用程序的状态(如键值对状态、操作符状态等),并将其持久化到可插拔的后端存储(如内存、文件系统、RocksDB 等)中,以实现容错和恢复功能。
这些组件相互配合,构成了 Flink 运行时架构,能够支持高效且容错的流处理和批处理应用程序的执行。
介绍
1、程序结构
在学习Flink的运行时架构之前先看下Flink的程序结构。Flink程序的基本构建块是流和转换,流是数据记录流(理论上流是无限的),转换是将一个或多个流作为输入并输出一个或多个流。所有的转换称为算子,流就是连接这些算子的桥梁。总的来说Source负责读取数据,Transformation利用各种算子对数据进行加工,Sink负责输出。
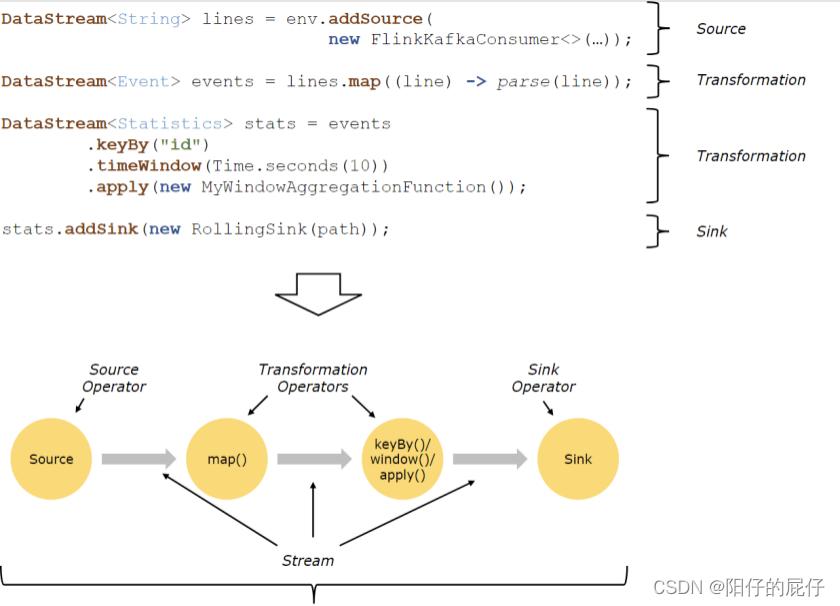
1.1、Source
在FlinK中,只有输出流的算子被定义为数据源,Flink在流或者批处理上大概有4类source。
1、基于本地集合的 source
2、基于文件的 source
3、基于网络套接字的 source
4、自定义的 source(自定义的 source 常见的有 Apache kafka、RabbitMQ 、mysql、redis、es 等等)
1.2、Transformation
在Flink中,接收数据流进行处理之后产生输出流的算子被定义为转换,通过数据转换的各种操作,可以将数据转换计算成你想要的数据。Flink定义了丰富的API可以进行各种复杂的转换,转换算子包含:Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select等等
1.3、Sink
数据流经过了各种转换计算之后,通过接收器将结果数据发送到相应的存储介质或者其他的响应的算子叫做Sink。在Flink中的Sink可以有以下定义。
1、写入文件
2、打印出来
3、写入 socket
4、自定义的 sink(自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等等)
1.4、数据流
1、在程序运行时Flink上运行的程序会被映射成逻辑数据流(DataFlow),就是上面咱们了解到的三大块,DataFlow就是一个有向无环图(DAG)。
2、大部分情况下,程序中的转换运算(transformations)和DataFlow的算子都是一一对应的。

2、Flink运行时组件
Flink的运行时架构主要包含4个组件,分别是:作业管理器(JobManager)、任务管理器(TaskManager)、资源管理器(ResourceManager)以及分发器(Dispatcher),因为Flink使用Java和Scale实现的,所以所有的组建都会运行在Java虚拟机上。
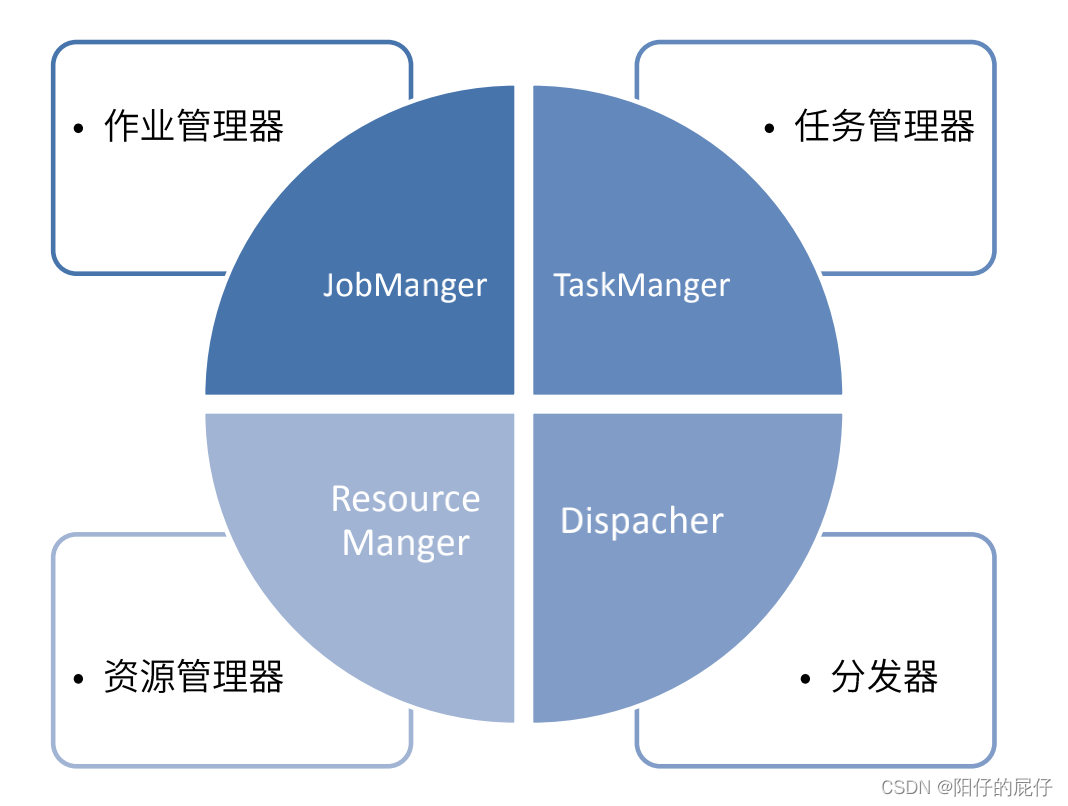
2.1、Dispatcher
分发器为任务的提交提供了一个Rest接口,Dispatcher会启动一个WebUI用来方便的提交作业、展示和监控作业执行的信息。Dispatcher在架构中不是必须的,取决于作业的提交运行方式(例如Yarn架构中就不需要该组件)。
2.2、JobManager
作业管理器,控制一个应用程序执行的主进程,即每个应用程序都会被一个不同的JobManager 所控制执行。JobManager在Flink应用程序执行中有一下几个步骤:
1、首先接收到要执行的应用程序,该应用程序包括(作业图(JobGraph)、逻辑数据流图(logical dataflow graph),和打包了所有的类、库以及其他资源的jar包)。
2、将作业图(JobGraph)转换成物理执行图(ExecutionGraph),物理执行图包含了所有并发执行的任务。
3、JobManager会根据物理执行图的任务并行度向资源管理器申请资源(ResourceManager)插槽(slot)。
4、申请到资源之后就根据执行图将任务分发到真正执行的任务管理器(TaskManager)执行。
5、在应用运行的过程中,JobManager会负责各种协调工作,比如全局检查点的协调(CheckPoint)。
2.3、TaskManager
任务管理器是Flink中的工作进程,通常Flink中会有多个TaskManager并行运行,每个TaskManager中包含了多个插槽(slot),插槽的数量,就是应用的任务并行度。
1、应用启动之后TaskManager会向资源管理器注册他所拥有的插槽。
2、JobManager提交了任务之后,ResourceManager会分配1个或多个插槽给JobManager执行调用,真正执行任务。
3、在执行过程中TaskManager可以跟其他的同一应用的TaskManager交换数据。
2.4、ResourceManager
资源管理器,主要负责任务管理器的插槽的管理。TaskManager的插槽是Flink中定义的处理资源的单元。Flink为同的环境和资源管理工具提供了不同的资源管理器,比如在Standalone模式中,当JobManager申请资源时,若没有足够的slot就会等待超时并取消掉其他的任务。但是在yarn、k8s等部署模式中,当ResourceManager没有足够的资源时,他还可以向资源提供平台发起会话申请足够的资源,以启动TaskManager的容器。并且他还负责将空闲的TaskManager进行回收释放计算资源。
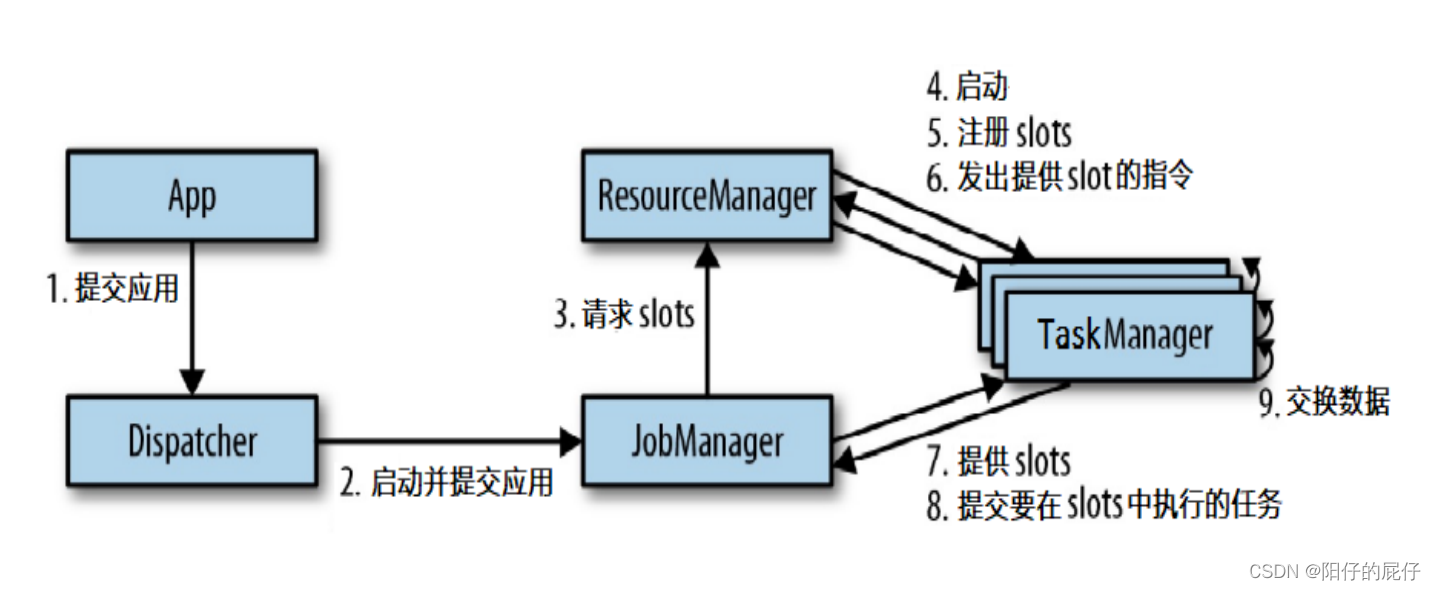
3、任务提交流程
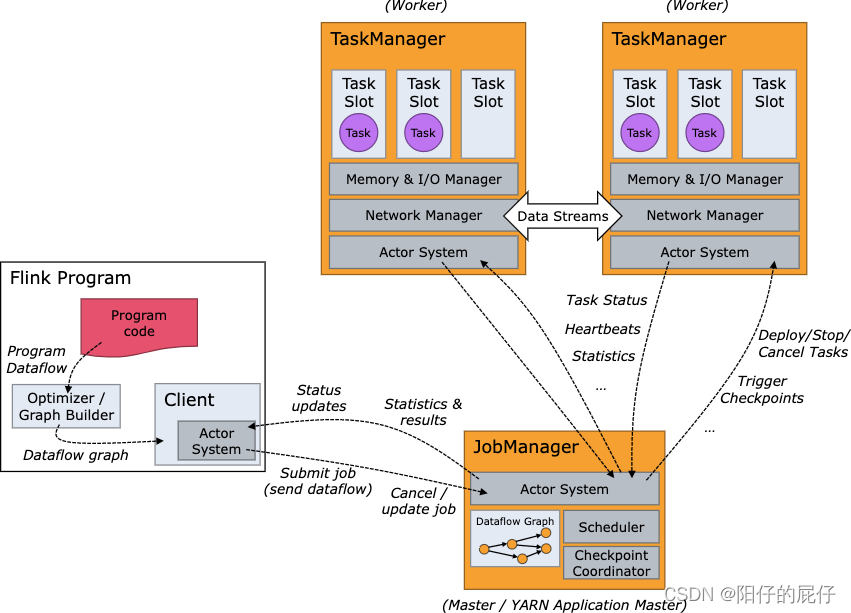
了解了Flink运行中的一些重要组件,我们看一下Flink在运行中作业提交的交互流程。下面的这幅图是一个整体的作业提交分发、申请资源以及调度执行的任务提交流程。在不同的部署模式下任务的提交流程稍有不同。
3.1、standalone 模式
通常在我们进行测试或者本地开发的时候会部署使用该模式进行调试,下面是standalone的任务提交流程。

独立集群至少需要两个进程,一个主进程负责管理Dispatcher和ResourceManager,另一个进程主要负责管理TaskManager。主进程会为Dispatcher和ResourceManager创建独立的线程来运行,TaskManager也是需要注册到ResourceManager,在JobManager申请资源的时候被ResourceManager分配。
3.2、yarn 模式
Yarn 是 Apache hadoop的资源管理组件,他负责管理集群下的资计算资源(主要是集群的CPU和内存)。Flink 在Yarn模式上部署的话有两种方式:作业模式(Job Mode)和会话模式(session Mode)。yarn的两种部署方式区别就是作业模式下一个Job提交就会启动一个集群,这个集群就单独运行一个作业,一旦作业结束集群就会停止,全部资源就会释放。而会话模式就是创建一个长时间运行的集群,等着作业提交分配资源执行,该模式下可以运行多个作业。
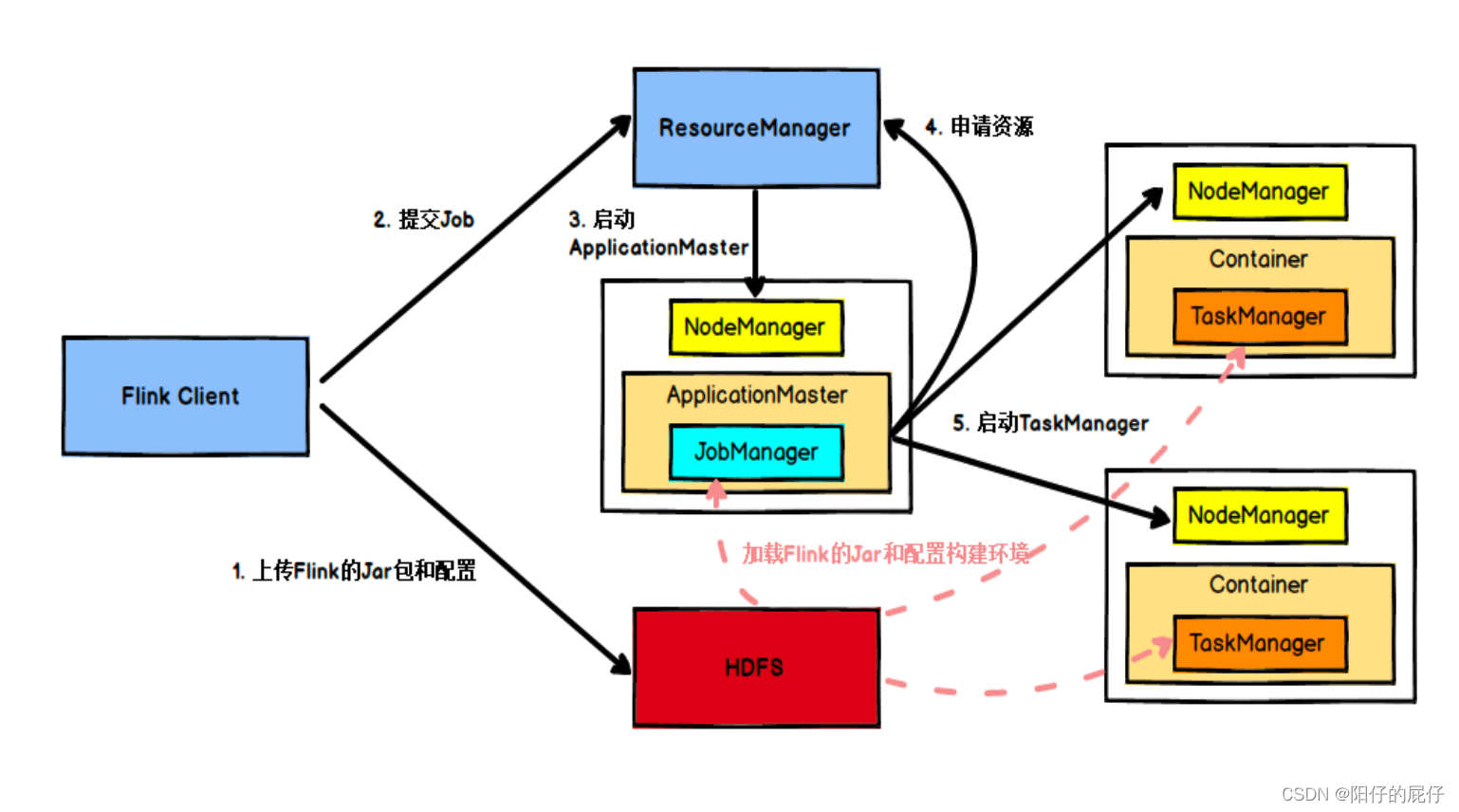
1、Flink的Client提交Jar包和配置文件上传到HDFS,以便JobManager和TaskManager共享这些数据。
2、Client提交作业到Yarn的ResourceManager,Yarn的ResourceManager接收到Flink作业之后启动分配congainer资源然后通知NodeManager启动一个ApplicationMaster。
3、ApplicationMaster会先加载1上传到HDFS上的资源启动Flink的JobManager和ResourceManager。
4、JobManager会分析作业中的流图进而转化为可执行图(包含了可并行的任务),并计算出需要的slot。
5、JobManager会先从Flink的ResourceManager申请资源,此时还没有资源可用,Flink的ResourceManager就会向上从Yarn集群的资源管理器申请资源。
6、Yarn资源管理器会根据需要的资源分配Container并通知NodeManager会加载HDFS上1时候的资源并启动Flink的TaskManager并向Yarn的资源管理器和Flink的资源管理器注册资源。并且向JobManager发送心跳包。
7、JobManager获得了足够的资源之后就将分解之后的任务发送至TaskManager 执行。
8、在次过程中JobManager协调全局的工作,比如进行检查点的保存等等。
4、任务调度原理
Flink的任务调度原理就是从我们写的代码开始打包提交到Flink集群转换到真正执行的过程。
1、首先我们写的代码进行编译打包就是按照代码定义从程序流图转换为数据流图(StreamGraph / DataFlow Graph)。
2、Client(可以是命令行或者WebUI)提交的时候将数据流图进行合并(DataFlow Graph -> JobFraph)并提交给JobManager。
3、JobManager接收到JobFraph之后经过分析在将JobFraph进行并行拆分生成执行图(JobGraph -> executionGraph)
4、JobManager根据最后的物理执行图去ResourceManager申请对应的资源,并且将作业分配给Taskmanager执行。
5、TaskManager实时的将统计信息、心跳信息等信息同步给JobManager。
上图中我们可以看到JobManager申请到两个TaskManager的资源执行任务,并且每个TaskManager有3个插槽,我们能看出来整个集群的并行度是6,但是我们作业的并行度是4。
这里看到上图肯定几个问题需要确认
1、Flink中是怎么实现并行的?
2、并行的任务需要占用多少个Slot?
3、一个流程序包含了多少个任务?
4.1、并行度
对于上面遗留的问题:1、Flink中是怎么实现并行的?,首先要了解的就是Flink中定义的并行度的概念。
4.1.1、概念
一个特定的算子的自任务的个数就是该算子的并行度(parallelism)。一般情况下一个流的并行度就是该流中所有算子中含有最大并行度的算子的并行度。
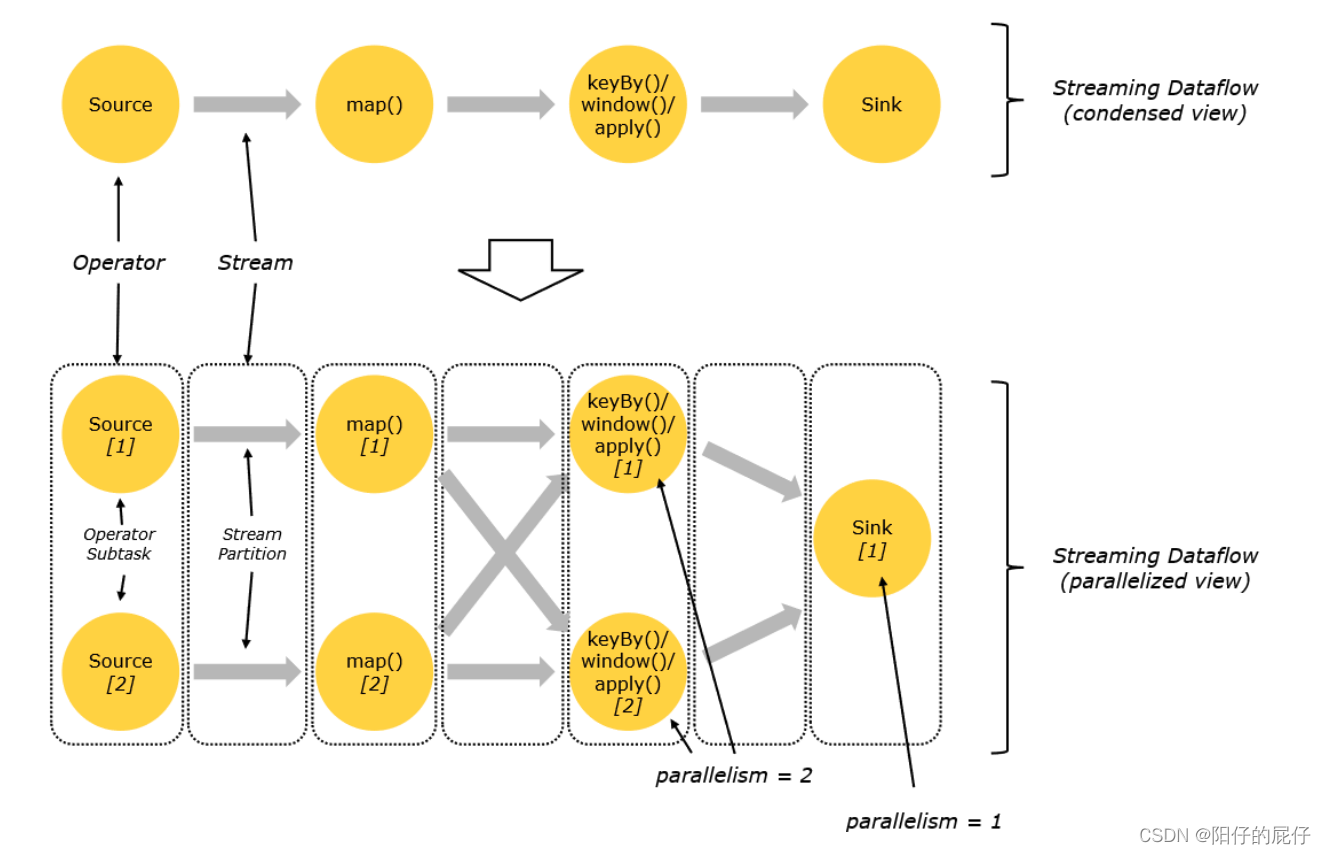
上图中是JobManager按照设置的并行度划分的数据流图,其中Sink的并行度设置为1,其他的算子的并行度设置为2。 按照定义我们可以知道整个流的并行度应该是2,并且只要有至少一个或者多个TaskManager可以提供至少2个Slot就可以部署执行该任务。
4.4.2、Flink中的并行度设置
上图中的并行度怎么设置的呢,在Flink中可以有三种方式设置并行度:
1、全局设置
env.setParallelism(1);2、算子纬度设置
flatMap(new GpsConstructionTimeFlatMapFunction()).setParallelism(2)3、默认配置
# 程序默认并行计算的个数 parallelism.default: 1三种设置方式的优先级:算子纬度 > 全局纬度 > 默认配置
4.2、TaskManager 与 Slots
对于上面遗留的问题2:并行的任务需要占用多少个Slot?需要先了解下Slot资源。
4.2.1、概念
1、Flink每个TaskManager都是一个独立的JVM进程,可以执行一个线程或多个线程。
2、为了控制一个TaskManager可以接收多个任务,TaskManager通过taskSlot资源来进行控制。每个slot可以认为是一块独立的内存。
4.2.2、Slot
默认情况下Flink中的Slot是可以共享的,即使他们是不同任务的子任务,这样做的好处就是既可以节省资源又可以保证一个slot可以保存作业的整个管道,减少网络交互。
4.2.3、Slot与TaskManager关系
slot是一个静态的概念,指的是TaskManager具有的并发能力。
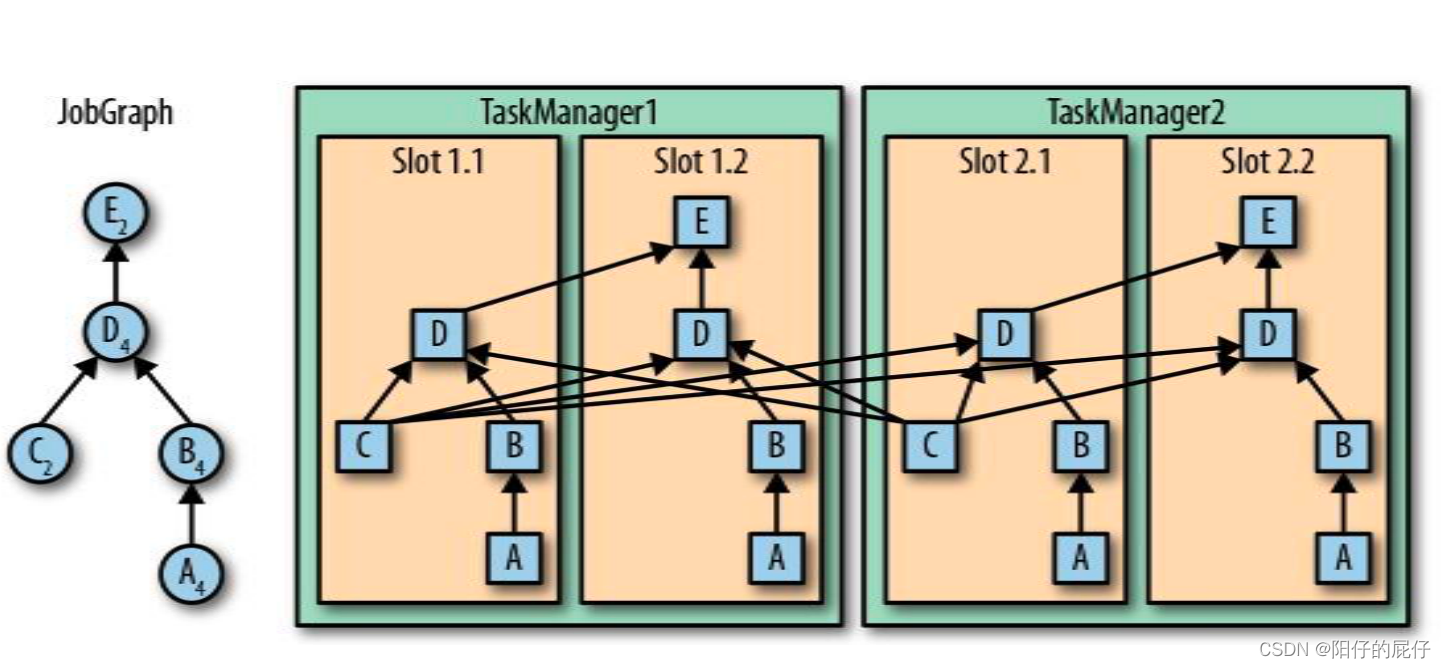
上图就是一个数据并行和任务并行并共享slot的一个执行图。
1、首先作业执行图分为5个任务
1.1、A和C分别是并行度为4和2的Source。
1.2、B是并行度为4的转换算子。
1.3、D是一个并行度为4的转换算子。
1.4、E是并行度为2的Sink算子。
2、我们可以看到右图就是转换之后的实际的物理执行图,有两个并行能力为2的TaskManager就说明咱们的集群的并行度可以支撑为4的并行度的作业。
2.1、Source A分布在4个Slot中,Source C分布在Slot1.1和2.1中,转换算子B、D分布在4个Slot中,Sink算子分布在1.2、2.2的Slot中。
2.2、例如Slot的1.1中的算子B、C共享了一个Slot。他们都是属于不同的任务,这叫任务并行。
2.3、A算在分布在4分Slot中这叫做数据并行。
2.4、其中1.2和2.2的Slot保留有整合数据管道,即使其他的算子出了问题,这个算子内的数据也可以得到准确的输出。并且这两个Slot中的算子进行数据交换的时候不会进过网络提高了效率。
4.2.4、并行度和Slot的关系


4.3、执行图
4.3.1、Flink执行图
咱们在上面还遗留有一个问题:3、一个流程序包含了多少个任务?咱们要想知道有多少个任务就要知道Flink是怎么执行的。
Flink的执行图可以分为下面四个层级
Stream -> JobGraph -> ExecutionGraph -> 物理执行图
1、StreamGraph:程序流图,用来表示开发者使用API开发的程序拓扑结构。
2、JobGraph:StreamGraph在提交到JobManager的时候会进行一次优化,将可以合并的算子进行合并,将多个符合条件的节点chain在一起成为一个执行节点。
3、ExecutionGraph:JobManager 将JobGraph根据并行度拆分成并行的任务,到了这一步就是调度层最核心的数据结构。
4、物理执行图:JobManager 将ExecutionGraph部署到实际的TaskManager的Slot上进行执行的物理图。
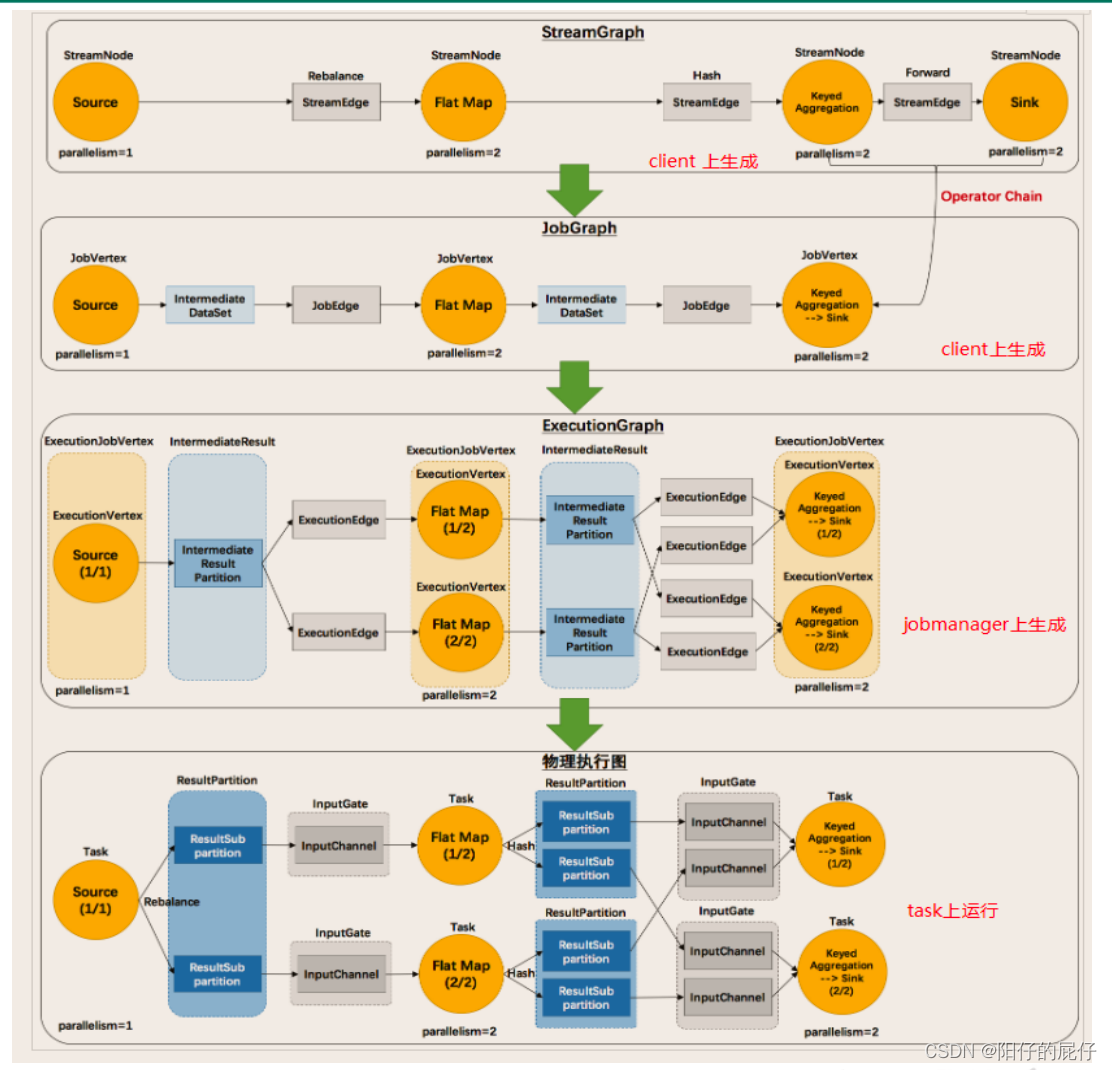
在了解了上面Flink的执行图之后我们知道了我们编写的代码经过编译打包之后上传到Flink集群执行的整个过程,以及我们的任务是如何被拆分到对应的Slot上的,但是有个疑问点就是StreamGraph -> JobManager的时候,咱们怎么知道那些程序可以进行合并呢?那就是咱们要知道Flink中的数据传输形式和任务链。
4.3.2、数据传输形式
Flink中的数据传输主要分为两种形式:
1、one - to - one:Stream维护着分区和元素的顺序,例如并行度相同的source和map算子。这就意味着source和map算子任务看到的元素顺序和个数都是相同的,这类的算子任务都属于one - to - one的对应关系(如map、filter、flatMap等等)。
2、Redistributing:若Stream的分区发生变化,每个算子的子任务根据依据选择的transformation发送数据到不同的目标算子。比如keyBy操作是基于HashCode充分区,broastCast和reblance是随机分区。也比如基本转换算子中source(1) -> map(2)虽然他们都属于 one - to - one的关系但是因为下游的分区发生了变化,也会默认按照轮训的逻辑将数据传输到下游算子。
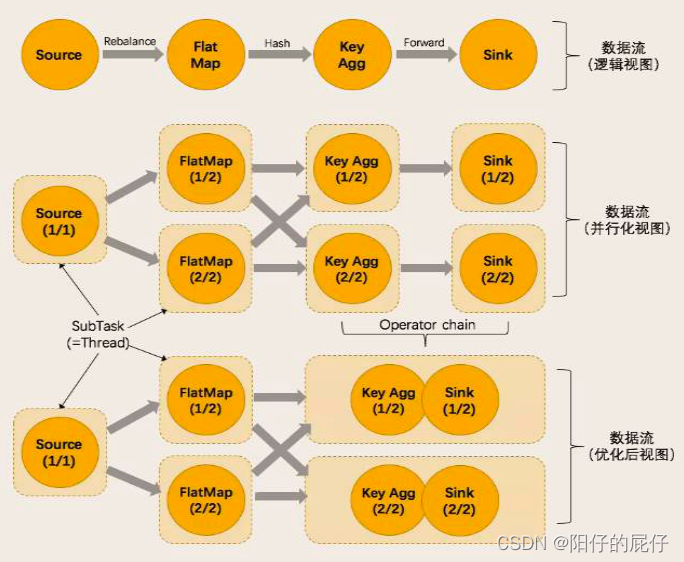
4.3.3、任务链
任务链是Flink采用的一种优化技术,可以在特定条件下减少本地开销。为了满足任务链的要求,上线游的算子必须满足
1、并行度相同。
2、必须是 one - to - one 的对应关系。
如下图:
1、source和FlapMap为设么不能合并因为并行度不同。
2、FlapMap和Key Agg 不能合并因为进行了keyBy。
3、Key Agg和Sink可以合并是因为满足相同的并行度并且是one - to - one的对应关系。
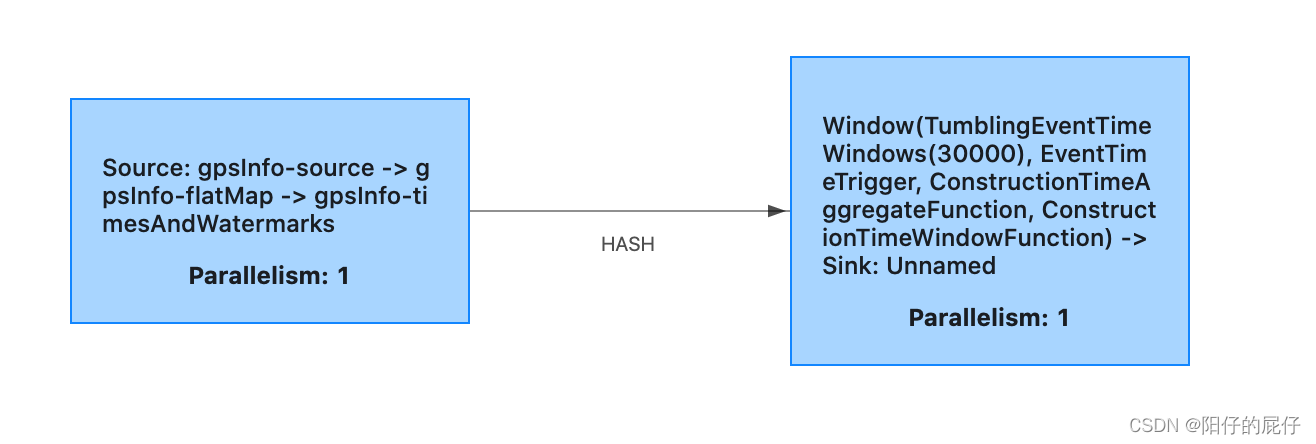
下图是我们线上执行的任务,因为设置水位线之后发生了keyBy操作所以不能合并,但是前面的source和FlatMap和设置水位线合并,开窗口和窗口聚合函数和Sink是同一个并行度并且是one - to - one操作,可以合并。
5、总结
好了我们关于Flink的运行时架构有了一个比较全面的认识和理解,我们系统学习了
1、Flink的代码编写结构和Flink中的数据流。
2、Flink运行时的4大组件。
3、Flink的集中部署方式,以及任务提交的交互流程。
4、Flink的任务调度原理,包括:任务的并行度概念和设置、任务执行的必要资源和资源的申请以及任务的提交流程过程中生成的执行图和任务执行过程中的数据传输形式以及Flink为了优化所生成的任务链。
基础概念讲解完毕,后续咱们就要开始API的介绍啦,敬请期待。
相关文章:
Flink 系列四 Flink 运行时架构
目录 前言 介绍 1、程序结构 1.1、Source 1.2、Transformation 1.3、Sink 1.4、数据流 2、Flink运行时组件 2.1、Dispatcher 2.2、JobManager 2.3、TaskManager 2.4、ResourceManager 3、任务提交流程 3.1、standalone 模式 3.2、yarn 模式 4、任务调度原理 4…...
14-3_Qt 5.9 C++开发指南_QUdpSocket实现 UDP 通信_UDP 单播和广播
文章目录 1.UDP通信概述2. UDP 单播和广播2.1 UDP 通信实例程序功能2.2 主窗口类定义和构造函数2.3 UDP通信的实现2.4 源码2.4.1 可视化UI设计2.4.2 mainwindow.h2.4.3 mainwindow.cpp 1.UDP通信概述 UDP(User Datagram Protocol,用户数据报协议)是轻量的、不可靠的…...
【知识图谱】图数据库Neo4jDesktop的安装图文详解(小白适用)
neo4j 的安装需要有jdk环境的支持。因此在安装Neo4j之前,需要安装Java JDK。 一.安装JDK 参考文章https://blog.csdn.net/weixin_41824534/article/details/104147067?spm1001.2014.3001.5502 二.Neo4j下载 进入Neo4j官网 选择下载中心 下滑选择Neo4j Deskto…...

kafka中幂等性producer和事务性producer
幂等性producer 在Kafka中,“幂等性生产者”的概念是指一种特性,它确保消息在生产者的发送操作被重试时仅发送一次。幂等性是一种重要的特性,因为在分布式系统中,网络问题或其他故障可能导致生产者发送的消息在传输过程中失败,从而需要重新发送。如果生产者没有幂等性保证…...
)
静态路由 (华为设备)
默认路由:当路由器 收到目标地址不在路由表中的数据包时,将会 全部 发送 到 默认路由所定义的吓一跳 ,作为位置地址 数据包的 最后求助方式,这就是默认路由器的功能,默认路由的使用,可以大大的节省系统资源…...
Django学习笔记-默认的用户认证系统(auth)
一、Django默认的用户认证系统 Django 自带一个用户验证系统。它负责处理用户账号、组、权限和基于cookie的用户会话。 Django 验证系统处理验证和授权。简单来说,验证检验用户是否是他们的用户,授权决定已验证用户能做什么。这里的术语验证用于指代这…...

[SQL挖掘机] - 存储过程
介绍: 当你在sql中需要多次执行相同的一组sql语句时,存储过程是一个非常有用的工具。它是一段预先定义好的sql代码块,可以被命名并保存在数据库中,以便重复使用。 存储过程可以包含多个sql语句、逻辑流程、条件判断和循环等,可以…...

MySQL8.0.32详细安装教程(奶妈级手把手教你安装)
MySQL安装详解 前言 对于无论是刚开始接触编程的小伙伴,还是有了几年工作经验的程序猿(程序媛)来讲,数据库的安装一直都是一个比 较复杂的过程,安装完成以后可能会记得一段时间,但是等到我们换了一台电脑或…...
glut太阳系源码修改和对cpu占用观察
#include <GL/glut.h> static int day 100; // day 的变化:从 0 到 359 void myDisplay(void) {//glEnable(GL_DEPTH_TEST);glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);glMatrixMode(GL_PROJECTION);glLoadIdentity();gluPerspective(75, 1, 1, 40…...

掌握NLTK:Python自然语言处理库中级教程
在之前的初级教程中,我们已经了解了NLTK(Natural Language Toolkit)的基本用法,如进行文本分词、词性标注和停用词移除等。在本篇中级教程中,我们将进一步探索NLTK的更多功能,包括词干提取、词形还原、n-gr…...

Go语言的崛起:探究越来越多公司选择Go语言的原因和优势
🌷🍁 博主猫头虎 带您 Go to Golang Language.✨✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~…...

MongoDB 6.0.8 安装配置
一、前言 MongoDB是一个基于分布式文件存储的数据库。由C语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。在高负载的情况下,添加更多的节点,可以保证服务器性能。 MongoDB 将数据存储为一个文档,数据结构由键值(key>value…...

无涯教程-Lua - nested语句函数
Lua编程语言允许在另一个循环中使用一个循环。以下部分显示了一些示例来说明这一概念。 nested loops - 语法 Lua中嵌套for循环语句的语法如下- for init,max/min value, increment dofor init,max/min value, incrementdostatement(s)endstatement(s) end Lua编程语言中的…...
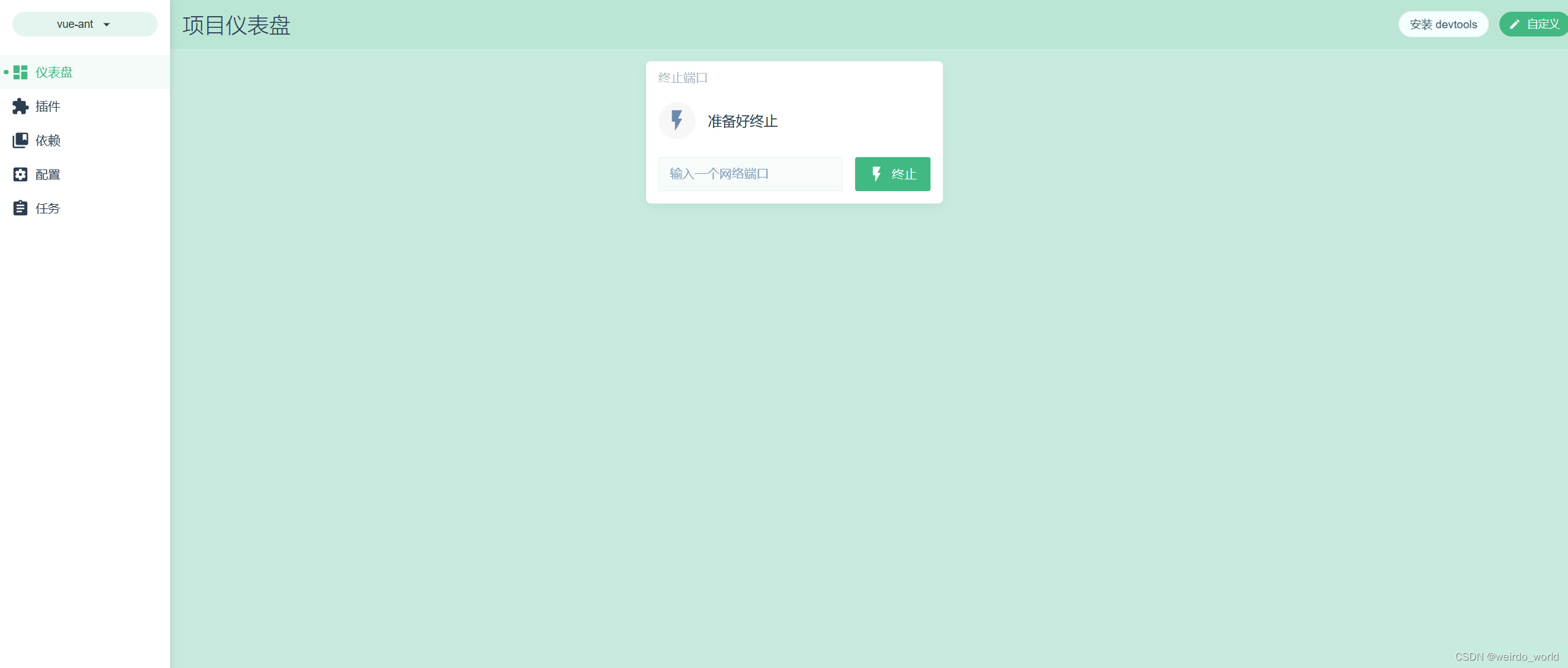
如何使用vue ui创建一个项目?
首先打开cmd 输入vue ui 等待浏览器打开一个窗口,按照下图操作 在"功能页面"中,各个插件代表以下意思: Babel:Babel是一个JavaScript编译器,用于将ES6代码转换为向后兼容的JavaScript版本,以确保…...
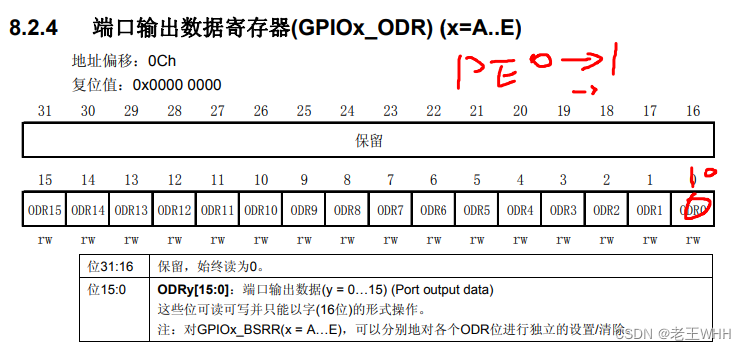
STM32——LED内容补充(寄存器点灯及反转的原理)
文章目录 点灯流程开时钟配置IO关灯操作灯反转宏定义最后给自己说 本篇文章使用的是STM32F103xC系列的芯片,四个led灯在PE2,PE3,PE4,PE5上连接 点灯流程 1.开时钟 2.配置IO口 (1)清零指定寄存器位 (2)设置模式为推挽输…...

使用Spring Boot和EasyExcel的导入导出
在当今信息化社会,数据的导入和导出在各种业务场景中变得越来越重要。为了满足复杂的导入导出需求,结合Java编程语言、Spring Boot框架以及EasyExcel库,我们可以轻松地构建出强大而灵活的数据处理系统。本文将引导您通过一个案例学习如何使用…...
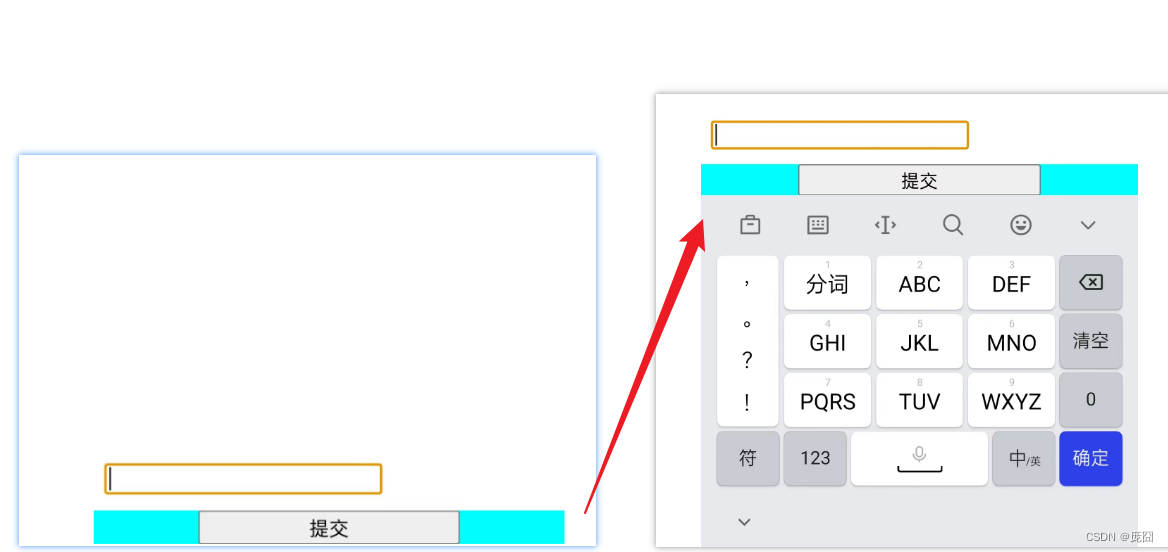
【H5移动端】常用的移动端方案合集-键盘呼起、全面屏适配、图片大小显示、300ms点击延迟、首屏优化(不定期补充~)
文章目录 前言键盘呼起问题靠近底部的输入项被键盘遮挡底部按钮被顶上去 全面屏适配图片大小显示问题解决300ms延迟首屏优化 前言 这篇文章总结了我在工作中做H5遇到的一些问题,包括我是怎么解决的。可能不是当下的最优解,但是能保证解决问题。 单位适…...
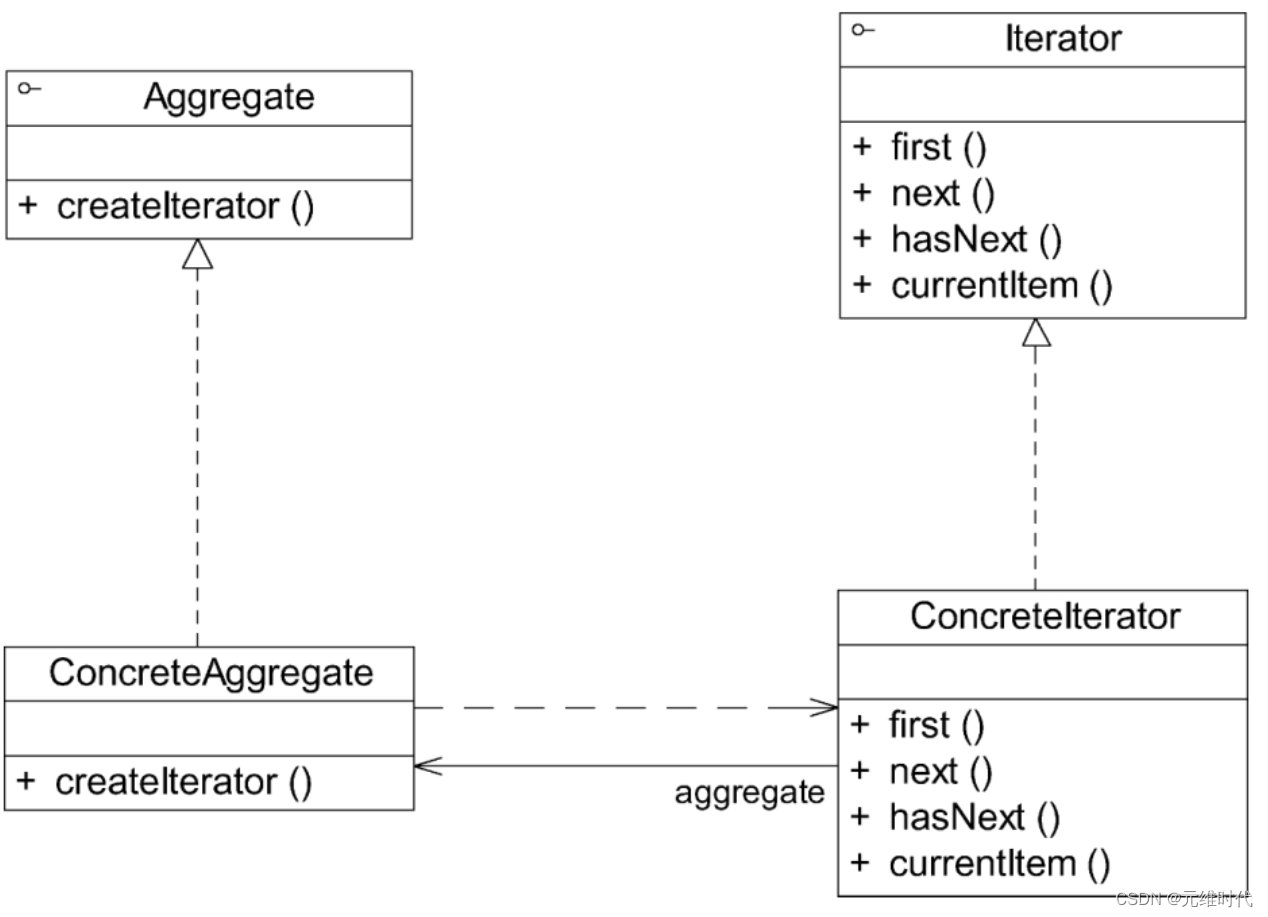
迭代器模式——遍历聚合对象中的元素
1、简介 1.1、概述 在软件开发时,经常需要使用聚合对象来存储一系列数据。聚合对象拥有两个职责:一是存储数据;二是遍历数据。从依赖性来看,前者是聚合对象的基本职责;而后者既是可变化的,又是可分离的。…...

亿赛通电子文档安全管理系统远程命令执行
人这一生,不是看你贫穷和富有,而是看你都做了些啥。 漏洞描述 亿赛通电子文档安全管理系统存在远程命令执行漏洞,攻击者通过构造特定的请求可执行任意命令 漏洞复现: 访问url: 构造payload请求 POST /solr/flow/d…...
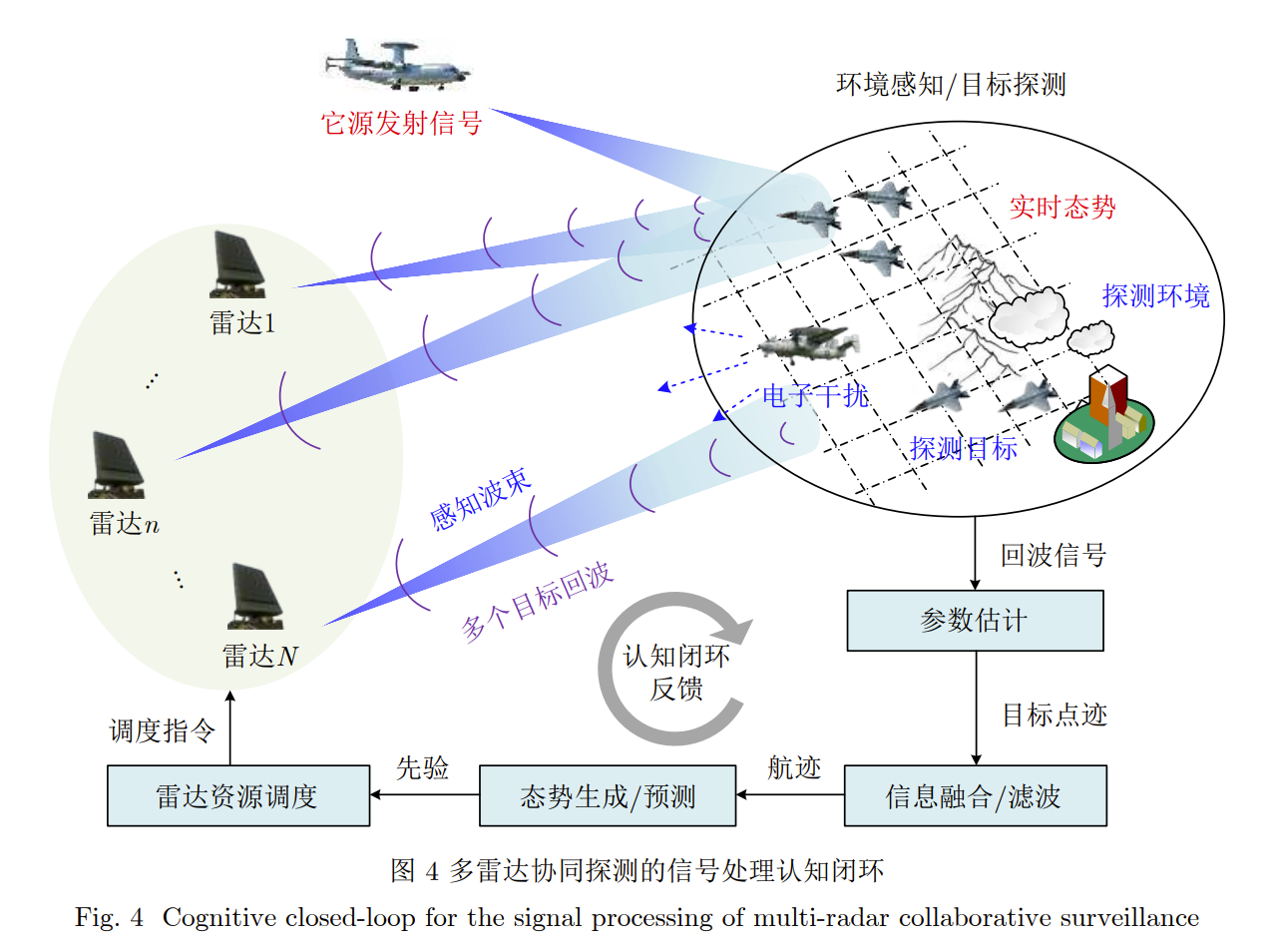
多雷达探测论文阅读笔记:雷达学报 2023, 多雷达协同探测技术研究进展:认知跟踪与资源调度算法
多雷达协同探测技术 原始笔记链接:https://mp.weixin.qq.com/s?__biz=Mzg4MjgxMjgyMg==&mid=2247486627&idx=1&sn=f32c31bfea98b85f2105254a4e64d210&chksm=cf51be5af826374c706f3c9dcd5392e0ed2a5fb31ab20924b7dd38e1b1ae32abe9a48afa8174#rd ↑ \uparrow …...

SetFit快速入门指南:如何在5分钟内完成小样本文本分类
SetFit快速入门指南:如何在5分钟内完成小样本文本分类 【免费下载链接】setfit Efficient few-shot learning with Sentence Transformers 项目地址: https://gitcode.com/gh_mirrors/se/setfit SetFit是一个高效且无需提示词的框架,专为小样本微…...
:12类边界场景+87行防御型代码片段)
仅限持牌机构内部流通的PHP支付安全Checklist(含银联/网联/跨境PayPal对接特例):12类边界场景+87行防御型代码片段
第一章:金融级PHP支付接口安全设计原则与合规基线金融级PHP支付接口的设计必须以等保三级、PCI DSS v4.0及《中国人民银行关于规范支付服务市场秩序的通知》为刚性约束,安全不是附加功能,而是架构的默认属性。核心设计原则包括最小权限暴露、…...

Meta推出由高薪超级智能实验室研发的全新AI模型
Meta于本周三正式发布了其最新人工智能模型,这也是该公司组建一支高薪团队以在AI赛道上与竞争对手展开较量后推出的首个重磅成果。这款名为Muse Spark的新模型由Meta超级智能实验室打造。该实验室汇聚了一批来自各大AI公司的顶尖人才,于去年正式成立&…...

OpenCore Legacy Patcher技术揭秘:老Mac升级macOS的底层原理与实战指南
OpenCore Legacy Patcher技术揭秘:老Mac升级macOS的底层原理与实战指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 对于拥有2007年以后的Inte…...

秒杀系统设计:十万QPS下的技术架构演进
在电商大促场景中,秒杀系统是典型的高并发、低库存业务模型,其核心挑战在于瞬时十万级QPS(每秒查询率)下的系统稳定性与数据一致性。对于软件测试从业者而言,这不仅涉及性能压测的极限挑战,更需关注架构演进…...

DataCap实战指南:从多源数据整合到智能可视化的全流程解析
1. DataCap入门:为什么你需要这个数据瑞士军刀 第一次接触DataCap是在三年前的一个企业数据治理项目里。当时客户有十几个不同系统的数据需要整合,从传统的MySQL到实时分析的ClickHouse,还有一堆Excel和CSV文件。团队折腾了两周都没搞定数据…...

OpenAI呼吁重新审视税收政策,迎接AI带来的新经济时代
ChatGPT的开发商OpenAI近日呼吁政策制定者重新思考税收体系的结构,并提出了一系列针对人工智能潜在经济与社会影响的政策建议。在周一发布的一份政策文件中,OpenAI表示,AI可能从根本上重塑经济格局,其中包括若干潜在风险ÿ…...

Steam Achievement Manager:全方位掌控游戏成就的开源解决方案
Steam Achievement Manager:全方位掌控游戏成就的开源解决方案 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 一、功能解析:三大核…...

算法工程师的随身匕首:PyTorch 极简入门与实战
PyTorch 快速入门指南 一、PyTorch 是什么? PyTorch 是一个基于 Python 的深度学习框架,由 Facebook AI Research 开发。它以动态计算图和直观的接口著称,是研究和生产中最受欢迎的框架之一。 二、环境安装 # 基础安装(CPU版本&am…...

Cursor Pro功能解锁技术指南:突破限制与优化使用方案
Cursor Pro功能解锁技术指南:突破限制与优化使用方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...