Elasticsearch 常用 HTTP 接口
本文记录工作中常用的关于 Elasticsearch 的 HTTP 接口,以作备用,读者也可以参考,会持续补充更新。开发环境基于 Elasticsearch v5.6.8、v1.7.5、v2.x。
集群状态
集群信息
1 2 3 4 5 6 7 | http://localhost:9200/_cluster/stats?pretty http://localhost:9200/_cat/nodes http://localhost:9200/_cat/indices http://localhost:9200/_cluster/state http://localhost:9200/_cat/aliasesGET _nodes/_all/stats/fs?pretty=true |
可以看到整个集群的索引数、分片数、文档数、内存使用等等信息。
健康状况
1 | http://localhost:9200/_cat/health?v |
可以看到分片数量,状态【红、黄、绿】。
空间使用
查询每个节点的空间使用情况,预估数据大小:
1 | http://localhost:9200/_cat/allocation?v |
分片分布
1 | http://localhost:9200/_cat/shards |
索引状态
可以看到索引的数据条数、磁盘大小、分片个数【可以使用别名】。
各项指标解释说明参考:indices-stats 。
1 | http://localhost:9200/your_index/_stats |
集群配置信息
1 | http://localhost:9200/_cluster/settings?pretty |
对于一些可以设置的参数,临时生效,对于集群的管理很有帮助。
例如节点黑名单:cluster.routing.allocation.exclude._ip,临时下线节点,类似于黑名单,分片不会往指定的主机移动,同时会把分片从指定的节点全部移除,最终可以下线该节点,可通过 put transient 设置临时生效。
1 2 3 4 5 | curl -XPUT 127.0.0.1:9200/_cluster/settings -d '{"transient" :{"cluster.routing.allocation.exclude._ip" : "192.168.0.1"}
}'
|
例如临时关闭分片重分配【开启时设置值为 all】。
1 2 3 4 5 6 7 8 9 10 11 12 | curl -XPUT 127.0.0.1:9200/_cluster/settings -d '{"transient": {"cluster.routing.allocation.enable": "none"}
}'PUT /_cluster/settings/
{"transient": {"cluster.routing.allocation.enable": "none"}
}
|
设置整个集群每个节点可以分配的分片数,主要是为了数据分布均匀。
1 2 3 4 5 6 7 8 | GET _cluster/settingsPUT /_cluster/settings/
{"transient": {"cluster.routing.allocation.total_shards_per_node": "50"}
}
|
设置慢索引阈值,指定索引进行操作,可以使用通配符:
1 2 3 | curl -XPUT 127.0.0.1:9200/your_index_*/_settings -d '{"index.indexing.slowlog.threshold.index.info": "10s"
}''
|
设置慢查询阈值方式类似:
1 2 3 | curl -XPUT 127.0.0.1:9200/your_index_*/_settings -d '{"index.indexing.slowlog.threshold.search.info": "10s"
}'
|
推迟索引分片的重新分配时间平【适用于 Elasticsearch 节点短时间离线再加入集群,提前设置好这个参数,避免从分片的复制移动,降低网络 IO】。
1 2 3 4 5 6 | PUT /your_index/_settings
{"settings": {"index.unassigned.node_left.delayed_timeout": "5m"}
}
|
可以使用索引别名、通配符设置,这样就可以一次性设置多个索引,甚至全部的索引。
热点线程
查看热点线程,可以判断热点线程是 search,bulk,还是 merge 类型,从而进一步分析是查询还是写入导致 CPU 负载过高。
1 2 3 | http://localhost:9200/_nodes/node0/hot_threadshttp://localhost:9200/_nodes/hot_threads |
请求队列
查看请求队列情况,可以看到每种类型请求的积压情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 | http://localhost:9200/_cat/thread_pool?v# 添加参数可以查看各个指标 http://localhost:9200/_cat/thread_pool/search?v&h=node_name,ip,name,active,queue,rejected,completed,type,queue_size注意,size 指标【在节点启动时是 0,随着请求进来才会增加】有特殊含义,不代表配置文件中的 size 参数【fixed 类型】。size:会从 0 开始增长,表示已经开启的线程池大小,直到 max 值,即配置文件中配置的。 min、max:含义根据线程池类型不同而不同。查询请求:/_tasks?detailed=true&actions=*search*取消单个请求:/_tasks/xx/_cancel取消整个节点:/_tasks/_cancel?nodes=xx&actions=*search* |
节点配置信息
可以查看节点的 JVM 配置、插件信息、队列配置等等。
1 2 3 | http://localhost:9200/_nodes/node_id http://localhost:9200/_nodes?pretty=true http://localhost:9200/_nodes/stats/thread_pool?pretty=true |
注意,thread_pool 线程池相关参数自从 v5.x 以后不支持动态设置【即通过 put 接口】,只能通过更改节点的配置文件并重启节点来操作,这也说明了这个参数是对于节点生效,不同配置的节点可以设置不同的值。
使用堆内存大小
使用
1 | http://localhost:9200/_cat/fielddata |
查看当前集群中每个数据节点上被 fielddata 所使用的堆内存大小。
此外还可以指定字段
1 2 | http://localhost:9200/_cat/fielddata?v&fields=uid&pretty http://localhost:9200/_cat/fielddata/uid?v&pretty |
按照节点、索引来查询:
1 2 3 4 5 6 7 8 9 | 按照索引、分片 http://localhost:9200/_stats/fielddata?fields=*按照节点 http://localhost:9200/_nodes/stats/indices/fielddata?fields=*按照节点、索引分片 http://localhost:9200/_nodes/stats/indices/fielddata?level=indices&fields=* http://localhost:9200/_nodes/stats/indices/fielddata?level=indices&fields=_uid |
清理缓存
1 2 3 | curl localhost:9200/index/_cache/clear?pretty&filter=false&field_data=true&fields=_uid,site_name关于 `&bloom=false` 参数的问题,要看当前 `Elasticsearch` 版本是否支持,`v5.6.x` 是不支持了。 |
推迟索引分片的重新分配时间
适用于节点短时间离线再加入集群,提前设置好,避免从分片的复制移动。
1 2 3 4 5 6 | PUT your_index/_settings
{"settings": {"index.unassigned.node_left.delayed_timeout": "5m"}
}
|
排除掉节点
不让索引的分片分配在上面,想取消设置为 null 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 索引级别的
PUT your_index/_settings
{"index.routing.allocation.exclude._ip": "ip1,ip2"
}# 集群级别的,等价于下线节点,滚动重启时需要
PUT /_cluster/settings/
{"transient": {"cluster.routing.allocation.exclude._ip": "ip1,ip2"}
}# 集群均衡移动分片的并发数,不能太大
cluster.routing.allocation.cluster_concurrent_rebalance
|
基于负载的智能路由查询
v6.2 以及以上版本,search 智能路由设置,v7.0 以及以上版本默认开启。
1 2 3 4 5 6 | PUT /_cluster/settings
{"transient": {"cluster.routing.use_adaptive_replica_selection": true}
}
|
查询全局超时时间
search 全局超时时间,避免某些耗时的查询把集群拖垮。
1 2 3 | search.default_search_timeout示例:5m |
查询时指定分片主机等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | preference=_shards:8,12
preference=_only_nodes:1
preference=_primary
preference=_replicaPOST your_index/_search?preference=_shards:12
{"query": {"match_phrase": {"content": " 查证 & quot;}}
}# 注意,指定节点之后还要指定分片,否则查询时报错:找不到某个分片对应的节点。
# 示例:
POST your_index_name/_search?preference=_only_nodes:YKA3ZivmSj2K6qutW6KNQQ&preference=_shards:3
{"query": {"match_all": {}}
}
|
分片迁移的并发数带宽流量大小等等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # 并发数
PUT _cluster/settings
{"transient": {"cluster.routing.allocation.node_concurrent_outgoing_recoveries": "3","cluster.routing.allocation.node_concurrent_incoming_recoveries": "3","cluster.routing.allocation.node_concurrent_recoveries": 3}
}# 带宽
PUT _cluster/settings
{"transient": {"indices.recovery.max_bytes_per_sec": "20mb" }
}
|
只读索引问题
在集群机器的磁盘快用完之前,集群会自动设置这台机器上面的节点的索引为【只读模式】,不可写入,写入直接拒绝并抛出异常信息。
1 | 20/10/10 19:02:44 ERROR ESBulkProcessor: {"index":"your_index_name","type":"post","id":"12aad31610551fb2e236367bbde01db7","cause":{"type":"exception","reason":"Elasticsearch exception [type=cluster_block_exception, reason=blocked by: [FORBIDDEN/12/index read-only /allow delete (api)];]"},"status":403}
|
此时,除了清理数据,还需要手动设置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | GET your_index_*/_settingsPUT your_index_*/_settings
{"index": {"blocks": {"read_only_allow_delete": "false"}}
}PUT your_index_*/_settings
{"index": {"blocks": {"read_only_allow_delete": null}}
}
|
参考官方文档:cluster.routing.allocation.disk.watermark.flood_stage 。
分析器
可以查看不同分析器的分词结果,或者基于某个索引的某个字段查看分词结果。下面列举一些例子,其它更多的内容请读者参考另外一篇博客:Elasticsearch 分析器使用入门指南 。
查看集群安装的各种分词器效果,指定文本内容、分词器即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | POST _analyze
{"text":" 行完成,是否成功请查看 ccc","analyzer":"wordsEN"
}POST _analyze
{"text":" 行完成,是否成功请查看 ccc","analyzer":"standard"
}POST _analyze
{"text":" 行完成,是否成功请查看 ccc","analyzer":"english"
}
|
查看某个索引的某个字段的分词器效果【索引已经指定分词器,可以通过 mapping 查看】,指定索引名称、文本内容、字段名称,不要指定索引的 type,否则请求变为了新建文档:
1 2 3 4 5 | POST my-index-post/_analyze
{"text":" 行完成,是否成功请查看 ccc","field":"content"
}
|
查询时也可以指定分词器【不同分词器会影响返回的结果,例如 standard 分词器会过滤掉标点符号,所以查不到数据】,特别指定分词器即可。另外只能使用 match,不能使用 match_phrase。
1 2 3 4 5 6 7 8 9 10 11 | POST my-index-post/post/_search
{"query": {"match": {"content":{"query": ",","analyzer": "standard"}}}
}
|
创建索引
创建带 mapping 的索引:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | PUT /my-index-post/
{"settings": {"index.number_of_shards": 3,"index.number_of_replicas": 1,"index.refresh_interval": "30s","index.routing.allocation.total_shards_per_node": 3},"mappings": {"post": {"_all": {"enabled": false},"dynamic_templates": [{"title1": {"match": "title","match_mapping_type": "*","mapping": {"type": "text","analyzer": "wordsEN"}}}]}}
}
|
创建带 mapping 的 type【在索引已经存在的情况下】:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | PUT /my-index-post/_mapping/post/
{"_all": {"enabled": false},"dynamic_templates": [{"title1": {"mapping": {"analyzer": "wordsEN","type": "text"},"match": "title"}},{"title2": {"mapping": {"analyzer": "wordsEN","type": "text"},"match": "*_title"}}],"properties": {"avatar_url": {"type": "keyword"}}
}
|
更新索引的 mapping【在索引、类型都已经存在的情况下】:
1 2 3 4 5 6 7 8 9 10 11 12 | PUT /my-index-post/_mapping/post
{"post": {"properties": {"title": {"type": "text","analyzer": "english","search_analyzer": "standard" }}}
}
|
添加删除别名
给索引增加别名:
1 2 3 4 5 6 7 8 9 10 11 | POST /_aliases
{"actions": [{"add": {"index": "my-index-post","alias": "my-index-post-all"}}]
}
|
移除索引的别名:
1 2 3 4 5 6 7 8 9 10 11 | POST /_aliases
{"actions": [{"remove": {"index": "my-index-post","alias": "my-index-post-all"}}]
}
|
导入数据
1 2 3 4 5 6 7 | 把文件中的数据导入索引,批量的形式 由于数据中可能存在一些特殊符号,所以使用文件的形式,in 为文件路径 文件内容格式,1 条数据需要包含 2 行内容,index 表示索引数据
{"index":{}}
JSON 原始数据 curl -XPOST 'http://localhost:9200/my-index-post/post/_bulk' --data-binary @"$in"
|
bulk 接口,详情参考另外一篇博客: 使用 Elasticsearch 的 bulk 接口批量导入数据 。
查询数据
脚本查询
Elasticsearch 提供了脚本的支持,可以通过 Groovy 外置脚本【已经过时,v6.x 以及之后的版本,不建议使用】、内置 painless 脚本实现各种复杂的操作【类似于写逻辑代码,对数据进行 ETL 操作,需要集群配置开启】。
以下是关于 v2.x 的说明:
默认的脚本语言是 Groovy,一种快速表达的脚本语言,在语法上与 JavaScript 类似。它在 Elasticsearch v1.3.0 版本首次引入并运行在沙盒中,然而 Groovy 脚本引擎存在漏洞,允许攻击者通过构建 Groovy 脚本,在 Elasticsearch Java VM 运行时脱离沙盒并执行 shell 命令。
因此,在版本 v1.3.8、1.4.3 和 v1.5.0 及更高的版本中,它已经被默认禁用。此外,您可以通过设置集群中的所有节点的 config/elasticsearch.yml 文件来禁用动态 Groovy 脚本:script.groovy.sandbox.enabled: false,这将关闭 Groovy 沙盒,从而防止动态 Groovy 脚本作为请求的一部分被接受。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | Groovy 脚本
{"query": {"bool": {"filter": {"script": {"script": "doc ['keywords'].values.length == 2"}}}}
}painless 脚本
{"query": {"bool": {"filter": {"script": {"script": {"source": "doc ['keywords'].values.length == 2","lang": "painless"}}}}}
}{"query": {"bool": {"must": [{"range": {"update_timestamp": {"gte": 1607670109000}}},{"script": {"script": {"source": "(doc ['view_cnt'].value)>doc ['comment_cnt'].value","lang": "painless"}}}]}}
}
|
日期桶聚合
对日期格式的字段做桶聚合,可以使用 interval 设置桶间隔,使用 extended_bounds 设置桶边界,其它还可以设置时区、doc 过滤等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | "aggs": {"by_month": {"date_histogram": {"field": "publish_timestamp","interval": "day","time_zone": "+08:00","format": "yyyy-MM-dd","min_doc_count": 100000,"extended_bounds": {"min": "2019-08-30","max": "2019-09-24"}}}}
|
对于聚合结果不准的问题,可以增加参数,适当提高准确性。size 参数规定了最后返回的 term 个数【默认是 10 个】,shard_size 参数规定了每个分片上返回的个数【默认是 size * 1.5 + 10】,如果 shard_size 小于 size,那么分片也会按照 size 指定的个数计算。
聚合的字段可能存在一些频率很低的词条,如果这些词条数目比例很大,那么就会造成很多不必要的计算。因此可以通过设置 min_doc_count 和 shard_min_doc_count 来规定最小的文档数目,只有满足这个参数要求的个数的词条才会被记录返回。min_doc_count:规定了最终结果的筛选,shard_min_doc_count:规定了分片中计算返回时的筛选。
1 2 3 4 5 6 7 8 9 10 11 | "aggs": {"aggs_sentiment":{"terms": {"field": "sentiment","size": 10,"shard_size": 30,"min_doc_count": 10000,"shard_min_doc_count": 50}}
}
|
更新文档
指定部分字段进行更新,不影响其它字段【但是要注意,如果字段只是索引 index 而没有存储 _source,更新后会无法查询这个字段】。
1 2 3 4 5 6 | POST /my-index-user/user/0f42d65be1f5287e1c9c26e3728814aa/_update
{"doc" : {"friends" : ["98681482902","63639783663","59956667929"]}
}
|
自动缓存相关
terms lookup 查询:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 自动缓存
POST my-index-post/_search
{"query": {"terms": {"user_item_id":{"index": "my-index-user","type": "user","id": "0f42d65be1f5287e1c9c26e3728814aa","path": "friends"}}}
}
|
操作缓存的接口:
1 2 | 关闭缓存 curl -XPOST 'localhost:9200/_cache/clear?filter_path=your_cache_key' |
多层嵌套反转桶聚合
多层聚合查询,关于嵌套、反转,参考:nested-aggregation 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | POST combine-paas-1003-index/2723-data/_search
{"aggs": {"x": {"aggs": {"xx": {"aggs": {"xxx": {"aggs": {"xxxx_interaction_cnt": {"sum": {"field": "2723_interaction_cnt"}}},"reverse_nested": {}}},"terms": {"field": "Titan_sports.yundongerji","size": 100}}},"nested": {"path": "Titan_sports"}}},"query": {"bool": {"must": [{"term": {"2723_is_noise": {"value": " 否 & quot;}}}]}},"size": 1
}
|
统计个数聚合
对于多篇文章,统计每个站点下面的作者个数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | -- 多层嵌套以及特殊的聚合,每个 site_name 下面的作者个数统计
{"aggs": {"s": {"aggs": {"a": {"cardinality": {"field": "author"}}},"terms": {"field": "site_name","size": 0}}},"query": {},"size": 0
}
|
存在查询
exists、missing 这两类查询在不同的版本之间使用方式不一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | -- 存在、不存在判断条件,1.7.5 版本和 2.3.4 版本的方式不一样
-- 2.3.4:使用 exists、missing 关键字即可
{"query": {"exists": {"field": "gender"}}
}{"query": {"missing": {"field": "gender"}}
}-- 更高版本【v5.x 以及以上】的 ES 关键字 missing 已经被废弃,改为 must_not 和 exists 组合查询,以下有示例
{"query": {"bool": {"must_not": {"exists": {"field": "user"}}}}
}-- 1.7.5:使用 filter 后再使用对应关键词,本质是一种过滤器
{"query": {"filtered": {"filter": {"exists": {"field": "data_type"}}}}
}-- 此外,不同版本连接 ES 的 client 方式也不一样【tcp 连接,如果是 http 连接就不会有问题】,代码不能兼容,所以只能使用其中 1 种方式【在本博客中可以搜索到相关总结】
|
随机取数
随机取数【需要 ES 集群支持脚本请求】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | GET your_index_name/_search
{"query": {"match_all": {}},"sort": {"_script": {"script": "Math.random ()","type": "number","order": "desc"}},"size": 20
}
|
如果 ES 集群不支持脚本请求,会抛出异常:illegal_argument_exception,原因:cannot execute [inline] scripts。
删除数据
根据查询条件删除数据:
1 2 3 4 5 6 7 8 9 10 11 | POST my-index-post/post/_delete_by_query/
{"query": {"terms": {"id": ["1","2"]}}
}
|
当然,如果是低版本的 Elasticsearch,在 1.x 的版本中还可以使用发送 DELETE 请求的方式删除数据,容易引发一些操作失误,不建议使用。
更多内容参考:Elasticsearch 根据查询条件删除数据的 API 。
索引关闭开启
主要有两个接口:
- 开启索引,
curl -XPOST http://localhost:9200/your_index/_open - 关闭索引,
curl -XPOST http://localhost:9200/your_index/_close
参考这篇博客的部分内容:使用 http 接口删除 Elasticsearch 集群的索引 。
迁移数据
迁移一个索引的数据到另外一个索引,切记需要提前创建好索引,包含 mapping,避免字段类型出问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | POST _reindex
{"source": {"index": "my-index-post","type": "post"},"dest": {"index": "my-index-post-bak","type": "post"}
}size 参数在最外层表示随机抽取 n 条测试;
size 参数在 source 里面表示 batch 大小,默认 1000;参数 wait_for_completion=false 可以让任务在后台一直运行到完成,否则当数据量大的时候,执行时间过长,会超时退出。查看任务状态,取消任务 GET _tasks?detailed=true&actions=*reindexPOST _tasks/task_id:1/_cancelPOST _tasks/_cancel?nodes=nodexx&actions=*search*
|
此外,参考:Elasticsearch 的 Reindex API 详解 ,里面包含了常见的参数使用方式,以及查看迁移任务进度、取消迁移任务的方式。
移动分片
需要先关闭 rebalance,再手动移动分片,否则由于手动迁移分片造成集群进行分片的重新分配,进而消耗 IO、CPU 资源。手动迁移分片完成之后,再打开 rebalance,让集群自行进行重新分配管理。
临时参数设置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 关闭
curl -XPUT 'localhost:9200/_cluster/settings' -d
'{"transient": {"cluster.routing.allocation.enable": "none"}
}'打开
curl -XPUT 'localhost:9200/_cluster/settings' -d
'{"transient": {"cluster.routing.allocation.enable": "all"}
}'
|
分片的迁移使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | move:移动分片
cancel:取消分片
allocate:重新分配分片 curl -XPOST 'localhost:9200/_cluster/reroute' -d '{"commands" : [{"move" :{"index" : "test", "shard" : 0,"from_node" : "node1", "to_node" : "node2"}},"cancel" :{"index" : "test", "shard" : 0, "node" : "node1"}},{"allocate" : {"index" : "test", "shard" : 1, "node" : "node3"}}]
}'将分配失败的分片重新分配
curl -XGET 'localhost:9200/_cluster/reroute?retry_failed=true'用命令手动分配分片,接受丢数据(ES 集群升级前关闭了 your_index 索引,升级后,把副本数设置为 0,打开有 20 个分片无法分配,集群保持红色。关闭也无效,只好接受丢数据恢复空分片)。
{"commands": [{"allocate_empty_primary": {"index": "your_index","shard": 17,"node": "nodexx","accept_data_loss": true}}]
}
|
注意,allocate 命令还有一个参数,"allow_primary" : true,即允许该分片做主分片,但是这样可能会造成数据丢失【在不断写入数据的时候】,因此要慎用【如果数据在分配过程中是静态的则可以考虑使用】。
当然,手动操作需要在熟悉集群的 API 使用的情况下,例如需要获取节点、索引、分片的信息,不然的话不知道参数怎么填写、分片怎么迁移。此时可以使用 Head、kopf、Cerebro 等可视化工具进行查看,比较适合运维人员,而且,分片的迁移指挥工作也可以交给这些工具,只要通过鼠标点击就可以完成分片的迁移,很方便。
验证
检验查询语句的合法性,不仅仅是满足 JSON 格式那么简单:
1 2 3 4 5 6 7 8 9 10 11 | POST /my-index-post/_validate/query?explain
{"query": {"match": {"content":{"query": ",","analyzer": "wordsEN"}}}
}
|
检查分片分配的相关信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | 不带任何参数执行该命令,会输出当前所有未分配分片的失败原因
curl -XGET 'localhost:9200/_cluster/allocation/explain该命令可查看指定分片当前所在节点以及分配到该节点的理由,和未分配到其他节点的原因
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{"index": < 索引名 & gt;,"shard": < 分片号 & gt;,"primary": true/false
}'将分配失败的分片重新进行分配
POST _cluster/reroute?retry_failed=true移动分片
POST /_cluster/reroute/
{"commands": [{"move": {"index": "your_index_name","shard": 0,"from_node": "dev5","to_node": "dev6"}}]
}用命令手动分配分片,接受丢数据【原因:ES 集群升级前关闭了某个索引,升级后,把副本数设置为 0,打开有 20 个分片无法分配,集群保持红色。关闭也无效,只好接受丢数据恢复空分片】。
{"commands": [{"allocate_empty_primary": {"index": "your_index_name","shard": 17,"node": "node1","accept_data_loss": true}}]
} |
相关文章:

Elasticsearch 常用 HTTP 接口
本文记录工作中常用的关于 Elasticsearch 的 HTTP 接口,以作备用,读者也可以参考,会持续补充更新。开发环境基于 Elasticsearch v5.6.8、v1.7.5、v2.x。 集群状态 集群信息 1 2 3 4 5 6 7http://localhost:9200/_cluster/stats?pretty http…...

games106 homework1实现
games106 homework1 gltf介绍图: 骨骼动画 动画相关属性: 对GLTF的理解参照了这篇文章: glTF格式详解(动画) GLTF文件格式详解 buffer和bufferView对象用于引用动画数据。 buffer对象用来指定原始动画数据, bufferView对象用来引用buff…...
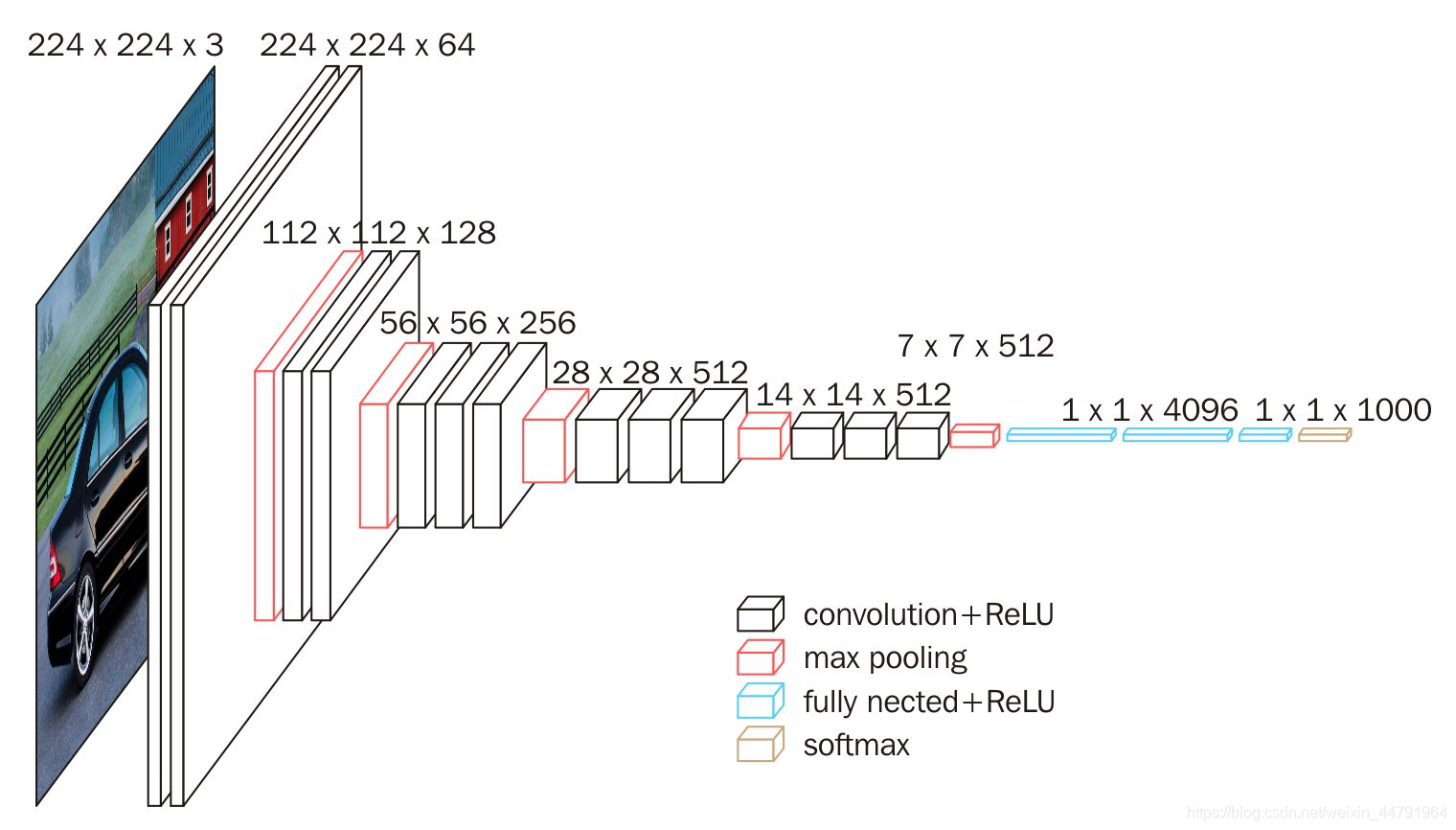
Pytorch使用VGG16模型进行预测猫狗二分类
目录 1. VGG16 1.1 VGG16 介绍 1.1.1 VGG16 网络的整体结构 1.2 Pytorch使用VGG16进行猫狗二分类实战 1.2.1 数据集准备 1.2.2 构建VGG网络 1.2.3 训练和评估模型 1. VGG16 1.1 VGG16 介绍 深度学习已经在计算机视觉领域取得了巨大的成功,特别是在图像分类任…...
安装nvm使用nvm管理node切换npm镜像后使用vue ui管理构建项目成功
如果安装nvm前已经单独安装过node.js的请先自行卸载原有node和环境变量里面的配置; 亲测成功,有哪些问题可以在评论区发消息或者私聊我 1、安装nvm的步骤如下 下载nvm安装包 在nvm的GitHub仓库,如下是国内镜像仓库: 点击这里跳…...
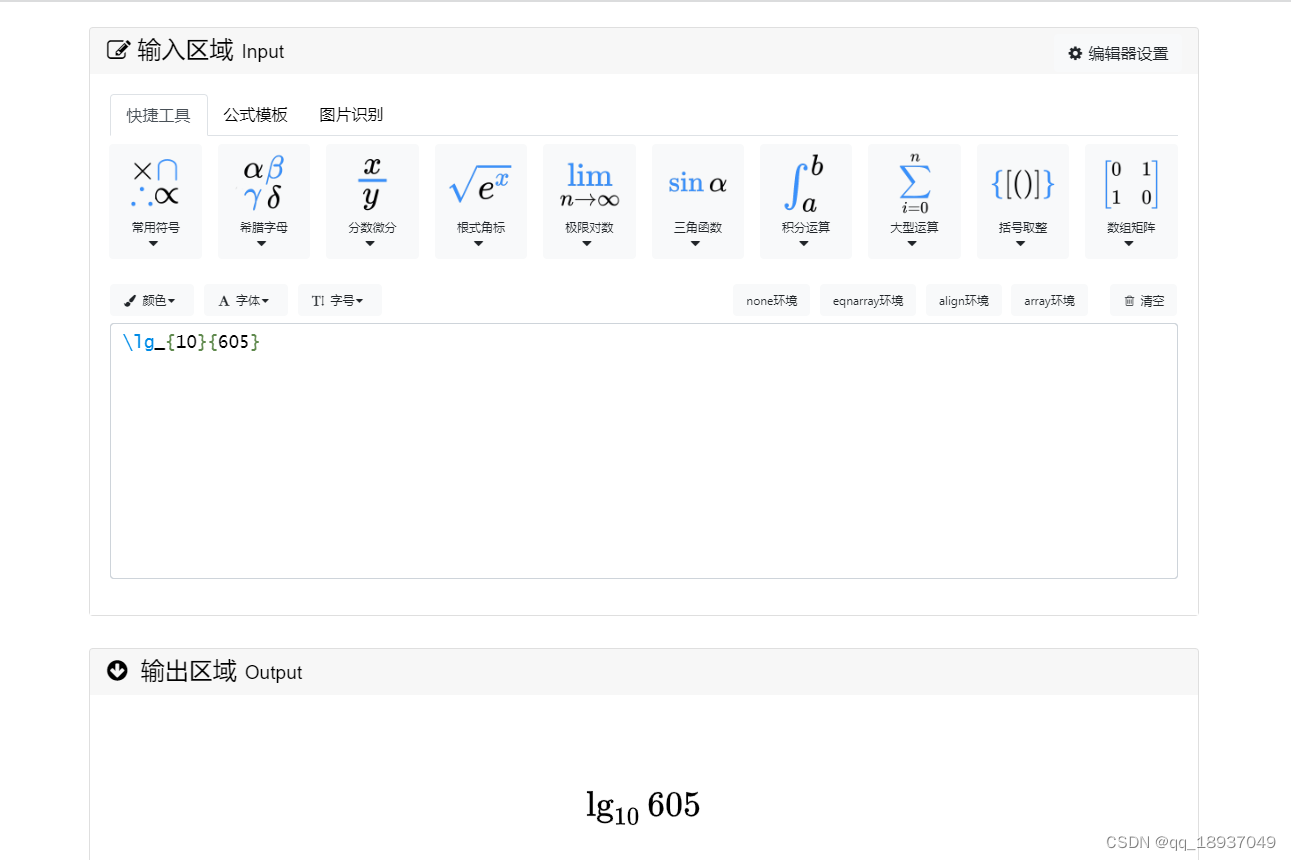
在线LaTeX公式编辑器编辑公式
在线LaTeX公式编辑器编辑公式 在编辑LaTex文档时候,需要输入公式,可以使用在线LaTeX公式编辑器编辑公式,其链接为: 在线LaTeX公式编辑器,https://www.latexlive.com/home 图1 在线LaTeX公式编辑器界面 图2 在线LaTeX公式编辑器…...

【C、C++】学习0
C、C学习路线 C语法:变量、条件、循环、字符串、数组、函数、结构体等指针、内存管理推荐书籍:《C Primer Plus》、《C和指针》、《C专家编程》 CC语言基础C的面向对象(封装、继承与多态)特性泛型模板STL等等推荐书籍(…...

python GUI nicegui初识一(登录界面创建)
最近尝试了python的nicegui库,虽然可能也有一些不足,但个人感觉对于想要开发不过对ui设计感到很麻烦的人来说是很友好的了,毕竟nicegui可以利用TailwindCSS和Quasar进行ui开发,并且也支持定制自己的css样式。 这里记录一下自己利…...
【单片机】51单片机串口的收发实验,串口程序
这段代码是使用C语言编写的用于8051单片机的串口通信程序。它实现了以下功能: 引入必要的头文件,包括reg52.h、intrins.h、string.h、stdio.h和stdlib.h。 定义了常量FSOC和BAUD,分别表示系统时钟频率和波特率。 定义了一个发送数据的函数…...
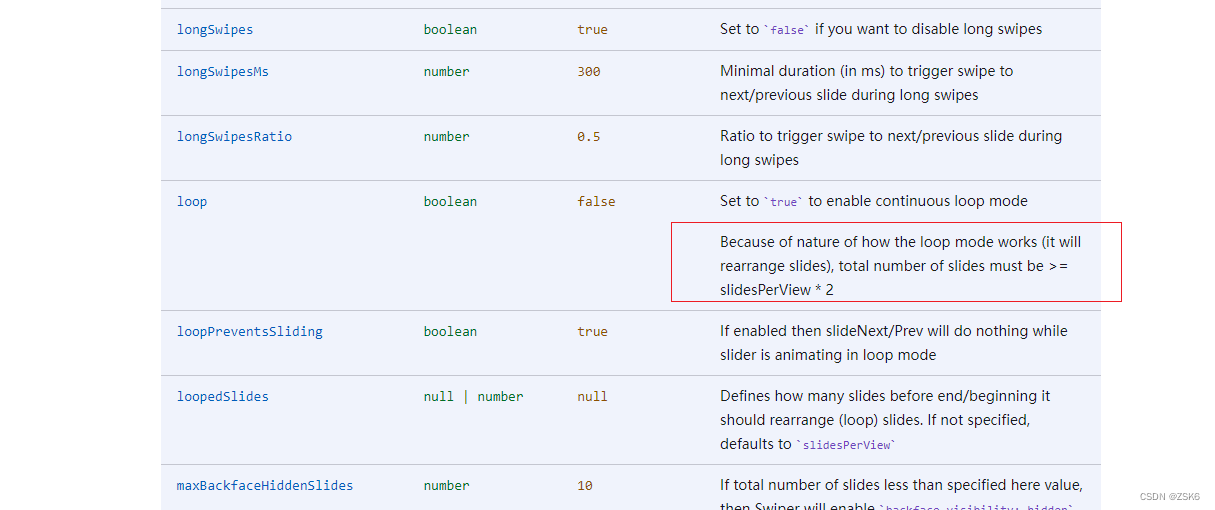
【bug】记录一次使用Swiper插件时loop属性和slidersPerView属性冲突问题
简言 最近在vue3使用swiper时,突然发现loop属性和slides-per-view属性同时存在启用时,loop生效,下一步只能生效一次的bug,上一步却是好的。非常滴奇怪。 解决过程 分析属性是否使用错误。 loop是循环模式,布尔型。 …...
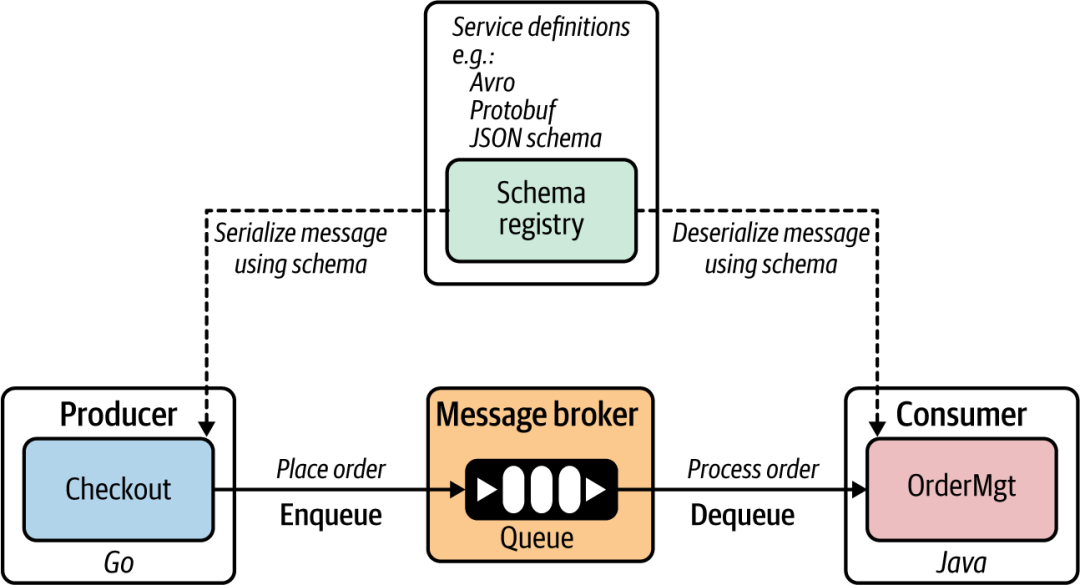
云原生应用里的服务发现
服务定义: 服务定义是声明给定服务如何被消费者/客户端使用的方式。在建立服务之间的同步通信通道之前,它会与消费者共享。 同步通信中的服务定义: 微服务可以将其服务定义发布到服务注册表(或由微服务所有者手动发布)…...

【零基础学Rust | 基础系列 | 基础语法】变量,数据类型,运算符,控制流
文章目录 简介:一,变量1,变量的定义2,变量的可变性3,变量的隐藏 二、数据类型1,标量类型2,复合类型 三,运算符1,算术运算符2,比较运算符3,逻辑运算…...

运输层---概述
目录 运输层主要内容一.概述和传输层服务1.1 概述1.2 传输服务和协议1.3 传输层 vs. 网络层1.4 Internet传输层协议 二. 多路复用与多路分解(解复用)2.1 概述2.2 无连接与面向连接的多路分解(解复用)2.3面向连接的多路复用*2.4 We…...

高速公路巡检无人机,为何成为公路巡检的主流工具
随着无人机技术的不断发展,无人机越来越多地应用于各个领域。其中,在高速公路领域,高速公路巡检无人机已成为公路巡检的得力助手。高速公路巡检无人机之所以能够成为公路巡检中的主流工具,主要是因为其具备以下三大特性。 一、高速…...
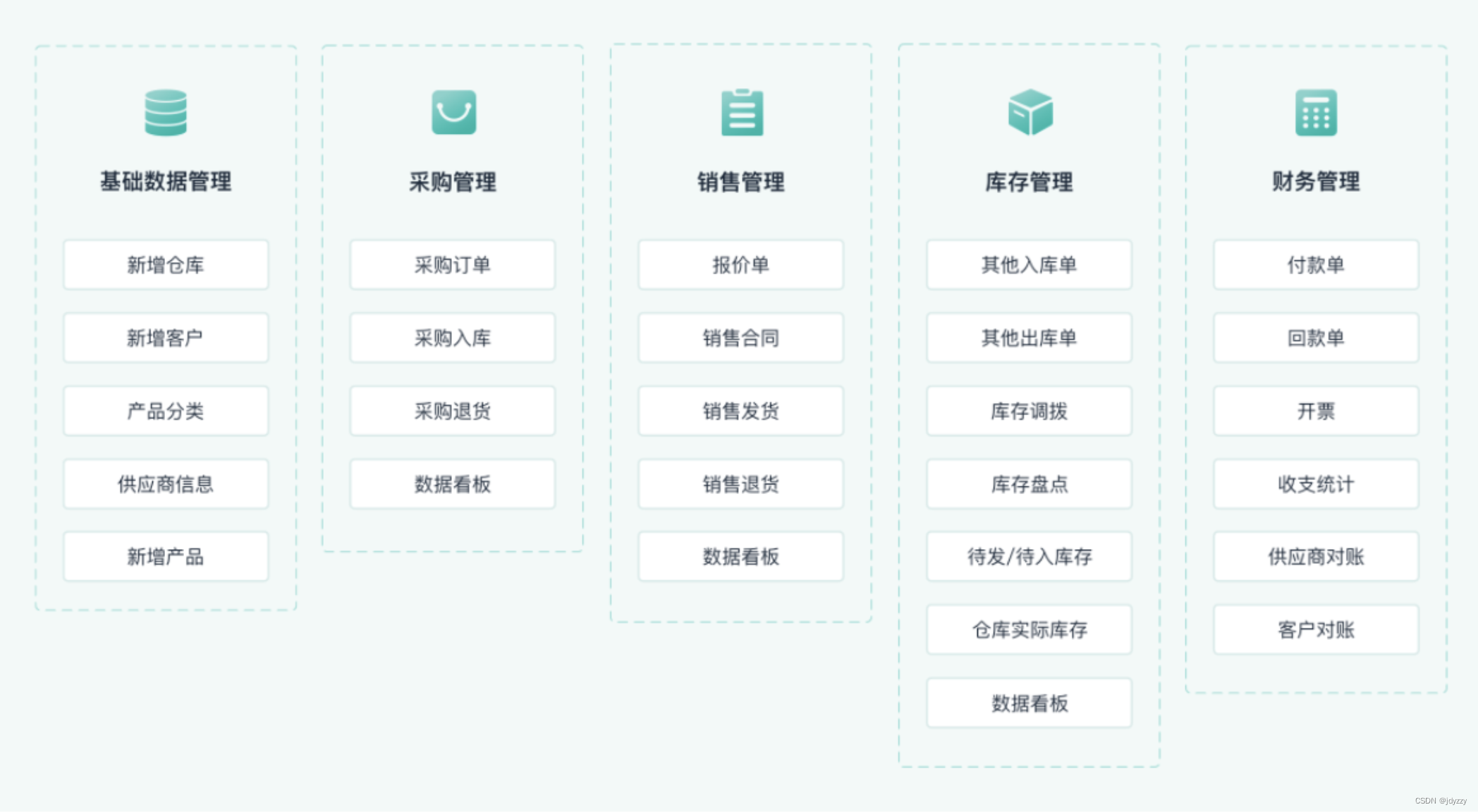
仓库管理系统有哪些功能,如何对仓库进行有效管理
阅读本文,您可以了解:1、仓库管理系统有哪些功能;2、如何对仓库进行有效管理。 仓库是制造业的开端,原材料的领料开始。企业的仓库管理是涉及企业生产、企业资金流和企业的经营风险的关键环节。在众多的工业企业、制造型企业、贸…...

Java 比Automic更高效的累加器
1、 java常见的原子类 类 Atomiclnteger、AtomicIntegerArray、AtomicIntegerFieldUpdater、AtomicLongArray、 AtomicLongFieldUpdater、AtomicReference、AtomicReferenceArray 和 AtomicReference- FieldUpdater 常见的原子类使用方法 使用 AtomicReference 来创建一个原…...

antDv table组件滚动截图方法的实现
在开发中经常遇到table内容过多产生滚动的场景,正常情况下不产生滚动进行截图就很好实现,一旦产生滚动就会变得有点棘手。 下面分两种场景阐述解决的方法过程 场景一:右侧不固定列的情况 场景二:右侧固定列的情况 场景一 打开…...

JavaSE【抽象类和接口】(抽象类、接口、实现多个接口、接口的继承)
一、抽象类 在 Java 中,一个类如果被 abstract 修饰称为抽象类,抽象类中被 abstract 修饰的方法称为抽象方法,抽象方法不用 给出具体的实现体。 1.语法 // 抽象类:被 abstract 修饰的类 public abstract class Shape { …...

微信小程序如何跳转H5页面
1、登录微信公众后台,进入【开发->开发管理->业务域名】,点击修改。 2、首先请下载校验文件,并将文件放置在域名根目录下。 我是把文件放在nginx主机的data目录下,然后通过增加nginx.config配置,重启nginx后可…...
:bit_cast)
C++(20):bit_cast
C++20之前如果想对不同的指针之间做类型转换需要通过reinterpret_cast,对于整数与指针之前的转换也需要通过reinterpret_cast: C++:reinterpret_cast_c++ reparant_cast_风静如云的博客-CSDN博客 但是reinterpret_cast的缺点是不同的编译环境下,无法包装转型的安全一致。 …...
STM32 低功耗-停止模式
STM32 停止模式 文章目录 STM32 停止模式第1章 低功耗模式简介第2章 停止模式简介2.1 进入停止模式2.1 退出停止模式 第3章 停止模式程序部分总结 第1章 低功耗模式简介 在 STM32 的正常工作中,具有四种工作模式:运行、睡眠、停止以及待机模式。 在系统…...

你的终端神器之Oh My Zsh吭
1.安装环境准备 1.1.查看物理内存 [rootaiserver ~]# free -m 1.2.操作系统版本 [rootaiserver ~]# cat /etc/redhat-release 1.3.操作系统内存 [rootaiserver ~]# df -h /dev/shm/ 1.4.磁盘空间 [rootaiserver ~]# df -TH [rootaiserver ~]# df -h /tmp/ [rootaiserver ~]# d…...

从48小时到15分钟:智能黑苹果配置工具的革命性突破
从48小时到15分钟:智能黑苹果配置工具的革命性突破 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 黑苹果配置长期以来被视为一项高门槛技…...

蓝牙技术基础知识
文章目录概述1、Basic Rate -经典蓝牙2、Low Energy(LE)几个常用的蓝牙规范:A2DPProfile 汇总概述 在网络上收集的一些资料,做一下汇总,方便自己查阅和学习。 作为一种通用的无线通信技术,规范…...

剑指offer-61、序列化二叉树
请实现两个函数,分别⽤来序列化和反序列化⼆叉树⼆叉树的序列化是指:把⼀棵⼆叉树按照某种遍历⽅式的结果以某种格式保存为字符串,从⽽使得内存中建⽴起来的⼆叉树可以持久保存。序列化可以基于先序、中序、后序、层序的⼆叉树遍历⽅式来进⾏…...
:整体流程与交互设计)
Qt6 Host + Updater 更新方案(1):整体流程与交互设计
你有没有遇到过这种尴尬:软件提示“有新版本”,点了更新却失败;或者更新到一半程序直接卡死;再或者最常见的——Windows 下主程序正在运行,EXE 被占用,根本没法覆盖替换。很多 Qt 新手第一次做在线升级&…...

AudioSwitch:Windows音频设备一键切换与音量管理的终极解决方案
AudioSwitch:Windows音频设备一键切换与音量管理的终极解决方案 【免费下载链接】AudioSwitch Switch between default audio input or output change volume 项目地址: https://gitcode.com/gh_mirrors/au/AudioSwitch 在Windows系统中频繁切换音频设备是否…...

Snap.Hutao:5分钟掌握原神玩家必备的终极桌面工具箱
Snap.Hutao:5分钟掌握原神玩家必备的终极桌面工具箱 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hutao…...

Awoo Installer:Switch游戏安装全场景解决方案的技术突破与实践指南
Awoo Installer:Switch游戏安装全场景解决方案的技术突破与实践指南 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer作为…...

第二十五节:Skill的打包、版本控制与社区发布
引言 上一章,我们为Skill精心打造了专业的README文档,这好比为产品准备好了精美的说明书。但要让用户能真正“安装”并使用你的成果,我们还需要完成从本地项目到可分发“产品”的关键转化。本章,我们将聚焦于Skill的打包、版本控制…...

s2-pro语音合成多场景应用:远程医疗问诊语音记录转述与播报
s2-pro语音合成多场景应用:远程医疗问诊语音记录转述与播报 1. 医疗语音转述的痛点与解决方案 在远程医疗场景中,医生与患者的语音问诊记录需要准确转述为文字并生成语音播报,传统方式面临三大挑战: 效率瓶颈:人工转…...