基于facenet+faiss开发构建人脸识别系统
facenet是一款非常经典的神经网络模型,它可以直接学习从人脸图像到欧几里德空间的映射(直接将人脸映射到欧几里得空间)。在欧几里德空间中,距离直接对应于人脸相似性的度量。一旦这个空间产生,使用标准技术,将FaceNet嵌入作为特征向量,就可以很容易地实现人脸识别、验证和聚类等任务。作者使用经过训练的深度卷积网络来直接优化嵌入本身,而不是像以前的深度学习方法那样使用中间瓶颈层。为了训练,作者使用了一种新的online triplet mining方法生成的粗略对齐的匹配/非匹配的人脸块的 triplets。该方法的好处是更大的recognition performance:实现了最先进的人脸识别性能,每一张脸仅使用128字节(128维空间向量)。
在之前的一些项目就有使用到facenet模型,用于人脸识别本质上来说是借助于facenet模型将输入的标准的人脸图像数据转化为了128维的向量,之后通过对向量的计算,比如:相似度计算、距离计算,转化为了人脸识别的计算,当然了后面也可以使用机器学习模型来接收facenet的输出向量做进一步的预测都是可以的,我们之前的项目采用的是向量直接匹配计算的方式,由于当时数据量不大,所以向量的匹配计算等价于暴力搜索,但是一旦数据量激增,这种方式带来的时间成本就是难以接受的了。
最近正好在用faiss,就有一个想法,想要将facenet模型和faiss做一个集成来开发一套高性能的人脸识别系统,我将整体的构思绘制如下图所示:
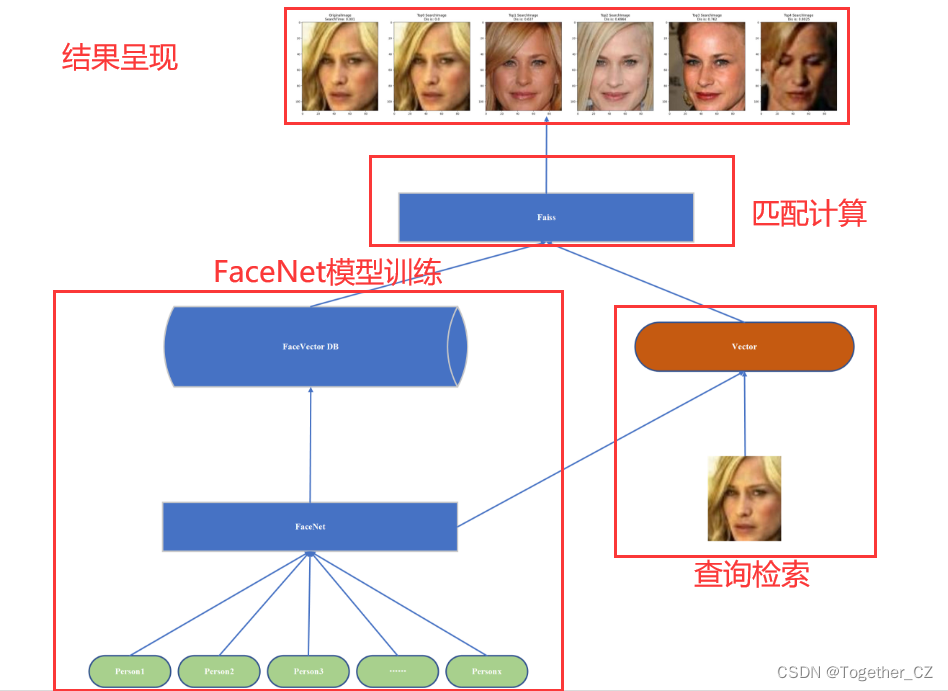
整体的思路还是比较清晰明了的。
接下来先简单回顾一下相关技术原理。
Facenet是一种用于人脸识别和人脸验证的深度学习模型,通过将人脸图像转换成高维空间中的嵌入向量来表示每个人脸。该模型由Google的研究科学家Florian Schroff、Dengyong Zhou和Christian Szegedy于2015年提出。
Facenet模型的构建原理基于卷积神经网络(Convolutional Neural Network, CNN)。下面是Facenet模型的主要构建原理:
-
输入图像:首先,将人脸图像作为输入提供给Facenet模型。
-
卷积神经网络(CNN):Facenet模型通过多个卷积层和池化层来提取图像中的特征。卷积层用于捕获空间特征,如边缘和纹理等。池化层用于减小特征图的尺寸并保留重要的特征。
-
Triplet Loss:Facenet模型使用三元组损失函数(Triplet Loss)来学习一个紧凑的人脸嵌入向量空间。Triplet Loss的目标是使同一人的嵌入向量之间的距离尽可能小,不同人的嵌入向量之间的距离尽可能大。这样可以使得不同人的嵌入向量在空间上得到有效的分离。
Facenet算法的优点:
-
高准确率:Facenet模型在人脸识别和人脸验证任务上取得了非常出色的准确率,甚至在大规模人脸识别数据集上也表现优异。
-
基于嵌入向量的表示:Facenet将人脸图像转换为紧凑的嵌入向量,使得不同人的人脸之间能够得到有效的分离,并且嵌入向量具有良好的可比性。
-
大规模训练:Facenet模型可以通过使用大规模的人脸图像数据集进行训练,从而获得更好的泛化能力。
Facenet算法的缺点:
-
高计算资源需求:由于Facenet模型的深度和复杂性,需要大量的计算资源来进行训练和推理。这使得在某些设备或场景下应用Facenet模型变得困难。
-
影响因素敏感:Facenet模型对输入图像的光照、角度和尺度等因素敏感。在实际应用中,需要考虑这些因素对人脸识别或验证的影响。
Faiss是一种用于高效相似性搜索的库,由Facebook人工智能研究实验室开发。它基于近似最近邻(Approximate Nearest Neighbor, ANN)算法,旨在解决大规模数据集的相似性搜索问题。Faiss可以在GPU和CPU上运行,并提供了多种近似搜索算法和索引结构。
Faiss的主要构建原理是使用索引结构对数据进行预处理,以便于在搜索时快速定位到相似的数据点。下面是Faiss的主要特点和优势:
-
高效:Faiss通过高度优化的算法和索引结构,实现了非常高效的相似性搜索。它可以处理包含数百万或上亿个数据点的大规模数据集。
-
支持多种索引算法:Faiss提供多种索引算法,包括快速扫描、k-means、倒排文件等等。这些算法可以针对不同的数据特点和搜索需求选择最合适的索引结构,以提高搜索性能。
-
可扩展性:Faiss可以在单个GPU或多个GPU上运行,并且支持分布式计算。这使得它能够有效地处理大规模数据集并实现快速搜索。
-
索引更新和存储:Faiss允许动态地更新索引结构,可以添加、删除或修改数据点。此外,Faiss还提供了存储和加载索引结构的功能,方便在不同环境中使用。
-
多种语言支持:Faiss支持多种编程语言接口,如C++、Python等,使得它在不同的开发环境下都易于使用和集成。
Faiss算法的一些缺点包括:
-
近似性:Faiss提供的是近似最近邻搜索,并不保证精确的最近邻搜索结果。虽然近似搜索能够在处理大规模数据时显著提高搜索速度,但在对结果的准确性有严格要求的应用中,可能需要使用精确搜索算法。
-
参数调优:Faiss中的索引算法有多个参数需要调整,以获得最佳的搜索性能。对于不熟悉Faiss的用户来说,可能需要一些实验和调优才能找到最优的配置。
-
存储需求:基于索引结构的相似性搜索常常需要占用较大的存储空间,尤其是当数据集非常大时。这可能对存储资源造成压力。
接下来我们来实现自己的想法,facenet本身模型网上有开源的,这里我就不再自己训练了,直接使用了网上开源的模型,自己搜索就有很多的,选择合适自己使用的即可,接下来就是要实现人脸向量数据库的构建,核心实现如下所示:
def batch2Vec(picDir="datasets/", save_path="faceDB.json"):"""批量数据向量化处理"""feature=[]person={}count=0for one_person in os.listdir(picDir):oneDir=picDir+one_person+"/"print("one_person: ", one_person, ", one_num: ", len(os.listdir(oneDir)), ", count: ", count)for one_pic in os.listdir(oneDir):one_path=oneDir+one_picone_vec=sinleImg2Vec(pic_path=one_path)if one_person in person:person[one_person].append([one_pic, one_vec])else:person[one_person]=[[one_pic, one_vec]]feature.append([one_path, one_vec])count+=1print("feature_length: ", len(feature))with open(save_path, "w") as f:f.write(json.dumps(feature))with open("person.json", "w") as f:f.write(json.dumps(person))之后我们就可以基于人脸向量数据库来构建faiss索引,输入单个查询向量来进行计算了,核心实现如下所示:
#检索计算
start=time.time()
distances, indexs = index.search(query, topK)
print("distances_shape: ", distances.shape)
print("indexs_shape: ", indexs.shape)
end=time.time()
delta=round(end-start, 4)
#对比可视化
plt.clf()
plt.figure(figsize=(36,6))
plt.subplot(1,6,1)
plt.imshow(Image.open(pic_path))
plt.title("OriginalImage\nSearchTime: "+str(delta)+"s")
indexs=indexs.tolist()[0]
print("indexs: ", indexs)
for i in range(len(indexs)):one_ind=indexs[i]plt.subplot(1,6,i+2)plt.imshow(Image.open(images[one_ind]))one_dis= distance(query, vectors[one_ind])plt.title("Top"+str(i)+" SearchImage\nDis is: "+str(round(one_dis, 4)))
plt.savefig("compare.jpg")接下来我们看下实际结果详情。
查询输入:

检索输出如下:

查询输入:

检索输出:

查询输入:

检索输出:

查询输入:

检索输出:

整体体验下来感觉精度和速度还是非常不错的,可见这个流程是没有问题的。
相关文章:
基于facenet+faiss开发构建人脸识别系统
facenet是一款非常经典的神经网络模型,它可以直接学习从人脸图像到欧几里德空间的映射(直接将人脸映射到欧几里得空间)。在欧几里德空间中,距离直接对应于人脸相似性的度量。一旦这个空间产生,使用标准技术,将FaceNet嵌入作为特征…...
数据分析的心脏:获取数据的好工具
打开网站:Scrape and Monitor Data from Any Website with No Code 新建机器人: 选择类型: 填写目标网站网址: 输入网址:https://cn.wsj.com/zh-hans/news/technology 第一次录制需要安装chrome插件: 并设置…...
【万字长文】SpringBoot整合Atomikos实现多数据源分布式事务(提供Gitee源码)
前言:在最近的实际开发的过程中,遇到了在多数据源的情况下要保证原子性的问题,这个问题当时遇到了也是思考了一段时间,后来通过搜集大量资料与学习,最后是采用了分布式事务来解决这个问题,在讲解之前&#…...

js中什么是宏任务、微任务?宏任务、微任务有哪些?又是怎么执行的?
目录 目录 目录 参考资料 必看强烈建议十分钟看完视频 ,即可学会 必看参考详解宏任务微任务 参考资料 1 宏任务与微任务_哔哩哔哩_bilibili 什么是宏任务、微任务?宏任务、微任务有哪些?又是怎么执行的?_什么是宏任务和微任…...
Word中如何断开表格中线段
Word中如何断开表格中线段_word表格断线怎么弄_仰望星空_LiDAR的博客-CSDN博客有时候为了美观,需要实现如下的效果,即第2条线段被断开成3段步骤如下:选中需要断开的格网,如下,再选择段落、针对下框标即可。_word表格断…...

大数据指标体系-笔记
指标体系 1 总体流程图 1.1 2 模型‘ 2.1 OSM OSM(Object,Strategy,Measure) 「业务度量」涉及到以下两个概念:一个是KPI ,用来直 接衡量策略的有效性;一个是Target,是预先给出的值,用来判断是否达到预期 2.2 UJM User, Journey, Map 2.3 AARRR-海盗 AARRR(Acquisitio…...
Arthas协助MQ消费性能优化
背景 项目中使用AWS的SQS消息队列进行异步处理,QA通过压测发现单机TPS在23左右,目标性能在500TPS,所以需要对消费逻辑进行优化,提升消费速度。 目标 消费TPS从23提升到500 优化流程 优化的思路是先分析定位性能瓶颈ÿ…...
【Linux】【docker】安装sonarQube免费社区版9.9
文章目录 ⛺sonarQube 镜像容器⛺Linux 安装镜像🍁出现 Permission denied的异常🍁安装sonarQube 中文包🍁重启服务 ⛺代码上传到sonarQube扫描🍁java语言配置🍁配置 JS TS Php Go Python⛏️出现异常sonar-scanner.ba…...

C/C++实现librosa音频处理库melspectrogram和mfcc
C/C实现librosa音频处理库melspectrogram和mfcc 目录 C/C实现librosa音频处理库melspectrogram和mfcc 1.项目结构 2.依赖环境 3.C librosa音频处理库实现 (1) 对齐读取音频文件 (2) 对齐melspectrogram (3) 对齐MFCC 4.Demo运行 5.librosa库C源码下载 深度学习语音处…...

浪潮服务器硬盘指示灯显示黄色的服务器数据恢复案例
服务器数据恢复环境: 宁夏某市某单位的一台浪潮服务器,该服务器中有一组由6块SAS硬盘组建的RAID5阵列。 服务器上存放的是Oracle数据库文件,操作系统层面划分了1个卷。 服务器故障&初检: 服务器在运行过程中有两块磁盘的指示灯…...

宋浩概率论笔记(三)随机向量/二维随机变量
第三更:本章的内容最重要的在于概念的理解与抽象,二重积分通常情况下不会考得很难。此外,本次暂且忽略【二维连续型随机变量函数的分布】这一章节,非常抽象且难度较高,之后有时间再更新。...

附件展示 点击下载
效果图 实现代码 <el-table-column prop"attachment" label"合同附件" width"250" show-overflow-tooltip><template slot-scope"scope"><div v-if"scope.row.cceedcAppendixInfoList &&scope.row.ccee…...

HotSpot虚拟机之Class文件及字节码指令
目录 一、javac编译 1. 编译过程 2. 语法糖 二、Class文件 1. 文件格式 2. 常量池项目 3. 属性类型 三、Class文件实例 1. 源代码 2. javap分析Class文件 四、字节码指令 五、参考资料 一、javac编译 1. 编译过程 javac命令由Java语言编写,目的将Ja…...
关于盐雾试验
盐雾实验一般被称为盐雾试验,是一种主要利用盐雾试验设备所创造的人工模拟盐雾环境条件来考核产品或金属材料耐腐蚀性能的环境试验。 盐雾实验的主要目的是考核产品或金属材料的耐盐雾腐蚀性能,盐雾试验结果也是对产品质量的判定,是正确衡量…...
windows美化任务栏,不使用软件
1.任务栏透明: 效果图: (1).winr打开命令行 输入regedit回车打开注册表 regedit (2).在注册表中打开 \HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced 这个路径 \HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explore…...
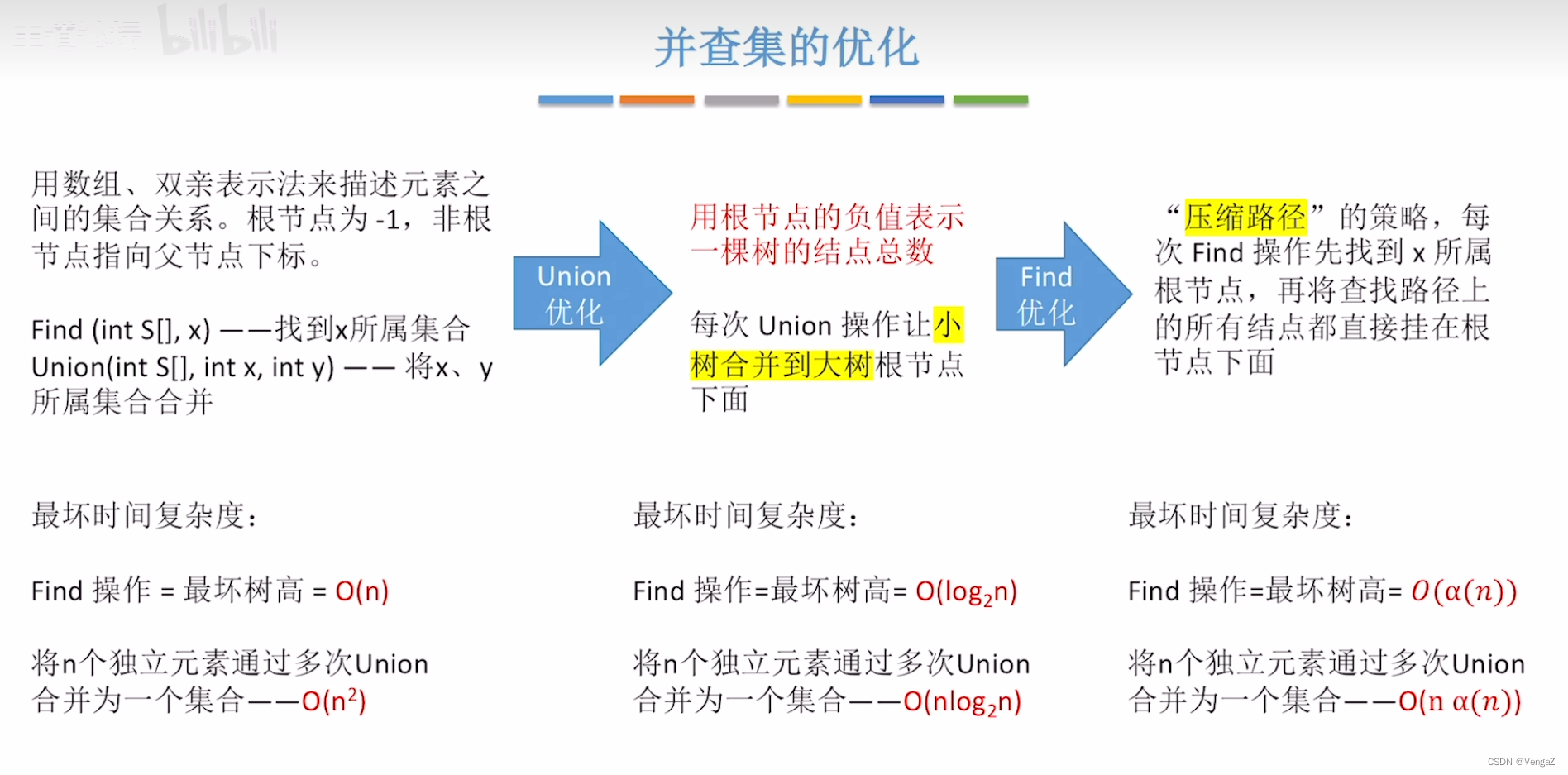
24考研数据结构-并查集
目录 5.5.2 并查集(双亲表示法)1. 并查集的存储结构2. 并查集的代码实现初始化并查时间复杂度union操作的优化(不要瘦高的树)并查集的进一步优化(find的优化,压缩路径)优化总结 数据结构&#x…...
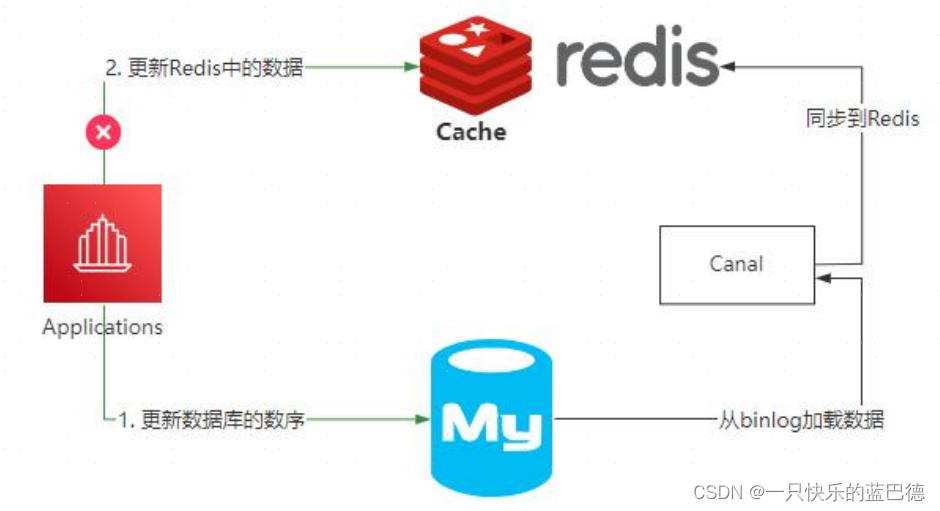
Redis 和 Mysql 如何保证数据一致性
项目场景: 一般情况下,Redis 用来实现应用和数据库之间读操作的缓存层,主要目的是减少数据库 IO,还可以提升数据的 IO 性能。 如下图所示,这是它的整体架构。 当应用程序需要去读取某个数据的时候,首先会先…...
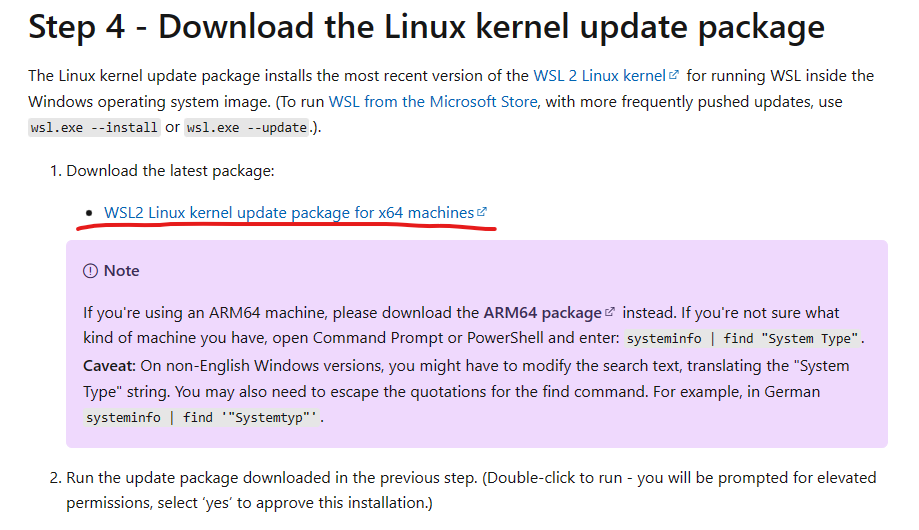
WSL1升级为WSL2
首先需要启用组件 使用管理员打开Powershell并运行 Enable-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform启用后会要求重启计算机 从https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi获取WSL2 Linux内核更新包,…...

力扣 1049. 最后一块石头的重量 II
题目来源:https://leetcode.cn/problems/last-stone-weight-ii/description/ C题解(思路来源代码随想录):本题其实就是尽量让石头分成重量相同的两堆,相撞之后剩下的石头最小,这样就化解成01背包问题了。 …...
【广州华锐视点】葡萄种植VR虚拟仿真实训平台
随着虚拟现实(VR)技术的不断发展,越来越多的教育领域开始尝试将VR技术应用于教学中。在葡萄栽培这一专业领域,我们开发了一款创新的VR实训课件,旨在为学生提供沉浸式的互动学习体验。本篇文案将为您介绍葡萄种植VR虚拟仿真实训平台所提供的互…...
在并网系统中的应用与优化)
逆变器核心技术解析:锁相环(PLL)在并网系统中的应用与优化
1. 锁相环(PLL)在并网逆变器中的核心作用 想象一下你正在参加一场合唱比赛,如果每个人的节奏都不一致,整个表演就会变得杂乱无章。并网逆变器面临的也是类似的问题——它需要与电网保持完美的"节奏同步",而这个"指挥家"就…...

别再傻傻分不清:DNS、RANS、LES到底该用FDM还是FVM来算?
湍流模拟方法选择指南:DNS、RANS、LES与FDM、FVM的实战搭配策略 在计算流体力学(CFD)的实际工程应用中,选择合适的湍流模型与数值方法是每个工程师都会面临的挑战。面对复杂的流体流动问题,如何在计算精度、资源消耗和…...

使用GitHub Actions实现SDMatte模型的CI/CD自动化流水线
使用GitHub Actions实现SDMatte模型的CI/CD自动化流水线 1. 为什么需要自动化流水线 在机器学习项目开发中,团队经常面临这样的困境:每次代码更新后,需要手动运行测试、构建镜像、部署环境,这个过程不仅耗时耗力,还容…...

5*5窗口的高斯滤波模板
本文介绍了一个55高斯模板的生成过程。首先以标准差σ3创建初始模板矩阵,通过双重循环计算每个位置的高斯函数值。随后对模板进行归一化处理,确保系数总和为1。最后将归一化后的模板进行1024倍定点化处理,便于后续数字信号处理应用。该代码实…...

Lingyuxiu MXJ LoRA效果惊艳展示:高清细腻真人人像生成作品集
Lingyuxiu MXJ LoRA效果惊艳展示:高清细腻真人人像生成作品集 1. 项目简介 Lingyuxiu MXJ LoRA是一款专门为生成唯美真人风格人像而设计的轻量级AI图像生成系统。这个项目最大的特点是能够创造出五官细腻、光影柔和、质感逼真的人像作品,而且完全不需要…...

终极write-good CLI指南:10个快速提升英语写作质量的命令行技巧
终极write-good CLI指南:10个快速提升英语写作质量的命令行技巧 【免费下载链接】write-good Naive linter for English prose 项目地址: https://gitcode.com/gh_mirrors/wr/write-good write-good是一款专为开发者打造的英语写作质量检查工具,它…...

OpenClaw隐私保护:千问3.5-9B本地化处理敏感数据方案
OpenClaw隐私保护:千问3.5-9B本地化处理敏感数据方案 1. 为什么我们需要本地化AI处理 去年处理一份投资协议时,我犯了个致命错误——将包含客户隐私条款的合同上传到某云端AI工具进行摘要生成。三天后,法务团队在公开搜索引擎的缓存记录中发…...

Obsidian 零基础入门教程
Obsidian 零基础入门教程 目录 前言:为什么选择 Obsidian核心概念与基础操作 笔记即数据库双向链接创建你的第一个笔记库Markdown 基础语法内部链接与反向链接 核心功能实践指南 图谱视图标签的使用安装与配置核心插件 工作流示例:管理读书笔记后续学习…...

2026届必备的十大AI科研网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 伴随人工智能技术的迅猛发展,AI论文工具已然成为学术写作范畴的关键辅助方式&…...

深度学习_YOLO,卡尔曼滤波和
1.YOLO 1.1 简介 YOLO系列算法是一类典型的one-stage目标检测算法,其利用anchor box将分类与目标定位的回归问题结合起来,从而做到了高效、灵活和泛化性能好,所以在工业界也十分受欢迎. Yolo算法采用一个单独的CNN模型实现end-to-end的目标检…...