C/C++实现librosa音频处理库melspectrogram和mfcc
C/C++实现librosa音频处理库melspectrogram和mfcc
目录
C/C++实现librosa音频处理库melspectrogram和mfcc
1.项目结构
2.依赖环境
3.C++ librosa音频处理库实现
(1) 对齐读取音频文件
(2) 对齐melspectrogram
(3) 对齐MFCC
4.Demo运行
5.librosa库C++源码下载
深度学习语音处理中,经常要用到音频处理库librosa,奈何librosa目前仅有python版本;而语音识别算法开发中,经常要用到melspectrogram和MFCC这些音频信息,因此需要实现C/C++版本melspectrogram和MFCC;网上已经存在很多版本的C/C++的melspectrogram和MFCC,但测试发现跟Python的librosa的处理结果存在很大差异;经过多次优化测试,本项目实现了C/C++版本的音频处理库librosa中load、melspectrogram和mfcc的功能,项目基本完整对齐Pyhon音频处理库librosa三个功能:
- librosa.load:实现语音读取
- librosa.feature.melspectrogram:实现计算melspectrogram
- librosa.feature.mfcc:实现计算MFCC

【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/132077896
1.项目结构
2.依赖环境
项目需要安装Python和C/C++相关的依赖包
Python依赖库,使用pip install即可
numpy==1.16.3
matplotlib==3.1.0
Pillow==6.0.0
easydict==1.9
opencv-contrib-python==4.5.2.52
opencv-python==4.5.1.48
pandas==1.1.5
PyYAML==5.3.1
scikit-image==0.17.2
scikit-learn==0.24.0
scipy==1.5.4
seaborn==0.11.2
tqdm==4.55.1
xmltodict==0.12.0
pybaseutils==0.7.6
librosa==0.8.1
pyaudio==0.2.11
pydub==0.23.1
C++依赖库,主要用到Eigen3和OpenCV
- Eigen3:用于矩阵计算,项目已经支持Eigen3,无须安装
- OpenCV: 用于显示图像,安装方法请参考Ubuntu18.04安装opencv和opencv_contrib
3.C++ librosa音频处理库实现
(1) 对齐读取音频文件
Python中可使用librosa.load读取音频文件
data, sr = librosa.load(path, sr, mono)Python实现读取音频文件:
# -*-coding: utf-8 -*-
import numpy as np
import librosadef read_audio(audio_file, sr=16000, mono=True):"""默认将多声道音频文件转换为单声道,并返回一维数组;如果你需要处理多声道音频文件,可以使用 mono=False,参数来保留所有声道,并返回二维数组。:param audio_file::param sr: sampling rate:param mono: 设置为true是单通道,否则是双通道:return:"""audio_data, sr = librosa.load(audio_file, sr=sr, mono=mono)audio_data = audio_data.T.reshape(-1)return audio_data, srdef print_vector(name, data):np.set_printoptions(precision=7, suppress=False)print("------------------------%s------------------------\n" % name)print("{}".format(data.tolist()))if __name__ == '__main__':sr = Noneaudio_file = "data/data_s1.wav"data, sr = read_audio(audio_file, sr=sr, mono=False)print("sr = %d, data size=%d" % (sr, len(data)))print_vector("audio data", data)
C/C++读取音频文件:需要根据音频的数据格式进行解码,参考:C语言解析wav文件格式 ,本项目已经实现C/C++版本的读取音频数据,可支持单声道和双声道音频数据(mono)
/*** 读取音频文件,目前仅支持wav格式文件* @param filename wav格式文件* @param out 输出音频数据* @param sr 输出音频采样率* @param mono 设置为true是单通道,否则是双通道* @return*/
int read_audio(const char *filename, vector<float> &out, int *sr, bool mono = true);#include <iostream>
#include <vector>
#include <algorithm>
#include "librosa/audio_utils.h"
#include "librosa/librosa.h"using namespace std;int main() {int sr = -1;string audio_file = "../data/data_s1.wav";vector<float> data;int res = read_audio(audio_file.c_str(), data, &sr, false);if (res < 0) {printf("read wav file error: %s\n", audio_file.c_str());return -1;}printf("sr = %d, data size=%d\n", sr, data.size());print_vector("audio data", data);return 0;
}
测试和对比Python和C++版本读取音频文件数据,经过多轮测试,二者的读取的音频数值差异已经很小,基本已经对齐python librosa库的librosa.load()函数
| 数值对比 | |
| C++版本 | 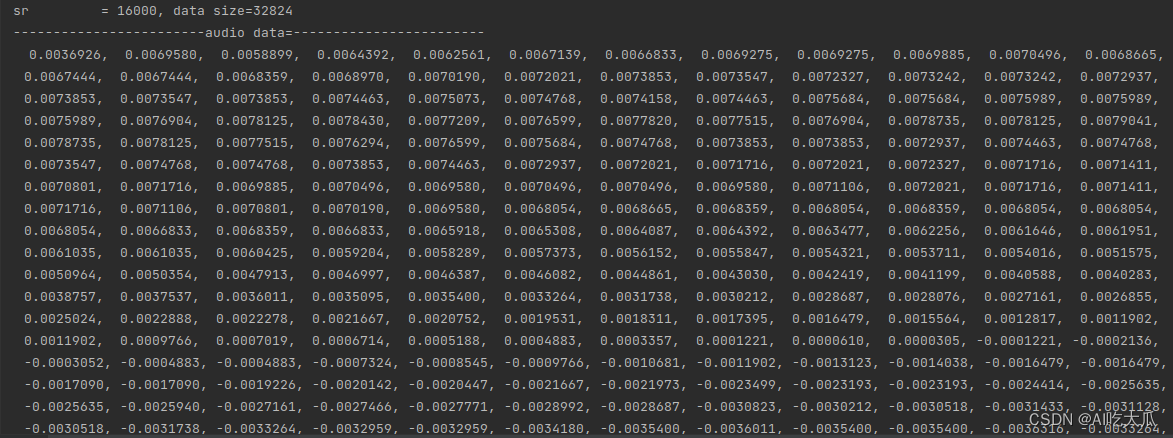 |
| Python版本 | 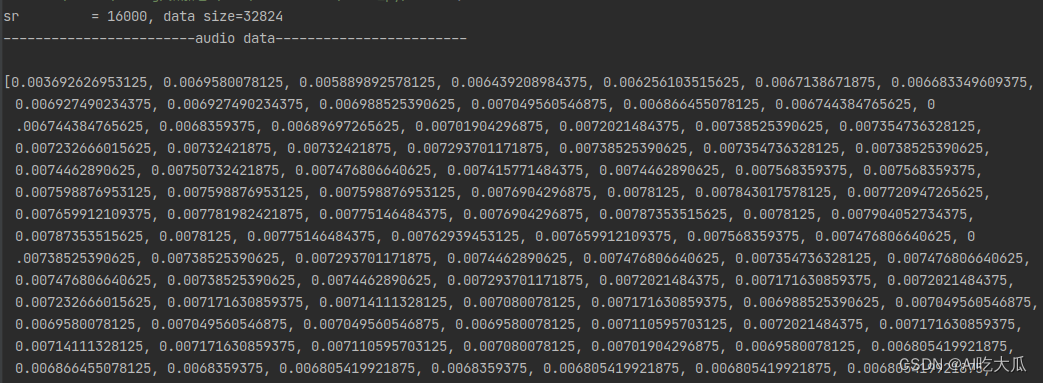 |
(2) 对齐melspectrogram
关于melspectrogram梅尔频谱的相关原理,请参考基于梅尔频谱的音频信号分类识别(Pytorch)
Python的librosa库的提供了librosa.feature.melspectrogram()函数,返回一个二维数组,可以使用OpenCV显示该图像
def librosa_feature_melspectrogram(y,sr=16000,n_mels=128,n_fft=2048,hop_length=256,win_length=None,window="hann",center=True,pad_mode="reflect",power=2.0,fmin=0.0,fmax=None,**kwargs):"""计算音频梅尔频谱图(Mel Spectrogram):param y: 音频时间序列:param sr: 采样率:param n_mels: number of Mel bands to generate产生的梅尔带数:param n_fft: length of the FFT window FFT窗口的长度:param hop_length: number of samples between successive frames 帧移(相邻窗之间的距离):param win_length: 窗口的长度为win_length,默认win_length = n_fft:param window::param center: 如果为True,则填充信号y,以使帧 t以y [t * hop_length]为中心。如果为False,则帧t从y [t * hop_length]开始:param pad_mode::param power: 幅度谱的指数。例如1代表能量,2代表功率,等等:param fmin: 最低频率(Hz):param fmax: 最高频率(以Hz为单位),如果为None,则使用fmax = sr / 2.0:param kwargs::return: 返回Mel频谱shape=(n_mels,n_frames),n_mels是Mel频率的维度(频域),n_frames为时间帧长度(时域)"""mel = librosa.feature.melspectrogram(y=y,sr=sr,S=None,n_mels=n_mels,n_fft=n_fft,hop_length=hop_length,win_length=win_length,window=window,center=center,pad_mode=pad_mode,power=power,fmin=fmin,fmax=fmax,**kwargs)return mel
根据Python版本的librosa.feature.melspectrogram(),项目实现了C++版本melspectrogram
/**** compute mel spectrogram similar with librosa.feature.melspectrogram* @param x input audio signal* @param sr sample rate of 'x'* @param n_fft length of the FFT size* @param n_hop number of samples between successive frames* @param win window function. currently only supports 'hann'* @param center same as librosa* @param mode pad mode. support "reflect","symmetric","edge"* @param power exponent for the magnitude melspectrogram* @param n_mels number of mel bands* @param fmin lowest frequency (in Hz)* @param fmax highest frequency (in Hz)* @return mel spectrogram matrix*/
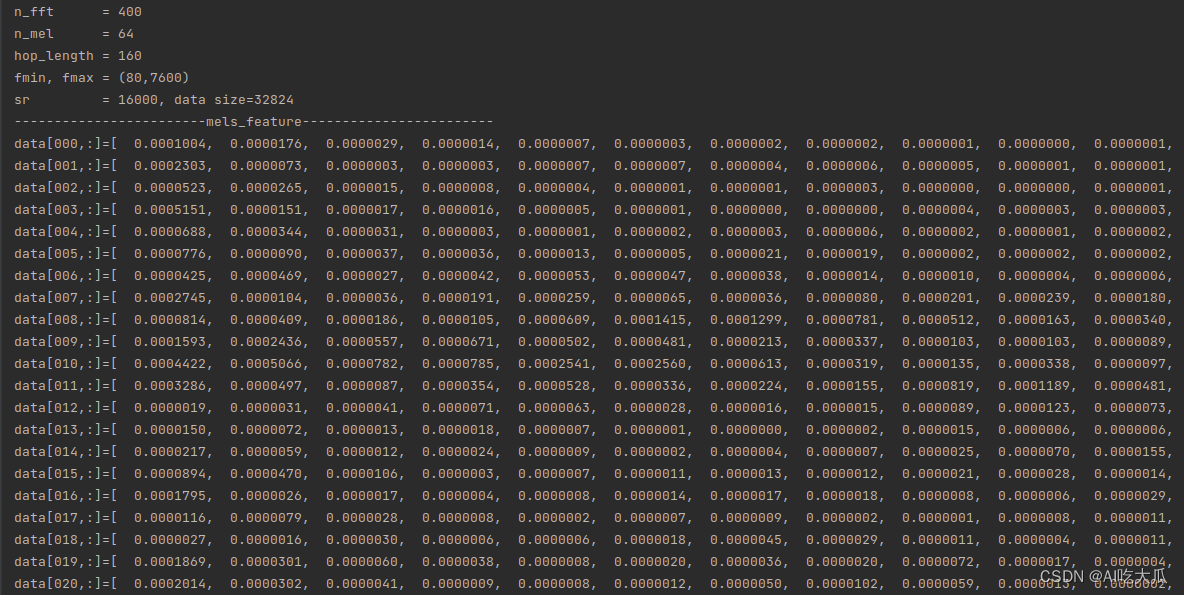
static std::vector <std::vector<float>> melspectrogram(std::vector<float> &x, int sr,int n_fft, int n_hop, const std::string &win, bool center,const std::string &mode,float power, int n_mels, int fmin, int fmax)测试和对比Python和C++版本melspectrogram,二者的返回数值差异已经很小,其可视化的梅尔频谱图基本一致。
| 版本 | 数值对比 |
| C++版本 |
|
| Python版本 |
|

(3) 对齐MFCC
Python版可使用librosa库的librosa.feature.mfcc实现MFCC(Mel-frequency cepstral coefficients)
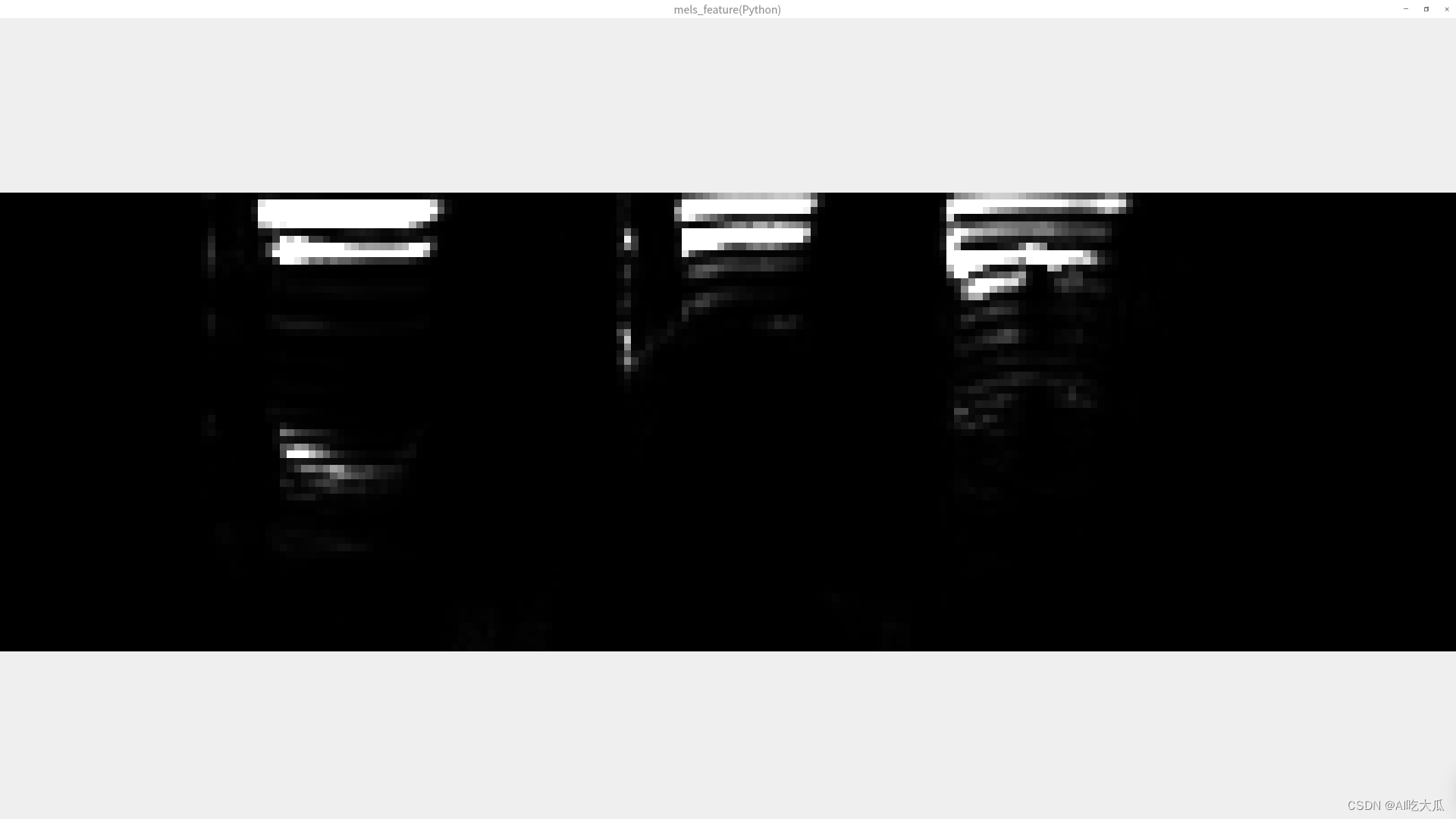
def librosa_feature_mfcc(y,sr=16000,n_mfcc=128,n_mels=128,n_fft=2048,hop_length=256,win_length=None,window="hann",center=True,pad_mode="reflect",power=2.0,fmin=0.0,fmax=None,dct_type=2,**kwargs):"""计算音频MFCC:param y: 音频时间序列:param sr: 采样率:param n_mfcc: number of MFCCs to return:param n_mels: number of Mel bands to generate产生的梅尔带数:param n_fft: length of the FFT window FFT窗口的长度:param hop_length: number of samples between successive frames 帧移(相邻窗之间的距离):param win_length: 窗口的长度为win_length,默认win_length = n_fft:param window::param center: 如果为True,则填充信号y,以使帧 t以y [t * hop_length]为中心。如果为False,则帧t从y [t * hop_length]开始:param pad_mode::param power: 幅度谱的指数。例如1代表能量,2代表功率,等等:param fmin: 最低频率(Hz):param fmax: 最高频率(以Hz为单位),如果为None,则使用fmax = sr / 2.0:param kwargs::return: 返回MFCC shape=(n_mfcc,n_frames)"""# MFCC 梅尔频率倒谱系数mfcc = librosa.feature.mfcc(y=y,sr=sr,S=None,n_mfcc=n_mfcc,n_mels=n_mels,n_fft=n_fft,hop_length=hop_length,win_length=win_length,window=window,center=center,pad_mode=pad_mode,power=power,fmin=fmin,fmax=fmax,dct_type=dct_type,**kwargs)return mfcc
根据Python版本的librosa.feature.mfcc(),项目实现了C++版本MFCC
/**** compute mfcc similar with librosa.feature.mfcc* @param x input audio signal* @param sr sample rate of 'x'* @param n_fft length of the FFT size* @param n_hop number of samples between successive frames* @param win window function. currently only supports 'hann'* @param center same as librosa* @param mode pad mode. support "reflect","symmetric","edge"* @param power exponent for the magnitude melspectrogram* @param n_mels number of mel bands* @param fmin lowest frequency (in Hz)* @param fmax highest frequency (in Hz)* @param n_mfcc number of mfccs* @param norm ortho-normal dct basis* @param type dct type. currently only supports 'type-II'* @return mfcc matrix*/
static std::vector<std::vector<float>> mfcc(std::vector<float> &x, int sr,int n_fft, int n_hop, const std::string &win, bool center, const std::string &mode,float power, int n_mels, int fmin, int fmax,int n_mfcc, bool norm, int type)测试和对比Python和C++版本MFCC,二者的返回数值差异已经很小,其可视化的MFCC图基本一致。
| 版本 | 数值对比 |
| C++版本 |
|
| Python版本 |
|


4.Demo运行
- C++版本,可在项目根目录,终端输入:bash build.sh ,即可运行测试demo
#!/usr/bin/env bash
if [ ! -d "build/" ];thenmkdir "build"
elseecho "exist build"
fi
cd build
cmake ..
make -j4
sleep 1./mainmain函数
/***** @Author : 390737991@qq.com* @E-mail :* @Date :* @Brief : C/C++实现Melspectrogram和MFCC*/
#include <iostream>
#include <vector>
#include <algorithm>
#include "librosa/audio_utils.h"
#include "librosa/librosa.h"
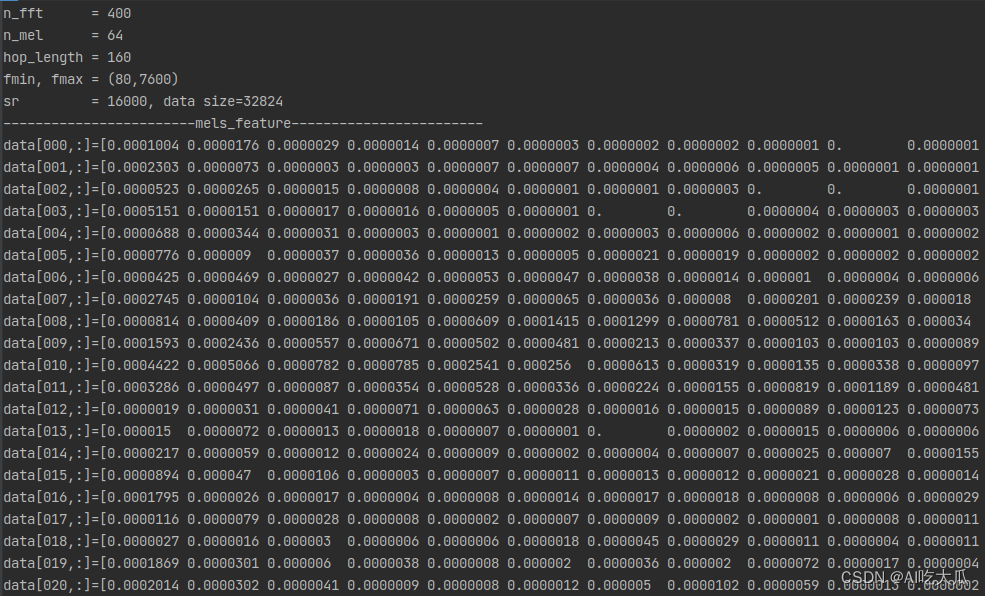
#include "librosa/cv_utils.h"using namespace std;int main() {int sr = -1;int n_fft = 400;int hop_length = 160;int n_mel = 64;int fmin = 80;int fmax = 7600;int n_mfcc = 64;int dct_type = 2;float power = 2.f;bool center = false;bool norm = true;string window = "hann";string pad_mode = "reflect";//string audio_file = "../data/data_d2.wav";string audio_file = "../data/data_s1.wav";vector<float> data;int res = read_audio(audio_file.c_str(), data, &sr, false);if (res < 0) {printf("read wav file error: %s\n", audio_file.c_str());return -1;}printf("n_fft = %d\n", n_fft);printf("n_mel = %d\n", n_mel);printf("hop_length = %d\n", hop_length);printf("fmin, fmax = (%d,%d)\n", fmin, fmax);printf("sr = %d, data size=%d\n", sr, data.size());//print_vector("audio data", data);// compute mel Melspectrogramvector<vector<float>> mels_feature = librosa::Feature::melspectrogram(data, sr, n_fft, hop_length, window,center, pad_mode, power, n_mel, fmin, fmax);int mels_w = (int) mels_feature.size();int mels_h = (int) mels_feature[0].size();cv::Mat mels_image = vector2mat<float>(get_vector(mels_feature), 1, mels_h);print_feature("mels_feature", mels_feature);printf("mels_feature size(n_frames,n_mels)=(%d,%d)\n", mels_w, mels_h);image_show("mels_feature(C++)", mels_image, 10);// compute MFCCvector<vector<float>> mfcc_feature = librosa::Feature::mfcc(data, sr, n_fft, hop_length, window, center, pad_mode,power, n_mel, fmin, fmax, n_mfcc, norm, dct_type);int mfcc_w = (int) mfcc_feature.size();int mfcc_h = (int) mfcc_feature[0].size();cv::Mat mfcc_image = vector2mat<float>(get_vector(mfcc_feature), 1, mfcc_h);print_feature("mfcc_feature", mfcc_feature);printf("mfcc_feature size(n_frames,n_mfcc)=(%d,%d)\n", mfcc_w, mfcc_h);image_show("mfcc_feature(C++)", mfcc_image, 10);cv::waitKey(0);printf("finish...");return 0;
}
- Python版本,可在项目根目录,终端输入:python main.py ,即可运行测试demo
# -*-coding: utf-8 -*-
"""@Author :@E-mail : @Date : 2023-08-01 22:27:56@Brief :
"""
import cv2
import numpy as np
import librosadef cv_show_image(title, image, use_rgb=False, delay=0):"""调用OpenCV显示图片:param title: 图像标题:param image: 输入是否是RGB图像:param use_rgb: True:输入image是RGB的图像, False:返输入image是BGR格式的图像:param delay: delay=0表示暂停,delay>0表示延时delay毫米:return:"""img = image.copy()if img.shape[-1] == 3 and use_rgb:img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) # 将BGR转为RGB# cv2.namedWindow(title, flags=cv2.WINDOW_AUTOSIZE)cv2.namedWindow(title, flags=cv2.WINDOW_NORMAL)cv2.imshow(title, img)cv2.waitKey(delay)return imgdef librosa_feature_melspectrogram(y,sr=16000,n_mels=128,n_fft=2048,hop_length=256,win_length=None,window="hann",center=True,pad_mode="reflect",power=2.0,fmin=0.0,fmax=None,**kwargs):"""计算音频梅尔频谱图(Mel Spectrogram):param y: 音频时间序列:param sr: 采样率:param n_mels: number of Mel bands to generate产生的梅尔带数:param n_fft: length of the FFT window FFT窗口的长度:param hop_length: number of samples between successive frames 帧移(相邻窗之间的距离):param win_length: 窗口的长度为win_length,默认win_length = n_fft:param window::param center: 如果为True,则填充信号y,以使帧 t以y [t * hop_length]为中心。如果为False,则帧t从y [t * hop_length]开始:param pad_mode::param power: 幅度谱的指数。例如1代表能量,2代表功率,等等:param fmin: 最低频率(Hz):param fmax: 最高频率(以Hz为单位),如果为None,则使用fmax = sr / 2.0:param kwargs::return: 返回Mel频谱shape=(n_mels,n_frames),n_mels是Mel频率的维度(频域),n_frames为时间帧长度(时域)"""mel = librosa.feature.melspectrogram(y=y,sr=sr,S=None,n_mels=n_mels,n_fft=n_fft,hop_length=hop_length,win_length=win_length,window=window,center=center,pad_mode=pad_mode,power=power,fmin=fmin,fmax=fmax,**kwargs)return meldef librosa_feature_mfcc(y,sr=16000,n_mfcc=128,n_mels=128,n_fft=2048,hop_length=256,win_length=None,window="hann",center=True,pad_mode="reflect",power=2.0,fmin=0.0,fmax=None,dct_type=2,**kwargs):"""计算音频MFCC:param y: 音频时间序列:param sr: 采样率:param n_mfcc: number of MFCCs to return:param n_mels: number of Mel bands to generate产生的梅尔带数:param n_fft: length of the FFT window FFT窗口的长度:param hop_length: number of samples between successive frames 帧移(相邻窗之间的距离):param win_length: 窗口的长度为win_length,默认win_length = n_fft:param window::param center: 如果为True,则填充信号y,以使帧 t以y [t * hop_length]为中心。如果为False,则帧t从y [t * hop_length]开始:param pad_mode::param power: 幅度谱的指数。例如1代表能量,2代表功率,等等:param fmin: 最低频率(Hz):param fmax: 最高频率(以Hz为单位),如果为None,则使用fmax = sr / 2.0:param kwargs::return: 返回MFCC shape=(n_mfcc,n_frames)"""# MFCC 梅尔频率倒谱系数mfcc = librosa.feature.mfcc(y=y,sr=sr,S=None,n_mfcc=n_mfcc,n_mels=n_mels,n_fft=n_fft,hop_length=hop_length,win_length=win_length,window=window,center=center,pad_mode=pad_mode,power=power,fmin=fmin,fmax=fmax,dct_type=dct_type,**kwargs)return mfccdef read_audio(audio_file, sr=16000, mono=True):"""默认将多声道音频文件转换为单声道,并返回一维数组;如果你需要处理多声道音频文件,可以使用 mono=False,参数来保留所有声道,并返回二维数组。:param audio_file::param sr: sampling rate:param mono: 设置为true是单通道,否则是双通道:return:"""audio_data, sr = librosa.load(audio_file, sr=sr, mono=mono)audio_data = audio_data.T.reshape(-1)return audio_data, srdef print_feature(name, feature):h, w = feature.shape[:2]np.set_printoptions(precision=7, suppress=True, linewidth=(11 + 3) * w)print("------------------------{}------------------------".format(name))for i in range(w):v = feature[:, i].reshape(-1)print("data[{:0=3d},:]={}".format(i, v))def print_vector(name, data):np.set_printoptions(precision=7, suppress=False)print("------------------------%s------------------------\n" % name)print("{}".format(data.tolist()))if __name__ == '__main__':sr = Nonen_fft = 400hop_length = 160n_mel = 64fmin = 80fmax = 7600n_mfcc = 64dct_type = 2power = 2.0center = Falsenorm = Truewindow = "hann"pad_mode = "reflect"audio_file = "data/data_s1.wav"data, sr = read_audio(audio_file, sr=sr, mono=False)print("n_fft = %d" % n_fft)print("n_mel = %d" % n_mel)print("hop_length = %d" % hop_length)print("fmin, fmax = (%d,%d)" % (fmin, fmax))print("sr = %d, data size=%d" % (sr, len(data)))# print_vector("audio data", data)mels_feature = librosa_feature_melspectrogram(y=data,sr=sr,n_mels=n_mel,n_fft=n_fft,hop_length=hop_length,win_length=None,fmin=fmin,fmax=fmax,window=window,center=center,pad_mode=pad_mode,power=power)print_feature("mels_feature", mels_feature)print("mels_feature size(n_frames,n_mels)=({},{})".format(mels_feature.shape[1], mels_feature.shape[0]))cv_show_image("mels_feature(Python)", mels_feature, delay=10)mfcc_feature = librosa_feature_mfcc(y=data,sr=sr,n_mfcc=n_mfcc,n_mels=n_mel,n_fft=n_fft,hop_length=hop_length,win_length=None,fmin=fmin,fmax=fmax,window=window,center=center,pad_mode=pad_mode,power=power,dct_type=dct_type)print_feature("mfcc_feature", mfcc_feature)print("mfcc_feature size(n_frames,n_mfcc)=({},{})".format(mfcc_feature.shape[1], mfcc_feature.shape[0]))cv_show_image("mfcc_feature(Python)", mfcc_feature, delay=10)cv2.waitKey(0)
5.librosa库C++源码下载
C/C++实现librosa音频处理库melspectrogram和mfcc项目代码下载地址:C/C++实现librosa音频处理库melspectrogram和mfcc
项目源码内容包含:
- 提供C++版的read_audio()函数读取音频文件,目前仅支持wav格式文件,支持单/双声道音频读取
- 提供C++版的librosa::Feature::melspectrogram(),实现melspectrogram功能
- 提供C++版的librosa::Feature::mfcc(),实现MFCC功能
- 提供OpenCV图谱显示方式
- 项目demo自带测试数据,编译build完成后,即可运行
相关文章:

C/C++实现librosa音频处理库melspectrogram和mfcc
C/C实现librosa音频处理库melspectrogram和mfcc 目录 C/C实现librosa音频处理库melspectrogram和mfcc 1.项目结构 2.依赖环境 3.C librosa音频处理库实现 (1) 对齐读取音频文件 (2) 对齐melspectrogram (3) 对齐MFCC 4.Demo运行 5.librosa库C源码下载 深度学习语音处…...

浪潮服务器硬盘指示灯显示黄色的服务器数据恢复案例
服务器数据恢复环境: 宁夏某市某单位的一台浪潮服务器,该服务器中有一组由6块SAS硬盘组建的RAID5阵列。 服务器上存放的是Oracle数据库文件,操作系统层面划分了1个卷。 服务器故障&初检: 服务器在运行过程中有两块磁盘的指示灯…...

宋浩概率论笔记(三)随机向量/二维随机变量
第三更:本章的内容最重要的在于概念的理解与抽象,二重积分通常情况下不会考得很难。此外,本次暂且忽略【二维连续型随机变量函数的分布】这一章节,非常抽象且难度较高,之后有时间再更新。...

附件展示 点击下载
效果图 实现代码 <el-table-column prop"attachment" label"合同附件" width"250" show-overflow-tooltip><template slot-scope"scope"><div v-if"scope.row.cceedcAppendixInfoList &&scope.row.ccee…...

HotSpot虚拟机之Class文件及字节码指令
目录 一、javac编译 1. 编译过程 2. 语法糖 二、Class文件 1. 文件格式 2. 常量池项目 3. 属性类型 三、Class文件实例 1. 源代码 2. javap分析Class文件 四、字节码指令 五、参考资料 一、javac编译 1. 编译过程 javac命令由Java语言编写,目的将Ja…...
关于盐雾试验
盐雾实验一般被称为盐雾试验,是一种主要利用盐雾试验设备所创造的人工模拟盐雾环境条件来考核产品或金属材料耐腐蚀性能的环境试验。 盐雾实验的主要目的是考核产品或金属材料的耐盐雾腐蚀性能,盐雾试验结果也是对产品质量的判定,是正确衡量…...
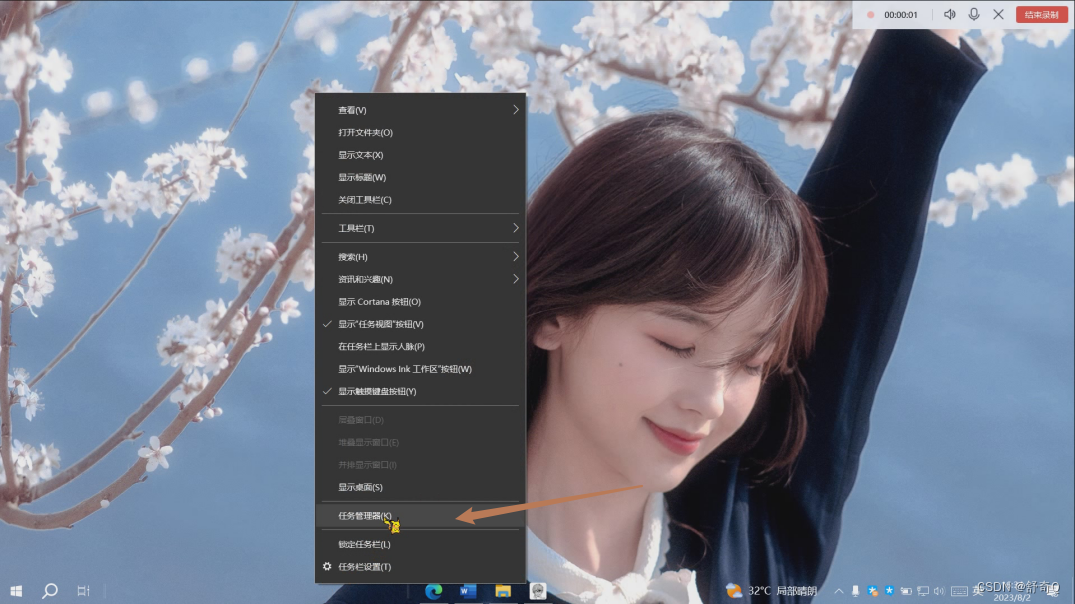
windows美化任务栏,不使用软件
1.任务栏透明: 效果图: (1).winr打开命令行 输入regedit回车打开注册表 regedit (2).在注册表中打开 \HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced 这个路径 \HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explore…...
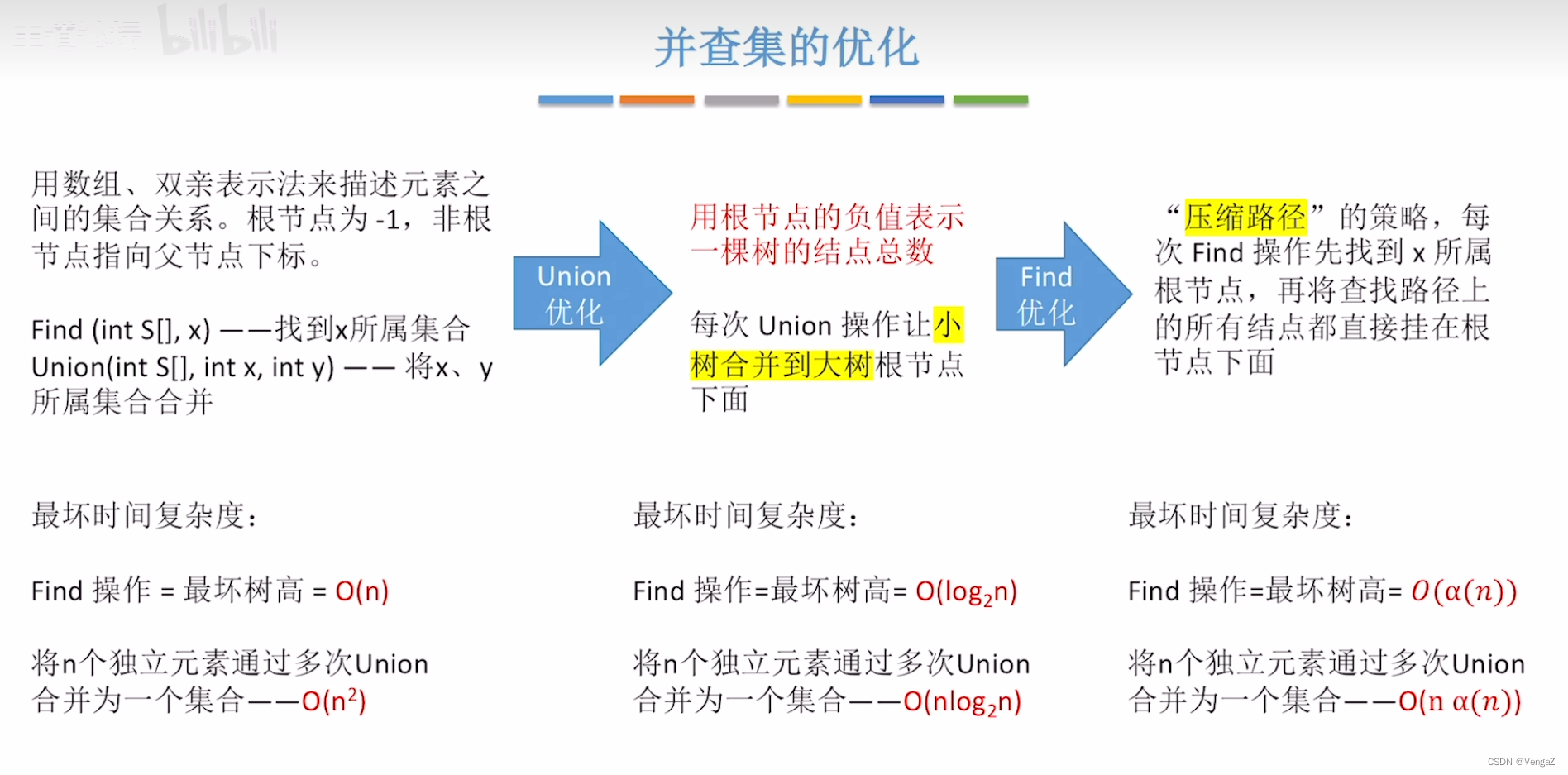
24考研数据结构-并查集
目录 5.5.2 并查集(双亲表示法)1. 并查集的存储结构2. 并查集的代码实现初始化并查时间复杂度union操作的优化(不要瘦高的树)并查集的进一步优化(find的优化,压缩路径)优化总结 数据结构&#x…...
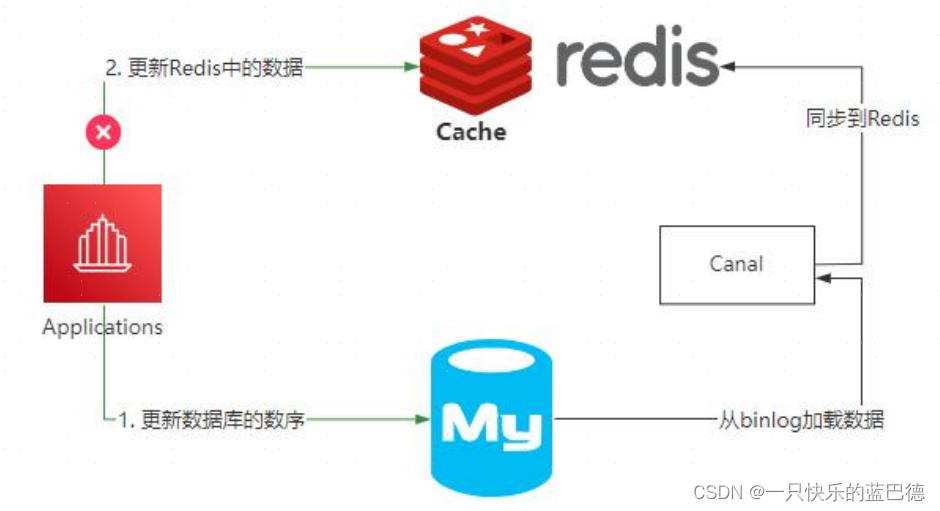
Redis 和 Mysql 如何保证数据一致性
项目场景: 一般情况下,Redis 用来实现应用和数据库之间读操作的缓存层,主要目的是减少数据库 IO,还可以提升数据的 IO 性能。 如下图所示,这是它的整体架构。 当应用程序需要去读取某个数据的时候,首先会先…...
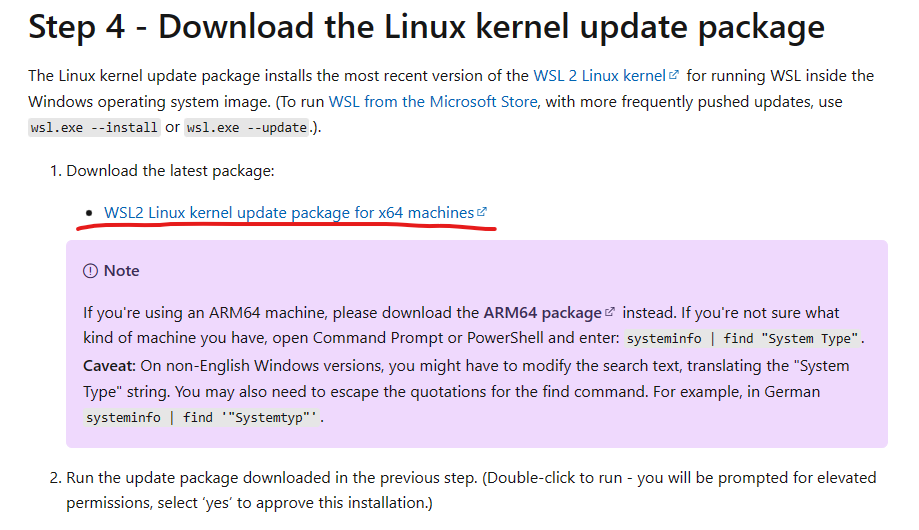
WSL1升级为WSL2
首先需要启用组件 使用管理员打开Powershell并运行 Enable-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform启用后会要求重启计算机 从https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi获取WSL2 Linux内核更新包,…...

力扣 1049. 最后一块石头的重量 II
题目来源:https://leetcode.cn/problems/last-stone-weight-ii/description/ C题解(思路来源代码随想录):本题其实就是尽量让石头分成重量相同的两堆,相撞之后剩下的石头最小,这样就化解成01背包问题了。 …...
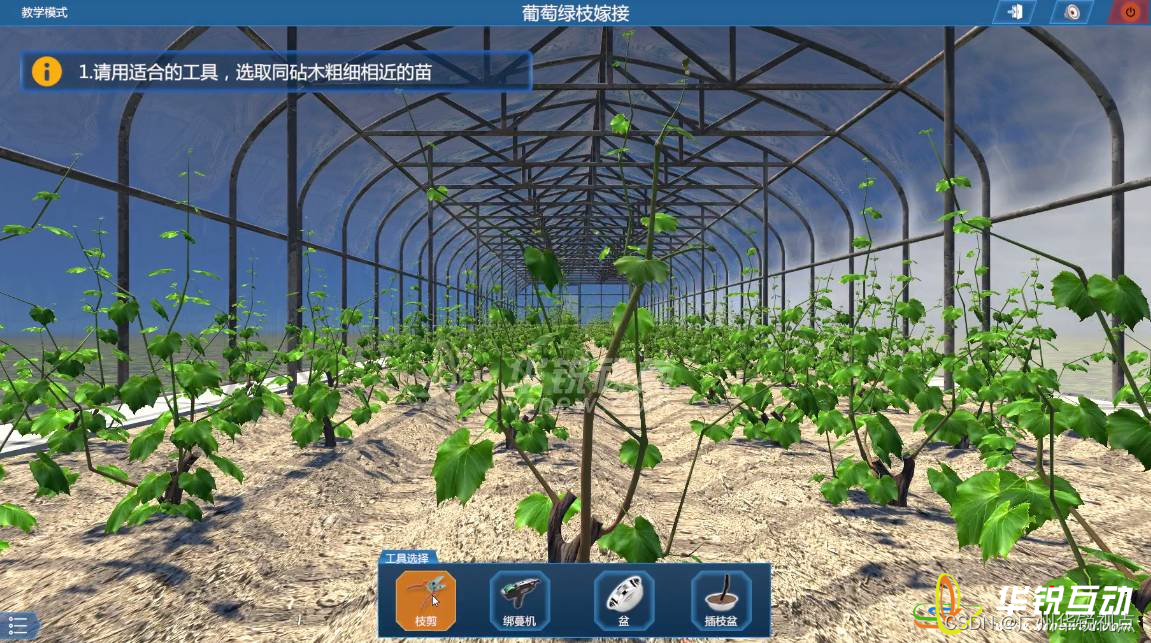
【广州华锐视点】葡萄种植VR虚拟仿真实训平台
随着虚拟现实(VR)技术的不断发展,越来越多的教育领域开始尝试将VR技术应用于教学中。在葡萄栽培这一专业领域,我们开发了一款创新的VR实训课件,旨在为学生提供沉浸式的互动学习体验。本篇文案将为您介绍葡萄种植VR虚拟仿真实训平台所提供的互…...
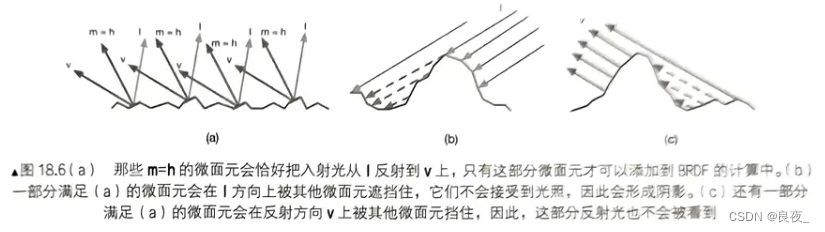
PBR材质理解整理
PBR Material 草履虫都能看懂的PBR讲解(迫真) 先前看了很多遍类似的了,结合《Unity Shader 入门精要》中的内容整理了下便于以后理解,以后有补充再添加。 光与材质相交会发生散射和吸收,散射改变光的方向,…...

从c++的角度来看ffmpeg 的架构
------------------------------------------------------------------------- author: hjjdebug date: 2023年 08月 01日 星期二 11:26:40 CST descriptor: 从c的角度来看ffmpeg 的架构 ------------------------------------------------------------------------…...

Ubuntu安装JDK与IntelliJ IDEA
目录 前言 Ubuntu 安装 JDK 1、更新软件包列表 2、安装OpenJDK 3、验证安装 Ubuntu安装IntelliJ IDEA 1、下载 IntelliJ IDEA 2、解压缩 IntelliJ IDEA 安装包 3、移动 IntelliJ IDEA 到安装目录 4、启动 IntelliJ IDEA 前言 APT(Advanced Package Tool&…...

【雕爷学编程】Arduino动手做(182)---DRV8833双路电机驱动模块2
37款传感器与执行器的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止这37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的&am…...

一个完整的http请求响应过程
一、 HTTP请求和响应步骤 以上完整表示了HTTP请求和响应的7个步骤,下面从TCP/IP协议模型的角度来理解HTTP请求和响应如何传递的。 二、TCP/IP协议 TCP/IP协议模型(Transmission Control Protocol/Internet Protocol),包含了一系…...

Unity通过代码切换材质
效果展示 代码 using System.Collections; using System.Collections.Generic; using UnityEngine;public class MaterialSwitcher : MonoBehaviour {public Material newMaterial; // 新材质private Material oldMaterial; // 旧材质private Renderer renderer; // 渲染器组件…...
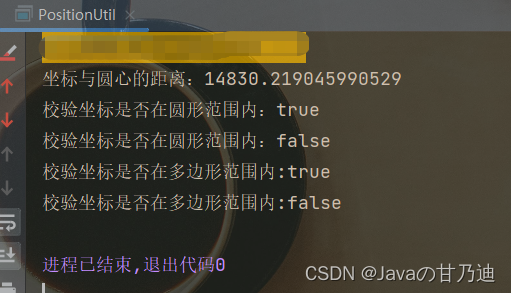
Java根据坐标经纬度计算两点距离(5种方法)、校验经纬度是否在圆/多边形区域内的算法推荐
目录 前言 一、根据坐标经纬度计算两点距离(5种方法) 1.方法一 2.方法二 3.方法三 4.方法四 5.方法五 5.1 POM引入第三方依赖 5.2 代码 6.测试结果对比 二、校验经纬度是否在制定区域内 1.判断一个坐标是否在圆形区域内 2.判断一个坐标是否…...

PIC单片机如何设计延时
PIC单片机如何设计延时 PIC单片机的延时基本有两种,一种是自己设计的delay()函数,另一种就是利用其自带的Time定时器。当然一般Time定时器的精度要高于自己设计delay()函数,Time定时器是单片机内部的硬件寄存器模块,而delay()函数是利用自加自减来实现延时,代码进行顺序执…...

【数据湖01】一文了解啥是数据湖~
说实话,我刚开始听到"数据湖"这个词也懵,以为是多高大上的东西。干了几年数据才发现,其实就是个"大杂烩仓库"。先讲个真事:老刘是怎么被数据搞崩溃的我兄弟老刘,某电商公司负责人。2022年业务暴涨…...

基于ip-iq变换的谐波检测算法,并联型APF/有源电力滤波器/谐波电流检测 matlab/
基于ip-iq变换的谐波检测算法,并联型APF/有源电力滤波器/谐波电流检测 matlab/ simulink仿真学习模型,其他检测方法也做了,有参考文献,适合自学。车间里变频器嗡嗡作响,流水线上的机械臂突然抽搐了两下。老师傅老张叼着…...

Qwen1.5-1.8B GPTQ模型轻量化部署效果:低显存占用下的性能保持
Qwen1.5-1.8B GPTQ模型轻量化部署效果:低显存占用下的性能保持 最近在折腾大模型本地部署的朋友,可能都遇到过同一个头疼的问题:模型效果不错,但显存要求太高,自己的显卡根本跑不起来。动辄几十GB的显存需求ÿ…...
)
ZGC实战:如何在大内存场景下实现毫秒级GC停顿(附调优参数详解)
ZGC深度调优:TB级堆内存下的毫秒级GC实战指南 引言:大内存时代的GC挑战 在当今云计算与大数据时代,Java应用堆内存规模正经历指数级增长。从早期的GB级到如今的TB级,传统垃圾回收器如G1、CMS已无法满足低延迟需求。某头部电商平台…...

终极write-good CLI指南:10个快速提升英语写作质量的命令行技巧
终极write-good CLI指南:10个快速提升英语写作质量的命令行技巧 【免费下载链接】write-good Naive linter for English prose 项目地址: https://gitcode.com/gh_mirrors/wr/write-good write-good是一款专为开发者打造的英语写作质量检查工具,它…...

OpenClaw技能扩展:Qwen3.5-9B代码生成+本地执行实战
OpenClaw技能扩展:Qwen3.5-9B代码生成本地执行实战 1. 为什么需要代码生成与自动执行? 作为一名长期与数据打交道的开发者,我每天要处理大量重复性脚本编写任务:数据清洗、格式转换、日志分析...这些工作往往占用了70%以上的编码…...

【独家首发】.NET 9 AOT编译边缘优化白皮书:静态链接、无GC堆、零依赖二进制生成全流程
第一章:.NET 9 AOT编译边缘优化全景概览.NET 9 将 AOT(Ahead-of-Time)编译能力推向生产级边缘场景,显著降低冷启动延迟、内存占用与部署包体积,尤其适用于 IoT 设备、Serverless 函数、嵌入式容器及轻量 WebAssembly 应…...
:MySQL、PG与Oracle原生审计机制对比)
数据库安全与运维管控(一):MySQL、PG与Oracle原生审计机制对比
在满足等保2.0、SOC2 或金融合规审查时,“开启数据库审计”是硬性指标。合规要求企业必须记录“谁、在什么时间、执行了什么SQL、结果如何”。面对这个需求,开发和运维通常首先想到的是利用数据库引擎自带的原生审计功能。但在海量并发(高 QP…...

告别迷茫!ESP-IDF下LVGL驱动ST7789/ILI9341屏幕的引脚配置与Menuconfig选项全解析
告别迷茫!ESP-IDF下LVGL驱动ST7789/ILI9341屏幕的引脚配置与Menuconfig选项全解析 第一次在ESP32上尝试LVGL时,面对密密麻麻的Menuconfig选项和复杂的引脚配置,相信不少开发者都会感到无从下手。本文将带你深入理解ESP-IDF框架下LVGL显示驱动…...
)
nCode后处理实战:5个云图显示问题及快速解决方法(附截图)
nCode后处理实战:5个云图显示问题及快速解决方法(附截图) 刚接触nCode的工程师常常会在后处理阶段遇到各种云图显示问题——全红/全蓝的单调色块、突然出现的NaN警告、无限寿命区域干扰有效数据观察……这些看似简单的可视化问题,…...