Flink - sink算子
水善利万物而不争,处众人之所恶,故几于道💦
文章目录
1. Kafka_Sink
2. Kafka_Sink - 自定义序列化器
3. Redis_Sink_String
4. Redis_Sink_list
5. Redis_Sink_set
6. Redis_Sink_hash
7. 有界流数据写入到ES
8. 无界流数据写入到ES
9. 自定义sink - mysql_Sink
10. Jdbc_Sink
官方文档 - Flink1.13

1. Kafka_Sink
addSink(new FlinkKafkaProducer< String>(kafka_address,topic,序列化器)
要先添加依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.13.6</version>
</dependency>
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);stream.keyBy(WaterSensor::getId).sum("vc").map(JSON::toJSONString).addSink(new FlinkKafkaProducer<String>("hadoop101:9092", // kafaka地址"flink_sink_kafka", //要写入的Kafkatopicnew SimpleStringSchema() // 序列化器));try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:

2. Kafka_Sink - 自定义序列化器
自定义序列化器,new FlinkKafkaProducer()的时候,选择四个参数的构造方法,然后使用new KafkaSerializationSchema序列化器。然后重写serialize方法
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);Properties sinkConfig = new Properties();sinkConfig.setProperty("bootstrap.servers","hadoop101:9092");stream.keyBy(WaterSensor::getId).sum("vc").addSink(new FlinkKafkaProducer<WaterSensor>("defaultTopic", // 默认发往的topic ,一般用不上new KafkaSerializationSchema<WaterSensor>() { // 自定义的序列化器@Overridepublic ProducerRecord<byte[], byte[]> serialize(WaterSensor waterSensor,@Nullable Long aLong) {String s = JSON.toJSONString(waterSensor);return new ProducerRecord<>("flink_sink_kafka",s.getBytes(StandardCharsets.UTF_8));}},sinkConfig, // Kafka的配置FlinkKafkaProducer.Semantic.AT_LEAST_ONCE // 一致性语义:现在只能传入至少一次));try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:
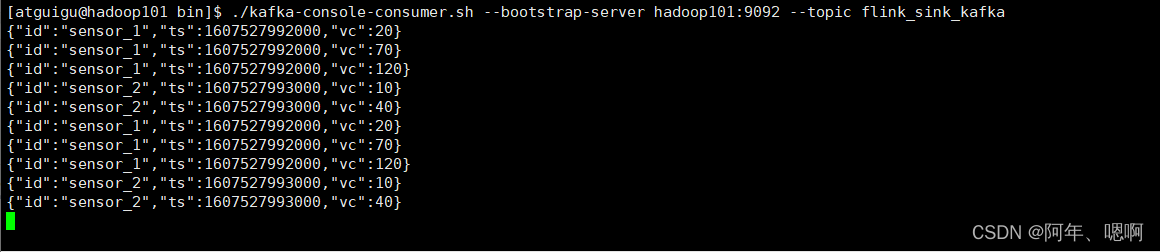
3. Redis_Sink_String
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到String结构里面
添加依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.83</version>
</dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.1.5</version>
</dependency>
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);SingleOutputStreamOperator<WaterSensor> result = stream.keyBy(WaterSensor::getId).sum("vc");/*
往redis里面写字符串,string 命令提示符用set
假设写的key是id,value是整个json格式的字符串
key value
sensor_1 json格式字符串*/// new一个单机版的配置FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder().setHost("hadoop101").setPort(6379).setMaxTotal(100) //最大连接数量.setMaxIdle(10) // 连接池里面的最大空闲.setMinIdle(2) // 连接池里面的最小空闲.setTimeout(10*1000) // 超时时间.build();// 写出到redis中result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {// 返回命令描述符:往不同的数据结构写数据用的方法不一样@Overridepublic RedisCommandDescription getCommandDescription() {// 写入到字符串,用setreturn new RedisCommandDescription(RedisCommand.SET);}@Overridepublic String getKeyFromData(WaterSensor waterSensor) {return waterSensor.getId();}@Overridepublic String getValueFromData(WaterSensor waterSensor) {return JSON.toJSONString(waterSensor);}}));try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:
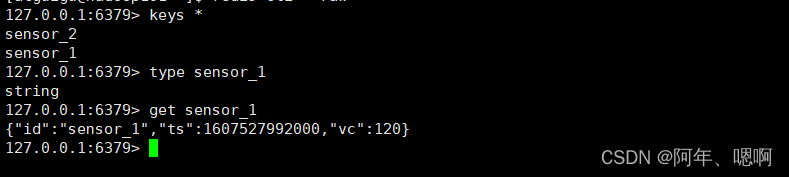
4. Redis_Sink_list
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到 list 结构里面
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);SingleOutputStreamOperator<WaterSensor> result = stream.keyBy(WaterSensor::getId).sum("vc");// key是id,value是处理后的json格式字符串FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder().setHost("hadoop101").setPort(6379).setMaxTotal(100) //最大连接数量.setMaxIdle(10) // 连接池里面的最大空闲.setMinIdle(2) // 连接池里面的最小空闲.setTimeout(10*1000) // 超时时间.build();result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {@Overridepublic RedisCommandDescription getCommandDescription() {// 写入listreturn new RedisCommandDescription(RedisCommand.RPUSH);}@Overridepublic String getKeyFromData(WaterSensor waterSensor) {return waterSensor.getId();}@Overridepublic String getValueFromData(WaterSensor waterSensor) {return JSON.toJSONString(waterSensor);}}));try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:
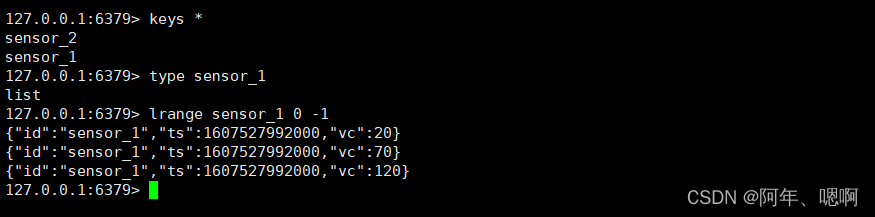
5. Redis_Sink_set
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到 set 结构里面
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);SingleOutputStreamOperator<WaterSensor> result = stream.keyBy(WaterSensor::getId).sum("vc");FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder().setHost("hadoop101").setPort(6379).setMaxTotal(100).setMaxIdle(10).setMinIdle(2).setTimeout(10*1000).build();result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {@Overridepublic RedisCommandDescription getCommandDescription() {// 数据写入set集合return new RedisCommandDescription(RedisCommand.SADD);}@Overridepublic String getKeyFromData(WaterSensor waterSensor) {return waterSensor.getId();}@Overridepublic String getValueFromData(WaterSensor waterSensor) {return JSON.toJSONString(waterSensor);}}));try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:

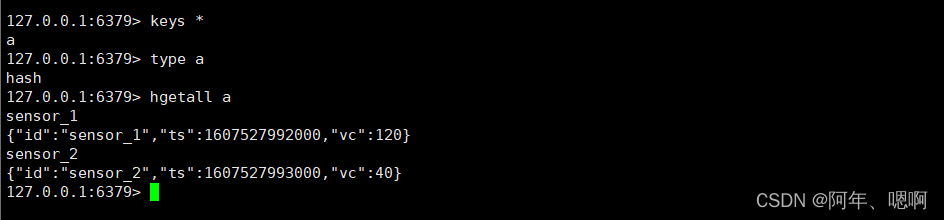
6. Redis_Sink_hash
addSink(new RedisSink<>(config, new RedisMapper< WaterSensor>() {}
写到 hash结构里面
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);SingleOutputStreamOperator<WaterSensor> result = stream.keyBy(WaterSensor::getId).sum("vc");FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder().setHost("hadoop101").setPort(6379).setMaxTotal(100).setMaxIdle(10).setMinIdle(2).setTimeout(10*1000).build();result.addSink(new RedisSink<>(config, new RedisMapper<WaterSensor>() {@Overridepublic RedisCommandDescription getCommandDescription() {// 数据写入hashreturn new RedisCommandDescription(RedisCommand.HSET,"a");}@Overridepublic String getKeyFromData(WaterSensor waterSensor) {return waterSensor.getId();}@Overridepublic String getValueFromData(WaterSensor waterSensor) {return JSON.toJSONString(waterSensor);}}));try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:
7. 有界流数据写入到ES中
new ElasticsearchSink.Builder()
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);SingleOutputStreamOperator<WaterSensor> result = stream.keyBy(WaterSensor::getId).sum("vc");List<HttpHost> hosts = Arrays.asList(new HttpHost("hadoop101", 9200),new HttpHost("hadoop102", 9200),new HttpHost("hadoop103", 9200));ElasticsearchSink.Builder<WaterSensor> builder = new ElasticsearchSink.Builder<WaterSensor>(hosts,new ElasticsearchSinkFunction<WaterSensor>() {@Overridepublic void process(WaterSensor element, // 需要写出的元素RuntimeContext runtimeContext, // 运行时上下文 不是context上下文对象RequestIndexer requestIndexer) { // 把要写出的数据,封装到RequestIndexer里面String msg = JSON.toJSONString(element);IndexRequest ir = Requests.indexRequest("sensor").type("_doc") // 定义type的时候, 不能下划线开头. _doc是唯一的特殊情况.id(element.getId()) // 定义每条数据的id. 如果不指定id, 会随机分配一个id. id重复的时候会更新数据.source(msg, XContentType.JSON);requestIndexer.add(ir); // 把ir存入到indexer, 就会自动的写入到es中}});result.addSink(builder.build());try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
8. 无界流数据写入到ES
和有界差不多 ,只不过把数据源换成socket,然后因为无界流,它高效不是你来一条就刷出去,所以设置刷新时间、大小、条数,才能看到结果。public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> result = env.socketTextStream("hadoop101",9999).map(line->{String[] data = line.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).keyBy(WaterSensor::getId).sum("vc");List<HttpHost> hosts = Arrays.asList(new HttpHost("hadoop101", 9200),new HttpHost("hadoop102", 9200),new HttpHost("hadoop103", 9200));ElasticsearchSink.Builder<WaterSensor> builder = new ElasticsearchSink.Builder<WaterSensor>(hosts,new ElasticsearchSinkFunction<WaterSensor>() {@Overridepublic void process(WaterSensor element, // 需要写出的元素RuntimeContext runtimeContext, // 运行时上下文 不是context上下文对象RequestIndexer requestIndexer) { // 把要写出的数据,封装到RequestIndexer里面String msg = JSON.toJSONString(element);IndexRequest ir = Requests.indexRequest("sensor").type("_doc") // 定义type的时候, 不能下划线开头. _doc是唯一的特殊情况.id(element.getId()) // 定义每条数据的id. 如果不指定id, 会随机分配一个id. id重复的时候会更新数据.source(msg, XContentType.JSON);requestIndexer.add(ir); // 把ir存入到indexer, 就会自动的写入到es中}});// 自动刷新时间builder.setBulkFlushInterval(2000); // 默认不会根据时间自动刷新builder.setBulkFlushMaxSizeMb(1024); // 当批次中的数据大于等于这个值刷新builder.setBulkFlushMaxActions(2); // 每来多少条数据刷新一次// 这三个是或的关系,只要有一个满足就会刷新result.addSink(builder.build());try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
9. 自定义sink - mysql_Sink
需要写一个类,实现RichSinkFunction,然后实现invoke方法。这里因为是写MySQL所以需要建立连接,那就用Rich版本。
记得导入MySQL依赖
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port", 1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);SingleOutputStreamOperator<WaterSensor> result = stream.keyBy(WaterSensor::getId).sum("vc");result.addSink(new MySqlSink());try {env.execute();} catch (Exception e) {e.printStackTrace();}}public static class MySqlSink extends RichSinkFunction<WaterSensor> {private Connection connection;@Overridepublic void open(Configuration parameters) throws Exception {Class.forName("com.mysql.cj.jdbc.Driver");connection = DriverManager.getConnection("jdbc:mysql://hadoop101:3306/test?useSSL=false", "root", "123456");}@Overridepublic void close() throws Exception {if (connection!=null){connection.close();}}// 调用:每来一条元素,这个方法执行一次@Overridepublic void invoke(WaterSensor value, Context context) throws Exception {// jdbc的方式想MySQL写数据
// String sql = "insert into sensor(id,ts,vc)values(?,?,?)";//如果主键不重复就新增,主键重复就更新
// String sql = "insert into sensor(id,ts,vc)values(?,?,?) duplicate key update vc=?";String sql = "replace into sensor(id,ts,vc)values(?,?,?)";// 1. 得到预处理语句PreparedStatement ps = connection.prepareStatement(sql);// 2. 给sql中的占位符进行赋值ps.setString(1,value.getId());ps.setLong(2,value.getTs());ps.setInt(3,value.getVc());
// ps.setInt(4,value.getVc());// 3. 执行ps.execute();// 4. 提交
// connection.commit(); MySQL默认自动提交,所以这个地方不用调用// 5. 关闭预处理ps.close();}
}
运行结果:

10. Jdbc_Sink
addSink(JdbcSink.sink(sql,JdbcStatementBuilder,执行参数,连接参数)
对于jdbc数据库,我们其实没必要自定义,因为官方给我们了一个JDBC Sink -> 官方JDBC Sink 传送门
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.11</artifactId><version>1.13.6</version>
</dependency>
public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(1);ArrayList<WaterSensor> waterSensors = new ArrayList<>();waterSensors.add(new WaterSensor("sensor_1", 1607527992000L, 20));waterSensors.add(new WaterSensor("sensor_1", 1607527994000L, 50));waterSensors.add(new WaterSensor("sensor_1", 1607527996000L, 50));waterSensors.add(new WaterSensor("sensor_2", 1607527993000L, 10));waterSensors.add(new WaterSensor("sensor_2", 1607527995000L, 30));DataStreamSource<WaterSensor> stream = env.fromCollection(waterSensors);SingleOutputStreamOperator<WaterSensor> result = stream.keyBy(WaterSensor::getId).sum("vc");result.addSink(JdbcSink.sink("replace into sensor(id,ts,vc)values(?,?,?)",new JdbcStatementBuilder<WaterSensor>() {@Overridepublic void accept(PreparedStatement ps,WaterSensor waterSensor) throws SQLException {// 只做一件事:给占位符赋值ps.setString(1,waterSensor.getId());ps.setLong(2,waterSensor.getTs());ps.setInt(3,waterSensor.getVc());}},new JdbcExecutionOptions.Builder() //设置执行参数.withBatchSize(1024) // 刷新大小上限.withBatchIntervalMs(2000) //刷新间隔.withMaxRetries(3) // 重试次数.build(),new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withDriverName("com.mysql.cj.jdbc.Driver").withUrl("jdbc:mysql://hadoop101:3306/test?useSSL=false").withUsername("root").withPassword("123456").build()));try {env.execute();} catch (Exception e) {e.printStackTrace();}
}
运行结果:

相关文章:
Flink - sink算子
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 1. Kafka_Sink 2. Kafka_Sink - 自定义序列化器 3. Redis_Sink_String 4. Redis_Sink_list 5. Redis_Sink_set 6. Redis_Sink_hash 7. 有界流数据写入到ES 8. 无界流数据写入到ES 9. 自定…...

【项目 线程2】3.5 线程的分离 3.6线程取消 3.7线程属性
3.5 线程的分离 #include <stdio.h> #include <pthread.h> #include <string.h> #include <unistd.h>void * callback(void * arg) {printf("chid thread id : %ld\n", pthread_self());return NULL; }int main() {// 创建一个子线程pthread…...
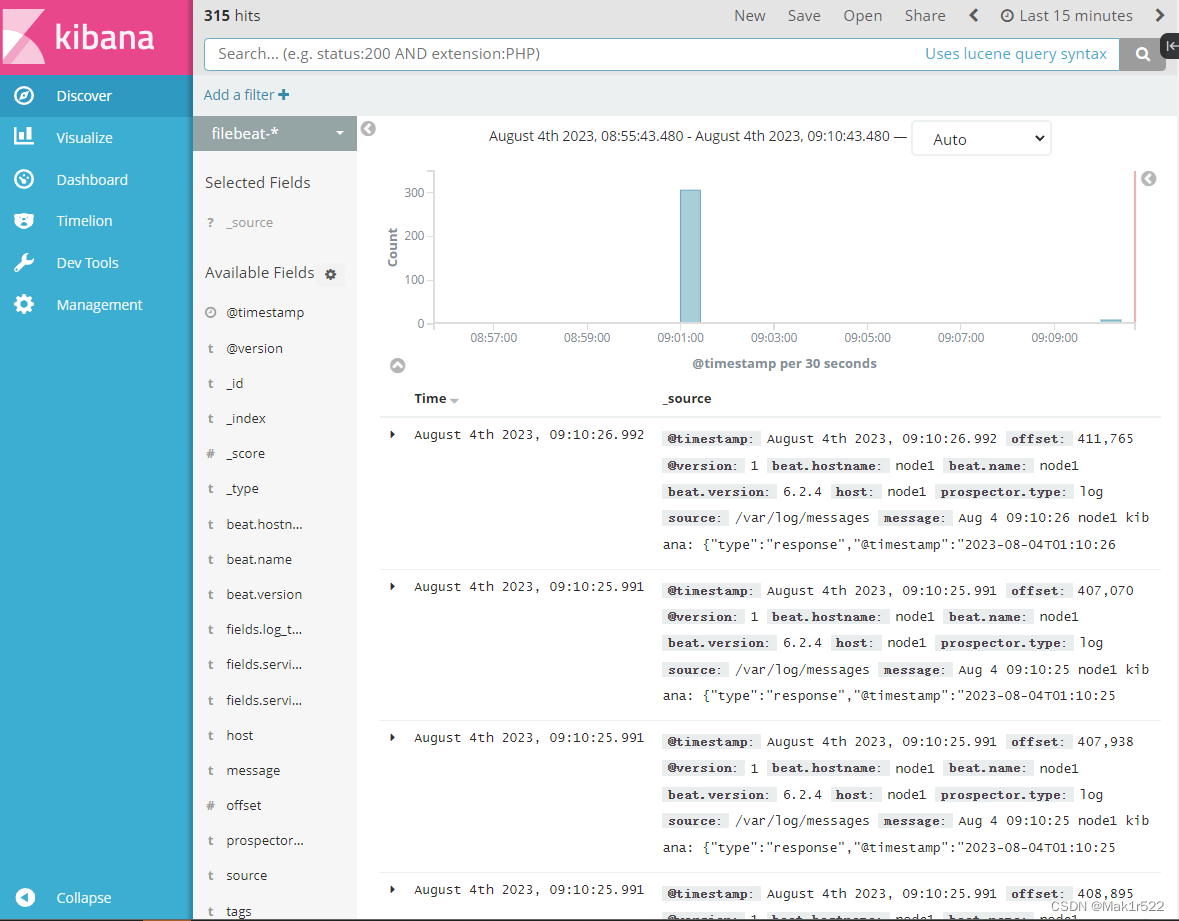
Filebeat+ELK 部署
目录 //在 Node1 节点上操作 1.安装 Filebeat 2.设置 filebeat 的主配置文件 3.在 Logstash 组件所在节点上新建一个 Logstash 配置文件 4.浏览器访问 http://192.168.193.40:5601 登录 Kibana,单击“Create In…...
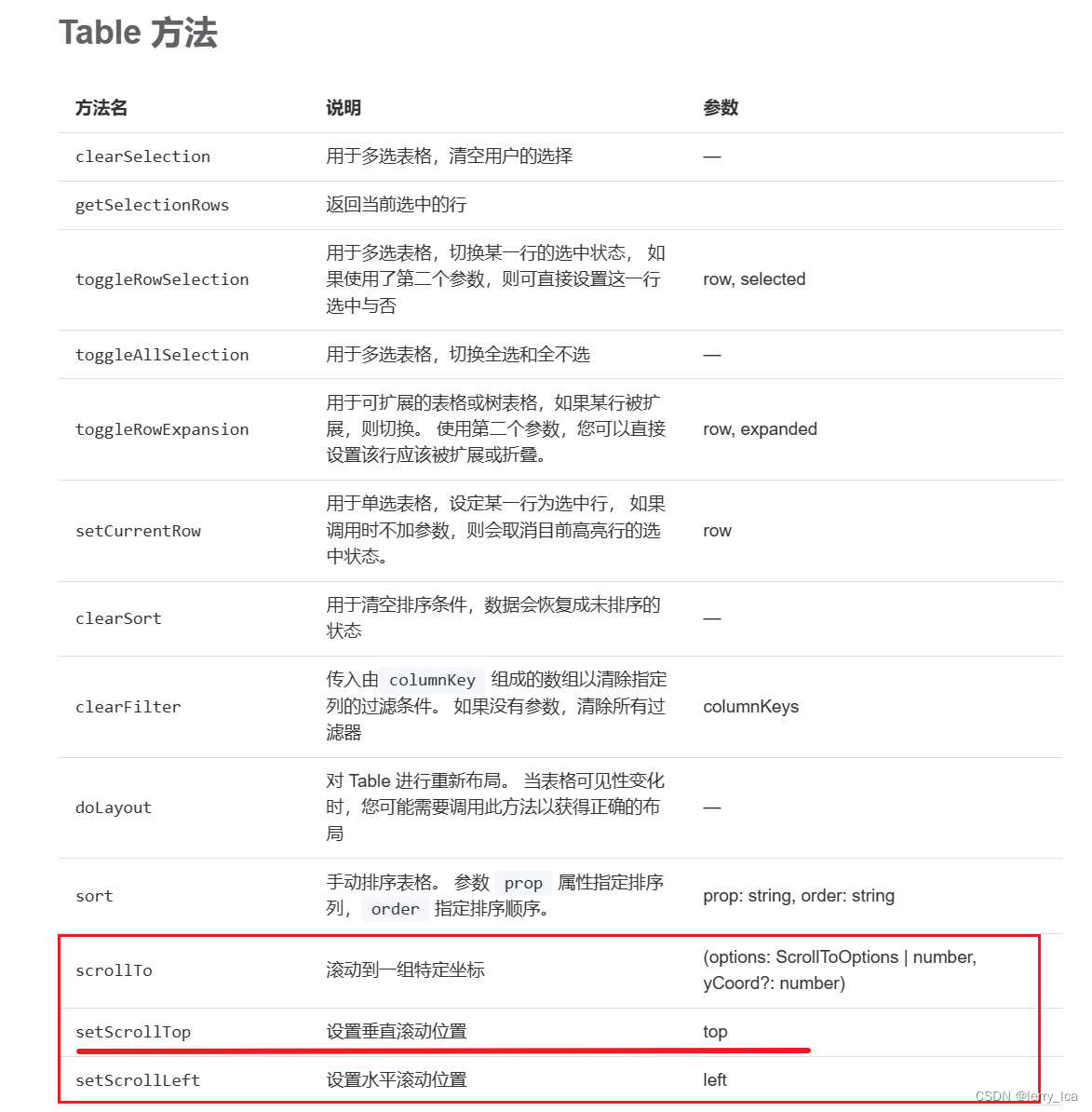
el-table点击表格某一行添加到URL参数,访问带参URL加载表格内容并滚动到选中行位置 [Vue3] [Element-plus 2.3]
写在最前 需求:有个表格列出了一些行数据,每个行数据点击后会加载出对应的详细数据,想要在点击了某一行后,能够将该点击反应到URL中,这样我复制这个URL发给其他人,他们打开时也能看到同样的行数据。 url会根…...
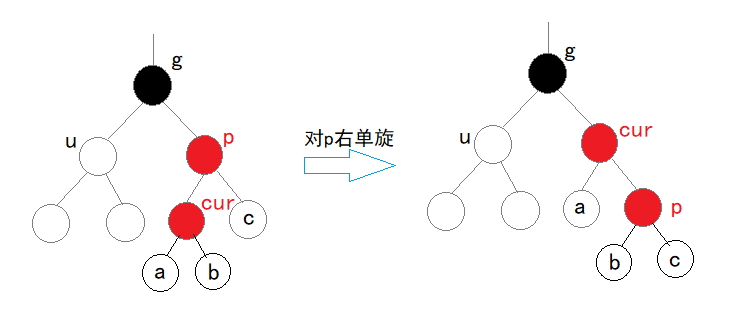
【树】 二叉树 堆与堆排序 平衡(AVL)树 红黑(RB)树
目录 1 树1.1 认识树1.2 树的相关概念1.3 树的表示孩子兄弟表示法 2 二叉树2.1 概念2. 2 特殊二叉树2.3 二叉树的性质2.4 二叉树的存储结构 3 堆 — 完全二叉树的顺序结构实现3.1 堆的概念3.2 核心代码3.3 堆应用1 堆排序2 TOP-K问题 4 二叉树的链式存储4.1 二叉链结构与初始化…...
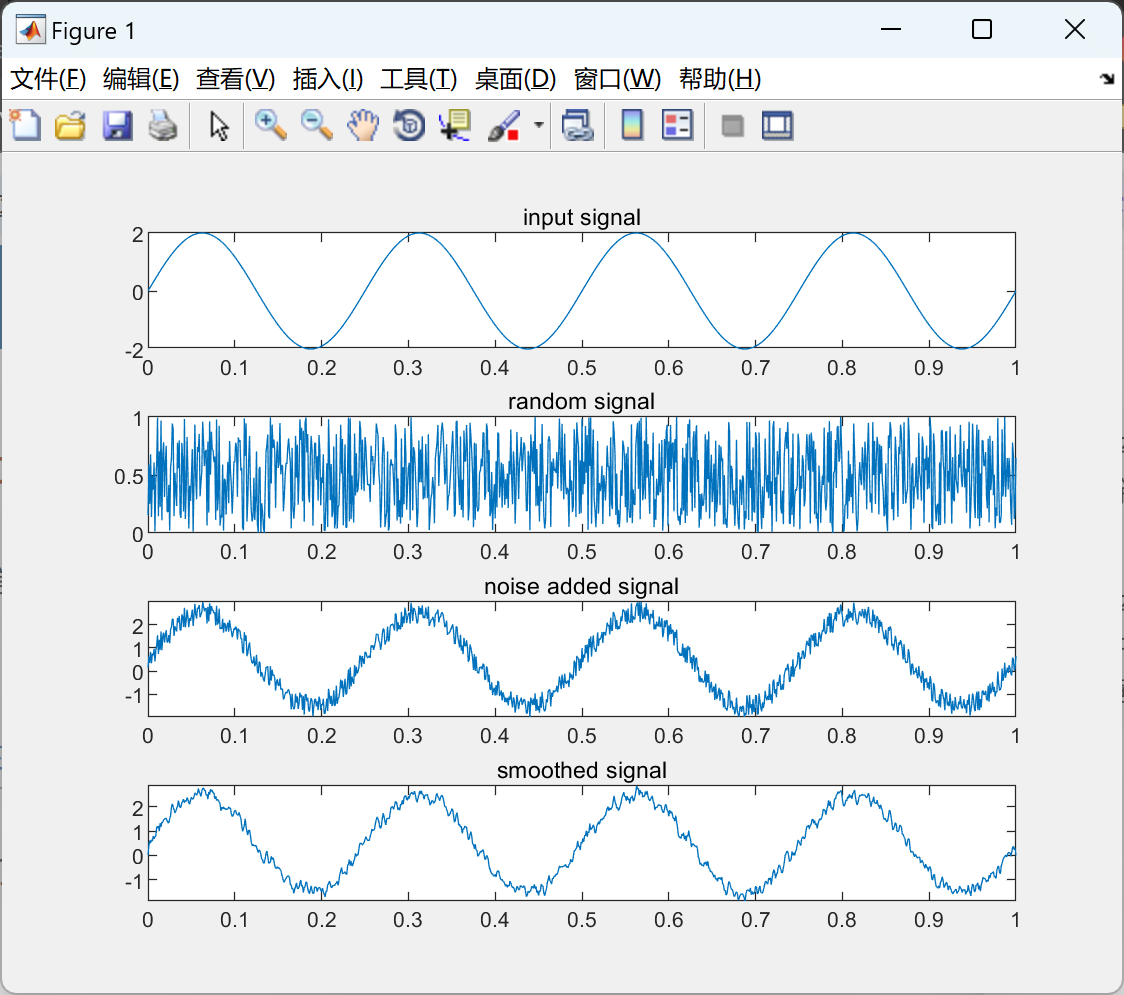
信号平滑或移动平均滤波研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
黑客技术(网络安全)自学
一、黑客是什么 原是指热心于计算机技术,水平高超的电脑专家,尤其是程序设计人员。但后来,黑客一词已被用于泛指那些专门利用电脑网络搞破坏或者恶作剧的家伙。 二、学习黑客技术的原因 其实,网络信息空间安全已经成为海陆空之…...

使用七牛云、阿里云、腾讯云的对象存储上传文件
说明:存在部分步骤省略的情况,请根据具体文档进行操作 下载相关sdk composer require qiniu/php-sdkcomposer require aliyuncs/oss-sdk-php composer require alibabacloud/sts-20150401composer require qcloud/cos-sdk-v5 composer require qcloud_s…...
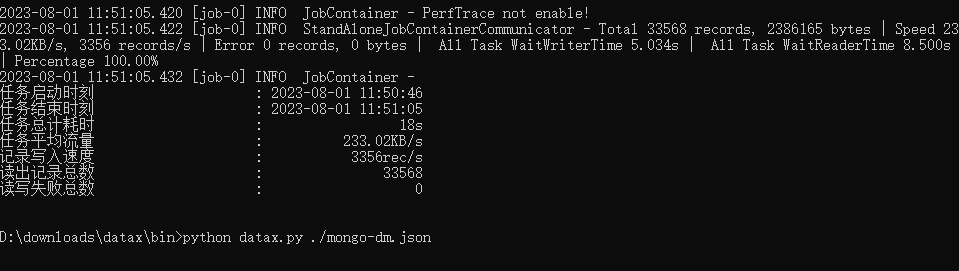
使用阿里云DataX完成数据同步
DataX DataX 是阿里云 DataWorks 数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, datab…...
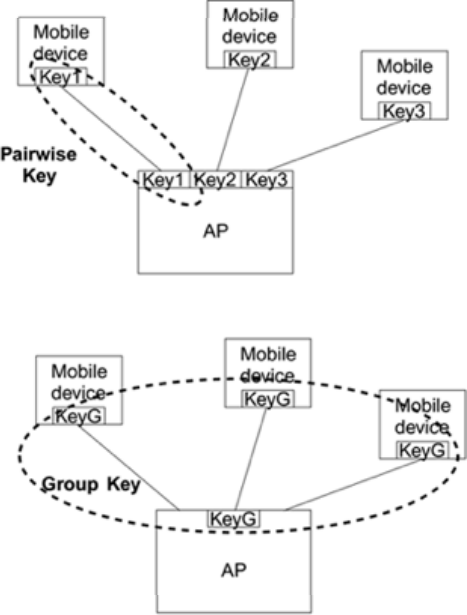
《Kali渗透基础》13. 无线渗透(三)
kali渗透 1:无线通信过程1.1:Open 认证1.2:PSK 认证1.3:关联请求 2:加密2.1:Open 无加密网络2.2:WEP 加密系统2.3:WPA 安全系统2.3.1:WPA12.3.2:WPA2 3&#…...
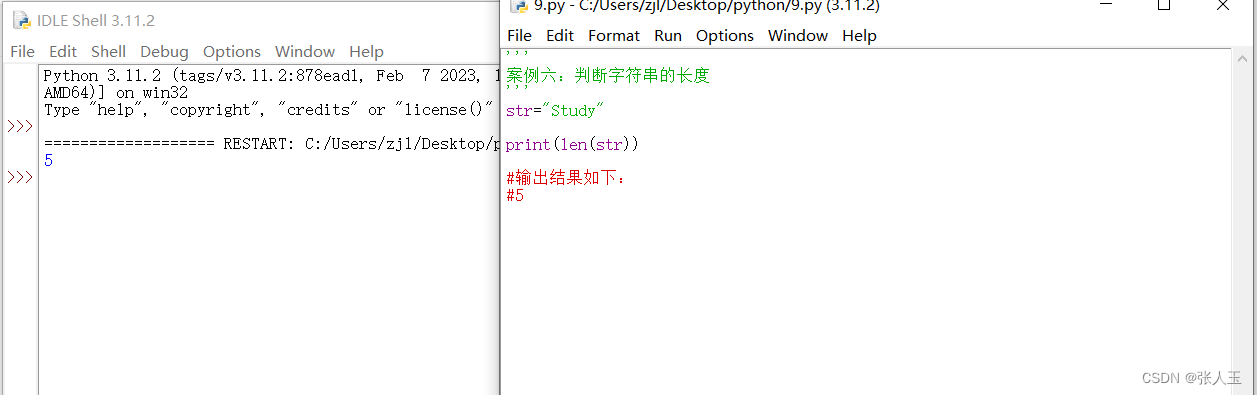
python——案例六:判断字符串的长度
案例六:判断字符串的长度str"Study"print(len(str))#输出结果如下: #5...

PC-windows-安卓-Linux音频系统框架概论
+我V hezkz17进数字音频系统研究开发交流答疑群(课题组) 一 PC 音频系统工作原理 PC音频系统的工作原理可以简要概括为以下几个步骤: 音频输入:音频信号可以通过多种方式输入到计算机,例如麦克风、线路输入、数字音频接口等。这些音频源会将声音转换为电信号。 模数转换…...

Web Worker API
Web Worker API Web Worker 使得在一个独立于 Web 应用程序主执行线程的后台线程中运行脚本操作成为可能。这样做的好处是可以在独立线程中执行费时的处理任务,使主线程(通常是 UI 线程)的运行不会被阻塞/放慢。 Web Worker概念与用法 Wor…...

1.4 MA多头/空头排列是真的吗?
MA策略验证——金叉和死叉 文章目录 MA策略验证——金叉和死叉公共代码论证步骤论证代码论证结果写在最后公共代码 code = 注意,这里改成股票代码 pro = ts.pro_api(tushare的token)df = pro.daily(ts_code=code)[...

基于SpringBoot+Vue的CSGO赛事管理系统设计与实现(源码+LW+部署文档等)
博主介绍: 大家好,我是一名在Java圈混迹十余年的程序员,精通Java编程语言,同时也熟练掌握微信小程序、Python和Android等技术,能够为大家提供全方位的技术支持和交流。 我擅长在JavaWeb、SSH、SSM、SpringBoot等框架…...

Android系统APP之SettingsProvider
前言 SettingsProvider顾名思义是一个提供设置数据共享的Provider,SettingsProvider和Android系统其它Provider有很多不一样的地方,如: SettingsProvider只接受int、float、string等基本类型的数据;SettingsProvider由Android系…...

go入门实践二-tcp服务端
文章目录 前言接口与方法并发-协程项目管理bufio包使用其他代码 前言 上一篇,我们通过go语言的hello-world入门,搭建了go的编程环境,并对go语法有了简单的了解。本文实现一个go的tcp服务端。借用这个示例,展示接口、协程、bufio的…...

SprinMVC获取请求参数
SprinMVC获取请求参数 Spring MVC 提供的获取请求参数的方式 通过 HttpServletRequest 获取请求参数通过控制器方法的形参获取请求参数使用 RequestParam 注解获取请求参数通过实体类对象获取请求参数(推荐) 通过ServlstAPI获取 将HttpServletRequest…...
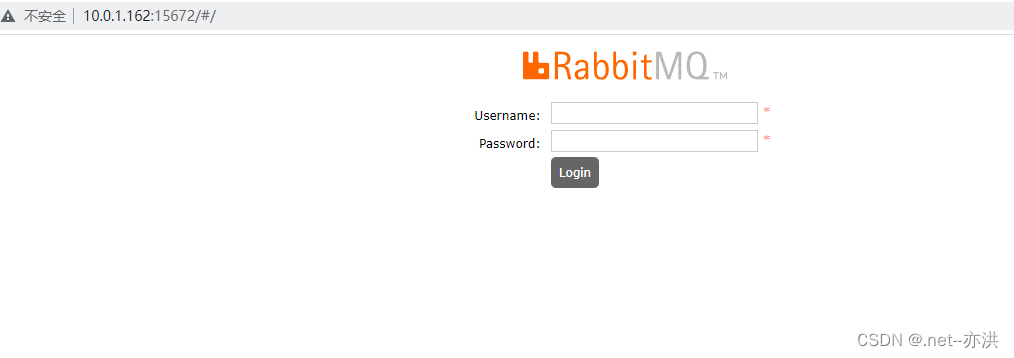
orangepi 4lts ubuntu安装RabbitMQ
4lts的emmc 系统安装选文件系统格式 ext4 需先安装erlang: sudo apt install erlang 安装RabbitMQ: sudo apt install rabbitmq-server - 添加用户以便远程访问: - 账号密码都是admin: sudo rabbitmqctl add_user admin admin -sudo rabbitmqct…...
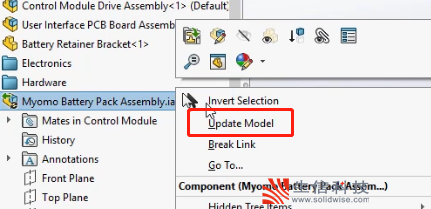
SolidWorks 3D Interconnect介绍
目前市面上有的三维设计软件有很多,如UG、Pro/E、CATIA等,而且每个三维设计软件都会生成自己文件格式。由于产品设计的原因,我们避免不了的会需要去使用不同三维设计软件的文件,这对于工程师来说其实是一件比较麻烦的事。 为什么…...
)
YOLO11导出TFLite格式:移动端轻量级部署,如何将YOLO11转换为TFLite格式,并测试推理效果全面实战(一)
🎬 Clf丶忆笙:个人主页 🔥 个人专栏:《YOLOv11全栈指南:从零基础到工业实战》 ⛺️ 努力不一定成功,但不努力一定不成功! 文章目录 一、YOLO11与TFLite技术概述 1.1 TFLite格式技术解析 1.2 YOLO11转TFLite的应用价值 二、环境准备与依赖安装 2.1 Python环境配置 2…...
的完整配置与性能分析)
Jetson Orin NX 16G显存够用吗?实测同时跑4个YOLOv8模型(含姿态估计)的完整配置与性能分析
Jetson Orin NX 16G显存实战:多模型并发推理的性能极限测试 当我们需要在边缘设备上部署多个视觉模型时,硬件选型往往成为最令人头疼的问题。最近在为一个智能监控项目做技术验证时,我遇到了一个典型场景:需要在单台设备上同时运行…...

不满意Oh My Zsh启动卡顿,来试试Starship吧城
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

DMA技术解析:提升嵌入式系统性能的关键
1. DMA技术概述:解放CPU的搬运工 DMA(Direct Memory Access)直接存储器访问技术,是现代嵌入式系统中提升性能的关键设计。我第一次在STM32项目中使用DMA传输时,实测发现ADC采样率从500kHz提升到2.1MHz,CPU占…...

AI赋能智能制造:预测性维护在工业4.0中的落地实践
1. 预测性维护:从被动维修到智能预防的革命 想象一下,你家的空调突然在炎热的夏天罢工了,维修师傅告诉你:"这个零件本来三个月前就该换了"。这种场景在工业生产中放大1000倍,就是传统维护方式带来的痛点。预…...

港口淡水罐远程监控物联网系统方案
随着全球贸易的持续增长,港口作为物流枢纽的重要性日益凸显。淡水作为港口运营的关键资源,不仅用于船舶补给、设备冷却,还涉及消防、生活用水等多个环节。当前,智慧码头理念与物联网技术深度融合,降本增效与数字化管理…...

GPEN部署教程:使用Podman替代Docker,在RHEL/CentOS安全环境中运行
GPEN部署教程:使用Podman替代Docker,在RHEL/CentOS安全环境中运行 1. 为什么选择Podman部署GPEN? 在企业级环境中,安全性和稳定性往往是首要考虑因素。传统的Docker虽然方便,但在安全隔离和权限管理方面存在一些局限…...
进阶实战:从JSON Schema到企业级应用架构)
OpenAI结构化输出(Structured Outputs)进阶实战:从JSON Schema到企业级应用架构
1. 结构化输出的企业级价值与应用场景 在复杂的企业环境中,数据格式的标准化程度直接影响系统间的协作效率。想象一下财务部门需要从销售报告中提取关键指标,如果每个系统的输出格式都不一样,光是数据清洗就要耗费大量时间。这就是为什么Open…...

ESP-Meshed:面向ESP32/ESP8266的轻量级分布式应用框架
1. ESP-Meshed 框架深度解析:面向 ESP32/ESP8266 的轻量级分布式应用构建框架1.1 框架定位与工程价值ESP-Meshed 并非 Espressif 官方 ESP-MESH 协议栈的替代品,而是一个面向嵌入式应用层的轻量级分布式框架。其核心设计哲学是:在不侵入底层网…...

从 RPA 到 IPA:AI Agent Harness Engineering 如何彻底取代传统自动化脚本
从 RPA 到 IPA:AI Agent Harness Engineering 如何彻底取代传统自动化脚本 摘要/引言 一、引言(超字数拆分前的整体架构先出,但后面核心章节正文每个会超1万) 想象一个场景:2022年的某一天,你是一家全球快消品牌亚太区电商平台的RPA项目经理。你带领8人团队,花了三个月…...