ARM进阶:内存屏障(DMB/DSB/ISB)的20个使用例子详解
在上一节内存屏障指令之DMB、DSB和ISB详解中,介绍了一下内存屏障的三个指令的作用并举了一些例子,对于内存屏障指令的使用时机,与处理器架构(比如Cortex-M和Cortex-A)和处理器的系统实现(同样的架构,有不同的实现,如STM32、NXP都有基于Cortex-M4的单片机)都有关系。
本节将通过20个例子继续深入理解内存屏障,主要从以下两方面来介绍:
(1)处理器架构要求:指在硬件体系结构中定义的规范和要求。它描述了处理器的指令集、寄存器、中断控制、内存访问、流水线结构等硬件特性。这些规范通常由处理器设计者或者架构定义组织(如ARM,x86等)确定。架构要求是通用的,适用于所有基于该架构的处理器。
(2)系统实现要求:指在具体处理器实现中,根据架构要求来实现这些规范的具体方法。每个处理器制造商可以根据架构规范,设计和生产自己的处理器,但他们的实现必须遵循架构规范。实现要求可能因处理器型号、版本和制造商而异。
文章目录
- 1 内存中普通数据的访问
- 2 设备(外设)间的访问
- 3 位带访问
- 4 SCS外设访问
- 5 通过NVIC使能中断
- 6 通过NVIC关闭中断
- 7 用CPS和MSR指令使能中断
- 8 用CPS和MSR指令关闭中断
- 9 禁用外设中断
- 10 更改中断的优先级
- 11 向量表配置-VTOR
- 12 向量表条目配置
- 13 内存映射的改变
- 14 进入睡眠模式
- 15 自启
- 16 CONTROL寄存器
- 17 MPU编程
- 18 多主系统
- 19 信号量和互斥锁(单核和多核)
- 20 自修改代码
- 总结
1 内存中普通数据的访问
这种情况下没有必要在每次内存访问之间都使用内存屏障:
- 处理器架构:只要不影响程序的运行,处理器就可以对数据传输重新排序
- 系统实现:在Cortex-M处理器中,数据传输是按照编程的顺序进行的
2 设备(外设)间的访问
在外设编程或外设访问期间,不需要在每一步之间使用内存屏障指令:
- 处理器架构:对同一设备的访问必须按照程序的顺序进行
- 系统实现:Cortex-M处理器不会重排序数据传输
如果编程顺序涉及许多不同的设备:
- 处理器架构:当访问不同的设备并且两个设备之间的编程顺序可能影响结果时,需要内存屏障。这是因为总线结构可能具有通往每个设备的不同总线分支,并且不同总线分支可能具有不同的延迟。
- 系统实现:Cortex-M处理器不会对数据传输进行重新排序,因此当访问不同的设备时不需要内存屏障
3 位带访问
Cortex-M3和Cortex-M4处理器上的位带访问是一个特殊的特性。它可以让内存映射的两个部分成为位可寻址的:
- 处理器架构:位带特性不是ARMv7或ARMv6体系结构的一部分,因此对于使用内存屏障进行位带访问没有体系结构定义的要求
- 系统实现:Cortex-M3和Cortex-M4处理器处理位带访问、位带区域以及位带别名区域,以编程顺序。没有必要使用内存屏障
ARM Cortex-M0和Cortex-M0+处理器没有位带特性。可以使用bus wrapper向Cortex-M0和Cortex-M0+处理器添加位带特性。在这种情况下,bus wrapper必须保持正确的内存顺序。
4 SCS外设访问
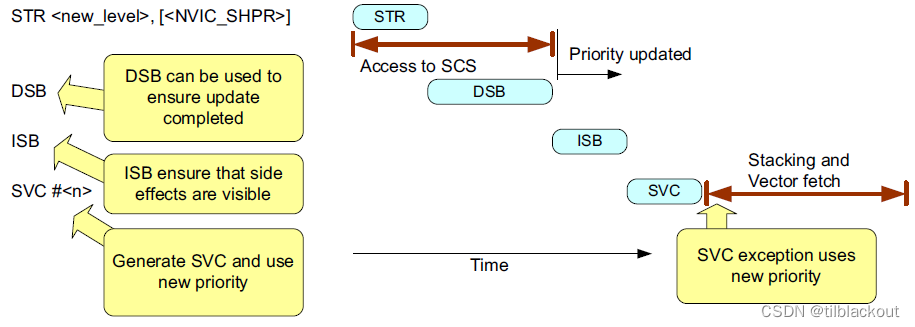
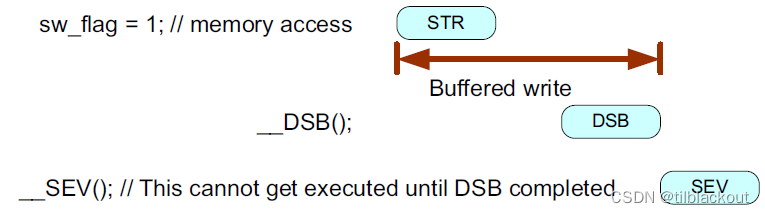
SCS外设访问,例如NVIC和调试访问,通常不需要使用内存屏障指令:不需要在每个SCS访问之间插入内存屏障指令,也不需要在SCS访问和设备内存访问之间插入内存屏障指令。
-
处理器架构:SCS所在的内存区域的MPU默认配置为强有序,自带
DMB的作用(如下图所示)
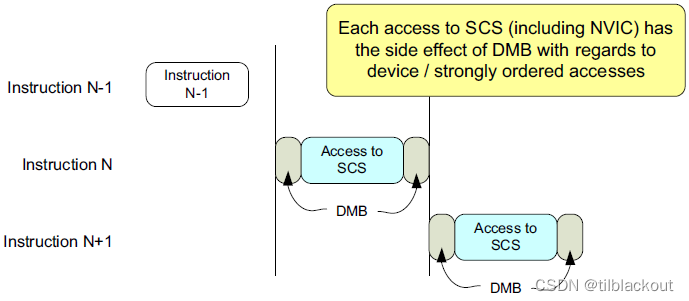
-
系统实现:不需要在每个SCS访问之间插入内存屏障指令,也不需要在SCS访问和设备内存访问之间插入内存屏障指令
处理器架构要求
- 如果需要立即看到SCS寄存器写入的效果,则需要
DSB - 不需要在相邻的两次访问SCS之间添加内存屏障指令
- 如果下一条指令必须在前一条指令产生作用后执行,此时需要调用
DSB指令,例子如下:
SCB->SCR |= SCB_SCR_SLEEPDEEP_Msk; /* Enable deepsleep */
__DSB(); /* Ensure effect of last store takes effect */
__WFI(); /* Enter sleep mode */
---------------------
void Device_IRQHandler(void) {software_flag = 1; /* Update software variable used in thread */SCB->SCR &= ~SCB_SCR_SLEEPONEXIT_Msk; /* Disable sleeponexit */__DSB(); /* Ensure effect of last store takes effect */return;
}
注意,当程序访问的是Normal内存时,SCS访问时,系统架构层面的DMB不能保证内存排序。如果程序的操作依赖于对SCS的访问与对普通内存的访问之间的顺序,那么就需要使用内存屏障指令,比如DMB或DSB。下面是一个例子:
STR R0, [R1] ; Access to a Normal Memory location
DMB ; Add DMB ensures ordering for ALL memory types
STR R3, [R2] ; Access to a SCS location
DMB ; Add DMB ensures ordering for ALL memory types
STR R0, [R1] ; Access to a Normal Memory location
- 如果
[R1]指向的是设备内存区域或强有序内存区域,则不需要DMB
系统实现要求
在现有的Cortex-M处理器中,忽略DMB或DSB指令不会导致错误,因为这些处理器中的SCS已经包含DSB行为:
- 在Cortex-M0、M0+处理器中,这种行为在访问完成后立即发生。在SCS访问后,并不严格要求
DSB。 - 在Cortex-M3和M4处理器中,内存屏障的作用在访问SCS后立即生效。对于SCS内存的访问,除了特殊情况下的
SLEEPONEXIT更新外,通常不严格要求使用DSB指令。- 如果异常处理程序在异常返回之前禁用了SCS中的
SLEEPONEXIT特性,则在SCR写入之后,在异常返回之前,需要DSB指令。参考前面的Device_IRQHandler例子。
- 如果异常处理程序在异常返回之前禁用了SCS中的
看一下在系统实现层面,对SCS访问的表现:
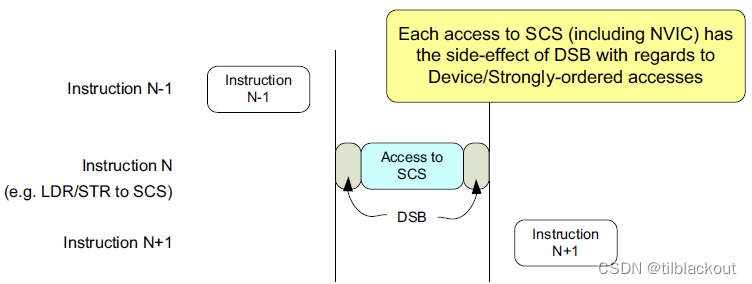
图中说得很清楚,每次访问SCS(包括NVIC)都具有对设备/强序访问的自动添加数据同步屏障DSB的连带作用。所以对于前面处理器架构要求中的例子,DSB可以去掉:
SCB->SCR |= SCB_SCR_SLEEPDEEP_Msk; /* Enable deepsleep */
__WFI(); /* Enter sleep mode */
注意:
- 现有的Cortex-M处理器不会重新排序任何数据传输,因此不需要使用
DMB指令 - 对于Cortex-M3和Cortex-M4处理器,如果SCS加载/存储后的指令是NOP指令,或者是条件失败(
condition failed)指令,则NOP指令或条件失败指令可以与SCS加载/存储指令并行执行
5 通过NVIC使能中断
通常,NVIC操作不需要使用内存屏障指令,代码如下所示:
device_config(); // Setup peripheral
NVIC_ClearingPending(device_IRQn); // clear pending status
NVIC_SetPriority(device_IRQn, priority); // set priority level
NVIC_EnableIRQ(device_IRQn); // Enable interrupt
- 当一个中断事件发生时,它可以先进入pending状态,而不管中断是否使能
前面有提到,从架构上看,每次访问SCS(NVIC属于SCS)时,对于设备内存或强有序内存的访问访问,相邻两次的操作之前都会插入DMB。
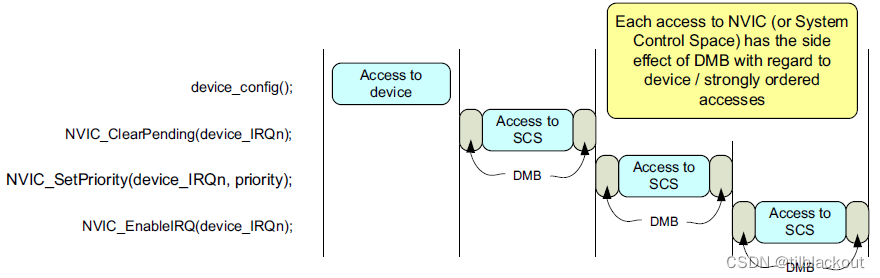
而从Cortex-M处理器的系统实现来看,每次访问SCS(NVIC属于SCS)时,对于设备内存或强有序内存的访问访问,相邻两次的操作之前都会插入DSB。
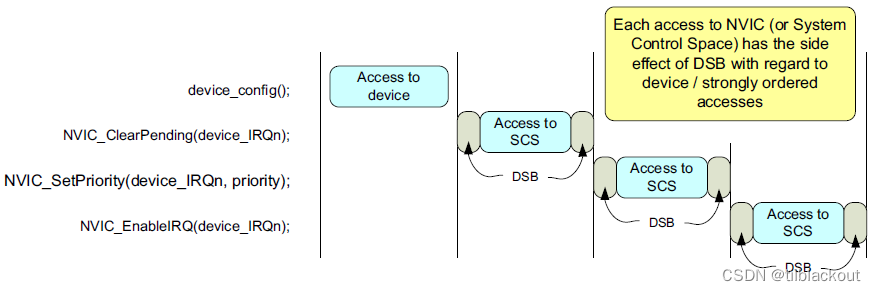
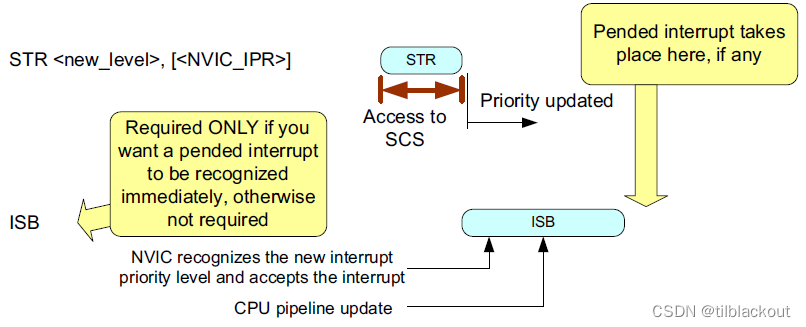
对于Cortex-M处理器来说,由于其流水线特性,如果中断已经处于挂起状态,处理器可以在执行中断服务程序之前在NVIC中启用中断后执行最多两个额外的指令。如下图所示:

处理器架构要求
不同的应用有不同的要求:
- 在一般的NVIC操作中,无需使用内存屏障
- NVIC和外设之间的操作间,无需使用内存屏障
- 如果一个已经挂起的中断需要在使能NVIC后马上被响应,需要添加一个
DSB,紧接着还要添加一个ISB
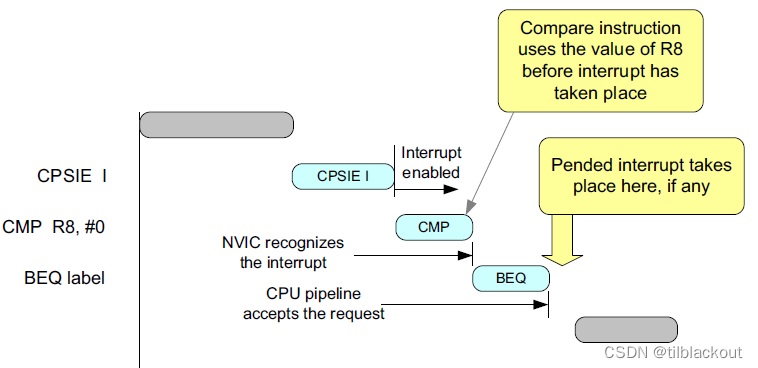
如果中断后的指令依赖于挂起的中断的结果,就应该添加内存屏障指令。处理中断的例子如下所示:
LDR R0, =0xE000E100 ; NVIC_SETENA address
MOVS R1, #0x1
STR R1, [R0] ; Enable IRQ #0
DSB ; Ensure write is completed
; (architecturally required, but not strictly
; required for existing Cortex-M processors)
ISB ; Ensure IRQ #0 is executed
CMP R8, #1 ; Value of R8 dependent on the execution
; result of IRQ #0 handler
如果省略了上面的内存屏障指令,CMP将在中断发生之前执行,如下图所示:
系统实现要求
不同的应用有不同的要求:
- 在一般的NVIC操作中,无需使用内存屏障
- 如果一个已经挂起的中断需要在使能NVIC后马上被响应,需要添加一个
ISB指令
注意:由于对NVIC(SCS)的访问本身就具有DSB内存屏障,因此省略DSB指令仍然可以立即识别已启用和挂起的中断。
6 通过NVIC关闭中断
由于Cortex-M的流水线架构,可以在进入中断序列(中断事件发生时,处理器执行的一系列操作和指令)的同时写入NVIC来禁用中断。因此,中断处理程序有可能会在NVIC禁用中断后立即执行。

处理器架构要求
根据不同的应用需求,需要使用内存屏障:
- 在禁用IRQ时,一般的NVIC编程不需要使用内存屏障
- 在NVIC编程与外设编程之间,也不需要使用内存屏障
- 如果需要确保在NVIC禁用中断后不会触发中断,可以添加
DSB指令,然后再添加ISB指令
下面是一个切换中断处理函数(修改向量表)的例子:
#define MEMORY_PTR(addr) (*((volatile unsigned long *)(addr)))NVIC_DisableIRQ(device_IRQn);
__DSB();
__ISB();
// Change vector to a different one
MEMORY_PTR(SCB->VTOR+0x40+(device_IRQn<<2))=(void) device_Handler;
系统实现要求
根据不同的应用需求,需要使用内存屏障:
- 在正常的NVIC编程中禁用IRQ时,不需要使用内存屏障
- 在NVIC编程和外设编程之间,也不需要使用内存屏障
- 如果需要确保在NVIC禁用中断后不会触发中断,可以添加
ISB指令
7 用CPS和MSR指令使能中断
在正常的应用程序中,在使用CPS指令启用中断后,不需要添加任何屏障指令:
_enable_irq(); /* 实际上是执行CPSIE I来清除PRIMASK */
如果一个中断已经处于挂起状态,在调用CPSIE I后,处理器将处理该中断。然而,在处理器进入异常处理程序之前,可能会执行额外的指令:
- 对于Cortex-M3或Cortex-M4,处理器在进入中断服务程序之前最多可以执行两条额外的指令
- 对于Cortex-M0,处理器在进入中断服务程序之前最多可以执行一条附加指令
如下图所示:

处理器架构要求
- 如果有必要确保在执行后续操作之前识别到挂起的中断,则应该在
CPSIE i之后使用ISB指令,如下图所示:
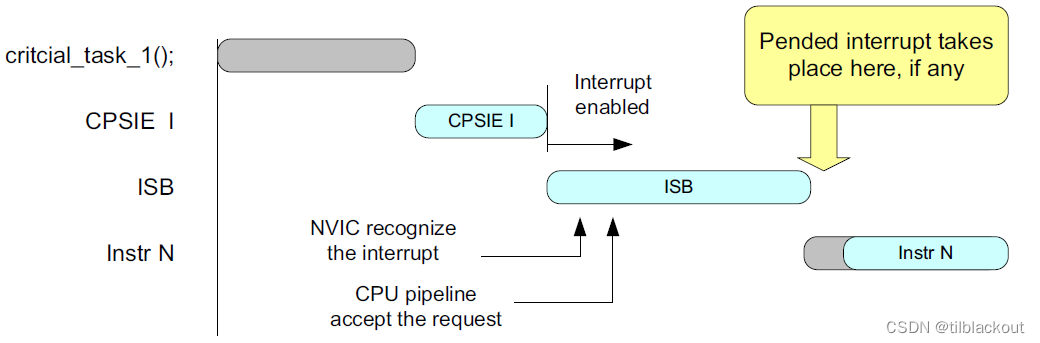
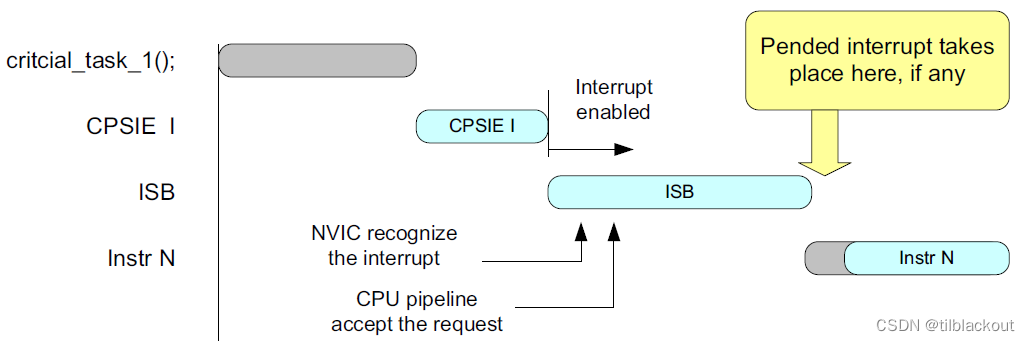
- 在两个临界区任务之间,如果你希望允许一个挂起的中断发生,可以使用
ISB指令来实现。代码如下所示:
__enable_irq(); // CPSIE I : Enable interrupt
__ISB(); // Allow pended interrupts to be recognized
__disable_irq(); // CPSID I : Disable interrupt
还有一个典型的例子是:
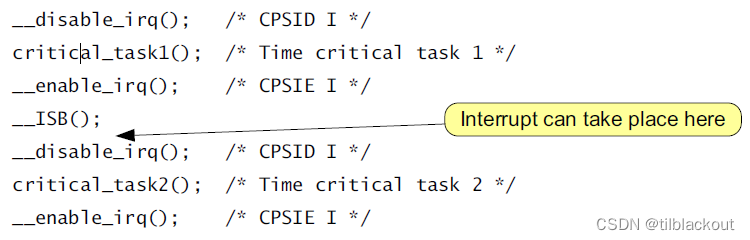
时序图如下:
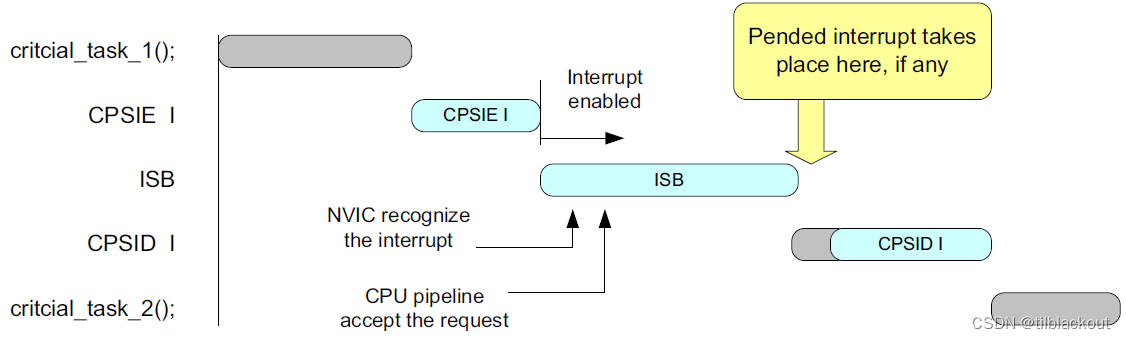
- 当使用
MSR指令启用中断时,要求同上
系统实现要求
在Cortex-M处理器中:
- 如果有必要确保在执行后续操作之前识别挂起的中断,则应该在
CPSIE i之后使用ISB指令。这与处理器架构要求相同 - 有一个例外是
CPSIE后面跟着CPSID,但在Cortex-M处理器中,可以不用在CPSIE和CPSID之间插入ISB。代码如下:
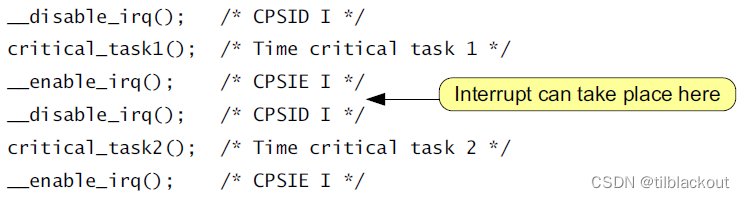
时序图如下:
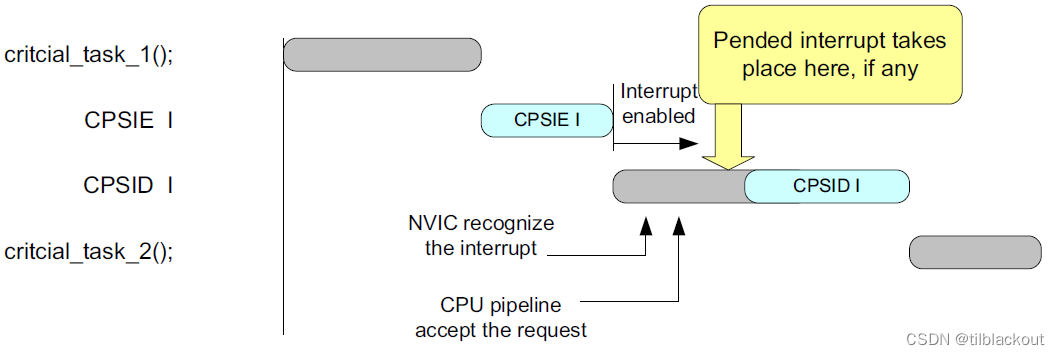
在系统实现需求中,不需要在__enable_irq()和__disable_irq()之间添加内存屏障指令。但是,在处理器架构要求中,如果需要在CPSIE和CPSID指令之间识别中断,则需要使用ISB指令。
- 当使用
MSR指令启用中断时,要求同上
根据处理器架构要求,在某些情况下,如果需要确保中断能够在正确地被识别,则需要添加ISB指令。这是因为在一些特定的处理器架构中,中断的使能和禁用可能需要额外的同步来保证其正确性。因此,根据架构要求,使用ISB指令是一种确保正确行为的方法。在系统实现要求中未添加内存屏障的情况下,这个操作在特定架构中已经被合理地处理了,因此不需要额外的内存屏障。在刚刚的代码中,根据具体的系统实现要求,它并不需要在__enable_irq()和__disable_irq()之间添加内存屏障指令。这意味着在特定的处理器实现中,中断使能和禁用的操作已经在硬件层面上得到了适当的同步,无需额外的内存屏障指令。
8 用CPS和MSR指令关闭中断
CPSID指令在指令流中自我同步,无需在CPSID之后插入内存屏障指令。
处理器架构要求
无需使用内存屏障。
系统实现要求
无需使用内存屏障。
- 当使用
MSR指令关闭中断时,要求同上
9 禁用外设中断
当在外设上禁用一个中断时,由于系统中存在多种可能的延迟源,可能需要额外的时间。下图显示了多种不同的延时源:
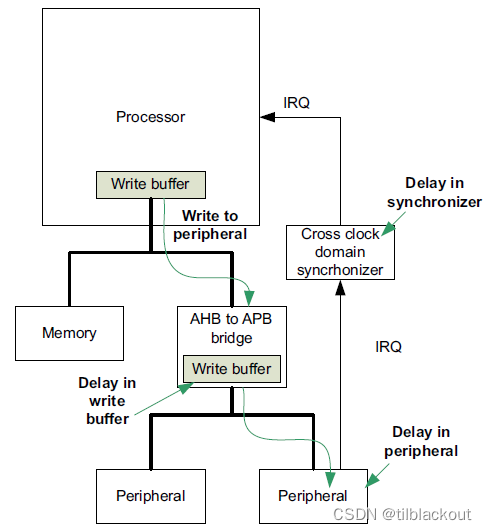
即使在禁用外设之后,也可能会在短时间内收到来自禁用外设的中断请求。
处理器架构要求
无要求,一切由下面的系统实现要求决定。
系统实现要求
延迟取决于设备。对于大多数情况,如果IRQ同步器中的延迟很小,可以使用以下步骤来禁用中断:
- 通过写入其控制寄存器
CONTROL来禁用外设中断 - 读取外设的控制寄存器,以确保其已更新
- 在NVIC中禁用IRQ
- 清除NVIC中的IRQ挂起状态
- 读取IRQ挂起状态。如果IRQ挂起被设置了,清除外设中的IRQ状态,然后再次清除NVIC中的IRQ挂起状态。必须重复此步骤,直到NVIC IRQ挂起状态保持清除。
这个步骤序列适用于大多数简单的微控制器设备,可以成功地禁用中断。然而,由于系统内可能发生的各种延迟因素,建议联系芯片供应商或制造商获取支持。
10 更改中断的优先级
优先级的设置由SCS中NVIC的Priority Level寄存器决定。对于Cortex-M3或Cortex-M4处理器,优先级级别可以动态地进行更改。然而对于ARMv6-M处理器,例如Cortex-M0或Cortex-M0+,不支持对已启用的中断或异常的优先级进行动态更改。在启用中断之前,就应该设置优先级。
处理器架构要求
由于SCS是强有序内存,所以NVIC配置不需要内存屏障。但是,在更改中断优先级后,如果中断已启用并且需要中断按照新的优先级级别执行,应该在其后插入DSB和ISB指令。
- 注意:在ARMv6-M处理器上,只有在中断被禁用时才应该更改中断的优先级级别,否则结果是不可预测的
如果下一个指令是CPSIE或MSR,根据处理器架构要求,应该插入一个DSB指令,然后再插入一个ISB指令(如果想让一个挂起的中断马上被识别到,就调用ISB,否则可以不调用)。这样的操作顺序可以确保中断状态的正确切换和指令的顺序执行,以防止中断状态的不一致或指令乱序执行问题。
系统实现要求
在Cortex-M处理器中,访问中断优先级寄存器本身就有DSB屏障了,因为SCS是强有序内存。在Cortex-M3或Cortex-M4处理器中:
- 如果需要立即识别优先级的更改,需要使用
ISB指令 - 如果不需要在随后的操作之前立即识别优先级的更改,则不需要插入内存屏障指令
- 如果下一个操作是
SVC异常,则不需要插入内存屏障指令
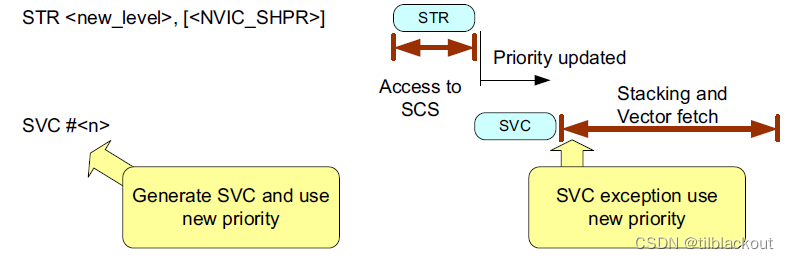
对于Cortex-M3或Cortex-M4处理器,如果优先级级别的更改可能导致新的中断嵌套(比当前正在执行的中断优先级高),并且我们希望立即执行此中断,则需要插入ISB指令。否则,由于流水线的原因,最多可能会多执行两条指令。
11 向量表配置-VTOR
在Cortex-M3和Cortex-M4处理器中,向量表的位置由SCS中VTOR(Vector Table Offset Register)的设置决定。
处理器架构要求
从架构上讲,在更改VTOR后,如果要立即产生异常并使用最新的向量表设置,则应该使用DSB指令。
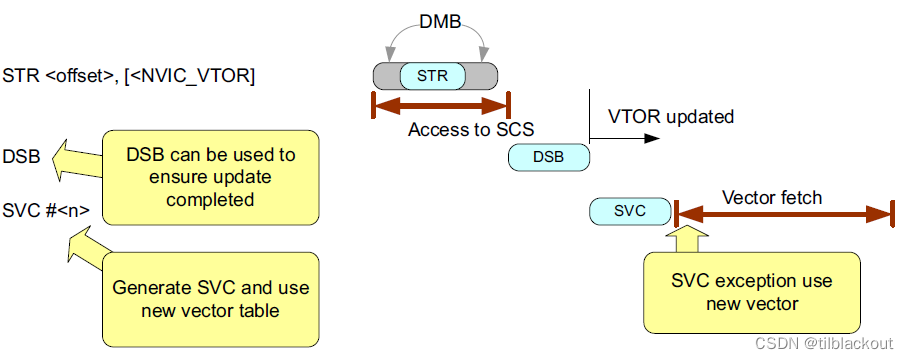
系统实现要求
在Cortex-M3、Cortex-M4和Cortex-M0+处理器中,对SCS的访问本身就具有DSB屏障,因此不需要插入DSB指令。
- Cortex-M0处理器没有
VTOR
12 向量表条目配置
这里指的是更新向量表中的各个条目(entry)。
处理器架构要求
如果向量表位于RAM(如SRAM/SDRAM)中,无论是通过VTOR重新定位还是通过设备相关的内存重映射机制进行重新定位,从架构上讲,在更新向量表条目后,如果要立即使能异常,则需要使用内存屏障指令。如下图所示:
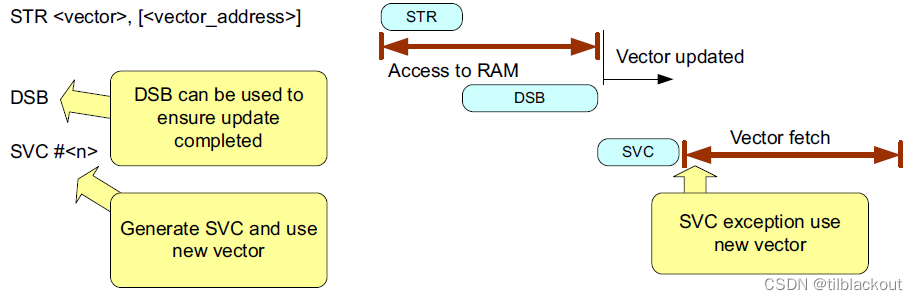
如果下一条指令是访问RAM,则还需要一个DMB指令:
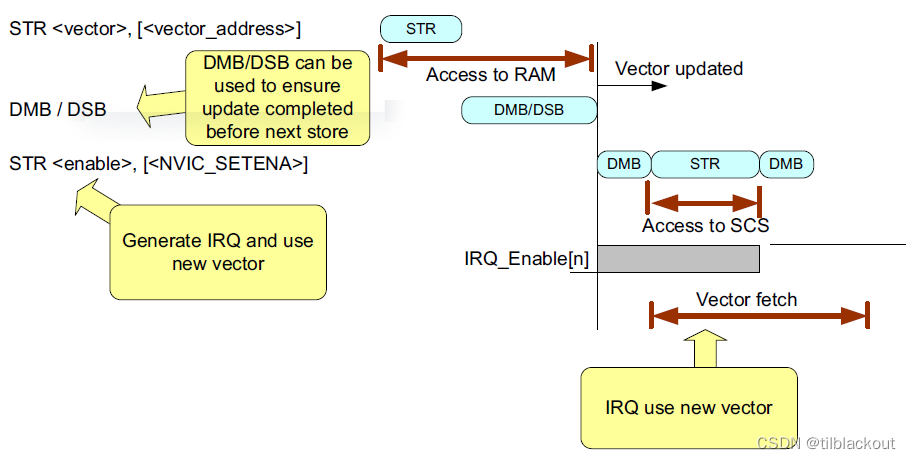
也就是说如果向量表保存在普通内存而不是强有序内存中,需要考虑内存屏障操作。
系统实现要求
在Cortex-M处理器中,省略DSB或DMB指令在修改向量条目时不会引发任何问题,因为异常条目序列在最后一个内存访问完成之前不会启动。
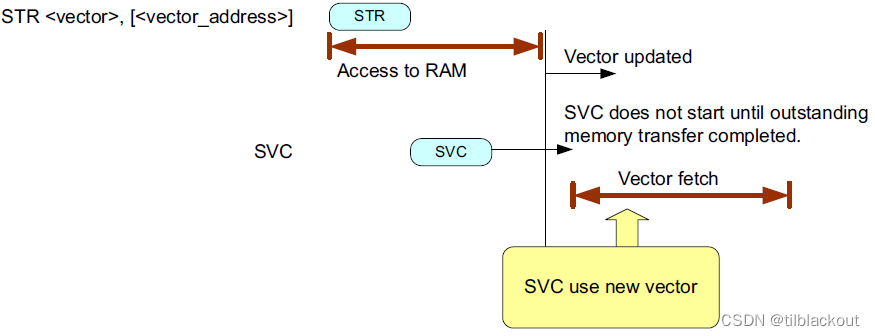
13 内存映射的改变
许多微控制器都包含了一种特定于设备的内存重映射功能,允许在运行时通过编程配置寄存器来更改内存映射,这个寄存器应放置在设备内存(device memory)中。在更改内存映射配置期间是否需要内存屏障指令取决于以下因素:
- 受影响的内存空间是否涵盖程序代码,即是否包括指令。
- 处理器与内存配置寄存器之间的特定于设备的数据路径,例如写缓冲区(CPU和寄存器之间需要经过写缓冲区)。
处理器架构要求
这里讨论的要求适用以下条件: - 除了处理器内部的任何内部写缓冲区外,没有影响内存重映射控制寄存器的设备特定写缓冲区
- 内存映射切换中没有额外的硬件延迟
从架构上讲,在进行内存映射更改的前后,应该插入内存屏障指令:
... ; application code before switching
DSB ; Ensure all memory accesses are completed
STR <remap>, [<remap_reg>] ; Write to memory; map control register
DSB ; Ensure the write is completed
ISB ; Flush instruction buffer (optional, only required if
; the memory map change affects program memory)
... ; application code after switching
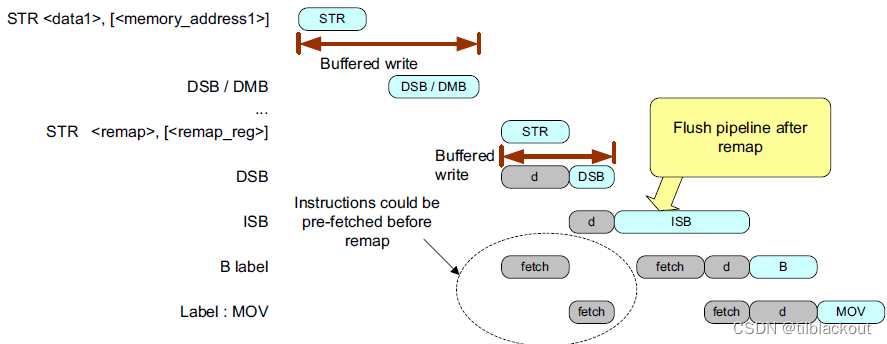
如果受影响的内存没有在任何程序代码中使用,则在内存映射更改后需要插入DSB指令,但可以省略ISB指令。
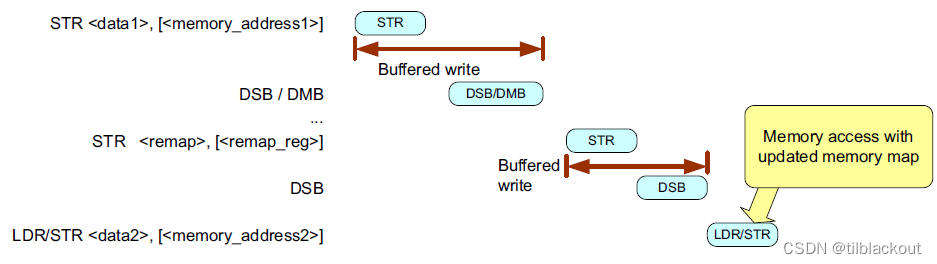
系统实现要求
这里讨论的要求同样适用以下条件:
- 除了处理器内部的任何内部写缓冲区外,没有影响内存重映射控制寄存器的设备特定写缓冲区
- 内存映射切换中没有额外的硬件延迟
在Cortex-M处理器中:
- 在进行内存映射更改之前,不需要DSB或DMB指令,因为这些处理器不允许两个写操作序列重叠
- 在重映射后,需要进行DSB然后ISB的序列,以确保使用最新的内存映射获取程序代码
在这个案例研究中,做出了两个假设。如果这些假设无效,例如,如果处理器与内存控制寄存器之间的数据路径包含额外的系统级写缓冲区,那么内存屏障指令不能保证传输完成。在这种情况下:
- 可以从先前访问的区域执行读取操作,以确保写缓冲区被清空。如果已向系统的各个部分发出了多个写传输,可能需要多次读取操作以确保所有写缓冲区都被清空。
- 或者,微控制器或SoC可能具有状态寄存器,指示是否存在任何正在进行的传输,并在内存重映射完成时进行通知。如果需要,这允许程序代码考虑内存重映射逻辑上的额外硬件延迟。
具体的差异还是得详细咨询不同芯片制造商。
14 进入睡眠模式
在Cortex-M处理器中,可以使用WFI和WFE指令进入睡眠模式。
处理器架构要求
从架构上来说,应该在执行WFI或WFE指令之前使用DSB指令:
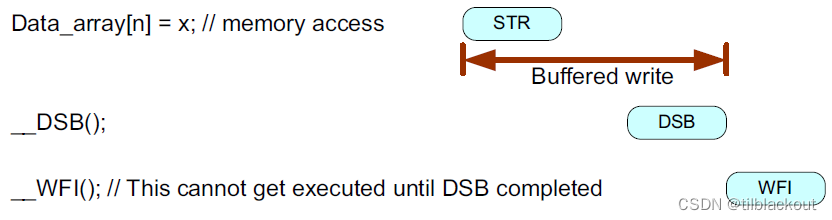
系统实现要求
对于不包含系统级写缓冲区的简单设计,在进入Cortex-M3(r2p0或更高版本)、Cortex-M4、Cortex-M0+和Cortex-M0处理器的睡眠模式之前,不需要使用内存屏障指令。这由处理器自身处理。如果内部总线包含一个位于处理器之外的系统级写缓冲区,则情况就更复杂了。在这种情况下,仅使用DSB指令可能是不够的,因为系统控制逻辑可能会在缓冲写完成之前关闭时钟。
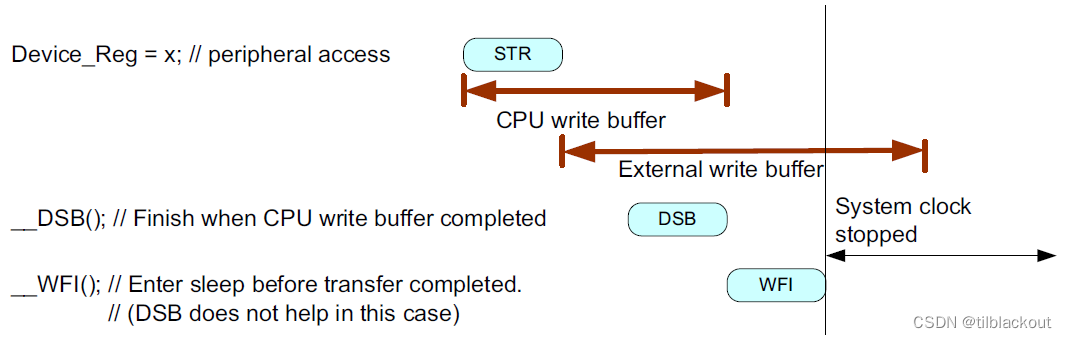
时钟信号被关闭可能不会导致错误,这取决于系统级设计、使用的休眠操作以及进入休眠模式前正在访问的外设。建议联系芯片供应商或制造商获取设备详细信息。通常可以通过向写缓冲器添加一个虚拟读操作以确保写缓冲器被清空来解决这个问题。下图显示了一个可能的解决方法:
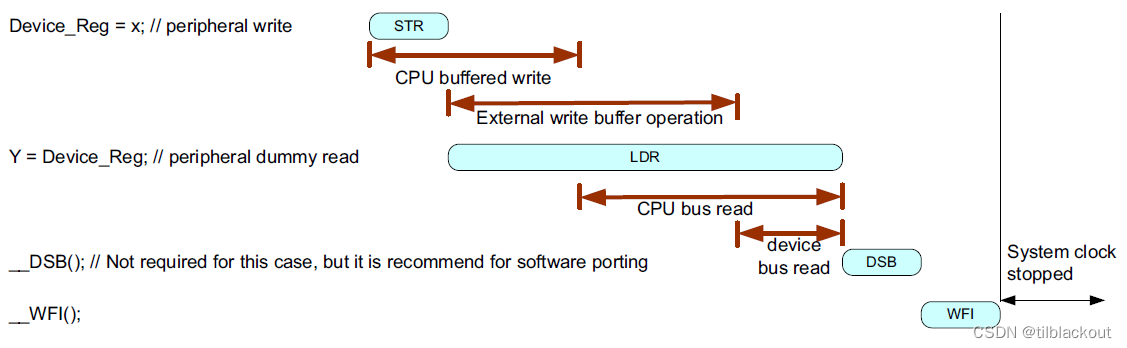
15 自启
Cortex-M处理器具有自启(self-reset)功能。可以通过AIRCR寄存器中的SYSRESETREQ位触发系统复位。在CMSIS库中,可以使用C函数NVIC_SystemReset(void)来使用这个功能。
处理器架构要求
在自启之前,需要使用DSB指令来确保所有未完成的传输都已完成,同时可以使用CPSID I关闭中断,这个是可选的,它可以防止在自启过程中触发一个已启用的中断请求。
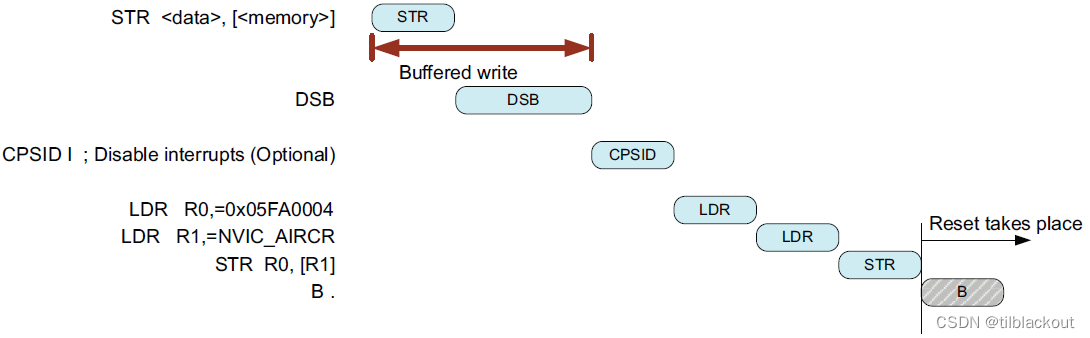
系统实现要求
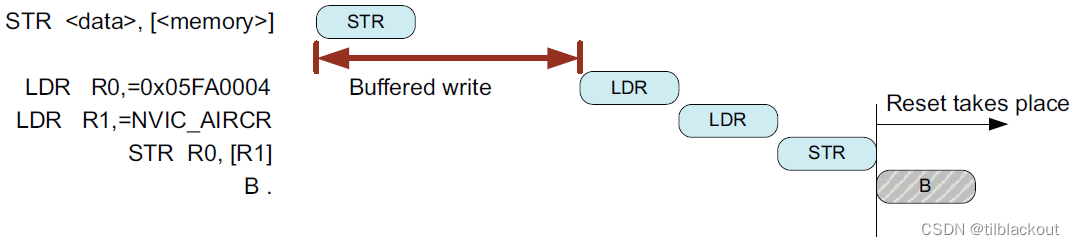
在Cortex-M处理器上,如果没有使用CPSID指令,DSB指令是可选的。因为对SCS的访问已经具有DSB屏障,在写操作完成之前,自启无法开始。如下图所示:
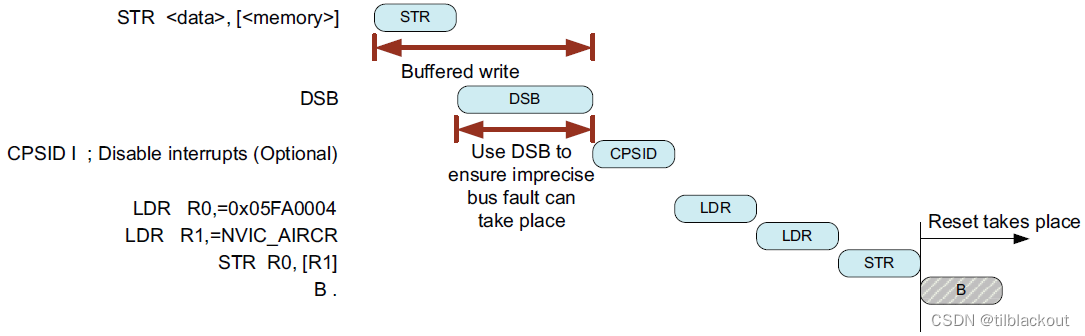
如果使用了CPSID指令,则应插入DSB指令,以确保CPSID在前一个传输完成后才执行。这样,如果前面的传输有导致imprecise bus fault,它会在禁用中断之前发生。
- 在ARMv6-M上没有
bus fault异常,因此在Cortex-M0处理器上不可用
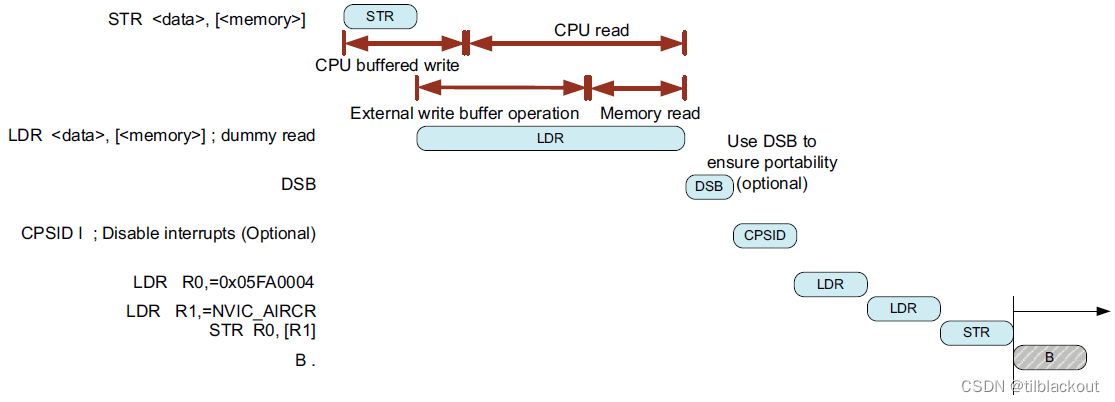
如果系统在总线级别存在写缓冲区时,可以通过在写缓冲区中进行虚拟读操作来确保在执行CPSID指令和进行自启之前,系统级别的写缓冲区已被清空。如下图所示:
如果你使用的是CMSIS 2.0或更高版本,则NVIC_SystemReset(void)函数已经包含了DSB指令。
16 CONTROL寄存器
CONTROL寄存器是Cortex-M处理器中实现的特殊寄存器之一,它可以通过MSR和MRS指令访问。
处理器架构要求
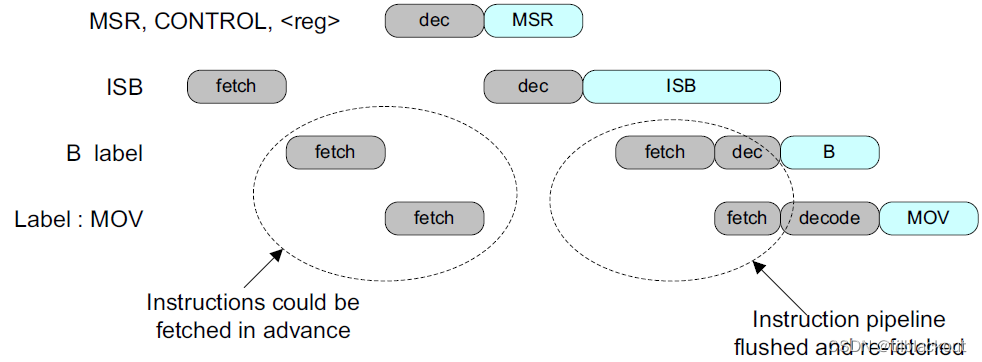
从架构上来说,在修改CONTROL寄存器后,应使用ISB指令。 下面是一个从特权执行切换到非特权执行的代码。
- Cortex-M0中不支持此操作
MOVS R0, #0x1
MSR CONTROL, R0 ; Switch to non-privileged state
ISB ; Instruction Synchronization Barrier
...
ISB确保以正确的特权级别取指,如下图所示:
我们还可以使用CONTROL寄存器来选择在线程模式下使用哪个堆栈指针。
系统实现要求
在Cortex-M处理器中,写入CONTROL寄存器后不执行ISB指令不会导致程序错误,除非你更改特权级别,且之前的权限级别已经预取接下来的指令。当且仅当你需要使用正确权限级别获取后续指令时,才需要ISB指令。
17 MPU编程
MPU是Cortex-M0+、Cortex-M3和Cortex-M4处理器的可选功能。
处理器架构要求
- MPU配置寄存器位于SCS中,因此在MPU编程的每个步骤之间不需要插入内存屏障指令
- 强有序内存不会强制执行与正常内存访问相关的顺序。 在架构设计中,MPU编程序列之前需要执行
DMB,以及在MPU编程完成后使用DSB来确保所有设置都被所有的总线可见 - 如果MPU设置的更改影响程序内存,还应添加一个
ISB指令,以确保使用更新的MPU设置重新获取指令
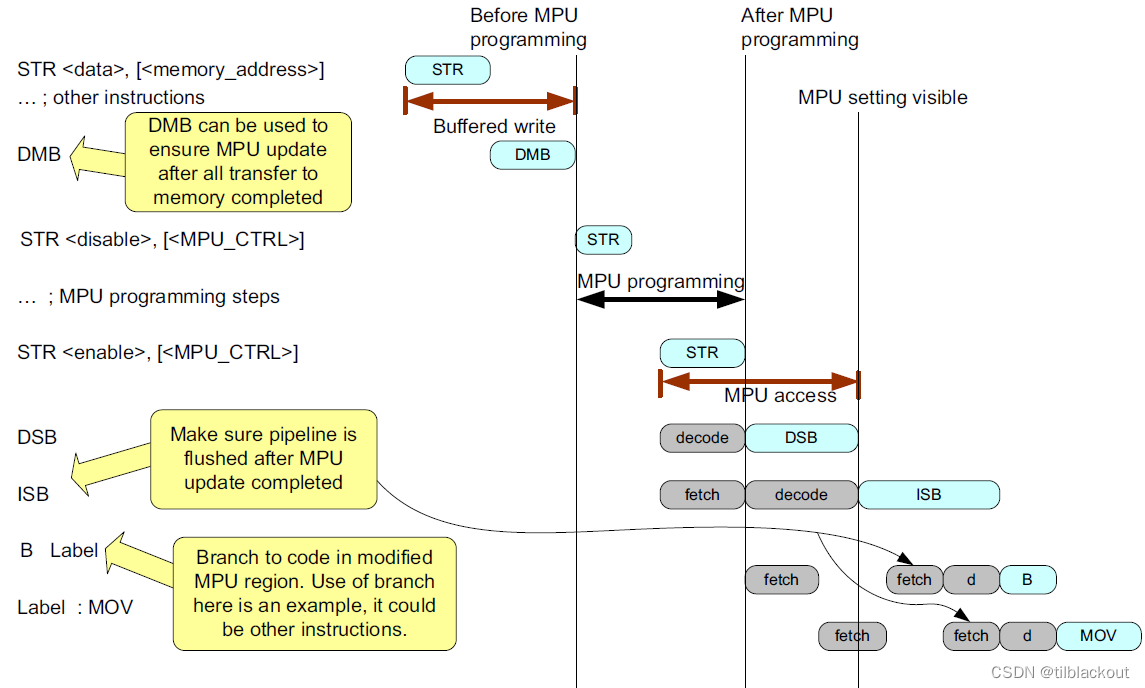
如果在异常处理程序中执行MPU编程步骤,则不需要ISB指令,因为异常进入和退出边界已经具有ISB。例如,在运行RTOS的应用程序中,可以在PendSV异常处理程序内进行上下文切换期间更新用户线程的MPU区域设置。在PendSV和用户线程之间切换异常退出序列,确保MPU设置生效。这适用于当前Cortex-M处理器的架构行为和系统实现。
系统实现要求
- 在Cortex-M0+、Cortex-M3和Cortex-M4处理器上,在进入MPU编程代码之前省略
DMB指令不会引起问题; - 在完成MPU编程代码之后省略
DSB指令也不会引起问题。 - 如果对MPU设置的更改只影响保存数据的内存而不影响保存程序内存,则在Cortex-M处理器上不需要
ISB指令。如果需要使用新的MPU设置来取后续指令,则需要ISB指令。
18 多主系统
如果你希望你的代码在多个系统中都能正常运行,即考虑代码在不同架构下的可移植性,那么使用内存屏障指令是很有必要的。
处理器架构要求
当处理共享数据并且需要确保它们在内存中的顺序不被改变或混乱时,需要使用DMB或DSB指令。例如,则在启动DMA操作之前需要使用DMB指令。
- 也可以使用
DSB代替DMB
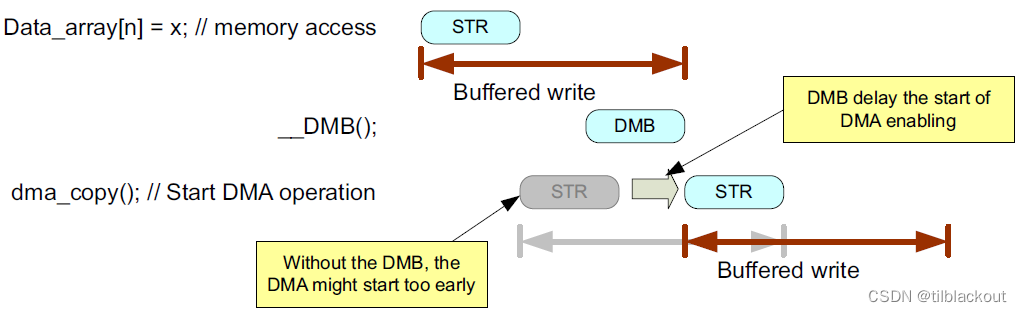
如果没有DMB,在架构上两个存储区可能会被重新排序或重叠,比如DMA可能在数据更新完成之前开始。另一个多主机示例是两个处理器之间共享内存中的信息通信。当向在不同处理器上运行的另一个程序传递数据时,通常会将数据写入共享内存,然后在共享内存中设置一个软件标志。在这种情况下,应使用DMB或DSB指令来确保两个内存访问之间的内存顺序正确:
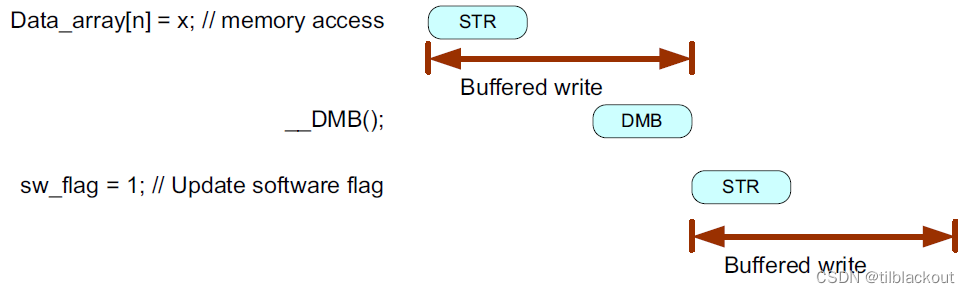
两个处理器之间的交互不限于共享内存。另一种可能的交互方式是事件通信(如消息队列)。在这种情况下,可能需要使用DSB指令来确保内存传输和事件之间的正确顺序被保留。
系统实现要求
在前面处理器架构要求的前两张图中去掉DMB或DSB指令时,并不会产生错误,因为Cortex-M处理器不会重新排序内存传输且不允许两个写传输重叠执行。
在Cortex-M3和Cortex-M4处理器中,处理器架构要求中的最后一张图需要使用DSB指令。但在Cortex-M0处理器中,省略DMB或DSB指令不会导致这三个示例中的任何错误,因为Cortex-M0处理器中没有写缓冲区。
19 信号量和互斥锁(单核和多核)
信号量和互斥量操作在许多操作系统中是必不可少的。它们可以在单处理器环境或多处理器环境中使用。
在多处理器环境中,信号量操作需要将软件变量放置在多个处理器之间共享内存中。为了确保正确的操作,应该使用内存屏障指令。如果在多处理器系统中存在缓存,则必须确保使用正确的缓存配置,以使共享内存中的数据在所有处理器之间一致。
处理器架构要求
在信号量和互斥量操作中应使用DMB指令。下面的例子展示了获取锁的简单代码,获取锁后需要使用DMB指令:
/* Note: __LDREXW和__STREXW是CMSIS函数 */
void get_lock(volatile int *Lock_Variable)
{ int status = 0;do {while (__LDREXW(&Lock_Variable) != 0); // Wait until Lock_Variable is freestatus = __STREXW(1, &Lock_Variable); // Try to set Lock_Variable} while (status!=0); //retry until lock successfully__DMB();return;
}
同样地,释放锁的代码在开始时应该有一个内存屏障:
void free_lock(volatile int *Lock_Variable)
{__DMB(); // Ensure memory operations completed beforeLock_Variable = 0;// releasing lockreturn;
}
这样做是为了避免在释放锁之前,由于流水线的原因,其它线程就“提前”释放了锁,从而可以访问共享资源。
系统实现要求
在使用Cortex-M3和Cortex-M4处理器的微控制器设备上,在信号量和互斥操作中省略DMB指令不会导致错误。但在下面的情况下可能会出错:
- 处理器具有缓存
- 软件在多核系统中使用。
ARM建议在操作系统设计中的信号量和互斥操作中使用DMB指令。
- Cortex-M0和Cortex-M0+处理器没有互斥访问的指令
20 自修改代码
通常我们的代码是静态的,不能被修改。但其实允许程序在运行时修改自己的代码,修改之后的代码会被立即执行,从而改变代码的行为。这种情况一般用于:反作弊(提高程序的复杂性和安全性)、加密和解密(提高数据安全性)。
如果程序包含自修改代码,如果修改后的程序代码要在修改后不久执行,就需要使用内存屏障。由于程序代码可以被预取,应该执行DSB指令,然后执行ISB指令以确保流水线被刷新。
处理器架构要求
架构需求是在修改程序内存后使用DSB指令后紧跟一个ISB指令。
STR <new_instr>, [<inst_address1>]
DSB ; Ensure store is completed before flushing pipeline
ISB ; Flush pipeline
B <inst_address1> ; Execute updated program
下图显示了满足自修改代码的处理器架构和实现要求所需的内存屏障指令。
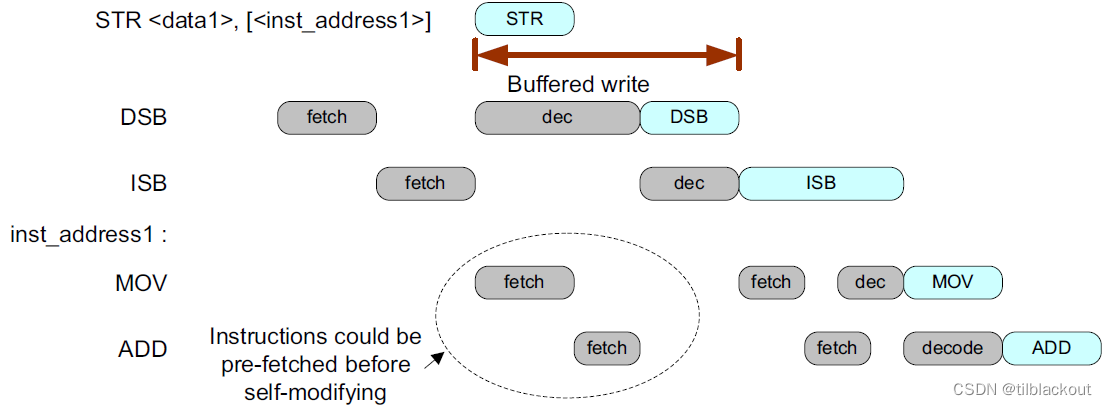
如果系统中存在缓存,则应该缓存刷新操作来确保更新指令缓存。
系统实现要求
总的来说,在修改程序内存后,需要先使用DSB然后使用ISB。如果处理器或系统中没有写缓冲区或缓存,例如基于Cortex-M0的微控制器,则可以省略DSB。
Cortex-M3和Cortex-M4处理器可以预取多达六条指令。如果应用程序在修改程序内存中的指令后不久执行该指令,可能会使用之前的指令。如果指令在修改后一段时间内未使用,程序可能可以正常工作,但不能完全保证。
某些Cortex-M3和Cortex-M4设计可能具有特定于实现的程序缓存以加速程序存储器访问。在修改程序代码后可能需要额外的步骤来确保程序缓存被清除。
总结
在ARM体系架构中,内存屏障是一种用来确保程序在多核或多线程环境下按照预期顺序执行的机制。ARM定义了三种内存屏障指令,分别是DMB(数据内存屏障)、DSB(数据同步屏障)和ISB(指令同步屏障)。
DMB指令用于确保内存访问的顺序性。在多核处理器中,不同核的缓存可能会引起数据一致性的问题,DMB指令在多核之间添加屏障,确保指令的执行顺序与内存访问的顺序一致,避免数据的读写乱序。
DSB指令用于确保指令的完成和数据的同步。它保证在DSB指令之前的所有指令都已经完成执行,然后再执行DSB指令之后的指令。这样可以避免指令的乱序执行和数据的读写乱序,确保执行的顺序性。
ISB指令用于确保指令的同步。它会刷新所有的指令缓存和流水线,使指令序列的执行从ISB指令之后重新开始。这样可以保证在ISB指令之前的所有指令都已经执行完毕,并且清除了所有执行过程中的缓存,使得指令的执行结果与预期一致。
综上所述,ARM的内存屏障机制通过DMB/DSB/ISB指令确保程序在多核或多线程环境下的正确顺序执行。这些指令提供了内存和指令的同步和顺序性保证,保证了程序的正确性和可靠性。
相关文章:
ARM进阶:内存屏障(DMB/DSB/ISB)的20个使用例子详解
在上一节内存屏障指令之DMB、DSB和ISB详解中,介绍了一下内存屏障的三个指令的作用并举了一些例子,对于内存屏障指令的使用时机,与处理器架构(比如Cortex-M和Cortex-A)和处理器的系统实现(同样的架构,有不同的实现,如ST…...
Cpp学习——模板
模板? 目录 模板? 1.介绍 2.函数模板的使用 3.函数模板的强制转换or显式调用 四,模板的分类 1.介绍 在Cpp3.0中,祖师爷便引入了模板的概念。这是一个重大的变革,为后来的Cpp标准化打下了铺垫。也正是因为有了模板࿰…...

HTTP 协议 版本详解
HTTP 协议 介绍<一> 简介 HTTP(Hypertext Transfer Protocol)是一种用于在客户端和服务器之间进行通信的协议。它是现代互联网中最常用的应用层协议之一。HTTP 的主要目的是实现超文本资源的传输,例如 HTML 文档、图像和音频文件等。…...

PHP语言基础知识(超详细)
文章目录 前言第一章 PHP语言学习介绍 1.1 PHP部署安装环境1.2 PHP代码工具选择 第二章 PHP代码基本语法 2.1 PHP函数知识介绍2.2 PHP常量变量介绍 2.2.1 PHP变量知识:2.2.2 PHP常量知识: 2.3 PHP注释信息介绍2.4 PHP数据类型介绍 2.4.1 整形数据类型2.4…...

Flex弹性盒子的项目属性
最近在写项目时用到了弹性盒子的项目属性,记录一下,以后用到继续扩充 <div class"concern-data"><div><img src"https://meituan.thexxdd.cn/lvyou/assets/pinglun-fc62482a.svg" alt""><span>1&…...

广州银行信用卡中心:强化数字引擎安全,实现业务稳步增长
广州银行信用卡中心是全国城商行中仅有的两家信用卡专营机构之一,拥有从金融产品研发至销售及后期风险控制、客户服务完整业务链条,曾获“2016年度最佳创新信用卡银行”。 数字引擎驱动业务增长 安全左移降低开发风险 近年来,广州银行信用卡…...

【Rust日报】2023-08-03 - Polars 获约 400 万美元种子轮融资
文章:2023 年对 Rust 编译器 CI 的改进 kobzol 的新文章,介绍了关于优化 Rust 编译器构建、测试和性能监视基础设施的方案和实施情况。 根据作者的工作,文章内容分为三类: Rust 编译器(rustc)构建配置、 Ru…...
装修小程序,开启装修公司智能化服务的新时代
随着数字化时代的来临,装修小程序成为提升服务质量和效率的关键工具。装修小程序旨在为装修公司提供数字化赋能、提高客户满意度的智慧装修平台。通过装修小程序,装修公司能够与客户进行在线沟通、展示设计方案、提高服务满意度等操作。 装修小程序的好处…...

使用PHP和Redis实现简单秒杀功能
安装Redis 首先,需要在服务器上安装Redis。如果使用Linux系统,可以使用命令行安装。如果使用Windows系统,可以下载并安装Redis二进制文件。 创建Redis连接 在PHP中,可以使用Redis扩展来连接Redis服务器。需要在PHP文件中包含Re…...
 FFmpeg拉取udp组播流并播放)
C#开发FFMPEG例子(API方式) FFmpeg拉取udp组播流并播放
代码及工程见https://download.csdn.net/download/daqinzl/88168680 开发工具:visual studio 2019 网上用C/C调用FFmpeg的API例子很多, c#使用ffmpeg.autogen的方式很简单,直接复制C/C调用FFmpeg的API的代码到C#中,然后在FFmpeg…...

Android性能优化—图片优化
图片优化是内存优化中很重要的一部分,加载Bitmap时往往需要消耗大量的内存,稍不注意就容易导致内存溢出(OOM)。 一、图片OOM问题产生 1、 一个页面一次加载过多图片; 2、加载大图片没有进行压缩(尺寸,质…...
如何搭建自动化测试框架?资深测试整理的PO模式,一套打通自动化...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Po模型介绍 1、简…...
软件外包开发的GO语言特点
Go语言(也称为Golang)是由Google开发的一种编程语言。它具有许多特点,使其成为许多项目范围的优秀选择。Go语言适用于需要高性能、并发和简洁易读的项目,特别是面向网络和分布式应用的项目。今天和大家分享项目的特点及适用的项目…...

【深度学习Week4】MobileNet_ShuffleNet
报错:unsafe legacy renegotiation disabled 解决方案: 尝试了更换cryptography36.0.2版本,以及更换下载链接的方法,都不行,最后采用了手动下载mat文件并上传到colab的方法 高光谱图像分类数据集简介Indian Pines&…...

649. Dota2 参议院
题目描述: 主要思路: 这是一个按照题意模拟的问题,利用队列模拟议员的投票顺序即可。 class Solution { public:string predictPartyVictory(string senate) {queue<int> r,d;int nsenate.length();for(int i0;i<n;i){if(senate[i…...
无人机管控平台,推动电力巡检管理水平提升
各地区无人机作业水平和管理水平存在参差不齐,电力巡检管理要求与业务发展水平不匹配的问题。同时,巡检数据的存储和管理分散,缺乏有效的整合与共享手段,使得内外业脱节,没有形成统一应用和闭环管理。这就导致巡检数据…...
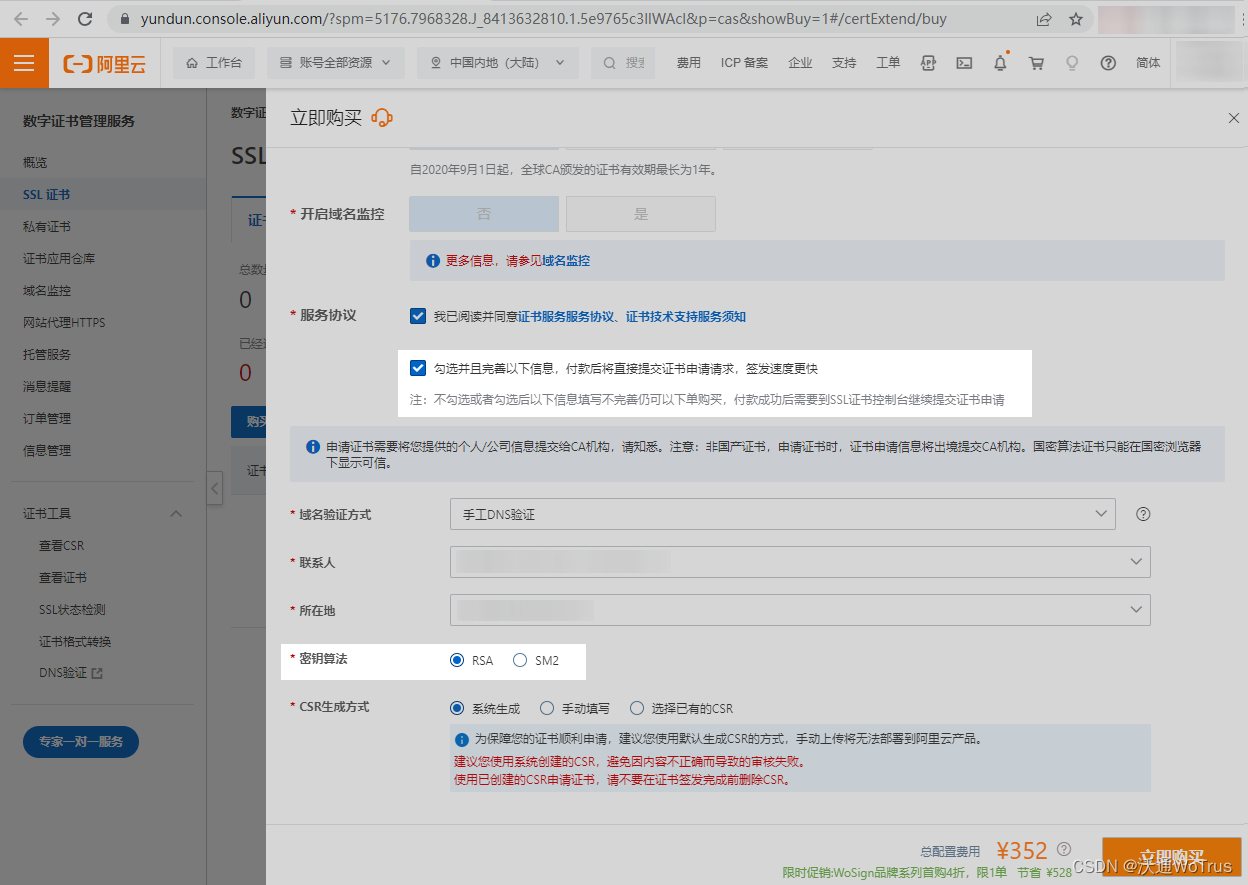
阿里云平台WoSignSSL证书应用案例
沃通CA与阿里云达成合作并在阿里云平台上线WoSign品牌SSL证书。自上线以来,WoSignSSL证书成为阿里云“数字证书管理服务”热销证书产品,获得阿里云平台客户认可,助力阿里云平台政府、金融、教育、供应链、游戏等各类行业客户实现网站系统数据…...
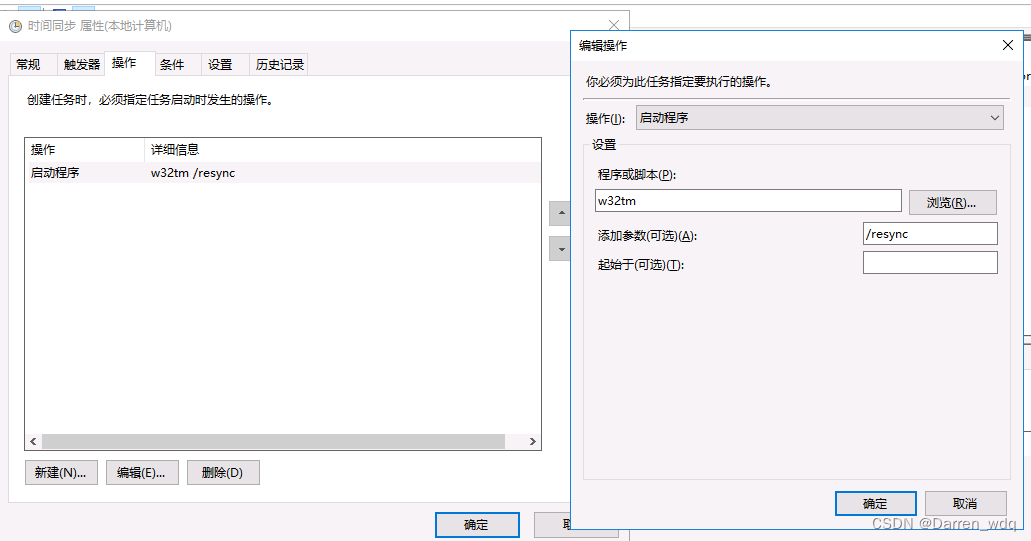
服务器时钟同步
服务器时钟同步 文章目录 服务器时钟同步背景windows时钟同步Linux机器上的时钟同步Centos时钟同步Ubuntu系统时钟同步 查看是否同步的命令 背景 运维,XXX服务器慢了2秒,导致XXX业务没有正常执行,请立即排查为啥会有时钟不同步的问题。 首先…...
AMEYA360:瑞萨电子MCU和MPU产品线将支持Microsoft Visual Studio Code
全球半导体解决方案供应商瑞萨电子宣布其客户现可以使用Microsoft Visual Studio Code(VS Code)开发瑞萨全系列微控制器(MCU)和微处理器(MPU)。瑞萨已为其所有嵌入式处理器开发了工具扩展,并将其…...

JSP--Java的服务器页面
jsp是什么? jsp的全称是Java server pages,翻译过来就是java的服务器页面。 jsp有什么作用? jsp的主要作用是代替Servlet程序回传html页面的数据,因为Servlet程序回传html页面数据是一件非常繁琐的事情,开发成本和维护成本都非常高…...
)
基于单片机的人脸识别门禁系统(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T5912205M设计简介:本设计是基于单片机的人脸识别门禁系统,主要实现以下功能:1、人脸识别并进行红外测温 2、人脸识别并…...

3步终极解决方案:免费Windows系统清理工具让C盘重获新生
3步终极解决方案:免费Windows系统清理工具让C盘重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也遇到过Windows系统C盘突然爆红的尴尬…...

DS18B20寄生供电模式全解析:3.3V系统下的STM32省电测温方案
DS18B20寄生供电模式全解析:3.3V系统下的STM32省电测温方案 在物联网设备开发中,低功耗设计往往决定着产品的成败。当我们需要在电池供电环境下实现长时间温度监测时,DS18B20传感器的寄生供电模式配合STM32的3.3V系统,能为我们带来…...

从抓包困境到源码掌控:微信小程序逆向分析与实战解包指南
1. 微信小程序抓包为何越来越难? 最近两年做过微信小程序抓包的开发者应该都深有体会,以前用Charles、Fiddler这类工具轻松就能抓到的数据包,现在越来越难捕获了。我去年11月接的一个图书馆预约系统项目就遇到了这个难题,当时用尽…...

TensorFlow Lite Micro入门教程:5分钟搭建你的第一个嵌入式AI应用
TensorFlow Lite Micro入门教程:5分钟搭建你的第一个嵌入式AI应用 【免费下载链接】tflite-micro Infrastructure to enable deployment of ML models to low-power resource-constrained embedded targets (including microcontrollers and digital signal process…...

OpenClaw自动化测试:Qwen3-14b_int4_awq在开发提效中的应用
OpenClaw自动化测试:Qwen3-14b_int4_awq在开发提效中的应用 1. 为什么选择OpenClawQwen3组合做测试自动化 去年接手一个持续集成项目时,我每天要花3小时重复执行测试脚本、分析日志。直到发现OpenClaw这个能操控本地环境的AI智能体框架,配合…...

Phi-3-mini-128k-instruct在WSL2中的高效部署与性能调优
Phi-3-mini-128k-instruct在WSL2中的高效部署与性能调优 如果你是一名Windows用户,同时又对运行最新的大语言模型充满兴趣,那么“如何在Windows上高效地跑模型”这个问题,可能已经困扰你很久了。直接在Windows上部署,环境配置复杂…...

AI建站工具选型指南:不同定位工具对比与筛选标准
市面上的建站工具琳琅满目,宣传语都差不多。但对于想用AI建站工具做正经生意的你来说,光看广告远远不够。你需要一套自己的筛选标准,来分辨哪个工具是“玩具”,哪个才是能帮你赚钱的“生产力工具”。这篇文章不会直接告诉你“哪个…...

Keylogger实战案例:从信息收集到数据发送的全过程演示
Keylogger实战案例:从信息收集到数据发送的全过程演示 【免费下载链接】Keylogger Get Keyboard,Mouse,ScreenShot,Microphone Inputs from Target Computer and Send to your Mail. 项目地址: https://gitcode.com/gh_mirrors/ke/Keylogger 键盘记录器&…...

RK3568平台下EM05 4G模块Kernel驱动移植与调试实战
1. RK3568平台EM05 4G模块驱动移植概述 在嵌入式设备开发中,4G模块的集成是物联网项目的关键环节。Rockchip RK3568作为一款高性能处理器,搭配移远通信的EM05 4G模块时,需要完成内核驱动的移植工作。这个过程中最核心的就是让Linux内核正确识…...