【计算机视觉】BLIP:统一理解和生成的自举多模态模型
文章目录
- 一、导读
- 二、背景和动机
- 三、方法
- 3.1 模型架构
- 3.2 预训练目标
- 3.3 BLIP 高效率利用噪声网络数据的方法:CapFilt
- 四、实验
- 4.1 实验结果
- 4.2 各个下游任务 BLIP 与其他 VLP 模型的对比
一、导读
BLIP 是一种多模态 Transformer 模型,主要针对以往的视觉语言训练 (Vision-Language Pre-training, VLP) 框架的两个常见问题:
- 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。
- 大多数现有的预训练模型为了提高性能,使用从网络收集的嘈杂图像-文本对扩展数据集。这样虽然提高了性能,但是很明显这个带噪声的监督信号肯定不是最优的。
BLIP 这种新的 VLP 框架可以灵活地在视觉理解任务上和生成任务上面迁移,这是针对第一个问题的贡献。
至于第二个问题,BLIP 提出了一种高效率利用噪声网络数据的方法。即先使用嘈杂数据训练一遍 BLIP,再使用 BLIP 的生成功能生成一系列通过预训练的 Captioner 生成一系列的字幕,再把这些生成的字幕通过预训练的 Filter 过滤一遍,得到干净的数据。最后再使用干净的数据训练一遍 BLIP。

论文地址:
https://larxiv.org/pdf/2201.12086.pdf
代码地址:
https://github.com/salesforce/BLIP
二、背景和动机
视觉语言训练 (Vision-Language Pre-training, VLP) 最近在各种多模态下游任务上取得了巨大的成功。然而,现有方法有两个主要限制:
- 模型层面: 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。比如,基于编码器的模型,像 CLIP,ALBEF 不能直接转移到文本生成任务 (比如图像字幕),而基于编码器-解码器的模型,像 SimVLM 不能直接用于图像文本检索任务。
- 数据层面:大多数现有的预训练模型为了提高性能,使用从网络收集的嘈杂图像-文本对扩展数据集。这样虽然提高了性能,但是很明显这个带噪声的监督信号肯定不是最优的。
本文提出了 BLIP:Bootstrapping LanguageImage Pre-training,用于统一的视觉语言理解和生成。BLIP 是一种新的 VLP 框架,与现有的方法相比,它可以实现更广泛的下游任务。它分别从模型和数据的角度引入了两个贡献:
-
BLIP 提出了一种编码器-解码器混合架构 (Multimodal mixture of Encoder-Decoder, MED),MED 的特点是很灵活,它既可以作为单模态的编码器,又可以作为基于图像的文本编码器,或者基于图像的文本解码器。BLIP 由三个视觉语言目标联合训练:图像文本的对比学习、图像文本匹配和图像条件语言建模。
-
BLIP 提出了一种高效率利用噪声网络数据的方法。即先使用嘈杂数据训练一遍 BLIP,再使用 BLIP 的生成功能生成一系列通过预训练的 Captioner 生成一系列的字幕,再把这些生成的字幕通过预训练的 Filter 过滤一遍,从原始网络文本和合成文本中删除嘈杂的字幕,得到干净的数据。最后再使用干净的数据训练一遍 BLIP。
三、方法
3.1 模型架构
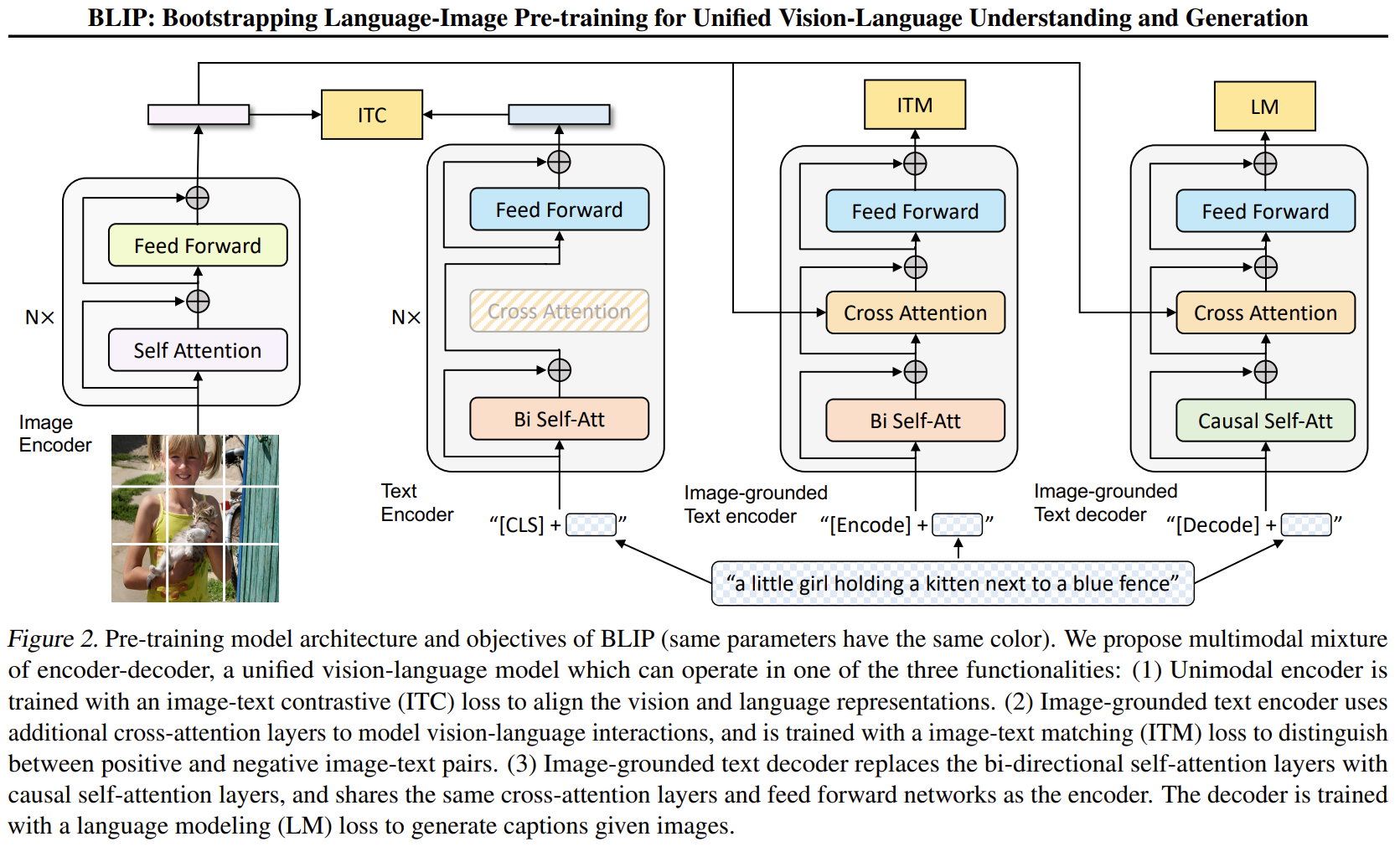
最左边的是视觉编码器,就是 ViT 的架构。将输入图像分割成一个个的 Patch 并将它们编码为一系列 Image Embedding,并使用额外的 [CLS] token 来表示全局的图像特征。
视觉编码器不采用之前的基于目标检测器的形式,因为 ViLT 和 SimVLM 等工作已经证明了 ViT 计算更加友好。
第2列的是视觉编码器,就是 BERT 的架构,其中 [CLS] token 附加到文本输入的开头以总结句子。作用是提取文本特征做对比学习。
第3列的是视觉文本编码器,使用 Cross-Attention,作用是根据 ViT 给的图片特征和文本输入做二分类,所以使用的是编码器,且注意力部分是双向的 Self-Attention。添加一个额外的 [Encode] token,作为图像文本的联合表征。
第4列的是视觉文本解码器,使用 Cross-Attention,作用是根据 ViT 给的图片特征和文本输入做文本生成的任务,所以使用的是解码器,且注意力部分是 Casual-Attention,目标是预测下一个 token。添加一个额外的 [Decode] token 和结束 token,作为生成结果的起点和终点。
一个需要注意的点是:相同颜色的部分是参数共享的,即视觉文本编码器和视觉文本解码器共享除 Self-Attention 层之外的所有参数。每个 image-text 在输入时,image 部分只需要过一个 ViT 模型,text 部分需要过3次文本模型。
3.2 预训练目标
BLIP 在预训练期间联合优化了3个目标,有两个理解任务的目标函数和一个生成任务的目标函数。
- 对比学习目标函数 (Image-Text Contrastive Loss, ITC)
ITC 作用于1 视觉编码器 和 2 文本编码器,目标是对齐视觉和文本的特征空间。方法是使得正样本图文对的相似性更大,负样本图文对的相似性更低,在 ALBEF 里面也有使用到。作者在这里依然使用了 ALBEF 中的动量编码器,它的目的是产生一些伪标签,辅助模型的训练。
- 图文匹配目标函数 (Image-Text Matching Loss, ITM)
ITM 作用于1 视觉编码器 和 3 视觉文本编码器,目标是学习图像文本的联合表征,以捕获视觉和语言之间的细粒度对齐。ITM 是一个二分类任务,使用一个分类头来预测图像文本对是正样本还是负样本。作者在这里依然使用了 ALBEF 中的 hard negative mining 技术。
- 语言模型目标函数 (Language Modeling Loss, LM)
BLIP 包含解码器,用于生成任务。既然有这个任务需求,那就意味着需要一个针对于生成任务的语言模型目标函数。LM 作用于1 视觉编码器 和 4 视觉文本编码器,目标是根据给定的图像以自回归方式来生成关于文本的描述。与 VLP 中广泛使用的 MLM 损失 (完形填空) 相比,LM 使模型能够将视觉信息转换为连贯的字幕。
3.3 BLIP 高效率利用噪声网络数据的方法:CapFilt
高质量的人工注释图像-文本对 { I h , T h } \{I_h, T_h\} {Ih,Th}(例如, COCO) 因为成本高昂所以数量不多。最近的工作 ALBEF, SimVLM 利用从网络自动收集的大量替代的图文对 { I w , T w } \{I_w, T_w\} {Iw,Tw} 。但是, 这些网络的替代数据集通常不会准确地描述图像的视觉内容, 质量相对嘈杂, 带噪声的监督信号肯定不是最优的。
BLIP 这里提出了一种高效率利用噪声网络数据的方法:Captioning and Filtering,CapFilt。
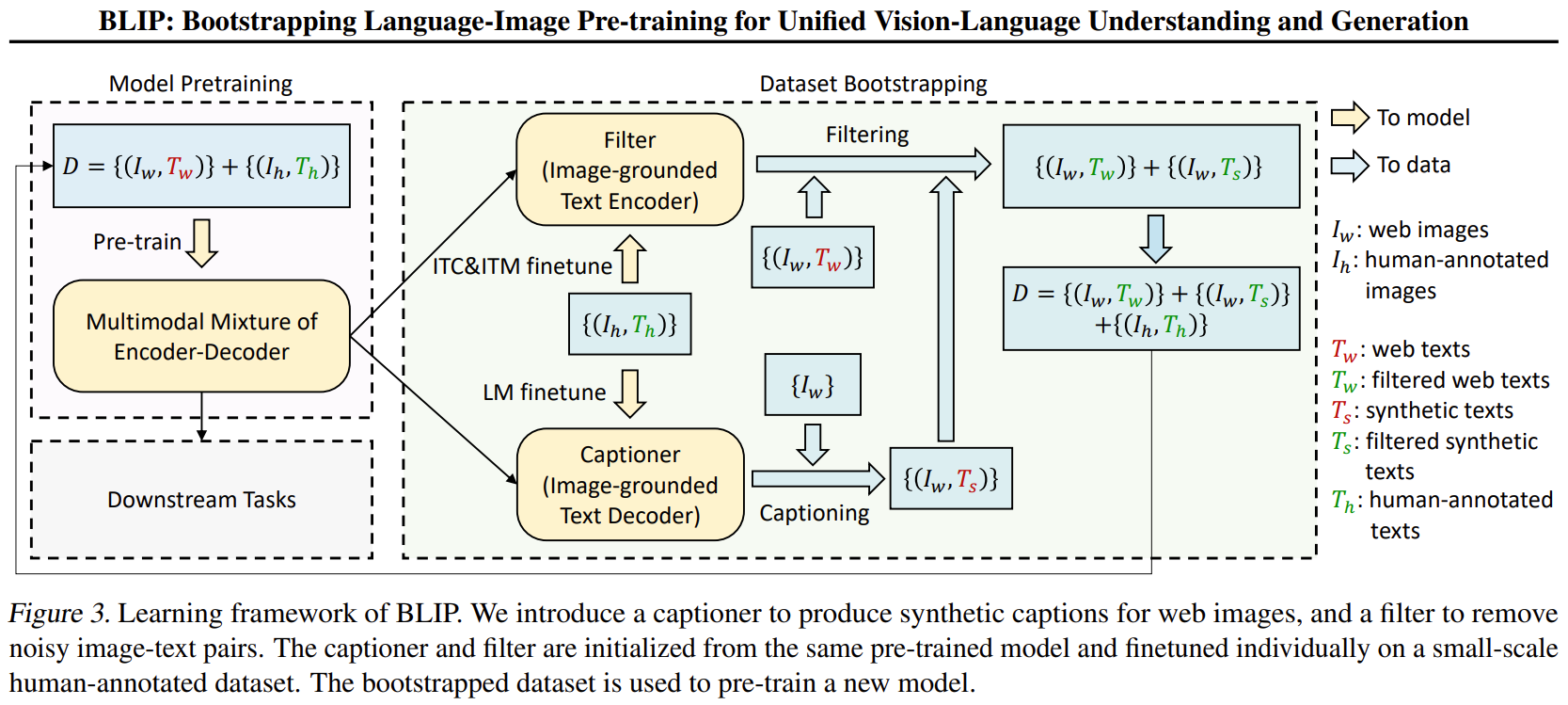
CapFilt 方法如上图2所示。它包含两个模块:
字幕器 Captioner: 给一张网络图片,生成字幕。它是一个视觉文本解码器,在 COCO 数据集上使用 LM 目标函数微调。给定网络图片 I w I_w Iw,Captioner 生成字幕 T s T_s Ts。
过滤器 Filter: 过滤掉噪声图文对。它是一个视觉文本编码器,看文本是否与图像匹配,在 COCO 数据集上使用 ITC 和 ITM 目标函数微调。Filter 删除原始 Web 文本 T w T_w Tw,和合成文本 T s T_s Ts中的嘈杂文本,如果 ITM 头将其预测为与图像不匹配,则认为文本有噪声。
最后,将过滤后的图像-文本对与人工注释对相结合,形成一个新的数据集,作者用它来预训练一个新的模型。
四、实验
BLIP 在两个 16-GPU 节点上面做预训练,视觉编码器以 ImageNet-1K 上预训练的 ViT 权重初始化,文本编码器以 BERT-Base 的权重初始化。使用 2880 的 Batch Size 训练 20 Epochs。
预训练数据集和 ALBEF 一样:
使用下面4个数据集,图片数加起来大概是 4M。
- Conceptual Captions
- SBU Captions
- COCO
- Visual Genome
还引入了噪声更大的 Conceptual 12M 数据集,最终将图像总数增加到 14.1M (有的数据集失效了)。作者还尝试了一个额外的 web 数据集 LAION ,该数据集包含 115M 图像,具有更多的噪声文本。
4.1 实验结果
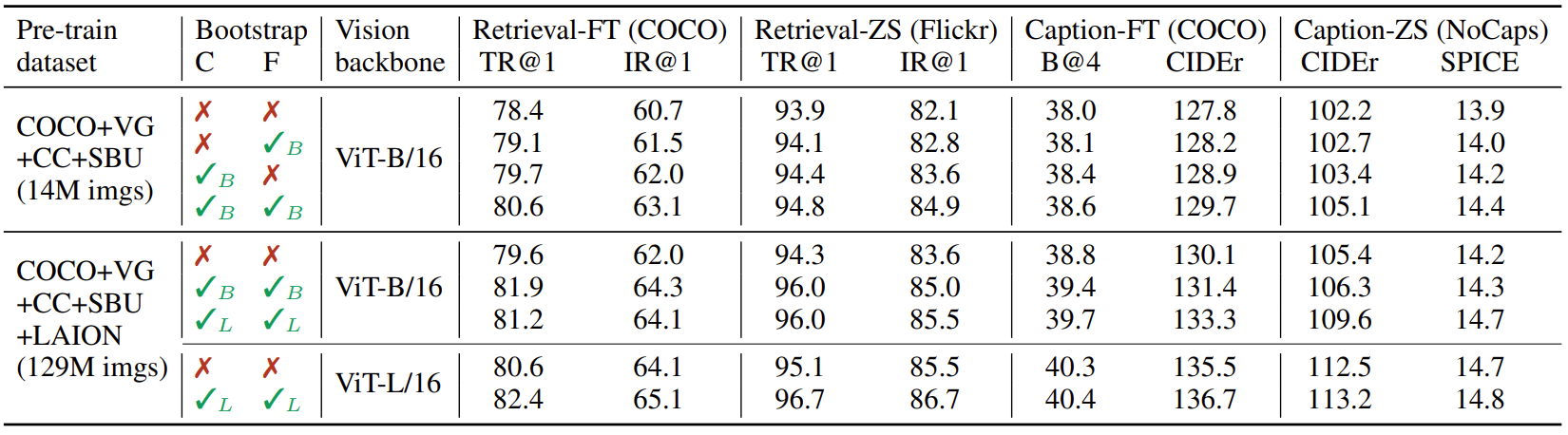
如下图所示,作者比较了在不同数据集上预训练的模型,是一个 CapFilt 的消融实验结果。Retrieval 代表检索任务的结果,Caption 代表生成任务的结果。
当使用 14M 的数据集设置时,联合使用字幕器 Captioner 和过滤器 Filter 可以观察到性能改进,而且它们的效果相互互补,证明了 CapFilt 方法能够从嘈杂的原始数据中提炼出有用的数据。
当使用更大的数据集 129M 的设置或者更大的模型 ViT-L 时,CapFilt 可以进一步提高性能,这验证了它在数据大小和模型大小方面的可扩展性。而且,仅仅增加字幕器和过滤器的模型尺寸时,也可以提高性能。
下图4中,作者展示了一些示例的字幕与对应的图片。 T w T_w Tw是直接从网络上爬取的原始字幕, T s T_s Ts是字幕器生成的字幕。图4中的红色文本是 Filter 删除的文本,绿色文本是 Filter 保留下来的文本。可以看出几张图片里面,红色的文本不是不好,只是没有绿色的文本对图片的描述更加贴切。这个结果说明了 CapFilt 方法确实是能够提升图文对数据集的质量。

4.2 各个下游任务 BLIP 与其他 VLP 模型的对比
检索任务实验结果:
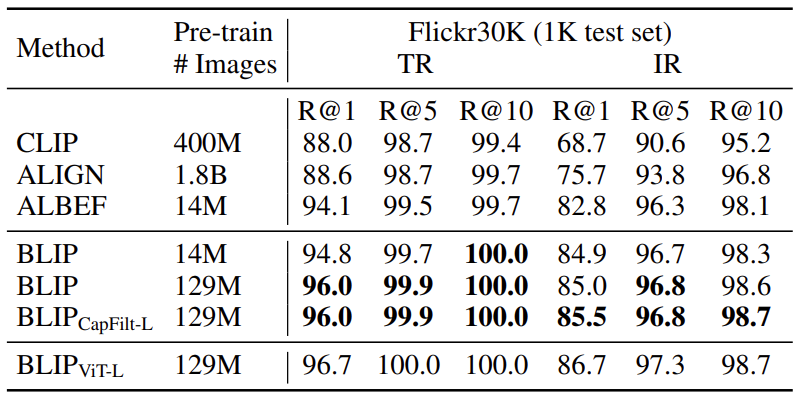
如下图所示是检索任务实验结果,作者做了两个数据集 COCO 和 Flickr30K。与现有方法相比,BLIP 实现了显着的性能提升。使用相同的 14M 预训练图像,BLIP 在 COCO 上的平均召回率 R@1 上比之前的最佳模型 ALBEF 高出 +2.7%。作者还通过将在 COCO 上微调的模型直接迁移到 Flickr30K 来做 Zero-Shot Retrieval。结果如图6所示,其中 BLIP 的性能也大大优于现有的方法。

图片字幕实验结果:
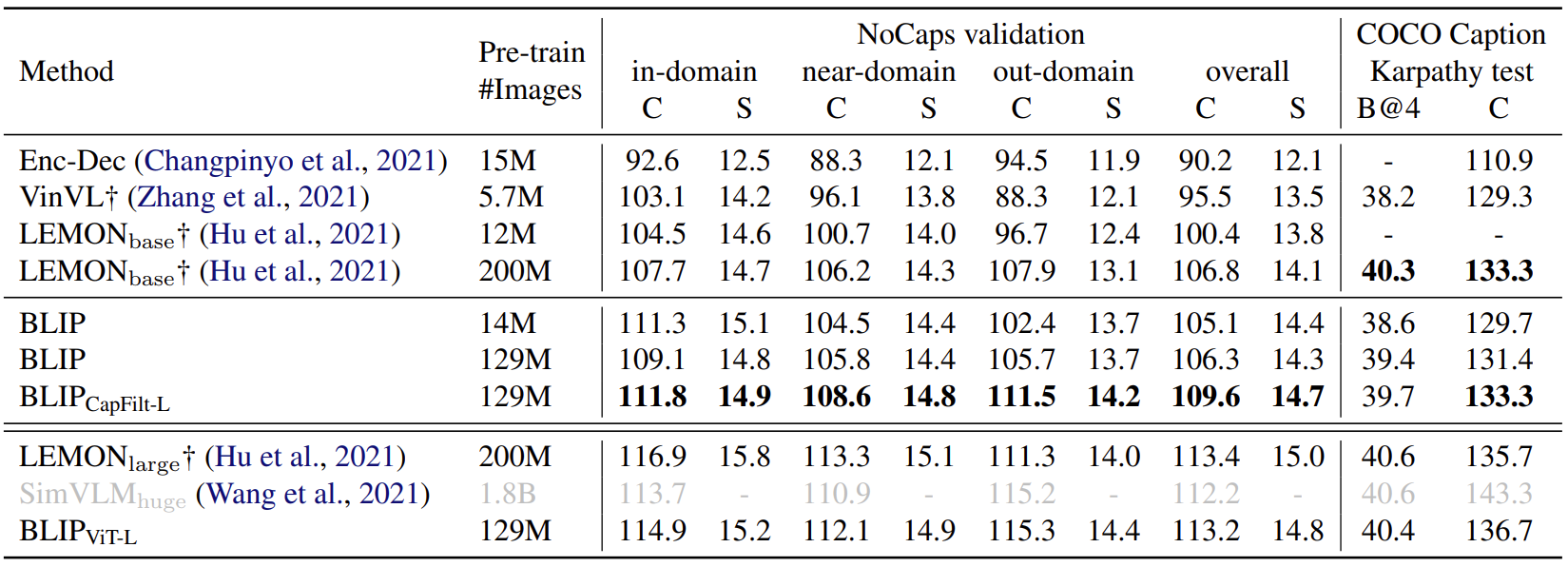
如下图所示是图片字幕任务实验结果,作者做了两个数据集 NoCaps 和 COCO,两者都使用在 COCO 上微调的模型和 LM 损失进行评估。作者遵循 SimVLM 的做法在每个字幕的开头添加了一个提示 “a picture of”,发现这样使得结果更好了。使用了 14M 预训练图像的 BLIP 大大优于使用相似数量预训练数据的方法。使用了 129M 图像的 BLIP 实现了与使用了 200M 的 LEMON 相比具有竞争力的性能。值得注意的是,LEMON 需要很耗费计算量的预训练的目标检测器和更高分辨率 (800×1333) 的输入图像,导致推理时间比使用低分辨率 (384×384) 输入图像的无检测器 BLIP 慢得多。
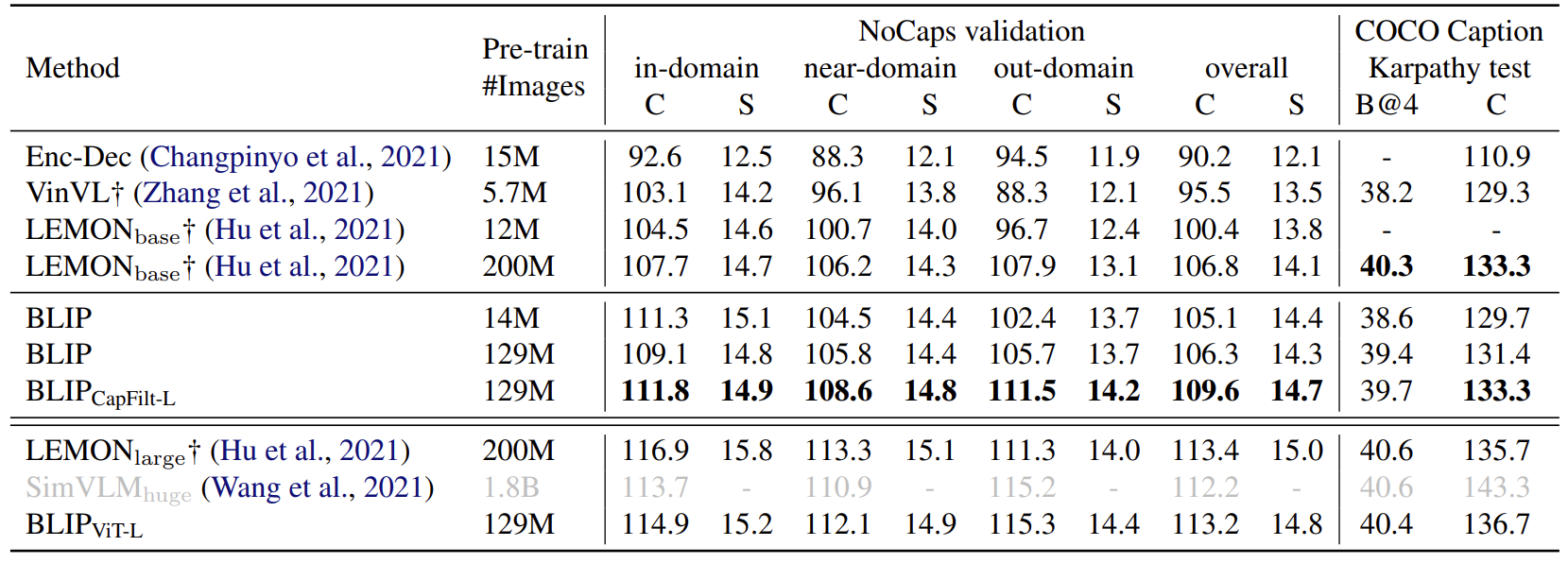
视觉问答 (Visual Question Answering, VQA) 实验结果:
VQA 要求模型预测给定图像和问题的答案。BLIP 没有将 VQA 制定为多答案分类任务,而是按照 ALBEF 的做法把 VQA 视为一种答案生成的任务。结构如下图8所示,在微调过程中,作者重新排列预训练模型,把视觉编码器的输出塞进文本编码器,这样图像和问题就编码为了多模态嵌入,再把这个表征输入文本解码器获得答案。VQA 模型使用真实答案作为目标使用 LM 损失进行微调。
结果如下图9所示,使用 14M 图像,BLIP 在测试集上优于 ALBEF 1.64%。
相关文章:
【计算机视觉】BLIP:统一理解和生成的自举多模态模型
文章目录 一、导读二、背景和动机三、方法3.1 模型架构3.2 预训练目标3.3 BLIP 高效率利用噪声网络数据的方法:CapFilt 四、实验4.1 实验结果4.2 各个下游任务 BLIP 与其他 VLP 模型的对比 一、导读 BLIP 是一种多模态 Transformer 模型,主要针对以往的…...
【Ansible】Ansible自动化运维工具之playbook剧本搭建LNMP架构
LNMP 一、playbooks 分布式部署 LNMP1. 环境配置2. 安装 ansble3. 安装 nginx3.1 准备 nginx 相关文件3.2 编写 lnmp.yaml 的 nginx 部分3.3 测试 nginx4. 安装 mysql4.1 准备 mysql 相关文件4.2 编写 lnmp.yaml 的 mysql 部分4.3 测试 mysql5. 安装 php5.1 编写 lnmp.yaml 的 …...

Spring中的事务
一、为什么需要事务? 事务定义 将一组操作封装成一个执行单元(封装到一起),要么全部成功,要么全部失败。 为什么要用事务? 比如转账分为两个操作: 第一步操作: A 账户 -100 元…...
38 非法地址访问的 segment fault 的调试
前言 在前面一篇文章 coredump 的生成和使用 中, 我们看到 "测试用例2 - 非法地址访问" 产生了一个 segment fault 我们这里 就来调试一下 这个 segment fault 是怎么回事 测试用例 #include "stdio.h"int main(int argc, char** argv) {int x 2; i…...
的用法详解)
c++中c_str()的用法详解
c_str()就是将C的string转化为C的字符串数组!!! C中没有string,所以函数c_str()就是将C的string转化为C的字符串数组,c_str()生成一个const char *指针,指向字符串的首地址。 下文通过3段简单的代码比较分析…...

谈谈关于新能源汽车的话题
新能源汽车是指使用新型能源替代传统燃油的汽车,主要包括纯电动汽车、插电式混合动力汽车和燃料电池汽车等。随着环境污染和能源安全问题的日益突出,新能源汽车已经成为全球汽车行业的发展趋势。下面我们来谈谈关于新能源汽车的话题。 首先,新…...
)
EventBus 开源库学习(二)
整体流程阅读 EventBus在使用的时候基本分为以下几步: 1、注册订阅者 EventBus.getDefault().register(this);2、订阅者解注册,否者会导致内存泄漏 EventBus.getDefault().unregister(this);3、在订阅者中编写注解为Subscribe的事件处理函数 Subscri…...

4_Apollo4BlueLite电源管理
1.Cortex-M4 Power Modes Apollo4BlueLite支持以下4种功耗模式: ▪ High Performance Active (not a differentiated power mode for the Cortex-M4) ▪ Active ▪ Sleep ▪ Deep Sleep (1)High Performance Mode 高性能模式不是arm定…...

Pytorch入门学习——快速搭建神经网络、优化器、梯度计算
我的代码可以在我的Github找到 GIthub地址 https://github.com/QinghongShao-sqh/Pytorch_Study 因为最近有同学问我如何Nerf入门,这里就简单给出一些我的建议: (1)基本的pytorch,机器学习,深度学习知识&a…...

举例说明typescript的Exclude、Omit、Pick
一、提前知识说明:联合类型 typescript的联合类型是一种用于表示一个值可以是多种类型中的一种的类型。我们使用竖线(|)来分隔每个类型,所以number | string | boolean是一个可以是number,string或boolean的值的类型。…...

记录一次Linux环境下遇到“段错误核心已转储”然后利用core文件解决问题的过程
参考Linux 下Coredump分析与配置 在做项目的时候,很容易遇到“段错误(核心已转储)”的问题。如果是语法错误还可以很快排查出来问题,但是碰到coredump就没办法直接找到问题,可以通过设置core文件来查找问题࿰…...

WPF中自定义Loading图
纯前端方式,通过动画实现Loading样式,如图所示 <Grid Width"35" Height"35" HorizontalAlignment"Center" VerticalAlignment"Center" Name"Loading"><Grid.Resources><DrawingBrus…...
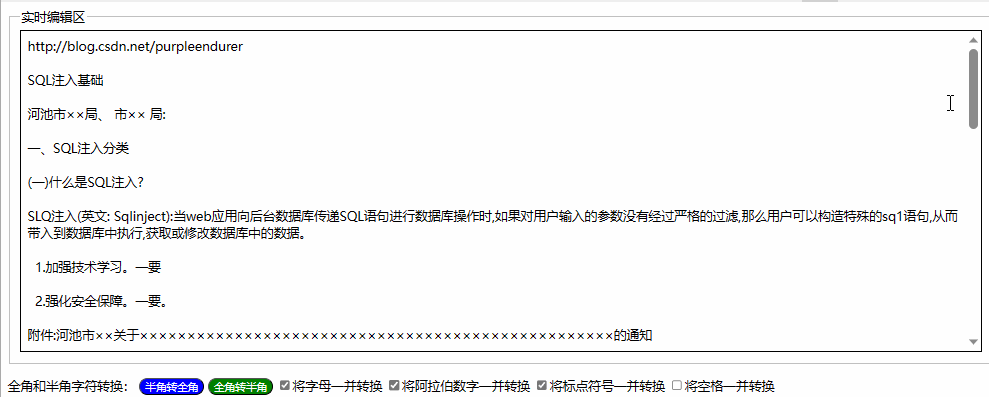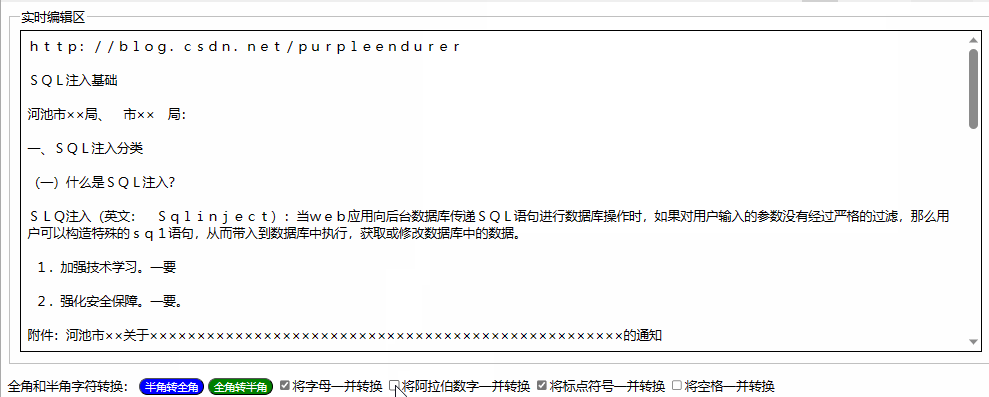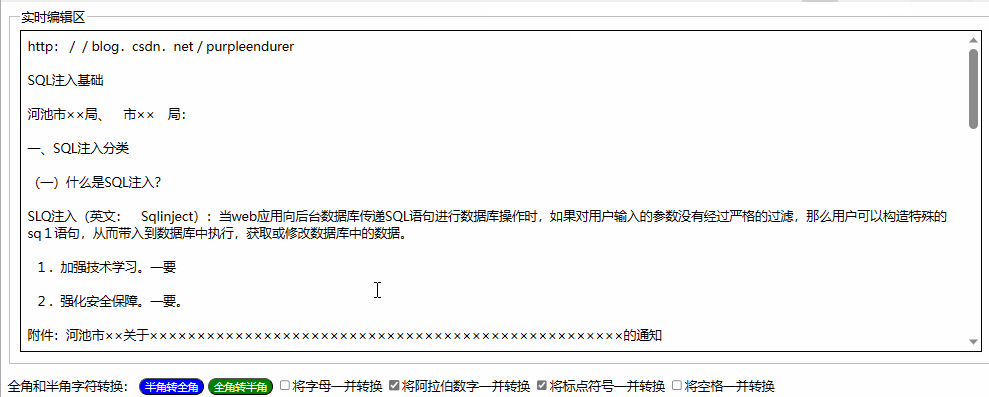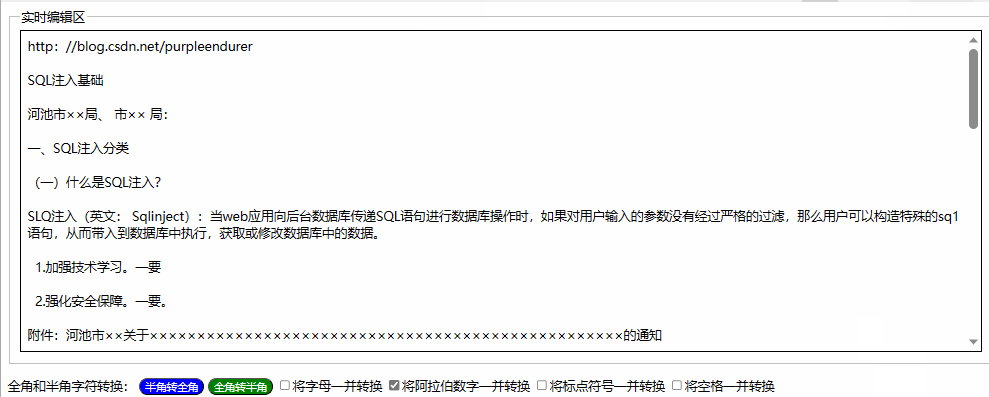
用html+javascript打造公文一键排版系统14:为半角和全角字符相互转换功能增加英文字母、阿拉伯数字、标点符号、空格选项
一、实际工作中需要对转换选项细化内容 在昨天我们实现了最简单的半角字符和全角字符相互转换功能,就是将英文字母、阿拉伯数字、标点符号、空格全部进行转换。 在实际工作中,我们有时只想英文字母、阿拉伯数字、标点符号、空格之中的一两类进行转换&a…...

叮咚买菜财报分析:叮咚买菜第二季度财报将低于市场预期
来源:猛兽财经 作者:猛兽财经 卖方分析师对叮咚买菜第二季度财报的预测 尽管叮咚买菜(DDL)尚未明确披露第二季度财报的具体日期,但根据其以往的业绩公告,猛兽财经认为叮咚买菜很有可能会在8月的第二周发布…...
设计模式行为型——中介者模式
目录 什么是中介者模式 中介者模式的实现 中介者模式角色 中介者模式类图 中介者模式代码实现 中介者模式的特点 优点 缺点 使用场景 注意事项 实际应用 什么是中介者模式 中介者模式(Mediator Pattern)属于行为型模式,是用来降低…...

Vue——formcreate表单设计器自定义组件实现(二)
前面我写过一个自定义电子签名的formcreate表单设计器组件,那时初识formcreate各种使用也颇为生疏,不过总算套出了一个组件不是。此次时隔半年又有机会接触formcreate,重新熟悉和领悟了一番各个方法和使用指南。趁热打铁将此次心得再次分享。…...
 和 人脸识别(Face recognition) 的区别)
人脸验证(Face verification) 和 人脸识别(Face recognition) 的区别
人脸验证(Face verification) 和 人脸识别(Face recognition) 的区别 Face verification 和 Face recognition 都是人脸识别的技术,但是它们的应用和目的不同。 Face verification(人脸验证)是指通过比对两张人脸图像,判断它们是…...

前端如何打开钉钉(如何唤起注册表中路径与软件路径不关联的软件)
在前端唤起本地应用时,我查询了资料,在注册表中找到腾讯视频会议的注册表情况,如下: 在前端代码中加入 window.location.href"wemeet:"; 就可以直接唤起腾讯视频会议,但是我无法唤起钉钉 之所以会这样&…...

数据可视化入门指南
数据可视化是一种将抽象的数值和数据转换为易于理解的图像的方法。它可以帮助人们更好地理解数据的含义,并且可以揭示数据中可能被忽视的模式和趋势。本文将为你提供一个简单的数据可视化入门指南。 为什么数据可视化重要? 在我们的生活中,数…...

React 18 响应事件
参考文章 响应事件 使用 React 可以在 JSX 中添加 事件处理函数。其中事件处理函数为自定义函数,它将在响应交互(如点击、悬停、表单输入框获得焦点等)时触发。 添加事件处理函数 如需添加一个事件处理函数,需要先定义一个函数…...

WarcraftHelper:魔兽争霸3终极优化工具,如何让经典游戏在现代电脑上流畅运行
WarcraftHelper:魔兽争霸3终极优化工具,如何让经典游戏在现代电脑上流畅运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还…...

MacBook Pro运行OpenClaw与百川2-13B-4bits量化版:性能实测与调优
MacBook Pro运行OpenClaw与百川2-13B-4bits量化版:性能实测与调优 1. 为什么选择这个组合? 去年底换了M2 Max芯片的MacBook Pro后,我一直在寻找能充分利用本地算力的AI工作流。直到发现OpenClaw这个开源自动化框架,配合百川2-13…...

ScriptGen Modern Studio 剧本创作工作站:5分钟快速部署,零基础开启AI编剧之旅
ScriptGen Modern Studio 剧本创作工作站:5分钟快速部署,零基础开启AI编剧之旅 1. 引言:AI时代的剧本创作革命 在创意产业蓬勃发展的今天,剧本创作正迎来技术革新的浪潮。传统编剧流程中,创作者常常面临灵感枯竭、格…...

阿里云YUM源配置避坑指南
在CentOS 7上安装MySQL 8时,正确配置阿里云提供的YUM源是确保安装顺利、避免依赖冲突的关键。核心步骤包括清理系统旧有冲突软件包、配置稳定的软件源、处理GPG密钥验证问题。以下是一个结合官方实践和阿里云镜像优化的详细方案。 一、 核心步骤与对比 为了清晰展…...

专业的办公家具哪家技术强
在企业发展进程中,办公家具的优劣至关重要。专业办公家具不仅能提升办公环境舒适度,还能彰显企业形象与实力。然而,市场上办公家具品牌众多,究竟哪家技术强呢?今天,就为大家详细介绍佛山市豪亿办公家具&…...

别再死记硬背CAN协议了!用STM32CubeMX+USB-CAN分析仪,5分钟搞定物理层与数据链路层实战
用STM32CubeMXUSB-CAN分析仪5分钟掌握CAN核心原理 当你第一次接触CAN总线时,是否被那些晦涩的术语搞得一头雾水?显性电平、位填充、采样点、仲裁机制...这些概念在纯理论讲解中往往显得抽象难懂。但今天,我要带你用一种全新的方式学习CAN——…...

【S32DS实战】S32K311 PIT定时器与IntCtrl_Ip中断联调:从配置到回调的完整流程解析
1. S32K311开发环境与硬件基础 如果你正在使用NXP的S32K311芯片做开发,那PIT定时器和中断控制绝对是必修课。我最近在汽车电子项目里就用这个组合实现了精确的传感器数据采集,实测误差可以控制在微秒级。先说说我的开发环境配置: 硬件&#x…...

实战模拟:基于快马平台构建openclaw智能分拣场景配置验证系统
今天想和大家分享一个特别实用的工业自动化模拟项目——用InsCode(快马)平台搭建的openclaw智能分拣系统。这个项目完美复现了真实工厂里机械臂分拣流水线的核心逻辑,特别适合用来验证不同抓取配置方案的效果。 场景搭建 整个系统模拟了传送带运输不同颜色ÿ…...

STM32F407实战指南:基于74HC595的4位数码管驱动与动态扫描详解
1. 从零认识数码管:你的第一个嵌入式显示方案 第一次接触数码管时,我完全被它简单粗暴的显示方式吸引了。这种由7个LED灯组成的显示器件,通过不同段的组合就能展示0-9的数字,成本不到2块钱却能在各种家电上看到它的身影。我们这次…...

2025年大模型年度复盘:RL、Agent与Omni的技术趋势解读
一、项目介绍准备 项目 1:基于 RAG 的大语言模型关系抽取 1、为什么不用传统语义相似度检索,改用关系原型检索? 传统相似度检索易召回伪近邻样本(语义相近、头尾实体不同→关系不同),干扰模型判断。 我先把…...