Kylin v10基于cephadm工具离线部署ceph分布式存储
1. 环境:
ceph:octopus
OS:Kylin-Server-V10_U1-Release-Build02-20210824-GFB-x86_64、CentOS Linux release 7.9.2009
2. ceph和cephadm
2.1 ceph简介
Ceph可用于向云平台提供对象存储、块设备服务和文件系统。所有Ceph存储集群部署都从设置每个Ceph节点开始,然后设置网络。
Ceph存储集群要求:至少有一个Ceph Monitor和一个Ceph Manager,并且至少有与Ceph集群上存储的对象副本一样多的Ceph osd(例如,如果一个给定对象的三个副本存储在Ceph集群上,那么该Ceph集群中必须至少存在三个osd)。
Monitors:Ceph监视器(ceph-mon)维护集群状态的映射,包括监视器映射、管理器映射、OSD映射、MDS映射和CRUSH映射。这些映射是Ceph守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。通常需要至少三个监视器来实现冗余和高可用性。
Managers:Ceph Manager守护进程(ceph-mgr)负责跟踪Ceph集群的运行时指标和当前状态,包括存储利用率、当前性能指标和系统负载。Ceph Manager守护进程还承载基于python的模块来管理和公开Ceph集群信息,包括基于web的Ceph Dashboard和REST API。通常需要至少两个管理器来实现高可用性。
Ceph OSD:对象存储守护进程(Ceph OSD, ceph-osd)存储数据,处理数据复制、恢复、再平衡,并通过检查其他Ceph OSD守护进程的心跳,为Ceph监视器和管理器提供一些监控信息。通常需要至少三个Ceph osd来实现冗余和高可用性。
MDSs: Ceph元数据服务器(MDS,ceph-mds)代表Ceph文件系统存储元数据(即,Ceph块设备和Ceph对象存储不使用MDS)。Ceph元数据服务器允许POSIX文件系统用户执行基本命令(如ls、find等),而不会给Ceph存储集群带来巨大的负担。
参考官方文档ceph
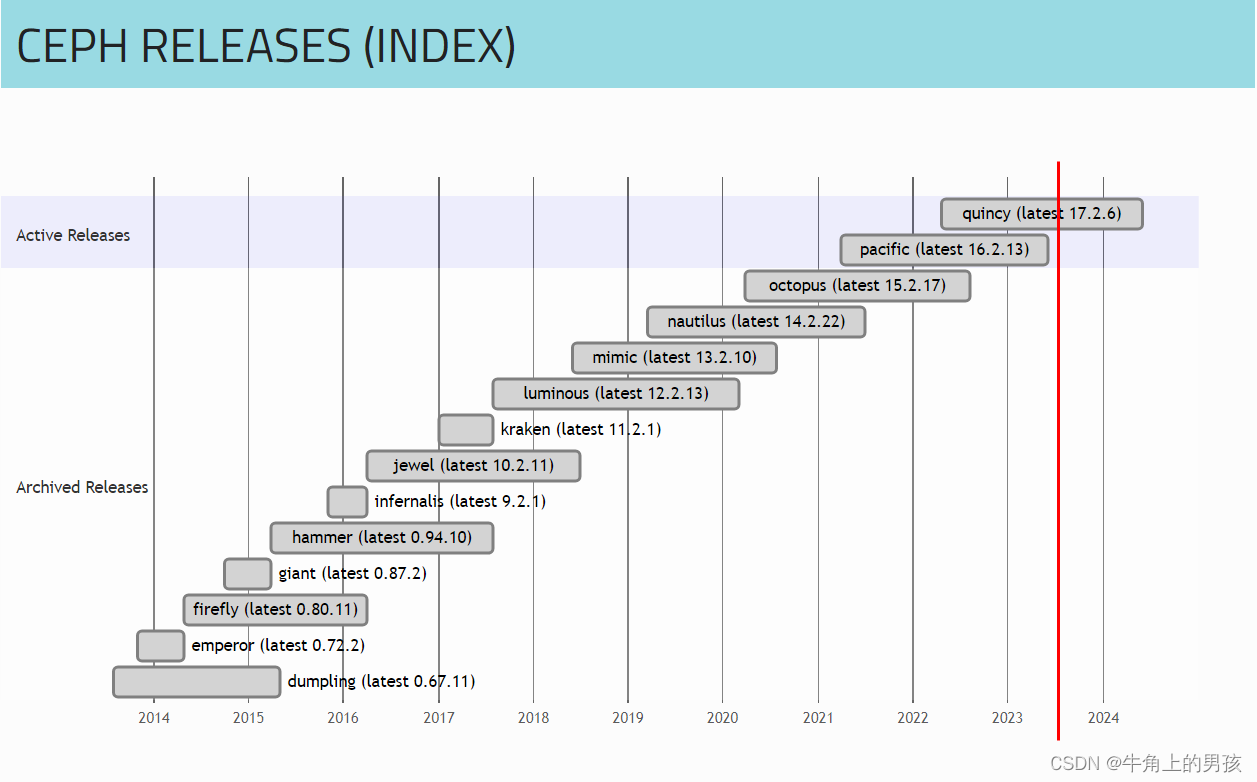
2.2 ceph releases
2.3 cephadm
cephadm是一个用于管理Ceph集群的实用程序。
- cephadm可以向集群中添加Ceph容器。
- cephadm可以从集群中删除Ceph容器。
- cephadm可以更新Ceph容器。
cephadm不依赖于外部配置工具,如Ansible、Rook或Salt。但是,这些外部配置工具可以用于自动化不是由cephadm本身执行的操作。
cephadm管理Ceph集群的整个生命周期。这个生命周期从引导过程开始,当cephadm在单个节点上创建一个小型Ceph集群时。该集群由一个监视器和一个管理器组成。然后,cephadm使用编排接口扩展集群,添加主机并提供Ceph守护进程和服务。这个生命周期的管理可以通过Ceph命令行界面(CLI)或仪表板(GUI)来执行。
参考官方文档cephadm
3. 节点规划
| 主机名 | 地址 | 角色 |
|---|---|---|
| ceph1 | 172.25.0.141 | mon, osd, mds, mgr, iscsi, cephadm |
| ceph2 | 172.25.0.142 | mon, osd, mds, mgr, iscsi |
| ceph3 | 172.25.0.143 | mon, osd, mds, mgr, iscsi |
4. 基础环境配置
4.1 地址配置
ceph1配置地址
nmcli connection modify ens33 ipv4.method manual ipv4.addresses 172.25.0.141/24 ipv4.gateway 172.25.0.2 connection.autoconnect yes
ceph2配置地址
nmcli connection modify ens33 ipv4.method manual ipv4.addresses 172.25.0.142/24 ipv4.gateway 172.25.0.2 connection.autoconnect yes
ceph3配置地址
nmcli connection modify ens33 ipv4.method manual ipv4.addresses 172.25.0.143/24 ipv4.gateway 172.25.0.2 connection.autoconnect yes
4.2 主机名配置
ceph1配置主机名
hostnamectl set-hostname ceph1
ceph2配置主机名
hostnamectl set-hostname ceph2
ceph3配置主机名
hostnamectl set-hostname ceph3
ceph1、ceph2、ceph3均配置hosts
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6172.25.0.141 ceph1
172.25.0.142 ceph2
172.25.0.143 ceph3
添加DNS解析,任意添加一个
vim /etc/resolv.conf
nameserver 223.5.5.5
4.3 防火墙
ceph1、ceph2、ceph3均需配置
关闭防火墙
systemctl disable --now firewalld
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
4.4 配置免密
ssh-keygen -f /root/.ssh/id_rsa -P ''
ssh-copy-id -o StrictHostKeyChecking=no 172.25.0.141
ssh-copy-id -o StrictHostKeyChecking=no 172.25.0.142
ssh-copy-id -o StrictHostKeyChecking=no 172.25.0.143
4.5 配置时间同步
ceph1、ceph2、ceph3均需安装软件包
yum -y install chrony
systemctl enable chronyd
ceph1作为服务端
vim /etc/chrony.conf
pool pool.ntp.org iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
allow 172.25.0.0/24
local stratum 10
keyfile /etc/chrony.keys
leapsectz right/UTC
logdir /var/log/chrony
重启服务
systemctl restart chronyd
ceph2、ceph2及其他后续节点作为客户端
vim /etc/chrony.conf
pool 172.25.0.141 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
keyfile /etc/chrony.keys
leapsectz right/UTC
logdir /var/log/chrony
重启服务
systemctl restart chronyd
使用客户端进行验证
chronyc sources -v
210 Number of sources = 1.-- Source mode '^' = server, '=' = peer, '#' = local clock./ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* ceph1 11 6 17 10 -68us[ -78us] +/- 2281us4.6 安装python3
4.6.1 Kylin V10
系统已经默认安装了python 3.7.4的版本,若未安装,配置好源后通过YUM安装
yum -y install python3
4.6.2 CentOS 7
安装python3
yum -y install epel-release
yum -y install python3
4.6 安装配置docker
4.6.1 Kylin V10
系统已经默认安装了docker-engine的版本,若未安装,配置好源后通过YUM安装
yum -y install docker-engine
4.6.2 CentOS 7
配置docker repo
yum -y install yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum -y install docker-ce
设置开机自启
systemctl enable docker
5. 安装cephadm
5.1 Kylin V10
下载cephadm软件包
wget http://mirrors.163.com/ceph/rpm-octopus/el7/noarch/cephadm-15.2.17-0.el7.noarch.rpm
安装cephadm
chmod 600 /var/log/tallylog
rpm -ivh cephadm-15.2.17-0.el7.noarch.rpm
5.2 CentOS 7
通过cephadm脚本授予执行权限
curl https://raw.githubusercontent.com/ceph/ceph/v15.2.1/src/cephadm/cephadm -o cephadm
chmod +x cephadm
或者
wget http://mirrors.163.com/ceph/rpm-octopus/el7/noarch/cephadm
基于发行版的名称配置ceph仓库
./cephadm add-repo --release octopus
执行cephadm安装程序
./cephadm install
安装ceph-common软件包
cephadm install ceph-common
octopus软件包地址:
https://repo.huaweicloud.com/ceph/rpm-octopus/
http://mirrors.163.com/ceph/rpm-octopus/
http://mirrors.aliyun.com/ceph/rpm-octopus/
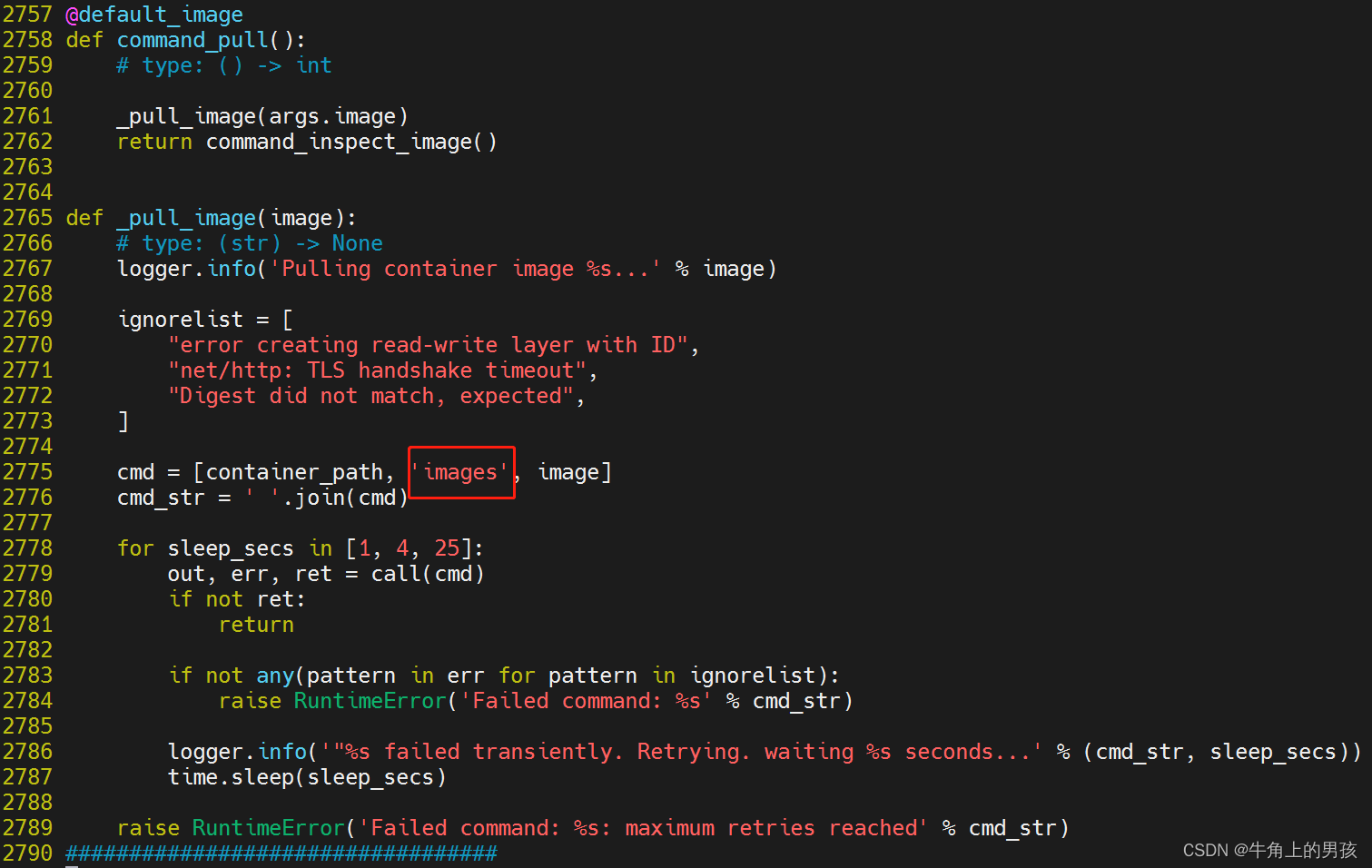
5.3 cephadm修改
离线使用本地的镜像,需要修改cephadm文件_pull_image函数的cmd列表中的pull,将其修改为images。
vim /usr/sbin/cephadm
6. 安装ceph
6.1 准备镜像
6.1.1 导入镜像
离线镜像已放置在百度云盘:
链接:https://pan.baidu.com/s/1UEkQo0XrwuCDI5u9H8sGkQ?pwd=zsd4
提取码:zsd4
离线load导入镜像
docker load < ceph-v15.img
docker load < prometheus-v2.18.1.img
docker load < node-exporter-v0.18.1.img
docker load < ceph-grafana-6.7.4.img
docker load < alertmanager-v0.20.0.img
在线pull镜像octopus
docker pull quay.io/ceph/ceph:v15
docker pull quay.io/prometheus/prometheus:v2.18.1
docker pull quay.io/prometheus/node-exporter:v0.18.1
docker pull quay.io/ceph/ceph-grafana:6.7.4
docker pull quay.io/prometheus/alertmanager:v0.20.0
quincy
docker pull quay.io/ceph/ceph:v17
docker pull quay.io/ceph/ceph-grafana:8.3.5
docker pull quay.io/prometheus/prometheus:v2.33.4
docker pull quay.io/prometheus/node-exporter:v1.3.1
docker pull quay.io/prometheus/alertmanager:v0.23.0
6.1.2 构建registryserver
docker load < registry-2.img
mkdir -p /data/registry/
docker run -d -p 4000:5000 -v /data/registry/:/var/lib/registry/ --restart=always --name registry registry:2
添加主机名解析
vim /etc/hosts
172.25.0.141 registryserver
注意:这个主机名简析需要放到第一行,便于cephadm shell使用
6.1.3 tag镜像及push进仓库
docker tag quay.io/ceph/ceph:v15 registryserver:4000/ceph/ceph:v15
docker tag quay.io/prometheus/prometheus:v2.18.1 registryserver:4000/prometheus/prometheus:v2.18.1
docker tag quay.io/prometheus/node-exporter:v0.18.1 registryserver:4000/prometheus/node-exporter:v0.18.1
docker tag quay.io/ceph/ceph-grafana:6.7.4 registryserver:4000/ceph/ceph-grafana:6.7.4
docker tag quay.io/prometheus/alertmanager:v0.20.0 registryserver:4000/prometheus/alertmanager:v0.20.0docker push registryserver:4000/ceph/ceph:v15
docker push registryserver:4000/prometheus/prometheus:v2.18.1
docker push registryserver:4000/prometheus/node-exporter:v0.18.1
docker push registryserver:4000/ceph/ceph-grafana:6.7.4
docker push registryserver:4000/prometheus/alertmanager:v0.20.06.2 bootstrap部署
mkdir -p /etc/ceph
cephadm bootstrap --mon-ip 172.25.0.141
该命令执行以下操作:
- 在本地主机上为新集群创建monitor 和 manager daemon守护程序。
- 为Ceph集群生成一个新的SSH密钥,并将其添加到root用户的/root/.ssh/authorized_keys文件中。
- 将与新群集进行通信所需的最小配置文件保存到/etc/ceph/ceph.conf。
- 向/etc/ceph/ceph.client.admin.keyring写入client.admin管理(特权!)secret key的副本。
- 将public key的副本写入/etc/ceph/ceph.pub。
[root@ceph1 ~]# cephadm bootstrap --mon-ip 172.25.0.141
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman|docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: d20e3700-2d2f-11ee-9166-000c29aa07d2
Verifying IP 172.25.0.141 port 3300 ...
Verifying IP 172.25.0.141 port 6789 ...
Mon IP 172.25.0.141 is in CIDR network 172.25.0.0/24
Pulling container image quay.io/ceph/ceph:v15...
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network...
Creating mgr...
Verifying port 9283 ...
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Wrote config to /etc/ceph/ceph.conf
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/10)...
mgr not available, waiting (2/10)...
mgr not available, waiting (3/10)...
mgr not available, waiting (4/10)...
mgr not available, waiting (5/10)...
mgr not available, waiting (6/10)...
mgr not available, waiting (7/10)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 5...
Mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to to /etc/ceph/ceph.pub
Adding key to root@localhost's authorized_keys...
Adding host ceph1...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Enabling mgr prometheus module...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 13...
Mgr epoch 13 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
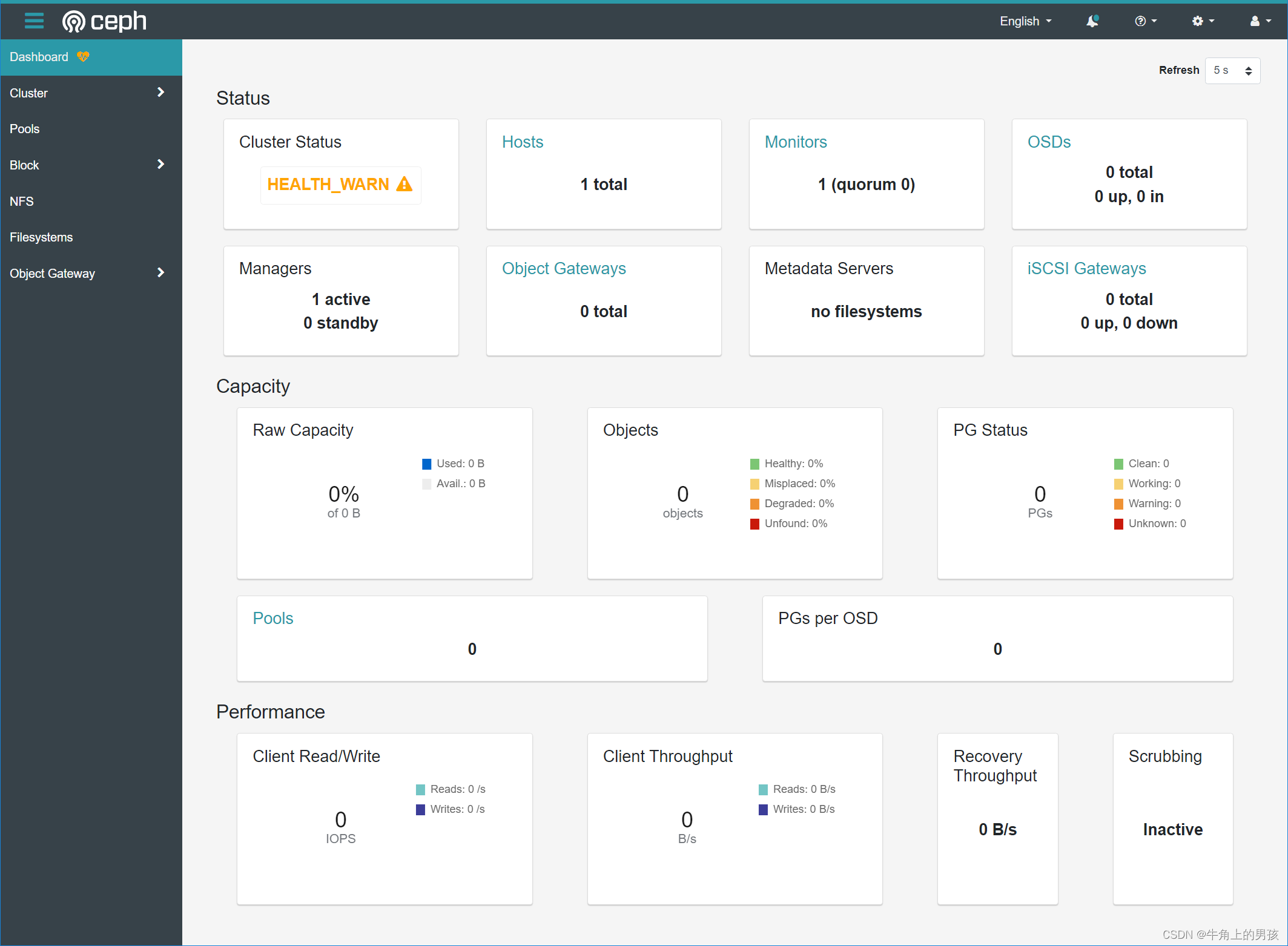
Ceph Dashboard is now available at:URL: https://ceph1:8443/User: adminPassword: cx763mtlk7You can access the Ceph CLI with:sudo /usr/sbin/cephadm shell --fsid d20e3700-2d2f-11ee-9166-000c29aa07d2 -c /etc/ceph/ceph.conf -k /etc/cPlease consider enabling telemetry to help improve Ceph:ceph telemetry onFor more information see:https://docs.ceph.com/docs/master/mgr/telemetry/Bootstrap complete.根据上文输出的URL、User、Password登录网页,如下

首次登录需要修改密码,修改密码之后登录如下:
通过cephadm shell启用ceph命令,也可以通过创建别名:
alias ceph='cephadm shell -- ceph'
而后直接在物理机上执行ceph -s
6.2 主机管理
6.2.1 查看可用主机
ceph orch host ls
[ceph: root@ceph1 /]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1 ceph1
6.2.1 添加主机
将主机添加到集群中
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph3
scp -r /etc/ceph root@ceph2:/etc/
scp -r /etc/ceph root@ceph3:/etc/
ceph orch host add ceph1 172.25.0.141
ceph orch host add ceph2 172.25.0.142
ceph orch host add ceph3 172.25.0.143
ceph orch host ls
[ceph: root@ceph1 /]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1 172.25.0.141
ceph2 172.25.0.142
ceph3 172.25.0.143
6.2.3 删除主机
从 环境中删除主机,如ceph3,确保正在运行的服务都已经停止和删除:
ceph orch host rm ceph3
6.3 部署MONS和MGRS
6.3.1 mon指定特定子网
ceph config set mon public_network 172.25.0.0/24
6.3.2 更改默认mon的数量
通过ceph orch ls 查看到相应服务的状态,如mon
[ceph: root@ceph1 /]# ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
alertmanager 1/1 9m ago 6h count:1 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f
crash 2/3 9m ago 6h * quay.io/ceph/ceph:v15 93146564743f
grafana 1/1 9m ago 6h count:1 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646
mgr 1/2 9m ago 6h count:2 quay.io/ceph/ceph:v15 93146564743f
mon 2/5 9m ago 6h count:5 quay.io/ceph/ceph:v15 93146564743f
node-exporter 1/3 10m ago 6h * quay.io/prometheus/node-exporter:v0.18.1 mix
osd.None 3/0 9m ago - <unmanaged> quay.io/ceph/ceph:v15 93146564743f
prometheus 1/1 9m ago 6h count:1 quay.io/prometheus/prometheus:v2.18.1 de242295e225
ceph集群一般默认会允许存在5个mon和2个mgr,将mon调整为3,执行如下命令:
ceph orch apply mon 3
[ceph: root@ceph1 /]# ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
alertmanager 1/1 35s ago 6h count:1 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f
crash 3/3 39s ago 6h * quay.io/ceph/ceph:v15 93146564743f
grafana 1/1 35s ago 6h count:1 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646
mgr 2/2 39s ago 6h count:2 quay.io/ceph/ceph:v15 93146564743f
mon 3/3 39s ago 11m ceph1;ceph2;ceph3;count:3 quay.io/ceph/ceph:v15 93146564743f
node-exporter 1/3 39s ago 6h * quay.io/prometheus/node-exporter:v0.18.1 mix
osd.None 3/0 35s ago - <unmanaged> quay.io/ceph/ceph:v15 93146564743f
prometheus 1/1 35s ago 6h count:1 quay.io/prometheus/prometheus:v2.18.1 de242295e225
6.3.3 部署mon和mgr
在特定的主机上部署mon
ceph orch apply mon --placement="3 ceph1 ceph2 ceph3"
在特定的主机上部署mgr
ceph orch apply mgr --placement="3 ceph1 ceph2 ceph3"
6.4 OSD部署
6.4.1 查看设备列表
执行命令ceph orch device ls查看群集主机上的存储设备清单可以显示为:
[ceph: root@ceph1 /]# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
ceph1 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
ceph1 /dev/sdc hdd 21.4G Unknown N/A N/A Yes
ceph1 /dev/sdd hdd 21.4G Unknown N/A N/A Yes
ceph2 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
ceph2 /dev/sdc hdd 21.4G Unknown N/A N/A Yes
ceph2 /dev/sdd hdd 21.4G Unknown N/A N/A Yes
ceph3 /dev/sdb hdd 21.4G Unknown N/A N/A Yes
ceph3 /dev/sdc hdd 21.4G Unknown N/A N/A Yes
ceph3 /dev/sdd hdd 21.4G Unknown N/A N/A Yes
6.4.2 创建OSD
如果满足以下所有条件,则认为存储设备可用:
- 设备必须没有分区。
- 设备不得具有任何LVM状态。
- 不得安装设备。
- 该设备不得包含文件系统。
- 该设备不得包含Ceph BlueStore OSD。
- 设备必须大于5 GB。
Ceph拒绝在不可用的设备上配置OSD。
Ceph使用任何可用和未使用的存储设备,如下:
ceph orch apply osd --all-available-devices
在特定主机上的特定设备创建OSD,
ceph1主机添加为OSD
ceph orch daemon add osd ceph1:/dev/sdb
ceph orch daemon add osd ceph1:/dev/sdc
ceph orch daemon add osd ceph1:/dev/sdd
ceph2主机添加为OSD
ceph orch daemon add osd ceph2:/dev/sdb
ceph orch daemon add osd ceph2:/dev/sdc
ceph orch daemon add osd ceph2:/dev/sdd
ceph3主机添加为OSD
ceph orch daemon add osd ceph3:/dev/sdb
ceph orch daemon add osd ceph3:/dev/sdc
ceph orch daemon add osd ceph3:/dev/sdd
6.4.3 移除OSD
ceph orch osd rm 3
6.4.4启停(osd)服务
ceph orch daemon start/stop/restart osd.3
6.5 RGW部署
6.5.1 创建一个领域
首先创建一个领域
radosgw-admin realm create --rgw-realm=radosgw --default
执行结果如下:
[ceph: root@ceph1 /]# radosgw-admin realm create --rgw-realm=radosgw --default
{"id": "c4b75303-5ef6-4d82-a60c-efa4ceea2bc2","name": "radosgw","current_period": "d4267c01-b762-473b-bcf5-f278b1ea608a","epoch": 1
}6.5.2 创建区域组
创建区域组
radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
执行结果如下:
[ceph: root@ceph1 /]# radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
{"id": "6a3dfbbf-3c09-4cc2-9644-1c17524ee4d1","name": "default","api_name": "default","is_master": "true","endpoints": [],"hostnames": [],"hostnames_s3website": [],"master_zone": "","zones": [],"placement_targets": [],"default_placement": "","realm_id": "c4b75303-5ef6-4d82-a60c-efa4ceea2bc2","sync_policy": {"groups": []}
}6.5.3 创建区域
创建区域
radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=cn --master --default
执行结果如下:
[ceph: root@ceph1 /]# radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=cn --master --default
{"id": "4531574f-a84b-464f-962b-7a29aad20080","name": "cn","domain_root": "cn.rgw.meta:root","control_pool": "cn.rgw.control","gc_pool": "cn.rgw.log:gc","lc_pool": "cn.rgw.log:lc","log_pool": "cn.rgw.log","intent_log_pool": "cn.rgw.log:intent","usage_log_pool": "cn.rgw.log:usage","roles_pool": "cn.rgw.meta:roles","reshard_pool": "cn.rgw.log:reshard","user_keys_pool": "cn.rgw.meta:users.keys","user_email_pool": "cn.rgw.meta:users.email","user_swift_pool": "cn.rgw.meta:users.swift","user_uid_pool": "cn.rgw.meta:users.uid","otp_pool": "cn.rgw.otp","system_key": {"access_key": "","secret_key": ""},"placement_pools": [{"key": "default-placement","val": {"index_pool": "cn.rgw.buckets.index","storage_classes": {"STANDARD": {"data_pool": "cn.rgw.buckets.data"}},"data_extra_pool": "cn.rgw.buckets.non-ec","index_type": 0}}],"realm_id": "c4b75303-5ef6-4d82-a60c-efa4ceea2bc2"
}
6.5.4 部署radosgw
为特定领域和区域部署radosgw守护程序
ceph orch apply rgw radosgw cn --placement="3 ceph1 ceph2 ceph3"
6.5.5 验证各节点是否启动rgw容器
ceph orch ps --daemon-type rgw
执行结果如下:
[ceph: root@ceph1 /]# ceph orch ps --daemon-type rgw
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
rgw.radosgw.cn.ceph1.jzxfhf ceph1 running (48s) 38s ago 48s 15.2.17 quay.io/ceph/ceph:v15 93146564743f f2b23eac68b0
rgw.radosgw.cn.ceph2.hdbbtx ceph2 running (55s) 42s ago 55s 15.2.17 quay.io/ceph/ceph:v15 93146564743f 1a96776d7b0f
rgw.radosgw.cn.ceph3.arlfch ceph3 running (52s) 41s ago 52s 15.2.17 quay.io/ceph/ceph:v15 93146564743f ab23d7f7a46c
6.6 MDS部署
Ceph 文件系统,名为 CephFS,兼容 POSIX,建立在 Ceph 对象存储RADOS之上,相关资料参考cephfs
6.6.1 创建数据存储池
创建一个用于cephfs数据存储的池
ceph osd pool create cephfs_data
6.6.2 创建元数据存储池
创建一个用于cephfs元数据存储的池
ceph osd pool create cephfs_metadata
6.6.3 创建文件系统
创建一个文件系统,名为cephfs:
ceph fs new cephfs cephfs_metadata cephfs_data
6.6.4 查看文件系统
查看文件系统列表
ceph fs ls
设置cephfs最大mds服务数量为3
ceph fs set cephfs max_mds 3
若mds只有一个,则需要设置mds为1,副本数若不够,size设置为1
ceph fs set cephfs max_mds 1
ceph osd pool set cephfs_metadata size 1
ceph osd pool set cephfs_data size 1
6.6.5 部署3个mds服务
在特定的主机上部署mds服务
ceph orch apply mds cephfs --placement="3 ceph1 ceph2 ceph3"
6.6.6 查看mds服务是否部署成功
ceph orch ps --daemon-type mds
执行结果如下:
[ceph: root@ceph1 /]# ceph orch ps --daemon-type mds
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
mds.cephfs.ceph1.gfvgda ceph1 running (10s) 4s ago 10s 15.2.17 quay.io/ceph/ceph:v15 93146564743f 7f216bfe781f
mds.cephfs.ceph2.ytkxqc ceph2 running (15s) 6s ago 15s 15.2.17 quay.io/ceph/ceph:v15 93146564743f dec713c46919
mds.cephfs.ceph3.tszetu ceph3 running (13s) 6s ago 13s 15.2.17 quay.io/ceph/ceph:v15 93146564743f 70ee41d1a81b6.6.6 查看文件系统状态
ceph mds stat
执行结果如下:
cephfs:3 {0=cephfs.ceph2.ytkxqc=up:active,1=cephfs.ceph3.tszetu=up:active,2=cephfs.ceph1.gfvgda=up:active}
查下ceph状态
[ceph: root@ceph1 /]# ceph -scluster:id: d20e3700-2d2f-11ee-9166-000c29aa07d2health: HEALTH_WARNinsufficient standby MDS daemons availableservices:mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 24h)mgr: ceph1.kxhbab(active, since 45m), standbys: ceph2.rovomy, ceph3.aseinmmds: cephfs:3 {0=cephfs.ceph2.ytkxqc=up:active,1=cephfs.ceph3.tszetu=up:active,2=cephfs.ceph1.gfvgda=up:active}osd: 9 osds: 9 up (since 22h), 9 in (since 22h)rgw: 3 daemons active (radowgw.cn.ceph1.jzxfhf, radowgw.cn.ceph2.hdbbtx, radowgw.cn.ceph3.arlfch)task status:data:pools: 9 pools, 233 pgsobjects: 269 objects, 14 KiBusage: 9.2 GiB used, 171 GiB / 180 GiB availpgs: 233 active+cleanio:client: 1.2 KiB/s rd, 1 op/s rd, 0 op/s wr
6.6.7 文件系统挂载
通过admin挂载文件系统
mount.ceph ceph1:6789,ceph2:6789,ceph3:6789:/ /mnt/cephfs -o name=admin
创建用户 cephfs,用于客户端访问CephFs
ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow r, allow rw path=/' osd 'allow rw pool=cephfs_data' -o ceph.client.cephfs.keyring
查看输出的ceph.client.cephfs.keyring密钥文件,或使用下面的命令查看密钥:
ceph auth get-key client.cephfs
挂载cephfs到各节点本地目录
在各个节点执行:
mkdir /mnt/cephfs/
mount -t ceph ceph1:6789,ceph2:6789,ceph3:6789:/ /mnt/cephfs/ -o name=cephfs,secret=<cephfs访问用户的密钥>
编辑各个节点的/etc/fstab文件,实现开机自动挂载,添加以下内容:
ceph1:6789,ceph2:6789,ceph3:6789:/ /mnt/cephfs ceph name=cephfs,secretfile=<cephfs访问用户的密钥>,noatime,_netdev 0 2
6.7 部署 iSCSI 网关
6.7.1 创建池
ceph osd pool create iscsi_pool
ceph osd pool application enable iscsi_pool rbd
6.7.2 部署 iSCSI 网关
ceph orch apply iscsi iscsi_pool admin admin --placement="1 ceph1"
6.7.3 列出主机和进程
ceph orch ps --daemon_type=iscsi
执行结果如下:
[ceph: root@ceph1 /]# ceph orch ps --daemon_type=iscsi
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
iscsi.iscsi.ceph1.dszfku ceph1 running (11s) 2s ago 12s 3.5 quay.io/ceph/ceph:v15 93146564743f b4395ebd49b6
6.7.4 删除iSCSI网关
查看列表
[ceph: root@ceph1 /]# ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
alertmanager 1/1 4m ago 5h count:1 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f
crash 3/3 12m ago 5h * quay.io/ceph/ceph:v15 93146564743f
grafana 1/1 4m ago 5h count:1 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646
iscsi.iscsi 1/1 4m ago 4m ceph1;count:1 quay.io/ceph/ceph:v15 93146564743f
mds.cephfs 3/3 12m ago 4h ceph1;ceph2;ceph3;count:3 quay.io/ceph/ceph:v15 93146564743f
mgr 3/3 12m ago 5h ceph1;ceph2;ceph3;count:3 quay.io/ceph/ceph:v15 93146564743f
mon 3/3 12m ago 23h ceph1;ceph2;ceph3;count:3 quay.io/ceph/ceph:v15 93146564743f
node-exporter 3/3 12m ago 5h * quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf
osd.None 9/0 12m ago - <unmanaged> quay.io/ceph/ceph:v15 93146564743f
prometheus 1/1 4m ago 5h count:1 quay.io/prometheus/prometheus:v2.18.1 de242295e225
rgw.radowgw.cn 3/3 12m ago 5h ceph1;ceph2;ceph3;count:3 quay.io/ceph/ceph:v15 93146564743f
删除iscsi网关
ceph orch rm iscsi.iscsi
7. 问题记录:
7.1 文件系统启动不了
执行如下命令ceph mds stat和ceph health detail查看文件系统状态,结果如下:
HEALTH_ERR 1 filesystem is offline; 1 filesystem is online with fewer MDS than max_mds
[ERR] MDS_ALL_DOWN: 1 filesystem is offlinefs cephfs is offline because no MDS is active for it.
[WRN] MDS_UP_LESS_THAN_MAX: 1 filesystem is online with fewer MDS than max_mdsfs cephfs has 0 MDS online, but wants 1
通过ceph orch ls查看mds是否部署或者成功启动,若没有部署则通过以下命令部署:
ceph orch apply mds cephfs --placement="1 ceph1"
7.2 文件系统挂载报错mount error 2 = No such file or directory
查看命令ceph mds stat发现文件系统创建中
cephfs:1 {0=cephfs.ceph1.npyywh=up:creating}
通过命令ceph -s查看,结果如下:
cluster:id: dd6e5410-221f-11ee-b47c-000c29fd771ahealth: HEALTH_WARN1 MDSs report slow metadata IOsReduced data availability: 64 pgs inactiveDegraded data redundancy: 65 pgs undersizedservices:mon: 1 daemons, quorum ceph1 (age 15h)mgr: ceph1.vtottx(active, since 15h)mds: cephfs:1 {0=cephfs.ceph1.npyywh=up:creating}osd: 3 osds: 3 up (since 15h), 3 in (since 15h); 1 remapped pgsdata:pools: 3 pools, 65 pgsobjects: 0 objects, 0 Busage: 3.0 GiB used, 57 GiB / 60 GiB availpgs: 98.462% pgs not active64 undersized+peered1 active+undersized+remapped
发现如下问题
1 MDSs report slow metadata IOs
Reduced data availability: 64 pgs inactive
Degraded data redundancy: 65 pgs undersized
由于单个节点集群,pg不足,满足不了三副本的要求,需要设置mds为1,故将cephfs_metadata和cephfs_data的size设置为1,其他资源池一样
ceph fs set cephfs max_mds 1
ceph osd pool set cephfs_metadata size 1
ceph osd pool set cephfs_data size 1
通过命令ceph mds stat 查询结果如下:
cephfs:1 {0=cephfs.ceph1.npyywh=up:active}
状态为active,可以正常挂载
7.3 /var/log/tallylog is either world writable or not a normal file
安装软件包cephadm-15.2.17-0.el7.noarch.rpm,报如下错误:
pam_tally2: /var/log/tallylog is either world writable or not a normal file
pam_tally2: Authentication error
执行如下命令解决
chmod 600 /var/log/tallylog
pam_tally2 --user root --reset
7.4 RuntimeError: uid/gid not found
执行cephadm shell,报如下错误:
Inferring fsid c8fb20bc-247c-11ee-a39c-000c29aa07d2
Inferring config /var/lib/ceph/c8fb20bc-247c-11ee-a39c-000c29aa07d2/mon.node1/config
Using recent ceph image quay.io/ceph/ceph@<none>
Non-zero exit code 125 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint stat -e CONTAINER_IMAGE=quay.io/ceph/ceph@<none> -e NODE_NAME=node1 quay.io/ceph/ceph@<none> -c %u %g /var/lib/ceph
stat: stderr /usr/bin/docker: invalid reference format.
stat: stderr See '/usr/bin/docker run --help'.
Traceback (most recent call last):File "/usr/sbin/cephadm", line 6250, in <module>r = args.func()File "/usr/sbin/cephadm", line 1381, in _infer_fsidreturn func()File "/usr/sbin/cephadm", line 1412, in _infer_configreturn func()File "/usr/sbin/cephadm", line 1440, in _infer_imagereturn func()File "/usr/sbin/cephadm", line 3573, in command_shellmake_log_dir(args.fsid)File "/usr/sbin/cephadm", line 1538, in make_log_diruid, gid = extract_uid_gid()File "/usr/sbin/cephadm", line 2155, in extract_uid_gidraise RuntimeError('uid/gid not found')
RuntimeError: uid/gid not found
经过分析,确认 “cephadmin shell” 命令会启动一个 ceph容器;因安装在离线环境中,通过docker load的镜像,丢失了 “RepoDigest” 信息,所有无法启动容器。
解决办法是使用docker registry 创建本地仓库,然后推送镜像到仓库,再拉取该镜像来完善 “RepoDigest” 信息。(所有主机),同时主机名的解析也需要放到第一位,以免解析不到。
7.5 iptables: No chain/target/match by that name.
执行docker restart registry时候报如下错误
Error response from daemon: Cannot restart container registry: driver failed programming external connectivity on endpoint registry (dd9a9c15a451daa6abd2b85e840d7856c5c5f98c1fb1ae35897d3fbb28e2997c): (iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 4000 -j DNAT --to-destination 172.17.0.2:5000 ! -i docker0: iptables: No chain/target/match by that name.(exit status 1))
在麒麟系统里面使用了firewalld代替了iptables,在运行容器前,firewalld是运行的,iptables会被使用,后来关闭了firewalld导致无法找到iptables相关信息,解决办法是重启docker更新容器,执行如下命令:
systemctl restart docker
7.6 /usr/bin/ceph: timeout after 60 seconds
执行cephadm bootstrap
错误如下:
cephadm bootstrap --mon-ip 172.25.0.141
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman|docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: 65ae4594-2d2c-11ee-b17b-000c29aa07d2
Verifying IP 172.25.0.141 port 3300 ...
Verifying IP 172.25.0.141 port 6789 ...
Mon IP 172.25.0.141 is in CIDR network 172.25.0.0/24
Pulling container image quay.io/ceph/ceph:v15...
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
/usr/bin/ceph: timeout after 60 seconds
Non-zero exit code -9 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint /usr/bin/ceph -e CONTAINER_IMAGE=quay.io/ceph/ceph:v15 -e NODE_NAME=ceph1 -v /var/lib/ceph/65ae4594-2d2c-11ee-b17b-000c29aa07d2/mon.ceph1:/var/lib/ceph/mon/ceph-ceph1:z -v /tmp/ceph-tmpuylyqrau:/etc/ceph/ceph.client.admin.keyring:z -v /tmp/ceph-tmp85t1j6sg:/etc/ceph/ceph.conf:z quay.io/ceph/ceph:v15 status
mon not available, waiting (1/10)...
/usr/bin/ceph: timeout after 60 seconds
Non-zero exit code -9 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint /usr/bin/ceph -e CONTAINER_IMAGE=quay.io/ceph/ceph:v15 -e NODE_NAME=ceph1 -v /var/lib/ceph/65ae4594-2d2c-11ee-b17b-000c29aa07d2/mon.ceph1:/var/lib/ceph/mon/ceph-ceph1:z -v /tmp/ceph-tmpuylyqrau:/etc/ceph/ceph.client.admin.keyring:z -v /tmp/ceph-tmp85t1j6sg:/etc/ceph/ceph.conf:z quay.io/ceph/ceph:v15 status
mon not available, waiting (2/10)...
/usr/bin/ceph: timeout after 60 seconds
Non-zero exit code -9 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint /usr/bin/ceph -e CONTAINER_IMAGE=quay.io/ceph/ceph:v15 -e NODE_NAME=ceph1 -v /var/lib/ceph/65ae4594-2d2c-11ee-b17b-000c29aa07d2/mon.ceph1:/var/lib/ceph/mon/ceph-ceph1:z -v /tmp/ceph-tmpuylyqrau:/etc/ceph/ceph.client.admin.keyring:z -v /tmp/ceph-tmp85t1j6sg:/etc/ceph/ceph.conf:z quay.io/ceph/ceph:v15 status
mon not available, waiting (3/10)...
/usr/bin/ceph: timeout after 60 seconds
Non-zero exit code -9 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint /usr/bin/ceph -e CONTAINER_IMAGE=quay.io/ceph/ceph:v15 -e NODE_NAME=ceph1 -v /var/lib/ceph/65ae4594-2d2c-11ee-b17b-000c29aa07d2/mon.ceph1:/var/lib/ceph/mon/ceph-ceph1:z -v /tmp/ceph-tmpuylyqrau:/etc/ceph/ceph.client.admin.keyring:z -v /tmp/ceph-tmp85t1j6sg:/etc/ceph/ceph.conf:z quay.io/ceph/ceph:v15 status
mon not available, waiting (4/10)...
/usr/bin/ceph: timeout after 60 seconds
Non-zero exit code -9 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint /usr/bin/ceph -e CONTAINER_IMAGE=quay.io/ceph/ceph:v15 -e NODE_NAME=ceph1 -v /var/lib/ceph/65ae4594-2d2c-11ee-b17b-000c29aa07d2/mon.ceph1:/var/lib/ceph/mon/ceph-ceph1:z -v /tmp/ceph-tmpuylyqrau:/etc/ceph/ceph.client.admin.keyring:z -v /tmp/ceph-tmp85t1j6sg:/etc/ceph/ceph.conf:z quay.io/ceph/ceph:v15 status
mon not available, waiting (5/10)...
然后手动执行
docker run -it --ipc=host --net=host -e CONTAINER_IMAGE=quay.io/ceph/ceph:v15 -e NODE_NAME=ceph1 -v /var/lib/ceph/65ae4594-2d2c-11ee-b17b-000c29aa07d2/mon.ceph1:/var/lib/ceph/mon/ceph-ceph1:z -v /tmp/ceph-tmpuylyqrau:/etc/ceph/ceph.client.admin.keyring:z -v /tmp/ceph-tmp85t1j6sg:/etc/ceph/ceph.conf:z quay.io/ceph/ceph:v15 bash
bash进去后执行ceph -s,发现如下错误
[root@ceph1 /]# ceph -s
2023-07-28T10:01:34.083+0000 7f0dc4f41700 0 monclient(hunting): authenticate timed out after 300
2023-07-28T10:06:34.087+0000 7f0dc4f41700 0 monclient(hunting): authenticate timed out after 300
2023-07-28T10:11:34.087+0000 7f0dc4f41700 0 monclient(hunting): authenticate timed out after 300
查阅相关资料,发现跟DNS解析有关,修改/etc/resolv.conf,加入一个DNS SERVER
vim /etc/resolv.conf
nameserver 223.5.5.5
问题得到解决。
7.7 ERROR: Cannot infer an fsid, one must be specified
执行ceph -s,报如下错误:
ERROR: Cannot infer an fsid, one must be specified: ['65ae4594-2d2c-11ee-b17b-000c29aa07d2', '70eb8f7c-2d2f-11ee- 8265-000c29aa07d2', 'd20e3700-2d2f-11ee-9166-000c29aa07d2']由于多次部署失败导致的,将失败的fsid删除即可,操作如下:
cephadm rm-cluster --fsid 65ae4594-2d2c-11ee-b17b-000c29aa07d2 --force
cephadm rm-cluster --fsid 70eb8f7c-2d2f-11ee-8265-000c29aa07d2 --force
7.8 2 failed cephadm daemon(s),daemon node-exporter.ceph2 on ceph2 is in error state
执行ceph -s,报信息2 failed cephadm daemon(s),如下
[ceph: root@ceph1 /]# ceph -scluster:id: d20e3700-2d2f-11ee-9166-000c29aa07d2health: HEALTH_WARN2 failed cephadm daemon(s)Degraded data redundancy: 1 pg undersizedservices:mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 9m)mgr: ceph1.kxhbab(active, since 6h), standbys: ceph3.aseinmosd: 3 osds: 3 up (since 42m), 3 in (since 42m); 1 remapped pgsdata:pools: 1 pools, 1 pgsobjects: 0 objects, 0 Busage: 3.0 GiB used, 57 GiB / 60 GiB availpgs: 1 active+undersized+remapped
通过ceph health detail查看
HEALTH_WARN 2 failed cephadm daemon(s); Degraded data redundancy: 1 pg undersized
[WRN] CEPHADM_FAILED_DAEMON: 2 failed cephadm daemon(s)daemon node-exporter.ceph2 on ceph2 is in error statedaemon node-exporter.ceph3 on ceph3 is in error state
[WRN] PG_DEGRADED: Degraded data redundancy: 1 pg undersizedpg 1.0 is stuck undersized for 44m, current state active+undersized+remapped, last acting [1,0]
发现是ceph2、ceph3上node-exporter有问题,再次通过ceph orch ps查看,如下
[ceph: root@ceph1 /]# ceph orch ps
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
alertmanager.ceph1 ceph1 running (17m) 6m ago 6h 0.20.0 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f f640d60309a8
crash.ceph1 ceph1 running (6h) 6m ago 6h 15.2.17 quay.io/ceph/ceph:v15 93146564743f 167923df16d6
crash.ceph2 ceph2 running (45m) 6m ago 45m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 36930ffad980
crash.ceph3 ceph3 running (7h) 6m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f 3cf33326be8f
grafana.ceph1 ceph1 running (66m) 6m ago 6h 6.7.4 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646 a9f1cd6dd382
mgr.ceph1.kxhbab ceph1 running (6h) 6m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f c738e894f955
mgr.ceph3.aseinm ceph3 running (7h) 6m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f 2657cef61946
mon.ceph1 ceph1 running (6h) 6m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f ac8d2bf766d9
mon.ceph2 ceph2 running (45m) 6m ago 45m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 30fc64339e92
mon.ceph3 ceph3 running (7h) 6m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f b98335e1b0e1
node-exporter.ceph1 ceph1 running (66m) 6m ago 6h 0.18.1 quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf 7bb7cc89e4bf
node-exporter.ceph2 ceph2 error 6m ago 7h <unknown> quay.io/prometheus/node-exporter:v0.18.1 <unknown> <unknown>
node-exporter.ceph3 ceph3 error 6m ago 7h <unknown> quay.io/prometheus/node-exporter:v0.18.1 <unknown> <unknown>
osd.0 ceph1 running (45m) 6m ago 45m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 56418e7d64a2
osd.1 ceph1 running (45m) 6m ago 45m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 04be93b74209
osd.2 ceph1 running (45m) 6m ago 45m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 15ca4a2a1acc
prometheus.ceph1 ceph1 running (17m) 6m ago 6h 2.18.1 quay.io/prometheus/prometheus:v2.18.1 de242295e225 8dfaf3f5b9c2
ceph2、ceph3上node-exporter状态为error,将该服务重启
ceph orch daemon restart node-exporter.ceph2
ceph orch daemon restart node-exporter.ceph3
重启之后正常,如下:
[ceph: root@ceph1 /]# ceph -scluster:id: d20e3700-2d2f-11ee-9166-000c29aa07d2health: HEALTH_WARNDegraded data redundancy: 1 pg undersizedservices:mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 22m)mgr: ceph1.kxhbab(active, since 6h), standbys: ceph3.aseinmosd: 3 osds: 3 up (since 56m), 3 in (since 56m); 1 remapped pgsdata:pools: 1 pools, 1 pgsobjects: 0 objects, 0 Busage: 3.0 GiB used, 57 GiB / 60 GiB availpgs: 1 active+undersized+remapped7.8 1 failed cephadm daemon(s),daemon node-exporter.ceph2 on ceph2 is in error state
执行ceph -s,报信息1 failed cephadm daemon(s),如下
[ceph: root@ceph1 /]# ceph -scluster:id: d20e3700-2d2f-11ee-9166-000c29aa07d2health: HEALTH_WARN1 failed cephadm daemon(s)services:mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 49m)mgr: ceph1.kxhbab(active, since 6h), standbys: ceph3.aseinmosd: 9 osds: 8 up (since 116s), 8 in (since 116s)data:pools: 1 pools, 1 pgsobjects: 0 objects, 0 Busage: 8.0 GiB used, 152 GiB / 160 GiB availpgs: 1 active+clean通过ceph health detail查看
[ceph: root@ceph1 /]# ceph health detail
HEALTH_WARN 1 failed cephadm daemon(s)
[WRN] CEPHADM_FAILED_DAEMON: 1 failed cephadm daemon(s)daemon osd.3 on ceph2 is in unknown state
发现是ceph2上osd.3有问题,再次通过ceph orch ps查看,如下
[ceph: root@ceph1 /]# ceph orch ps
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
alertmanager.ceph1 ceph1 running (53m) 2m ago 7h 0.20.0 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f f640d60309a8
crash.ceph1 ceph1 running (6h) 2m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f 167923df16d6
crash.ceph2 ceph2 running (82m) 77s ago 82m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 36930ffad980
crash.ceph3 ceph3 running (7h) 31s ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f 3cf33326be8f
grafana.ceph1 ceph1 running (103m) 2m ago 7h 6.7.4 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646 a9f1cd6dd382
mgr.ceph1.kxhbab ceph1 running (6h) 2m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f c738e894f955
mgr.ceph3.aseinm ceph3 running (7h) 31s ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f 2657cef61946
mon.ceph1 ceph1 running (6h) 2m ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f ac8d2bf766d9
mon.ceph2 ceph2 running (82m) 77s ago 82m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 30fc64339e92
mon.ceph3 ceph3 running (7h) 31s ago 7h 15.2.17 quay.io/ceph/ceph:v15 93146564743f b98335e1b0e1
node-exporter.ceph1 ceph1 running (103m) 2m ago 7h 0.18.1 quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf 7bb7cc89e4bf
node-exporter.ceph2 ceph2 running (34m) 77s ago 8h 0.18.1 quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf 9cde6dd53b22
node-exporter.ceph3 ceph3 running (33m) 31s ago 8h 0.18.1 quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf 106d248979bc
osd.0 ceph1 running (82m) 2m ago 82m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 56418e7d64a2
osd.1 ceph1 running (81m) 2m ago 81m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 04be93b74209
osd.2 ceph1 running (81m) 2m ago 81m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 15ca4a2a1acc
osd.3 ceph2 unknown 77s ago 2m <unknown> quay.io/ceph/ceph:v15 <unknown> <unknown>
osd.4 ceph2 running (98s) 77s ago 100s 15.2.17 quay.io/ceph/ceph:v15 93146564743f 02800b38df89
osd.5 ceph2 running (82s) 77s ago 84s 15.2.17 quay.io/ceph/ceph:v15 93146564743f 05ce4a9c9588
osd.6 ceph3 running (60s) 31s ago 61s 15.2.17 quay.io/ceph/ceph:v15 93146564743f 0d22f79c41ab
osd.7 ceph3 running (45s) 31s ago 47s 15.2.17 quay.io/ceph/ceph:v15 93146564743f a80a852550e3
osd.8 ceph3 running (32s) 31s ago 33s 15.2.17 quay.io/ceph/ceph:v15 93146564743f 51ebec72bb3f
prometheus.ceph1 ceph1 running (53m) 2m ago 7h 2.18.1 quay.io/prometheus/prometheus:v2.18.1 de242295e225 8dfaf3f5b9c2ceph2上osd.3状态为unknown
ceph osd tree查看下osd状态
[ceph: root@ceph1 /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.15588 root default
-3 0.05846 host ceph10 hdd 0.01949 osd.0 up 1.00000 1.000001 hdd 0.01949 osd.1 up 1.00000 1.000002 hdd 0.01949 osd.2 up 1.00000 1.00000
-5 0.03897 host ceph24 hdd 0.01949 osd.4 up 1.00000 1.000005 hdd 0.01949 osd.5 up 1.00000 1.00000
-7 0.05846 host ceph36 hdd 0.01949 osd.6 up 1.00000 1.000007 hdd 0.01949 osd.7 up 1.00000 1.000008 hdd 0.01949 osd.8 up 1.00000 1.000003 0 osd.3 down 0 1.00000发现osd.3的状态为down,针对服务做一次重启
ceph orch daemon restart osd.3
等待一端时间后发现ceph orch ps获取的osd.3的状态为error
采取删除重新部署后,登录到ceph2,将磁盘重新初始化,用于满足OSD部署,如下
dmsetup rm ceph--89a94f3b--e5ef--4ec9--b828--d86ea84d6540-osd--block--e4a8e9c8--20e6--4847--8176--510533616844
vgremove ceph-89a94f3b-e5ef-4ec9-b828-d86ea84d6540
pvremove /dev/sdb
mkfs.xfs -f /dev/sdb
在ceph1上删除重新添加
ceph osd rm 3
ceph orch daemon rm osd.3 --force
ceph orch daemon add osd ceph2:/dev/sdb
重新部署后正常,估计一开始磁盘遇到些问题,如下:
[ceph: root@ceph1 /]# ceph -scluster:id: d20e3700-2d2f-11ee-9166-000c29aa07d2health: HEALTH_OKservices:mon: 3 daemons, quorum ceph1,ceph2,ceph3 (age 16h)mgr: ceph1.kxhbab(active, since 22h), standbys: ceph3.aseinmosd: 9 osds: 9 up (since 15h), 9 in (since 15h)data:pools: 1 pools, 1 pgsobjects: 0 objects, 0 Busage: 9.1 GiB used, 171 GiB / 180 GiB availpgs: 1 active+clean8. 参考文献:
https://docs.ceph.com/en/latest/cephadm/
https://docs.ceph.com/en/latest/cephfs/
https://blog.csdn.net/DoloresOOO/article/details/106855093
https://blog.csdn.net/XU_sun_/article/details/119909860
https://blog.csdn.net/networken/article/details/106870859
https://zhuanlan.zhihu.com/p/598832268
https://www.jianshu.com/p/b2aab379d7ec
https://blog.csdn.net/JineD/article/details/113886368
http://dbaselife.com/doc/752/
http://www.chenlianfu.com/?p=3388
http://mirrors.163.com/ceph/rpm-octopus/el7/noarch/
https://blog.csdn.net/qq_27979109/article/details/120345676#3mondocker_runcephconf_718
https://cloud-atlas.readthedocs.io/zh_CN/latest/ceph/deploy/install_mobile_cloud_ceph/debug_ceph_authenticate_time_out.html
https://access.redhat.com/documentation/zh-cn/red_hat_ceph_storage/5/html/operations_guide/introduction-to-the-ceph-orchestrator
相关文章:
Kylin v10基于cephadm工具离线部署ceph分布式存储
1. 环境: ceph:octopus OS:Kylin-Server-V10_U1-Release-Build02-20210824-GFB-x86_64、CentOS Linux release 7.9.2009 2. ceph和cephadm 2.1 ceph简介 Ceph可用于向云平台提供对象存储、块设备服务和文件系统。所有Ceph存储集群部署都从…...
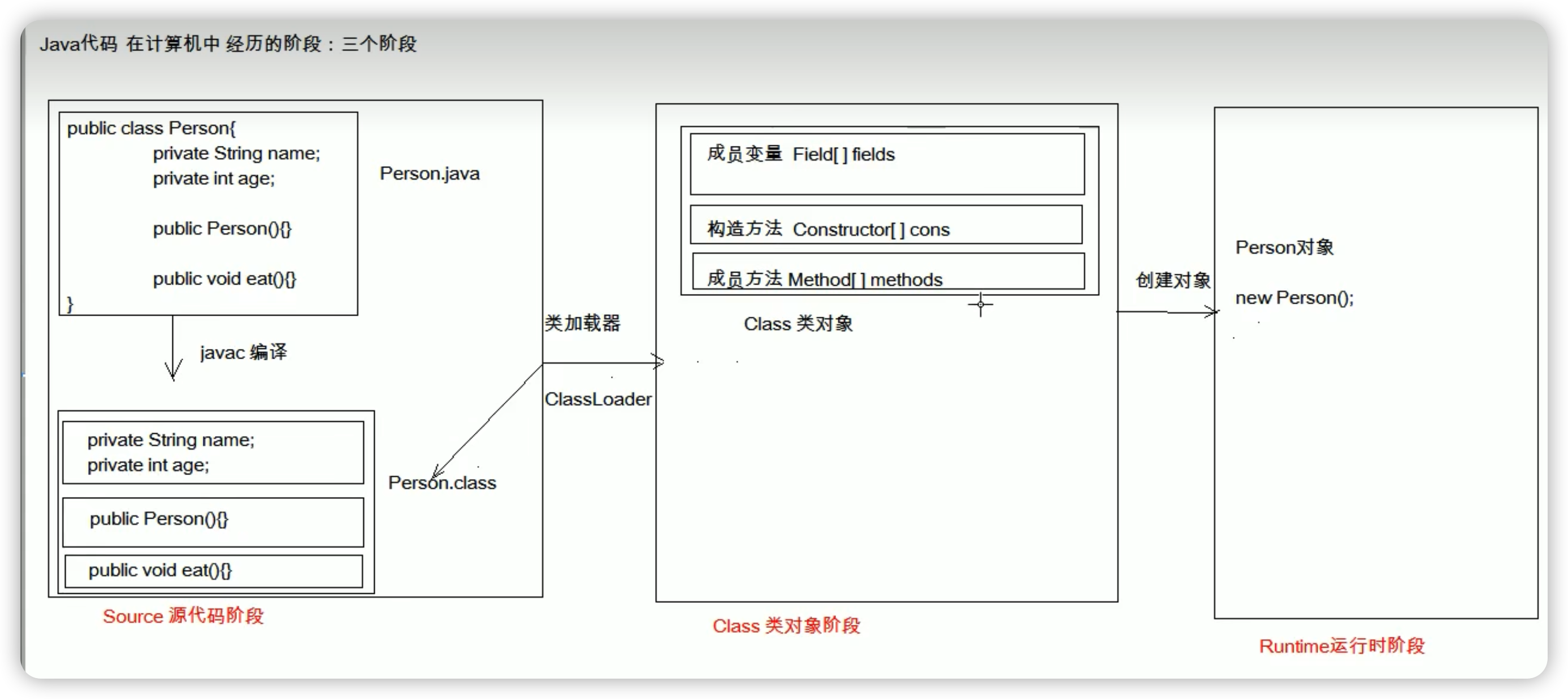
框架的前置学习-反射
运行java代码要经历的三个阶段 反射,程序框架设计的灵魂,将类的各个组成部分封装成其他对象,这就是反射机制。 框架:半成品的软件,在框架的基础上进行开发,可以简化编码 反射的好处: 可以在…...
【使用bat脚本实现批量创建文件夹、批量复制文件至对应文件夹中】
使用bat脚本实现批量创建文件夹、批量复制文件至对应文件夹中 常用cmd命令 场景一:在指定位置批量创建文件夹 在桌面创建一个txt文件编写创建目录代码 //在桌面"五保户结算单"的文件夹下创建名称为"1张三"的文件夹 md E:\桌面\五保户结算单\…...
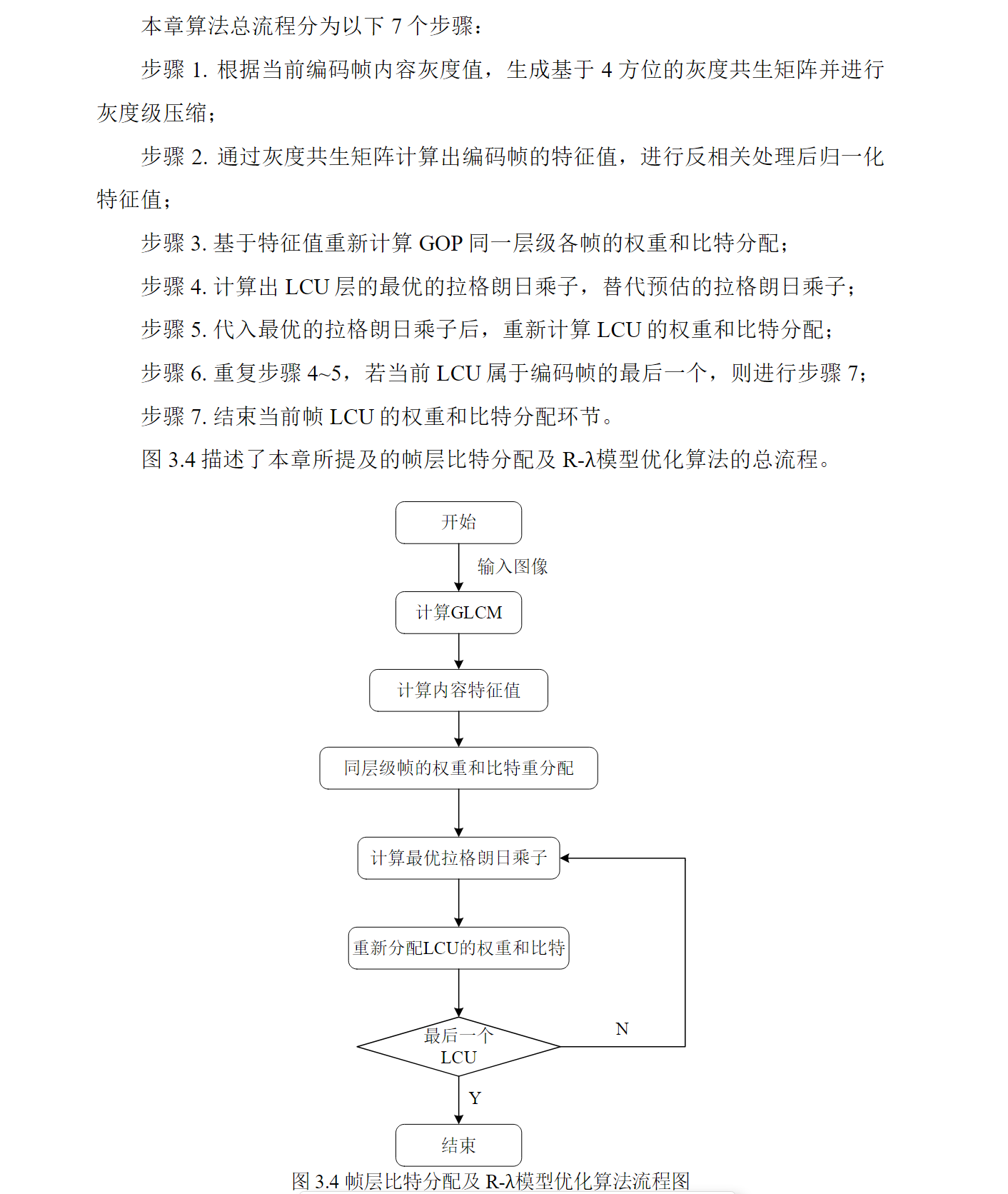
面向视频会议场景的 H.266/VVC 码率控制算法研究
文章目录 面向视频会议场景的 H.266/VVC 码率控制算法研究个人总结摘要为什么要码率控制码率控制的关键会议类视频码率控制研究背景视频会议系统研究现状目前基于 R-λ模型的码率控制算法的问题文章主要两大优化算法优化算法1:基于视频内容相关特征值的码率控制算法…...
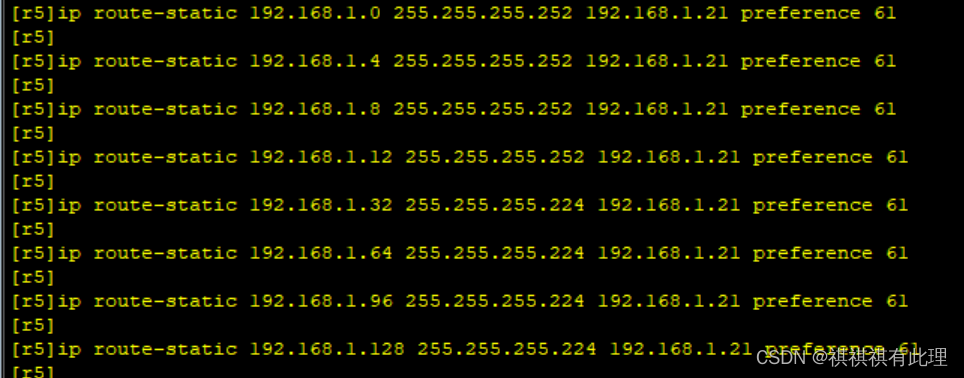
【网络基础实战之路】设计网络划分的实战详解
系列文章传送门: 【网络基础实战之路】设计网络划分的实战详解 【网络基础实战之路】一文弄懂TCP的三次握手与四次断开 【网络基础实战之路】基于MGRE多点协议的实战详解 【网络基础实战之路】基于OSPF协议建立两个MGRE网络的实验详解 PS:本要求基于…...
MacBook触控板窗口管理 Swish for Mac
Swish for Mac是一款用于通过手势来控制mac应用窗口的软件,你可以通过这款软件在触控板上进行手势控制,你可以在使用前预设好不同手势的功能,然后就能直接通过这些手势让窗口按照你想要的方式进行变动了 Swish 支持 Haptick Feedback 震动反…...
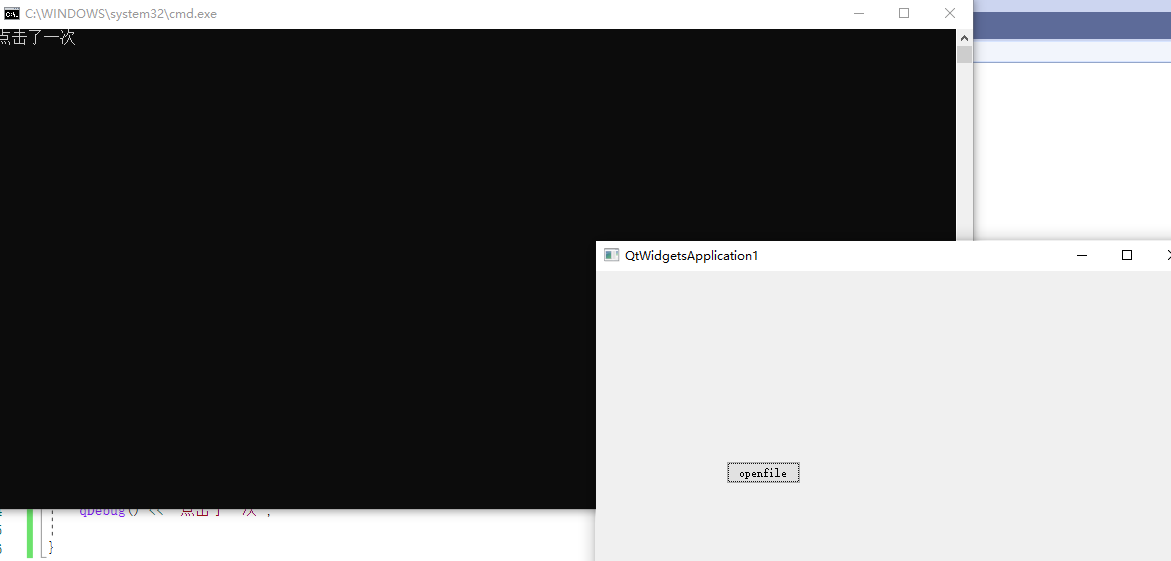
VS开发Qt程序,无法打印QDebug调试信息,VS进行Qt开发时Qt Designer无法使用“转到槽”选项
VS开发Qt程序,无法打印QDebug调试信息,VS进行Qt开发时Qt Designer无法使用“转到槽”选项 VS开发Qt程序,无法打印QDebug调试信息VS进行Qt开发时Qt Designer无法使用“转到槽”选项 VS开发Qt程序,无法打印QDebug调试信息 解决方案…...
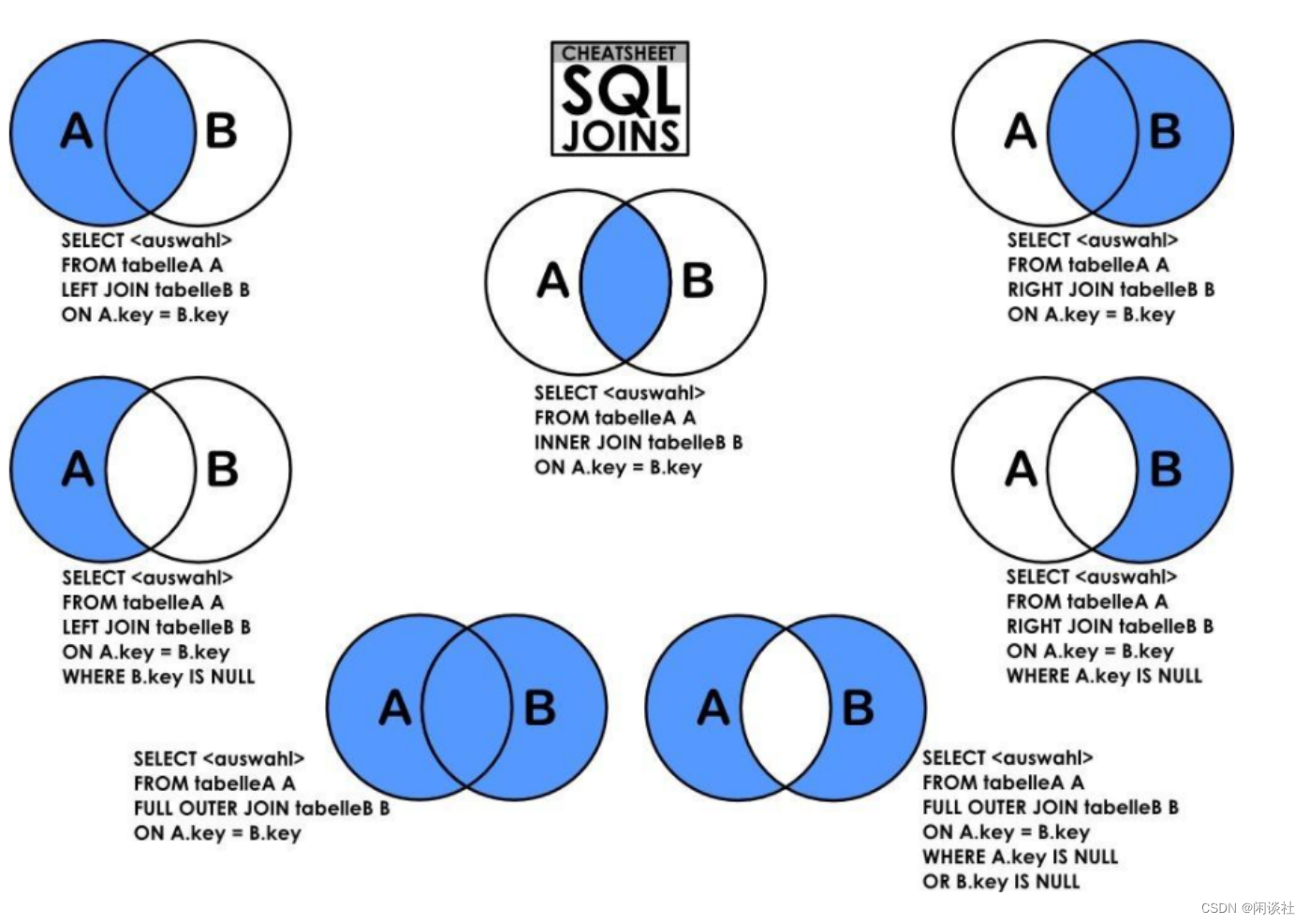
MySQL操作命令详解:增删改查
文章目录 一、CRUD1.1 数据库操作1.2 表操作1.2.1 五大约束1.2.2 创建表1.2.3 修改表1.2.3 删除表1.2.4 表数据的增删改查1.2.5 去重方式 二、高级查询2.1 基础查询2.2 条件查询2.3 范围查询2.4 判空查询2.5 模糊查询2.6 分页查询2.7 查询后排序2.8 聚合查询2.9 分组查询2.10 联…...

MySQL字段类型与存储空间的关系
在 MySQL 中,对于整数类型(如 INT)、字符类型(如 VARCHAR)、浮点数类型(如 DOUBLE)等,参数(括号中的数字或长度)通常用于限制数据的范围或精度,但…...

红船元宇宙 上海布袋除尘器后一家太平洋百货月底停业
上海布袋除尘器后一家太平洋百货即将停业。 7月31日,上海太平洋百货微信公号发布公告称,由于与合资方的合作期限今年届满,上海太平洋百货徐汇店将于2023年8月31日营业结束后正式谢幕,终止经营,并于即日起开展大型主题感…...
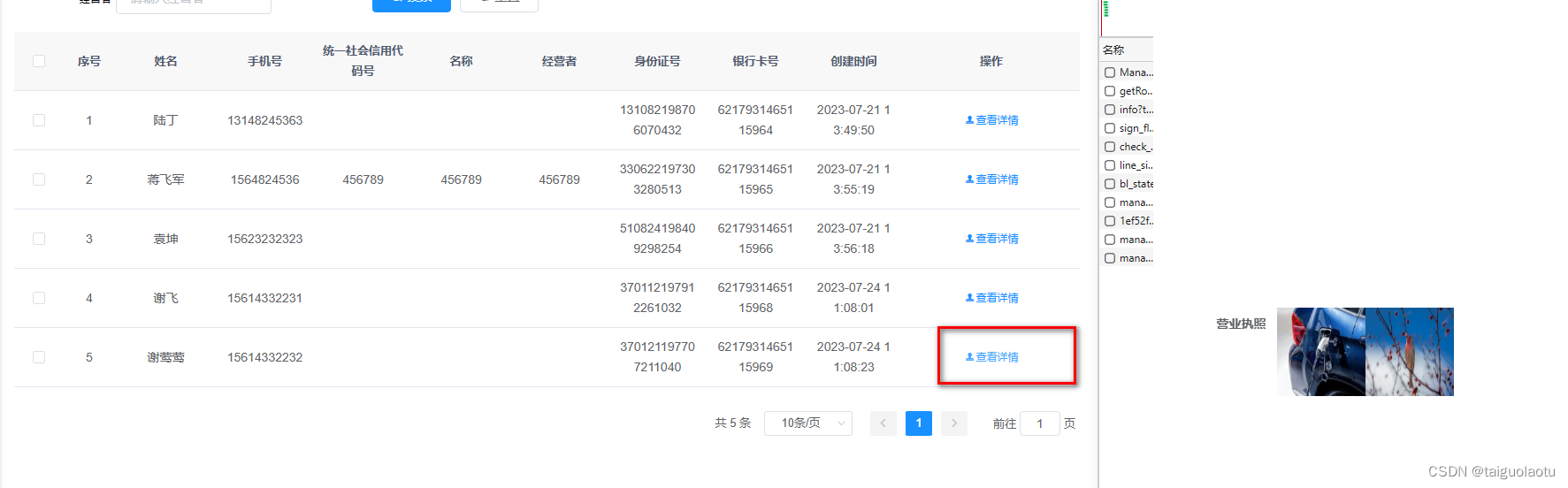
vue 图片回显标签
第一种 <el-form-item label"打款银行回单"><image-preview :src"form.bankreceiptUrl" :width"120" :height"120"/></el-form-item>// 值为 https://t11.baidu.com/it/app106&fJPEG&fm30&fmtauto&…...

《向量数据库指南》——使用SQuAD 数据集演示Faiss 功能
使用 SQuAD 数据集进行演示 现在,我们可以通过示例演示了解 Faiss 功能。本次示例中,将使用斯坦福的问答数据集(SQuAD)。SQuAD 是一个常用的自然语言处理(NLP)数据集,该数据集基于用户在百科中提出的问题,每个问题的答案都来自于对应阅读段落的一段文本,共计 500 多…...
)
java多线程并发面试题总结(史上最全40道)
1、多线程有什么用? 一个可能在很多人看来很扯淡的一个问题:我会用多线程就好了,还管它有什么用?在我看来,这个回答更扯淡。所谓"知其然知其所以然","会用"只是"知其然"&am…...
IDEA强大的VisualGC插件
前言 开发阶段实时监测,自己的JVM信息,实时可视化 Hotspot JVM 垃圾回收监控工具, 支持查看本地和远程JVM进程, 支持G1 and ZGC算法。 插件安装 在线安装 IntelliJ IDEA 可通过在线安装的方式,安装插件 JDK VisualGC,安装步骤: …...

桐乡上元教育室内设计培训班-CAD学习
室内设计四大软件】 1、Auto ca??d:着重培训建筑与室内设计所用知识,增强实践性施工图纸的绘制与操作速度; 课程包括:CAD基本命令与修改器;室内平面图、地面、天花、照明等图;室内立面图绘制;室内剖面图绘制;定植尅家具的平面、立…...

h5浏览pdf文件
将hybrid整个复制到一级文件夹下 hybrid地址:https://download.csdn.net/download/qq_37194189/88157330 创建一个 pdf页面用于展示pdf文件 <template><view style"width: 100%;" ><web-view :src"pdfUrl"></web-view&…...

无涯教程-Lua - 嵌套if语句函数
在Lua编程中,您可以在另一个if or else if语句中使用一个if or else if语句。 nested if statements - 语法 嵌套if 语句的语法如下- if( boolean_expression 1) then--[ Executes when the boolean expression 1 is true --]if(boolean_expression 2)then--[ Ex…...

vue v-slot指令
目录 定义语法使用场景场景一场景二场景三tips只有一个默认插槽时 定义 在Vue中, v-slot 指令用于定义插槽的模板内容。它用于在父组件中传递内容到子组件中的插槽。 v-slot 指令可以用于 标签或组件标签上,以便在子组件中使用插槽。 语法 使用 v-slo…...

【机器学习】西瓜书学习心得及课后习题参考答案—第6章支持向量机
笔记心得 6.1 间隔与支持向量—— w w w是法向量,垂直与超平面 w T x b 0 w^Txb0 wTxb0。这一节了解了支持向量机的基本型。 min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i b ) ≥ 1 , i 1 , 2 , . . . , m . \min_{w,b} \frac{1}{2}||w||^2 \\ s.…...
无涯教程-Perl - 面向对象
Perl中的面向对象概念很大程度上基于引用以及匿名数组和哈希。让我们开始学习面向对象Perl的基本概念。 定义类 在Perl中定义一个类非常简单。类以最简单的形式对应于Perl软件包。要在Perl中创建一个类,我们首先构建一个包。 Perl软件包在Perl程序中提供了一个单…...

避坑!这些毕设太好抄了,3000+毕设案例推荐第1038期
381、基于Java的对外公告智慧管理系统的设计与实现(论文+代码+PPT)对外公告智慧管理系统主要功能包括:会员管理、公告管理、审核任务、审核节点、审核日志、回复管理、通知管理、通知接收者、工作流管理、组织机构、消息推送、消息推送接收者…...

分切机程序开发:上下收放卷张力控制实现
分切机程序 ,上下收放卷张力控制,无电子凸轮功能。 触摸屏威纶通,PLC是三菱FX3U系列 在自动化生产领域,分切机的稳定运行至关重要,尤其是上下收放卷张力的精准控制。本文将探讨基于威纶通触摸屏和三菱FX3U系列PLC&…...
:表格重塑与数据整合)
Pandas 操作指南(五):表格重塑与数据整合
在数据分析中,并不是所有表格一开始都具有合适的结构。有时,一张表虽然保存了所需数据,但其组织方式并不利于统计与比较;有时,信息分散在多张表中,需要先整合后分析。由此可见,分析不仅依赖于数…...

实战演练:用快马平台生成含“陷阱”的ensp企业网攻防实验环境
作为一名经常需要搭建网络实验环境的技术爱好者,最近发现用InsCode(快马)平台来生成ensp项目特别高效。今天想分享一个实战案例:如何快速构建带"陷阱"的企业网攻防演练环境。 项目设计思路 这个实验环境模拟了典型的三层企业网络架构。最外层是…...

G-Helper华硕优化工具:5分钟解锁300%性能提升的轻量级解决方案
G-Helper华硕优化工具:5分钟解锁300%性能提升的轻量级解决方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, S…...

Spyglass实战指南:从约束到违例豁免的CDC/RDC检查全流程
1. Spyglass入门:CDC/RDC检查基础 第一次接触Spyglass时,我被它复杂的规则体系搞得晕头转向。直到在项目中真正用它解决了几个棘手的跨时钟域问题,才明白这个工具的价值。简单来说,Spyglass就像个经验丰富的"电路医生"&…...

英雄联盟录像编辑终极指南:免费开源工具League Director完全教程
英雄联盟录像编辑终极指南:免费开源工具League Director完全教程 【免费下载链接】leaguedirector League Director is a tool for staging and recording videos from League of Legends replays 项目地址: https://gitcode.com/gh_mirrors/le/leaguedirector …...
)
手把手教你用VSCode和ST-Link V2给ODrive V3.6编译烧录056固件(附避坑指南)
从零开始:ODrive V3.6固件编译与烧录全流程实战指南 当你第一次拿到ODrive V3.6这款高性能电机驱动板时,可能会被它强大的功能所吸引,同时也可能对如何开始使用感到些许迷茫。本文将带你一步步完成从环境搭建到固件烧录的全过程,…...
用C++实现信奥题 P7015 [CERC2013] Crane)
打卡信奥刷题(3076)用C++实现信奥题 P7015 [CERC2013] Crane
P7015 [CERC2013] Crane 题目描述 有 nnn 个箱子等着装上船。箱子的编号是 a1,a2,⋯ ,ana_1,a_2,\cdots,a_na1,a2,⋯,an。你的工作是通过若干次交换,将它们从小到大排列。你每次可以选择一个区间,将它的前半部分与后半部分交换,两半内…...

当LabVIEW遇见AI:使用快马平台集成机器学习实现数据趋势预测
当LabVIEW遇见AI:使用快马平台集成机器学习实现数据趋势预测 最近在做一个工业设备状态监测的项目,需要实时预测电机振动趋势。传统LabVIEW开发虽然擅长数据采集和可视化,但加入AI预测能力一直让我头疼。直到尝试了InsCode(快马)平台&#x…...