【计算机视觉 | 图像分割】arxiv 计算机视觉关于图像分割的学术速递(8 月 1 日论文合集)
文章目录
- 一、分割|语义相关(16篇)
- 1.1 DPMix: Mixture of Depth and Point Cloud Video Experts for 4D Action Segmentation
- 1.2 Investigating and Improving Latent Density Segmentation Models for Aleatoric Uncertainty Quantification in Medical Imaging
- 1.3 Domain Adaptation for Medical Image Segmentation using Transformation-Invariant Self-Training
- 1.4 Audio-visual segmentation, sound localization, semantic-aware sounding objects localization
- 1.5 Contrastive Conditional Latent Diffusion for Audio-visual Segmentation
- 1.6 Transferable Attack for Semantic Segmentation
- 1.7 Towards Unbalanced Motion: Part-Decoupling Network for Video Portrait Segmentation
- 1.8 Rethinking Collaborative Perception from the Spatial-Temporal Importance of Semantic Information
- 1.9 3D Medical Image Segmentation with Sparse Annotation via Cross-Teaching between 3D and 2D Networks
- 1.10 ScribbleVC: Scribble-supervised Medical Image Segmentation with Vision-Class Embedding
- 1.11 PD-SEG: Population Disaggregation Using Deep Segmentation Networks For Improved Built Settlement Mask
- 1.12 XMem++: Production-level Video Segmentation From Few Annotated Frames
- 1.13 CMDA: Cross-Modality Domain Adaptation for Nighttime Semantic Segmentation
- 1.14 A hybrid approach for improving U-Net variants in medical image segmentation
- 1.15 An objective validation of polyp and instrument segmentation methods in colonoscopy through Medico 2020 polyp segmentation and MedAI 2021 transparency challenges
- 1.16 Cross-dimensional transfer learning in medical image segmentation with deep learning
一、分割|语义相关(16篇)
1.1 DPMix: Mixture of Depth and Point Cloud Video Experts for 4D Action Segmentation
DPMix:深度和点云视频专家的混合4D动作分割
https://arxiv.org/abs/2307.16803

在这份技术报告中,我们介绍了针对自我中心动作分割任务的人机交互 4D (HOI4D) 数据集进行的研究结果。 作为一个相对新颖的研究领域,点云视频方法可能不擅长时间建模,特别是对于长点云视频(例如,150 帧)。 相比之下,传统的视频理解方法已经得到了很好的发展。 它们在时间建模上的有效性已在许多大规模视频数据集上得到了广泛验证。 因此,我们将点云视频转换为深度视频,并采用传统的视频建模方法来改进4D动作分割。 通过融合深度和点云视频方法,精度显着提高。 所提出的方法名为深度和点云视频专家混合 (DPMix),在 2023 年 HOI4D 挑战赛的 4D 动作分割赛道中获得了第一名。
1.2 Investigating and Improving Latent Density Segmentation Models for Aleatoric Uncertainty Quantification in Medical Imaging
医学影像中任意不确定性量化的潜在密度分割模型研究与改进
https://arxiv.org/abs/2307.16694

数据不确定性,例如传感器噪声或遮挡,可能会在图像中引入不可减少的模糊性,从而导致不同但合理的语义假设。 在机器学习中,这种模糊性通常被称为任意不确定性。 潜在密度模型可以用来解决图像分割中的这个问题。 最流行的方法是概率 U-Net (PU-Net),它使用潜在正态密度来优化条件数据对数似然证据下界。 在这项工作中,我们证明了 PU-Net 潜在空间是严重不均匀的。 结果,梯度下降的有效性受到抑制,模型对潜在空间样本的定位变得极其敏感,导致预测有缺陷。 为了解决这个问题,我们提出了 Sinkhorn PU-Net (SPU-Net),它使用 Sinkhorn Divergence 来促进所有潜在维度的同质性,有效提高梯度下降更新和模型鲁棒性。 我们的结果表明,通过将其应用于各种临床分割问题的公共数据集,与之前基于匈牙利匹配指标进行概率分割的潜在变量模型相比,SPU-Net 获得了高达 11% 的性能提升。 结果表明,通过鼓励均匀的潜在空间,可以显着改进医学图像分割的潜在密度建模。
1.3 Domain Adaptation for Medical Image Segmentation using Transformation-Invariant Self-Training
基于变换不变自学习的医学图像分割领域自适应
https://arxiv.org/abs/2307.16660

能够利用未标记数据的模型对于克服不同成像设备和配置所获取的数据集之间的巨大分布差距至关重要。 在这方面,基于伪标记的自我训练技术已被证明对于半监督域适应非常有效。 然而,伪标签的不可靠性可能会阻碍自训练技术从未标记的目标数据集中诱导抽象表示的能力,特别是在分布差距较大的情况下。 由于神经网络性能对于图像变换应该是不变的,因此我们利用这一事实来识别不确定的伪标签。 事实上,我们认为变换不变检测可以提供更合理的地面事实近似值。 因此,我们提出了一种用于领域适应的半监督学习策略,称为变换不变自训练(TI-ST)。 所提出的方法评估像素级伪标签的可靠性并在自训练期间过滤掉不可靠的检测。 我们使用三种不同模式的医学图像、两种不同的网络架构和几种替代的最先进的域适应方法对域适应进行综合评估。 实验结果证实了我们提出的方法在缓解目标域注释缺失和提高目标域分割性能方面的优越性。
1.4 Audio-visual segmentation, sound localization, semantic-aware sounding objects localization
视听分割、声音定位、语义感知的发声对象定位
https://arxiv.org/abs/2307.16620

视听分割(AVS)任务旨在从给定视频中分割发声对象。 现有的工作主要集中于融合给定视频的音频和视觉特征以实现发声对象掩模。 然而,我们观察到,现有技术倾向于分割视频中的某个显着对象,而不管音频信息如何。 这是因为探测对象通常是 AVS 数据集中最显着的对象。 因此,由于数据集偏差,当前的 AVS 方法可能无法定位真实的发声对象。 在这项工作中,我们提出了一种视听实例感知分割方法来克服数据集偏差。 简而言之,我们的方法首先通过对象分割网络定位视频中潜在的发声对象,然后将发声对象候选者与给定的音频相关联。 我们注意到,一个物体可能在一个视频中是发声物体,但在另一个视频中可能是无声物体。 这会给训练我们的对象分割网络带来歧义,因为只有发声对象才有相应的分割掩模。 因此,我们提出了一个静默的对象感知分割目标来减轻歧义。 此外,由于音频的类别信息是未知的,特别是对于多个声源,我们建议探索视听语义相关性,然后将音频与潜在对象相关联。 具体来说,我们将预测的音频类别分数加入到潜在的实例掩码中,这些分数将突出显示相应的发声实例,同时抑制听不见的实例。 当我们强制参与实例掩码类似于真实掩码时,我们能够建立视听语义相关性。 AVS 基准测试的实验结果表明,我们的方法可以有效地分割发声对象,而不会偏向显着对象。
1.5 Contrastive Conditional Latent Diffusion for Audio-visual Segmentation
用于视听分割的对比条件隐含扩散算法
https://arxiv.org/abs/2307.16579

我们提出了一种用于视听分割(AVS)的具有对比学习的潜在扩散模型,以广泛探索音频的贡献。 我们将 AVS 解释为条件生成任务,其中音频被定义为声音生成器分段的条件变量。 根据我们的新解释,特别有必要对音频和最终分割图之间的相关性进行建模,以确保其贡献。 我们在我们的框架中引入了潜在扩散模型,以实现语义相关的表示学习。 具体来说,我们的扩散模型学习地面实况分割图的条件生成过程,从而在测试阶段执行去噪过程时进行地面实况感知推理。 作为条件扩散模型,我们认为确保条件变量对模型输出有贡献至关重要。 然后,我们将对比学习引入到我们的框架中来学习视听对应关系,这被证明与最大化模型预测和音频数据之间的互信息是一致的。 通过这种方式,我们通过对比学习的潜在扩散模型明确最大化了音频对 AVS 的贡献。 基准数据集上的实验结果验证了我们解决方案的有效性。
1.6 Transferable Attack for Semantic Segmentation
语义分词的可转移攻击
https://arxiv.org/abs/2307.16572

众所周知,语义分割模型容易受到小输入扰动的影响。 在本文中,我们全面分析了语义分割模型在对抗性攻击方面的性能,并观察到从源模型生成的对抗性示例无法攻击目标模型,即传统的攻击方法,如 PGD 和 FGSM ,不能很好地迁移到目标模型,因此有必要研究可迁移攻击,特别是语义分割的可迁移攻击。 我们发现,为了实现可转移攻击,攻击应该具有有效的数据增强和平移不变特征来处理未见过的模型,以及稳定的优化策略来找到最佳攻击方向。 基于上述观察,我们提出了一种用于语义分割的集成攻击,通过聚合来自分类的多个可转移攻击来实现具有更高可转移性的更有效的攻击。
1.7 Towards Unbalanced Motion: Part-Decoupling Network for Video Portrait Segmentation
走向不平衡运动:用于视频人像分割的部分解耦网络
https://arxiv.org/abs/2307.16565

视频肖像分割(VPS)旨在从视频帧中分割出突出的前景肖像,近年来受到了广泛关注。 然而,现有 VPS 数据集的简单性导致对该任务的广泛研究受到限制。 在这项工作中,我们提出了一种新的复杂的大规模多场景视频肖像分割数据集 MVPS,由 7 个场景类别的 101 个视频片段组成,其中 10,843 个采样帧在像素级别进行了精细注释。 该数据集场景多样,背景环境复杂,是目前VPS中最复杂的数据集。 通过数据集构建过程中对大量人像视频的观察,我们发现,由于人体的关节结构,人像的运动是部分关联的,导致不同部分的运动相对独立。 也就是说,肖像的不同部分的运动是不平衡的。 针对这种不平衡,一个直观且合理的想法是,通过将肖像解耦成多个部分,可以更好地利用肖像中的不同运动状态。 为了实现这一目标,我们提出了一种用于视频肖像分割的部分解耦网络(PDNet)。 具体来说,提出了一种帧间部分区分注意力(IPDA)模块,该模块无监督地将肖像分割成多个部分,并对每个不同部分指定的判别特征利用不同的注意力。 这样,可以对运动不平衡的肖像部分给予适当的关注,以提取部分区分的相关性,从而可以更准确地分割肖像。 实验结果表明,与最先进的方法相比,我们的方法取得了领先的性能。
1.8 Rethinking Collaborative Perception from the Spatial-Temporal Importance of Semantic Information
从语义信息的时空重要性反思协同感知
https://arxiv.org/abs/2307.16517

通过共享语义信息进行协作对于增强感知能力至关重要。 然而,现有的协作感知方法往往只关注语义信息的空间特征,而忽略了时间维度在协作者选择和语义信息融合中的重要性,从而导致性能下降。 在本文中,我们提出了一种新颖的协作感知框架——IoSI-CP,它从时间和空间维度考虑了语义信息(IoSI)的重要性。 具体来说,我们开发了一种基于 IoSI 的协作者选择方法,该方法可以有效识别有利的协作者,但排除那些带来负面收益的协作者。 此外,我们提出了一种称为 HPHA(历史先验混合注意力)的语义信息融合算法,该算法集成了多尺度变换器模块和短期注意力模块,以从空间和时间维度捕获 IoSI,并分配不同的权重以进行有效聚合。 对两个开放数据集的大量实验表明,与最先进的方法相比,我们提出的 IoSI-CP 显着提高了感知性能。
1.9 3D Medical Image Segmentation with Sparse Annotation via Cross-Teaching between 3D and 2D Networks
基于3D和2D网络交叉教学的稀疏注记三维医学图像分割
https://arxiv.org/abs/2307.16256

医学图像分割通常需要大型且精确注释的数据集。 然而,获得像素级注释是一项劳动密集型任务,需要领域专家付出巨大努力,这使得在实际临床场景中获得该注释具有挑战性。 在这种情况下,减少所需的注释量是一种更实用的方法。 一种可行的方向是稀疏注释,它只涉及几个切片的注释,并且比传统的弱注释方法(例如边界框和涂鸦)具有多个优点,因为它保留了精确的边界。 然而,由于监督信号的稀缺,从稀疏注释中学习具有挑战性。 为了解决这个问题,我们提出了一个框架,可以使用 3D 和 2D 网络的交叉教学从稀疏注释中稳健地学习。 考虑到这些网络的特点,我们开发了两种伪标签选择策略,即硬-软置信度阈值和一致标签融合。 我们在 MMWHS 数据集上的实验结果表明,我们的方法优于最先进的 (SOTA) 半监督分割方法。 此外,我们的方法取得的结果与完全监督的上限结果相当。
1.10 ScribbleVC: Scribble-supervised Medical Image Segmentation with Vision-Class Embedding
ScribbleVC:基于视觉类嵌入的涂鸦监督医学图像分割
https://arxiv.org/abs/2307.16226

医学图像分割在临床决策、治疗计划和疾病监测中发挥着至关重要的作用。 然而,由于缺乏高质量注释、成像噪声和患者之间的解剖差异等多种因素,医学图像的准确分割具有挑战性。 此外,现有的标签高效方法和完全监督方法之间在性能上仍然存在相当大的差距。 为了解决上述挑战,我们提出了 ScribbleVC,这是一种用于涂鸦监督医学图像分割的新颖框架,它通过多模态信息增强机制利用视觉和类嵌入。 此外,ScribbleVC统一利用CNN特征和Transformer特征来实现更好的视觉特征提取。 所提出的方法将基于涂鸦的方法与分割网络和类嵌入模块相结合,以产生准确的分割掩模。 我们在三个基准数据集上评估 ScribbleVC,并将其与最先进的方法进行比较。 实验结果表明,我们的方法在准确性、鲁棒性和效率方面优于现有方法。 数据集和代码发布在 GitHub 上。
1.11 PD-SEG: Population Disaggregation Using Deep Segmentation Networks For Improved Built Settlement Mask
PD-SEG:基于深度分割网络的改进聚落面具种群分解
https://arxiv.org/abs/2307.16084

任何涉及优化利用资源进行发展和规划举措的政策层面的决策程序和学术研究都依赖于准确的人口密度统计数据。 WorldPop 和 Meta 提供的当前尖端数据集未能成功实现巴基斯坦等发展中国家的这一目标; 他们的算法的输入提供了有缺陷的估计,无法捕捉空间和土地利用动态。 为了以 30 米 x 30 米的分辨率精确估计人口数量,我们使用通过深度分割网络和卫星图像获得的精确构建的沉降掩模。 兴趣点 (POI) 数据还用于排除非住宅区。
1.12 XMem++: Production-level Video Segmentation From Few Annotated Frames
XMem++:从少量带注解的帧中进行生产级视频分割
https://arxiv.org/abs/2307.15958

尽管用户引导的视频分割取得了进步,但为高度复杂的场景一致地提取复杂对象仍然是一项劳动密集型任务,尤其是对于生产而言。 大多数框架需要注释的情况并不罕见。 我们引入了一种新颖的半监督视频对象分割(SSVOS)模型 XMem++,它通过永久内存模块改进了现有的基于内存的模型。 大多数现有方法都专注于单帧注释,而我们的方法可以有效地处理同一对象或区域具有不同外观的多个用户选择的帧。 我们的方法可以提取高度一致的结果,同时保持所需的帧注释数量较低。 我们进一步引入了一种迭代和基于注意力的框架建议机制,它计算下一个最佳的注释框架。 我们的方法是实时的,不需要在每次用户输入后重新训练。 我们还引入了一个新的数据集 PUMaVOS,它涵盖了以前的基准测试中未发现的新的具有挑战性的用例。 我们在具有挑战性的(部分和多类)分割场景以及长视频上展示了 SOTA 性能,同时确保比任何现有方法显着减少帧注释。
1.13 CMDA: Cross-Modality Domain Adaptation for Nighttime Semantic Segmentation
CMDA:面向夜间语义分割的跨通道领域自适应
https://arxiv.org/abs/2307.15942

大多数夜间语义分割研究都是基于领域适应方法和图像输入。 然而,受传统相机低动态范围的限制,图像无法捕捉弱光条件下的结构细节和边界信息。 事件相机作为一种新型视觉传感器,以其高动态范围与传统相机形成互补。 为此,我们提出了一种新颖的无监督跨模态域适应(CMDA)框架,利用多模态(图像和事件)信息进行夜间语义分割,仅在白天图像上添加标签。 在 CMDA 中,我们设计了图像运动提取器来提取运动信息,设计了图像内容提取器来从图像中提取内容信息,以弥合不同模态(图像到事件)和领域(白天到夜晚)之间的差距。 此外,我们还介绍了第一个图像事件夜间语义分割数据集。 对公共图像数据集和提出的图像事件数据集的广泛实验证明了我们提出的方法的有效性。
1.14 A hybrid approach for improving U-Net variants in medical image segmentation
一种改进医学图像分割中U网变体的混合方法
https://arxiv.org/abs/2307.16462

医学图像分割对于医学成像领域至关重要,因为它使专业人员能够更准确地检查和理解不同成像方式提供的信息。 将医学图像分割成各种感兴趣的片段或区域的技术称为医学图像分割。 生成的分割图像可用于许多不同的用途,包括诊断、手术计划和治疗评估。
在研究的初始阶段,主要重点是回顾现有的深度学习方法,包括 MultiResUNet、Attention U-Net、经典 U-Net 和其他变体等研究。 注意特征向量或图动态地为关键信息添加重要权重,并且大多数这些变体都使用它们来提高准确性,但网络参数要求更加严格。 它们面临着某些问题,例如过度拟合,因为它们的可训练参数数量非常多,推理时间也非常多。
因此,本研究的目的是使用深度可分离卷积来减少网络参数要求,同时保持某些医学图像分割任务的性能,例如使用注意系统和残差连接的皮肤病变分割。
1.15 An objective validation of polyp and instrument segmentation methods in colonoscopy through Medico 2020 polyp segmentation and MedAI 2021 transparency challenges
通过Medico 2020息肉分割和MEDai 2021透明度挑战对结肠镜检查中息肉和器械分割方法的客观验证
https://arxiv.org/abs/2307.16262

由于早期检测癌前息肉的重要性,结肠镜检查图像的自动分析一直是一个活跃的研究领域。 然而,由于各种因素,例如内窥镜医师的技能和经验差异、注意力不集中以及疲劳导致息肉漏检率较高,在实时检查期间检测息肉可能具有挑战性。 深度学习已成为应对这一挑战的一种有前途的解决方案,因为它可以帮助内窥镜医生实时检测和分类被忽视的息肉和异常。 除了算法的准确性之外,透明度和可解释性对于解释算法预测的原因和方式也至关重要。 此外,大多数算法都是在私有数据、闭源或专有软件中开发的,并且方法缺乏可重复性。 因此,为了促进高效、透明方法的发展,我们组织了“Medico自动息肉分割(Medico 2020)”和“MedAI:医学图像分割的透明度(MedAI 2021)”竞赛。 我们对每项贡献进行了全面的总结和分析,强调了表现最佳的方法的优势,并讨论了将此类方法转化为临床的可能性。 对于透明度任务,包括胃肠病专家在内的多学科团队访问了每份提交内容,并根据开源实践、失败案例分析、消融研究、评估的可用性和可理解性对团队进行了评估,以更深入地了解模型的 临床部署的可信度。 通过对挑战的全面分析,我们不仅强调了息肉和手术器械分割方面的进展,还鼓励定性评估,以构建更加透明和易于理解的基于人工智能的结肠镜检查系统。
1.16 Cross-dimensional transfer learning in medical image segmentation with deep learning
深度学习的跨维转移学习在医学图像分割中的应用
https://arxiv.org/abs/2307.15872

在过去的十年中,卷积神经网络已经出现,并推动了各种图像分析和计算机视觉应用领域的最先进技术。 二维图像分类网络的性能不断提高,并在由数百万张自然图像组成的数据库上进行训练。 然而,有限的注释数据和采集限制阻碍了医学图像分析的进展。 考虑到医学成像数据的体积,这些限制甚至更加明显。 在本文中,我们介绍了一种有效的方法,可以将在自然图像上训练的 2D 分类网络的效率转移到 2D、3D 单模态和多模态医学图像分割应用中。 在这个方向上,我们基于两个关键原则设计了新颖的架构:通过将 2D 预训练编码器嵌入到更高维度的 U-Net 中进行权重转移,以及通过将 2D 分割网络扩展到更高维度来进行维度转移。 所提出的网络在包含不同模式的基准上进行了测试:MR、CT 和超声图像。 我们的 2D 网络在专门用于超声心动图数据分割的 CAMUS 挑战赛中排名第一,并超越了最先进的水平。 关于 CHAOS 挑战赛中的 2D/3D MR 和 CT 腹部图像,我们的方法在 Dice、RAVD、ASSD 和 MSSD 分数方面大大优于挑战论文中描述的其他基于 2D 的方法,并在在线评估平台上排名第三。 我们应用于BraTS 2022比赛的3D网络也取得了可喜的结果,整个肿瘤的平均Dice得分为91.69%(91.22%),肿瘤核心的平均Dice得分为83.23%(84.77%),肿瘤核心的平均Dice得分为81.75%(83.88%)。 使用基于重量(尺寸)转移的方法增强肿瘤。 实验和定性结果说明了我们的多维医学图像分割方法的有效性。
相关文章:
【计算机视觉 | 图像分割】arxiv 计算机视觉关于图像分割的学术速递(8 月 1 日论文合集)
文章目录 一、分割|语义相关(16篇)1.1 DPMix: Mixture of Depth and Point Cloud Video Experts for 4D Action Segmentation1.2 Investigating and Improving Latent Density Segmentation Models for Aleatoric Uncertainty Quantification in Medical Imaging1.3 Domain Ada…...

Jetson nano 安装swapfile 解决Cannot allocate memory 问题
在jetson nano上执行一些程序的时候,由于nano的内存只有4GB,因此可能会出现以下报错信息,例如:OSError:Cannot allocate memory 的问题。可以尝试用下面的方法解决:通过安装 swapfile,可以解决这个问题。 …...
ElasticsSearch基础概念和安装
ElasticSearch基础概念以及可视化界面安装 文章目录 ElasticSearch基础概念以及可视化界面安装1、引言2、基本概念3、倒排索引机制3.1、倒排索引 4、使用docker安装ElasticSearch4.1、下载镜像文件4.2 、创建实例,启动es 5.安装Kibana 1、引言 Elastic 的底层是开源库 Lucene。…...

【GEMM预备工作】行主序和列主序矩阵的内存中的连续性,解决理解问题
在内存存储中,默认矩阵是按照行优先储存的,即矩阵的每一列在内存中是连续的。行优先矩阵储存中行数据是不连续的。 而对于列主序的矩阵,是按照列优先储存的,即矩阵的每一行在内存中是连续的。列优先矩阵储存中列数据是不连续的&am…...

利用el-button 画圆 ,通过border-radius >50% 就成圆形
<el-button type"danger" style"border-radius: 100%; height: 100px;width: 100px;" plain><span style"font-weight: bold;">工艺分析</span></el-button>通过border-radius >50% 就成圆形。 border-radius: 50% …...

在tensorflow分布式训练过程中突然终止(终止)
问题 这是为那些将从服务器接收渐变的员工提供的培训功能,在计算权重和偏差后,将更新的渐变发送到服务器。代码如下: def train():"""Train CIFAR-10 for a number of steps."""g1 tf.Graph()with g1.as_de…...
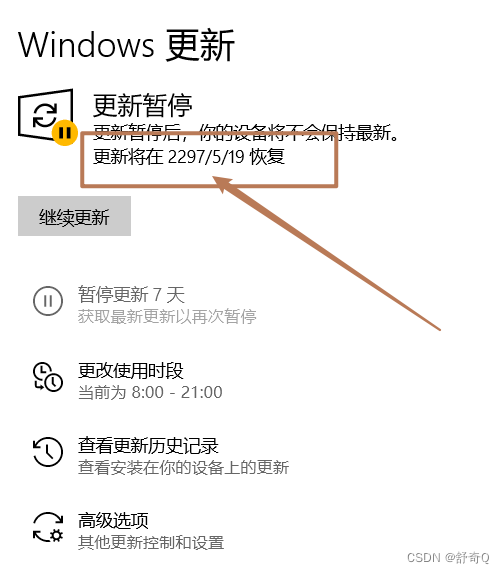
windows永久暂停更新
目录 1.winr,输入regedit打开注册表 2.打开注册表的这个路径: 计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings 右键空白地方新建QWORD值命名为:FlightSettingsMaxPauseDays 3.双击FlightSettingsMaxPauseDays,修改里面的值为100000,右边基数设置…...
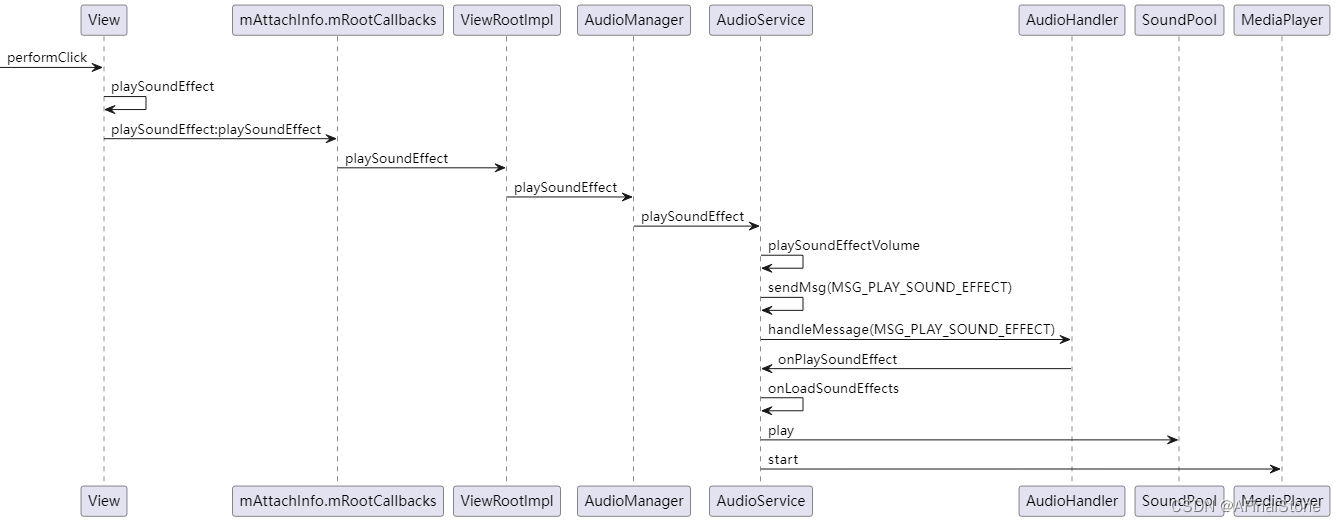
Android 9系统源码_音频管理(一)按键音效源码解析
前言 当用户点击Android智能设备的按钮的时候,如果伴随有按键音效的话,会给用户更好的交互体验。本期我们将会结合Android系统源码来具体分析一下控件是如何发出按键音效的。 一、系统加载按键音效资源 1、在TV版的Android智能设备中,我们…...

PyTorch搭建神经网络
PyTorch版本:1.12.1PyTorch官方文档PyTorch中文文档 PyTorch中搭建并训练一个神经网络分为以下几步: 定义神经网络定义损失函数以及优化器训练:反向传播、梯度下降 下面以LeNet-5为例,搭建一个卷积神经网络用于手写数字识别。 …...

TiDB 优雅关闭
背景 今天使用tiup做实验的事后,将tidb节点从2个缩到1个,发现tiup返回成功但是tidb-server进程还在。 这就引发的我的好奇心,why? 实验复现 启动集群 #( 07/31/23 8:32下午 )( happyZBMAC-f298743e3 ):~/docker/tiup/tiproxy…...
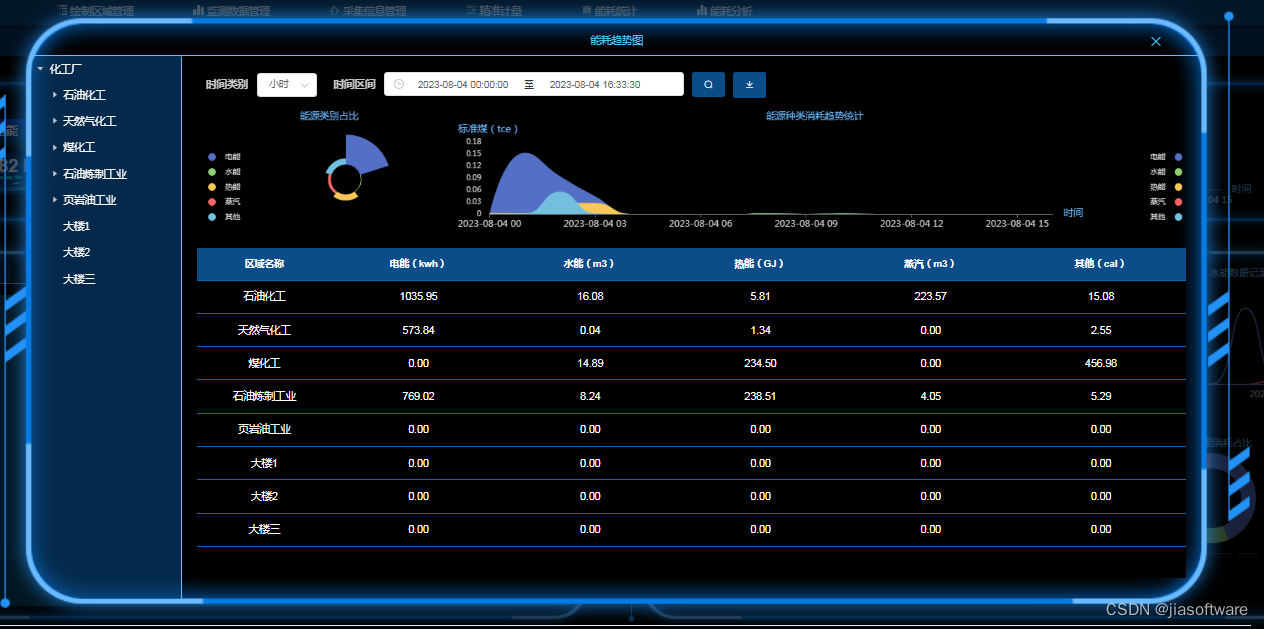
食品厂能源管理系统助力节能减排,提升可持续发展
随着全球能源问题的日益突出,食品厂作为能源消耗较大的行业,如何有效管理和利用能源成为了一项重要任务。引入食品厂能源管理系统可以帮助企业实现节能减排,提高能源利用效率,同时也符合可持续发展的理念。 食品厂能源管理系统的…...

ABAP读取文本函数效率优化,read_text --->zread_text
FUNCTION zread_text. *“---------------------------------------------------------------------- "“本地接口: *” IMPORTING *” VALUE(CLIENT) LIKE SY-MANDT DEFAULT SY-MANDT *" VALUE(ID) LIKE THEAD-TDID *" VALUE(LANGUAGE) LIKE THEAD-…...

Spring Data Repository 使用详解
8.1. 核心概念 Spring Data repository 抽象的中心接口是 Repository。它把要管理的 domain 类以及 domain 类的ID类型作为泛型参数。这个接口主要是作为一个标记接口,用来捕捉工作中的类型,并帮助你发现扩展这个接口的接口。 CrudRepository 和 ListCr…...
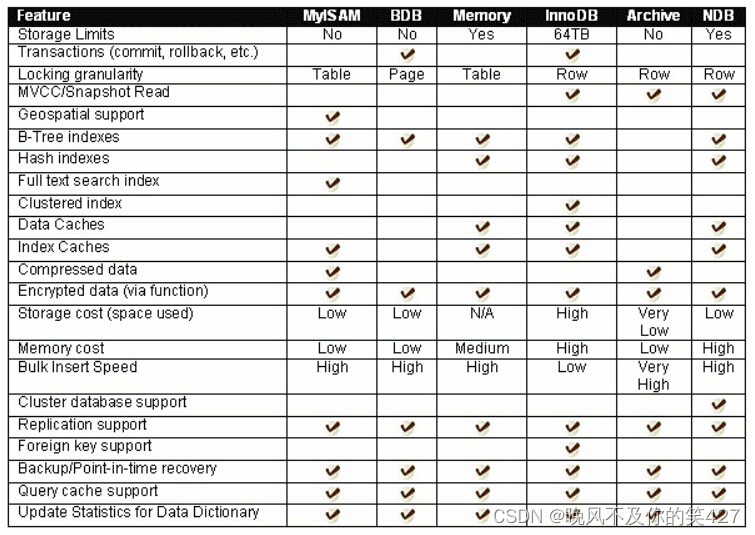
[ MySQL ] — 数据库环境安装、概念和基本使用
目录 安装MySQL 获取mysql官⽅yum源 安装mysql yum 源 安装mysql服务 启动服务 登录 方法1:获取临时root密码 方法2:无密码 方法3:跳过密码认证 配置my.cnf 卸载环境 设置开机启动(可以不设) 常见问题 安装遇到秘钥过期的问题&…...

Apache Thrift C++库的TThreadPoolServer模式的完整示例
1. 本程序功能 1) 要有完整的request 和 response; 2) 支持多进程并行处理任务; 3)子进程任务结束后无僵尸进程 2.Apache Thrift C++库的编译和安装 见 步步详解:Apache Thrift C++库从编译到工作模式DEMO_北雨南萍的博客-CSDN博客 3.框架生成 数据字段定义: cat D…...
图解java.util.concurrent并发包源码系列——深入理解ReentrantLock,看完可以吊打面试官
图解java.util.concurrent并发包源码系列——深入理解ReentrantLock,看完可以吊打面试官 ReentrantLock是什么,有什么作用ReentrantLock的使用ReentrantLock源码解析ReentrantLock#lock方法FairSync#tryAcquire方法NonfairSync#tryAcquire方法 Reentrant…...
【计算机网络】网络基础(上)
文章目录 1. 网络发展认识协议 2.网络协议初识协议分层OSI七层模型 | TCP/IP网络传输基本流程情况1:同一个局域网(子网)数据在两台通信机器中如何流转协议报头的理解局域网通信原理(故事版本)一般原理数据碰撞结论 情况2:跨一个路由器的两个子网IP地址与…...
51单片机(普中HC6800-EM3 V3.0)实验例程软件分析 实验四 蜂鸣器
目录 前言 一、原理图及知识点介绍 1.1、蜂鸣器原理图: 二、代码分析 前言 第一个实验:51单片机(普中HC6800-EM3 V3.0)实验例程软件分析 实验一 点亮第一个LED_ManGo CHEN的博客-CSDN博客 第二个实验:51单片机(普中HC6800-EM…...

无向图-已知根节点求高度
深搜板子题,无向图,加边加两个,dfs输入两个参数变量,一个是当前深搜节点,另一个是父节点(避免重复搜索父节点),恢复现场 ///首先完成数组模拟邻接表#include<iostream> #incl…...
)
RIP动态路由协议 (已过时,逐渐退出舞台)
RIP 路由更新:RIP1/2 每30秒钟广播(255.255.255.255)/组播 (224.0.0.9)一次超时:180秒未收到更新,即标记为不可用(跳数16),240秒收不到,即从路由表中删除 ;跳…...

快速验证域名跳转思路:用快马十分钟搭建jxx登录页检测工具原型
快速验证域名跳转思路:用快马十分钟搭建jxx登录页检测工具原型 最近注意到"jxx登录网页最新域名在哪"这个关键词搜索量突然增加,很多用户都在寻找特定网站的访问入口。这种需求其实很常见——当某个服务频繁更换域名时,普通用户很…...

ModTheSpire技术全解析:从模组加载到高级开发指南
ModTheSpire技术全解析:从模组加载到高级开发指南 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 引言:为何需要模组加载器? 当你在《Slay The Spi…...

小白友好:Neeshck-Z-lmage_LYX_v2部署教程,详解显卡驱动兼容性与CUDA锁定
小白友好:Neeshck-Z-lmage_LYX_v2部署教程,详解显卡驱动兼容性与CUDA锁定 1. 工具简介:为什么选择它? 想体验一款功能强大、操作简单的国产文生图工具,却总在环境配置这一步卡住?特别是显卡驱动和CUDA版本…...

seo高级优化如何利用社交媒体_seo高级优化如何进行技术优化
SEO高级优化如何利用社交媒体 在当前的数字营销环境中,搜索引擎优化(SEO)已经不再是一个简单的任务,它已经演变成了一个复杂而多层次的过程。SEO高级优化不仅仅涉及内容创作,还包括技术优化、用户体验以及社交媒体的有…...

用快马AI快速生成你的第一个微信小程序待办事项原型
用快马AI快速生成你的第一个微信小程序待办事项原型 最近想尝试开发一个微信小程序来管理日常任务,但作为新手,从零开始写代码确实有点无从下手。好在发现了InsCode(快马)平台,它通过AI生成代码的能力,帮我快速搭建了一个待办事项…...

FLUX.1-dev旗舰版多GPU部署:分布式推理加速方案
FLUX.1-dev旗舰版多GPU部署:分布式推理加速方案 1. 引言 想象一下,你正在处理一批高分辨率图像生成任务,单张GPU需要等待数分钟才能完成。随着任务量增加,这种等待变得难以忍受。这就是为什么我们需要多GPU部署方案——将计算负…...

glb/gltf格式模型怎么在线修改坐标轴位置中心
哈哈 ,发现一个好方法,关键还是免费的,可以在线修改坐标轴位置中心 为什么要修改物体坐标轴啊,因为有时候加载到平台时候,物体在天上飘着,要不然在地下 1:咱们先打开bj.glbxz.com&…...

软件PWM库原理与工程实践:轻量级非阻塞式脉宽调制实现
1. PWM库技术解析:面向嵌入式工程师的底层实现与工程化应用1.1 库定位与核心价值PWM(Pulse Width Modulation)库是一个轻量级、非阻塞式脉宽调制信号生成工具,专为资源受限的微控制器平台设计。其核心价值不在于替代硬件PWM外设&a…...

Qt【第七篇】 ——— QSS 样式表与绘图 API 核心用法及 UI 定制功能总结
目录 QSS widget.cpp(QSS的基本使用) widget.cpp(QSS选择器的用法) widget.cpp(QSS子控件选择器) widget.cpp(QSS伪类选择器) widget.cpp(QSS盒子模型) QSS 基…...

FinalBurn Neo终极指南:如何打造完美的复古游戏体验
FinalBurn Neo终极指南:如何打造完美的复古游戏体验 【免费下载链接】FBNeo FinalBurn Neo - We are Team FBNeo. 项目地址: https://gitcode.com/gh_mirrors/fb/FBNeo FinalBurn Neo(简称FBNeo)是一款开源街机游戏模拟器,…...