PyTorch搭建神经网络
- PyTorch版本:1.12.1
- PyTorch官方文档
- PyTorch中文文档
PyTorch中搭建并训练一个神经网络分为以下几步:
- 定义神经网络
- 定义损失函数以及优化器
- 训练:反向传播、梯度下降
下面以LeNet-5为例,搭建一个卷积神经网络用于手写数字识别。
1. 模型简介——LeNet-5
LeNet-5是一个经典的深度卷积神经网络,由Yann LeCun在1998年提出用于解决手写数字识别问题。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一,被认为是卷积神经网络的起源之一。
如下图所示,LeNet-5的结构是一个7层的卷积神经网络(不含输入层),其中包括2个卷积层、2个下采样层(池化层)、2个全连接层以及输出层。

1.1 输入层(Input layer)
输入层接收大小为 32*32 的灰度手写数字图像,像素灰度值范围为0-255。为了加快训练速度以及提高模型准确性,通常会对输入图像的像素值进行归一化。
1.2卷积层C1(Convolutional layer C1)
卷积层C1含有6个卷积核,每个卷积核的大小为 5*5 ,步长为1,填充为0。卷积层C1产生6个大小为 28*28 的特征图。
1.3 下采样层S2(Subsampling layer S2)
采样层S2采用最大池化(max-pooling)操作,这可以减少特征图的大小从而提高计算效率,并且池化操作对于轻微的位置变化可以保持一定的不变性。池化层每个窗口的大小为 2*2 ,步长为2。池化层S2产生6个大小为 14*14 的特征图。
1.4 卷积层C3(Convolutional layer C3)
卷积层C3包括16个卷积核,每个卷积核的大小为 5*5 ,步长为1,填充为0。卷积层C1产生16个大小为 10*10的特征图。
1.5 下采样层S4(Subsampling layer S4)
下采样层S4采用最大池化操作,每个窗口的大小为 2*2 ,步长为2。池化层S4产生16个大小为 5*5 的特征图。
1.6 全连接层C5(Fully connected layer C5)
C5将16个大小为 5*5 的特征图拉成一个长度为400的向量,并通过一个包括120个神经元的全连接层。120是由LeNet-5的设计者根据实验得到的最佳值。
1.7 全连接层F6(Fully connected layer F6)
全连接层F6将120个神经元连接到84个神经元。
1.8 输出层(Output layer)
输出层由10个神经元组成,每个神经元对应0-9的激活值(激活值越大,是该数字的可能性越大)。模型训练时,使用交叉熵损失函数计算输出层与样本真实标签之间的误差,然后通过反向传播算法更新模型的参数(包括卷积核和全连接层)直至模型达到指定效果或者达到指定迭代次数。
在实际应用中,通常会对LeNet-5进行一些改进,例如增加网络深度、增加卷积核数量、添加正则化等方法,以进一步提高模型的准确性和泛化能力。
2. 数据集简介——MNIST
MNIST是一个手写体数字的图片数据集,包含60,000个训练图像和10,000个测试图像,由美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。数据集中的图像都是灰度图像,大小为 28*28 像素,每个像素点的值为 0 到 255 之间的灰度值。
使用torchvision中的datasets可自动下载该数据集:
train_dataset = torchvision.datasets.MNIST(root="data/", train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.MNIST(root="data/", train=False, transform=transforms.ToTensor(), download=True)
其中:
-
root表示将数据集存放在当前目录下的’data’文件夹中。
-
train=True表示导入的是训练数据;train=False表示导入的是测试数据。
-
transform表示对每个数据进行的变化,这里是将其变为Tensor,Tensor是PyTorch中存储数据的主要格式。
-
download表示是否将数据下载到本地。
3. 定义神经网络
PyTorch中主要有以下两种方式定义神经网络
3.1 使用前馈神经网络方式
这种方法需要继承torch.nn.Module并且实现__init__()和forward()这两个方法。其中__init__()可以用于做一些初始化工作,比如定义输入数据、隐藏层、激活函数等;forward()是实现前向传播的核心函数,用于定义神经网络的结构和参数,在前向传播的过程中,输入的数据将按照该函数定义的神经网络结构进行计算并得到最终的输出。
import torch.nn.functional as F
from torch import nnclass MyCNN(nn.Module):def __init__(self, in_channels):super(MyCNN, self).__init__()self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5, stride=1) # 定义卷积核self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 定义最大池化层self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = nn.Linear(in_features=16 * 4 * 4, out_features=120) # 定义全连接层self.fc2 = nn.Linear(in_features=120, out_features=84)self.fc3 = nn.Linear(in_features=84, out_features=10)def forward(self, x):x1 = self.conv1(x) # 卷积层C1x2 = F.relu(x1) # 激活函数x3 = self.pool1(x2) # 下采样层S2x4 = self.conv2(x3) # 卷积层C3x5 = F.relu(x4)x6 = self.pool2(x5) # 下采样层S4x7 = x.reshape(x6.shape[0], -1) # 二维变成一维,以输入到全连接层x8 = self.fc1(x7) # 全连接层C5x9 = F.relu(x8)x10 = self.fc2(x9) # 全连接层F6x11 = F.relu(x10)x12 = self.fc3(x11) # 输出层return x12
代码解释
-
__init__():
定义了用到的卷积核、池化层以及全连接层,其中:
- nn.Conv2d,定义二维卷积核。in_channels,输入通道数量;out_channels,输出通道数量;kernel_size,卷积核大小;stride,卷积时的步长。
- nn.MaxPool2d,定义二维最大池化层。kernel_size,池化的窗口大小;stride,池化时的步长。
- nn.Linear,定义全连接层。in_features,输入数据的大小;out_features,输出数据的大小。
-
forward():
__init__()函数中仅仅是定义了各个层,但并未将它们连接起来搭建出一个神经网络,forward()函数的作用就是搭建一个神经网络,使得输入的数据沿着指定的结构进行前向传播:
- forward除了self之外,还接收一个参数x作为输入数据。
- x = self.conv1(x):输入的x经过卷积计算后得到x1,对应于卷积层C1。
- x2 = F.relu(x1) :对卷积后的数据进行ReLU激活操作。
- x3 = self.pool1(x2) :对数据进行池化,对应于下采样层S2。
- ……
- 与上面类似,数据依次经过卷积层C3、下采样层S4、全连接层C5、全连接层F6以及输出层,从而使输入x沿着指定的路径得到最终的输出。
注:
-
为了更好的展示数据如何沿着神经网络进行前向传播,这里对每一层的输出设置了不同的变量命名,实际应用时,可以将x1~x12都写作x,只要不影响前向传播即可。
-
二维卷积以及池化操作得到的是二维的特则图,但全连接层需要一维的数据,因此需要对数据尺寸进行修改,即:
x7 = x.reshape(x6.shape[0], -1)
3.2 使用序列化方法
这种方式使用torch.nn.Sequential方式定义模型,将神经网络以序列的方式进行连接,每个层使用前面层计算的输出作为输入,并且在内部会维护层与层之间的权重矩阵和偏置向量。
from torch import nnin_channels = 1
model = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5, stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(in_features=16 * 4 * 4, out_features=120),nn.Linear(in_features=120, out_features=84),nn.Linear(in_features=84, out_features=10)
)
3.3总结
- 第一种可以更好的根据需要搭建网络结构;
- 第二种方式网络以序列的方式搭建网络,不适用于复杂网络;
- 对于一些复杂的含有重复层的网络,可将两种方式结合使用。序列化方法定义重复层,然后使用第一种方式根据网络结构进行组装。
4. 定义损失函数以及优化器
-
损失函数
损失函数用于计算真实值和预测值之间的差异。在PyTorch官方文档中,给出了可用的损失函数列表。
这里,我们使用交叉熵损失函数torch.nn.CrossEntropyLoss()。该损失函数内部自动加上了Softmax,用于解决多分类问题,也可用于解决二分类问题。
-
优化器
优化器根据损失函数求出的损失,对神经网络的参数进行更新。在PyTorch官方文档中,给出了可用的优化器。
这里,我们使用**torch.optim.Adam()**作为我们的优化器。
from torch import nn, optimcriterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.Adam(model.parameters()) # 优化器
其中:
- model.parameters()是待优化的参数。
5.训练模型
模型的训练主要包括3部分:
- 前向传播
- 反向传播
- 梯度下降
简单的说就是取出数据,放到模型里面跑一次得到预测值,计算与真实值之间的损失,然后计算梯度,根据梯度更新一次网络。
代码实现如下:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MyCNN(1).to(device) # 加载模型到设备num_epochs = 100
for epoch in range(num_epochs):for batch_idx, (data, label) in enumerate(train_loader):data = data.to(device=device) # 加载数据到设备label = label.to(device=device)# 前向传播pre = model(data)loss = criterion(pre, label)# 反向传播optimizer.zero_grad()loss.backward()# 梯度下降optimizer.step()
其中:
-
torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’):选择使用GPU或者CPU训练,若电脑有GPU且配置正确,则使用GPU训练,否则使用CPU训练(模型和数据必须都放在GPU或者CPU上)。
-
for epoch in range(num_epochs):模型训练次数。
-
for batch_idx, (data, label) in enumerate(train_loader):mini-batch对数据进行小批量训练。
-
前向传播:
- pre = model(data):将数据放入模型中训练。
- loss = criterion(pre, label):通过损失函数得到本次训练的损失。
-
反向传播:
- optimizer.zero_grad():将梯度归零。训练时通常使用mini-batch方法,如果不将梯度清零的话,梯度会与上一个batch的梯度相关,因此该函数要写在反向传播和梯度下降之前。
- loss.backward():反向传播。计算得到每个参数的梯度。
-
梯度下降
optimizer.step():执行一次优化步骤,对参数进行更新。注意:optimizer.step()只负责通过梯度下降对参数进行优化,并不负责产生梯度,梯度是loss.backward()方法产生的。
6. 测试模型
模型训练完毕后,可以使用测试集对模型进行测试:
loss = 0with torch.no_grad(): # 关闭梯度计算model.eval() # 评估模式for batch_idx, (data, label) in enumerate(test_loader):data = data.to(device=device)label = label.to(device=device)pre = model(data)loss += criterion(pre, label).item()model.train() # 训练模式
loss = loss / len(test_loader.dataset)
其中:
-
with torch.no_grad():关闭梯度计算。在训练模型时,需要计算根据反向传播计算梯度以更新参数,但在对验证集或者测试集进行预测时,并不需要更新参数,因此也就不需要计算梯度。因此,为了避免浪费计算资源,在模型评估时最后关闭梯度计算。
-
model.eval():将模型切换到评估模式。在神经网络中,出于防止过拟合等目的,一般会加入Dropout和Batch Normalization层,在模型训练阶段,根据输入数据的变化,这些层的参数也会发生变化。在评估模式下,Dropout层会让所有的网络节点都生效,而Batch Normalization层会停止计算和更新均值和方差,直接使用在训练阶段已经学出的均值和方差。
-
model.train():将模型切换到训练模式。此时Dropout层使网络中的节点以一定概率失效,Batch Normalization层根据输入的数据更新均值和方差。在将模型切换到评估模式之后,在下一次训练之前必须再切换到训练模式。
-
注意with torch.no_grad()和model.eval()的区别:
with torch.no_grad()关闭的是梯度计算,和神经网络整体有关;而model.eval()和梯度没有关系,只和Dropout和Batch Normalization这两层有关系。
7. 整体代码
以下是最终的代码(使用前馈神经网络的方式定义神经网络)。由于这里仅仅是为了介绍如何搭建一个模型,另外出于篇幅考虑,对于一些细节方面未做具体改进,主要包括以下几点:
- 除了训练集和测试集之外,还可以使用验证集评估模型性能以设置早停
- 为了得到更好的模型性能,一般会对数据进行归一化
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torch import optim
from torch.utils.data import DataLoader
from torchvision import transformsclass MyCNN(nn.Module):def __init__(self, in_channels):super(MyCNN, self).__init__()self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5, stride=1) # 定义卷积核self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 定义最大池化层self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = nn.Linear(in_features=16 * 4 * 4, out_features=120) # 定义全连接层self.fc2 = nn.Linear(in_features=120, out_features=84)self.fc3 = nn.Linear(in_features=84, out_features=10)def forward(self, x):x = self.conv1(x) # 卷积层C1x = F.relu(x) # 激活函数x = self.pool1(x) # 下采样层S2x = self.conv2(x) # 卷积层C3x = F.relu(x)x = self.pool2(x) # 下采样层S4x = x.reshape(x.shape[0], -1) # 二维变成一维,以输入到全连接层x = self.fc1(x) # 全连接层C5x = F.relu(x)x = self.fc2(x) # 全连接层F6x = F.relu(x)x = self.fc3(x) # 输出层return xdef train(model, criterion, optimizer, train_loader, device, num_epochs=200):for epoch in range(num_epochs):for batch_idx, (data, label) in enumerate(train_loader):data = data.to(device=device) # 加载数据到设备label = label.to(device=device)# 前向传播pre = model(data)loss = criterion(pre, label)# 反向传播optimizer.zero_grad()loss.backward()# 梯度下降optimizer.step()def test(model, criterion, test_loader, device):loss = 0with torch.no_grad(): # 关闭梯度计算model.eval() # 评估模式for batch_idx, (data, label) in enumerate(test_loader):data = data.to(device=device)label = label.to(device=device)pre = model(data)loss += criterion(pre, label).item()model.train() # 训练模式loss = loss / len(test_loader.dataset)return lossdef main():batch_size = 4num_epochs = 200train_dataset = torchvision.datasets.MNIST(root="data/", train=True, transform=transforms.ToTensor(),download=True) # 下载数据集test_dataset = torchvision.datasets.MNIST(root="data/", train=False, transform=transforms.ToTensor(), download=True)train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size,shuffle=True) # 将数据集(Dataset)自动分成一个个的Batch,以用于批处理test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 选择加载数据的设备,GPU或者CPUmodel = MyCNN(1).to(device) # 模型和数据应加载到同一种设备上criterion = nn.CrossEntropyLoss() # 损失函数optimizer = optim.Adam(model.parameters()) # 优化器train(model, criterion, optimizer, train_loader, device, num_epochs)print(test(model, criterion, test_loader, device))if __name__ == '__main__':main()相关文章:
PyTorch搭建神经网络
PyTorch版本:1.12.1PyTorch官方文档PyTorch中文文档 PyTorch中搭建并训练一个神经网络分为以下几步: 定义神经网络定义损失函数以及优化器训练:反向传播、梯度下降 下面以LeNet-5为例,搭建一个卷积神经网络用于手写数字识别。 …...

TiDB 优雅关闭
背景 今天使用tiup做实验的事后,将tidb节点从2个缩到1个,发现tiup返回成功但是tidb-server进程还在。 这就引发的我的好奇心,why? 实验复现 启动集群 #( 07/31/23 8:32下午 )( happyZBMAC-f298743e3 ):~/docker/tiup/tiproxy…...
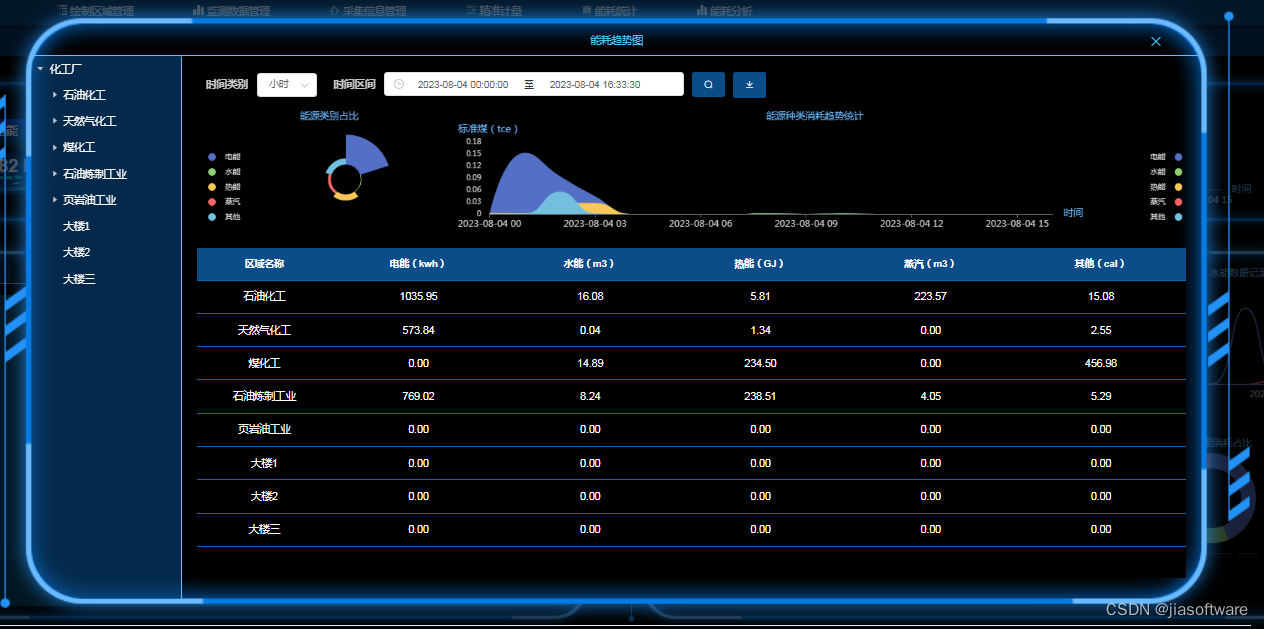
食品厂能源管理系统助力节能减排,提升可持续发展
随着全球能源问题的日益突出,食品厂作为能源消耗较大的行业,如何有效管理和利用能源成为了一项重要任务。引入食品厂能源管理系统可以帮助企业实现节能减排,提高能源利用效率,同时也符合可持续发展的理念。 食品厂能源管理系统的…...

ABAP读取文本函数效率优化,read_text --->zread_text
FUNCTION zread_text. *“---------------------------------------------------------------------- "“本地接口: *” IMPORTING *” VALUE(CLIENT) LIKE SY-MANDT DEFAULT SY-MANDT *" VALUE(ID) LIKE THEAD-TDID *" VALUE(LANGUAGE) LIKE THEAD-…...

Spring Data Repository 使用详解
8.1. 核心概念 Spring Data repository 抽象的中心接口是 Repository。它把要管理的 domain 类以及 domain 类的ID类型作为泛型参数。这个接口主要是作为一个标记接口,用来捕捉工作中的类型,并帮助你发现扩展这个接口的接口。 CrudRepository 和 ListCr…...
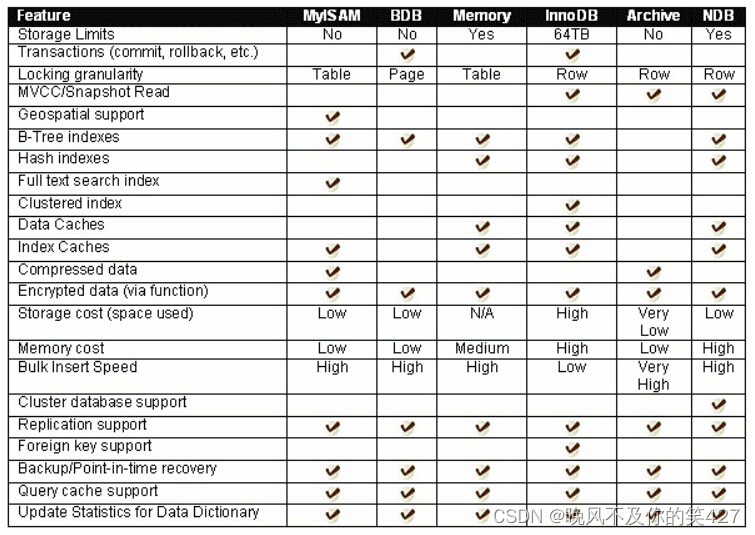
[ MySQL ] — 数据库环境安装、概念和基本使用
目录 安装MySQL 获取mysql官⽅yum源 安装mysql yum 源 安装mysql服务 启动服务 登录 方法1:获取临时root密码 方法2:无密码 方法3:跳过密码认证 配置my.cnf 卸载环境 设置开机启动(可以不设) 常见问题 安装遇到秘钥过期的问题&…...

Apache Thrift C++库的TThreadPoolServer模式的完整示例
1. 本程序功能 1) 要有完整的request 和 response; 2) 支持多进程并行处理任务; 3)子进程任务结束后无僵尸进程 2.Apache Thrift C++库的编译和安装 见 步步详解:Apache Thrift C++库从编译到工作模式DEMO_北雨南萍的博客-CSDN博客 3.框架生成 数据字段定义: cat D…...
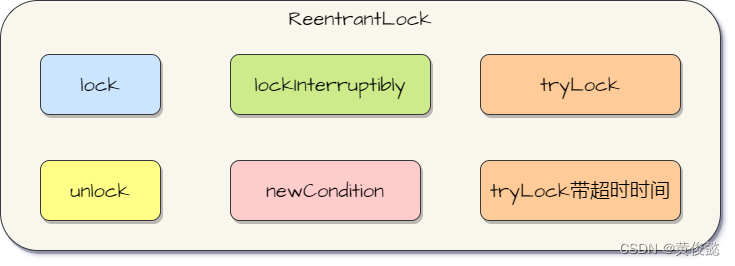
图解java.util.concurrent并发包源码系列——深入理解ReentrantLock,看完可以吊打面试官
图解java.util.concurrent并发包源码系列——深入理解ReentrantLock,看完可以吊打面试官 ReentrantLock是什么,有什么作用ReentrantLock的使用ReentrantLock源码解析ReentrantLock#lock方法FairSync#tryAcquire方法NonfairSync#tryAcquire方法 Reentrant…...
【计算机网络】网络基础(上)
文章目录 1. 网络发展认识协议 2.网络协议初识协议分层OSI七层模型 | TCP/IP网络传输基本流程情况1:同一个局域网(子网)数据在两台通信机器中如何流转协议报头的理解局域网通信原理(故事版本)一般原理数据碰撞结论 情况2:跨一个路由器的两个子网IP地址与…...
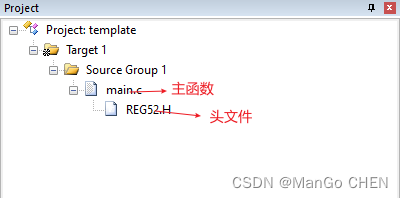
51单片机(普中HC6800-EM3 V3.0)实验例程软件分析 实验四 蜂鸣器
目录 前言 一、原理图及知识点介绍 1.1、蜂鸣器原理图: 二、代码分析 前言 第一个实验:51单片机(普中HC6800-EM3 V3.0)实验例程软件分析 实验一 点亮第一个LED_ManGo CHEN的博客-CSDN博客 第二个实验:51单片机(普中HC6800-EM…...

无向图-已知根节点求高度
深搜板子题,无向图,加边加两个,dfs输入两个参数变量,一个是当前深搜节点,另一个是父节点(避免重复搜索父节点),恢复现场 ///首先完成数组模拟邻接表#include<iostream> #incl…...
)
RIP动态路由协议 (已过时,逐渐退出舞台)
RIP 路由更新:RIP1/2 每30秒钟广播(255.255.255.255)/组播 (224.0.0.9)一次超时:180秒未收到更新,即标记为不可用(跳数16),240秒收不到,即从路由表中删除 ;跳…...
)
C++ operator关键字的使用(重载运算符、仿函数、类型转换操作符)
目录 定义operator重载运算符operator重载函数调用运算符operator类型转换操作符 定义 C11 中,operator 是一个关键字,用于重载运算符。通过重载运算符,您可以定义自定义类型的对象在使用内置运算符时的行为。 operator重载用法一般可以分为…...
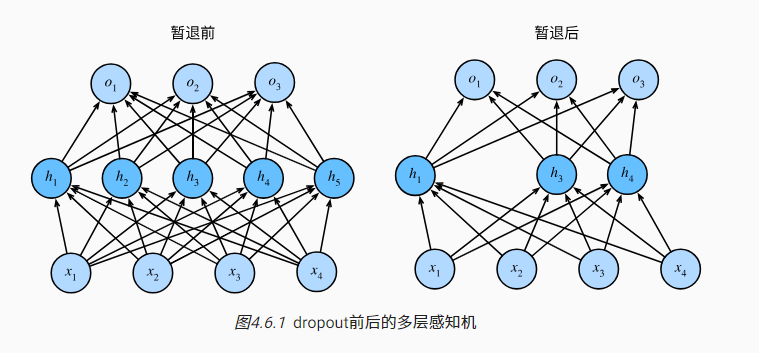
深度学习笔记-暂退法(Drop out)
背景 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预…...

使用自适应去噪在线顺序极限学习机预测飞机发动机剩余使用寿命(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
实验5-7 使用函数求1到10的阶乘和 (10 分)
实验5-7 使用函数求1到10的阶乘和 (10 分) 本题要求实现一个计算非负整数阶乘的简单函数,使得可以利用该函数,计算1!2!⋯10!的值。 函数接口定义: double fact( int n ); 其中n是用户传入的参数,其值不超过…...
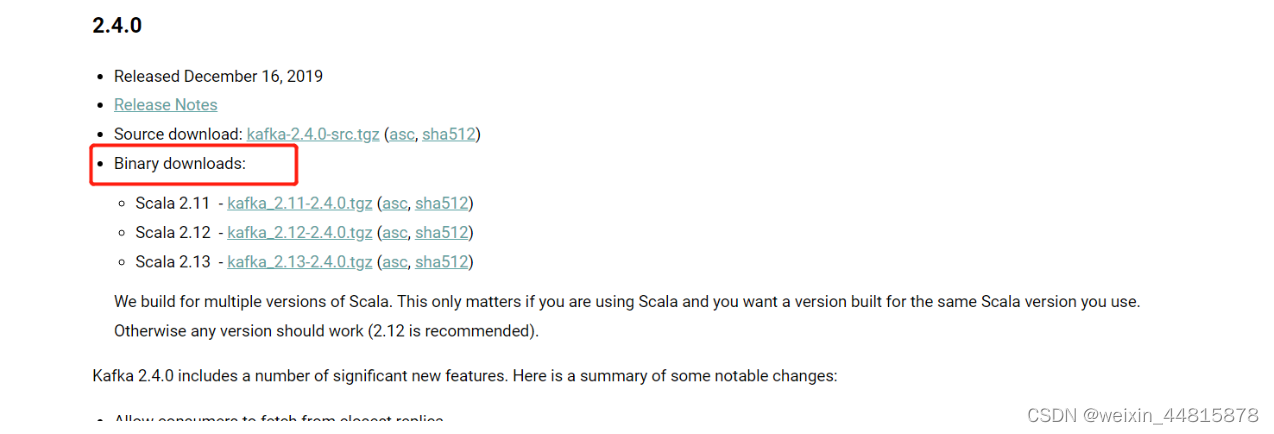
kafka部署
1.kafka安装部署 1.1 kafaka下载 https://archive.apache.org/dist/kafka/2.4.0/kafka_2.12-2.4.0.tgz Binary downloads是指预编译的软件包,可供直接下载和安装,无需手动编译。在计算机领域中,二进制下载通常指预构建的软件分发包,可以直接安装在系统上并使用 "2.…...

Spring Security6入门及自定义登录
一、前言 Spring Security已经更新到了6.x,通过本专栏记录以下Spring Security6学习过程,当然大家可参考Spring Security5专栏对比学习 Spring Security5专栏地址:security5 Spring Security是spring家族产品中的一个安全框架,核心功能包括…...

开放式蓝牙耳机哪个品牌好用?盘点几款很不错的开放式耳机
相比传统入耳式耳机,开放式耳机因其不入耳不伤耳的开放设计,不仅带来了舒适的佩戴体验,还创造了一种与周围环境互动的全新方式,户外运动过程时也无需担心发生事故,安全性更高。我整理了几款比较好用的开放式耳机给大…...
WebGL: 几个入门小例子
本文罗列几个WebGL入门例子,用于帮助WebGL学习。 一、概述 WebGL (Web Graphics Library)是一组基于Open ES、在Web内渲染3D图形的Javascript APIs。 Ref. from Khronos Group: WebGL WebGL™ is a cross-platform, royalty-free open web standard for a low-lev…...

5分钟搞定B站缓存视频:m4s转MP4完整解决方案
5分钟搞定B站缓存视频:m4s转MP4完整解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过B站缓存视频无法在其他设备…...

从芯片手册到稳定波形:深入解读74LS161的异步清零与同步计数,搞定数字钟六十进制
从芯片手册到稳定波形:深入解读74LS161的异步清零与同步计数,搞定数字钟六十进制 在数字电路设计中,计数器芯片74LS161的应用无处不在,从简单的分频器到复杂的数字钟系统都能见到它的身影。但真正深入理解这颗经典芯片内部工作机…...

零代码自动化:OpenClaw+Qwen3.5-9B处理Excel数据透视表
零代码自动化:OpenClawQwen3.5-9B处理Excel数据透视表 1. 为什么需要零代码Excel自动化 作为经常与数据打交道的分析师,我每周都要重复处理类似的Excel报表:数据清洗、透视分析、生成图表。这些操作虽然简单,但耗时且容易出错。…...

【VBA】【EXCEL】工作日_节假日
Option Explicit 函数一:计算两个日期之间的工作日天数用法:CalcWorkDays(开始日期, 结束日期)示例:CalcWorkDays(A1,B1)Function CalcWorkDays(startDate As Date, endDate As Date) As LongDim i As DateDim workCount As LongDim isHolida…...

三天踩坑实录:用Pyinstaller打包PaddleOCR+PyQt5桌面应用,我总结的这份spec文件配置清单请收好
从崩溃到优雅:PaddleOCRPyQt5打包终极配置指南 打包PaddleOCR和PyQt5组合的桌面应用,就像在迷宫中寻找出口——每个转角都可能遇到新的障碍。经过72小时的反复试错和数十次失败构建后,我终于整理出一套稳定可靠的spec文件配置方案。这份指南不…...

扶摇速记:眼前流水,曲折前向
英语单词 went,意为【走】或走【去】,它是动词 go 的过去式。 went v. (go过去式) 去,走 我们可以这样去理解,其中 -t,表动词,是构词语法形式,含义主要来自wen-,而went 或 wen-的首字…...

Free RTOS:任务状态,任务管理与调度理论
目录 1.任务状态 1.1 FreeRTOS的任务状态: 1.2 阻塞状态(Blocked) 1.3 暂停状态(Suspended) 原型如下: 1.4 就绪状态(Ready) 1.5 完整的状态转换图 1.6 代码 2.任务管理与调度理论 2.1 调度 2.2 FreeRTOS调度 STM32CubeMX FreeRTOS源码 代…...

html 列表和表格的使用
1:列表是以结构化,易读性更强的方式提供信息的方法,我们学习了有序列表和无序列表。有序列表特点是有先后顺序,用数字,字母或数字标记,适合步骤,排名,流程,核心标签<o…...

SAP ABAP老系统也能玩转REST API?手把手教你用SICF和IF_HTTP_EXTENSION打通接口
SAP ABAP老系统也能玩转REST API?手把手教你用SICF和IF_HTTP_EXTENSION打通接口 在数字化转型浪潮中,许多企业仍运行着历史悠久的SAP ABAP系统。这些系统承载着核心业务逻辑,却常因技术栈陈旧而难以与现代应用生态对接。本文将揭示如何利用AB…...

千问3.5-9B多模态扩展:OpenClaw处理图片与文本混合任务
千问3.5-9B多模态扩展:OpenClaw处理图片与文本混合任务 1. 为什么需要本地多模态自动化 去年夏天,我电脑里堆积了上千张混杂着文字说明的截图——有技术文档片段、会议纪要、临时灵感记录。手动整理这些内容时,我突然意识到:如果…...