C++ - 模板分离编译
模板分离编译
我们先来看一个问题,我们用 stack 容器的声明定义分离的例子来引出这个问题:
// stack.h
// stack.h
#pragma once
#include<deque>namespace My_stack
{template<class T, class Container = std::deque<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back ();}T top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};
}现有如上这个stack 类,我们把 push ()函数 和 pop()函数声明定义分离,如下所示:
// stack.cpp
#include"stack.h"namespace My_stack
{template<class T, class Container>void stack<T, Container>::push(const T& x){_con.push_back(x);}template<class T, class Container>void stack<T, Container>::pop(){_con.pop_back();}
}看似上述的分离是没有问题,但是,当我们编译的时候就报错了:

上述报了一些 link 链接错误,这时候我们就很疑惑,反复查看声明和定义的链接关系,也看不出问题。
我们调用 size ()这些没有进行声明定义分离的函数是没有 问题,问题就出在,我们什么定义分离的 push()和 pop()。
我们在简单定义一个 A 类来对比:
// stack.hnamespace My_stack
{class A{public:void fun1();void fun2();};
}// stack.cppnamespace My_stack
{void func1() // 定义了{}// 未定义// void func2()
}在从源文件生成 可执行文件,有以下几步:

上述的 push()函数 和 func2 ()函数都编译通过了,因为声明只是一个承诺,编译器在编译的时候,只会看函数有没有声明,如果这个函数有定义,那么就会去看这个函数的定义是否和声明一致,一致那么就编译通过了;没有定义有声明也是可以编译通过的。
但是在最后链接的时候:
- fun1()函数有声明和定义,成功链接上了;
- 而func2()有声明但是没有定义,所以没有连接上(这是正常的);
- 但是此时的问题是 push()函数有声明和定义,但是却链接失败了。
简单形容就是,我想买手机像func1()这个朋友借钱,它有声明,也就给我承诺了借我1000元,在最后买手机的时候,func1()也借给了我1000元。
而 func2()就是有声明,承诺给我500元,但是在买手机那一天,他却说它家里面有事,有需要用钱就没借我钱。
最后是 push()他也有声明,也承诺借钱给我,买手机那一天也确实向银行转了钱,但是我却没有收到。
最后push()的问题不是出在 我 和 push()身上,而是出在银行身上。
所以,现在你应该明白这个问题出来哪一个身上了,没错就是 编译器的问题。
问题就出在编译的时候,因为地址是存在编译生成的 .s 文件当中,而在声明当中给的模版参数是 T,编译器在编译的时候不知道 这个 T 是什么类型,没错,就是出在了没有实例化上面。编译器都不知道实例化出的 T 的类型是什么,就无法生成这个函数的地址。
func1()可以生成地址是因为 func1()不是模版函数,而push()是模版参数,只有实例化之后才能生成地址。
解决方式
第一种是显示实例化:
namespace My_stack
{template<class T, class Container>void stack<T, Container>::push(const T& x){_con.push_back(x);}template<class T, class Container>void stack<T, Container>::pop(){_con.pop_back();}templateclass stack<int>;
}这里的 template 是语法规定,告诉编译器这里是 显示实例化。
但是这个方式只能适用于单个类型,如果是其他类型的模版参数就不行了。
我们反观 top()这些函数,没有进行声明定义分离的函数,之所以能找到是因为这些函数的地址不需要再下面进行寻找,编译的时候就已经找到了地址(有定义就实例化,自然就找到了地址)。
而其他函数在后面需要找是因为,push()这些函数只有声明。
所以,如果我们想要进行声明定义分离的话,模版的分离不能分在两个问题,因为把声明和定义分离在同一个文件当中(如下代码所示):
#pragma once
#include<deque>namespace My_stack
{template<class T, class Container = std::deque<T>>class stack{public:void push(const T& x);void pop();//void push(const T& x)//{// _con.push_back(x);//}//void pop()//{// _con.pop_back ();//}T top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};template<class T, class Container>void stack<T, Container>::push(const T& x){_con.push_back(x);}template<class T, class Container>void stack<T, Container>::pop(){_con.pop_back();}
}在库当中也是这样,把声明和定义,分离在同一个文件当中。
当然,为了实现像之前一样的,用 .cpp 和 .h 两个文件实现的声明和定义分离的效果,我们可以将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。推荐使用这种
这里的 .hpp 表示的意思就是 .cpp 和 .h 的合体。当然不写成 .hpp 也是可以的。
模版的优缺点
【优点】
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
- 增强了代码的灵活性
【缺陷】
- 模板会导致代码膨胀问题,也会导致编译时间变长
- 现模板编译错误时,错误信息非常凌乱,不易定位错误
相关文章:
C++ - 模板分离编译
模板分离编译 我们先来看一个问题,我们用 stack 容器的声明定义分离的例子来引出这个问题: // stack.h // stack.h #pragma once #include<deque>namespace My_stack {template<class T, class Container std::deque<T>>class stack…...
如何把非1024的采样数放入aac编码器
一. aac对数据规格要求 二、代码实现 1.初始化 2.填入数据 3.取数据 三.图解 一. aac对放入的采样数要求 我们知道aac每次接受的字节数是固定的,在之前的文章里有介绍libfdk_aac音频采样数和编码字节数注意 它支持的采样数和编码字节数分别是: fdk_aac …...

linux安装nodejs和vue
下载nodejs 打开 下载地址页面中下载**Linux Binaries (x64)**的二进制包设置安装目录 sudo mkdir -p /usr/local/lib/nodejs # 解压 如下载的 node-v18.17.0-linux-x64.tar.xz sudo tar -xJvf node-v18.17.0-linux-x64.tar.xz -C /usr/local/lib/nodejs 加入到PATH #######…...

spring整合mybatis
所需配置: <dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>m…...
Spring指定bean在哪个应用加载
1.背景 某项目,spring架构,有2个不同的WebAppApplication入口,大部分service类共用,小部分类有区别,只需要在一个应用中加载,不需要在另一个应用中加载. 2.实现代码 自定义限制注解 package mis.shared.annotation;import java.lang.annotation.ElementType; import java.lan…...

二维网格划分 LRU缓存设计
背景 有大量的二维矩形需要存储查看点在哪些矩形中给定一个矩形 查看与哪些矩阵相交项目背景与图形图像基本无关,只涉及大文件分块读取,所以不用实现游戏行业中的物理引擎 设计思路 使用空间划分算法:二维栅格将整个空间划分为多个小区域。…...

C++中使用 sizeof 确定变量的长度
C中使用 sizeof 确定变量的长度 变量长度指的是程序员声明变量时,编译器将预留多少内存,用于存储赋给该变量的数据。变量的长度随类型而异, C 提供了一个方便的运算符——sizeof,可用于确定变量的长度(单位为字节&…...

我们的衣物收纳商品政策
本政策涵盖的衣物收纳商品 衣物收纳商品是指带有抽屉或铰链门的家具商品,用于存放衣物。此政策适用于独立式衣物收纳商品,包括但不限于高度为 27 英寸(69 厘米或 686 毫米)或更高(从地面到商品顶部测量)的…...

代码随想录算法训练营第25天| 第七章 回溯算法part02: leetcode 216、leetcode 17
Part I : 回溯算法基础 对回溯算法不清楚的可以参看前一篇:代码随想录算法训练营第24天| 第七章 回溯算法part01 理论基础、leetcode 77 Part II: 相关题目 Leetcode 216.组合总和III 解决问题:在数字1~9之间,找出k个数且它们的和为n从而…...

WebAPI文档与自动化测试
目录 1、控制器,项目属性里需要勾选输出Xml文档选项: 2、下载文档的网页数据 3、运行访问网址 4、接口测试: 5、批量测试: 6、微服务文档 总结: 本篇介绍框架的WebAPI文档与自动化测试 1、控制器,项…...

netty架构
https://zhuanlan.zhihu.com/p/181239748 https://cloud.tencent.com/developer/article/1754078...

拉普拉斯平滑算法
原理 最简单的拉普拉斯平滑算法的原理是将每个顶点都移动到相邻顶点的平均位置上。公式 示例(UE5代码片段) 参考 https://blog.csdn.net/mrbaolong/article/details/105859109...

Java课题笔记~ IoC 控制反转
二、IoC 控制反转 控制反转(IoC,Inversion of Control),是一个概念,是一种思想。指将传统上由程序代码直接操控的对象调用权交给容器,通过容器来实现对象的 装配和管理。控制反转就是对对象控制权的转移&a…...
【Spring】Spring中的设计模式
文章目录 责任链模式工厂模式适配器模式代理模式模版方法观察者模式构造器模式 责任链模式 Spring中的Aop的通知调用会使用责任链模式责任链模式介绍 角色:抽象处理者(Handler)具体处理者(ConcreteHandler1)客户类角…...

【ChatGLM_02】LangChain知识库+Lora微调chatglm2-6b模型+提示词Prompt的使用原则
经验沉淀 1 知识库1.1 Langchain知识库的主要功能(1) 配置知识库(2) 文档数据测试(3) 知识库测试模式(4) 模型配置 2 微调2.1 微调模型的概念2.2 微调模型的方法和步骤(1) 基于ptuning v2 的微调(2) 基于lora的微调 3 提示词3.1 Prompts的定义及原则(1) Prompts是什么…...

构建未来移动应用:探索安卓、iOS和HarmonyOS的技术之旅
安卓、iOS和HarmonyOS的比较分析 在移动应用开发领域,安卓、iOS和HarmonyOS是三个常见的操作系统。本文将对它们进行比较分析,并展示一些相关的代码示例。 安卓(Android) 安卓是由Google开发的移动操作系统,基于Lin…...

【新版系统架构补充】-嵌入式软件
嵌入式软件 嵌入式软件是指应用在嵌入式计算机系统当中的各种软件,除了具有通用软件的一般特性,还具有一些与嵌入式系统相关的特点,包括:规模较小、开发难度大、实时性和可靠性要求高、要求固化存储。 嵌入式软件分类࿱…...
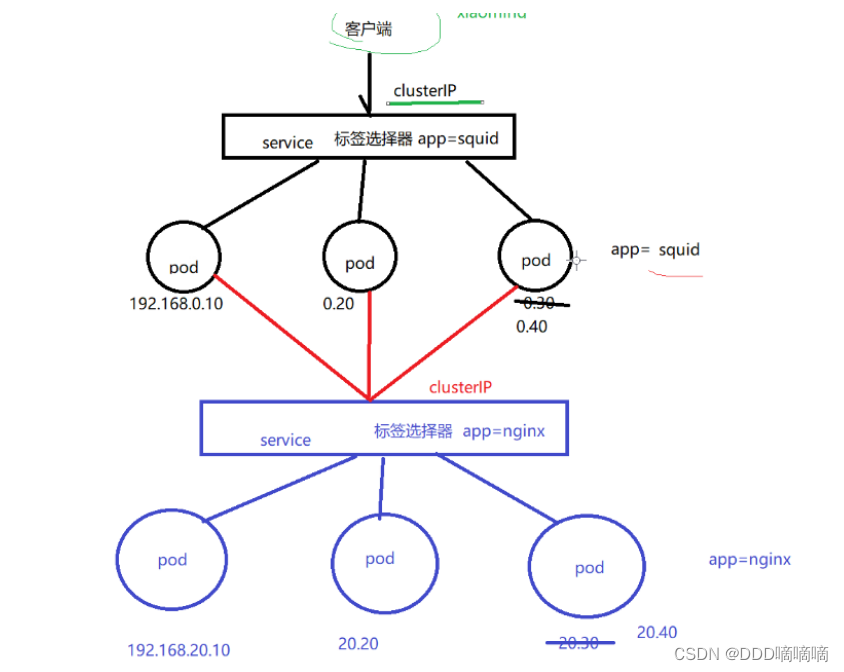
【云原生】K8S超详细概述
目录 一、Kubernets概述1.1 K8S什么1.2为什么要用K8S 二、Kubernetes 集群架构与组件2.1Master组件Kube-apiserverKube-controller-managerKube-scheduler 2.2 配置存储中心etcd 2.3 Node 组件KubeletKube-Proxydocker 或 rocket 三、 Kubernetes 核心概念3.1Pod3.2Pod 控制器K…...
Node.js -模块的加载机制)
(五)Node.js -模块的加载机制
1. 优先从缓存中加载 模块在第一次加载后会被缓存。这意味着多次调用require()不会导致模块的代码被执行多次。 注意:不论是内置模块、用户自定义模块、还是第三方模块,它们都会优先从缓存中加载,从而提高模块的加载效率。 2. 内置模块的加载…...
【docker】Windows11系统下安装并配置阿里云镜像加速
【docker】Windows11系统下安装并配置阿里云镜像加速 提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论 文章目录 【docker】Windows11系统下安装并配置阿里云镜像加速一、查看Windows环境是否支持docker二、 启动Hyper-V三、 官网下载安装Docker应用和数据…...

VCS编译优化全攻略:从-pcmakeprof时间分析到partition配置技巧
VCS编译优化全攻略:从-pcmakeprof时间分析到partition配置技巧 在芯片验证领域,编译时间直接影响着工程师的迭代效率。当RTL代码规模突破千万行时,一次完整编译可能消耗数小时,而传统增量编译往往因为细粒度不足导致不必要的重复工…...

OpenClaw排错大全:Phi-3-mini-128k-instruct接口连接失败7种解决方案
OpenClaw排错大全:Phi-3-mini-128k-instruct接口连接失败7种解决方案 1. 问题背景与排查思路 上周我在本地部署Phi-3-mini-128k-instruct模型时,遇到了OpenClaw连接失败的棘手问题。控制台不断报错"Model connection timeout",但…...

别再死磕公式了!用OpenCV StereoBM/SGBM实战双目测距,从标定到3D点云一气呵成
双目视觉实战:从标定到3D点云的完整OpenCV实现 去年夏天,我尝试用两个普通的USB摄像头搭建了一个简易的深度感知系统。最初以为只要简单调用几个OpenCV函数就能搞定,结果在标定环节就卡了整整两周——棋盘格图像拍了几十张,参数却…...

VSCode高效前端开发:Live Server插件与Chrome浏览器无缝联调指南
1. 为什么你需要Live Server插件 作为前端开发者,最烦人的事情莫过于每次修改代码后都要手动刷新浏览器。我刚开始写前端的时候,经常在HTML、CSS和JavaScript文件之间来回切换,每次保存后都要切到浏览器按F5,效率低得让人抓狂。直…...
)
用Python给双足机器人做个“不倒翁”大脑:线性倒立摆仿真入门(附完整代码)
用Python给双足机器人做个“不倒翁”大脑:线性倒立摆仿真入门(附完整代码) 当你在公园里看到小朋友玩不倒翁时,有没有想过双足机器人也需要类似的"不倒"能力?线性倒立摆模型(LIPM)就是…...

RAGFlow Agent 搞定火电复杂图表
在当前的 LLM 应用层,有一个共识正在逐渐变得 painful:通用大模型在处理垂直领域的“存量知识”时,几乎是无能的。 这种无能尤其体现在工业领域。当我们把目光从“写周报、画海报”的互联网场景移开,投向真正硬核的“火电行业”时…...

深圳 SEO 关键词推广的常见方法有哪些_深圳 SEO 关键词推广与竞价排名有何不同
深圳 SEO 关键词推广的常见方法有哪些 在数字化营销的时代,深圳 SEO 关键词推广已经成为企业提升网站曝光率和吸引潜在客户的重要手段。究竟有哪些常见的深圳 SEO 关键词推广方法呢?本文将详细探讨这些方法,帮助你更好地理解和实践深圳 SEO …...
manga-image-translator:如何让图片中的文字跨越语言障碍?
manga-image-translator:如何让图片中的文字跨越语言障碍? 【免费下载链接】manga-image-translator Translate manga/image 一键翻译各类图片内文字 https://cotrans.touhou.ai/ (no longer working) 项目地址: https://gitcode.com/gh_mirrors/ma/ma…...

突破鸣潮帧率限制:WaveTools工具箱全攻略与优化指南
突破鸣潮帧率限制:WaveTools工具箱全攻略与优化指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 在《鸣潮》1.2版本更新后,许多玩家发现游戏帧率被锁定在60FPS,无法充…...

[资源管理]:全链路智能化的Manifest协同方案
[资源管理]:全链路智能化的Manifest协同方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 定位核心矛盾:资源管理的系统性困境 在数字内容分发领域,Manife…...