Kafka介绍
目录
1,kafka简单介绍
2,kafka使用场景
3,kafka基本概念
kafka集群
数据冗余
分区的写入
读取分区数据
顺序消费
顺序消费典型的应用场景:
批量消费
提交策略
kafka如何保证高并发
零拷贝技术(netty)
1,kafka简单介绍
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息系统。最大的特性就是可以实时处理大量数据来满足需求。
2,kafka使用场景
1,日志收集:可以用kafka收集各种服务的日志 ,通过已统一接口的形式开放给各种消费者。
2,消息系统:解耦生产和消费者,缓存消息。
3,用户活动追踪:kafka可以记录webapp或app用户的各种活动,如浏览网页,点击等活动,这些活动可以发送到kafka,然后订阅者通过订阅这些消息来做监控。
4,运营指标:可以用于监控各种数据。
3,kafka基本概念
kafka是一个分布式的分区的消息,提供消息系统应该具备的功能。
| 名称 | 解释 |
| broker | 消息中间件处理节点,一个broker就是一个kafka节点,多个broker构成一个kafka集群。 |
| topic | kafka根据消息进行分类,发布到kafka的每个消息都有一个对应的topic |
| producer | 消息生产(发布)者 |
| consumer | 消息消费(订阅)者 |
| consumergroup | 消息订阅集群,一个消息可以被多个consumergroup消费,但是一个consumergroup只有一个consumer可以消费消息。 |
| partition | 分区,一个topic可以对应多个分区 |
| replica | 副本,是一个只能追加写消息的日志文件 |
| offset | 偏移量 |
kafka中的topic被分为了多个partition分区。topic实际上是一个逻辑概念,partition是最小的存储单元,存储着一个topic的部分数据。每个partition都是一个单独的log文件,每条记录都以追加的形式写入。
partition中的每条记录都会被分配一个特有的offset,当一条记录写入时,他会追加到log文件的末尾,并分配一个序号,作为一个offset。
这里需要注意顺序消费的场景。每个topic对应多个partition,这些分区是无序的,但是分区里面的数据是有序的,所以我们在做顺序消费的场景的时候,需要注意要将消息放到一个partition。
kafka集群
kafka支持集群化部署就是依赖于分区机制。

这么设计的优点:
1,如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之后,Topic 就可以水平扩展 。
2,一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持更多的 Consumer。
3,一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。
数据冗余
在kafka集群中,kafka为Partition做了数据冗余处理,这样即使一个broker挂了,消费者也可以在其他broker找到这个partition。
分区的写入
既然一个topic可以有多个Partition,那么消息进来的时候,到底该进那个Partition呢,kafka提供了三种模式
1,使用 Partition Key 写入特定 Partition
Producer 发送消息的时候,可以指定一个 Partition Key,这样就可以写入特定 Partition 了。
Partition Key 可以使用任意值,例如设备ID、User ID。
Partition Key 会传递给一个 Hash 函数,由计算结果决定写入哪个 Partition。
所以,有相同 Partition Key 的消息,会被放到相同的 Partition。
例如使用 User ID 作为 Partition Key,那么此 ID 的消息就都在同一个 Partition,这样可以保证此类消息的有序性。
这种方式需要注意 Partition 热点问题。
例如使用 User ID 作为 Partition Key,如果某一个 User 产生的消息特别多,是一个头部活跃用户,那么此用户的消息都进入同一个 Partition 就会产生热点问题,导致某个 Partition 极其繁忙。
2,由 kafka 决定
如果没有使用 Partition Key,Kafka 就会使用轮询的方式来决定写入哪个 Partition。
这样,消息会均衡的写入各个 Partition。
但这样无法确保消息的有序性。
3,自定义规则
Kafka 支持自定义规则,一个 Producer 可以使用自己的分区指定规则。
读取分区数据
kafka是一个pull模型的消息队列,他不会向消费者主动去推送消息。必须由消费者去轮询。基于这种设置,有下面几种情况
一共有三种情况。
1.分区数高于消费者数量
在这种场景下,消费者2需要消费分区-1和分区-2的消息,会导致消费流量倾斜,消费者2所在的服务实例负载较高。
2,分区数低于消费者数量
在这种场景下,消费者3没有分配到分区,不消费数据,消费者3所在的服务实例负载较低。
3,分区数是消费者数量的N倍(N=1,2,3...)
这种场景下,每个消费者负责的分区数量一致,消费者负载均衡。
通常Kafka产生堆积的原因都是消费速率跟不上生产速率,生产者发送消费没有什么业务逻辑,而消费者消费时需要等待业务逻辑处理。因此,我们来看看“不考虑优化业务逻辑的前提下,如何通过设置合理的Topic分区数来提高消费能力”。
1,不确定生产速率和消费速率:分区数 = 部署的服务实例数
当研发人员需要申请新的Topic但还无法预估生产者和消费者处理消息的能力时,可以先按照标准场景申请与 服务实例数 相等的分区数。
2,明确生产速率低于消费速率:分区数 = 部署的服务实例数
当业务系统稳定运行并且确定Topic的平均生产速率低于消费速率时,也应该申请与 服务实例数 相等的分区数,避免消息突增时作为消费者的服务实例负载倾斜。
3,生产速率高于消费速率(同时增加分区数和服务实例数):分区数 = 部署的服务实例数
当业务能预估到消息的生产速率高于消费速率,最直接的方式就是同时增加分区数和服务实例数,从而提高整体消费速率。但往往在非必要的情况下增加服务实例数会导致严重的资源浪费,因此在不增加服务实例数的前提下,也可以通过提高单机 并行度 来提高消费速率。
4,生产速率高于消费速率(增加分区数,服务实例数不变):分区数 = 部署的服务实例数 * N 承接上一个场景,假设服务实例数为4,需要申请12个分区,那么单机 并行度 = 3,并行度在消费者注解中添加,如下
concurrency = "3":
但设置并行度的场景存在一个弊端:服务实例扩容时,可能会出现消费者总数大于分区数,从而导致负载不均衡。
顺序消费
在Kafka中,Topic在单个分区的生产消费是有序的。通常我们申请多个分区是为了提高生产消费的吞吐量,但多个分区就会导致消费消息时无序。保证顺序消费的方法有:
要想保证顺序消费,就必须要保证顺序消费的消息在同一个队列。
1.只申请1个分区:仅推荐在吞吐量低的顺序场景下用
2.这种场景申请多个分区,生产时使用消息Key:生产者发送消息时如果指定了Key,则这条消息会根据Key的Hash发送到对应的分区,也就是说带有相同Key的消息会被发送到相同的分区。(如果不携带Key的话是轮询发送到所有分区)
顺序消费典型的应用场景:
1,用于同步数据库和redis之间的数据(单个消费者)
2,某些电商场景必须严格遵守消息的执行顺序,比如说待支付--已支付---开始发货---订单完成----评价。如果开始发货在已支付之前面执行,就会产生业务问题。
在使用消息key来确保消息发布到多个分区时,要注意key的hash,尽量避免大多数消息发布到一个分区,否则会出现流量倾斜。
批量消费
批量消费可以一次性消费到多条消息,如果是顺序不敏感的业务,可以另外开启线程池多线程处理这批消息。但是需要特别注意的是:
1,当这批消息里有个别消息处理失败,有可能会导致其他没处理失败的消息重试,处理逻辑需要做好业务幂等;
2,触发重试必须在 @KafkaListener 注解的方法中抛出 BatchListenerFailedException 这个异常(默认重试9次后打印错误日志),并在异常中设置这批消息中索引最小的消费失败的消息(后面会给出示例);
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory;import java.util.Properties;@Configuration public class Aaa {@Beanpublic ConcurrentKafkaListenerContainerFactory<?, ?> batchFactory(ConsumerFactory<Object, Object> kafkaConsumerFactory) {ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(kafkaConsumerFactory);// 表示开启批量消费factory.setBatchListener(true);Properties properties = new Properties();// 表示批量消费时最大批次为50条properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "50");// 禁用轮询自动提交offset,而是每消费完一批消息提交一次offsetproperties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");factory.getContainerProperties().setKafkaConsumerProperties(properties);return factory;} }
import javafx.util.Pair; import lombok.extern.slf4j.Slf4j; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.listener.BatchListenerFailedException; import org.springframework.stereotype.Service;import java.util.List; import java.util.Optional; import java.util.Random; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors;@Slf4j@Servicepublic class KafkaConsumer {private final ExecutorService executorService = Executors.newFixedThreadPool(10);@KafkaListener(topics = "arch-kafka-admin", groupId = "kafka-admin", containerFactory = "batchFactory")public void consume(List<ConsumerRecord<String, DataDTO>> records) {// 提交到线程池处理并获取处理结果Optional<Pair<ConsumerRecord<String, DataDTO>, Exception>> firstFailRecord = records.stream().map(record -> new Pair<>(record, executorService.submit(() -> process(record)))).map(fp -> {Exception e;try {e = fp.getValue().get();} catch (Exception ex) {e = ex;}return new Pair<>(fp.getKey(), e);}).filter(fp -> fp.getValue() != null).findFirst();// 批量消费有异常的, 获取第一个产生异常的消息, 并抛出 BatchListenerFailedException 触发重试if (firstFailRecord.isPresent()) {Pair<ConsumerRecord<String, DataDTO>, Exception> pair = firstFailRecord.get();ConsumerRecord<String, DataDTO> record = pair.getKey();log.error(pair.getValue().getMessage(), pair.getValue());throw new BatchListenerFailedException(String.format("批量消费失败: 分区: %s, 偏移量: %s", record.partition(), record.offset()), record);}}// 模拟业务处理public Exception process(ConsumerRecord<String, DataDTO> record) {try {// 模拟业务处理Thread.sleep(new Random().nextInt(100));return null;} catch (Exception e) {return e;}}}
重试需要在 consume 方法所在的线程中抛出
BatchListenerFailedException 异常才能触发正确的重试,抛出其他异常会导致无限重试。
提交策略
1,自动提交:默认配置(配置中心公共配置)为自动提交,即每隔一段时间(默认5s)提交一次,自动提交可以很大程度上降低Kafka服务端的压力,并且减少客户端的网络开销,如果消费逻辑做好了业务幂等,尽可能选择自动提交。 实际上自动提交并不是严格地每间隔一段时间提交一次偏移量(旧版的客户端是有一个AutoCommitTask进行轮询提交),而是每次在调用 KafkaConsumer.poll()时判断当前时间距离上次提交时间是否超过了配置了提交间隔,如果超过了就进行提交,所以实际上的提交时间会超过配置的提交间隔。另外由于KafkaConsumer.poll()方法会返回多条消息(由配置项,max.poll.records控制),因此如果上一批消息消费耗时超过提交间隔,也会导致实际提交时间推迟。
2,手动提交:即spring.kafka.consumer.enable-auto-commit=false,设置手动提交时需要主动调用提交方法,具体方法根据使用的客户端而定。当消息量较大时使用手动提交会给Kafka服务端带来压力,并增加客户端的网络开销,不过还是建议重要消息或者是无法保证业务幂等的消费逻辑使用手动提交。
使用kafka-client:Kafka自带的客户端,需要主动调用KafkaConsumer.commitSync()或KafkaConsumer.commiAsync()进行偏移量提交。
使用spring-kafka:基于spring和kafka-client封装的高阶API,当是否自动提交设置为false时,每消费完一条消息就会自动提交一次偏移量(同步提交),无需手动调用API提交。
kafka如何保证高并发
kafka的高并发依赖于页缓存技术和磁盘顺序写。
有研究表名,在磁盘中的顺序读写要比在内存中的随机读写要快。
页缓存技术是操作系统级别的缓存(page cache),即先将数据写入到系统缓存中(内存),并且是只写入到内存中,由操作系统决定什么时候写入磁盘。

kafka在写数据的时候,是以顺序写的方式来刷盘的,即只在文件末尾来追加数据,而不是在文件的随机位置写入数据。
上面那个图里,Kafka 在写数据的时候,一方面基于 OS 层面的 Page Cache 来写数据,所以性能很高,本质就是在写内存。
另外一个,它是采用磁盘顺序写的方式,所以即使数据刷入磁盘的时候,性能也是极高的,也跟写内存是差不多的。
零拷贝技术(netty)
操作系统层面的技术。操作系统里面的进程有两种类型,一个是操作系统级别的,一个是用户级别的。其中操作系统级别的可以直接访问内存,直接对系统内存进行读写。用户级别的进程(咱们的java项目,或者redis等等第三方应用)是不能直接操作内存和硬盘等硬件的,必须由操作系统去操作。于是就有了两个缓冲区,一个是用户缓冲区,一个是内核缓冲区。第三方应用程序先通过操作系统将想要拿到的数据告诉操作系统,然后操作系统放到用户缓冲区,这个时候咱们的程序才可以拿到数据。
采用常规的思路,kafka获取数据的流程:
1,操作系统从磁盘中拿到数据,放到内核缓冲区,2,然后再从内核缓冲区复制数据到用户缓冲区,3,然后再用用户缓冲区放到socket缓冲区(也是系统级别的,用户进程无法直接操作),4,最后再从socket缓冲区通过网卡发送出去。
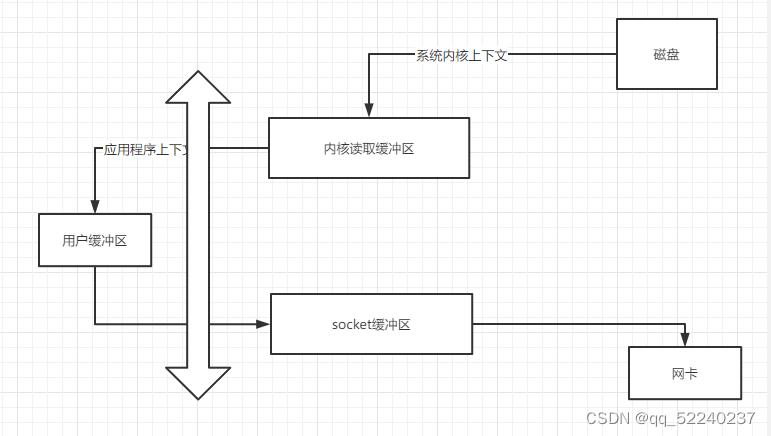
可以看到从磁盘到内核读取缓冲区复制了一次,从内核缓冲区复制到用户缓冲区,复制了一次,从用户缓冲区复制到socket缓冲区复制了一次,从socket缓冲区复制到nicbuffer复制了一次。一共是复制了4次,期间还进行了2次上下文切换
但是使用了零拷贝技术,网卡可以直接从内核缓冲区去读取数据。这样就可以实现内核空间和应用空间之间的零拷贝了。
拷贝步骤:
1,操作系统将磁盘中的数据放到内核读取缓冲区
2,网卡直接从内核读取缓冲区获取数据发送。
以上是kafka 的读和写,当我们的kafka集群如果经过调优,可以达到写的时候写入到oscache中,读的时候也从oscache中读。
相关文章:
Kafka介绍
目录 1,kafka简单介绍 2,kafka使用场景 3,kafka基本概念 kafka集群 数据冗余 分区的写入 读取分区数据 顺序消费 顺序消费典型的应用场景: 批量消费 提交策略 kafka如何保证高并发 零拷贝技术(netty&#…...

Django使用uwsgi+nginx部署,admin没有样式解决办法
Django使用uwsginginx部署,admin没有样式解决办法 如果使用了虚拟环境则修改nginx.conf文件中的/static/路径为你虚拟环境的路径,没有使用虚拟环境则改为你python安装路径下的static server {listen 8008;server_name location; #改为自己的域名,没域名…...
穷举深搜暴搜回溯剪枝(3)
一)字母大小写全排列 784. 字母大小写全排列 - 力扣(LeetCode) 1)从每一个字符开始进行枚举,如果枚举的是一个数字字符,直接忽视 如果是字母的话,进行选择是变还是不变 2)当进行遍历到叶子结点的时候,直接将…...

Bash 脚本的参数等
bash 的 $值 $0 : 表示当前脚本的名称${BASH_SOURCE[0]} : 表示当前 Bash 脚本文件的路径,可以理解为 $0 的安全版本,防止被修改。$1 : 表示第一个参数,以此类推$ : 表示所有传入脚本的参数$UID : 表示当前用户的 ID 号。如果当前用户是 roo…...

从哪些方面学HTML技术? - 易智编译EaseEditing
学习HTML技术是前端开发的基础,它用于定义网页的结构和内容。以下是学习HTML技术时可以关注的方面: HTML基本语法: 了解HTML标签的基本语法和用法,学习如何创建HTML文档和元素。 常用HTML标签: 学习常用的HTML标签&…...
非阻塞IO
非阻塞IO fcntl 一个文件描述符, 默认都是阻塞IO。fcntl可以将某个文件描述符设置为非阻塞IO,先看一下文档介绍。 传入的cmd的值不同,后面追加的参数也不相同。 fcntl函数有5种功能: 复制一个现有的描述符(cmd F_DUPFD)。获得…...

Debian如何让multilib和交叉编译工具链共存
Debian一个槽点是gcc/g/gfortran-multilib和交叉编译工具链如gcc/g/gfortran-riscv64-linux-gnu会互相卸载,解决办法如下: 1、安装build-essential(gcc/g/libc6-dev/make/dpkg-dev)和gfortran,记下被安装的gcc版本&am…...
Flink之JDBC Sink
这里介绍一下Flink Sink中jdbc sink的使用方法,以mysql为例,这里代码分为两种,事务和非事务 非事务代码 import org.apache.flink.connector.jdbc.JdbcConnectionOptions; import org.apache.flink.connector.jdbc.JdbcExecutionOptions; import org.apache.flink.connector.…...

lifecycleScope Unresolved reference
描述 导入了lifecycle.lifecycleScope,但是在activity中使用lifecycleScope报错出现Unresolved reference找不到引用。 导包 import androidx.lifecycle.lifecycleScope使用 lifecycleScope.launch(Dispatchers.IO) {...}错误 方案 代码中的activity继承Activ…...

P5960 【模板】差分约束算法
【模板】差分约束算法 题目描述 给出一组包含 m m m 个不等式,有 n n n 个未知数的形如: { x c 1 − x c 1 ′ ≤ y 1 x c 2 − x c 2 ′ ≤ y 2 ⋯ x c m − x c m ′ ≤ y m \begin{cases} x_{c_1}-x_{c_1}\leq y_1 \\x_{c_2}-x_{c_2} \leq y_2 \\…...
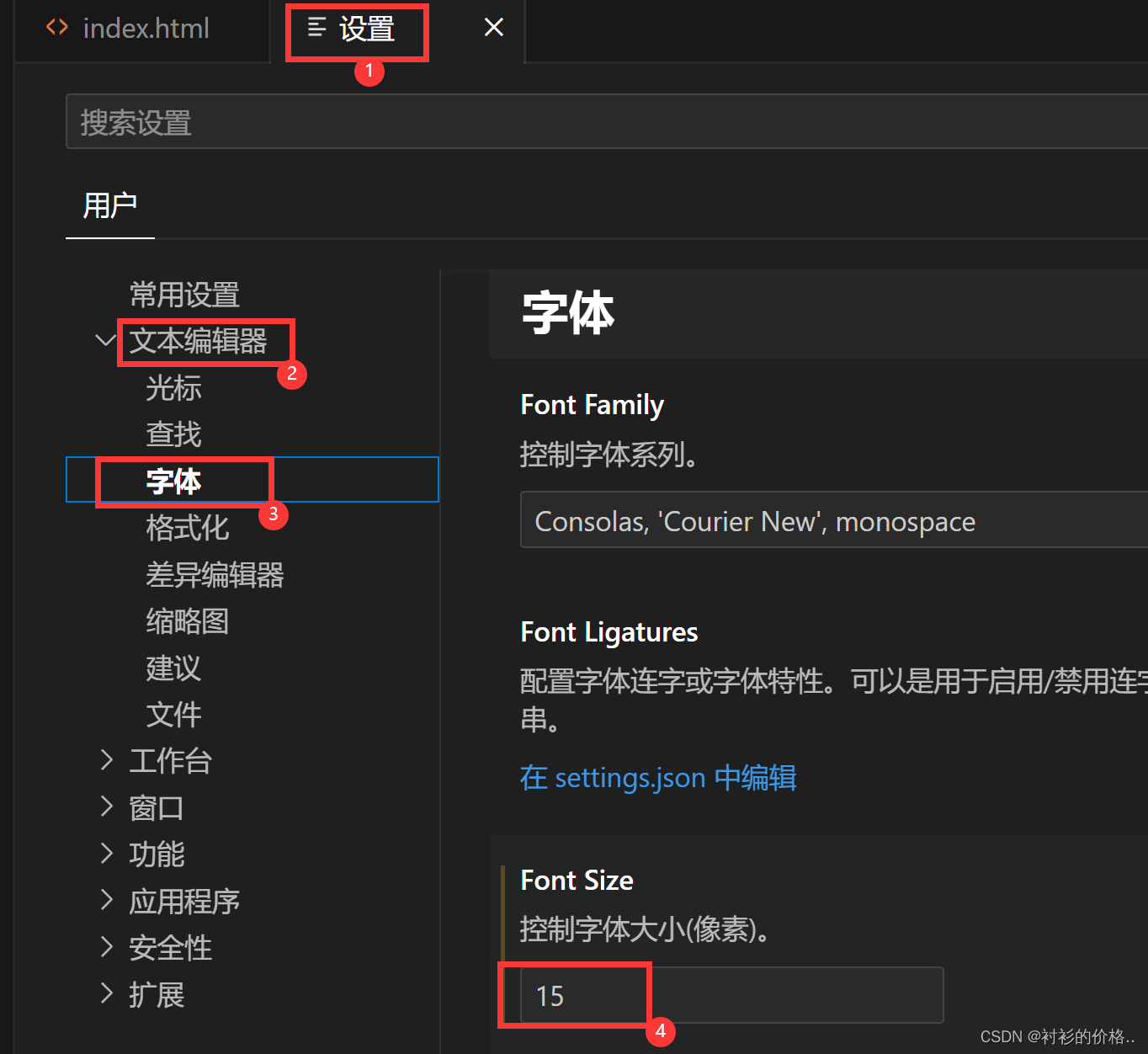
VSCode---通过ctrl+鼠标滚动改变字体大小
打开设置然后在右边输editor.mouseWheelZoo勾选即可实现鼠标滚动改变字体大小 4.这种设置的字体大小是固定的...
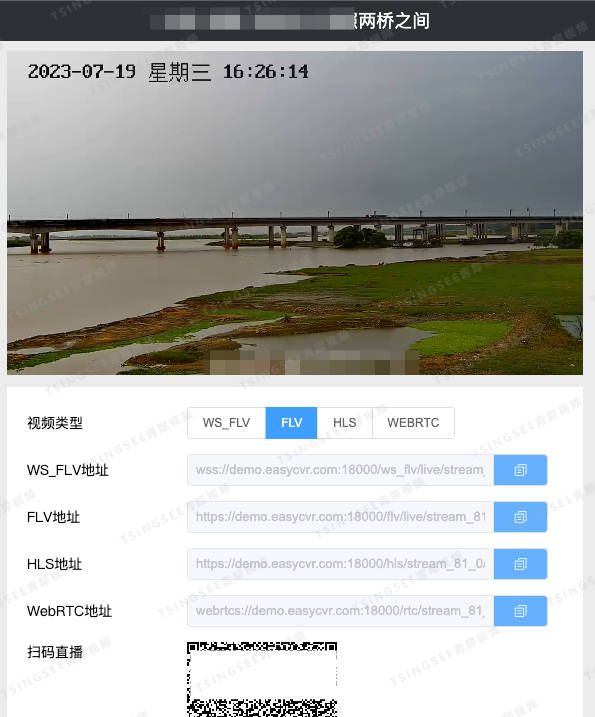
视频监控汇聚平台EasyCVR视频分享页面WebRTC流地址播放不了是什么原因?
开源EasyDarwin视频监控TSINGSEE青犀视频平台EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,在视频监控播放上,TSINGSEE青犀视频安防监控汇聚平台可支持1、4、9、16个画面窗口播放,可同时播放多…...
Libevent开源库的介绍与应用
libeventhttps://libevent.org/ 一、初识 1、libevent介绍 Libevent 是一个用C语言编写的、轻量级的开源高性能事件通知库,主要有以下几个亮点:事件驱动( event-driven),高性能;轻量级,专注于网络ÿ…...

【LNMP】LNMP
LNMP:是目前成熟的企业网站的应用模式之一,指的是一套协同工作的系统和相关软件;能够提供静态页面服务,也可以提供动态web服务 L Linux系统,操作系统N Nginx网站服务,前端,提供前端的静态…...
uniapp自定义头部导航栏
有时我们需要一些特殊的头部导航栏页面,取消传统的导航栏,来增加页面的美观度。 下面我就教大家如何配置: 一、效果图 二、实现 首先在uniapp中打开pages.json配置文件,在单个路由配置style里面设置导航栏样式nav…...
Django实现音乐网站 ⑹
使用Python Django框架制作一个音乐网站, 本篇主要是在添加编辑过程中对后台歌手功能优化及表模型名称修改、模型继承内容。 目录 表模型名称修改 模型继承 创建抽象基类 其他模型继承 更新表结构 歌手新增、编辑优化 表字段名称修改 隐藏单曲数和专辑数 姓…...
dubbo-helloworld示例
1、工程架构 2、创建模块 (1)创建父工程,引入公共依赖 pom.xml依赖 <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></depende…...
)
电脑ADB连接手机的方式通过网络无法adb连接手机的问题(已解决)
首先电脑要下载adb工具,将压缩包解压到C盘:https://download.csdn.net/download/qq_43445867/87975072 1、使用USB线连接 打开手机USB调试;PC端安装手机USB驱动。 1.打开DOS命令窗口,进入adb文件夹,输入adb.exe devices回车列出设…...

79 | Python数据分析篇 —— Pandas中groupby聚合操作和透视表基础
Pandas是Python中最常用的数据处理库之一,它提供了高效的数据结构和数据分析工具。在进行数据分析和机器学习等领域的工作时,Pandas是必不可少的库之一。本文将介绍Pandas中的groupby聚合操作和透视表,包括groupby操作、透视表的基础知识、练习题和答案。 文章目录 Pandas中…...
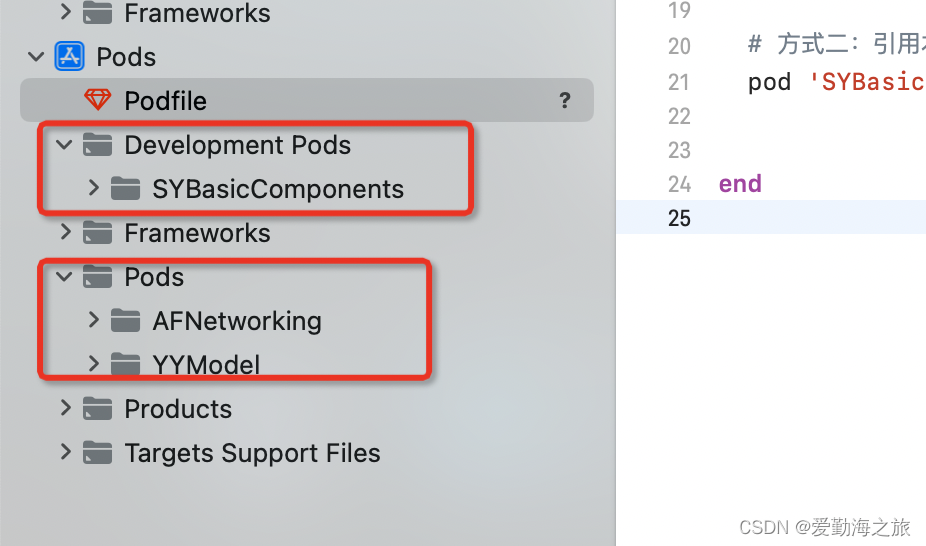
iOS 搭建组件化私有库
一、创建私有库索引 步骤1是在没有索引库的情况下或者是新增索引的时候才需要用到(创建基础组件库) 首先在码云上建立一个私有库索引,起名为SYComponentSpec 二、本地添加私有库索引 添加私有库索引 pod repo add SYComponentSpec https:/…...

EPLAN端子图表修改避坑指南:从占位符到动态区域,手把手教你定制专属端子连接图
EPLAN端子图表深度定制指南:从占位符优化到动态布局实战 在电气工程设计领域,EPLAN作为行业标杆软件,其端子图表功能直接影响项目交付的专业度和效率。许多工程师在项目后期常遇到这样的困境:标准端子图表无法满足客户特殊规范要求…...
)
【2026最新版Linux安装Mysql】CentOS 7 安装 MySQL 8.4.9 完整流程(RPM 手动安装+避坑+面试)
前言:本文记录在 CentOS 7 / RHEL 7 上,通过官网 RPM Bundle tar 包手动安装 MySQL 8.4.9(LTS) 的完整可复现流程。适合需要在老版本 CentOS 上部署 MySQL、为 Python/AI 后端或 Java 项目准备数据库环境的读者。读完可按步骤完成…...

Linux包管理核心:yum机制详解与实战配置指南
1. 项目概述:为什么你需要掌握yum?在Linux的世界里,尤其是以Red Hat、CentOS、Fedora为代表的发行版中,yum(Yellowdog Updater, Modified)是每一位系统管理员和开发者绕不开的核心工具。你可以把它想象成一…...
)
Anaconda安装后必做的两件事:快速配置清华镜像源和验证环境(附常用conda命令清单)
Anaconda安装后的高效配置指南:镜像加速与环境验证全攻略 当你第一次打开Anaconda Prompt时,那种面对全新工具既兴奋又忐忑的心情我深有体会。作为Python数据科学领域的瑞士军刀,Anaconda的强大功能背后隐藏着许多新手容易忽略的配置细节。本…...

别再只下载不固化!紫光同创FPGA/CPLD烧录到Flash的保姆级避坑指南
紫光同创FPGA/CPLD烧录实战:从临时下载到永久固化的全流程精解 第一次成功将程序下载到紫光同创FPGA开发板时的兴奋,很快被一个残酷现实浇灭——断电重启后,所有心血归零。这个场景对许多初学者来说再熟悉不过。JTAG下载只是起点,…...

STM32体重秤电子秤称重超重报警Proteus仿真资源包
STM32体重秤电子秤称重超重报警Proteus仿真资源包 【下载地址】STM32体重秤电子秤称重超重报警Proteus仿真资源包 本资源包提供了基于STM32单片机的体重秤电子秤称重超重报警系统的完整解决方案。资源内容包括源代码、Proteus仿真文件以及全套相关资料,帮助用户快速…...

告别传统编程:用AI语音命令5倍速开发Godot游戏
告别传统编程:用AI语音命令5倍速开发Godot游戏 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP 还在为复杂的…...

GameEngineFromScratch输入管理系统:跨平台输入事件处理机制终极指南 [特殊字符]
GameEngineFromScratch输入管理系统:跨平台输入事件处理机制终极指南 🎮 【免费下载链接】GameEngineFromScratch 配合我的知乎专栏写的项目 项目地址: https://gitcode.com/gh_mirrors/ga/GameEngineFromScratch GameEngineFromScratch输入管理系…...

立模框架三维扫描检测:构建装配式生产装备的数字化精度基准
在建筑工业化与智能建造协同发展的浪潮中,装配式建筑已成为行业转型升级的主旋律。作为PC构件生产的核心工装,立模框架的几何精度直接决定了预制墙板、叠合梁柱等构件的成型质量,进而影响施工现场的装配效率与结构安全。图片来源网络…...

OpenSTA静态时序分析引擎技术深度解析:开源时序验证核心架构揭秘
OpenSTA静态时序分析引擎技术深度解析:开源时序验证核心架构揭秘 【免费下载链接】OpenSTA OpenSTA engine 项目地址: https://gitcode.com/gh_mirrors/op/OpenSTA OpenSTA作为一款开源的静态时序分析引擎,为数字集成电路设计提供了工业级的时序验…...