[SQL系列] 从头开始学PostgreSQL 分库分表
什么是分库分表
分库分表是一种数据库架构设计的方法,用于应对大规模数据的存储和查询。当单个数据库的存储容量或查询性能无法满足需求时,可以通过将数据分散存储在多个数据库服务器上,以提高系统的可扩展性和性能。
分库分表通常包括两个步骤:分库和分表。
分库
分库是指将单个数据库按照一定规则划分为多个数据库,每个数据库可以存储一部分数据。这样可以减少单个数据库的数据量,提高查询效率。常见的分库方式包括垂直分库和水平分库。
垂直分库是指按照功能模块或业务领域将数据分成多个数据库。例如,可以将订单数据、用户数据、商品数据分别存储在不同的数据库中。
水平分库是指按照数据特征将数据分成多个数据库,例如按照时间、地理位置等。例如,可以将订单数据按照月份分别存储在不同的数据库中。
分表
分表是指将单个表按照一定规则划分为多个表,每个表可以存储一部分数据。这样可以减少单个表的数据量,提高查询效率。常见的分表方式包括垂直分表和水平分表。
垂直分表是指按照功能模块或业务领域将表分成多个部分。例如,可以将订单表按照订单状态分成多个部分。
水平分表是指按照数据特征将表分成多个部分,例如按照时间、地理位置等。例如,可以将订单表按照月份分别存储在不同的表中。
从PostgreSQL 11开始,就有三种表分区:
1. 范围分区(Range Partition)
范围分区是将表按照某个列的值划分成一段或多段。每个分区的端点值存储在 pg_partition_range 系统表中。范围分区支持基于时间戳的自动分区,例如根据日期列自动创建每天、每月、每年等分区。
2. 列表分区(List Partition)
列表分区是将表按照某个列的值存储在数组中,每个分区的值存储在 pg_partition_list 系统表中。列表分区的支持比较灵活,可以自定义分区值,也可以使用预先定义好的列表进行分区。
3. 哈希分区(Hash Partition)
哈希分区是将表按照某个列的值进行哈希运算,将结果映射到不同的分区。哈希分区可以使用任何哈希函数,例如 MD5、SHA1 等。哈希分区的优点是可以平均分布数据,避免某个分区存储过多数据,提高查询效率。
示例
1. 创建主表
首先,我们需要创建一个主表,用于存储所有分表的公共字段和索引。在示例中,我们创建一个名为 customers 的表,其中包含 id、name、age 和 address 列。
testdb=# CREATE TABLE customers ( id SERIAL PRIMARY KEY, name VARCHAR(50) NOT NULL, age INT NOT NULL, address VARCHAR(100) NOT NULL
);2. 创建分表
接下来,我们需要创建多个分表,每个分表都包含主表的所有字段和额外的特定字段。在示例中,我们创建年龄分区表
user=# create table customers_10 () inherits (customers);
CREATE TABLE
user=# create table customers_20 () inherits (customers);
CREATE TABLE
user=# create table customers_30 () inherits (customers);
CREATE TABLE
user=#user=# \dList of relationsSchema | Name | Type | Owner
--------+-----------------------+----------+-------public | customers | table | userpublic | customers_10 | table | userpublic | customers_20 | table | userpublic | customers_30 | table | user3. 定义分表规则
使用 PostgreSQL 提供的分表规则(partitioning)功能,定义如何将数据分配到不同的分表中。在示例中,我们使用 AGE 列作为分表规则,将数据分配到 customers_age 分表中。
首先创建一个function,年龄为 (0,10), [10,20), [20, ...)分别插入三张不同的表里。
然后创建一个trigger,在插入到customers之前开始执行这个function。
这样子当我们向这个customers表插入数据的时候
user=# create or replace function customers_partition_trigger()
returns trigger as $$
begin
if NEW.age < 10 then
insert into customers_10 values (NEW.*);
elseif NEW.age < 20 then
insert into customers_20 values (NEW.*);
else insert into customers_30 values (NEW.*);
end if;
return null;
end;
$$
language plpgsql;
CREATE FUNCTIONuser=# create trigger insert_customers_partition_trigger
user-# before insert on customers
user-# for each row execute procedure customers_partition_trigger();
CREATE TRIGGER4. 向表中插入数据,这里数据仍会显示在父表中,但是实际上父表仅仅作为整个分区表结构的展示,实际插入的记录是保存在子表中。
user=# INSERT INTO customers VALUES (1, 'Alice', 25, 'New York');
INSERT 0 0
user=# INSERT INTO customers VALUES (2, 'Bob', 35, 'San Francisco');
INSERT 0 0
user=# INSERT INTO customers VALUES (3, 'Charlie', 18, 'Chicago');
INSERT 0 0
user=# INSERT INTO customers VALUES (3, 'Charlie', 18, 'Chicago');
INSERT 0 0
user=# select * from customers;id | name | age | address
----+---------+-----+---------------3 | Charlie | 18 | Chicago3 | Charlie | 18 | Chicago1 | Alice | 25 | New York2 | Bob | 35 | San Francisco
(4 rows)user=# select * from customers_10;id | name | age | address
----+------+-----+---------
(0 rows)user=# select * from customers_20;id | name | age | address
----+---------+-----+---------3 | Charlie | 18 | Chicago3 | Charlie | 18 | Chicago
(2 rows)user=# select * from customers_30;id | name | age | address
----+-------+-----+---------------1 | Alice | 25 | New York2 | Bob | 35 | San Francisco
(2 rows)5. 设置分表约束,加快查询效率。因为如果查询主表的话,会直接扫描所有的子表来查询,但是如果加上constraint的话,会允许规划器根据条件查询对应的子分区,在数据很多的情况下可以加快查询速度。
user=# alter table customers_10
user-# add constraint customers_10_check_age_key
user-# check (age < 10);
ALTER TABLEuser=# alter table customers_20
user-# add constraint customers_20_check_age_key
user-# check (age < 20);
ALTER TABLEuser=# alter table customers_30
user-# add constraint customers_30_check_age_key
user-# check (age < 30);
ALTER TABLE优缺点
分库分表都有 一定的优缺点,下面来盘点下。
优点
- 提高系统可扩展性:通过将数据分散存储在多个数据库服务器上,可以提高系统的可扩展性,方便扩展存储容量和处理能力。
- 提高系统性能:通过将数据分散存储在多个数据库服务器上,可以提高系统的性能,减少单个数据库的压力。
- 降低数据冗余:通过将数据分散存储在多个数据库服务器上,可以降低数据冗余,减少数据丢失的风险。
缺点
- 复杂性:分库分表需要对数据进行划分和维护,增加了系统的复杂性和维护成本。
- 数据一致性:分库分表可能导致数据不一致,需要额外的机制来保证数据的一致性。
- 事务处理:分库分表可能会影响事务的处理,需要额外的机制来支持跨库的事务处理。
相关文章:

[SQL系列] 从头开始学PostgreSQL 分库分表
什么是分库分表 分库分表是一种数据库架构设计的方法,用于应对大规模数据的存储和查询。当单个数据库的存储容量或查询性能无法满足需求时,可以通过将数据分散存储在多个数据库服务器上,以提高系统的可扩展性和性能。 分库分表通常包…...

【VScode】Remote-SSH XHR failed无法访问远程服务器
问题概述 当使用VScode连接远程服务器时,往往需要使用Remote-SSH这个插件。而该插件有一个小bug,当远程服务器网络不佳时容易出现。 在控制台会出现下述语句: Resolver error: Error: XHR failed at y.onerror (vscode-file://vscode-app/…...
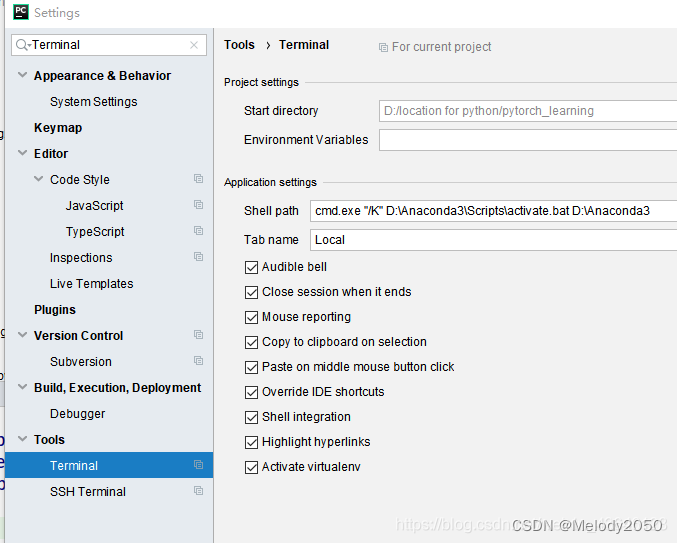
pycharm打开terminal报错
Pycharm打开终端报错如何解决?估计是终端启动conda不顺利,需要重新设置路径。参考以下文章的做法即可。 Windows下Pycharm中Terminal无法进入conda环境和Python Console 不能使用 给pycharm中Terminal 添加新的shell,才可以使用conda环境 W…...
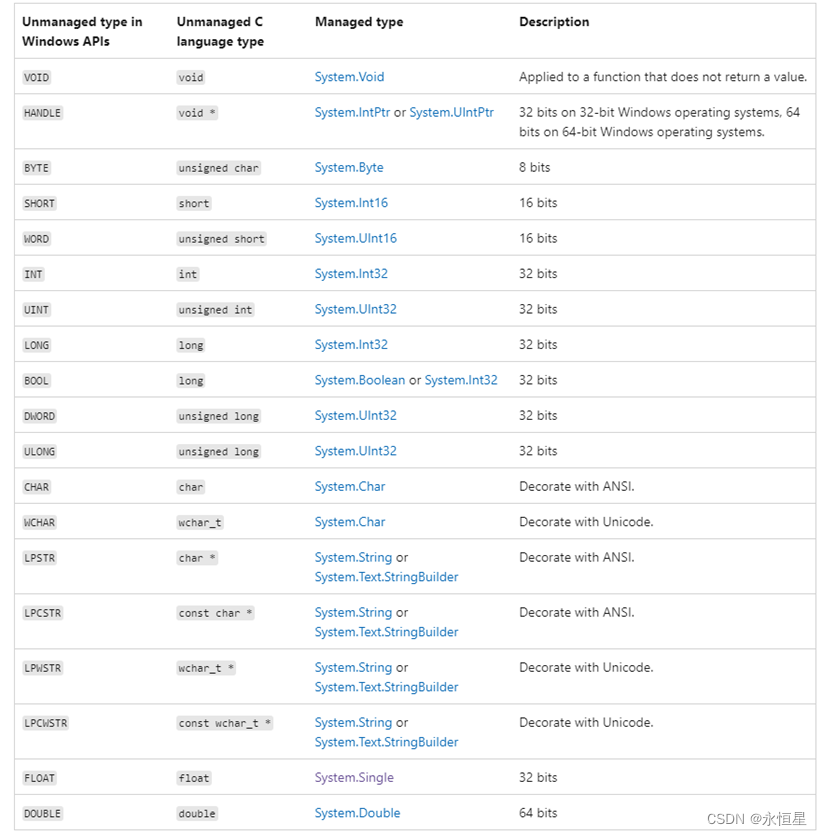
C#与C/C++交互(1)——需要了解的基础知识
【前言】 C#中用于实现调用C/C的方案是P/Invoke(Platform Invoke),让托管代码可以调用库中的函数。类似的功能,JAVA中叫JNI,Python中叫Ctypes。 常见的代码用法如下: [DllImport("Test.dll", E…...

LeetCode笔记:Weekly Contest 356
LeetCode笔记:Weekly Contest 356 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/weekly-contest-356/ 1. 题目一…...

2 Python的基础语法
概述 在上一节的内容中,我们介绍了Python的诞生、发展历程、特色、缺点和应用领域。从本节开始,我们将正式学习Python。Python是一门简洁和优雅的语言,有自己特殊的一些语法规则。因此,在介绍Python编程的有关知识之前,…...
抖音seo矩阵系统源代码开发搭建技术分享
抖音SEO矩阵系统是一个较为复杂的系统,其开发和搭建需要掌握一定的技术。以下是一些技术分享: 技术分享 抖音SEO矩阵系统的源代码可以使用JAVA、Python、PHP等多种语言进行开发。其中,JAVA语言的应用较为广泛,因为JAVA语言有良好…...

python#django数据库一对一/一对多/多对多
一对一OneToOneField 用户和用户信息 搭建 # 一对一 class TestUser(models.Model): usernamemodels.CharField(max_length32) password models.CharField(max_length32) class TestInfo(models.Model): mick_namemodels.CharField(max_length32) usermode…...

记RT-Thread rt_timer_start函数的问题
我使用的RT-Thread版本为4.0.3。 我看了5.0.1的代码,此问已经被修复。 在4.0.3版本中的rt_timer_start函数源码如下: rt_err_t rt_timer_start(rt_timer_t timer) {unsigned int row_lvl;rt_list_t *timer_list;register rt_base_t level;rt_list_t *r…...

C++初阶——拷贝构造和运算符重载(const成员)
目录 1. 拷贝构造函数 1.2 拷贝构造函数特征: 2. 默认拷贝构造函数 2.1 未显式定义,编译器会生成默认的拷贝构造函数。 默认的拷贝构造函数对象按内存存储按字节序完成拷贝,这种拷贝叫做浅拷贝,或者值拷贝 3. 运算符重载 3.1…...
go练习 day01
DTO: note_dto.go package dtoimport "king/model"type NoteAddDTO struct {ID uintTitle string json:"title" form:"title" binding:"required" message:"标题不能为空"Content string json:"conten…...
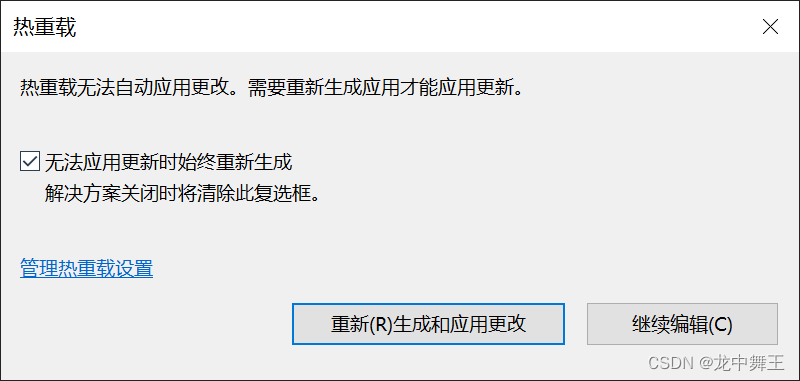
C# Blazor 学习笔记(0.1):如何开始Blazor和vs基本设置
文章目录 前言资源推荐环境如何开始Blazor个人推荐设置注释快捷键热重载设置 前言 Blazor简单来说就是微软提供的.NET 前端框架。使用 WebAssembly的“云浏览器”,集成了Vue,React,Angular等知名前端框架的特点。 资源推荐 微软官方文档 Blazor入门基础视频合集 …...

原码的乘法运算 补码乘法运算
补码乘法 对比...

找不到d3dx9_43.dll丢失怎么解决(分享几种解决方法)
为什么我们打开电脑软件或许游戏时候,电脑会报错出现d3dx9_43.dll丢失,或许找不到d3dx9_43.dll等等的提示。下面来详细介绍一下d3dx9_43.dll详细解决方法跟d3dx9_43.dll是什么。 如果你的系统中没有安装或安装不完整的d3dx9_43.dll运行时,应…...

篇四:建造者模式:逐步构造复杂对象
篇四:“建造者模式:逐步构造复杂对象” 设计模式是软件开发中的重要组成部分,建造者模式是创建型设计模式中的一种。建造者模式旨在逐步构造复杂对象,将对象的构造与其表示分离,从而使得同样的构建过程可以创建不同的…...
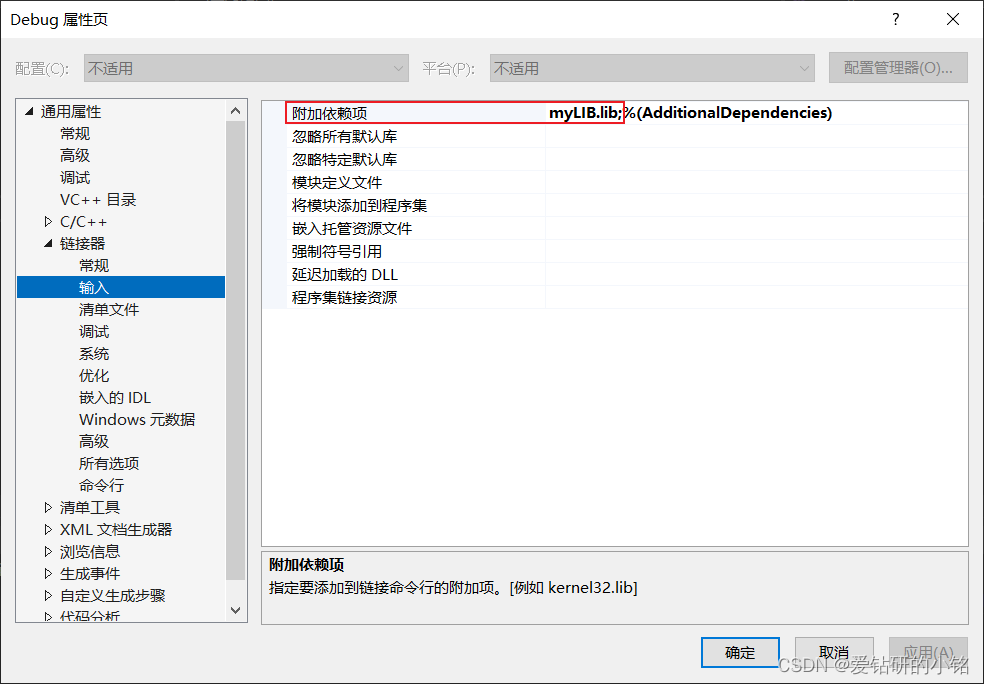
vs导出和导入动态库和静态库
1. 动态库和导出和导入 1.1 动态库的导出 1. 创建新项目 新建新项目,选择动态链接库(DLL)。 填写项目名称,并选择项目保存的路径,然后点击创建。 创建完成后,会自动生成如下所示文件,可以根据…...

30 使用easyExcel依赖生成Excel
30.1 导入依赖 <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>2.2.6</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId&…...
排序进行曲-v2.0
文章目录 小程一言直接插入排序步骤举例复杂度分析应用场景实际举例代码实现 希尔排序步骤举例复杂度分析应用场景实际举例代码实现 堆排序步骤举例复杂度分析应用场景实际举例代码实现 小程一言 这篇文章是在排序进行曲1.0之后的续讲, 由于在上一篇讲的排序的基本…...
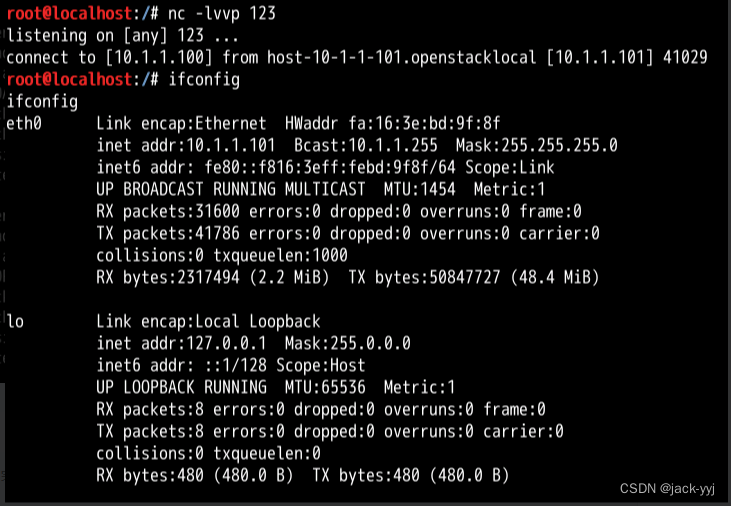
反弹shell的N种姿势
预备知识1. 关于反弹shell 就是控制端监听在某TCP/UDP端口,被控端发起请求到该端口,并将其命令行的输入输出转到控制端。reverse shell与telnet,ssh等标准shell对应,本质上是网络概念的客户端与服务端的角色反转。2. 反弹shel…...
创意视频剪辑教程:快速合并视频并标题,让你的作品更吸睛!
想要让你的视频作品脱颖而出,引人注目?不再担心,我们为你带来了一款创意视频剪辑教程,教你如何快速合并视频并添加令人惊艳的标题效果!让你的作品在分钟内变得酷炫而精彩,向世界展示你的创意! …...

独立开发者如何借助Taotoken多模型能力打造全能AI助手应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力打造全能AI助手应用 对于独立开发者或小型工作室而言,构建一个功能全面的AI助手…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

Pandrator:基于Python的自动化内容生成与数据转换工具实践
1. 项目概述与核心价值最近在折腾一些自动化数据处理和内容生成的工作流,发现了一个挺有意思的开源项目,叫Pandrator。乍一看这个名字,可能会联想到“潘多拉”和“生成器”的结合,实际上它也确实是一个功能强大的内容转换与生成工…...

【最新v2.7.1 版本安装包】OpenClaw 小白入门必看,零基础无需命令零代码保姆级教学
OpenClaw v2.7.1 一键安装部署教程|可视化傻瓜式搭建 ✨适配系统:Windows10/11 64 位 ✨当前版本:v2.7.1 版本(虾壳云版) ✨安装包大小:58.7MB 【点击下载最新安装包】https://xiake.yun/api/download/…...

构建团队技能仓库:从知识管理到可执行技能包的系统化实践
1. 项目概述:从“技能包”到高效能工具箱最近在梳理团队内部的技术资产时,我反复思考一个问题:如何让那些散落在个人电脑、项目文档和口头交流中的“隐性知识”和“高效技能”,变成一个团队可以随时取用、持续进化的公共资产&…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...

Otter多模态大模型实战:从架构解析到部署应用的完整指南
1. 项目概述:当多模态大模型学会“看”与“说”最近在开源社区里,一个名为Otter的多模态大模型项目引起了我的注意。它来自EvolvingLMMs-Lab,这个实验室的名字就很有意思,“Evolving LMMs”—— 进化中的大型多模态模型。Otter 这…...