为什么list.sort()比Stream().sorted()更快?
真的更好吗?
先简单写个demo
List<Integer> userList = new ArrayList<>();Random rand = new Random();for (int i = 0; i < 10000 ; i++) {userList.add(rand.nextInt(1000));}List<Integer> userList2 = new ArrayList<>();userList2.addAll(userList);Long startTime1 = System.currentTimeMillis();userList2.stream().sorted(Comparator.comparing(Integer::intValue)).collect(Collectors.toList());System.out.println("stream.sort耗时:"+(System.currentTimeMillis() - startTime1)+"ms");Long startTime = System.currentTimeMillis();userList.sort(Comparator.comparing(Integer::intValue));System.out.println("List.sort()耗时:"+(System.currentTimeMillis()-startTime)+"ms");输出
stream.sort耗时:62ms
List.sort()耗时:7ms由此可见list原生排序性能更好。
能证明吗?
证据错了。
再把demo变换一下,先输出stream.sort
List<Integer> userList = new ArrayList<>();Random rand = new Random();for (int i = 0; i < 10000 ; i++) {userList.add(rand.nextInt(1000));}List<Integer> userList2 = new ArrayList<>();userList2.addAll(userList);Long startTime = System.currentTimeMillis();userList.sort(Comparator.comparing(Integer::intValue));System.out.println("List.sort()耗时:"+(System.currentTimeMillis()-startTime)+"ms");Long startTime1 = System.currentTimeMillis();userList2.stream().sorted(Comparator.comparing(Integer::intValue)).collect(Collectors.toList());System.out.println("stream.sort耗时:"+(System.currentTimeMillis() - startTime1)+"ms");此时输出变成了
List.sort()耗时:68ms
stream.sort耗时:13ms这能证明上面的结论错误了吗?
都不能。
两种方式都不能证明什么。
使用这种方式在很多场景下是不够的,某些场景下,JVM会对代码进行JIT编译和内联优化。
Long startTime = System.currentTimeMillis();
...
System.currentTimeMillis() - startTime此时,代码优化前后执行的结果就会非常大。
基准测试是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试。基准测试使得被测试代码获得足够预热,让被测试代码得到充分的JIT编译和优化。
下面是通过JMH做一下基准测试,分别测试集合大小在100,10000,100000时两种排序方式的性能差异。
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;import java.util.*;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 2, time = 1)
@Measurement(iterations = 5, time = 5)
@Fork(1)
@State(Scope.Thread)
public class SortBenchmark {@Param(value = {"100", "10000", "100000"})private int operationSize; private static List<Integer> arrayList;public static void main(String[] args) throws RunnerException {// 启动基准测试Options opt = new OptionsBuilder().include(SortBenchmark.class.getSimpleName()) .result("SortBenchmark.json").mode(Mode.All).resultFormat(ResultFormatType.JSON).build();new Runner(opt).run(); }@Setuppublic void init() {arrayList = new ArrayList<>();Random random = new Random();for (int i = 0; i < operationSize; i++) {arrayList.add(random.nextInt(10000));}}@Benchmarkpublic void sort(Blackhole blackhole) {arrayList.sort(Comparator.comparing(e -> e));blackhole.consume(arrayList);}@Benchmarkpublic void streamSorted(Blackhole blackhole) {arrayList = arrayList.stream().sorted(Comparator.comparing(e -> e)).collect(Collectors.toList());blackhole.consume(arrayList);}}性能测试结果:

可以看到,list sort()效率确实比stream().sorted()要好。
为什么更好?
流本身的损耗
java的stream让我们可以在应用层就可以高效地实现类似数据库SQL的聚合操作了,它可以让代码更加简洁优雅。
但是,假设我们要对一个list排序,得先把list转成stream流,排序完成后需要将数据收集起来重新形成list,这部份额外的开销有多大呢?
我们可以通过以下代码来进行基准测试
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 2, time = 1)
@Measurement(iterations = 5, time = 5)
@Fork(1)
@State(Scope.Thread)
public class SortBenchmark3 {@Param(value = {"100", "10000"})private int operationSize; // 操作次数private static List<Integer> arrayList;public static void main(String[] args) throws RunnerException {// 启动基准测试Options opt = new OptionsBuilder().include(SortBenchmark3.class.getSimpleName()) // 要导入的测试类.result("SortBenchmark3.json").mode(Mode.All).resultFormat(ResultFormatType.JSON).build();new Runner(opt).run(); // 执行测试}@Setuppublic void init() {// 启动执行事件arrayList = new ArrayList<>();Random random = new Random();for (int i = 0; i < operationSize; i++) {arrayList.add(random.nextInt(10000));}}@Benchmarkpublic void stream(Blackhole blackhole) {arrayList.stream().collect(Collectors.toList());blackhole.consume(arrayList);}@Benchmarkpublic void sort(Blackhole blackhole) {arrayList.stream().sorted(Comparator.comparing(Integer::intValue)).collect(Collectors.toList());blackhole.consume(arrayList);}}方法stream测试将一个集合转为流再收集回来的耗时。
方法sort测试将一个集合转为流再排序再收集回来的全过程耗时。
测试结果如下:

可以发现,集合转为流再收集回来的过程,肯定会耗时,但是它占全过程的比率并不算高。
因此,这部只能说是小部份的原因。
排序过程
我们可以通过以下源码很直观的看到。
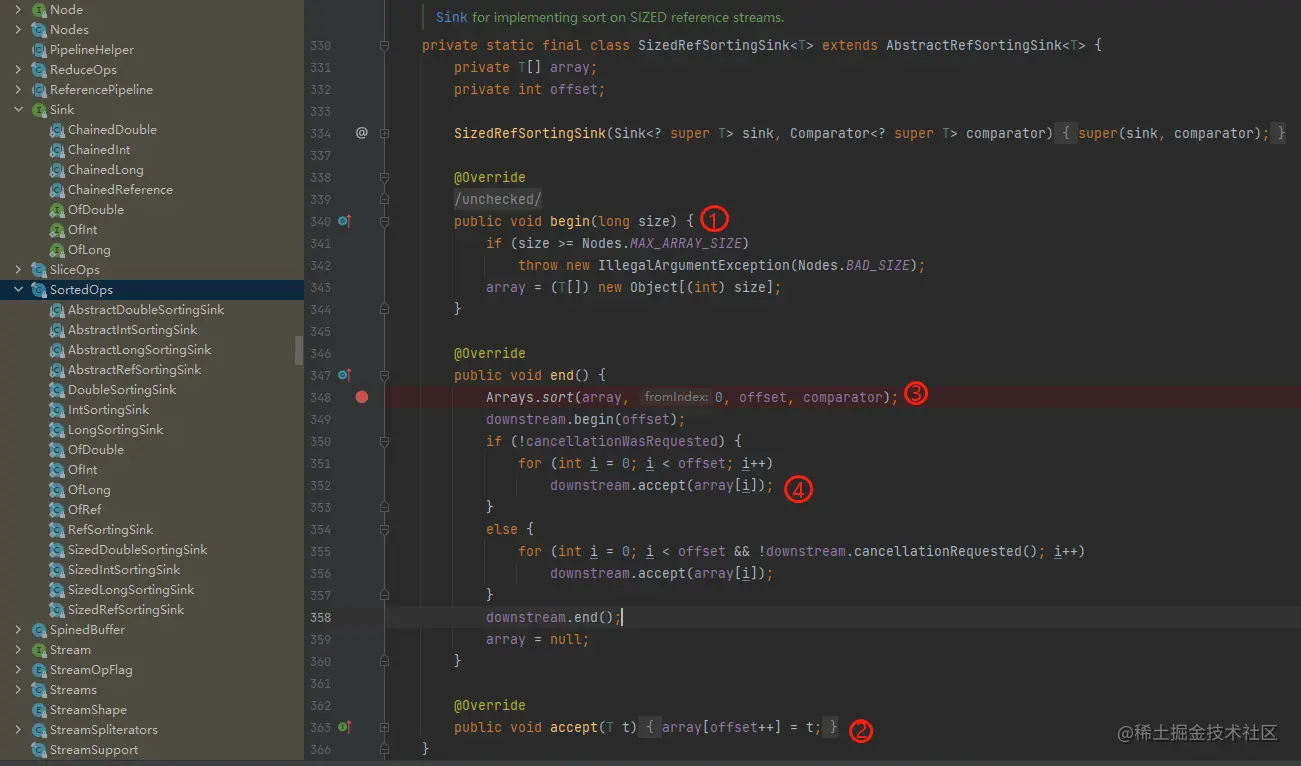
- 1 begin方法初始化一个数组。
- 2 accept 接收上游数据。
- 3 end 方法开始进行排序。
这里第3步直接调用了原生的排序方法,完成排序后,第4步,遍历向下游发送数据。
所以通过源码,我们也能很明显地看到,stream()排序所需时间肯定是 > 原生排序时间。
只不过,这里要量化地搞明白,到底多出了多少,这里得去编译jdk源码,在第3步前后将时间打印出来。
这一步我就不做了。
感兴趣的朋友可以去测一下。
不过我觉得这两点也能很好地回答,为什么list.sort()比Stream().sorted()更快。
补充说明:
- 本文说的stream()流指的是串行流,而不是并行流。
- 绝大多数场景下,几百几千几万的数据,开心就好,怎么方便怎么用,没有必要去计较这点性能差异。
相关文章:
为什么list.sort()比Stream().sorted()更快?
真的更好吗? 先简单写个demo List<Integer> userList new ArrayList<>();Random rand new Random();for (int i 0; i < 10000 ; i) {userList.add(rand.nextInt(1000));}List<Integer> userList2 new ArrayList<>();userList2.add…...

SQL账户SA登录失败,提示错误:18456
错误代码 18456 表示 SQL Server 登录失败。这个错误通常表示提供的凭据(用户名和密码)无法成功验证或者没有权限访问所请求的数据库。以下是一些常见的可能原因和解决方法: 1.错误的凭据:请确认提供的SA账户的用户名和密码是否正…...
Linux 终端操作命令(1)
Linux 命令 终端命令格式 command [-options] [parameter] 说明: command:命令名,相应功能的英文单词或单词的缩写[-options]:选项,可用来对命令进行控制,也可以省略parameter:传给命令的参…...

java与javaw运行jar程序
运行jar程序 一、java.exe启动jar程序 (会显示console黑窗口) 1、一般用法: java -jar myJar.jar2、重命名进程名称启动: echo off copy "%JAVA_HOME%\bin\java.exe" "%JAVA_HOME%\bin\myProcess.exe" myProcess -jar myJar.jar e…...

安装和配置 Home Assistant 教程 HACS Homkit 米家等智能设备接入
安装和配置 Home Assistant 教程 简介 Home Assistant 是一款开源的智能家居自动化平台,可以帮助你集成和控制各种智能设备,从灯光到温度调节器,从摄像头到媒体播放器。本教程将引导你如何在 Docker 环境中安装和配置 Home Assistant&#…...

解决 Android Studio 的 Gradle 面板上只有关于测试的 task 的问题
文章目录 问题描述解决办法 笔者出问题时的运行环境: Android Studio Flamingo | 2022.2.1 Android SDK 33 Gradle 8.0.1 JDK 17 问题描述 笔者最近发现一个奇怪的事情。笔者的 Android Studio 的 Gradle 面板上居然除了用于测试的 task 之外,其它什…...
安全杂记 - 复现nodejs沙箱绕过
目录 一. 配置环境1.下载nodejs2.nodejs配置3.报错解决方法 二. nodej沙箱绕过1. vm模块2.使用this或引用类型来进行沙箱绕过 一. 配置环境 1.下载nodejs 官网:https://nodejs.org/en2.nodejs配置 安装nodejs的msi文件,默认配置一直下一步即可&#x…...

信息安全事件分类分级指南
范围 本指导性技术文件为信息安全事件的分类分级提供指导,用于信息安全事件的防范与处置,为事前准备、事中应对、事后处理 提供一个基础指南,可供信息系统和基础信息传输网络的运营和使用单位以及信息安全主管部门参考使用。 术语和定义 下…...

Vue系列第八篇:echarts绘制柱状图和折线图
本篇将使用echarts框架进行柱状图和折线图绘制。 目录 1.绘制效果 2.安装echarts 3.前端代码 4.后端代码 1.绘制效果 2.安装echarts // 安装echarts版本4 npm i -D echarts4 3.前端代码 src/api/api.js //业务服务调用接口封装import service from ../service.js //npm …...
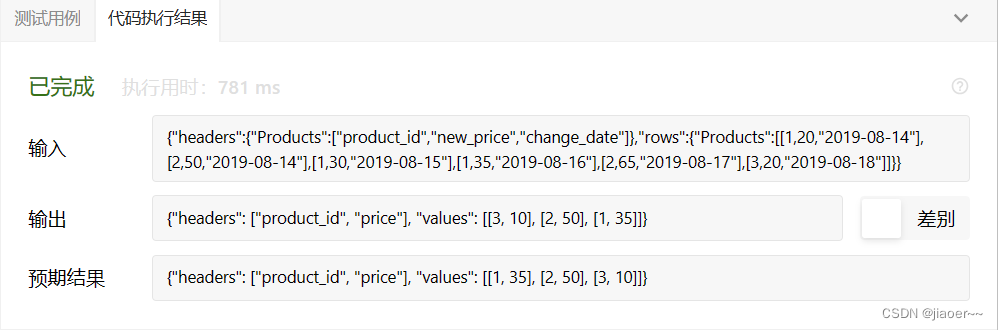
SQL-每日一题【1164. 指定日期的产品价格】
题目 产品数据表: Products 写一段 SQL来查找在 2019-08-16 时全部产品的价格,假设所有产品在修改前的价格都是 10 。 以 任意顺序 返回结果表。 查询结果格式如下例所示。 示例 1: 解题思路 1.题目要求我们查找在 2019-08-16 时全部产品的价格,假设所…...

memcpy、memmove、memcmp、memset函数的作用与区别
一、memcpy与memmove 1、memcpy 作用:从source的位置开始向后复制num个字节的数据到destination的内存位置。 注意: memcpy() 函数在遇到 ’\0’ 的时候不会停下来(strcpy字符串拷贝函数在遇到’\0’的时候会停下来);destination和source…...

socket 到底是个啥
我相信大家在面试过程中或多或少都会被问到这样一个问题:你能解释一下什么是 socket 吗 我记得我当初的回答很是浅显:socket 也叫套接字,用来负责不同主机程序之间的网络通信连接,socket 的表现方式由四元组(ip地址&am…...

奥威BI—数字化转型首选,以数据驱动企业发展
奥威BI系统BI方案可以迅速构建企业级大数据分析平台,可以将大量数据转化为直观、易于理解的图表和图形,推动和促进数字化转型的进程,帮助企业更好地了解自身的运营状况,及时发现问题并采取相应的措施,提高运营效率和质…...

vue中swiper使用
1.引包 说明:导入相应js引css import "Swiper" from "swiper" import "swiper/css/swiper.css"; import "swiper/js/swiper"; 2.结构 说明:必要的结构使用;直接封装成一个组件 <template>…...

webpack与vite区别
webpack和Vite作为两种常用的前端构建工具,主要有以下几点区别: 构建速度 webpack采用“打包”的方式构建,需要将所有模块打包成几个大的bundle文件,构建速度较慢。 Vite采用了“按需编译”的方式,只在浏览器请求时才编译对应模块,启动速度更快。 dev server webpack dev s…...
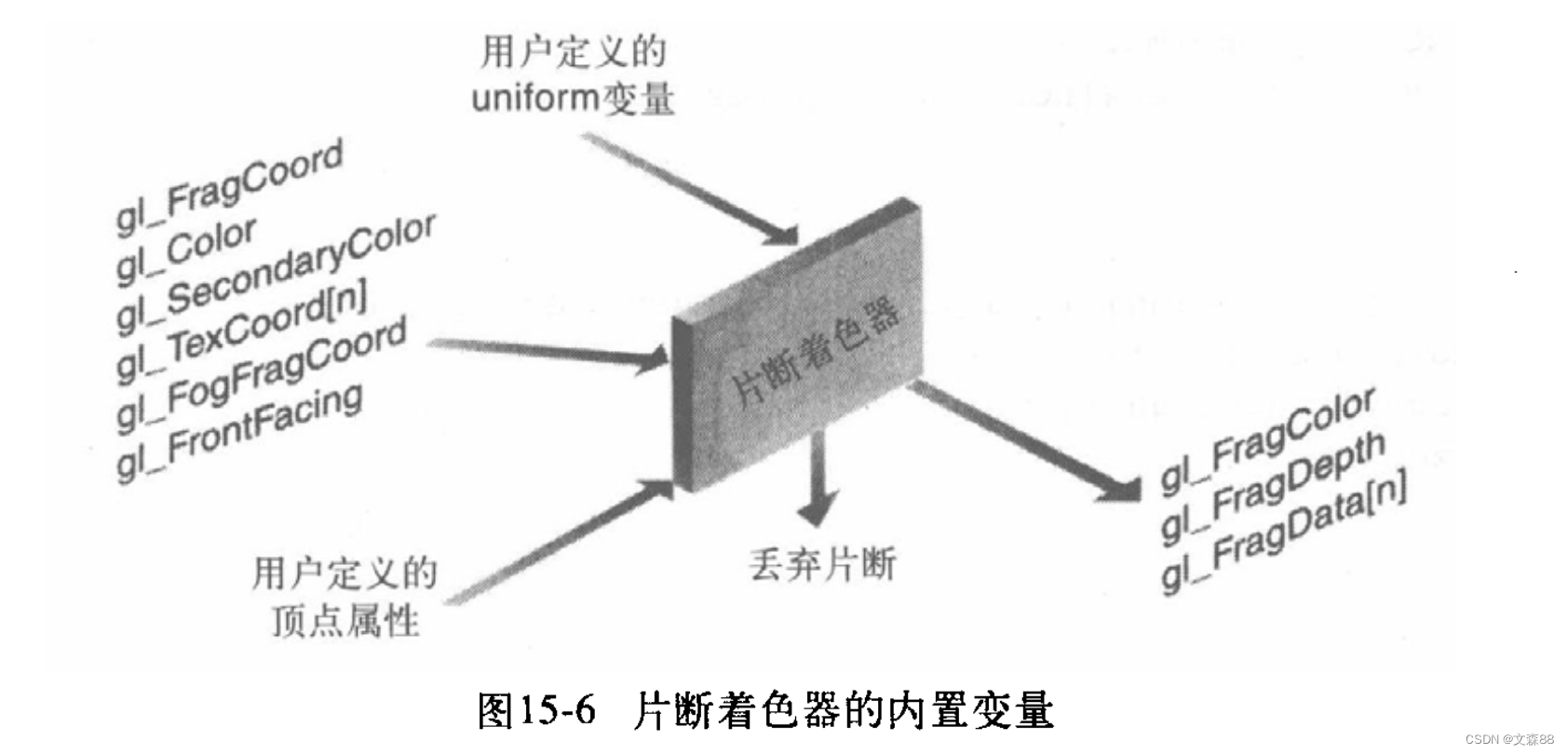
GLSL用于图像处理
Pipeline 硬件处理顶点和片段的Pipeline 软件的输入 顶点着色器 顶点的glsl 输入–特殊全局变量 变量 类型 指定函数 描述 gl_ Vertex vec4 glVertex 顶点的全局空间坐标 gl_Color vec4 glColor 主颜色值 gl_SecondaryColor vec4 glSecondaryColor 辅助颜色值 gl_Normal …...

即将发布的 Kibana 版本可运行 Node.js 18
作者:Thomas Watson Kibana 构建在 Node.js 框架之上。 为了确保每个 Kibana 版本的稳定性和使用寿命,我们始终将捆绑的 Node.js 二进制文件保持为最新的最新长期支持 (LTS) 版本。 当 Node.js 版本 18 升级到 LTS 时,我们开始将 Kibana 升级…...

基于遗传算法改进的支持向量机多分类仿真,基于GA-SVM的多分类预测,支持相机的详细原理
目录 背影 支持向量机SVM的详细原理 SVM的定义 SVM理论 遗传算法的原理及步骤 SVM应用实例,基于遗传算法优化SVM的多分类预测 完整代码包括SVM工具箱:https://download.csdn.net/download/abc991835105/88175549 代码 结果分析 展望 背影 多分类预测对现代智能化社会拥有重…...
MySQL5.7源码编译Debug版本
编译环境Ubuntu22.04LTS 1 官方下载MySQL源码 https://dev.mysql.com/downloads/mysql/?spma2c6h.12873639.article-detail.4.68e61a14ghILh5 2 安装基础软件 cmakeclangpkg-configperl 参考:https://dev.mysql.com/doc/refman/5.7/en/source-installation-prere…...
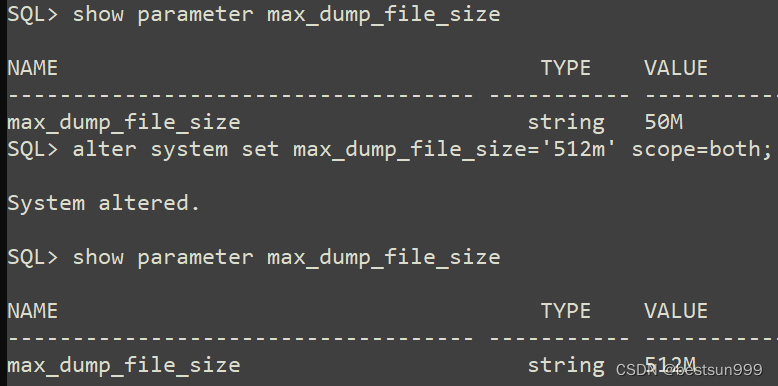
ORA-48913: Writing into trace file failed, file size limit [50000000] reached
检查某环境的alert_orcl1.log时,发现有很多的ORA-48913报错,细节如下 Sat Jul 22 19:34:04 2023 Non critical error ORA-48913 caught while writing to trace file "/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_dw00_138010.trc" E…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

告别标题栏!在RK3568 Buildroot固件上,让你的Qt应用开机全屏显示的保姆级教程
RK3568嵌入式全屏实战:从Weston配置到Qt应用独占显示的完整指南 在嵌入式Linux系统开发中,GUI应用的全屏显示往往成为工程师面临的第一个"拦路虎"。当你在RK3568平台上精心开发的Qt应用启动后,却发现屏幕顶部顽固地挂着Weston窗口管…...

CircuitPython Web Workflow实战:无线开发Yoto Mini与I2C硬件验证
1. 项目概述与核心价值如果你玩过像树莓派Pico或者ESP32这类微控制器,肯定对“插拔-编程-调试”这个循环不陌生。每次改几行代码,就得拔下USB线,重新上电,然后盯着串口监视器看输出。这个过程在项目初期调试硬件时,尤其…...
:从F0曲线调制到微表情时序对齐)
ElevenLabs情绪驱动API实战手册(2024企业级部署全链路):从F0曲线调制到微表情时序对齐
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪驱动API核心架构与演进脉络 ElevenLabs 的情绪驱动 API 并非简单叠加情感标签的语音合成增强层,而是构建在多模态表征学习与实时声学参数调控双引擎之上的闭环系统。其核心架…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

【Canvas动画录制实战】从WebM到MP4:MediaRecorder全流程解析与避坑指南
1. Canvas动画录制基础与准备工作 如果你正在开发一个数据可视化项目或者HTML5小游戏,可能会遇到需要将动态内容保存为视频的需求。Canvas动画录制就是解决这个问题的关键技术方案。相比传统的录屏软件,直接通过代码录制能获得更清晰的画质,还…...

【模拟电路】Circuit JS:从零到一,构建你的首个交互式电路实验
1. 初识Circuit JS:你的虚拟电路实验室 第一次接触Circuit JS时,我正为一个简单的LED电路设计发愁。传统仿真软件要么安装复杂,要么收费昂贵,直到发现这个直接在浏览器里运行的免费工具。打开网页的瞬间,就像走进了中学…...

从Awesome List到个人知识库:开发者如何高效筛选与组织技术资源
1. 项目概述:一份面向开发者的“Awesome List”清单 如果你在GitHub上混迹过一段时间,尤其是热衷于探索前沿技术、寻找优质学习资源或开源项目,那么你大概率见过或者使用过一种特殊的仓库—— Awesome List 。简单来说,这是一个…...

奥里亚语语音合成准确率骤降?揭秘ElevenLabs最新v4.2模型在Odisha方言中的5大发音偏差与3步校准法
更多请点击: https://intelliparadigm.com 第一章:奥里亚语语音合成准确率骤降现象全景透视 近期多个基于深度学习的奥里亚语(Odia)TTS系统在部署后出现显著性能退化:词级发音准确率从92.4%骤降至73.1%,尤…...