【Python】Locust持续优化:InfluxDB与Grafana实现数据持久化与可视化分析
目录
前言
influxDB
安装运行InfluxDB
用Python 上报数据到influxdb
ocust 数据写入到 influx
Locust的生命周期
上报数据
优化升级
配置Grafana
总结
资料获取方法
前言
在进行性能测试时,我们需要对测试结果进行监控和分析,以便于及时发现问题并进行优化。
Locust在内存中维护了一个时间序列数据结构,用于存储每个事件的统计信息。 这个数据结构允许我们在Charts标签页中查看不同时间点的性能指标,但是正因为Locust WebUI上展示的数据实际上是存储在内存中的。所以在Locust测试结束后,这些数据将不再可用。 如果我们需要长期保存以便后续分析测试数据,可以考虑将Locust的测试数据上报到外部的数据存储系统,如InfluxDB,并使用Grafana等可视化工具进行展示和分析。
本文将介绍如何使用Locust进行负载测试,并将测试数据上报到InfluxDB。同时,我们将使用Grafana对测试数据进行展示和分析。
最终效果:
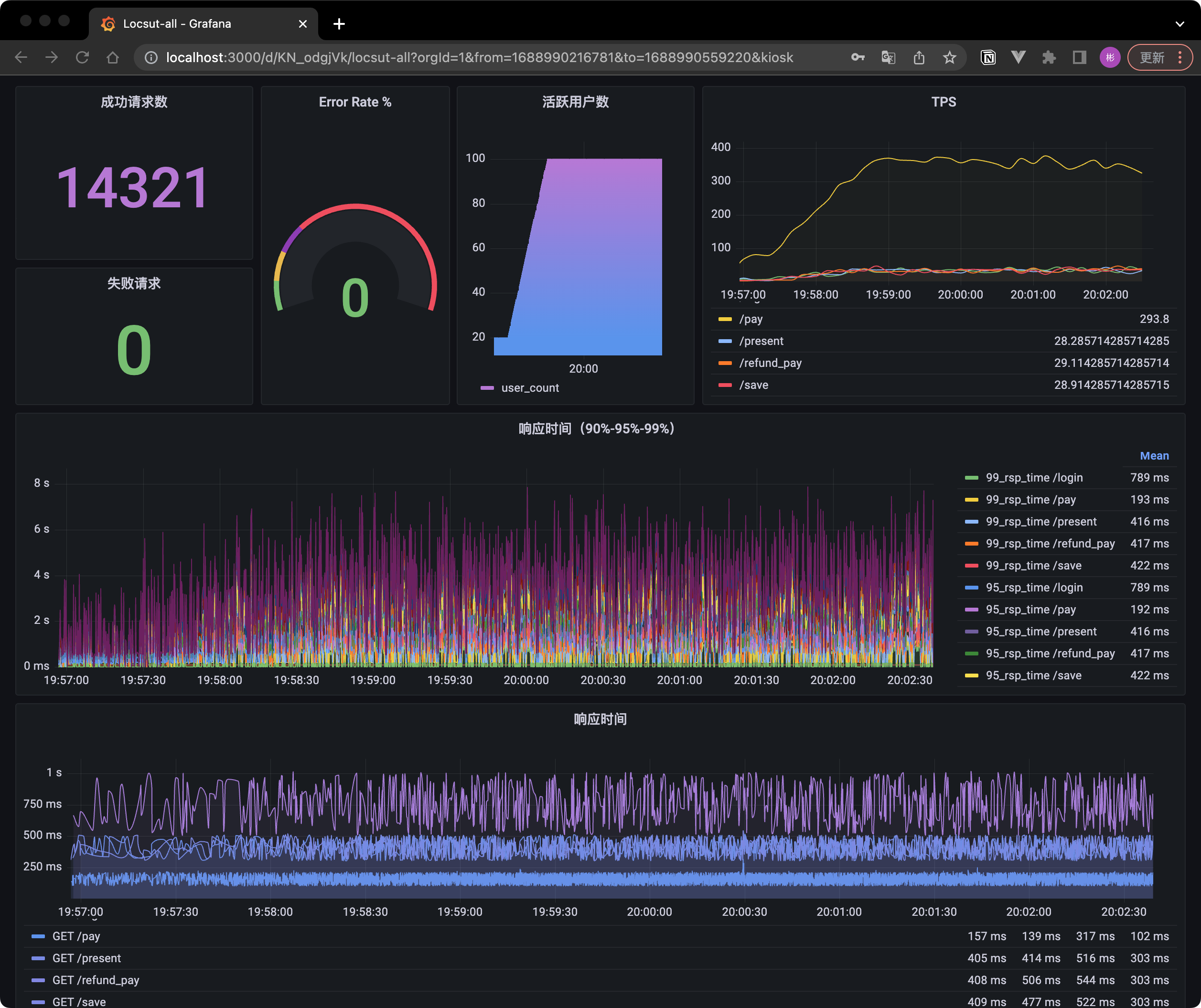
influxDB
InfluxDB是一款开源的时间序列数据库,专为处理大量的时间序列数据而设计。时间序列数据通常是按照时间顺序存储的数据点,每个数据点都包含一个时间戳和一个或多个与之相关的值。这种数据类型在许多场景下都非常常见,如监控系统、物联网设备、金融市场数据等。在这些场景下,数据上报是一种关键的需求,因为它可以帮助我们实时了解系统的状态和性能。
注: InfluxDB 开源的时单机版本,集群版本并未开元,但是对于普通用户的日常场景已经完全够用。
以下是关于InfluxDB的关键特性和优势的表格:
| 特性 | 优势 |
|---|---|
| 高性能 | 针对时间序列数据进行了优化,可以快速地写入和查询大量数据。 |
| 数据压缩 | 使用了高效的数据压缩算法,在磁盘上节省大量空间。 |
| 自带查询语言 | 具有一种名为InfluxQL的查询语言,类似于SQL,便于查询和分析数据。 |
| 数据保留策略 | 支持设置数据保留策略,可以自动清除过期的数据。 |
| 易于集成 | 具有丰富的API和客户端库,可以轻松地与其他系统和工具集成。 |
安装运行InfluxDB
如果你已经安装了Docker,可以直接使用官方的InfluxDB镜像来运行InfluxDB:
docker run -p 8086:8086 -v $PWD:/var/lib/influxdb influxdb:1.8
此命令将在Docker容器中启动InfluxDB,并将主机上的8086端口映射到容器的8086端口。
点击查看在如何在不同操作系统中如何安装 InfluxDB
用Python 上报数据到influxdb
首先,确保已经安装了influxdb库:
pip install influxdb
然后,使用以下代码上报数据到InfluxDB:
以下是一个使用Python操作InfluxDB上报数据的示例,对照MySQL进行注释:
import time
from influxdb import InfluxDBClient# 连接到InfluxDB(类似于连接到MySQL数据库)
client = InfluxDBClient(host='localhost', port=8086)# 创建数据库(类似于在MySQL中创建一个新的数据库)
client.create_database('mydb')# 切换到创建的数据库(类似于在MySQL中选择一个数据库)
client.switch_database('mydb')# 上报数据(类似于在MySQL中插入一条记录)
data = [{# 在InfluxDB中,measurement相当于MySQL中的表名"measurement": "cpu_load",# tags相当于MySQL中的索引列,用于快速查询"tags": {"host": "server01","region": "us-west"},# time为时间戳,是InfluxDB中的关键字段"time": int(time.time_ns()),# fields相当于MySQL中的数据列,用于存储实际的数据值"fields": {"value": 0.64}}
]# 写入数据(类似于在MySQL中执行INSERT语句)
client.write_points(data)
在这个示例中,我们首先连接到InfluxDB(类似于连接到MySQL数据库),然后创建一个名为mydb的数据库(类似于在MySQL中创建一个新的数据库),并切换到创建的数据库(类似于在MySQL中选择一个数据库)。接着,我们准备了一条名为cpu_load的数据(在InfluxDB中,measurement相当于MySQL中的表名),并为数据添加了host和region标签(类似于MySQL中的索引列)。最后,我们将数据写入到InfluxDB中(类似于在MySQL中执行INSERT语句)。
执行上面的代码后我们可以看到我们的操作成功了:
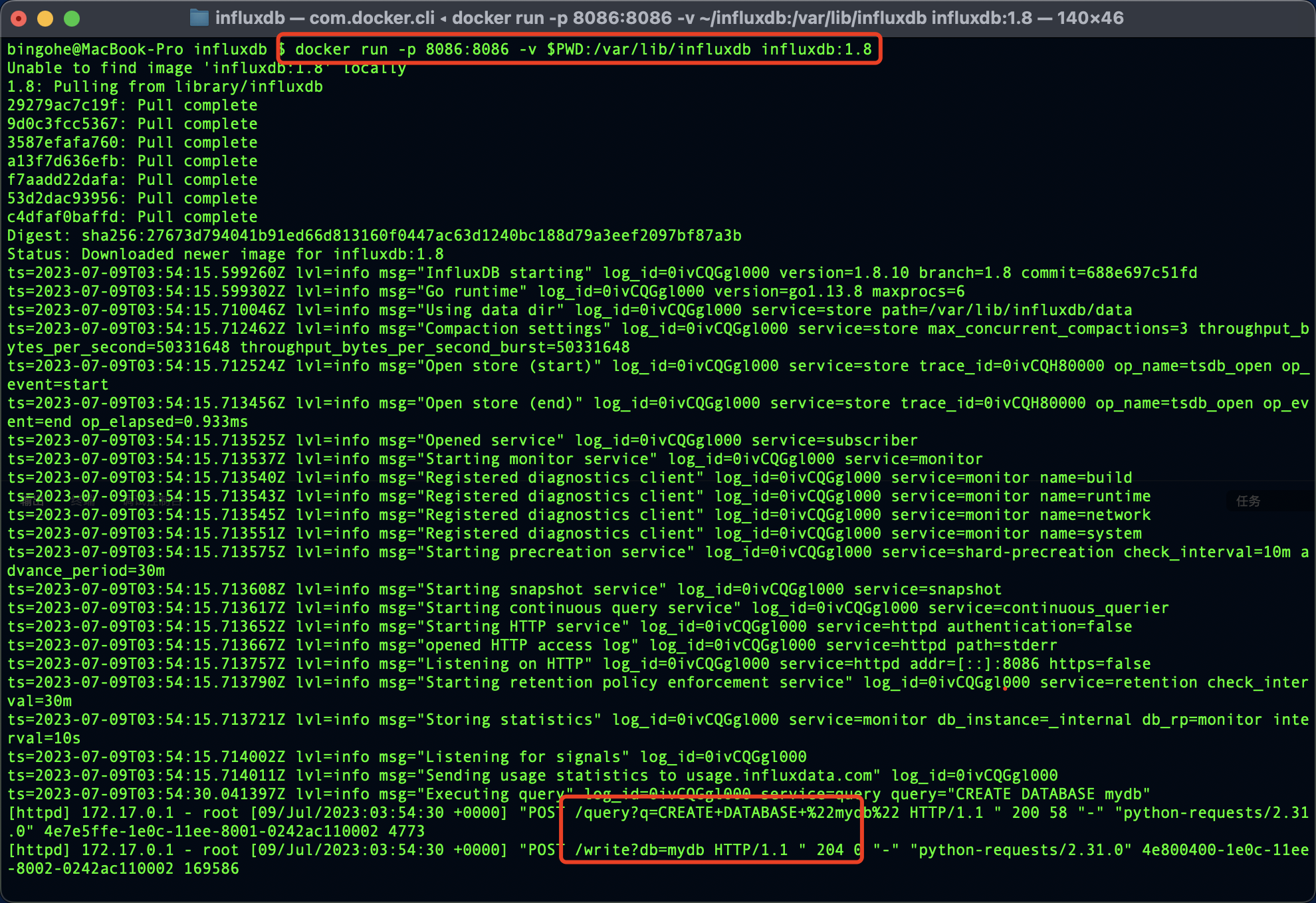
如果我们安装了influx-cli就可以在命令行中直接查询刚才写入的数据:
bingohe@MacBook-Pro ~ $ /usr/local/Cellar/influxdb@1/1.11.1/bin/influx
Connected to http://localhost:8086 version 1.8.10
InfluxDB shell version: 1.11.1
> show databases;
name: databases
name
----
_internal
mydb
> use mydb
Using database mydb
> show measurements;
name: measurements
name
----
cpu_load
> select * from cpu_load;
name: cpu_load
time host region value
---- ---- ------ -----
1688874870046897000 server01 us-west 0.64
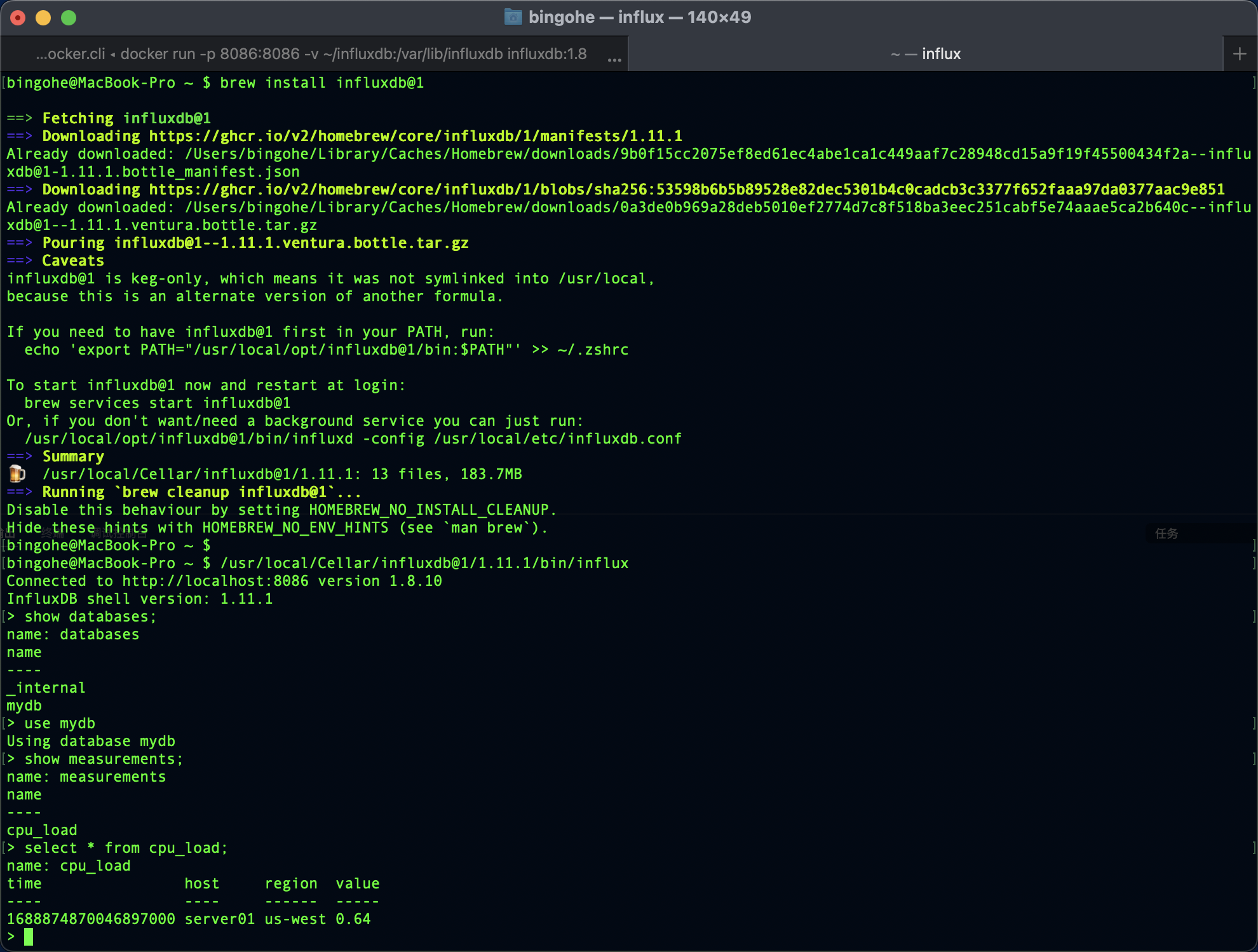
点击查看如何使用命令行访问InfluxDB
ocust 数据写入到 influx
在 【Python】万字长文,Locust 性能测试指北(上) 中我们提到过Locust的生命周期,我们也通过Locust生命周期实现了集合点的功能。现在我们一起来通过它实现测试数据的实时展示。
Locust的生命周期
点击查看Locust的生命周期
上报数据
我们先来看看常用的事件里面可以获取到的数据:
import time
from locust import HttpUser, task, between, events@events.request.add_listener
def request_handler(*args, **kwargs):print(f"request args: {args}")print(f"request kwargs: {kwargs}")@events.worker_report.add_listener
def worker_report_handlers(*args, **kwargs):print(f"worker_report args: {args}")print(f"worker_report kwargs: {kwargs}")@events.test_start.add_listener
def test_start_handlers(*args, **kwargs):print(f"test_start args: {args}")print(f"test_start kwargs: {kwargs}")@events.test_stop.add_listener
def test_stop_handlers(*args, **kwargs):print(f"test_stop args: {args}")print(f"test_stop kwargs: {kwargs}")class QuickstartUser(HttpUser):wait_time = between(1, 2)@taskdef root(self):with self.client.get("/", json={"time": time.time()}, catch_response=True) as rsp:rsp_json = rsp.json()if rsp_json["id"] != 5:# 失败时上报返回的数据rsp.failure(f"{rsp_json}")
运行一次测试时能看到这些生命周期内的Locust 对外暴露的数据:
test_start args: ()
test_start kwargs: {'environment': <locust.env.Environment object at 0x10c426c70>}
request args: ()
request kwargs: {'request_type': 'GET', 'response_time': 2.6886250000011103, 'name': '/', 'context': {}, 'response': <Response [200]>, 'exception': None, 'start_time': 1688888321.896039, 'url': 'http://0.0.0.0:10000/', 'response_length': 8}
request args: ()
request kwargs: {'request_type': 'GET', 'response_time': 2.735957999998817, 'name': '/', 'context': {}, 'response': <Response [200]>, 'exception': CatchResponseError("{'id': 6}"), 'start_time': 1688888323.421389, 'url': 'http://0.0.0.0:10000/', 'response_length': 8}
test_stopping args: ()
test_stopping kwargs: {'environment': <locust.env.Environment object at 0x10c426c70>}
test_stop args: ()
test_stop kwargs: {'environment': <locust.env.Environment object at 0x10c426c70>}
从上面的监控我们可以看到,每次任务启动和停止的时候会分别调用@events.test_start.add_listener和@events.test_stop.add_listener装饰的函数,每次请求发生的的时候都会调用@events.request.add_listener 监听器装饰的函数,我们就是要利用这一点来进行数据的上报。
通过查看 Locust 的 EventHook 源码注释我们可以看到标准的使用方法:
#.../site-packages/locust/event.py
...
class EventHook:"""Simple event class used to provide hooks for different types of events in Locust.Here's how to use the EventHook class::my_event = EventHook()def on_my_event(a, b, **kw):print("Event was fired with arguments: %s, %s" % (a, b))my_event.add_listener(on_my_event)my_event.fire(a="foo", b="bar")If reverse is True, then the handlers will run in the reverse orderthat they were inserted"""
...
结合前面的写数据到 influxDB的实现,上报数据这一项一下子就变简单了:
简单实现每次请求数据上报 到 influxDB
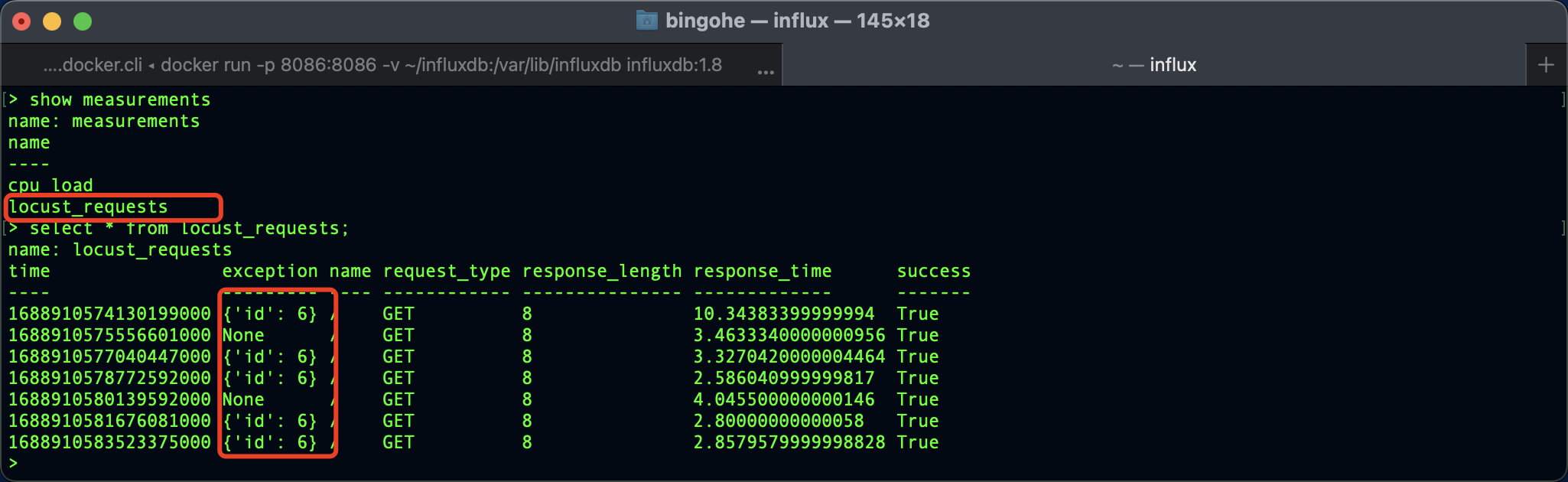
下面的代码运行Locust测试后会自动创建一个locust_requests的 measurement,然后将每次请求的数据上报。
运行方法可以参考我的上一篇文章
import time
from datetime import datetime
from influxdb import InfluxDBClientfrom locust import HttpUser, task, between, eventsclient = InfluxDBClient(host='localhost', port=8086, database="mydb")def request(request_type, name, response_time, response_length, response, context, exception, url, start_time):_time = datetime.utcnow()was_successful = Trueif response:was_successful = 199 < response.status_code < 400tags = {'request_type': request_type,'name': name,'success': was_successful,'exception': str(exception),}fields = {'response_time': response_time,'response_length': response_length,}data = {"measurement": 'locust_requests', "tags": tags, "time": _time, "fields": fields}client.write_points([data])# 在每次请求的时候通过前面定义的request函数写数据到 DB
events.request.add_listener(request)class QuickstartUser(HttpUser):wait_time = between(1, 2)@taskdef root(self):with self.client.get("/", json={"time": time.time()}, catch_response=True) as rsp:rsp_json = rsp.json()if rsp_json["id"] != 5:rsp.failure(f"{rsp_json}")
上报的数据 influxDB 中查询到:
优化升级
上面的这个上报很粗糙,每次请求会上报一次数据,会影响实际的压测,如果我们将要上报的数据放在一个数据结构中中,异步的上报这个数据将极大的提升性能
# 将 __flush_points 方法中的写入操作放到一个单独的线程中,避免阻塞主线程,提高性能。
self.write_thread = threading.Thread(target=self.__write_points_worker)# 批量写入
if len(self.write_batch) >= self.batch_size or time.time() - self.last_flush_time >= self.interval_ms / 1000:# 使用 gzip 压缩上报的数据
influxdb_writer = InfluxDBWriter('localhost', 8086, 'mydb', batch_size=1000, gzip_enabled=True)
...
配置Grafana
在测试数据被上报到InfluxDB之后,可以通过Grafana进行数据展示和分析。需要先在Grafana中配置InfluxDB数据源,然后创建相应的图表和仪表盘。
在创建图表和仪表盘时,可以选择InfluxDB作为数据源,并使用InfluxQL查询语言进行数据查询和过滤。可以根据需要选择不同的图表类型和显示方式,以展示测试结果数据的趋势和变化。
总结
本文介绍了如何将Locust测试数据上报到InfluxDB,并通过Grafana进行展示和分析。通过将测试数据与监控工具相结合,可以更好地了解系统的性能和稳定性,及时发现问题并进行优化,也可以方便后续进行测试数据分析。希望本文能对大家有所帮助。
资料获取方法
【留言777】


各位想获取源码等教程资料的朋友请点赞 + 评论 + 收藏,三连!
三连之后我会在评论区挨个私信发给你们~
相关文章:
【Python】Locust持续优化:InfluxDB与Grafana实现数据持久化与可视化分析
目录 前言 influxDB 安装运行InfluxDB 用Python 上报数据到influxdb ocust 数据写入到 influx Locust的生命周期 上报数据 优化升级 配置Grafana 总结 资料获取方法 前言 在进行性能测试时,我们需要对测试结果进行监控和分析,以便于及时发现问…...

数组模拟循环链表
5073. 空闲块 - AcWing题库 数组模拟循环链表 /*从当前位置开始遍历空闲块链表(初始是从地址最小的第一个空闲块开始),寻找满足条件的最小块 (即:大于等于请求空间的最小空闲块,如果有多个大小相同的最小空…...

第三章 图论 No.5最小生成树之虚拟源点,完全图与次小生成树
文章目录 虚拟源点:1146. 新的开始贪心或kruskal性质:1145. 北极通讯网络最小生成树与完全图:346. 走廊泼水节次小生成树:1148. 秘密的牛奶运输 虚拟源点:1146. 新的开始 1146. 新的开始 - AcWing题库 与一般的最小…...

RESTful API的讲解以及用PHP实现RESTful API
RESTful API是什么 RESTful是一种设计风格,是一种用于构建Web服务的架构。RESTful API是一种基于REST(Representational State Transfer)架构风格的Web服务接口设计规范。它强调使用HTTP协议中的请求方法(例如GET、POST、PUT、DEL…...

Spring中@Component和@Bean的区别
1. 用途不同 Component用于标识普通类 Bean是在配置类中声明和配置Bean对象 2. 使用方式不同 Component是一个类级别的注解,Spring通过ComponentScan注解扫描并注册为Bean. Bean是一个方法级别的注解,在配置类中手动声明和配置Bean 3. 控制权不同 Component注解修饰的类使…...

【问题解决】mysql 数据库字符串分割之后多行输出方法
背景: 项目需要从一张表查询出来数据插入到另一张表,其中有一个字段是用逗号分隔的字符串,需要多行输入到另一张表,那么这个如何实现呢 方案: 下面先粘贴下sql语句: select SUBSTRING_INDEX(SUBSTRING_…...

flutter开发实战-时间显示刚刚几分钟前几小时前
flutter开发实战-时间显示刚刚几分钟前几小时前 在开发中经常遇到从服务端获取的时间戳,需要转换显示刚刚、几分钟前、几小时前、几天前、年月日等格式。 一、代码实现 static String timeFormatterChatTimeStamp(int seconds) {try {int nowDateSeconds (DateTi…...
导出LLaMA等LLM模型为onnx
通过onnx模型可以在支持onnx推理的推理引擎上进行推理,从而可以将LLM部署在更加广泛的平台上面。此外还可以具有避免pytorch依赖,获得更好的性能等优势。 这篇博客(大模型LLaMa及周边项目(二) - 知乎)进行…...

回顾 OWASP 机器学习十大风险
日复一日,越来越多的机器学习 (ML) 模型正在开发中。机器学习模型用于查找训练数据中的模式,可以产生令人印象深刻的检测和分类能力。机器学习已经为人工智能的许多领域提供了动力,包括情感分析、图像分类、面部检测、威胁情报等。 数十亿美…...
ENSP软件的基本使用命令(第三十一课)
ENSP软件的基本使用命令(第三十一课) 下面的图片是今天操作的核心基础操作 1 命令行页面 交换机 路由器 PC机 分别展示一下 页面的样子 2 基本命令结构...

五、FreeRTOS数据类型和编程规范
1、数据类型 (1)每个移植的版本都含有自己的portmacro.h头文件,里面定义了2个数据类型。 (2)TickType_t FreeRTOS配置了一个周期性的时钟中断:Tick Interrup每发生一次中断,中断次数累加,这被称为tick counttick count这个变量…...
码出高效_第二章 | 面向对象_上
目录 一. OOP理念1. 概念辨析2. 四大特性1. 抽象2. 封装3. 继承4. 多态 二. 初识Java1. JDKJDK 5-11的重要类、特性及重大改变 2. JRE关于JVM 三. 类1. 概述2. 接口和抽象类1. 概念及相同点2. 不同点3. 总结 3. 内部类4. 访问权限控制1. 由来2. public/private/无/private3. 推…...
大学生课设实训|基于springboot的在线拍卖系统
目录 项目描述 主要技术栈 功能效果 数据库设计 开发顺序 业务功能 大家好!我是龍弟-idea!需要源码资料信息可私聊我【HWL__666666】! 项目描述 本系统是一个网上商品竞拍系统,为拍卖者和竞买者提供一个在线交流平台。本项…...
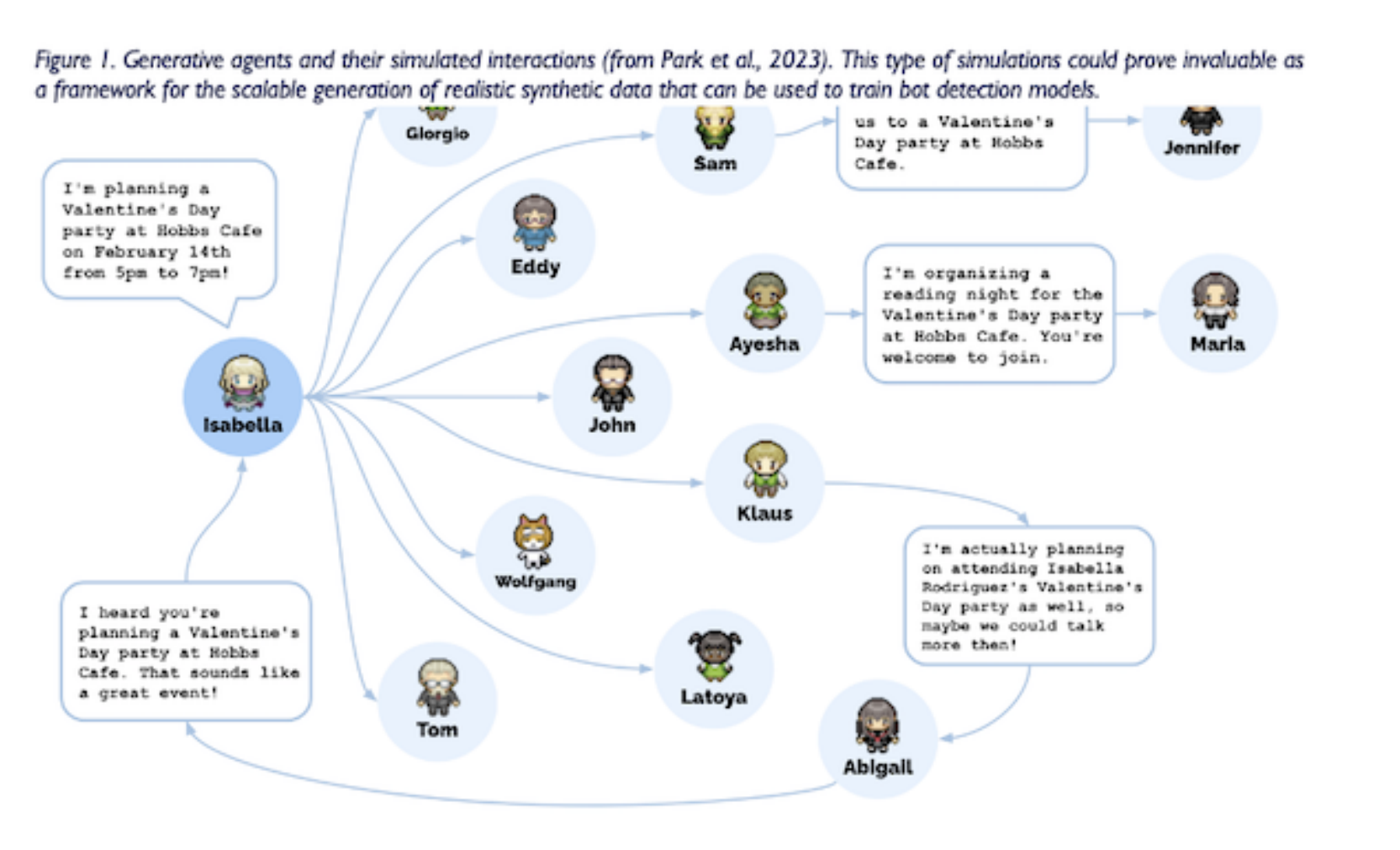
论文阅读 - Social bot detection in the age of ChatGPT: Challenges and opportunities
论文链接:https://www.researchgate.net/publication/371661341_Social_bot_detection_in_the_age_of_ChatGPT_Challenges_and_opportunities 目录 摘要: 引言 1.1. Background on social bots and their role in society 1.2. The rise of AI-gene…...
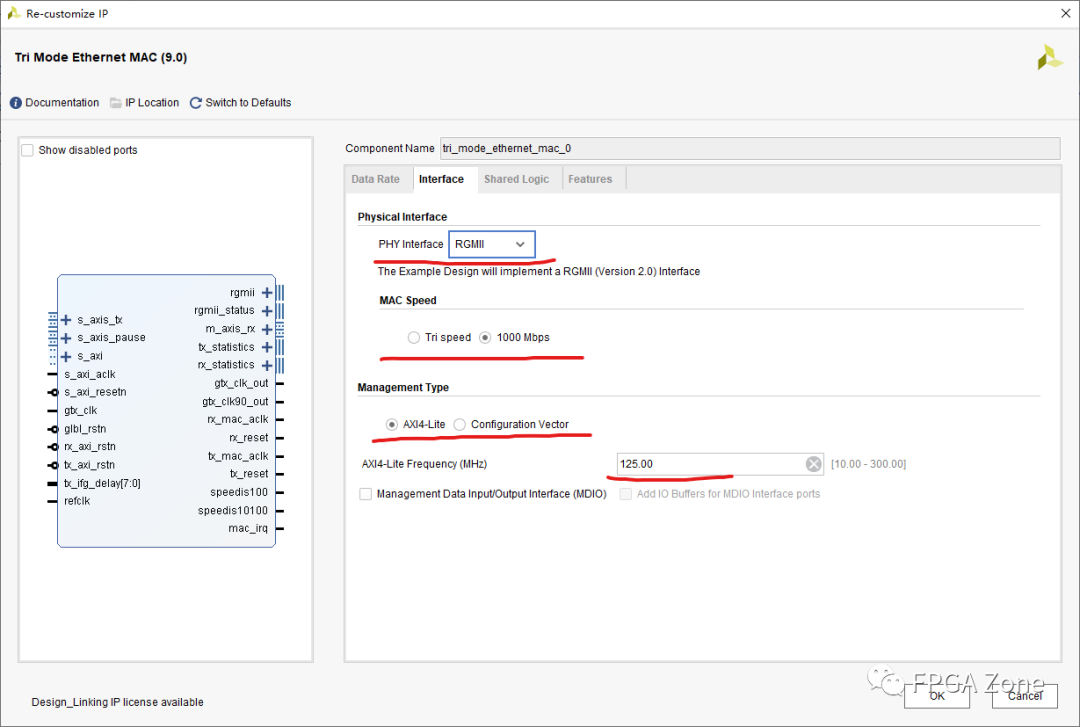
FPGA优质开源项目 - UDP RGMII千兆以太网
本文介绍一个FPGA开源项目:UDP RGMII千兆以太网通信。该项目在我之前的工作中主要是用于FPGA和电脑端之间进行图像数据传输。本文简要介绍一下该项目的千兆以太网通信方案、以太网IP核的使用以及Vivado工程源代码结构。 Vivado 的 Tri Mode Ethernet MAC IP核需要付…...
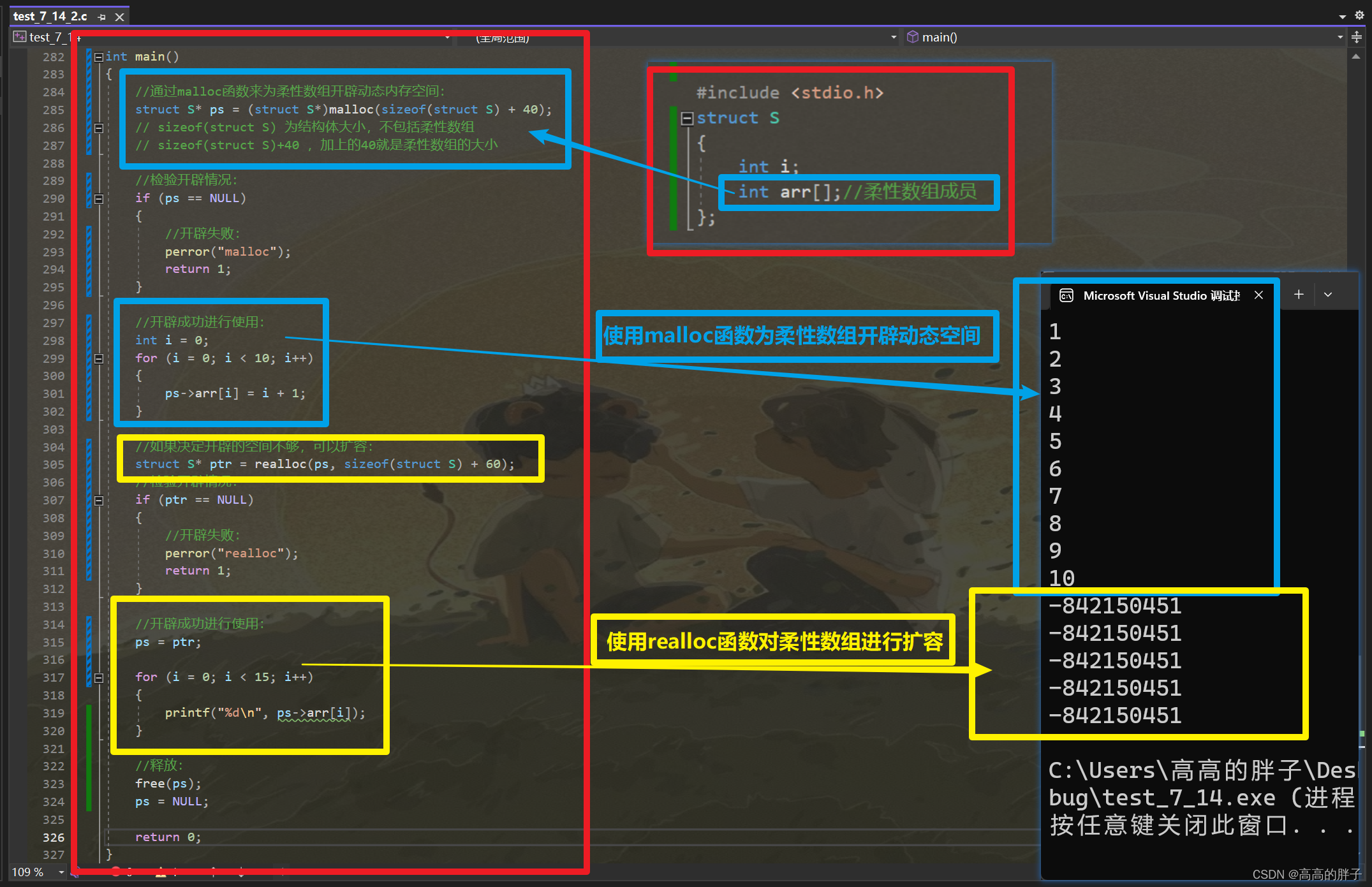
学C的第三十二天【动态内存管理】
相关代码gitee自取:C语言学习日记: 加油努力 (gitee.com) 接上期: 学C的第三十一天【通讯录的实现】_高高的胖子的博客-CSDN博客 1 . 为什么存在动态内存分配 学到现在认识的内存开辟方式有两种: 创建变量: int val …...

聊聊elasticsearch的data-streams
序 本文主要研究一下elasticsearch的data-streams data-streams 主要特性 首先data streams是由一个或者多个自动生成的隐藏索引组成的,它的格式为.ds-<data-stream>-<yyyy.MM.dd>-<generation> 示例.ds-web-server-logs-2099.03.07-000034&a…...

unreal engine c++ 创建tcp server, tcp client
TCP客户端 TcpConnect.h // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "CoreMinimal.h" #include "Common/UdpSocketReceiver.h" #include "GameFramework/Actor.h"DECLARE_DELEGATE…...
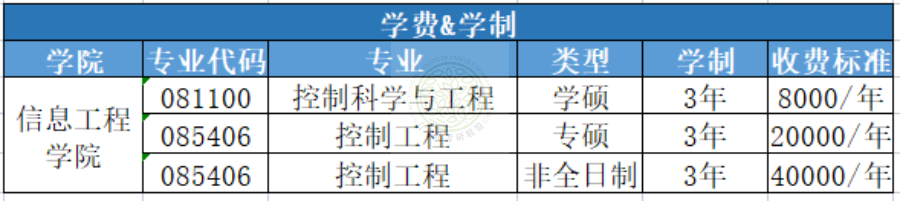
24届华东理工大学近5年自动化考研院校分析
今天给大家带来的是华东理工大学控制考研分析 满满干货~还不快快点赞收藏 一、华东理工大学 学校简介 华东理工大学原名华东化工学院,1956年被定为全国首批招收研究生的学校之一,1960年起被中共中央确定为教育部直属的全国重点大学&#…...
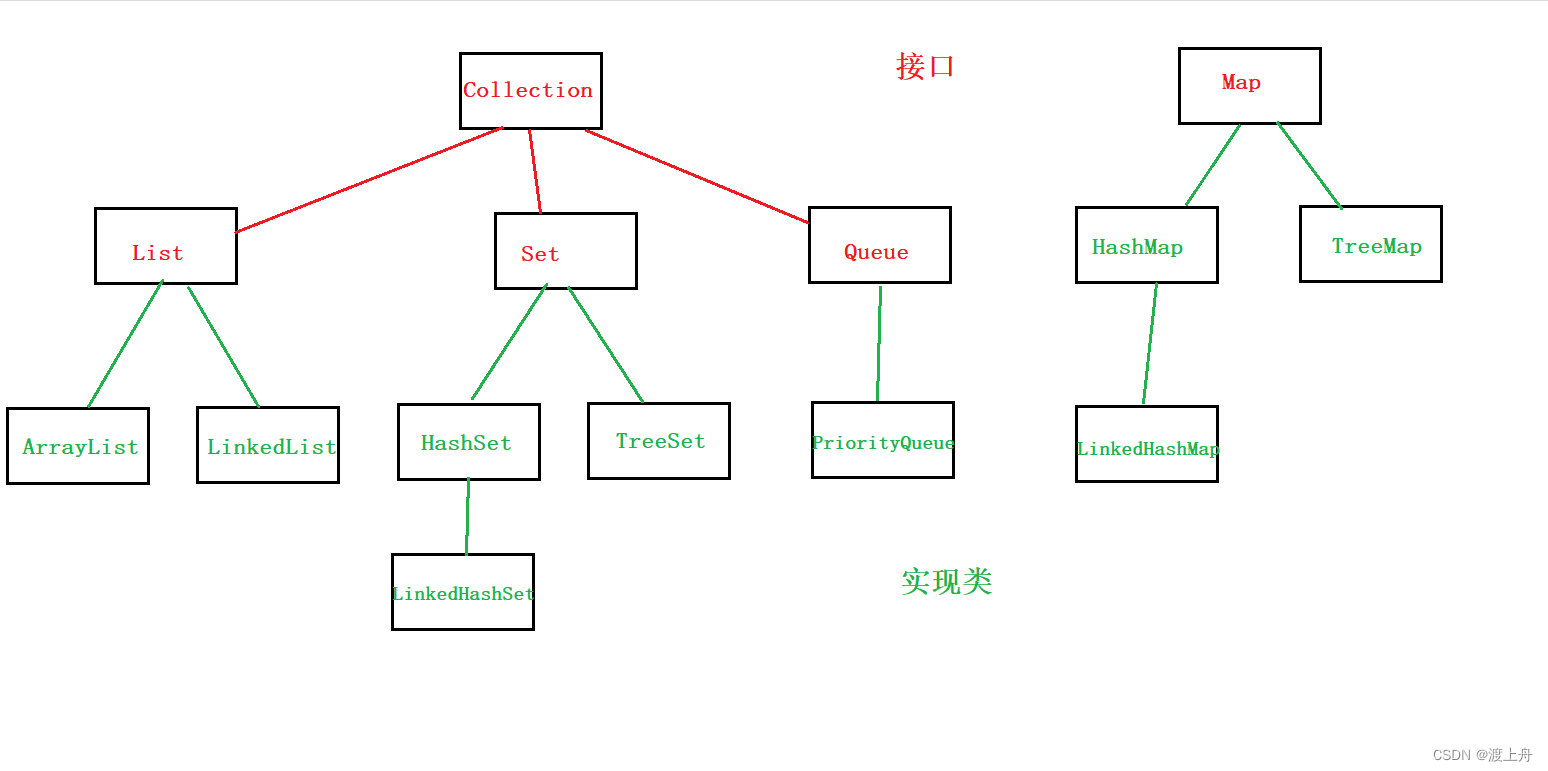
初识集合和背后的数据结构
目录 集合 Java集合框架 数据结构 算法 集合 集合,是用来存放数据的容器。其主要表现为将多个元素置于一个单元中,用于对这些元素进行增删查改。例如,一副扑克牌(一组牌的集合)、一个邮箱(一组邮件的集合)。 Java中有很多种集…...

原来赛事专用匹克球工厂还有这么多门道?你了解吗?
引言在匹克球运动蓬勃发展的当下,赛事专用匹克球的品质至关重要。而赛事专用匹克球工厂背后,其实隐藏着诸多门道。泉州凯瑞麟体育用品有限公司作为行业内的佼佼者,在这方面有着独特的技术与经验。核心材料与技术创新赛事专用匹克球对核心材料…...

xc-union 从 1.0.0 到 2.0.0:开源私域返利基座
618 拼的不只是流量,更是开发效率。 每到大促节点,很多团队都会集中遇到同一类需求: 查券/导购工具要尽快上线H5 页面先跑,后端接口后续持续扩展要求可快速交付,也要支持后续二开 问题是,如果从零开始手撸&…...

智能驾驶系统场景下的自动化仿真测试评价技术【附仿真】
✨ 长期致力于智能驾驶系统、有效性评价、测试用例生成、测试场景优化、自动化仿真测试平台研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于复杂度…...

多语言交易所源码/币币交易+期权交易+永续合约+Defi借贷+新币申购+矿机理财/前端uniapp纯源码+后端php
简介: 多语言交易所源码/币币交易期权交易永续合约Defi借贷新币申购矿机理财/前端uniapp纯源码后端php 语言:7种,看图 前端是uniapp纯源码,只有手机端,后端是php框架,清理了后门的,是最开始蓝…...

太空算力产业正崛起
未来,渔民只需通过手机App向卫星发起查询,卫星便可借助高光谱相机精准定位金枪鱼位置,再通过在轨“智慧大脑”分析处理,将鱼群坐标、渔具使用建议及销售渠道指导等实用信息,精准传回渔民手中。这一充满“黑科技”色彩的…...

摆脱论文困扰!盘点2026年普遍认可的的降AI率软件
轻松降低论文AI率在2026年已不再是天方夜谭。最新实测数据显示,2026年降AI率软件正以惊人的效率和精准度颠覆传统方法,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,真正实现高效降AI率,帮你告别论文焦虑。…...

洛雪音乐六音音源修复完整指南:快速恢复音乐播放功能
洛雪音乐六音音源修复完整指南:快速恢复音乐播放功能 【免费下载链接】New_lxmusic_source 六音音源修复版 项目地址: https://gitcode.com/gh_mirrors/ne/New_lxmusic_source 洛雪音乐是一款广受欢迎的开源音乐播放器,但近期许多用户遇到了六音音…...

OpCore-Simplify:10分钟搞定黑苹果配置,告别3天手动调试的智能神器
OpCore-Simplify:10分钟搞定黑苹果配置,告别3天手动调试的智能神器 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂…...

万用表档位介绍与测量
万用表档位介绍与测量一:万用表档位介绍二:表笔的连接三:电阻测量(Ω)四:电流测量注意事项:1、测电流一定是串联,绝对不能直接把表笔搭在电源两极!一搭就烧表、炸保险。2…...

端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践
端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践 【免费下载链接】wekws Production First and Production Ready End-to-End Keyword Spotting Toolkit 项目地址: https://gitcode.com/gh_mirrors/we/wekws 在物联网设备普及的今天&#x…...