PoseFormer:基于视频的2D-to-3D单人姿态估计
3D Human Pose Estimation with Spatial and Temporal Transformers论文解析
- 摘要
- 1. 简介
- 2. Related Works
- 2.1 2D-to-3D Lifting HPE
- 2.2 GNNs in 3D HPE
- 2.3 Vision Transformers
- 3. Method
- 3.1 Temporal Transformer Baseline
- 3.2 PoseFormer: Spatial-Temporal Transformer
- Spatial Transformer Module
- Temporal Transformer Module
- Regression Head
- Loss Function
- 4. 数据集
- 4.1 [Human3.6M](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6682899)
- 4.2 [MPI-INF-3DHP](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8374605)
- 5. 评测指标
论文链接:3D Human Pose Estimation with Spatial and Temporal Transformers
论文代码:https://github.com/zczcwh/PoseFormer
论文出处:2021 ICCV
论文单位:University of Central Florida, USA
摘要
- Transformer架构已经成为自然语言处理中的首选模型,现在正被引入到计算机视觉任务中,例如图像分类、对象检测和语义分割。
- 然而,在人体姿态估计领域,卷积架构仍然占主导地位。
- 在这项工作中,我们呈现PoseFormer,一种纯粹基于Transformer的方法,用于视频中的3D人体姿势估计,不涉及卷积架构。
- 受视觉Transformer最新发展的启发,我们设计了一个时空Transformer结构,以全面建模每帧内的人体关节关系以及帧间的时间相关性,然后输出中心帧的精确三维人体姿态。
- 我们在两个流行的和标准的基准数据集:Human3.6M和MPI-INF-3DHP上定量和定性地评估了我们的方法。大量的实验表明,PoseFormer在两个数据集上都达到了最先进的性能。
1. 简介
- 人体姿态估计(HPE) 旨在从图像和视频等输入数据中定位关节并构建身体表示(例如骨骼位置)。
- HPE提供人体的几何和运动信息,可以应用于广泛的应用(如人机交互,运动分析,医疗保健)。
- 目前的工作大致可以分为两类: (1)直接估算方法,(2)2D-to-3D提升方法。
- 直接估计方法从2D图像或视频帧中推断出3D人体姿势,而无需中间估计2D姿势表示。
- 2D-to-3D提升方法从中间估计的2D姿势推断出3D人体姿势。
- 得益于最先进的2D姿态检测器的优异性能,2D-to-3D提升方法通常优于直接估计方法。
- 然而,这些2D姿势到3D的映射是non-trivial; 由于深度模糊和遮挡,相同的2D姿态可以生成各种潜在的3D姿态。
- 为了缓解这些问题并保持自然的连贯性,许多最近的作品将来自视频的时间信息整合到他们的方法中。然而,基于cnn的方法通常依赖于固有的有限时间连通性的扩张技术,而循环网络主要受限于简单的顺序相关性。
- 最近,Transformer 由于其效率、可扩展性和强大的建模能力,已经成为自然语言处理(NLP)事实上的模型。由于Transformer 的self-attention 机制,可以清楚地捕获跨长输入序列的全局相关性。这使得它特别适合序列数据问题的架构,因此可以自然地扩展到3D HPE。
- 凭借其全面的连通性和表达,Transformer 提供了一个跨帧学习更强的时间表示的机会。
- 然而,最近的研究表明,Transformer 需要特定的设计才能在视觉任务中达到与CNN同类产品相当的性能。具体来说,它们通常需要非常大规模的训练数据集,或者如果应用于较小的数据集,则增强数据增强和正则化。
- 此外,现有的视觉变压器主要局限于图像分类、目标检测和分割,但如何利用变压器的力量进行3D HPE仍然不清楚。
- 为了回答这个问题,我们首先将变压器直接应用于2D-to-3D lifting HPE。在这种情况下,我们将给定序列中每帧的整个2D姿态视为一个标记( token)(图1(a))。 虽然这种基线方法在一定程度上是有效的,但它忽略了空间关系(关节对关节)的自然区别。
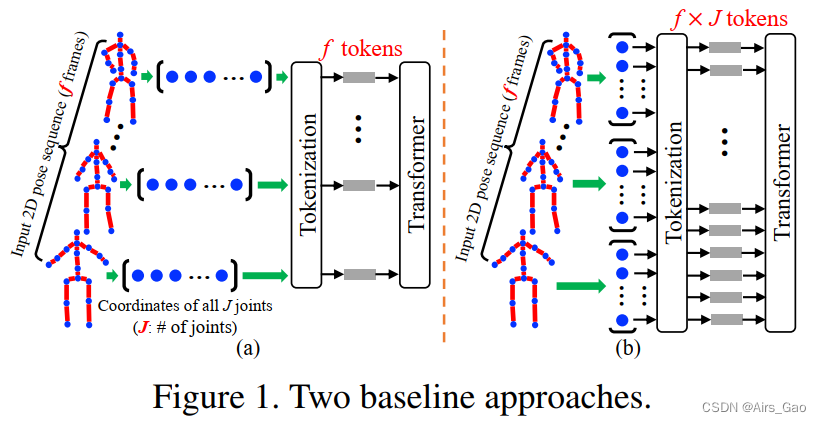
- 对该基线的自然扩展是将每个2D关节坐标视为一个token,提供由序列所有帧中的这些关节组成的输入(图1(b))。然而,在这种情况下,当使用长帧序列时,token的数量变得越来越大(在3D HPE中,每帧最多243帧,17个关节是常见的,token的数量将为243×17=4131)。由于Transformer计算每个token对另一个token的直接关注,因此模型的内存需求接近不合理的水平。
- 因此,作为应对这些挑战的有效解决方案,我们提出了PoseFormer,这是第一个用于视频中2d到3d提升HPE的纯Transformer网络。
- PoseFormer使用两个维度的不同Transformer模块直接对空间和时间方面进行建模。
- PoseFormer不仅在空间和时间元素之间产生强大的表示,而且不会对长输入序列产生大量的token计数。
- 在高层次上,PoseFormer只是从现成的2D姿态估计器中提取一系列检测到的2D姿态,并输出中心帧的3D姿态。
- 更具体地说,我们建立了一个空间Transformer模块来编码每个帧中二维关节之间的局部关系。 空间self-attention层考虑二维关节的位置信息,并返回该帧的潜在特征表示。接下来,我们的时间Transformer模块分析每个空间特征表示之间的全局依赖关系,并生成准确的3D姿态估计。
- 在两种流行的3D HPE基准(Human3.6M和MPI-INF-3DHP)上的实验评估表明,PoseFormer在这两个数据集上都达到了最先进的性能。我们将我们估计的3D姿态与SOAT方法进行比较,并发现
PoseFormer产生更平滑、更可靠的结果。此外,消融研究中还提供了PoseFormer注意力图的可视化和分析,以了解模型的内部工作原理并证明其有效性。 - 我们的贡献有三方面:
(1)我们提出了第一个纯基于Transformer的模型PoseFormer,用于3D HPE的2d到3D lifting。
(2)我们设计了一个有效的时空Transformer模型,其中空间Transformer模块编码人体关节之间的局部关系,而时间Transformer模块捕获整个序列中跨帧的全局依赖关系。
(3)我们的PoseFormer模型在Human3.6M和MPI-INF-3DHP数据集上取得了SOAT效果。
2. Related Works
- 在这里,我们具体总结了3D单人单视图HPE方法。
- 直接估计方法: 从二维图像中推断三维人体姿态,而不需要中间估计二维姿态表示。
- 2D-to-3D lifting 方法: 利用2D姿态作为输入来生成相应的3D姿态,这在该领域的最新方法中较为流行。任何现成的2D姿态估计器都可以有效地与这些方法兼容。
2.1 2D-to-3D Lifting HPE
- 2D到3d提升方法利用从输入图像或视频帧估计的2D姿势。
- OpenPose、CPN、AlphaPose和HRNet被广泛用作2D姿态检测器。
- 基于这种中间表示,可以使用多种方法生成3D姿态。
- 然而,以前最先进的方法依赖于扩展的时间卷积(dilated temporal convolutions)来捕获全局依赖关系,这在时间连接上是有限的。
- 此外,这些工作中的大多数使用简单的操作将关节坐标投影到潜在空间,而没有考虑人体关节的运动学相关性。
2.2 GNNs in 3D HPE
- 自然地,人体姿势可以表示为一个graph,其中关节是nodes ,骨骼是 edges。
- 图神经网络(GNNs)也被应用于 2D-to-3D pose lifting 问题,并提供了很好的表现。
- 对于我们的PoseFormer,transformer可以被视为一种具有独特且通常有利的图操作的GNN。
- 具体来说,一个transformer编码器模块本质上形成了一个全连接图,其中边缘权重是使用输入条件,多头self-attention计算的。
- 该操作还包括节点特征的规范化,跨注意头输出的前馈聚合器,以及使其能够有效地扩展堆叠层的剩余连接。
- 与其他图操作相比,这样的操作是有利的。例如,节点之间连接的强度由transformer的self-attention机制决定,而不是像典型的那样通过邻接矩阵预定义。
- 本任务中使用的基于gcn的配方。 这使得模型能够灵活地根据每个输入姿势调整关节的相对重要性。
- 此外,transformer的综合缩放和归一化组件可能有利于减轻当多层堆叠在一起时困扰许多GNN操作变体的过度平滑效应。
2.3 Vision Transformers
- 最近,有一个新兴的兴趣将 Transformer 应用于视觉任务。
- DEtection TRansformer (DETR) 用于目标检测与全景分割。
- Vision Transformer (ViT) ,纯Transformer 构架,在图像分类方面达到了SOAT的性能。
- Transpose,基于Transformer 构架,从图像中估计3D姿态。
- MEsh TRansfOrmer,将cnn与Transformer 网络结合起来,从单个图像重建3D pose 和 mesh vertices。
- 本文方法的时空Transformer 架构利用了每帧中的关键点相关性,并保留了视频中的自然时间一致性。
3. Method
- Pipeline:通过现成的2D姿态检测器获得每帧的2D姿态,使用连续帧的二维姿态序列作为输入,估计中心帧的三维姿态。
3.1 Temporal Transformer Baseline
- 作为 2D-to-3D lifting 的基线应用,我们将每个2D姿态视为输入token,并使用Transformer 来捕获输入之间的全局依赖关系,如图2(a)所示。
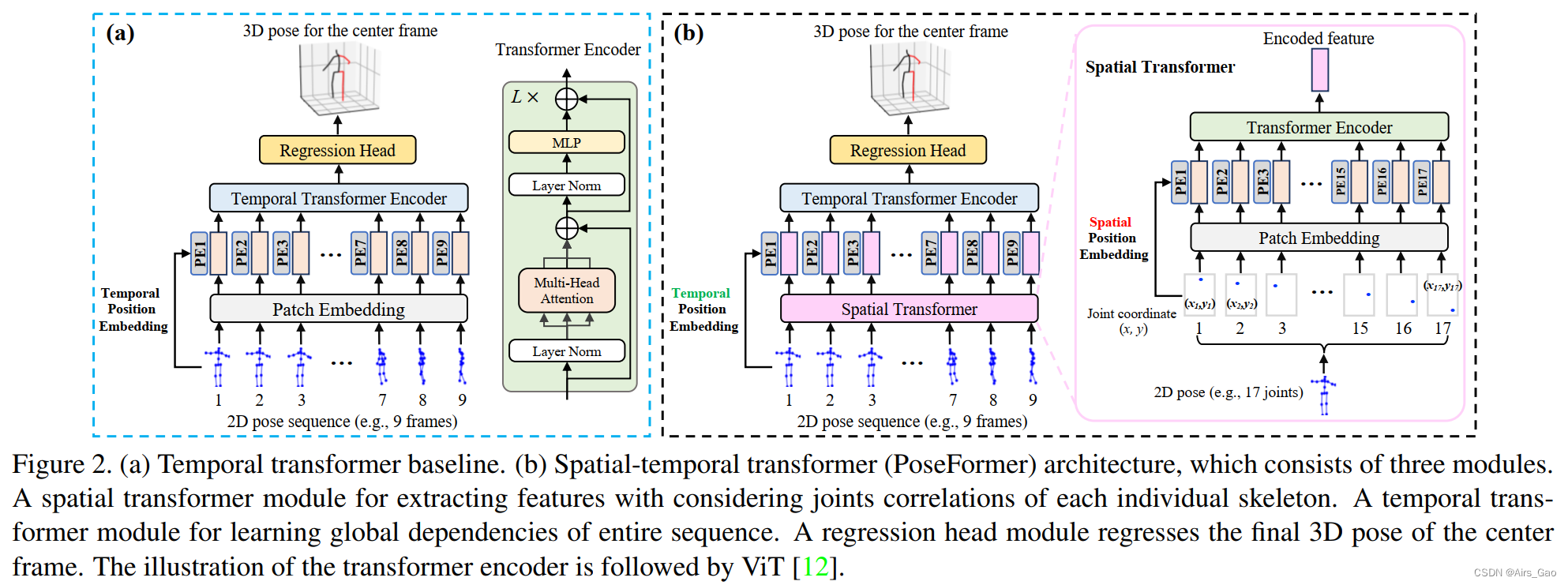
- 我们将把每个输入token称为一个patch,在术语上类似于ViT.
- 对于输入序列X∈R^(f×(J·2)),f 为输入序列的帧数,J为每帧的关节数2D位姿,2表示关节在2D空间中的坐标。
- patch embedding 是一个可训练的线性投影层,将每个patch 嵌入到高维特征中。
- Transformer 网络利用位置嵌入来保留序列的位置信息。
- self-attention是Transformer 的核心功能,它将输入序列的不同位置与嵌入特征联系起来。
- 我们的Transformer 编码器由多头自注意块和多层感知器(MLP)块组成。LayerNorm在每个块之前应用,剩余连接在每个块之后应用。
- 为了预测中心帧的三维姿态,编码器输出Y∈Rf×C通过在帧维中取平均值,收缩为向量y∈R1×C。最后,一个MLP块将输出回归到 y∈R1×(J*3),即中心框架的3D姿态。
3.2 PoseFormer: Spatial-Temporal Transformer
- 我们观察到,时间Transformer基线主要关注输入序列中帧之间的全局依赖关系。利用线性变换patch embedding将关节坐标投影到隐维上。
- 然而,由于简单的线性投影层无法学习到attention信息,局部关节坐标之间的运动信息在时序Transformer基线中没有得到强有力的表示。
- 一个潜在的解决方案是将每个关节坐标视为一个单独的patch,并将所有帧的关节作为输入馈送到Transformer(见图1(b))。
- 然而,patch的数量会迅速增加(帧数 f 乘以关节数 J),导致模型的计算复杂度为O((f·J)2)。
- 为了有效地学习局部联合相关性,我们分别对空间和时间信息使用了两个分离的Transformer。
- 如图2(b)所示,PoseFormer由三个模块组成: spatial transformer module, temporal transformer module, and regression head module。
Spatial Transformer Module
- Spatial Transformer Module是从单个帧中提取高维特征嵌入。给定一个具有 J 个关节的二维姿态,我们将每个关节(即两个坐标)视为一个patch,并按照通用视觉变换pipeline在所有patch之间进行特征提取。
- 首先,我们用可训练的线性投影将每个关节的坐标映射到高维空间,这被称为spatial patch embedding。
Temporal Transformer Module
- 由于Spatial Transformer Module为每个单独的帧编码高维特征,因此Temporal Transformer Module的目标是跨帧序列建模依赖关系。
- 在Temporal Transformer Module之前,我们加入了可学习的时序位置嵌入来保留帧的位置信息。
- 对于Temporal Transformer Module编码器,我们采用与Spatial Transformer Module编码器相同的架构,该架构由多头self-attention块和MLP块组成。
- 时序变压器模块的输出为 Y∈Rf*(J*c)。
Regression Head
- 由于我们使用一组帧序列来预测中心帧的三维姿态,因此Temporal Transformer Module Y∈Rf*(J·c)的输出需要简化为 y∈R1*(J·c)。
- 我们在帧维度上应用加权平均操作(使用学习到的权重)来实现这一点。
- 最后,一个具有Layer范数和一个线性层的简单MLP块返回输出 y∈R1*(J·3),这是中心帧的预测三维姿态。
Loss Function
- 为了训练我们的时空转换模型,我们使用了标准的MPJPE (Mean Per Joint Position Error)损失以最小化预测值与ground truth姿态之间的误差为
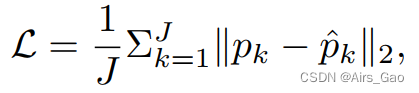
4. 数据集
4.1 Human3.6M
- Human3.6M是3D单人HPE使用最广泛的室内数据集。
- 由11名专业演员表演坐、走、打电话等17种动作。
- 每个受试者在室内环境中从4个不同的角度拍摄视频。
- 该数据集包含360万视频帧,其中包含基于精确标记的动作捕捉系统捕获的3D地面真相注释。
- 根据之前的工作,我们采用相同的实验设置: 所有15个动作都用于训练和测试,模型训练在5个sections(S1, S5,S6, S7, S8)和测试在 2个sections(S9和S11)。
4.2 MPI-INF-3DHP
- MPI-INF-3DHP是一个更具挑战性的三维姿态数据集。
- 它既包含受限的室内场景,也包含复杂的室外场景。
- 有8个演员表演8个动作,从14个摄像机视图,涵盖了更大的多样性的姿势。
- MPI-INF-3DHP提供了6个不同场景的测试集。
5. 评测指标
- MPJPE :Mean Per Joint Position Error,平均每个关节位置误差,估计关节与地面真值之间的平均欧几里得距离,单位为毫米。
- P-MPJPE: P-MPJPE是估计的三维姿态与ground truth经过后处理后的刚性对准后的MPJPE,对单个关节预测失败具有更强的鲁棒性。
- PCK:Percentage of Correct Keypoint,在150mm范围内的正确关节点的百分比。
- AUC:Area Under Curve,曲线下面积。
相关文章:
PoseFormer:基于视频的2D-to-3D单人姿态估计
3D Human Pose Estimation with Spatial and Temporal Transformers论文解析 摘要1. 简介2. Related Works2.1 2D-to-3D Lifting HPE2.2 GNNs in 3D HPE2.3 Vision Transformers 3. Method3.1 Temporal Transformer Baseline3.2 PoseFormer: Spatial-Temporal TransformerSpati…...

Fortinet发布2023年第二季度财报
全球网络与安全融合领域领导者Fortinet(Nasdaq:FTNT),于近日公布2023年第二季度财报。 Fortinet 创始人、董事长兼首席执行官谢青表示:“作为业内领先的网络安全平台和安全组网厂商,得益于当下对整合型供应…...

智慧消防 | 气体灭火系统压力在线监测正当其时
气体灭火设备在消防安全系统中扮演着重要的角色。根据最新版的《气瓶安全技术规程》TSG23-2021规定,IG541气体钢瓶需要每3年进行一次检测。未按时进行检测可能导致压力掉压、瓶体外部锈蚀、钢瓶位置钢瓶内部腐蚀等风险,这些问题都可能对消防安全和效能产…...
并查集练习 — 扩展问题(二)
根据并查集练习 —岛屿数量的问题再次扩展: 原题是给定一个二维数组matrix(char[][]),里面的值不是1就是0,上、下、左、右相邻的1认为是一片岛。返回matrix中岛的数量。 扩展为:如果是中国的地图࿰…...
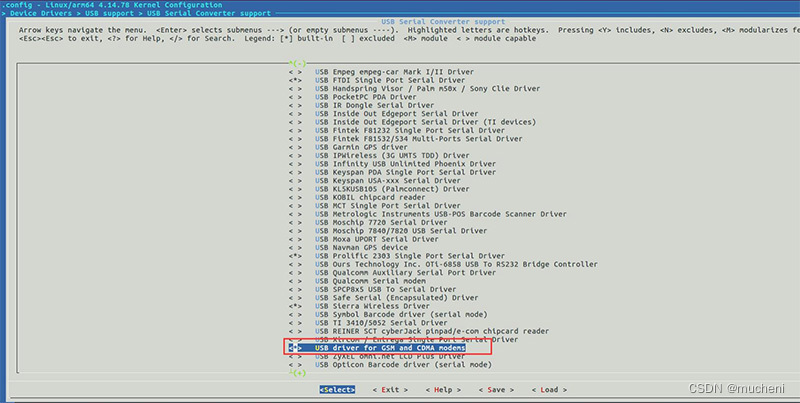
iTOP-i.MX8MM开发板添加 isb 转串口设备驱动
对于通过 USB 接口访问的模块,在 Linux 内核中集成 USB 驱动程序。我们需要配置内核选中支持 GSM 和 CDMA 模块的 USB 转串口驱动 > Device Drivers -> USB support (USB_SUPPORT [y]) -> USB Serial Converter support (USB_SERIAL [y]) -> USB dr…...

Golang实现Redis分布式锁解决秒杀问题
先写一个脚本sql,插入2000个用户 INSERT INTO sys_users (mobile, password) SELECT numbers.n AS mobile,$2a$10$zKQfSn/GCcR6MX4nHk3MsOMhJnI0qxN4MFdiufDMH2wzuTaR9G1sq AS password FROM (SELECT ones.n tens.n*10 hundreds.n*100 thousands.n*1000 1 AS n…...

狂神说-通俗易懂的23种设计模式
狂神说-通俗易懂的23种设计模式 文章目录 1、设计模式概述2、OOP七大原则4、工厂模式5、抽象工厂模式6、建造者模式7、原型模式8、适配器模式9、桥接模式10、静态代理模式11、静态代理再理解12、动态代理详解 1、设计模式概述 设计模式的基本要素: 1、模式名称 2、…...

VR实景导航——开启3D可视化实景导航新体验
数字化时代,我们大家出门在外都是离不开各种导航软件,人们对导航的需求也越来越高,而传统的导航软件由于精度不够,无法满足人们对真实场景的需求,这个时候就需要VR实景导航为我们实景指引目的地的所在。 VR实景导航以其…...
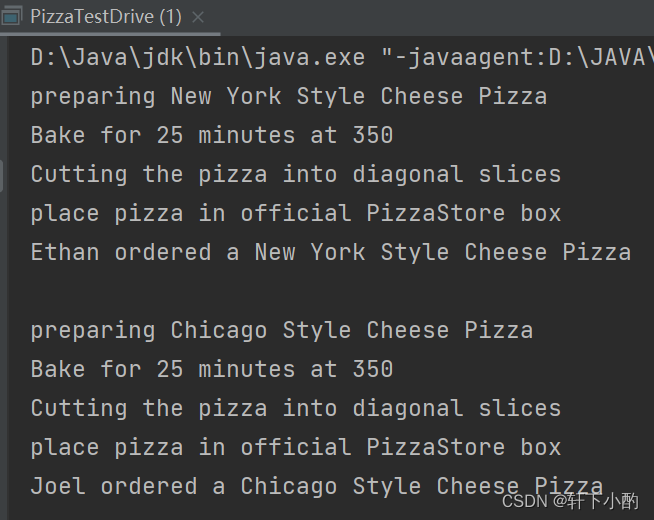
《HeadFirst设计模式(第二版)》第四章代码——工厂模式
代码文件目录结构: Cheese: 原料ingredient类中只以Cheese为例,不重复展示: package Chapter4_FactoryPattern.abstractFactoryPattern.Ingredient;/*** Author 竹心* Date 2023/8/4**/public abstract class Cheese {String name;String g…...

拖拽宫格vue-grid-layout详细应用及案例
文章目录 1、前言2、安装3、属性4、事件5、占位符样式修改6、案例 1、前言 vue-grid-layout是一个适用于vue的拖拽栅格布局库,功能齐全,适用于拖拽高度/宽度自由调节的布局需求,本文将讲述一些常用参数和事件,以及做一个同步拖拽…...

sanyo三洋摄像机卡有部分坏块恢复案例
sanyo三洋,这个品牌的摄像机真的是罕见。实际上日系摄像机领域就两个公司,一个是佳能一个索尼,其它的都厂商基本上全是用这两家公司的方案,当然松下这个怪咖除外!下面我们看看三洋的恢复案例。 故障存储:16G SD卡 故…...

【C++】STL——set和map及multiset和multiset的介绍及使用
🚀 作者简介:一名在后端领域学习,并渴望能够学有所成的追梦人。 🚁 个人主页:不 良 🔥 系列专栏:🛸C 🛹Linux 📕 学习格言:博观而约取࿰…...

帕累托森林:IEEE Fellow唐远炎院士出任「儒特科技」首席架构官
导语 「儒特科技」作为一家拥有全球独创性极致化微内核Web引擎架构的前沿科技企业,从成立即受到中科院软件所和工信部的重点孵化及扶持,成长异常迅速。前不久刚正式官方融入中国五大根操作系统体系,加速为其下游上千家相关衍生OS和应用软件企…...

数据库大数据
数据库 PyMongo模块的使用-MongoDB的Python接口 MapReduce将数据分解成子集,在不同机器上分开处理,并把结果集合起来,从而处理大数据的泛化框架。 Hadoop是MapReduce的一种实现,类似于C++是面向对象编程的实现一样。 NoSQL-Not Only SQL,技能能更新颖,更高效地访问(如…...

骨传导耳机是怎么工作的?骨传导耳机是智商税产品吗?
骨传导耳机是怎么工作的?骨传导耳机是智商税产品吗? 骨传导耳机是怎么工作的? 骨传导耳机的传声方式跟传统耳机完全不同,骨传导耳机就是利用骨传导的原理是直接将人体骨结构作为传声介质,通过颅骨来进行声音传播的&am…...
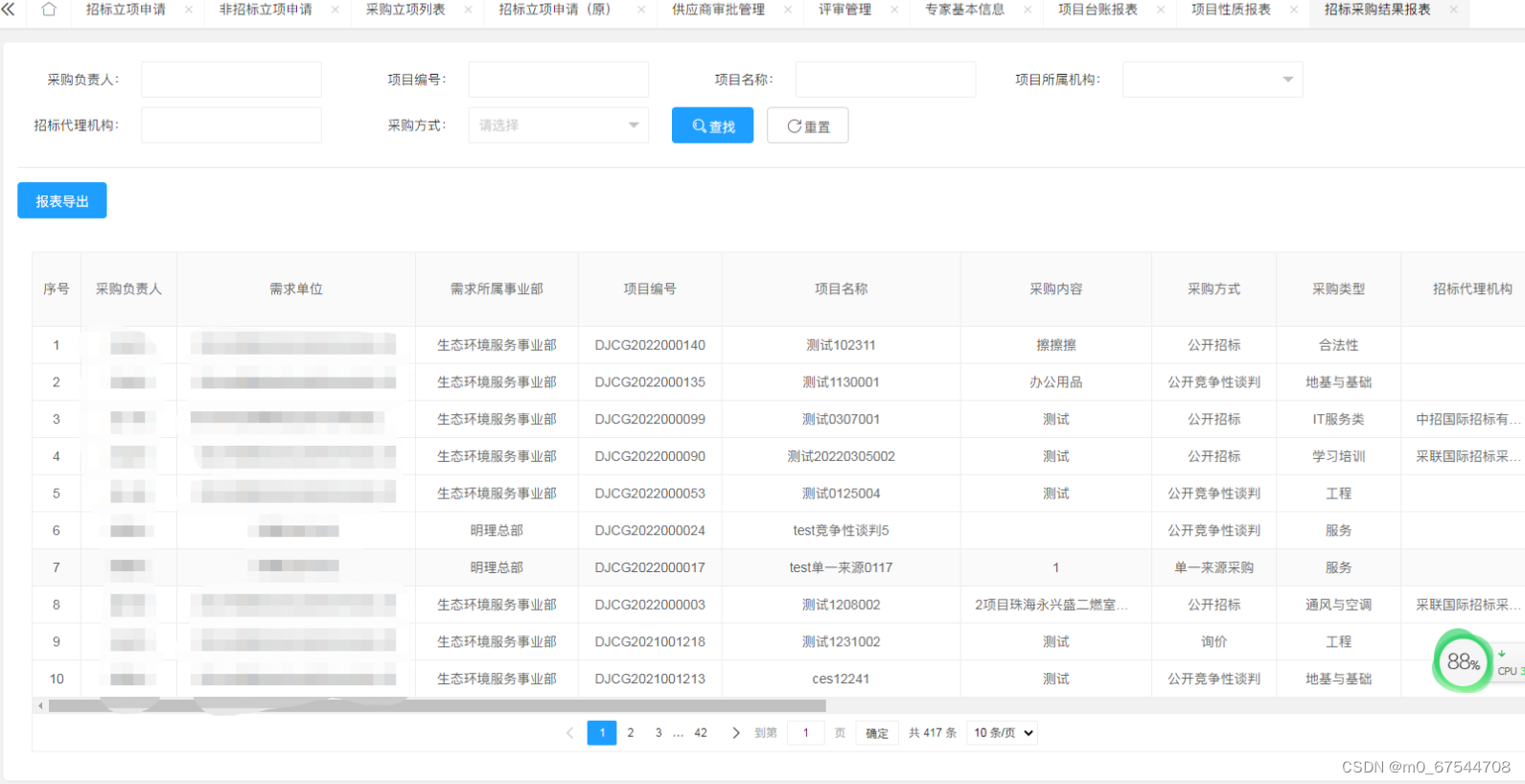
Java电子招投标采购系统源码-适合于招标代理、政府采购、企业采购、等业务的企业tbms
功能描述 1、门户管理:所有用户可在门户页面查看所有的公告信息及相关的通知信息。主要板块包含:招标公告、非招标公告、系统通知、政策法规。 2、立项管理:企业用户可对需要采购的项目进行立项申请,并提交审批,查…...

算法-合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 输入:intervals [[1,3],[2,6],[8,10],[15,…...
布基纳法索ECTN(BESC)申请流程
根据BURKINA FASO布基纳法索签发于 11/07/2006法令编号 00557的规定: 自2006年11月07 日起所有出口至布基纳法索(Burkina Faso)的货物,必须申请ECTN/BESC。ECTN是ELECTRONIC CARGO TRACKING NOTE的英文缩写,BESC是BORDEREAU DE SU…...
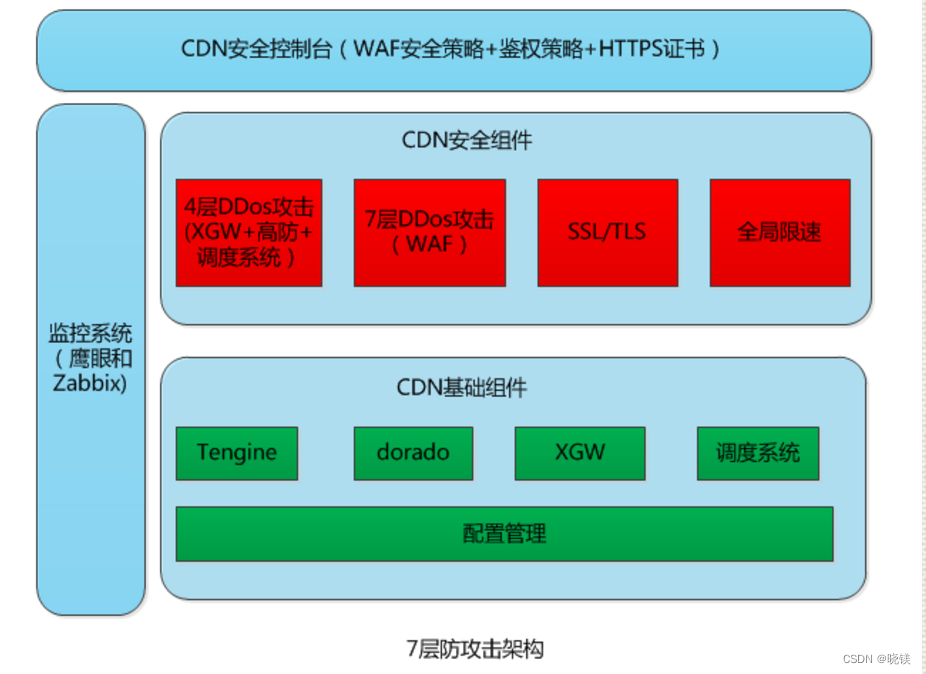
CDN安全面临的问题及防御架构
CDN安全 SQL注入攻击(各开发小组针对密码和权限的管理,和云安全部门的漏洞扫描和渗透测试) Web Server的安全(运营商和云安全部门或者漏洞纰漏第三方定期发布漏洞报告修复,例如:nginx版本号和nginx resol…...
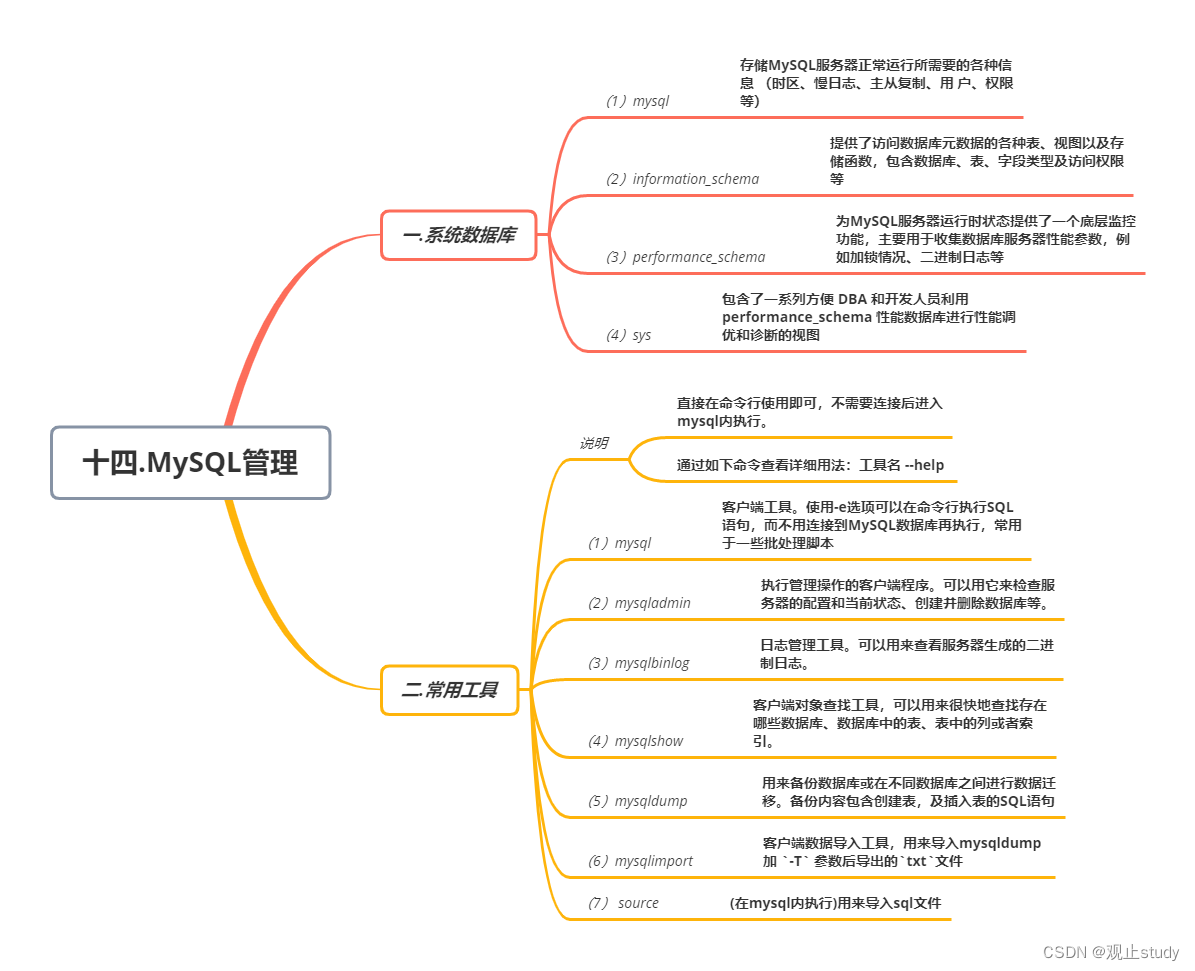
【MySQL】MySQL管理 (十四)
🚗MySQL学习第十四站~ 🚩本文已收录至专栏:MySQL通关路 ❤️文末附全文思维导图,感谢各位点赞收藏支持~ 一.系统数据库 MySQL8.0数据库安装完成后,自带了一下四个数据库,具体作用如下: 数据含…...

Pyinstaller:打包Python文件成exe可执行文件
1、pyinstaller安装pip install pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple2、打包单个文件如果所有代码是写在一个.py文件里的,可以尝试使用这种方式pyinstaller -F filesname.py成功运行后会在桌面生成三个文件:可执行文件.exe就在dist…...

3个步骤轻松解决B站缓存视频无法播放问题:m4s格式转换完全指南
3个步骤轻松解决B站缓存视频无法播放问题:m4s格式转换完全指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾遇到这样的情…...

为什么ITK在医学影像分析中如此强大?深入解析其Pipeline设计原理
为什么ITK在医学影像分析中如此强大?深入解析其Pipeline设计原理 医学影像处理领域对计算效率和精度有着近乎苛刻的要求,而ITK(InsightToolkit)正是在这样的需求背景下成长为行业标杆的开源工具包。当我们需要处理CT扫描的数百层切…...

深入解析C语言位运算与操作符
目录 1. 原码,反码,补码 2. 移位操作符 2.1 左移操作符 2.2 右移操作符 3. 位操作符:&,|,^,~ 3.1 按位与:& 3.2 按位或:| 3.3 按位异或:^ 3.4 按位取反&…...

利用快马平台快速搭建stm32f103c8t6最小系统板LED闪烁原型
最近在做一个嵌入式小项目,用到了经典的stm32f103c8t6最小系统板。作为嵌入式开发新手,最头疼的就是搭建开发环境和写各种初始化代码。不过这次尝试用InsCode(快马)平台后,整个过程顺畅多了,分享下我的经验。 项目背景 stm32f103c…...

在Discord上实时展示你的网易云音乐和QQ音乐播放状态
在Discord上实时展示你的网易云音乐和QQ音乐播放状态 【免费下载链接】NetEase-Cloud-Music-DiscordRPC 在Discord上显示网抑云/QQ音乐. Enables Discord Rich Presence For Netease Cloud Music/Tencent QQ Music. 项目地址: https://gitcode.com/gh_mirrors/ne/NetEase-Cl…...

多语言支持功能实现与配置指南:面向全球化用户的本地化解决方案
多语言支持功能实现与配置指南:面向全球化用户的本地化解决方案 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduc…...

深度解析VeraGrid:电力系统开源仿真平台的架构革新与实践应用
深度解析VeraGrid:电力系统开源仿真平台的架构革新与实践应用 【免费下载链接】VeraGrid VeraGrid, a cross-platform power systems software written in Python with user interface, used in academia and industry. 项目地址: https://gitcode.com/gh_mirrors…...

XUnity自动翻译器终极指南:5分钟实现Unity游戏无障碍汉化
XUnity自动翻译器终极指南:5分钟实现Unity游戏无障碍汉化 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏而苦恼?XUnity自动翻译器就是你的游戏语言救星!…...

塞尔达传说存档定制指南:打造个性化游戏体验
塞尔达传说存档定制指南:打造个性化游戏体验 【免费下载链接】BOTW-Save-Editor-GUI A Work in Progress Save Editor for BOTW 项目地址: https://gitcode.com/gh_mirrors/bo/BOTW-Save-Editor-GUI 在海拉鲁大陆的冒险中,你是否曾因资源匮乏而错…...