[腾讯云 Cloud studio 实战训练营] 制作Scrapy Demo爬取起点网月票榜小说数据
首语
最近接触到了一个关于云开发的IDE,什么意思呢?
就是我们通常开发不是在电脑上吗,既要下载编译器,还要下载合适的编辑器,有的时候甚至还需要配置开发环境,有些繁琐。
而这个云开发的IDE就是只需要一台能够上网的电脑就可以进行开发,完全不需要配置环境,下载编译器和编辑器。
Cloud Studio是什么
没错,这就是那一款云开发IDE。可以在浏览器上进行代码的编写,也可以将编写好的代码上传到你的Github或者Gitee。
Cloud Studio的优势
因为之前使用过JetBrains全家桶,所以就简单说一下对比,相较于传统的IDE来说,Clould Studio不需要下载安装即可在网页上使用。
相对来说更为方便,更为难得的是,Clould Studio在更为方便快捷的前提上,对比传统IDE的功能来讲,也都是具备的。
1. 代码纠错等基础功能
我们都知道,现在的IDE对于错误的代码不需要编译就可以标红提醒,因此Clould Studio也具备这样的功能,当然,代码补全这个很实用的功能也是具备的(对于我这种记忆力不好的人来说,这个功能还是很重要的)
2. 环境搭建
对于项目的环境搭建来说,由于Clould Studio收集了众多项目模板,因此对于需要的环境可以一键搭建,主打的就是一个方便快捷
也并不需要你创办虚拟环境,重新安装类库等,直接创建开发空间,就是一个独立的项目,不需要担心不同项目之间突然,冒出来一个问题。
也不需要为学校教了多门语言而苦恼多门语言的编译器安装与环境配置问题。
当时我学习java的时候确实为了环境配置而苦恼,只能说相见恨晚呐!
3. 链接云服务器
创建的项目运行后是在类似于云服务器上跑的,web项目也可以通过外网访问,工作空间内有分配的端口号和IP,也是非常的方便。
Clould Studio是使用ssh的方式来远程连接到,我们只需要在工作空间启动项目,然后就会出现这个按钮

点击后就会出现ssh的链接,使用对应的工具就可以远程链接了。
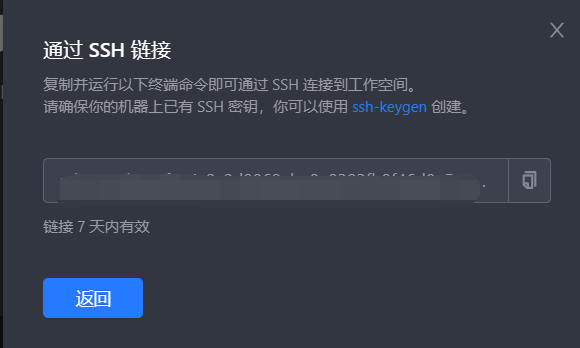
接下来我们就讲讲如何使用Clould Studio来制作我们的Scrapy Demo。
使用Clould Studio账号创建项目Demo
1. 注册创建Clould Studio账号
打开Clould Studio官方网站进行账号的注册登录:Clould Studio官网
在官网中我们可以看到对于Clould Studio的简单介绍:
而我们要使用的话就可以直接点击官网右上角的注册/登录按钮。
登录完成后回来到我们的工作空间(有个人和团体的)
2. 了解基本功能和内容
进入工作空间后,我们可以在左边看到一些木块,拢共分为三大类
-
开发空间——我们可以在开发空间看到我们创建的项目
-
空间模板——在空间模板里面有许多模板可以使用,不关你是python,java,C,vue语言,都有模板可供使用
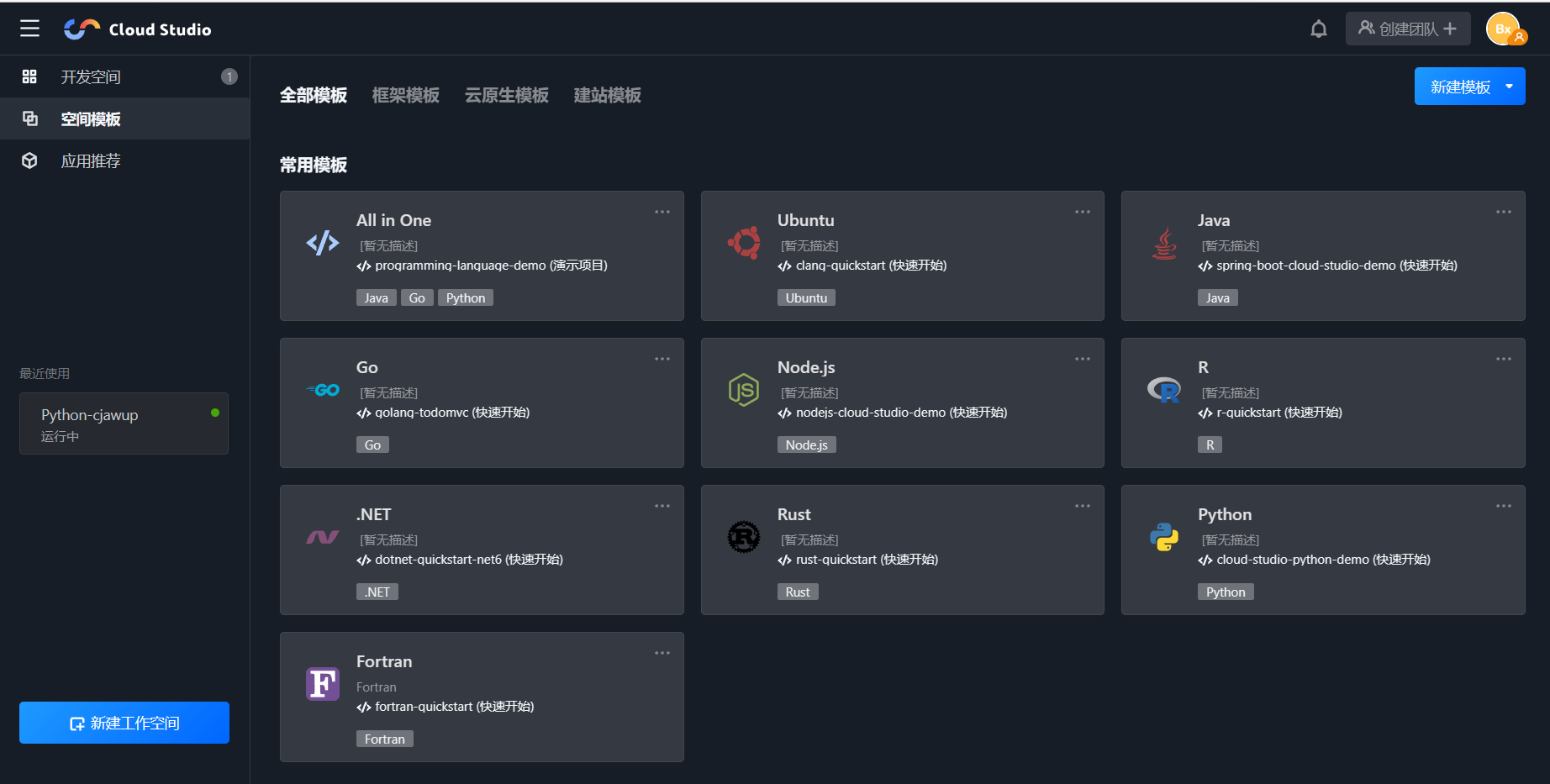
-
应用推荐——这里面是各位大佬制作好的项目,如果对某个项目感兴趣,想观摩源代码,我们只需要点击之后,点击Fork按钮,就可以将大佬们的项目copy到我们自己的工作空间。
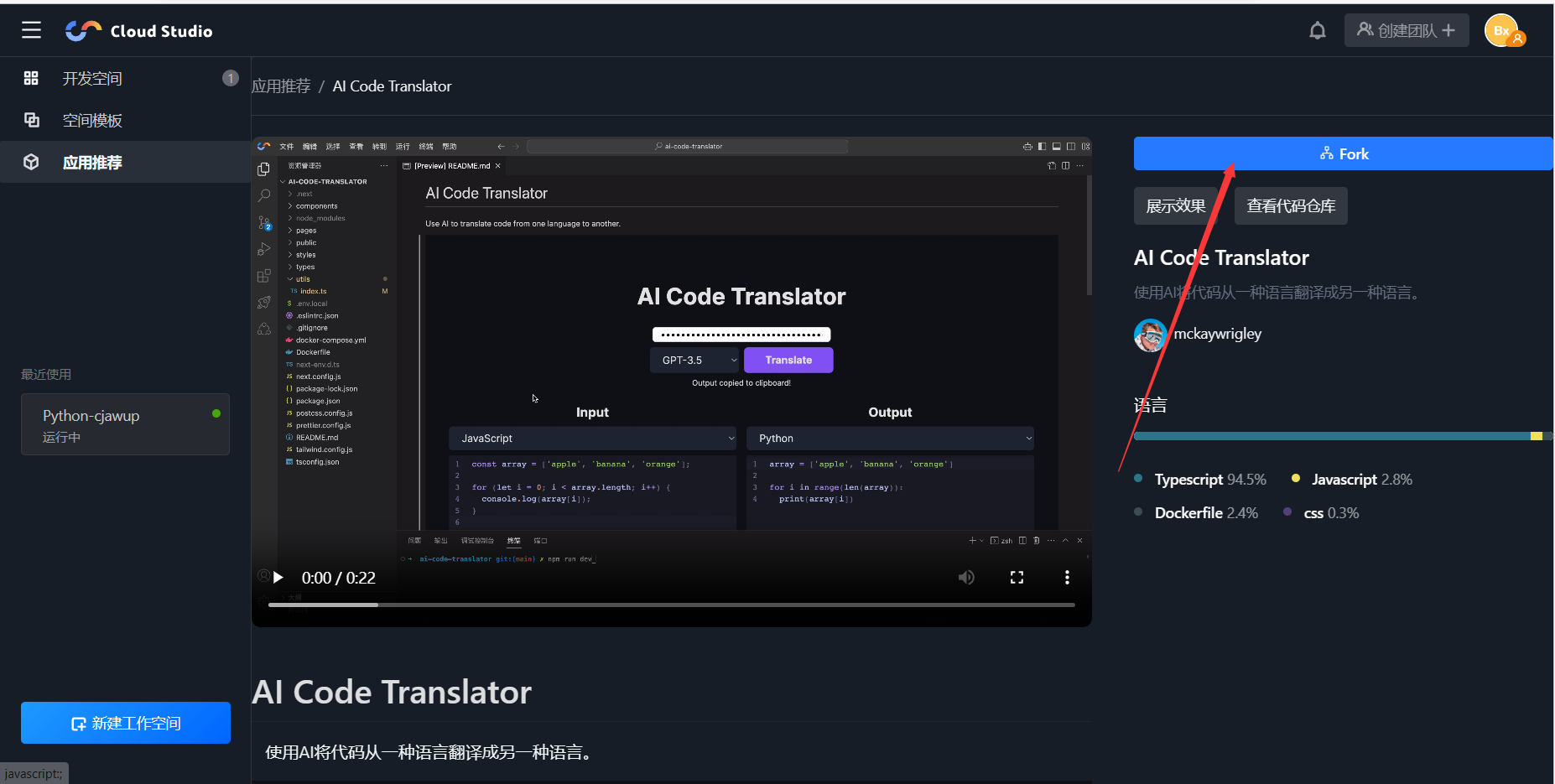
3. 创建Python模板
我们在空间模板中找到Python模板,然后点击一下就可以快速创建了,当然这需要一定的时间,不过时间也不长
我们的工作空间窗户建好之后,我们会发现自动运行了一个Demo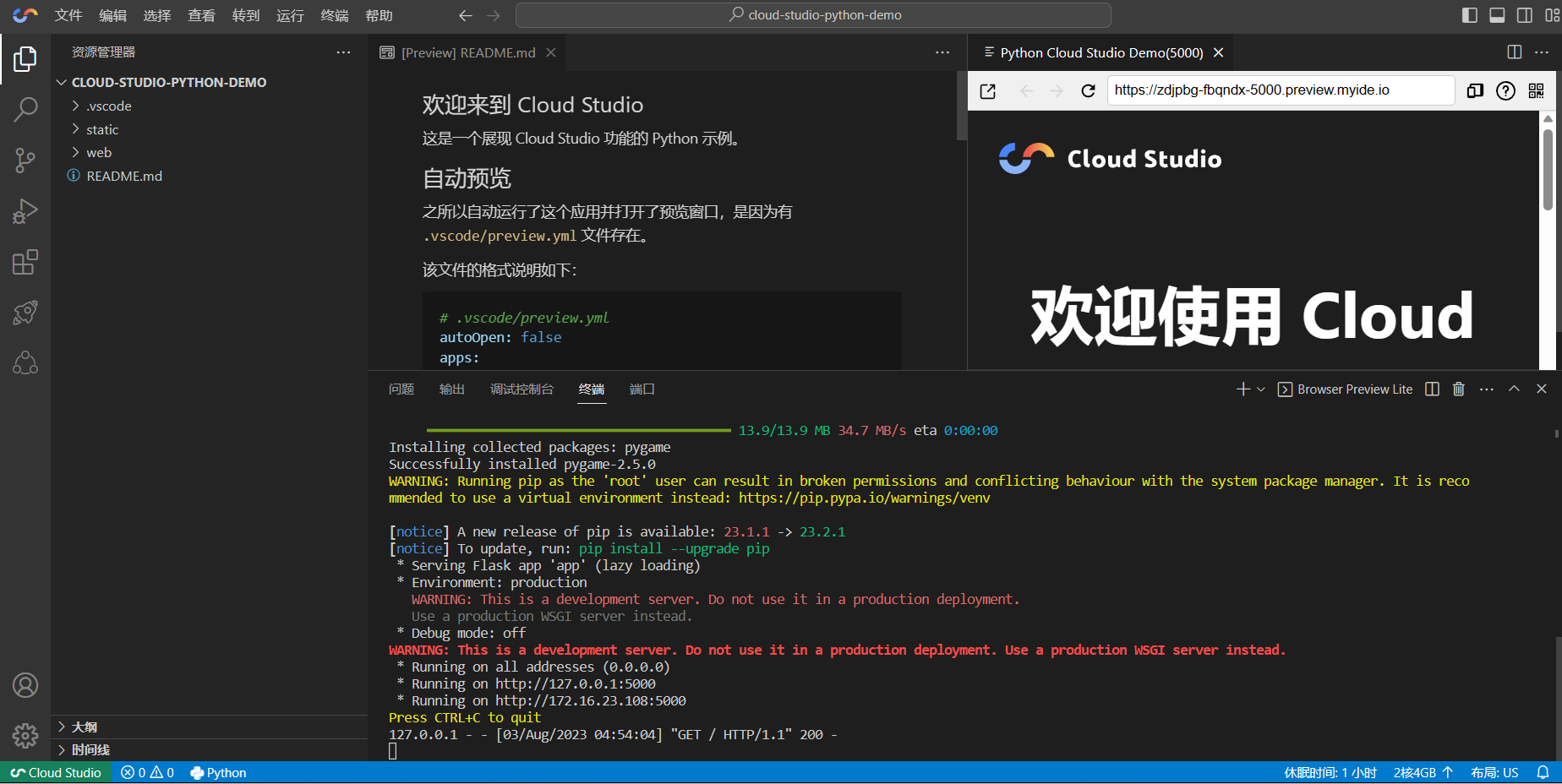
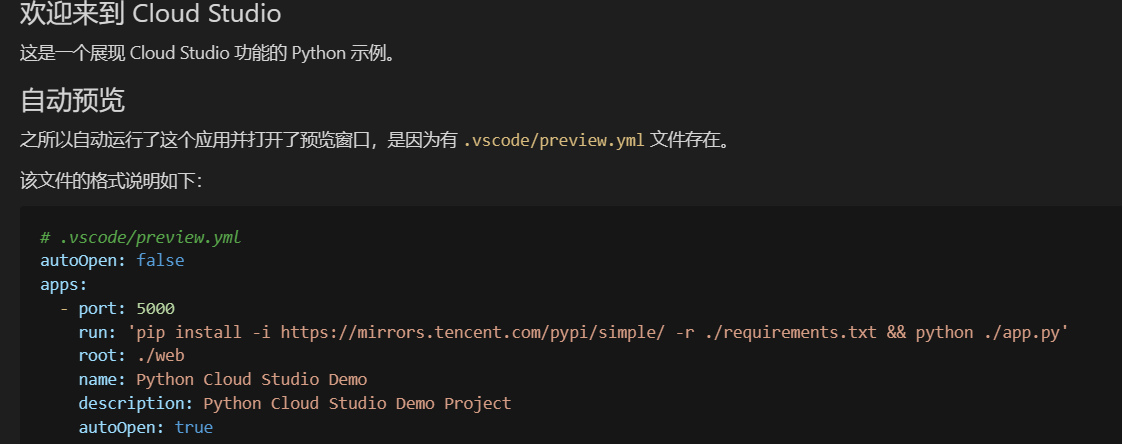
而在README文件中我们也可以看到关于这个Demo的相关介绍
当然我们不想运行的话也是可以直接删掉的。
4. 使用pip下载Scrapy库
虽然我使用pip list命令发现已经初始化了很多类库,比如flask,pygame等比较常用的,但是Scrapy是没有的,同样的,我也并没有发现Django库,我们使用的话,最好先查看一下有没有我们需要的类库。
先将我们不需要的文件删除掉,然后打开终端
之后再使用我们的pip工具下载我们需要的类库pip install Scrapy
下载完成后以防万一,我们再使用pip list命令检查一下是否安装成功

安装成功后我们就可以开始创建项目了
5. 创建Scrapy项目
创建Scrapy项目需要在终端输出命令创建,可别下载完就把终端×了啊
Scrapy startproject 项目名
出现下图内容就是创建成果了,同样的,我们还可以直接观察我们工作空间的目录,创建完成后会出现一个与项目名称同名的目录,那就是创建成果了
6. 创建爬虫文件
还是我们的终端,打开后切换到我们的项目目录下面,开始创建爬虫文件
cd 项目名称 // 切换到项目根目录
scrapy genspider qidian_spider www.xxx.com // 创建名字为qidian_spider,域名为www.xxx.com的爬虫文件

显示这样就是我们的爬虫创建成果啦,当然爬虫开始工作还需要我们编写代码,现在还需要编写代码
先打开看看怎么个事
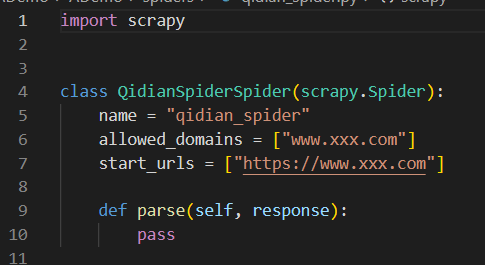
import scrapy # 使用的类库class QidianSpiderSpider(scrapy.Spider):name = "qidian_spider" # 爬虫名allowed_domains = ["www.xxx.com"] # 通域名start_urls = ["https://www.xxx.com"] #具体爬取的urldef parse(self, response):#爬虫代码编写在这里pass7. 确认爬取目标
爬取起点中文网月票榜上小说,获取小说名,作者名,连载状态,小说简介
我们要爬取某个网站,首先一点就是先获取到网站的URL,所以网站的URL就是:https://www.qidian.com/rank/yuepiao/
所以我们的代码中就可以修改url了
将start_urls = ["https://www.xxx.com"]
修改为start_urls = ["https://www.qidian.com/rank/yuepiao/"]
8. 修改项目配置
在没学Scrapy之前,我们都需要在确认网站url后填写headers头部信息,比如user_agent和cookies,那么在Scrapy中我们也需要填写这种头部信息
找到项目内的setting.py文件打开
.
将里面的内容修改加添加一些
将20行的ROBOTSTXT_OBEY = True改为ROBOTSTXT_OBEY = False
这个的意思是是否遵循机器人协议,默认是true,需要改为false
不然我们的爬虫有很多都无法爬取
添加代码:USER_AGENT:"你自己浏览器的请求头"
9. 编写爬取代码
import scrapyclass MonthlytickrtSpider(scrapy.Spider):name = "qidian_spider"allowed_domains = ["www.qidian.com"]start_urls = ["https://www.qidian.com/rank/yuepiao/"]def parse(self, response):print("===============项目开始运行===============") yuepiao_list = response.xpath('//div[@class="book-mid-info"]') # 月票榜小说数据列表data_list = [] # 创建空列表容纳每一本小说的数据"""data_dic = {也可以创建一个字典来存储}""" for i in yuepiao_list:book_name = i.xpath('h2/a/text()').extract()[0] # 小说名book_author = i.xpath('p[1]/a[1]/text()').extract()[0] # 作者名book_intro = i.xpath('p[@class="intro"]/text()').extract()[0] # 小说简介book_type = i.xpath('p[1]/a[2]/text()').extract()[0] # 小说更新状态book_src = i.xpath('h2/a/@href').extract()[0] # 小说链接book_data = {"小说名": book_name,"作者": book_author,"简介": book_intro,"更新状态": book_type,"链接": book_src,# 将取到每个小说的数据存入字典中}data_list.append(book_data) # 将字典存入列表# data_list[name] = book_data 将字典存入字典,以小说名为键print(data_list) # 终端查看小说数据return data_list
好好好,代码已经写完了,那么我们来看看运行效果吧

可以看到我们的爬虫也是成功的爬取到了我们想要的数据,那么我们的数据如何保存下来呢?
有两种办法,一种是使用我们在Python基础学过的os模块,一种是Scrapy自带的数据保存方法
10. 数据保存
1. 使用Scrapy的方法保存
Scrapy给我们了四种保存数据的方式,分别是json, json line, xml, csv
不需要编写代码,只需要在运行项目的时候添加命令参数即可
scrapy crawl 项目名称 -o 文件名称.你想要的格式
比如我们现在使用json的格式储存,我们只需要
scrapy crawl qidian_spider -o data.json
这样我们就可以看到在根目录生成了一个json格式的data文件,我们点进去看看
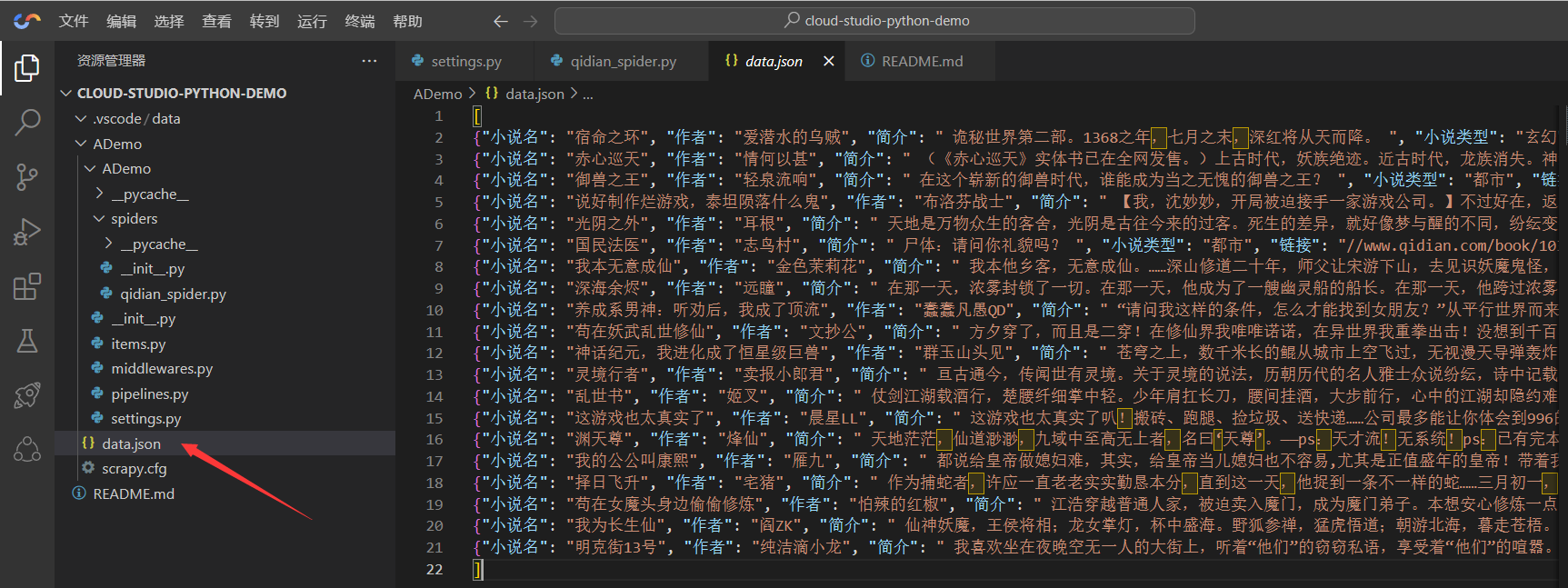
好了,这就成功了
2. 使用os模块保存数据
我们可以使用python自带的os模块来对文件进行操作
在爬虫里面添加的代码如下
with open('data.txt','w') as f:f.write(str(data_list))
注意添加到函数下面,return上面
效果如图:
使用Git管理代码
1. 填写好项目的README文件
## 欢迎来到 Cloud Studio ##这是布小禅使用Clould Studio尝试编写的一个小小的爬虫Python项目。## 项目介绍爬取起点小说网月票榜榜单内小说,书荒的书虫有福音了哈使用Scrapy爬虫框架,当然也仅仅只是用了一点,属于是使用大炮打蚊子了## 运行项目常见的Scrapy运行,使用命令`srapy crawl 项目内模块名`。需要注意的是,你需要在运行项目之前切换到项目内,而不是Clould Studio的默认目录,那样你会运行失败的
2. 使用git将代码上传到Gitee
我们先打开终端,输入git init初始化代码仓库
然后
git add .
git commit -m "爬取起点月票榜数据"
git clone git remote add origin # 仓库链接
git push -u origin master # 上传gitee
3. 项目完成销毁工作空间
先将工作空间关闭
退出之后回到工作空间,可以点击三个点删除

结语
相较于传统的IDE来说,Clould Studio更为的快捷和方便,不需要复杂的环境配置,不需要下载任何东西,只需要有一台能够连接互联网的电脑就可以进行开发工作了。
更为难能可贵的是,Clould Studio不仅仅没有因为快捷方便而舍弃了一部分功能,还在拥有大多数IDE功能的前提下增加了很多功能。比如新增的AI代码助手,模板一键搭建等都是很方便的。
以往除了vscode之外,我们想要一个全能的编辑器是很难,而Clould Studio就可以全能,什么语言它都兼容,而且写多个语言也不需要下载多个语言的编译器,就可以直接上手,为新手开发者和学生提供了很大的便利。
目前还没看到有缺点,是一款很优秀的软件,很适合入手。
相关文章:
[腾讯云 Cloud studio 实战训练营] 制作Scrapy Demo爬取起点网月票榜小说数据
首语 最近接触到了一个关于云开发的IDE,什么意思呢? 就是我们通常开发不是在电脑上吗,既要下载编译器,还要下载合适的编辑器,有的时候甚至还需要配置开发环境,有些繁琐。而这个云开发的IDE就是只需要一台…...

使用paddle进行酒店评论的情感分类5——batch准备
把原始语料中的每个句子通过截断和填充,转换成一个固定长度的句子,并将所有数据整理成mini-batch,用于训练模型,下面代码参照paddle官方 # 库文件导入 # encodingutf8 import re import random import requests import numpy as n…...
04-1_Qt 5.9 C++开发指南_常用界面设计组件_字符串QString
本章主要介绍Qt中的常用界面设计组件,因为更多的是涉及如何使用,因此会强调使用,也就是更多针对实例,而对于一些细节问题,需要参考《Qt5.9 c开发指南》进行学习。 文章目录 1. 字符串与普通转换、进制转换1.1 可视化U…...
Centos 从0搭建grafana和Prometheus 服务以及问题解决
下载 虚拟机下载 https://customerconnect.vmware.com/en/downloads/info/slug/desktop_end_user_computing/vmware_workstation_player/17_0 cenos 镜像下载 https://www.centos.org/download/ grafana 服务下载 https://grafana.com/grafana/download/7.4.0?platformlinux …...

【代码解读】RRNet: A Hybrid Detector for Object Detection in Drone-captured Images
文章目录 1. train.py2. DistributedWrapper类2.1 init函数2.2 train函数2.3 dist_training_process函数 3. RRNetOperator类3.1 init函数3.1.1 make_dataloader函数 3.2 training_process函数3.2.1 criterion函数 4. RRNet类(网络模型类)4.1 init函数4.…...
python人工智能可以干什么,python人工智能能干什么
大家好,给大家分享一下python做人工智能需要什么水平,很多人还不知道这一点。下面详细解释一下。现在让我们来看看! 人工智能包含常用机器学习和深度学习两个很重要的模块,而python拥有matplotlib、Numpy、sklearn、keras等大量的…...
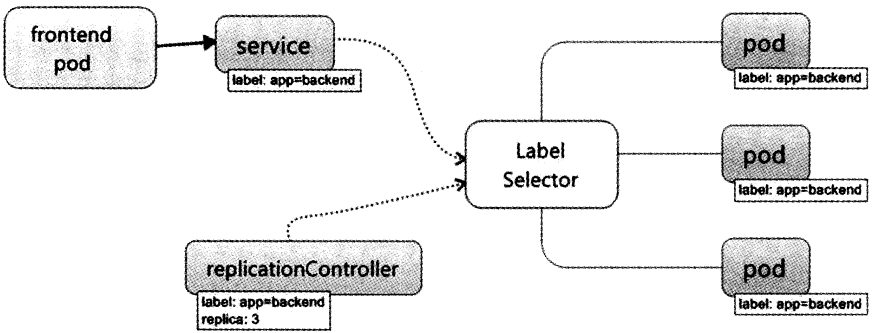
K8s工作原理
K8s title: Kubernetes之初探 subtitle: K8s的工作原理 date: 2018-09-18 18:26:37K8s概述 我清晰地记得曾经读到过的一篇博文,上面是这样写的, “云端教父AWS云端架构策略副总裁Adrian Cockcroft曾指出,两者虽然都是运用容器技术࿰…...
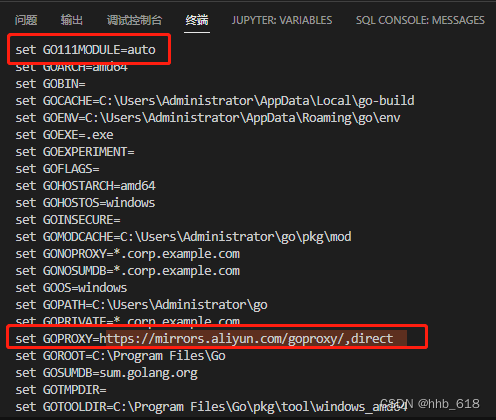
go错误集(持续更新)
1.提示以下报错 Build Error: go build -o c:\Users\Administrator\Desktop__debug_bin2343731882.exe -gcflags all-N -l . go: go.mod file not found in current directory or any parent directory; see ‘go help modules’ (exit status 1) 解决办法: go …...
【Docker】Docker中network的概要、常用命令、网络模式以及底层ip和容器映射变化的详细讲解
🚀欢迎来到本文🚀 🍉个人简介:陈童学哦,目前学习C/C、算法、Python、Java等方向,一个正在慢慢前行的普通人。 🏀系列专栏:陈童学的日记 💡其他专栏:CSTL&…...
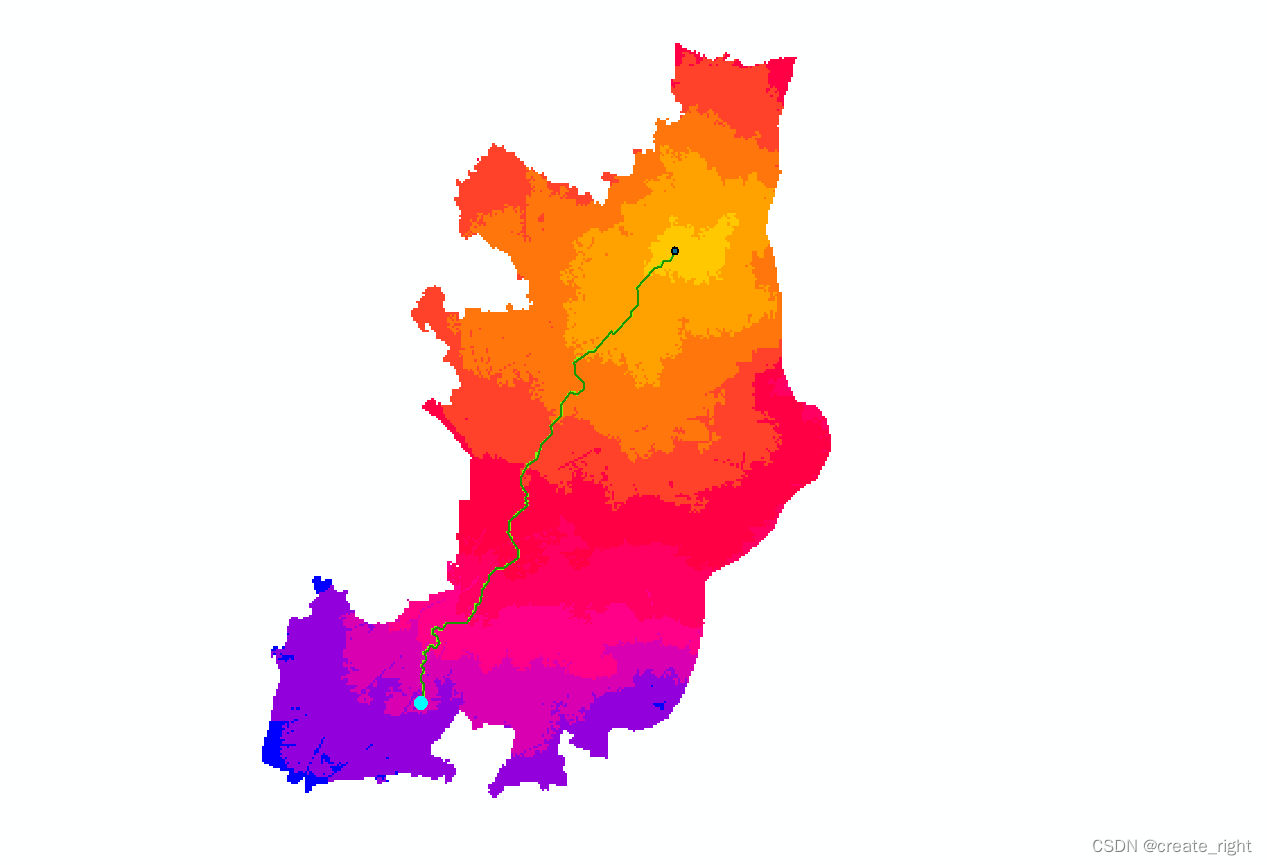
arcgis栅格数据之最佳路径分析
1、打开arcmap,加载数据,需要对影像进行监督分类,如下: 这里任选一种监督分类的方法(最大似然法),如下: 这里会先生成一个.ecd文件,然后再利用.ecd文件对影像进行分类。如…...

docker服务器部署Django
Django是一个广泛使用的Python Web框架,而Docker是一个增强应用程序部署的流行容器平台。结合这两个技术,可以轻松地部署和维护Django应用程序。在本文中,我们将探讨如何使用Docker在服务器上部署Django应用程序。 1、安装Docker和Docker Co…...
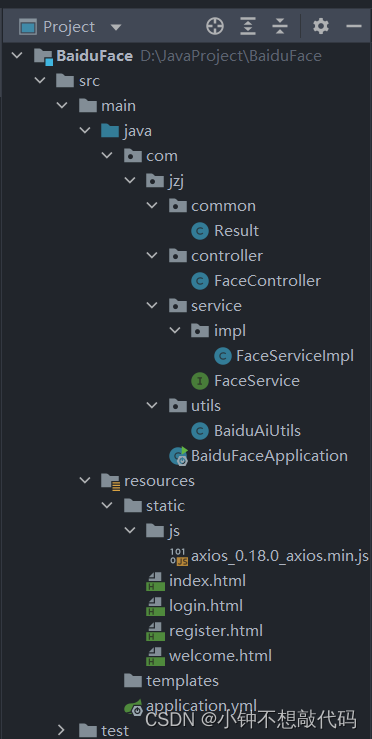
SpringBoot集成百度人脸识别实现登陆注册功能Demo(二)
前言 上一篇SpringBoot集成百度人脸demo中我使用的是调用本机摄像头完成人脸注册,本次demo根据业务需求的不同我采用文件上传的方式实现人脸注册。 效果演示 首页 注册 后端响应数据: 登录 后端响应数据: 项目结构 后端代码实现 1、Bai…...

FPGA纯verilog实现 LZMA 数据压缩,提供工程源码和技术支持
目录 1、前言2、我这儿已有的FPGA压缩算法方案3、FPGA LZMA数据压缩功能和性能4、FPGA LZMA 数据压缩设计方案输入输出接口描述数据处理流程LZ检索器数据同步LZMA 压缩器 为输出LZMA压缩流添加文件头 5、vivado仿真6、福利:工程代码的获取 1、前言 说到FPGA的应用&…...
C++实现一个链栈
C实现一个链栈 什么是链栈如何实现链栈链栈的实现开发环境代码实现运行结果 什么是链栈 链栈不名思意,就是既具有链表的特性,又具有栈的特性。 即: 链栈中的元素由指针域和数据域组成,通过指针指向下一个元素;2.链栈同…...
Vue电商项目--VUE插件的使用及原理
图片懒加载 图片懒加载,就是图片延迟加载。只加载页面可视区域上的图片,等滚动到页面下面时,再加载对应视口上的图片 而在vue中有一个插件 vue-lazyload - npm (npmjs.com) npm i vue-lazyload 去使用他,这里我们引入了一张图片…...

2.部署kubernetes的组件
文章目录 部署kubernetes单master的K8S集群Linux初始化部署etcd证书环境etcd软件备份还原etcd 部署master组件部署apiserver部署controller-manager部署scheduler部署kubectl 部署node组件部署dockernode01节点node02节点部署kube-proxy K8S 二进制搭建总结 部署kubernetes 常见…...

后端开发4.Elasticsearch的搭建
使用docker安装 安装elasticsearch 拉取镜像 docker pull elasticsearch:7.17.0容器间建立通信,创建 elastic的网关 docker network create elastic 创建es容器【自启动】【虚拟机处理器数量至少两个】 docker run --restart=always -p 9200:9200 -p 9300:9300 -e "…...
嵌入式该往哪个方向发展?
1. 你所在的城市嵌入式Linux岗位多吗?我觉得这是影响你做决定的另一个大问题。我们学嵌入式Linux这门技术,绝大部分人是为了从事相关的工作,而不是陶冶情操。但是根据火哥统计来看,嵌入式Linux的普遍薪资虽然高于单片机࿰…...

非凸科技受邀参加中科大线上量化分享
7月30日,非凸科技受邀参加由中国科学技术大学管理学院学生会、超级量化共同组织的“打开量化私募的黑箱”线上活动,分享量化前沿以及求职经验,助力同学们拿到心仪的offer。 活动上,非凸科技量化策略负责人陆一洲从多个角度分享了如…...
)
Linux 命令之 - chown(改变文件拥有者及所属组)
基本语法: chown [-R] 账号名称 文件或目录 chown [-R] 账号名称:用户组名称 文件或目录 参数: -R : 进行递归( recursive )的持续更改,即连同子目录下的所有文件、目录 都更新成为这个用户组。常常用在更改某一目录的情况。 参考&…...

Ubuntu 22.04 下配置 Arduino IDE 2.x:从安装到第三方库的完整避坑指南
1. 准备工作:下载Arduino IDE 2.x 在Ubuntu 22.04上配置Arduino开发环境,第一步自然是获取官方IDE。我推荐直接从Arduino官网下载最新版本,避免使用老旧软件包带来的兼容性问题。打开浏览器访问arduino.cc/en/software,你会看到两…...

基于Telegram的AI智能体框架:从原理到实践部署指南
1. 项目概述:一个基于Telegram的AI智能体框架最近在GitHub上看到一个挺有意思的项目,叫openclaw-telegram-ai-agent。光看名字,你大概能猜到它是个什么东西:一个运行在Telegram平台上的AI智能体(Agent)。但…...

告别卡顿!CXPatcher:让Mac上的Windows游戏性能飙升的终极修复工具
告别卡顿!CXPatcher:让Mac上的Windows游戏性能飙升的终极修复工具 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 你是否曾在Mac上…...
:从模糊描述到博物馆级输出的9类失效提示词避坑清单)
Midjourney后印象派风格实战手册(2024最新版):从模糊描述到博物馆级输出的9类失效提示词避坑清单
更多请点击: https://intelliparadigm.com 第一章:后印象派风格的本质解构与Midjourney语义映射 后印象派并非单一技法流派,而是一场以主观表达重构视觉真实性的认知革命。其核心在于色彩的情感自主性、形体的结构性简化,以及空间…...

大湾区制造企业品牌突围:从“有品无牌”到价值孵化
当看到2023年凯度BrandZ全球品牌百强榜上苹果以8800亿美元蝉联榜首,14个中国品牌入围时,我们能清晰地感受到品牌价值对企业的重要性。然而,在粤港澳大湾区(广东),众多制造型中小企业面临着尴尬的局面&#…...

避开STM32G4比较器的那些‘坑’:LOCK机制、EXTI连接与GPIO配置详解
STM32G4比较器开发实战:LOCK机制、EXTI映射与GPIO配置的深度解析 当你在深夜调试STM32G4的比较器模块时,突然发现中断死活不触发,或者LOCK寄存器配置后无法修改参数,这种挫败感我深有体会。本文将带你直击STM32G4比较器开发中最容…...

5个关键场景掌握openpilot:开源自动驾驶系统的实战指南
5个关键场景掌握openpilot:开源自动驾驶系统的实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trendi…...

国密SM2的P7格式签名,和PKCS#7到底有啥区别?一张图讲清楚
国密SM2的P7格式签名与PKCS#7核心差异解析:从结构到实战 在密码学应用开发中,数字签名格式的标准化是实现安全通信的基础。当开发者从国际通用的PKCS#7标准转向中国自主研发的国密SM2算法体系时,P7签名格式的差异往往成为第一个需要跨越的技术…...

如何3步搞定LaTeX中文排版?告别字体缺失烦恼的终极方案
如何3步搞定LaTeX中文排版?告别字体缺失烦恼的终极方案 【免费下载链接】latex-chinese-fonts Simplified Chinese fonts for the LaTeX typesetting. 项目地址: https://gitcode.com/gh_mirrors/la/latex-chinese-fonts 还在为LaTeX中文排版头疼吗ÿ…...

Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度
Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度 【免费下载链接】glass-browser A floating, always-on-top, transparent browser for Windows. 项目地址: https://gitcode.com/gh_mirrors/gl/glass-browser 当你在编写代码时需要查…...