pytorch求导
pytorch求导的初步认识
requires_grad
tensor(data, dtype=None, device=None, requires_grad=False)
requires_grad是torch.tensor类的一个属性。如果设置为True,它会告诉PyTorch跟踪对该张量的操作,允许在反向传播期间计算梯度。
x.requires_grad 判断一个tensor是否可以求导,返回布尔值
叶子变量-leaf variable
- 对于requires_grad=False 的张量,我们约定俗成地把它们归为叶子张量。
- 对于requires_grad为True的张量,如果他们是由用户创建的,则它们是叶张量。

如果某一个叶子变量,开始时不可导的,后面想设置它可导,该怎么办?
x.requires_grad_(True/False) 设置tensor的可导与不可导
注意:这种方法只适用于设置叶子变量,否则会出现如下错误

x = torch.tensor(2.0, requires_grad=True)
y = torch.pow(x, 2)
z = torch.add(y, 3)
z.backward()
print(x.grad)
print(y.grad)tensor(4.)
None
-
创建一个浮点型张量x,其值为2.0,并设置
requires_grad=True,使PyTorch可以跟踪x的计算历史并允许计算它的梯度。 -
创建一个新张量y,y是x的平方。
-
创建一个新张量z,z是y和3的和。
-
调用
z.backward()进行反向传播,计算z关于x的梯度。 -
打印x的梯度,应该是2*x=4.0。
-
试图打印y的梯度。但是,PyTorch默认只计算并保留叶子节点的梯度。非叶子节点的梯度在计算过程中会被释放掉,因此y的梯度应该为None。
保留中间变量的梯度
tensor.retain_grad()

retain_grad()和retain_graph是用来处理两个不同的情况
-
retain_grad(): 用于保留非叶子节点的梯度。如果你想在反向传播结束后查看或使用非叶子节点的梯度,你应该在非叶子节点上调用.retain_grad()。 -
retain_graph: 当你调用.backward()时,PyTorch会自动清除计算图以释放内存。这意味着你不能在同一个计算图上多次调用.backward()。但是,如果你需要多次调用.backward()(例如在某些特定的优化算法中),你可以在调用.backward()时设置retain_graph=True来保留计算图。
.grad
通过tensor的grad属性查看所求得的梯度值。
.grad_fn
在PyTorch中,.grad_fn属性是一个引用到创建该Tensor的Function对象。也就是说,这个属性可以告诉你这个张量是如何生成的。对于由用户直接创建的张量,它的.grad_fn是None。对于由某个操作创建的张量,.grad_fn将引用到一个与这个操作相关的对象。
import torchx = torch.tensor([1.0, 2.0], requires_grad=True)
y = x * 2
z = y.mean()print(x.grad_fn)
print(y.grad_fn)
print(z.grad_fn)

这里,x是由用户直接创建的,所以x.grad_fn是None。y是通过乘法操作创建的,所以y.grad_fn是一个MulBackward0对象,这表明y是通过乘法操作创建的。z是通过求平均数操作创建的,所以z.grad_fn是一个MeanBackward0对象。

pytorch自动求导实现神经网络
numpy手动实现
import numpy as np
import matplotlib.pyplot as pltN, D_in, H, D_out = 64, 1000, 100, 10 # 64个训练数据(只是一个batch),输入是1000维,hidden是100维,输出是10维'''随机创建一些训练数据'''
X = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)W1 = np.random.randn(D_in, H) # 1000维转成100维
W2 = np.random.randn(H, D_out) # 100维转成10维learning_rate = 1e-6all_loss = []epoch = 500for t in range(500): # 做500次迭代'''前向传播(forward pass)'''h = X.dot(W1) # N * Hh_relu = np.maximum(h, 0) # 激活函数,N * Hy_hat = h_relu.dot(W2) # N * D_out'''计算损失函数(compute loss)'''loss = np.square(y_hat - y).sum() # 均方误差,忽略了÷Nprint("Epoch:{} Loss:{}".format(t, loss)) # 打印每个迭代的损失all_loss.append(loss)'''后向传播(backward pass)'''# 计算梯度(此处没用torch,用最普通的链式求导,最终要得到 d{loss}/dX)grad_y_hat = 2.0 * (y_hat - y) # d{loss}/d{y_hat},N * D_outgrad_W2 = h_relu.T.dot(grad_y_hat) # 看前向传播中的第三个式子,d{loss}/d{W2},H * D_outgrad_h_relu = grad_y_hat.dot(W2.T) # 看前向传播中的第三个式子,d{loss}/d{h_relu},N * Hgrad_h = grad_h_relu.copy() # 这是h>0时的情况,d{h_relu}/d{h}=1grad_h[h < 0] = 0 # d{loss}/d{h}grad_W1 = X.T.dot(grad_h) # 看前向传播中的第一个式子,d{loss}/d{W1}'''参数更新(update weights of W1 and W2)'''W1 -= learning_rate * grad_W1W2 -= learning_rate * grad_W2plt.plot(all_loss)
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.show()pytorch自动实现
import torchN, D_in, H, D_out = 64, 1000, 100, 10 # 64个训练数据(只是一个batch),输入是1000维,hidden是100维,输出是10维'''随机创建一些训练数据'''
X = torch.randn(N, D_in)
y = torch.randn(N, D_out)W1 = torch.randn(D_in, H, requires_grad=True) # 1000维转成100维
W2 = torch.randn(H, D_out, requires_grad=True) # 100维转成10维learning_rate = 1e-6for t in range(500): # 做500次迭代'''前向传播(forward pass)'''y_hat = X.mm(W1).clamp(min=0).mm(W2) # N * D_out'''计算损失函数(compute loss)'''loss = (y_hat - y).pow(2).sum() # 均方误差,忽略了÷N,loss就是一个计算图(computation graph)print("Epoch:{} Loss:{}".format(t, loss.item())) # 打印每个迭代的损失'''后向传播(backward pass)'''loss.backward()'''参数更新(update weights of W1 and W2)'''with torch.no_grad():W1 -= learning_rate * W1.gradW2 -= learning_rate * W2.gradW1.grad.zero_()W2.grad.zero_()
pytorch手动实现
import torch
import matplotlib.pyplot as pltN, D_in, H, D_out = 64, 1000, 100, 10 # 64个训练数据(只是一个batch),输入是1000维,hidden是100维,输出是10维'''随机创建一些训练数据'''
X = torch.randn(N, D_in)
y = torch.randn(N, D_out)W1 = torch.randn(D_in, H) # 1000维转成100维
W2 = torch.randn(H, D_out) # 100维转成10维learning_rate = 1e-6all_loss = []for t in range(500): # 做500次迭代'''前向传播(forward pass)'''h = X.mm(W1) # N * Hh_relu = h.clamp(min=0) # 激活函数,N * Hy_hat = h_relu.mm(W2) # N * D_out'''计算损失函数(compute loss)'''loss = (y_hat - y).pow(2).sum().item() # 均方误差,忽略了÷Nprint("Epoch:{} Loss:{}".format(t, loss)) # 打印每个迭代的损失all_loss.append(loss)'''后向传播(backward pass)'''# 计算梯度(此处没用torch,用最普通的链式求导,最终要得到 d{loss}/dX)grad_y_hat = 2.0 * (y_hat - y) # d{loss}/d{y_hat},N * D_outgrad_W2 = h_relu.t().mm(grad_y_hat) # 看前向传播中的第三个式子,d{loss}/d{W2},H * D_outgrad_h_relu = grad_y_hat.mm(W2.t()) # 看前向传播中的第三个式子,d{loss}/d{h_relu},N * Hgrad_h = grad_h_relu.clone() # 这是h>0时的情况,d{h_relu}/d{h}=1grad_h[h < 0] = 0 # d{loss}/d{h}grad_W1 = X.t().mm(grad_h) # 看前向传播中的第一个式子,d{loss}/d{W1}'''参数更新(update weights of W1 and W2)'''W1 -= learning_rate * grad_W1W2 -= learning_rate * grad_W2plt.plot(all_loss)
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.show()torch.nn实现
import torch
import torch.nn as nn # 各种定义 neural network 的方法N, D_in, H, D_out = 64, 1000, 100, 10 # 64个训练数据(只是一个batch),输入是1000维,hidden是100维,输出是10维'''随机创建一些训练数据'''
X = torch.randn(N, D_in)
y = torch.randn(N, D_out)model = torch.nn.Sequential(torch.nn.Linear(D_in, H, bias=True), # W1 * X + b,默认Truetorch.nn.ReLU(),torch.nn.Linear(H, D_out)
)# model = model.cuda() #这是使用GPU的情况loss_fn = nn.MSELoss(reduction='sum')learning_rate = 1e-4for t in range(500): # 做500次迭代'''前向传播(forward pass)'''y_hat = model(X) # model(X) = model.forward(X), N * D_out'''计算损失函数(compute loss)'''loss = loss_fn(y_hat, y) # 均方误差,忽略了÷N,loss就是一个计算图(computation graph)print("Epoch:{} Loss:{}".format(t, loss.item())) # 打印每个迭代的损失'''后向传播(backward pass)'''loss.backward()'''参数更新(update weights of W1 and W2)'''with torch.no_grad():for param in model.parameters():param -= learning_rate * param.grad # 模型中所有的参数更新model.zero_grad()torch.nn的继承类
import torch
import torch.nn as nn # 各种定义 neural network 的方法
from torchsummary import summary
# pip install torchsummary
N, D_in, H, D_out = 64, 1000, 100, 10 # 64个训练数据(只是一个batch),输入是1000维,hidden是100维,输出是10维'''随机创建一些训练数据'''
X = torch.randn(N, D_in)
y = torch.randn(N, D_out)'''定义两层网络'''class TwoLayerNet(torch.nn.Module):def __init__(self, D_in, H, D_out):super(TwoLayerNet, self).__init__()# 定义模型结构self.linear1 = torch.nn.Linear(D_in, H, bias=False)self.linear2 = torch.nn.Linear(H, D_out, bias=False)def forward(self, x):y_hat = self.linear2(self.linear1(X).clamp(min=0))return y_hatmodel = TwoLayerNet(D_in, H, D_out)loss_fn = nn.MSELoss(reduction='sum')
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)for t in range(500): # 做500次迭代'''前向传播(forward pass)'''y_hat = model(X) # model.forward(), N * D_out'''计算损失函数(compute loss)'''loss = loss_fn(y_hat, y) # 均方误差,忽略了÷N,loss就是一个计算图(computation graph)print("Epoch:{} Loss:{}".format(t, loss.item())) # 打印每个迭代的损失optimizer.zero_grad() # 求导之前把 gradient 清空'''后向传播(backward pass)'''loss.backward()'''参数更新(update weights of W1 and W2)'''optimizer.step() # 一步把所有参数全更新print(summary(model, (64, 1000)))相关文章:
pytorch求导
pytorch求导的初步认识 requires_grad tensor(data, dtypeNone, deviceNone, requires_gradFalse)requires_grad是torch.tensor类的一个属性。如果设置为True,它会告诉PyTorch跟踪对该张量的操作,允许在反向传播期间计算梯度。 x.requires_grad 判…...

Java基础异常详解
Java基础异常详解 文章目录 Java基础异常详解编译时异常(Checked Exception):运行时异常(Unchecked Exception): Java中的异常是用于处理程序运行时出现的错误或异常情况的一种机制。 异常本身也是一个类。 异常分为…...

vue3+vue-i18n 监听语言的切换
最近在用 vue3 做一个后台管理系统,之前是只考虑中文,现在加了个需求是多语言。 本来也不是太难的需求,但是我用的并不熟悉,并且除了页面展示不同的语言,需求是在切换语言的时候在几个页面中需要做出一些自定义的行为&…...

【考研复习】24王道数据结构课后习题代码|2.3线性表的链式表示
文章目录 总结01 递归删除结点02 删除结点03 反向输出04 删除最小值05 逆置06 链表递增排序07 删除区间值08 找公共结点09 增序输出链表10 拆分链表--尾插11 拆分链表--头插12 删除相同元素13 合并链表14 生成含有公共元素的链表C15 求并集16 判断子序列17 判断循环链表是否对称…...
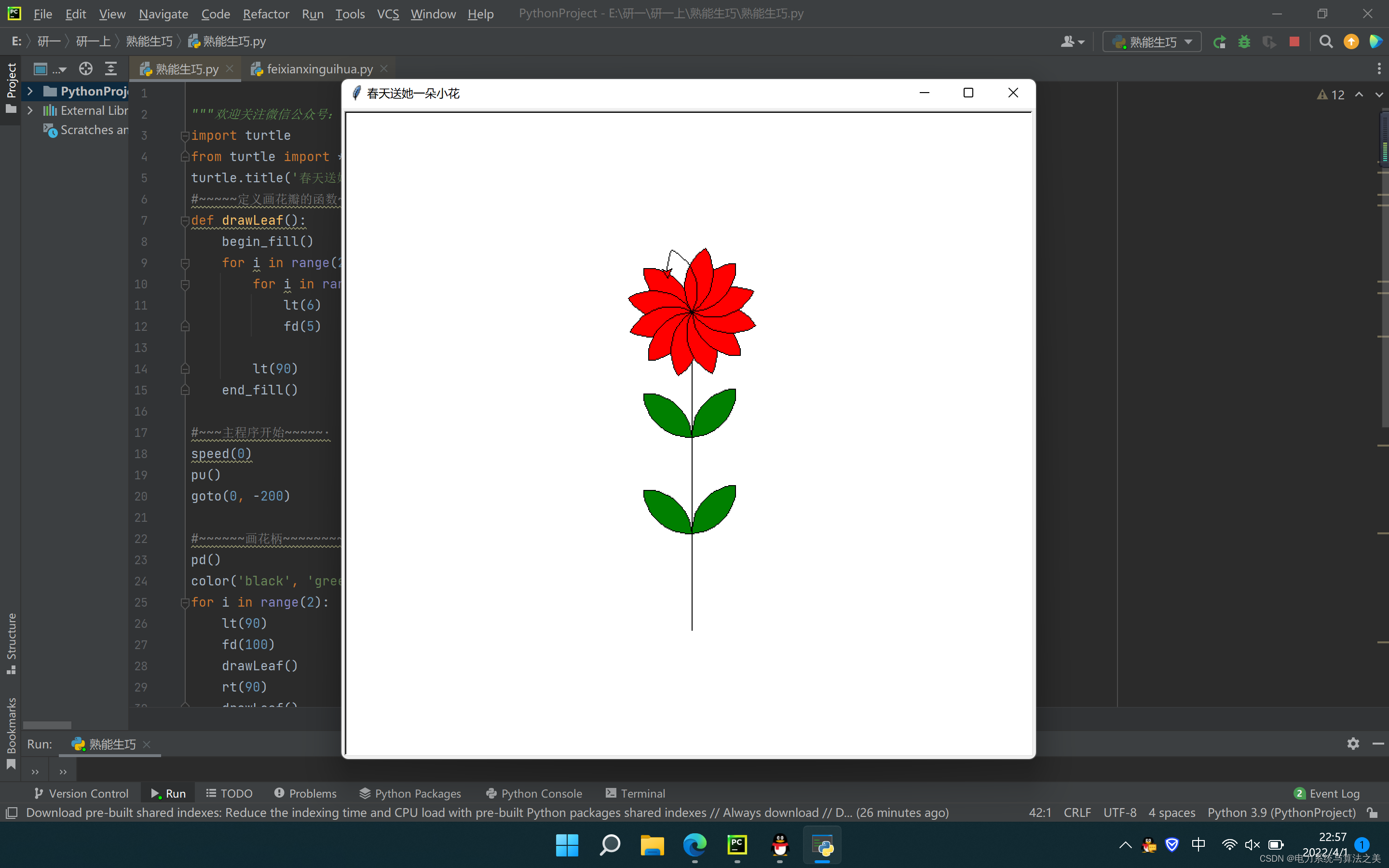
娇滴滴的一朵花(Python实现)
目录 1 娇滴滴的她 2 Python代码实现 1 娇滴滴的她 娇滴滴。双眉敛破春山色。春山色。 为君含笑,为君愁蹙。多情别後无消息。 此时更有谁知得。谁知得。夜深无寐,度江横笛。 2 Python代码实现 import turtle from turtle import * turtle.title(春天送她一朵小花)…...

Android AccessibilityService研究
AccessibilityService流程分析 AccessibilityService开启方式AccessibilityService 开启原理 AccessibilityService开启方式 . 在Framework里直接添加对应用app 服务component。 loadSetting(stmt, Settings.Secure.ACCESSIBILITY_ENABLED,1); loadSetting(stmt, Settings.Se…...

华为OD机试(含B卷)真题2023 算法分类版,58道20个算法分类,如果距离机考时间不多了,就看这个吧,稳稳的
目录 一、数据结构1、线性表2、优先队列3、滑动窗口4、二叉树5、并查集6、栈 二、算法1、基础算法2、字符串3、图4、动态规划5、数学 三、漫画算法2:小灰的算法进阶参与方式 很多小伙伴问我,华为OD机试算法题太多了,知识点繁杂,如…...
JMeter命令行执行+生成HTML报告
1、为什么用命令行模式 使用GUI方式启动jmeter,运行线程较多的测试时,会造成内存和CPU的大量消耗,导致客户机卡死; 所以一般采用的方式是在GUI模式下调整测试脚本,再用命令行模式执行; 命令行方式支持在…...

学习Boost二:从附录3来看编码习惯
附录C 关键字浅谈 在C11标准中(C11.2.12)总共定义了73个关键字(keyword)、2个“准”关键字(identifiers with special meaning)和11个操作符替代字(alternative representation)[1]。…...
STM32基础入门学习笔记:核心板 电路原理与驱动编程
文章目录: 一:LED灯操作 1.LED灯的点亮和熄灭 延迟闪烁 main.c led.c led.h BitAction枚举 2.LED呼吸灯(灯的强弱交替变化) main.c delay.c 3.按键控制LED灯 key.h key.c main.c 二:FLASH读写程序(有…...
最后一次模拟考试题解
哦我想这不用看都知道是为了水任务 T1 黑白染色 其实这题有原 什么手写体 md (指 markdown) 分析 首先这题如果你题目没看错的话 ,会发现其实他是 n m n \times m nm 让你求 n n n \times n nn 的区域内的点(不会只有我一个人题目看错了罢 然后我们会发现…...
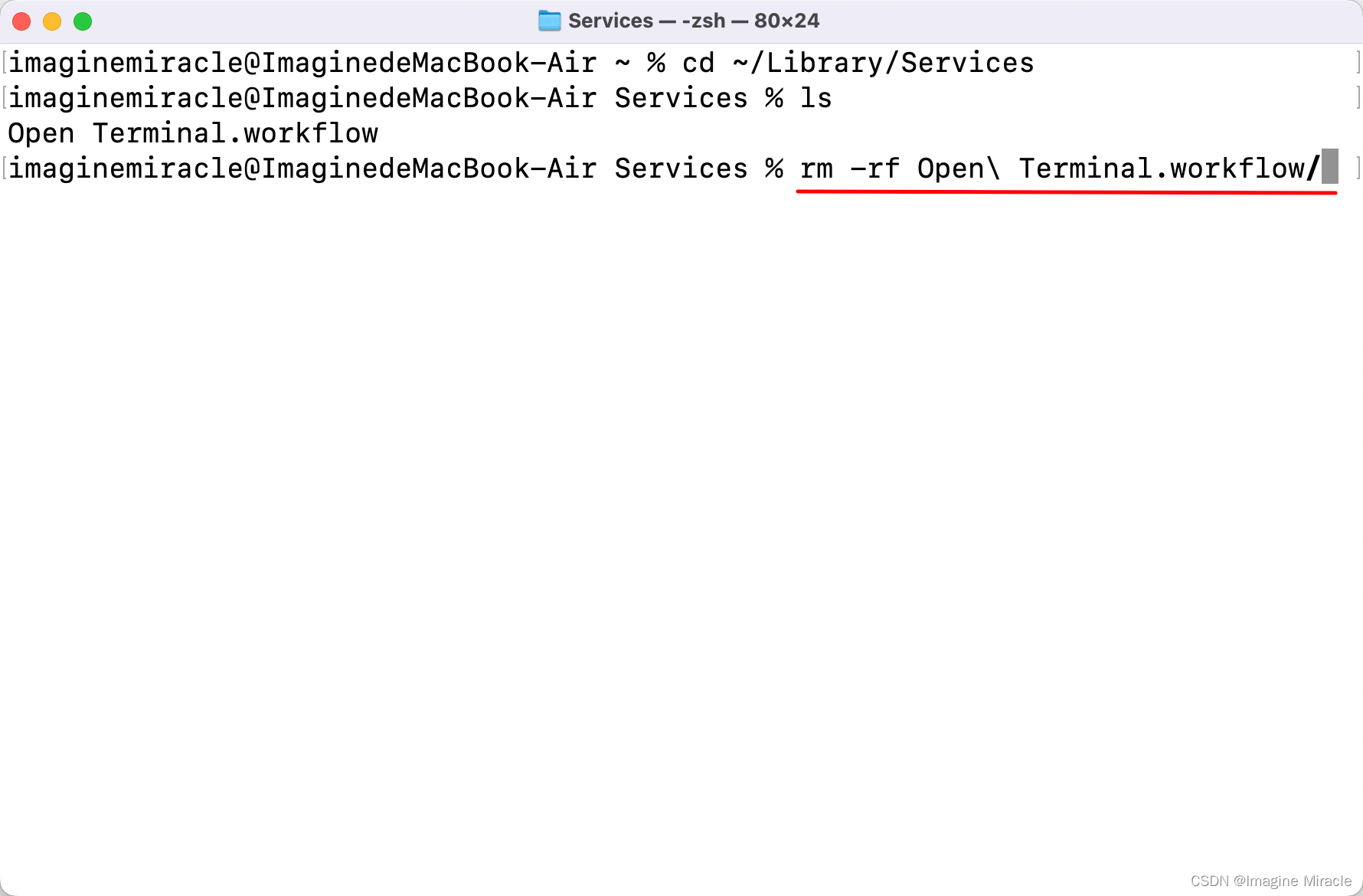
Mac 创建和删除 Automator 工作流程,设置 Terminal 快捷键
1. 创建 Automator 流程 本文以创建一个快捷键启动 Terminal 的自动操作为示例。 点击打开 自动操作; 点击 新建文稿 点击 快速操作 选择 运行 AppleScript 填入以下内容 保存名为 “Open Terminal” 打开 设置 > 键盘,选择 键盘快捷键 以此选择 服…...

2023华为OD机试真题B卷 Java 实现【最长的元音串】
前言 本题使用Java解答,如果需要Python代码,链接 题目 给定一个只由英文字母(a-z, A-Z)组成的字符串,找出其中最长的只包含元音字母(a, e, i, o, u, A, E, I, O, U)的子串,并返回其长度。如果不存在元音子串,则返回0。 输入: 一个由英文字母组成的字符串,长度大…...

网络防御之传输安全
1.什么是数据认证,有什么作用,有哪些实现的技术手段? 数据认证是一种权威的电子文档 作用:它能保证数据的完整性、可靠性、真实性 技术手段有数字签名、加密算法、哈希函数等 2.什么是身份认证,有什么作用,有哪些…...
【css】组合器
组合器是解释选择器之间关系的某种机制。在简单选择器器之间,可以包含一个组合器,从而实现简单选择器难以达到的效果。 CSS 中有四种组合器: 后代选择器 (空格):匹配属于指定元素后代的所有元素,示例:div …...

HTTPS、TLS加密传输
HTTPS、TLS加密传输 HTTPS、TLS加密传输1、HTTPS(HyperText Transfer Protocol Secure)2、TLS HTTPS、TLS加密传输 1、HTTPS(HyperText Transfer Protocol Secure) HTTPS(HyperText Transfer Protocol Secure&#x…...

docker frp 搭建 http + stcp 代理
所需服务器 2台 一台具有国外公网ip 一台具有国内 ip 内网外网都可以 外公网ip服务器配置如下 cat docker-compose.yamlversion: "2" services:frps:image: alpine:latesthostname: frpsrestart: alwayscontainer_name: frpsprivileged: trueuser: rootcommand: […...
项目出bug,找不到bug,如何拉回之前的版本
1.用gitee如何拉取代码 本文为转载于「闪耀太阳a」的原创文章原文链接:https://blog.csdn.net/Gufang617/article/details/119929145 怎么从gitee上拉取代码 1.首先找到gitee上想要拉取得代码URL地址 点击复制这里的https地址 1 ps:(另外一种方法&…...
vue-cli
vue-cli脚手架 案例一: 案例二: 案例三: 一、脚手架简介 Vue脚手架是Vue官方提供的标准化开发工具(开发平台),它提供命令行和UI界面,方便创建vue工程、配置第三方依赖、编译vue工程 1. …...
的不正确)
android获取屏幕分辨率的正确方法;获取到分辨率(垂直方向像素)的不正确
我通过下面的方法去获取屏幕分辨率的,但获取到的分辨率有时会不准确。原因是此方法有时候会忽略一些布局或控件的高度,从而得不到正确的高度。 public static String getDeviceResolution(Context context){//从系统服务中获取窗口管理器WindowManager w…...

用AI工具做技术课程:一个人完成录课、剪辑、上架全流程
软件测试从业者的知识变现新路径作为一名软件测试工程师,你手里握着大量值钱的东西——接口自动化怎么搭、性能瓶颈怎么定位、测试用例怎么设计才不漏测。这些东西在你的团队里可能是常识,但放到整个行业,就是别人愿意付费学习的硬通货。但一…...

实在Agent如何破解成本分析报告编制耗时耗力与数据滞后?企业架构师的避坑指南
摘要:在2026年的今天,尽管AI技术已深度普及,但许多企业的财务与运营部门仍深陷“数据泥潭”。传统的成本分析报告编制依赖于大量的人工导数、Excel汇总及跨系统搬运,导致报告产出即滞后,严重误导决策。作为一名深耕行业…...

AI驱动编辑预设:智能调色与音频处理实战指南
1. 项目概述:AI驱动的编辑预设库最近在折腾视频和图片后期的时候,发现一个挺有意思的项目,叫kaushalrao/ai-editor-presets。光看名字,你可能觉得这又是一个普通的滤镜包或者调色预设合集。但深入用下来,我发现它的核心…...

Linux内核构建自动化:jpoindexter/kern工具实战指南
1. 项目概述:一个被低估的Linux内核构建工具 如果你和我一样,长期在嵌入式开发、内核模块调试或者需要频繁定制Linux内核的岗位上工作,那么你一定对内核的配置、编译、打包这一套繁琐的流程感到又爱又恨。爱的是,这是深入理解操作…...

基于AI宏观流动性监测框架的黄金三日连跌研究:美联储加息预期按兵不动后的市场重定价逻辑
摘要:本文通过AI宏观利率模型、美元流动性监测系统与黄金波动率因子分析,结合美通胀数据、美债收益率变化及市场利率预期重定价过程,分析黄金连续三日回落背后的核心驱动逻辑,并探讨当前“高利率持续”环境下黄金资产的阶段性压力…...

重磅!国家首部NAD⁺抗衰共识发布,这11条建议必读!
2026年4月,国内首个《NAD⁺在衰老相关疾病中的作用及临床应用中国专家共识(2026版)》正式发布!这份由中华医学会老年医学分会牵头、汇聚全国衰老医学、代谢病、心血管病及神经病学等领域权威专家共同制定的国家级共识,…...

AWorksLP嵌入式系统移植FatFs驱动SD卡:从原理到实践全解析
1. 项目概述:为什么要在AWorksLP上折腾FatFs和SD卡?如果你正在用AWorksLP这类面向物联网的轻量级实时操作系统(RTOS)平台做开发,大概率会遇到一个经典需求:如何可靠、高效地存储数据。无论是记录传感器日志…...

ARMv8 PMU架构与性能监控实战指南
1. ARMv8 PMU架构深度解析在ARMv8架构中,性能监控单元(Performance Monitor Unit, PMU)是处理器微架构层面的重要组件,它为开发者提供了硬件级别的性能数据采集能力。不同于传统的软件性能分析工具,PMU通过专用寄存器直接监控处理器内部事件&…...

okbiye AI 写作新思路:毕业论文终稿一站式落地,不用熬夜硬熬
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 开篇引言 每到毕业季,毕业论文总会成为无数大学生最头疼的一道关卡。选题没方向、框架搭不起来、正文写不出深度、重复率居高不…...

【附C源码】循环队列的C语言实现
【附C源码】循环队列的C语言实现 队列作为基础数据结构之一,在操作系统调度、消息传递、广度优先搜索等场景中均有广泛应用。本文将探讨一种基于循环数组的队列实现方案,该方案在内存利用率和操作效率之间取得了较好的平衡。 设计思路 传统数组实现队列时…...