Python SQLAlchemy ( ORM )
From
- Python中强大的通用ORM框架:SQLAlchemy:https://zhuanlan.zhihu.com/p/444930067
- Python ORM之SQLAlchemy全面指南:https://zhuanlan.zhihu.com/p/387078089
SQLAlchemy 文档:https://www.sqlalchemy.org/
SQLAlchemy入门和进阶:https://zhuanlan.zhihu.com/p/27400862
1、ORM、SQLAlchemy 简介
ORM 技术:Object-Relational Mapping,把 "关系数据库的表结构" 映射到 "对象" 上。所以ORM框架应运而生。在Python中,最有名的ORM框架是 SQLAlchemy 。
SQLAlchemy 是 Python 中一款非常优秀的 ORM 框架,它可以与任意的第三方 web 框架相结合,如 flask、tornado、django、fastapi 等。
SQLALchemy 相较于 Django ORM 来说更贴近原生的 SQL 语句,因此学习难度较低。
SQLALchemy 由以下5个部分组成:
- Engine:框架引擎
- Connection Pooling:数据库链接池
- Dialect:方言,调用不同的数据库 API(Oracle, postgresql, Mysql) 并执行对应的 SQL语句。即 数据库DB API 种类。
- Schema / Types:" 类 到 表" 之间的映射规则
- SQL Exprression Language:SQL表达式语言
图示如下:
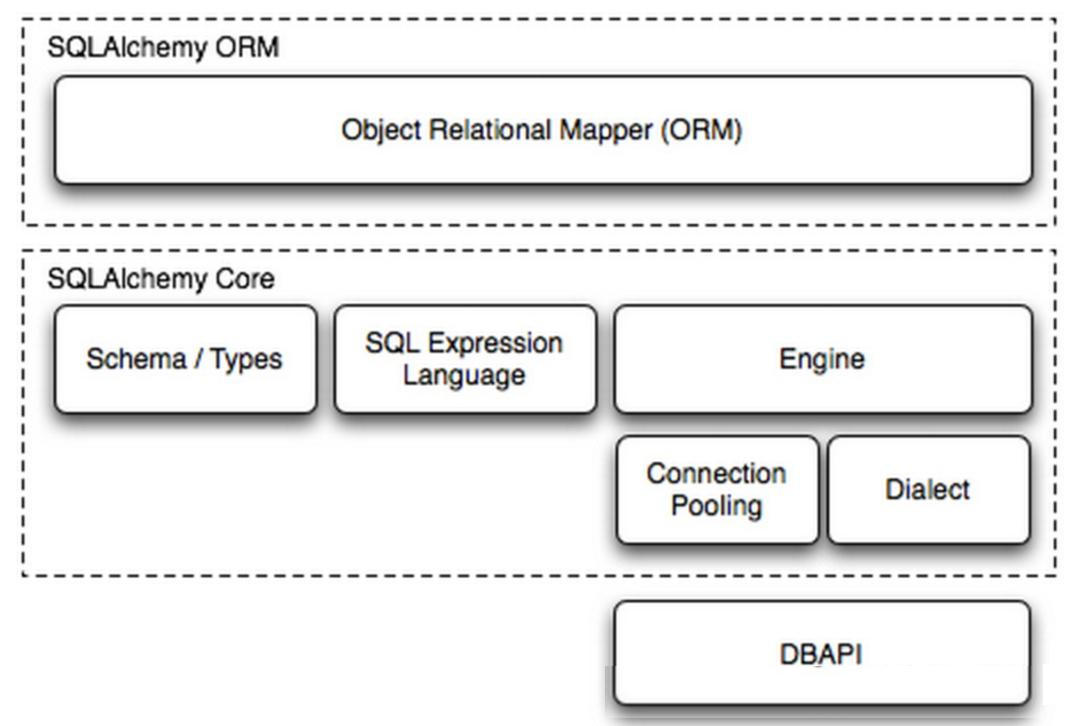
运行流程:
- 首先用户输入的操作会交由ORM对象
- 接下来ORM对象会将用户操作提交给SQLALchemy Core
- 其次该操作会由Schema/Types以及SQL Expression Language转换为SQL语句
- 然后Egine会匹配用户已经配置好的egine,并从链接池中去取出一个链接
- 最终该链接会通过Dialect调用DBAPI,将SQL语句转交给DBAPI去执行
安装 sqlalchemy
安装:pip install sqlalchemy
数据库 连接 字符串
SQLAlchemy 必须依赖其他操纵数据库的模块才能进行使用,也就是上面提到的 DBAPI。
SQLAlchemy 配合 DBAPI 使用时,链接字符串也有所不同,如下所示:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
连接 引擎
任何SQLAlchemy应用程序的开始都是一个Engine对象,此对象充当连接到特定数据库的中心源,提供被称为connection pool的对于这些数据库连接。
Engine对象通常是一个只为特定数据库服务器创建一次的全局对象,并使用一个URL字符串进行配置,该字符串将描述如何连接到数据库主机或后端。
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///:memory:', echo=True)
create_engine 的参数有很多,我列一些比较常用的:
- echo=False -- 如果为真,引擎将记录所有语句以及
repr()其参数列表的默认日志处理程序。 - enable_from_linting -- 默认为True。如果发现给定的SELECT语句与将导致笛卡尔积的元素取消链接,则将发出警告。
- encoding -- 默认为
utf-8 - future -- 使用2.0样式
- hide_parameters -- 布尔值,当设置为True时,SQL语句参数将不会显示在信息日志中,也不会格式化为 StatementError 对象。
- listeners -- 一个或多个列表
PoolListener将接收连接池事件的对象。 - logging_name -- 字符串标识符,默认为对象id的十六进制字符串。
- max_identifier_length -- 整数;重写方言确定的最大标识符长度。
- max_overflow=10 -- 允许在连接池中“溢出”的连接数,即可以在池大小设置(默认为5)之上或之外打开的连接数。
- pool_size=5 -- 在连接池中保持打开的连接数
- plugins -- 要加载的插件名称的字符串列表。
声明 映射
也就是在 Python 中创建的一个类,对应着数据库中的一张表,类的每个属性,就是这个表的字段名,这种 类对应于数据库中表的类,就称为映射类。
我们要创建一个映射类,是基于基类定义的,每个映射类都要继承这个基类 declarative_base()。
>>> from sqlalchemy.orm import declarative_base
>>> Base = declarative_base()
既然我们有了一个“基”类,就可以根据它定义任意数量的映射类。
我们将新建一张名为users的表,也就是用户表。一个名为User类将是我们映射此表的类。在类中,我们定义了要映射到的表的详细信息,主要是表名以及列的名称和数据类型:
from sqlalchemy import Column, Integer, Stringclass User(Base):__tablename__ = "users"id = Column(Integer, primary_key=True)name = Column(String)fullname = Column(String)nickname = Column(String)def __repr__(self):return "<User(name='%s', fullname='%s', nickname='%s')>" % (self.name,self.fullname,self.nickname,)
__tablename__ 代表表名
Column : 代表数据表中的一列,内部定义了数据类型
primary_key:主键
创建表到数据库
通过定义User类,我们已经定义了关于表的信息,称为table metadata,也就是表的元数据。我们可以通过检查__table__属性:
User.__table__
Table('users', MetaData(),
Column('id', Integer(), table=<users>, primary_key=True, nullable=False),
Column('name', String(), table=<users>),
Column('fullname', String(), table=<users>),
Column('nickname', String(), table=<users>), schema=None)
开始创建表:
>>> Base.metadata.create_all(engine)
BEGIN...
CREATE TABLE users (
id INTEGER NOT NULL,
name VARCHAR,
fullname VARCHAR,
nickname VARCHAR,
PRIMARY KEY (id)
)
[...] ()
COMMIT
创建映射类的实例
映射完成后,现在让我们创建一个User对象的实例:
>>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')
>>> ed_user.name
'ed'
>>> ed_user.nickname
'edsnickname'
>>> str(ed_user.id)
'None'
此时,实例对象只是在环境的内存中有效,并没有在表中真正生成数据。
创建会话
>>> from sqlalchemy.orm import sessionmaker
>>> Session = sessionmaker(bind=engine)
# 实例化
>>> session = Session()
我们对表的所有操作,都是通过会话实现的。
添加和更新对象
>>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')
>>> session.add(ed_user)
这里我们新增了一个用户,此时这个数据并没有被同步的数据库中,而是处于等待的状态。
只有执行了 commit() 方法后,才会真正在数据表中创建数据。
如果我们查询数据库,则首先刷新所有待处理信息,然后立即发出查询。
>>> our_user = session.query(User).filter_by(name='ed').first()
>>> our_user
<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>
此时得到的结果也并不是数据库表中的最终数据,而是映射类的一个对象。
回滚
在 commit() 之前,对实例对象的属性所做的更改,可以进行回滚,回到更改之前。
>>> session.rollback()
本质上只是把某一条数据(也就是映射类的实例)从内存中删除而已,并没有对数据库有任何操作。
查询
通过 query 关键字查询。
>>> for instance in session.query(User).order_by(User.id):
... print(instance.name, instance.fullname)
ed Ed Jones
wendy Wendy Williams
mary Mary Contrary
fred Fred Flintstone
- query.filter() 过滤
- query.filter_by() 根据关键字过滤
- query.all() 返回列表
- query.first() 返回第一个元素
- query.one() 有且只有一个元素时才正确返回
- query.one_or_none(),类似one,但如果没有找到结果,则不会引发错误
- query.scalar(),调用one方法,并在成功时返回行的第一列
- query.count() 计数
- query.order_by() 排序
query.join() 连接查询
>>> session.query(User).join(Address).\
... filter(Address.email_address=='jack@google.com').\
... all()
[<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>]
query(column.label()) 可以为字段名(列)设置别名:
>>> for row in session.query(User.name.label('name_label')).all():
... print(row.name_label)
ed
wendy
mary
fred
aliased()为查询对象设置别名:
>>> from sqlalchemy.orm import aliased
>>> user_alias = aliased(User, name='user_alias')SQL>>> for row in session.query(user_alias, user_alias.name).all():
... print(row.user_alias)
<User(name='ed', fullname='Ed Jones', nickname='eddie')>
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>
<User(name='mary', fullname='Mary Contrary', nickname='mary')>
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>
查询常用筛选器运算符
# 等于
query.filter(User.name == 'ed')# 不等于
query.filter(User.name != 'ed')# like和ilike
query.filter(User.name.like('%ed%'))
query.filter(User.name.ilike('%ed%')) # 不区分大小写# in
query.filter(User.name.in_(['ed', 'wendy', 'jack']))
query.filter(User.name.in_(
session.query(User.name).filter(User.name.like('%ed%'))
))
# not in
query.filter(~User.name.in_(['ed', 'wendy', 'jack']))# is
query.filter(User.name == None)
query.filter(User.name.is_(None))# is not
query.filter(User.name != None)
query.filter(User.name.is_not(None))# and
from sqlalchemy import and_
query.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones'))
query.filter(User.name == 'ed', User.fullname == 'Ed Jones')
query.filter(User.name == 'ed').filter(User.fullname == 'Ed Jones')# or
from sqlalchemy import or_
query.filter(or_(User.name == 'ed', User.name == 'wendy'))# match
query.filter(User.name.match('wendy'))
使用文本 SQL
文字字符串可以灵活地用于Query 查询。
>>> from sqlalchemy import text
SQL>>> for user in session.query(User).\
... filter(text("id<224")).\
... order_by(text("id")).all():
... print(user.name)
ed
wendy
mary
fred
使用冒号指定绑定参数。要指定值,请使用Query.params()方法:
>>> session.query(User).filter(text("id<:value and name=:name")).\
... params(value=224, name='fred').order_by(User.id).one()
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>
一对多
一个用户可以有多个邮件地址,意味着我们要新建一个表与用户表进行映射和查询。
>>> from sqlalchemy import ForeignKey
>>> from sqlalchemy.orm import relationship>>> class Address(Base):
... __tablename__ = 'addresses'
... id = Column(Integer, primary_key=True)
... email_address = Column(String, nullable=False)
... user_id = Column(Integer, ForeignKey('users.id'))
...
... user = relationship("User", back_populates="addresses")
...
... def __repr__(self):
... return "<Address(email_address='%s')>" % self.email_address>>> User.addresses = relationship(
... "Address", order_by=Address.id, back_populates="user")
ForeignKey定义两列之间依赖关系,表示关联了用户表的用户ID
relationship 告诉ORMAddress类本身应链接到User类,back_populates 表示引用的互补属性名,也就是本身的表名。
多对多
除了表的一对多,还存在多对多的关系,例如在一个博客网站中,有很多的博客BlogPost,每篇博客有很多的Keyword,每一个Keyword又能对应很多博客。
对于普通的多对多,我们需要创建一个未映射的Table构造以用作关联表。如下所示:
>>> from sqlalchemy import Table, Text
>>> # association table
>>> post_keywords = Table('post_keywords', Base.metadata,
... Column('post_id', ForeignKey('posts.id'), primary_key=True),
... Column('keyword_id', ForeignKey('keywords.id'), primary_key=True)
... )
下一步我们定义BlogPost和Keyword,使用互补 relationship 构造,每个引用post_keywords表作为关联表:
>>> class BlogPost(Base):
... __tablename__ = 'posts'
...
... id = Column(Integer, primary_key=True)
... user_id = Column(Integer, ForeignKey('users.id'))
... headline = Column(String(255), nullable=False)
... body = Column(Text)
...
... # many to many BlogPost<->Keyword
... keywords = relationship('Keyword',
... secondary=post_keywords,
... back_populates='posts')
...
... def __init__(self, headline, body, author):
... self.author = author
... self.headline = headline
... self.body = body
...
... def __repr__(self):
... return "BlogPost(%r, %r, %r)" % (self.headline, self.body, self.author)
>>> class Keyword(Base):
... __tablename__ = 'keywords'
...
... id = Column(Integer, primary_key=True)
... keyword = Column(String(50), nullable=False, unique=True)
... posts = relationship('BlogPost',
... secondary=post_keywords,
... back_populates='keywords')
...
... def __init__(self, keyword):
... self.keyword = keyword
多对多关系的定义特征是secondary关键字参数引用Table表示关联表的对象。
2、使用 SQLAlchemy 操作 表
创建单表
SQLAlchemy 不允许修改表结构,如果需要修改表结构则必须删除旧表,再创建新表,或者执行原生的 SQL 语句 ALERT TABLE 进行修改。
这意味着在使用非原生SQL语句修改表结构时,表中已有的所有记录将会丢失,所以我们最好一次性的设计好整个表结构避免后期修改:
# models.py
import datetime
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import scoped_sessionfrom sqlalchemy import (create_engine,Column,Integer,String,Enum,DECIMAL,DateTime,Boolean,UniqueConstraint,Index,
)
from sqlalchemy.ext.declarative import declarative_base# 基础类
Base = declarative_base()# 创建引擎
engine = create_engine("mysql+pymysql://tom:123@192.168.0.120:3306/db1?charset=utf8mb4",# "mysql+pymysql://tom@127.0.0.1:3306/db1?charset=utf8mb4", # 无密码时# 超过链接池大小外最多创建的链接max_overflow=0,# 链接池大小pool_size=5,# 链接池中没有可用链接则最多等待的秒数,超过该秒数后报错pool_timeout=10,# 多久之后对链接池中的链接进行一次回收pool_recycle=1,# 查看原生语句(未格式化)echo=True,
)# 绑定引擎
Session = sessionmaker(bind=engine)
# 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象conn
# 内部会采用threading.local进行隔离
session = scoped_session(Session)class UserInfo(Base):"""必须继承Base"""# 数据库中存储的表名__tablename__ = "userInfo"# 对于必须插入的字段,采用nullable=False进行约束,它相当于NOT NULLid = Column(Integer, primary_key=True, autoincrement=True, comment="主键")name = Column(String(32), index=True, nullable=False, comment="姓名")age = Column(Integer, nullable=False, comment="年龄")phone = Column(DECIMAL(6), nullable=False, unique=True, comment="手机号")address = Column(String(64), nullable=False, comment="地址")# 对于非必须插入的字段,不用采取nullable=False进行约束gender = Column(Enum("male", "female"), default="male", comment="性别")create_time = Column(DateTime, default=datetime.datetime.now, comment="创建时间")last_update_time = Column(DateTime, onupdate=datetime.datetime.now, comment="最后更新时间")delete_status = Column(Boolean(), default=False, comment="是否删除")__table__args__ = (UniqueConstraint("name", "age", "phone"), # 联合唯一约束Index("name", "addr", unique=True), # 联合唯一索引)def __str__(self):return f"object : <id:{self.id} name:{self.name}>"if __name__ == "__main__":# 删除表Base.metadata.drop_all(engine)# 创建表Base.metadata.create_all(engine)
记录操作
新增记录
新增单条记录:
# 获取链接池、ORM表对象
import models
user_instance = models.UserInfo(name="Jack",age=18,phone=330621,address="Beijing",gender="male"
)
models.session.add(user_instance)
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()批量新增
批量新增能减少TCP链接次数,提升插入性能:
# 获取链接池、ORM表对象
import models
user_instance1 = models.UserInfo(name="Tom",age=19,phone=330624,address="Shanghai",gender="male"
)
user_instance2 = models.UserInfo(name="Mary",age=20,phone=330623,address="Chongqing",gender="female"
)
models.session.add_all((user_instance1,user_instance2)
)
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()修改记录
修改某些记录:
# 获取链接池、ORM表对象
import models
# 修改的信息:
# - Jack -> Jack + son
# 在SQLAlchemy中,四则运算符号只能用于数值类型
# 如果是字符串类型需要在原本的基础值上做改变,必须设置
# - age -> age + 1
# synchronize_session=False
models.session.query(models.UserInfo)\.filter_by(name="Jack")\.update({"name": models.UserInfo.name + "son","age": models.UserInfo.age + 1},synchronize_session=False
)
# 本次修改具有字符串字段在原值基础上做更改的操作,所以必须添加
# synchronize_session=False
# 如果只修改年龄,则不用添加
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()删除记录
删除记录用的比较少,了解即可,一般都是像上面那样增加一个delete_status的字段,如果为1则代表删除:
# 获取链接池、ORM表对象
import models
models.session.query(models.UserInfo).filter_by(name="Mary").delete()
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()单表查询
基本查询
查所有记录、所有字段,all()方法将返回一个列表,内部包裹着每一行的记录对象:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo)\.all()
print(result)
# [<models.UserInfo object at 0x7f4d3d606fd0>, <models.UserInfo object at 0x7f4d3d606f70>]
for row in result:print(row)
# object : <id:1 name:Jackson>
# object : <id:2 name:Tom>
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()查所有记录、某些字段(注意,下面返回的元组实际上是一个命名元组,可以直接通过.操作符进行操作):
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo.id,models.UserInfo.name,models.UserInfo.age
).all()
print(result)
# [(1, 'Jackson', 19), (2, 'Tom', 19)]
for row in result:print(row)
# (1, 'Jackson', 19)
# (2, 'Tom', 19)
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()只拿第一条记录,first()方法将返回单条记录对象(注意,下面返回的元组实际上是一个命名元组,可以直接通过.操作符进行操作):
# 获取链接池、ORM表对象
import modelsresult = models.session.query(models.UserInfo.id,models.UserInfo.name,models.UserInfo.age
).first()print(result)
# (1, 'Jackson', 19)# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()AS别名
通过字段的label()方法,我们可以为它取一个别名:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo.name.label("s_name"),models.UserInfo.age.label("s_age")
).all()
for row in result:print(row.s_name)print(row.s_age)
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()条件查询
一个条件的过滤:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo,
).filter(models.UserInfo.name == "Jackson"
).all()
# 上面是Python语句形式的过滤条件,由filter方法调用
# 亦可以使用ORM的形式进行过滤,通过filter_by方法调用
# 如下所示
# .filter_by(name="Jackson").all()
# 个人更推荐使用filter过滤,它看起来更直观,更简单,可以支持 == != > < >= <=等常见符号
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()AND查询:
# 获取链接池、ORM表对象
import models
# 导入AND
from sqlalchemy import and_
result = models.session.query(models.UserInfo,
).filter(and_(models.UserInfo.name == "Jackson",models.UserInfo.gender == "male")
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()OR查询:
# 获取链接池、ORM表对象
import models
# 导入OR
from sqlalchemy import or_
result = models.session.query(models.UserInfo,
).filter(or_(models.UserInfo.name == "Jackson",models.UserInfo.gender == "male")
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()NOT查询:
# 获取链接池、ORM表对象
import models
# 导入NOT
from sqlalchemy import not_
result = models.session.query(models.UserInfo,
).filter(not_(models.UserInfo.name == "Jackson",)
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()范围查询
BETWEEN查询:
# 获取链接池、ORM表对象
import modelsresult = models.session.query(models.UserInfo,
).filter(models.UserInfo.age.between(15, 21)
).all()# 过滤成功的结果数量
print(len(result))
# 1# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()包含查询
IN查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo,
).filter(models.UserInfo.age.in_((18, 19, 20))
).all()
# 过滤成功的结果数量
print(len(result))
# 2
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7fdeeaa774f0>, <models.UserInfo object at 0x7fdeeaa77490>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()NOT IN,只需要加上~即可:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo,
).filter(~models.UserInfo.age.in_((18, 19, 20))
).all()
# 过滤成功的结果数量
print(len(result))
# 0
# 过滤成功的结果
print(result)
# []
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()模糊匹配
LIKE查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo,
).filter(models.UserInfo.name.like("Jack%")
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7fee1614f4f0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()分页查询
对结果all()返回的列表进行一次切片即可:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo,
).all()[0:1]
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7fee1614f4f0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()排序查询
ASC升序、DESC降序,需要指定排序规则:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo,
).filter(models.UserInfo.age > 12
).order_by(models.UserInfo.age.desc()
).all()
# 过滤成功的结果数量
print(len(result))
# 2
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f90eccd26d0>, <models.UserInfo object at 0x7f90eccd2670>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()聚合分组
聚合分组与having过滤:
# 获取链接池、ORM表对象
import models
# 导入聚合函数
from sqlalchemy import func
result = models.session.query(func.sum(models.UserInfo.age)
).group_by(models.UserInfo.gender
).having(func.sum(models.UserInfo.id > 1)
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [(Decimal('38'),)]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()多表查询
多表创建
五表关系:
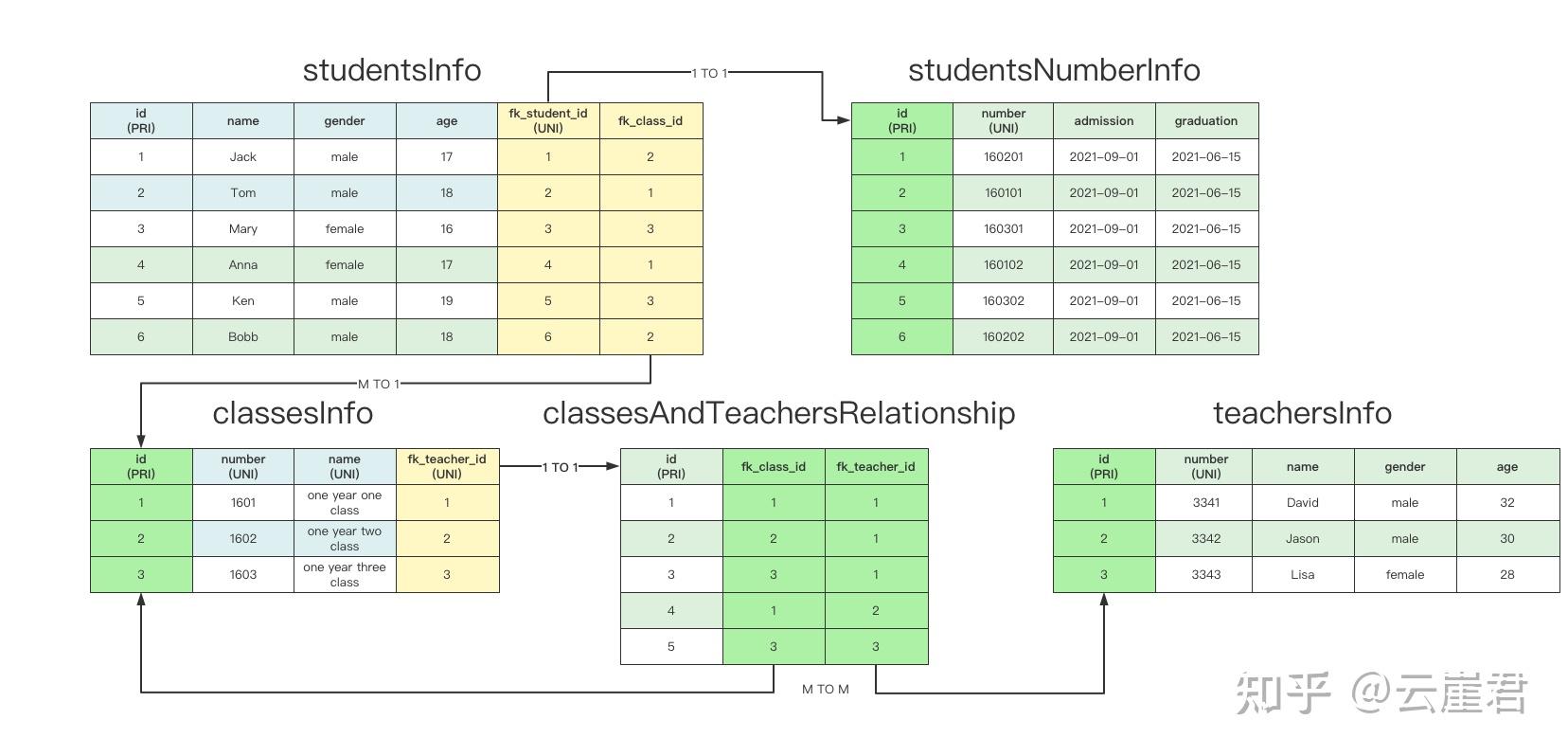
建表语句:
# models.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import relationship
from sqlalchemy import (create_engine,Column,Integer,Date,String,Enum,ForeignKey,UniqueConstraint,
)
from sqlalchemy.ext.declarative import declarative_base
# 基础类
Base = declarative_base()
# 创建引擎
engine = create_engine("mysql+pymysql://tom:123@192.168.0.120:3306/db1?charset=utf8mb4",# "mysql+pymysql://tom@127.0.0.1:3306/db1?charset=utf8mb4", # 无密码时# 超过链接池大小外最多创建的链接max_overflow=0,# 链接池大小pool_size=5,# 链接池中没有可用链接则最多等待的秒数,超过该秒数后报错pool_timeout=10,# 多久之后对链接池中的链接进行一次回收pool_recycle=1,# 查看原生语句# echo=True
)
# 绑定引擎
Session = sessionmaker(bind=engine)
# 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象
# 内部会采用threading.local进行隔离
session = scoped_session(Session)
class StudentsNumberInfo(Base):"""学号表"""__tablename__ = "studentsNumberInfo"id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")number = Column(Integer, nullable=False, unique=True, comment="学生编号")admission = Column(Date, nullable=False, comment="入学时间")graduation = Column(Date, nullable=False, comment="毕业时间")
class TeachersInfo(Base):"""教师表"""__tablename__ = "teachersInfo"id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")number = Column(Integer, nullable=False, unique=True, comment="教师编号")name = Column(String(64), nullable=False, comment="教师姓名")gender = Column(Enum("male", "female"), nullable=False, comment="教师性别")age = Column(Integer, nullable=False, comment="教师年龄")
class ClassesInfo(Base):"""班级表"""__tablename__ = "classesInfo"id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")number = Column(Integer, nullable=False, unique=True, comment="班级编号")name = Column(String(64), nullable=False, unique=True, comment="班级名称")# 一对一关系必须为连接表的连接字段创建UNIQUE的约束,这样才能是一对一,否则是一对多fk_teacher_id = Column(Integer,ForeignKey("teachersInfo.id",ondelete="CASCADE",onupdate="CASCADE",),nullable=False,unique=True,comment="班级负责人")# 下面这2个均属于逻辑字段,适用于正反向查询。在使用ORM的时候,我们不必每次都进行JOIN查询,而恰好正反向的查询使用频率会更高# 这种逻辑字段不会在物理层面上创建,它只适用于查询,本身不占据任何数据库的空间# sqlalchemy的正反向概念与Django有所不同,Django是外键字段在那边,那边就作为正# 而sqlalchemy是relationship字段在那边,那边就作为正# 比如班级表拥有 relationship 字段,而老师表不曾拥有# 那么用班级表的这个relationship字段查老师时,就称为正向查询# 反之,如果用老师来查班级,就称为反向查询# 另外对于这个逻辑字段而言,根据不同的表关系,创建的位置也不一样:# - 1 TO 1:建立在任意一方均可,查询频率高的一方最好# - 1 TO M:建立在M的一方# - M TO M:中间表中建立2个逻辑字段,这样任意一方都可以先反向,再正向拿到另一方# - 遵循一个原则,ForeignKey建立在那个表上,那个表上就建立relationship# - 有几个ForeignKey,就建立几个relationship# 总而言之,使用ORM与原生SQL最直观的区别就是正反向查询能带来更高的代码编写效率,也更加简单# 甚至我们可以不用外键约束,只创建这种逻辑字段,让表与表之间的耦合度更低,但是这样要避免脏数据的产生
# 班级负责人,这里是一对一关系,一个班级只有一个负责人leader_teacher = relationship(# 正向查询时所链接的表,当使用 classesInfo.leader_teacher 时,它将自动指向fk的那一条记录"TeachersInfo",# 反向查询时所链接的表,当使用 teachersInfo.leader_class 时,它将自动指向该老师所管理的班级backref="leader_class",)
class ClassesAndTeachersRelationship(Base):"""任教老师与班级的关系表"""__tablename__ = "classesAndTeachersRelationship"id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")# 中间表中注意不要设置单列的UNIQUE约束,否则就会变为一对一fk_teacher_id = Column(Integer,ForeignKey("teachersInfo.id",ondelete="CASCADE",onupdate="CASCADE",),nullable=False,comment="教师记录")
fk_class_id = Column(Integer,ForeignKey("classesInfo.id",ondelete="CASCADE",onupdate="CASCADE",),nullable=False,comment="班级记录")# 多对多关系的中间表必须使用联合唯一约束,防止出现重复数据__table_args__ = (UniqueConstraint("fk_teacher_id", "fk_class_id"),)
# 逻辑字段# 给班级用的,查看所有任教老师mid_to_teacher = relationship("TeachersInfo",backref="mid",)
# 给老师用的,查看所有任教班级mid_to_class = relationship("ClassesInfo",backref="mid")
class StudentsInfo(Base):"""学生信息表"""__tablename__ = "studentsInfo"id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")name = Column(String(64), nullable=False, comment="学生姓名")gender = Column(Enum("male", "female"), nullable=False, comment="学生性别")age = Column(Integer, nullable=False, comment="学生年龄")# 外键约束# 一对一关系必须为连接表的连接字段创建UNIQUE的约束,这样才能是一对一,否则是一对多fk_student_id = Column(Integer,ForeignKey("studentsNumberInfo.id",ondelete="CASCADE",onupdate="CASCADE"),nullable=False,comment="学生编号")# 相比于一对一,连接表的连接字段不用UNIQUE约束即为多对一关系fk_class_id = Column(Integer,ForeignKey("classesInfo.id",ondelete="CASCADE",onupdate="CASCADE"),comment="班级编号")# 逻辑字段# 所在班级, 这里是一对多关系,一个班级中可以有多名学生from_class = relationship("ClassesInfo",backref="have_student",)# 学生学号,这里是一对一关系,一个学生只能拥有一个学号number_info = relationship("StudentsNumberInfo",backref="student_info",)
if __name__ == "__main__":# 删除表Base.metadata.drop_all(engine)# 创建表Base.metadata.create_all(engine)插入数据:
# 获取链接池、ORM表对象
import models
import datetime
models.session.add_all((# 插入学号表数据models.StudentsNumberInfo(number=160201,admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))),models.StudentsNumberInfo(number=160101,admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))),models.StudentsNumberInfo(number=160301,admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))),models.StudentsNumberInfo(number=160102,admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))),models.StudentsNumberInfo(number=160302,admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))),models.StudentsNumberInfo(number=160202,admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))),# 插入教师表数据models.TeachersInfo(number=3341, name="David", gender="male", age=32,),models.TeachersInfo(number=3342, name="Jason", gender="male", age=30,),models.TeachersInfo(number=3343, name="Lisa", gender="female", age=28,),# 插入班级表数据models.ClassesInfo(number=1601, name="one year one class", fk_teacher_id=1),models.ClassesInfo(number=1602, name="one year two class", fk_teacher_id=2),models.ClassesInfo(number=1603, name="one year three class", fk_teacher_id=3),# 插入中间表数据models.ClassesAndTeachersRelationship(fk_class_id=1, fk_teacher_id=1),models.ClassesAndTeachersRelationship(fk_class_id=2, fk_teacher_id=1),models.ClassesAndTeachersRelationship(fk_class_id=3, fk_teacher_id=1),models.ClassesAndTeachersRelationship(fk_class_id=1, fk_teacher_id=2),models.ClassesAndTeachersRelationship(fk_class_id=3, fk_teacher_id=3),# 插入学生表数据models.StudentsInfo(name="Jack", gender="male", age=17, fk_student_id=1, fk_class_id=2),models.StudentsInfo(name="Tom", gender="male", age=18, fk_student_id=2, fk_class_id=1),models.StudentsInfo(name="Mary", gender="female", age=16, fk_student_id=3,fk_class_id=3),models.StudentsInfo(name="Anna", gender="female", age=17, fk_student_id=4,fk_class_id=1),models.StudentsInfo(name="Bobby", gender="male", age=18, fk_student_id=6, fk_class_id=2),)
)
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()JOIN查询
INNER JOIN:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.StudentsInfo.name,models.StudentsNumberInfo.number,models.ClassesInfo.number
).join(models.StudentsNumberInfo,models.StudentsInfo.fk_student_id == models.StudentsNumberInfo.id
).join(models.ClassesInfo,models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).all()
print(result)
# [('Jack', 160201, 1602), ('Tom', 160101, 1601), ('Mary', 160301, 1603), ('Anna', 160102, 1601), ('Bobby', 160202, 1602)]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()LEFT JOIN只需要在每个JOIN中指定isouter关键字参数为True即可:
session.query(左表.字段,右表.字段
)
.join(右表,链接条件,isouter=True
).all()RIGHT JOIN需要换表的位置,SQLALchemy本身并未提供RIGHT JOIN,所以使用时一定要注意驱动顺序,小表驱动大表(如果不注意顺序,MySQL优化器内部也会优化):
session.query(左表.字段,右表.字段
)
.join(左表,链接条件,isouter=True
).all()UNION&UNION ALL
将多个查询结果联合起来,必须使用filter(),后面不加all()方法。
因为all()会返回一个列表,而filter()返回的是一个<class 'sqlalchemy.orm.query.Query'>查询对象,此外,必须单拿某一个字段,不能不指定字段直接query():
# 获取链接池、ORM表对象
import models
students_name = models.session.query(models.StudentsInfo.name).filter()
students_number = models.session.query(models.StudentsNumberInfo.number)\.filter()
class_name = models.session.query(models.ClassesInfo.name).filter()
result = students_name.union_all(students_number).union_all(class_name)
print(result.all())
# [
# ('Jack',), ('Tom',), ('Mary',), ('Anna',), ('Bobby',),
# ('160101',), ('160102',), ('160201',), ('160202',), ('160301',), ('160302',),
# ('one year one class',), ('one year three class',), ('one year two class',)
# ]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()子查询
子查询使用subquery()实现,如下所示,查询每个班级中年龄最小的人:
# 获取链接池、ORM表对象
import models
from sqlalchemy import func
# 子查询中所有字段的访问都需要加上c的前缀
# 如 sub_query.c.id、 sub_query.c.name等
sub_query = models.session.query(# 使用label()来为字段AS一个别名# 后续访问需要通过sub_query.c.alias进行访问func.min(models.StudentsInfo.age).label("min_age"),models.ClassesInfo.id,models.ClassesInfo.name
).join(models.ClassesInfo,models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).group_by(models.ClassesInfo.id
).subquery()
result = models.session.query(models.StudentsInfo.name,sub_query.c.min_age,sub_query.c.name
).join(sub_query,sub_query.c.id == models.StudentsInfo.fk_class_id
).filter(sub_query.c.min_age == models.StudentsInfo.age
)
print(result.all())
# [('Jack', 17, 'one year two class'), ('Mary', 16, 'one year three class'), ('Anna', 17, 'one year one class')]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询
上面我们都是通过JOIN进行查询的,实际上我们也可以通过逻辑字段relationship进行查询。
下面是正向查询的示例,正向查询是指从有relationship逻辑字段的表开始查询:
# 查询所有学生的所在班级,我们可以通过学生的from_class字段拿到其所在班级
# 另外,对于学生来说,班级只能有一个,所以have_student应当是一个对象
# 获取链接池、ORM表对象
import models
students_lst = models.session.query(models.StudentsInfo
).all()
for row in students_lst:print(f"""student name : {row.name}from : {row.from_class.name}""")
# student name : Mary
# from : one year three class
# student name : Anna
# from : one year one class
# student name : Bobby
# from : one year two class
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()下面是反向查询的示例,反向查询是指从没有relationship逻辑字段的表开始查询:
# 查询所有班级中的所有学生,学生表中有relationship,并且它的backref为have_student,所以我们可以通过班级.have_student来获取所有学生记录
# 另外,对于班级来说,学生可以有多个,所以have_student应当是一个序列
# 获取链接池、ORM表对象
import models
classes_lst = models.session.query(models.ClassesInfo
).all()
for row in classes_lst:print("class name :", row.name)for student in row.have_student:print("student name :", student.name)
# class name : one year one class
# student name : Jack
# student name : Anna
# class name : one year two class
# student name : Tom
# class name : one year three class
# student name : Mary
# student name : Bobby
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()总结,正向查询的逻辑字段总是得到一个对象,反向查询的逻辑字段总是得到一个列表。
反向方法
使用逻辑字段relationship可以直接对一些跨表记录进行增删改查。
由于逻辑字段是一个类似于列表的存在(仅限于反向查询,正向查询总是得到一个对象),所以列表的绝大多数方法都能用。
<class 'sqlalchemy.orm.collections.InstrumentedList'>- append()- clear()- copy()- count()- extend()- index()- insert()- pop()- remove()- reverse()- sort()下面不再进行实机演示,因为我们上面的几张表中做了很多约束。
# 比如
# 给老师增加班级
result = session.query(Teachers).first()
# extend方法:
result.re_class.extend([Classes(name="三年级一班",),Classes(name="三年级二班",),
])
# 比如
# 减少老师所在的班级
result = session.query(Teachers).first()
# 待删除的班级对象,集合查找比较快
delete_class_set = {session.query(Classes).filter_by(id=7).first(),session.query(Classes).filter_by(id=8).first(),
}
# 循换老师所在的班级
# remove方法:
for class_obj in result.re_class:if class_obj in delete_class_set:result.re_class.remove(class_obj)
# 比如
# 清空老师所任教的所有班级
# 拿出一个老师
result = session.query(Teachers).first()
result.re_class.clear()查询案例
1)查看每个班级共有多少学生:
JOIN查询:
# 获取链接池、ORM表对象
import models
from sqlalchemy import func
result = models.session.query(models.ClassesInfo.name,func.count(models.StudentsInfo.id)
).join(models.StudentsInfo,models.ClassesInfo.id == models.StudentsInfo.fk_class_id
).group_by(models.ClassesInfo.id
).all()
print(result)
# [('one year one class', 2), ('one year two class', 2), ('one year three class', 1)]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
result = {}
class_lst = models.session.query(models.ClassesInfo
).all()
for row in class_lst:for student in row.have_student:count = result.setdefault(row.name, 0)result[row.name] = count + 1
print(result.items())
# dict_items([('one year one class', 2), ('one year two class', 2), ('one year three class', 1)])
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()2)查看每个学生的入学、毕业年份以及所在的班级名称:
JOIN查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.StudentsNumberInfo.number,models.StudentsInfo.name,models.ClassesInfo.name,models.StudentsNumberInfo.admission,models.StudentsNumberInfo.graduation
).join(models.StudentsInfo,models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).join(models.StudentsNumberInfo,models.StudentsNumberInfo.id == models.StudentsInfo.fk_student_id
).order_by(models.StudentsNumberInfo.number.asc()
).all()
print(result)
# [
# (160101, 'Tom', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160102, 'Anna', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160201, 'Jack', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160202, 'Bobby', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160301, 'Mary', 'one year three class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15))
# ]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
result = []
student_lst = models.session.query(models.StudentsInfo
).all()
for row in student_lst:result.append((row.number_info.number,row.name,row.from_class.name,row.number_info.admission,row.number_info.graduation))
print(result)
# [
# (160101, 'Tom', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160102, 'Anna', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160201, 'Jack', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160202, 'Bobby', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160301, 'Mary', 'one year three class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15))
# ]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()3)查看David所教授的学生中年龄最小的学生:
JOIN查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.TeachersInfo.name,models.StudentsInfo.name,models.StudentsInfo.age,models.ClassesInfo.name
).join(models.ClassesAndTeachersRelationship,models.ClassesAndTeachersRelationship.fk_class_id == models.ClassesInfo.id
).join(models.TeachersInfo,models.ClassesAndTeachersRelationship.fk_teacher_id == models.TeachersInfo.id
).join(models.StudentsInfo,models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).filter(models.TeachersInfo.name == "David"
).order_by(models.StudentsInfo.age.asc(),models.StudentsInfo.id.asc()
).limit(1).all()
print(result)
# [('David', 'Mary', 16, 'one year three class')]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
david = models.session.query(models.TeachersInfo
).filter(models.TeachersInfo.name == "David"
).first()
student_lst = []
# 反向查询拿到任教班级,反向是一个列表,所以直接for
for row in david.mid:cls = row.mid_to_class# 通过任教班级,反向拿到其下的所有学生cls_students = cls.have_student# 遍历学生for student in cls_students:student_lst.append((david.name,student.name,student.age,cls.name))
# 筛选出年龄最小的
min_age_student_lst = sorted(student_lst, key=lambda tpl: tpl[2])[0]
print(min_age_student_lst)
# ('David', 'Mary', 16, 'one year three class')
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()4)查看每个班级的负责人是谁,以及任课老师都有谁:
JOIN查询:
# 获取链接池、ORM表对象
import models
from sqlalchemy import func
# 先查任课老师
sub_query = models.session.query(models.ClassesAndTeachersRelationship.fk_class_id.label("class_id"),func.group_concat(models.TeachersInfo.name).label("have_teachers")
).join(models.ClassesInfo,models.ClassesAndTeachersRelationship.fk_class_id == models.ClassesInfo.id
).join(models.TeachersInfo,models.ClassesAndTeachersRelationship.fk_teacher_id == models.TeachersInfo.id
).group_by(models.ClassesAndTeachersRelationship.fk_class_id
).subquery()
result = models.session.query(models.ClassesInfo.name.label("class_name"),models.TeachersInfo.name.label("leader_teacher"),sub_query.c.have_teachers.label("have_teachers")
).join(models.TeachersInfo,models.ClassesInfo.fk_teacher_id == models.TeachersInfo.id
).join(sub_query,sub_query.c.class_id == models.ClassesInfo.id
).all()
print(result)
# [('one year one class', 'David', 'Jason,David'), ('one year two class', 'Jason', 'David'), ('one year three class', 'Lisa', 'David,Lisa')]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
result = []
# 获取所有班级
classes_lst = models.session.query(models.ClassesInfo
).all()
for cls in classes_lst:cls_message = [cls.name,cls.leader_teacher.name,[],]for row in cls.mid:cls_message[-1].append(row.mid_to_teacher.name)result.append(cls_message)
print(result)
# [['one year one class', 'David', ['David', 'Jason']], ['one year two class', 'Jason', ['David']], ['one year three class', 'Lisa', ['David', 'Lisa']]]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()原生SQL
查看执行命令
如果一条查询语句是filter()结尾,则该对象的__str__方法会返回格式化后的查询语句:
print(models.session.query(models.StudentsInfo).filter()
)
SELECT `studentsInfo`.id AS `studentsInfo_id`, `studentsInfo`.name AS `studentsInfo_name`, `studentsInfo`.gender AS `studentsInfo_gender`, `studentsInfo`.age AS `studentsInfo_age`, `studentsInfo`.fk_student_id AS `studentsInfo_fk_student_id`, `studentsInfo`.fk_class_id AS `studentsInfo_fk_class_id`
FROM `studentsInfo`执行原生命令
执行原生命令可使用session.execute()方法执行,它将返回一个cursor游标对象,如下所示:
# 获取链接池、ORM表对象
import models
cursor = models.session.execute("SELECT * FROM studentsInfo WHERE id = (:uid)", params={'uid': 1})
print(cursor.fetchall())
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close() # 获取链接池、ORM表对象相关文章:
Python SQLAlchemy ( ORM )
From Python中强大的通用ORM框架:SQLAlchemy:https://zhuanlan.zhihu.com/p/444930067Python ORM之SQLAlchemy全面指南:https://zhuanlan.zhihu.com/p/387078089 SQLAlchemy 文档:https://www.sqlalchemy.org/ SQLAlchemy入门和…...

鉴源实验室丨汽车网络安全运营
作者 | 苏少博 上海控安可信软件创新研究院汽车网络安全组 来源 | 鉴源实验室 社群 | 添加微信号“TICPShanghai”加入“上海控安51fusa安全社区” 01 概 述 1.1 背景 随着车辆技术的不断进步和智能化水平的提升,车辆行业正经历着快速的变革和技术进步。智能化…...

分布式链路追踪之SkyWalking详解和实战
SkyWalking 文章目录 SkyWalking1.SkyWalking概述2.SkyWalking架构设计3.SkyWalking部署4.应用程序接入SkyWalking5.SkyWalking配置应用告警5.1.告警规则5.2.Webhook(网络钩子)5.3.邮件告警实践 6.项目自动化部署接入SkyWalking6.1 整体思路6.2 启动参数…...

【工程实践】使用EDA(Easy Data Augmentation)做数据增强
工程项目中,由于数据量不够,经常需要用到数据增强技术,尝试使用EDA进行数据增强。 1.EDA简介 EDA是一种简单但是非常有效的文本数据增强方法,是由美国Protago实验室发表于 EMNLP-IJCNLP 2019 会议。EDA来自论文《EDA: Easy Data…...

ClickHouse(十三):Clickhouse MergeTree系列表引擎 - ReplicingMergeTree
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...

机器学习笔记之优化算法(十)梯度下降法铺垫:总体介绍
机器学习笔记之优化算法——梯度下降法铺垫:总体介绍 引言回顾:线搜索方法线搜索方法的方向 P k \mathcal P_k Pk线搜索方法的步长 α k \alpha_k αk 梯度下降方法整体介绍 引言 从本节开始,将介绍梯度下降法 ( Gradient Descent,GD ) …...

Selenium 根据元素文本内容定位
使用xpath定位元素时,有时候担心元素位置会变,可以考虑使用文本内容来定位的方式。 例如图中的【股市】按钮,只有按钮文本没变,即使位置变化也可以定位到该元素。 xpath内容样例: # 文本内容完全匹配 //button[text(…...

第17章-Spring AOP经典应用场景
文章目录 一、日志处理二、事务控制三、参数校验四、自定义注解五、AOP 方法失效问题1. ApplicationContext2. AopContext3. 注入自身 六、附录1. 示例代码 AOP 提供了一种面向切面操作的扩展机制,通常这些操作是与业务无关的,在实际应用中,可…...

Leetcode周赛 | 2023-8-6
2023-8-6 题1体会我的代码 题2我的超时代码题目体会我的代码 题3体会我的代码 题1 体会 这道题完全就是唬人,只要想明白了,只要有两个连续的数的和,大于target,那么一定可以,两边一次切一个就好了。 我的代码 题2 我…...

ts中interface自定义结构约束和对类的约束
一、interface自定义结构约束对后端接口返回数据 // interface自定义结构 一般用于较复杂的结构数据类型限制 如后端返回的接口数据// 首字母大写;用分割号隔开 interface Iobj{a:number;b:string } let obj:Iobj {a:1,b:2 }// 复杂类型 模拟后端返回的接口数据 interface Il…...

Oracle单实例升级补丁
目录 1.当前DB环境2.下载补丁包和opatch的升级包3.检查OPatch的版本4.检查补丁是否冲突5.关闭数据库实例,关闭监听6.应用patch7.加载变化的SQL到数据库8.ORACLE升级补丁查询 oracle19.3升级补丁到19.18 1.当前DB环境 [oraclelocalhost ~]$ cat /etc/redhat-releas…...

力扣初级算法(二分查找)
力扣初级算法(二分法): 每日一算法:二分法查找 学习内容: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 2.二分查找流程&…...

探索未来:直播实时美颜SDK在增强现实(AR)直播中的前景
在AR直播中,观众可以与虚拟元素实时互动,为用户带来更加丰富、沉浸式的体验。那么,直播美颜SDK在AR中有哪些应用呢?下文小编将于大家一同探讨美颜SDK与AR有哪些关联。 一、AR直播与直播实时美颜SDK的结合 增强现实技术在直播中…...

SQL 单行子查询 、多行子查询、单行函数、聚合函数 IN 、ANY 、SOME 、ALL
单行子查询 子查询结果是 一个列一行记录 select a,b,c from table where a >(select avg(xx) from table ) 还支持这种写法,这种比较少见 select a,b,c from table where (a ,b)(select xx,xxx from table where col‘000’ )…...
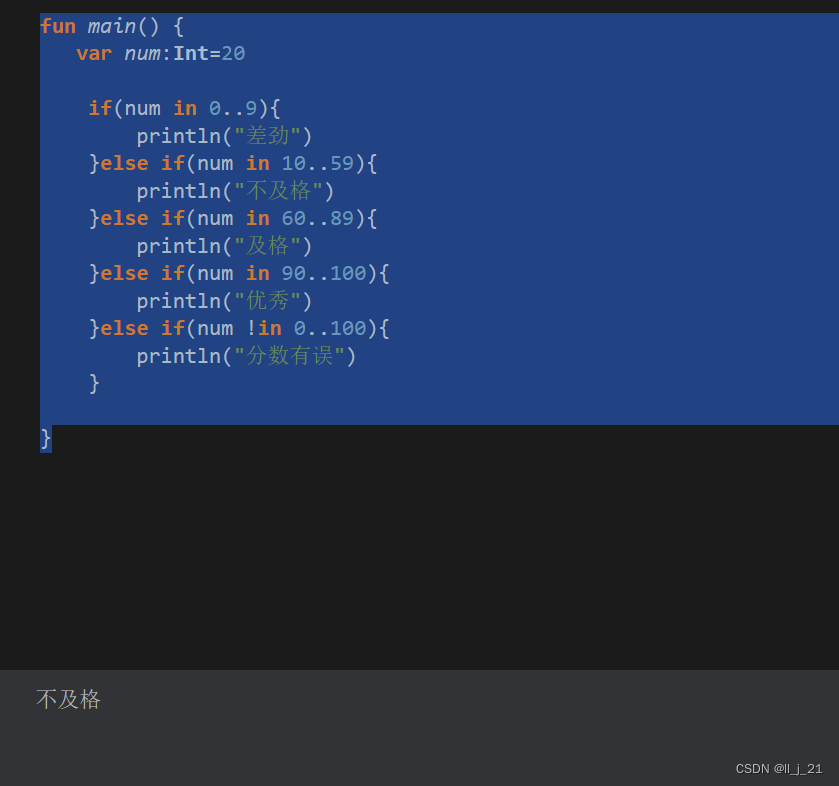
【第一阶段】kotlin的range表达式
range:范围:从哪里到哪里的意思 in:表示在 !in:表示不在 … :表示range表达式 代码示例: fun main() {var num:Int20if(num in 0..9){println("差劲")}else if(num in 10..59){println("不及格")}else if(num in 60..89…...
)
网络防御(5)
一、结合以下问题对当天内容进行总结 1. 什么是恶意软件? 2. 恶意软件有哪些特征? 3. 恶意软件的可分为那几类? 4. 恶意软件的免杀技术有哪些? 5. 反病毒技术有哪些? 6. 反病毒网关的工作原理是什么? 7. 反…...

gradle 命令行单元测试执行问题
文章目录 问题:命令行 执行失败最终解决方案(1)ADB命令(2)Java 环境配置 问题:命令行 执行失败 命令行 执行测试命令 无法使用(之前还能用的。没有任何改动,又不能用了) …...

剑指Offer12.矩阵中的路径 C++
1、题目描述 给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平…...

金鸣识别将无表格线的图片转为excel的几个常用方案
我们知道,金鸣识别要将横竖线齐全的表格图片转为excel非常简单,但要是表格线不齐全甚至没有表格线的图片呢?这就没那么容易了,在识别这类图片时,我们一般会使用以下的一种或多种方法进行处理: 1. 基于布局…...

刚刚更新win11,记事本消失怎么处理?你需要注意些什么?
记录window11的bug hello,我是小索奇 昨天索奇从window10更新到了window11,由于版本不兼容卸载了虚拟机,这是第一个令脑壳大的,算了,还是更新吧,了解了解win11的生态,后期重新装虚拟机 第一个可…...
)
香橙派Zero3无屏幕配网新玩法:用ESP32-C3蓝牙模块搞定WiFi连接(附完整代码)
香橙派Zero3无屏幕配网新玩法:用ESP32-C3蓝牙模块搞定WiFi连接(附完整代码) 在物联网和边缘计算项目中,无头设备(Headless Device)的网络配置一直是个棘手问题。想象一下:你刚拿到一块香橙派Zer…...
)
ROS Noetic下,5分钟搞定Hector SLAM建图(附避坑指南与完整launch文件)
ROS Noetic下Hector SLAM极速建图实战:从零到地图生成的避坑全指南 刚接触ROS和SLAM的开发者往往被复杂的配置和概念淹没,而Hector SLAM作为最轻量级的激光建图方案,却能在5分钟内让你看到实实在在的建图效果。本文将采用逆向教学法——先带你…...

Unity项目性能优化实战:除了Simplygon,还有哪些轻量级减面工具和技巧?
Unity项目性能优化实战:轻量级减面工具与技巧全解析 在Unity项目开发中,3D模型的性能优化是一个永恒的话题。当项目规模扩大、场景复杂度提升时,模型面数往往会成为性能瓶颈的首要因素。Simplygon作为业界知名的减面工具,虽然功能…...

编译和链接+预处理
编译(compile)和链接(link)在以前我们提到过,C语言是一门编译型的计算机语言,C语言的源代码都是文本文件,文本文件本身无法运行,电脑不能执行C语言代码,计算机能够执行的…...

嵌入式工程师核心素养:从测试到系统构建的全链路能力模型
1. 从“明星评选”看嵌入式工程师的成长路径与价值塑造最近看到一篇关于某公司内部“品质与服务创建活动”的报道,评选了四位明星工程师。这让我感触颇深。在嵌入式这个行当里摸爬滚打了十几年,我见过太多技术扎实但默默无闻的同行,也见过一些…...

什么是虚拟化
什么是虚拟化? 什么是虚拟化 虚拟化长期以来一直是一项基础 IT 技术,使企业能够在一台物理机器上运行多个独立的系统。 虚拟化是一种允许从单个物理机创建多个虚拟环境的技术。这些虚拟环境基本上是以前与硬件绑定的功能的逻辑(虚拟ÿ…...

小学期第一周
理论部分:学会了低通滤波器原理:只允许低于截止频率的信号通过,高于截止频率的信号被大幅衰减方波变成正弦波的原理:方波是基波无数奇次谐波的叠加,低通滤波器只留基波、滤掉高频谐波,输出就接近正弦波二阶…...

实体门店低获客成本增长案例:3 人转介绍模型 + 消费返还机制落地分析
一、案例背景该门店为 60㎡社区夫妻店,位于成熟居住商圈,周边覆盖 3 个社区共 3000 余户居民。此前门店采用传统公域投放 线下发单的获客模式,获客成本偏高,用户留存与老客转介绍率存在较大提升空间。二、核心运营方案设计本次方…...

pubnub代码示例
import time from pubnub.pnconfiguration import PNConfiguration from pubnub.pubnub import PubNub, SubscribeListener from pubnub.exceptions import PubNubExceptionpublish_key=pub-c-fab-b05a-c355bb3adac5 subscribe_key=sub...

CellSpectra的创新视角:从差异表达到协调性分析
单细胞RNA测序(scRNA-seq)让我们得以在单细胞分辨率下解析基因表达模式。然而,差异表达分析仅能识别单体基因变化,难以刻画基因间的协同调控;通路富集分析无法实现个体水平的统计推断;高稀疏性则进一步制约…...