机器学习实战1-kNN最近邻算法
文章目录
- 机器学习基础
- 机器学习的关键术语
- k-近邻算法(KNN)
- 准备:使用python导入数据
- 实施kNN分类算法
- 示例:使用kNN改进约会网站的配对效果
- 准备数据:从文本文件中解析数据
- 分析数据
- 准备数据:归一化数值
- 测试算法:作为完整程序验证分类器
- 手写识别系统
机器学习基础
机器学习的关键术语
1、属性:将一种事务分类的特征值称为属性,例如我们在做鸟类分类时,我们可以将体重、翼展、脚蹼、后背颜色作为特征,特征通常时训练样本的列,它们是独立测量得到的结果,多个特征联系在一起共同组成一个训练样本
2、目标变量:就是我们要分类的那个结果
3、训练集和测试集:训练集作为算法的输入,用于训练模型,测试集用于检验训练的效果
k-近邻算法(KNN)
主要思想:我们先将已知标签的数据以及对应的标签输入,当输入未知标签的数据时,我们希望根据输入的特征值来判断该数据的特征值,我们先计算该数据与我们已知标签的数据的距离,并将距离排序,取前k个数据,根据前k个数据中出现次数最多的数据的标签作为新数据标签的分类
kNN算法主要是用于分类的一种算法

准备:使用python导入数据
from numpy import *
# kNN排序时将使用这个模块提供好的函数
import operatordef createDataSet():group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])labels = ['A', 'A', 'B', 'B']return group, labels
实施kNN分类算法

def classify0(inX, dataSet, labels, k):dataSetSize = dataSet.shape[0]diffMat = tile(inX, (dataSetSize, 1) - dataSet)sqDiffMat = diffMat ** 2sqDistances = sqDiffMat.sum(axis = 1)distances = sqDistances ** 0.5sortedDistIndicies = distances.argsort()classCount = {}for i in range(k):voteIlabel = labels[sortedDistIndicies[i]]classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1), reverse= True)return sortedClassCount[0][0]
这里先说一下shape函数,只做简单说明,shape函数用于确定array的维度比如
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
print(group.shape)
这里输出的结果是(4,2)
也就是说返回的是矩阵或者数组每一维的长度,返回的结果是一个元组(tuple),元组和例表的区别不能忘记,元组不可修改,列表可以修改
tile()函数,tile是numpy模块中的一个函数,用于矩阵的复制,tile(A, reps), A表示我们要操作的矩阵,reps是我们复制的参数,可以是一个数也可以是一个矩阵(4, 2),tile(A, (4, 2))表示将A矩阵的列复制4次,行复制两次
argsort()方法,对数组进行排序,这里返回的是排序后的下标这和C++中的sort()方法不同
argsort()实现倒序排序
group = array([2, 3, 5, 4])
x = argsort(-group)
print(x)
字典中的get()方法
python中对于非数值型数据进行排序,例如字典
sorted(iterable, cmp=None, key=None, reverse=False)
iterable是一个迭代器,
cmp是比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1), reverse= True)
python中的items()返回的是一个列表,iteritems()返回一个迭代器, itemgetter()方法可用于指定关键字排序,operator.itemgetter(1)是按字典中的值进行排序,reverse= True按降序排序,python3已经不支持iteritems(),这里用items()即可。
字典中的get()方法
dict_name.get(key, default = None)
key是我们要查找字典中的key,如果存在则返回对应的值,如果不存在就返回第二个我们设置的参数,当我们没设置时,默认返回None
示例:使用kNN改进约会网站的配对效果

准备数据:从文本文件中解析数据
from numpy import *def file2matrix(filename):fr = open(filename)arrarOLines = fr.readlines()numberOfLines = len(arrarOLines)returnMat = zeros((numberOfLines, 3))classLabelVector = []index = 0for line in arrarOLines:line = line.strip()listFromLine = line.split('\t')# 将数据的前三行直接存入特征矩阵returnMat[index,:] = listFromLine[0:3]# 将字符串映射成数字if listFromLine[-1] == 'didntLike':classLabelVector.append(1)elif listFromLine[-1] == 'smallDoses':classLabelVector.append(2)elif listFromLine[-1] == 'largeDoses':classLabelVector.append(3)index += 1return returnMat, classLabelVector
分析数据
from numpy import *
# kNN排序时将使用这个模块提供好的函数
import operator
import matplotlib
import matplotlib.pyplot as pltdef createDataSet():group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])labels = ['A', 'A', 'B', 'B']return group, labelsdef classify0(inX, dataSet, labels, k):dataSetSize = dataSet.shape[0]diffMat = tile(inX, (dataSetSize, 1)) - dataSetsqDiffMat = diffMat ** 2sqDistances = sqDiffMat.sum(axis = 1)distances = sqDistances ** 0.5sortedDistIndicies = distances.argsort()classCount = {}for i in range(k):voteIlabel = labels[sortedDistIndicies[i]]classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1), reverse= True)return sortedClassCount[0][0]# [group, labels] = createDataSet()
# m = classify0([0, 0], group, labels, 2)
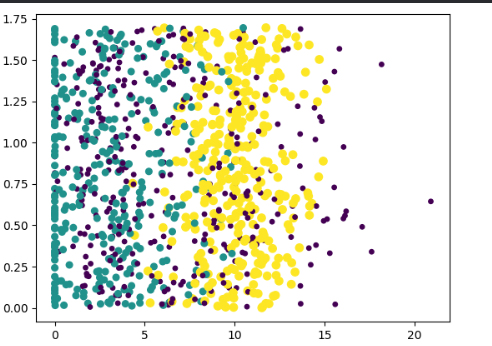
# print(m)def file2matrix(filename):fr = open(filename)arrarOLines = fr.readlines()numberOfLines = len(arrarOLines)returnMat = zeros((numberOfLines, 3))classLabelVector = []index = 0for line in arrarOLines:line = line.strip()listFromLine = line.split('\t')# 将数据的前三行直接存入特征矩阵returnMat[index,:] = listFromLine[0:3]# 将字符串映射成数字if listFromLine[-1] == 'didntLike':classLabelVector.append(1)elif listFromLine[-1] == 'smallDoses':classLabelVector.append(2)elif listFromLine[-1] == 'largeDoses':classLabelVector.append(3)index += 1return returnMat, classLabelVectordatingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0*array(datingLabels), 15.0*array(datingLabels))
plt.show()
结果截图:
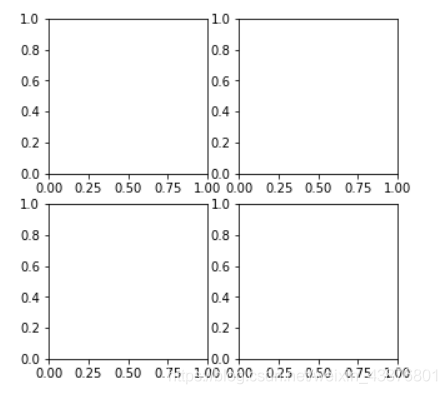
add_subplot(x)中参数的含义:
这里前两个表示几*几的网格,最后一个表示第几子图
可能说的有点绕口,下面上程序作图一看说明就明白
import matplotlib.pyplot as plt
fig = plt.figure(figsize = (5,5))
ax = fig.add_subplot(221)
ax = fig.add_subplot(222)
ax = fig.add_subplot(223)
ax = fig.add_subplot(224)
scatter()方法
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)
x,y:长度相同的数组,也就是我们即将绘制散点图的数据点,输入数据。
s:点的大小,默认 20,也可以是个数组,数组每个参数为对应点的大小。
c:点的颜色,默认蓝色 ‘b’,也可以是个 RGB 或 RGBA 二维行数组。
marker:点的样式,默认小圆圈 ‘o’。
cmap:Colormap,默认 None,标量或者是一个 colormap 的名字,只有 c 是一个浮点数数组的时才使用。如果没有申明就是 image.cmap。
norm:Normalize,默认 None,数据亮度在 0-1 之间,只有 c 是一个浮点数的数组的时才使用。
vmin,vmax::亮度设置,在 norm 参数存在时会忽略。
alpha::透明度设置,0-1 之间,默认 None,即不透明。
linewidths::标记点的长度。
edgecolors::颜色或颜色序列,默认为 ‘face’,可选值有 ‘face’, ‘none’, None。
plotnonfinite::布尔值,设置是否使用非限定的 c ( inf, -inf 或 nan) 绘制点。
**kwargs::其他参数。
我们主要用到的是前四个参数,第一个参数是我们要画散点图的横坐标,第二个是纵坐标,第三个散点图中点的颜色,第四个散点图中点的大小
准备数据:归一化数值
def autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormDataSet = zeros(shape(dataSet))m = dataSet.shape[0]normDataSet = dataSet - tile(minVals, (m, 1))normDataSet = normDataSet / tile(ranges, (m, 1))return normDataSet, ranges, minValsnormMat, ranges, minVals = autoNorm(datingDataMat)
print(normMat)
min()、max()方法
minVals = dataSet.min(0) 返回dataSet中每一列中的最小值数组
minVals = dataSet.min(1) 返回dataSet中每一行中的最小值数组
测试算法:作为完整程序验证分类器
def datingClassTest():hoRatio = 0.10datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')normMat, ranges, minVals = autoNorm(datingDataMat)m = normMat.shape[0]numTestVecs = int(m*hoRatio)errorCount = 0.0for i in range(numTestVecs):classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)print(f"the classifier came back with: {classifierResult}, the real answer is : {datingLabels[i]}")if classifierResult != datingLabels[i]:errorCount += 1.0print(f"the total error rate is : {errorCount / float(numTestVecs)}")datingClassTest();
手写识别系统
from numpy import *
# kNN排序时将使用这个模块提供好的函数
import operator
import matplotlib
import matplotlib.pyplot as pltdef createDataSet():group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])labels = ['A', 'A', 'B', 'B']return group, labelsdef classify0(inX, dataSet, labels, k):dataSetSize = dataSet.shape[0]diffMat = tile(inX, (dataSetSize, 1)) - dataSetsqDiffMat = diffMat ** 2sqDistances = sqDiffMat.sum(axis = 1)distances = sqDistances ** 0.5sortedDistIndicies = distances.argsort()classCount = {}for i in range(k):voteIlabel = labels[sortedDistIndicies[i]]classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1), reverse= True)return sortedClassCount[0][0]# [group, labels] = createDataSet()
# m = classify0([0, 0], group, labels, 2)
# print(m)def file2matrix(filename):fr = open(filename)arrarOLines = fr.readlines()numberOfLines = len(arrarOLines)returnMat = zeros((numberOfLines, 3))classLabelVector = []index = 0for line in arrarOLines:line = line.strip()listFromLine = line.split('\t')# 将数据的前三行直接存入特征矩阵returnMat[index,:] = listFromLine[0:3]# 将字符串映射成数字if listFromLine[-1] == 'didntLike':classLabelVector.append(1)elif listFromLine[-1] == 'smallDoses':classLabelVector.append(2)elif listFromLine[-1] == 'largeDoses':classLabelVector.append(3)index += 1return returnMat, classLabelVector# datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')
# print(datingDataMat)
# fig = plt.figure()
# ax = fig.add_subplot(111)
# ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2], 15.0*array(datingLabels), 15.0*array(datingLabels))
# plt.show()def autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormDataSet = zeros(shape(dataSet))m = dataSet.shape[0]normDataSet = dataSet - tile(minVals, (m, 1))normDataSet = normDataSet / tile(ranges, (m, 1))return normDataSet, ranges, minVals# normMat, ranges, minVals = autoNorm(datingDataMat)
# print(normMat)# def datingClassTest():
# hoRatio = 0.10
# datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')
# normMat, ranges, minVals = autoNorm(datingDataMat)
# m = normMat.shape[0]
# numTestVecs = int(m*hoRatio)
# errorCount = 0.0
# for i in range(numTestVecs):
# classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
# print(f"the classifier came back with: {classifierResult}, the real answer is : {datingLabels[i]}")
# if classifierResult != datingLabels[i]:
# errorCount += 1.0
# print(f"the total error rate is : {errorCount / float(numTestVecs)}")
#
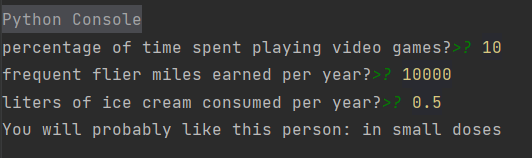
# datingClassTest();def classifyPerson():resultList = ['not at all', 'in small doses', 'in large doses']percentTats = float(input("percentage of time spent playing video games?"))ffMiles = float(input("frequent flier miles earned per year?"))iceCream = float(input("liters of ice cream consumed per year?"))datingDataMat, datingLabels = file2matrix('C:/Users/cxy/OneDrive/桌面/datingTestSet.txt')normMat, ranges, minVals = autoNorm(datingDataMat)inArr = array([ffMiles, percentTats, iceCream])classifierResult = classify0((inArr - minVals) / ranges, normMat, datingLabels, 3)print(f"You will probably like this person: {resultList[classifierResult - 1]}")classifyPerson()
相关文章:
机器学习实战1-kNN最近邻算法
文章目录 机器学习基础机器学习的关键术语 k-近邻算法(KNN)准备:使用python导入数据实施kNN分类算法示例:使用kNN改进约会网站的配对效果准备数据:从文本文件中解析数据分析数据准备数据:归一化数值测试算法…...
【eNSP】静态路由
【eNSP】静态路由 原理网关路由表 实验根据图片连接模块配置路由器设备R1R2R3R4 配置PC的IP地址、掩码、网关PC1PC2PC3 配置静态路由查看路由表R1R2R3R4测试能否通信 原理 网关 网关与路由器地址相同,一般路由地址为.1或.254。 网关是当电脑发送的数据的目标IP不在…...

算法训练Day42|1049. 最后一块石头的重量 II ● 494. 目标和 ● 474.一和零
背包类别 01背包:有n种物品,每种物品只有一个. 完全背包:有n种物品,每种物品有无限个. 多重背包:有n种物品,每种物品个数各不相同. 区别:仅仅体现在物品个数上的不同而已。 确定dp[i][j]数组的…...

HBase-组成
client 读写请求HMaster 管理元数据监控region是否需要进行负载均衡,故障转移和region的拆分RegionServer 负责数据cell的处理,例如写入数据put,查询数据get等 拆分合并Region的实际执行者,由Master监控,由regionServ…...

第一部分:领域中的基本概念
目录 一、什么是模型 二、什么是领域 三、什么是领域模型 四、什么是领域建模 一、什么是模型 模型是一种简化、它是对现实的解释,它与解决问题密切相关的方面抽象出来,而忽略无关细节。 二、什么是领域 领域是指某一专业或事物方面范围的涵盖。比如…...

react使用ref调用子组件的方法
Class类组件 import React, { useRef } from react;const MyComponent () > {const myComponentRef useRef(null);const handleClick () > {// 调用MyComponent组件的方法myComponentRef.current.myMethod();};return (<div><MyComponent ref{myComponentRe…...
JVM面试突击班2
JVM面试突击班2 对象被判定为不可达对象之后就“死”了吗 对象的生命周期 创建阶段 (1)为对象分配存储空间 (2)开始构造对象 (3)从超类到子类对static成员进行初始化 (4)超类成…...

【80天学习完《深入理解计算机系统》】第二天 2.2 整数的表示【有符号数,无符号数,符号数的扩展,有无符号数的转变】
专注 效率 记忆 预习 笔记 复习 做题 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录) 文章字体风格: 红色文字表示&#…...

基于 CentOS 7 构建 LVS-DR 群集以及配置nginx负载均衡
目录 一、基于 CentOS 7 构建 LVS-DR 群集 1、前期准备 1、关闭防火墙 2、安装ifconfig 3、准备四台虚拟机 2、在DS上 2.1、配置LVS虚拟IP 2.2、手工执行配置添加LVS服务并增加两台RS 2.3、查看配置 3、在RS端(第三台、第四台) 上 3.1、配置W…...
golang trace view 视图详解
大家好,我是蓝胖子,在golang中可以使用go pprof的工具对golang程序进行性能分析,其中通过go trace 命令生成的trace view视图对于我们分析系统延迟十分有帮助,鉴于当前对trace view视图的介绍还是很少,在粗略的看过tra…...

zju代码题:4-6
一 分段函数算水费 #include <stdio.h>int main() {/*** 定义两个* 定义浮点型变量* y:水费* x:用水的吨数* */double x, y;printf("Enter x(x>=0):\n"...

数据链路层概述
数据传输过程如下: 数据包按上述过程传输,详见(计算机网络概述三)。在分析数据链路层时可以假象成其沿着水平传播。 这三段链路层的传播方式可能会有所不同。 基本概念: 链路:指一个节点到相邻节点的一段物…...

Python代码使用技巧汇总:提升你的编程技能
各位程序员朋友们,今天我要跟大家分享一些关于Python代码的最佳使用技巧,这些技巧可以帮助你们成为更专业且高效的程序员。不管你是刚刚入门还是已经有一些经验,这些技巧都能够为你提供实际操作价值。 一、合理使用Python的数据结构和算法&am…...

Ae 效果:CC Spotlight
透视/CC Spotlight Perspective/CC Spotlight CC Spotlight(CC 聚光灯) 主要用途是创建和控制逼真的聚光灯效果。通过调整这些属性,可以模拟出各种不同的照明环境和效果,比如舞台照明、日出日落、特定的颜色照明等。 ◆ ◆ ◆ 效…...

如何在页面中嵌入音频和视频?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 嵌入音频⭐ 嵌入视频⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴趣、刚刚踏…...
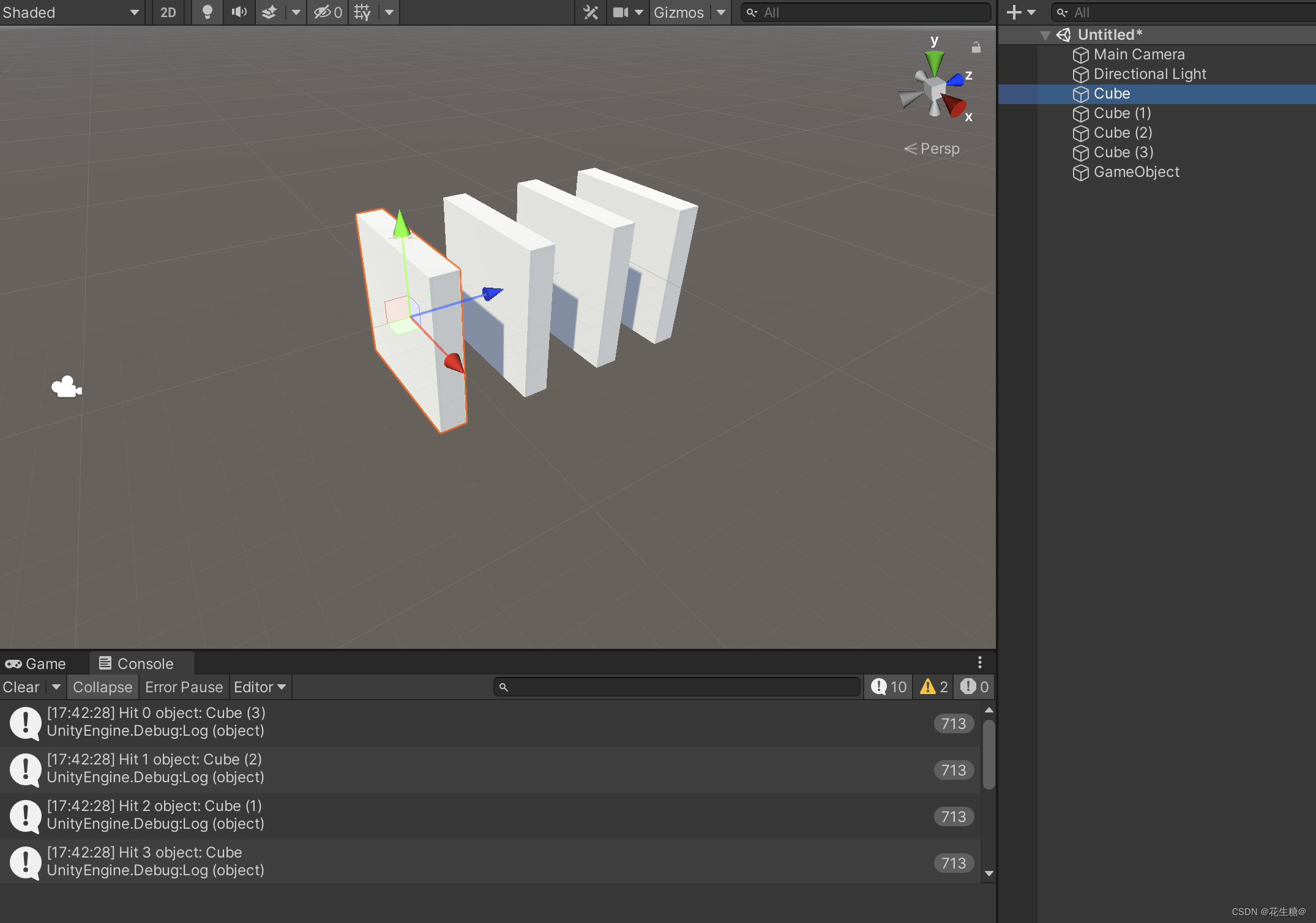
Unity 中检测射线穿过的所有的物体
在开发中 有个需求,射线要检测所有穿过的物体。 代码如下: using UnityEngine;public class HitCollider : MonoBehaviour {public float raycastDistance Mathf.Infinity;// Update is called once per framevoid Update(){Ray ray Camera.main.Scre…...
LeetCode 29题:两数相除
题目 给你两个整数,被除数 dividend 和除数 divisor。将两数相除,要求 不使用 乘法、除法和取余运算。 整数除法应该向零截断,也就是截去(truncate)其小数部分。例如,8.345 将被截断为 8 ,-2.…...
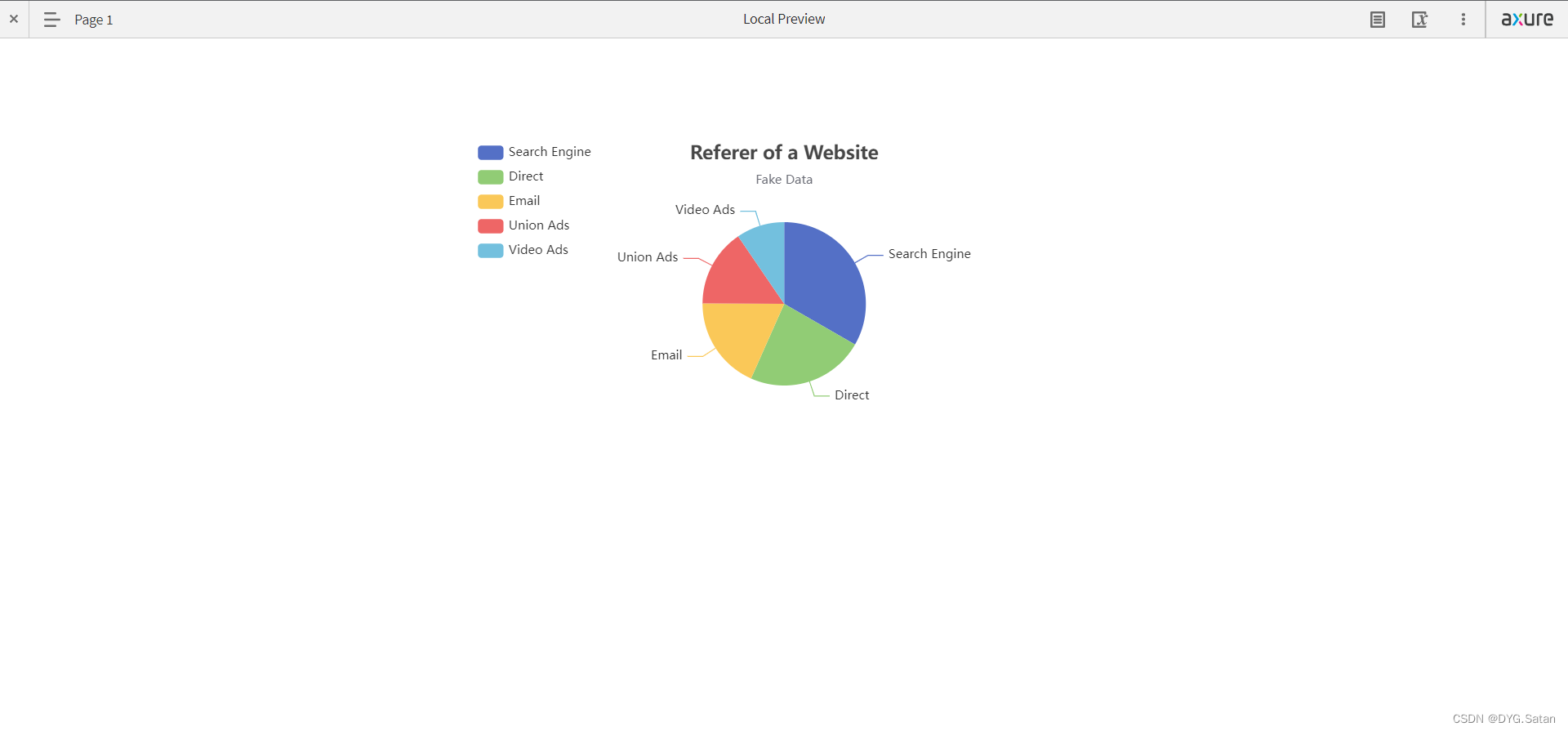
Axure RP9中使用Echarts示例
目录 在Axure中拖入一个矩形框,并命名tes 进入Echarts官网示例页面https://echarts.apache.org/examples/zh/index.html 选择自己需要的图表,修改数据,并复制左侧js代码 把上面复制的代码替换下方的option{}; javascript: var script docum…...
利用Jmeter做接口测试全流程分析
利用Jmeter做接口测试怎么做呢?过程真的是超级简单。 明白了原理以后,把零碎的知识点填充进去就可以了。这篇文章就来介绍一下如何利用Jmeter做接口测试的流程,主要针对的是功能测试。暂不涉及到自动化测试和性能测试的内容。 一把来说&…...

超级浏览器与指纹浏览器:功能与特点的比较
导语:随着互联网的快速发展,隐私和安全问题日益受到关注。在这个背景下,超级浏览器和指纹浏览器作为定制化浏览器的两个重要类型,各自具有独特的功能和特点。本文将对超级浏览器和指纹浏览器进行比较,帮助读者更好地理…...

巴洛克光影建模失败率高达83%?用这7个构图锚点+12组权威艺术史关键词立即逆转
更多请点击: https://kaifayun.com 第一章:巴洛克光影建模的危机本质与历史断层 “巴洛克光影建模”并非真实存在的技术流派,而是对20世纪末至21世纪初三维渲染实践中一种高度装饰化、过度依赖手工打光与物理不一致材质叠加现象的隐喻性指称…...

三氧化二铝与氢氧化钠反应的产物到底是四羟基合铝酸钠还是偏铝酸钠?
三氧化二铝与氢氧化钠反应的产物 三氧化二铝(Al₂O₃)与氢氧化钠(NaOH)反应,在水溶液或水存在下,实际生成的是 四羟基合铝酸钠(sodium tetrahydroxoaluminate),化学式为 …...

STM32F407用HAL库驱动42步进电机,从CubeMX配置到代码调试的完整避坑指南
STM32F407 HAL库驱动42步进电机实战:从CubeMX配置到高效调试的完整指南 第一次用STM32F407的HAL库驱动42步进电机时,我花了整整三天时间才让电机转起来。最让我抓狂的是明明CubeMX配置看起来一切正常,TIM1通道就是死活不出PWM波形。后来才发现…...

一款多功能显示控制器芯片,FHD 120/144Hz,支持最高1920x1080@120Hz.
主要特性特性类别具体规格输入接口1VGA (模拟RGB)、1HDMI 1.4 (带HDCP1.4/2.2)、1DP1.2 组合接口 (兼容HDMI 1.4,带HDCP1.4/2.2)输出接口2 Port LVDS,支持8bit/10bit最大分辨率1920x1200100Hz 或 1920x1080120Hz (带ODC)色彩深度输入:6/8/10b…...

提升3倍效率的Windows桌面端酷安社区解决方案:基于UWP平台的高性能第三方客户端
提升3倍效率的Windows桌面端酷安社区解决方案:基于UWP平台的高性能第三方客户端 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP Coolapk-UWP是一款基于UWP平台的第三方酷安客户…...

FLUX.1-dev-Controlnet-Union深度解析:多模态控制网络的架构与实战应用
FLUX.1-dev-Controlnet-Union深度解析:多模态控制网络的架构与实战应用 【免费下载链接】FLUX.1-dev-Controlnet-Union 项目地址: https://ai.gitcode.com/hf_mirrors/InstantX/FLUX.1-dev-Controlnet-Union FLUX.1-dev-Controlnet-Union作为FLUX.1-dev生态…...

Onekey Steam清单下载工具:快速获取游戏清单的完整指南
Onekey Steam清单下载工具:快速获取游戏清单的完整指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey是一款专业的开源Steam Depot清单下载工具,能够直接连接Ste…...

PentAGI:面向红队实战的开源渗透测试Agent系统
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正进红队实战的渗透测试Agent系统你有没有遇到过这样的场景:在一次内部红队演练中,刚摸到一台边缘业务服务器,想快速判断它是否暴露了Jenkins未授权访问、Confluence远程代码执行…...

FNF-PsychEngine终极指南:3个Lua脚本技巧让游戏体验飙升
FNF-PsychEngine终极指南:3个Lua脚本技巧让游戏体验飙升 【免费下载链接】FNF-PsychEngine Engine originally used on Mind Games mod 项目地址: https://gitcode.com/gh_mirrors/fn/FNF-PsychEngine FNF-PsychEngine是一款功能强大的节奏游戏引擎ÿ…...

【实操经验】拒答能力不达标,大模型备案怎么过
在生成式 AI 监管趋严的 2026 年,拒答率≥95% 是大模型备案的硬性门槛(GB/T 45644-2025)。不少自研或二次开发模型因安全对齐不足、拒答逻辑薄弱,测试时频繁 “翻车”—— 敏感问题答非所问、违法指令直接执行、多轮诱导轻易妥协&…...