【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者!
文章目录
- 介绍
- 流程步骤
- 1. 输入数据
- 2. 特征选择
- 3. 模型训练
- 4. I-Genes 评分计算
- 5. 输出结果
- IntelliGenesR
- 安装包
- 1. 特征选择
- 2. 模型训练和评估
- 3. I-Genes 评分计算
- 总结
- 系统信息
介绍
IntelliGenes 是一个新颖的机器学习(ML)流程,旨在通过多组学数据(包括全基因组测序、RNA-seq、临床和人口统计学信息)发现与疾病预测相关的生物标志物,并进行高精度的疾病预测。该流程结合了传统的统计方法和先进的机器学习算法,通过多组学数据的整合分析,发现新的生物标志物并预测疾病。该流程不仅能够提高疾病预测的准确性,还能为个性化医疗提供支持,帮助发现新的治疗靶点和干预措施。(该流程原是python代码,现在对它改成R包:IntelliGenes to IntelliGenesR)
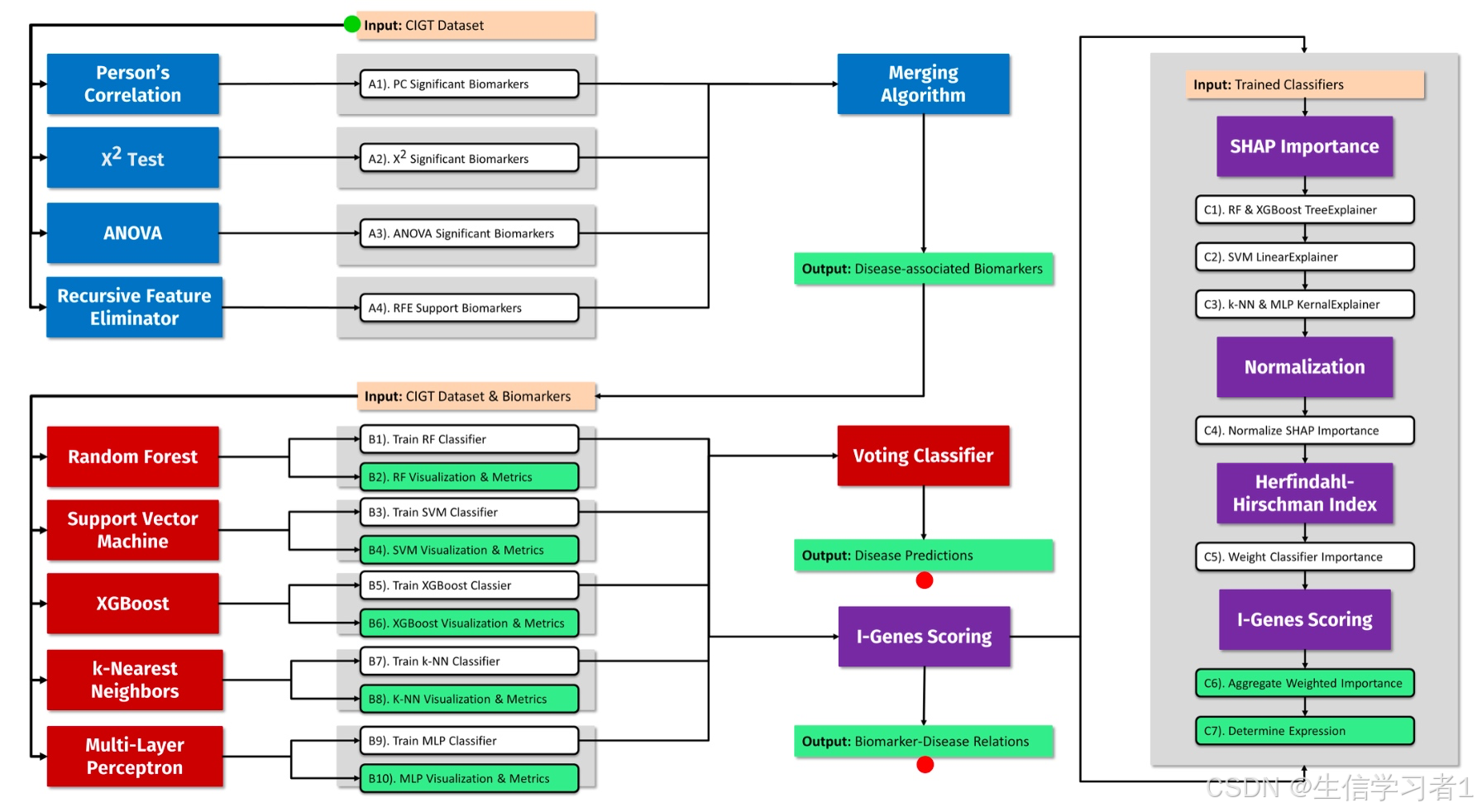
流程步骤
| Step | 作用 | 输入 | 输出 |
|---|---|---|---|
| 1. 数据准备 | 准备用于分析的多组学数据,包括 RNA 测序、临床和人口统计学信息 | 患者队列的 RNA 测序数据、临床和人口统计学数据 | 以 Clinically Integrated Genomics and Transcriptomics (CIGT) 格式组织的数据 |
| 2. 特征选择 | 使用统计测试(如 ANOVA)识别与疾病表型相关的基因子集 | CIGT 格式数据 | 与疾病显著相关的生物标志物列表 |
| 3. 模型训练 | 使用多种机器学习分类器(如 RF、SVM、XGBoost 等)构建高性能预测模型 | 特征选择阶段筛选出的生物标志物 | 训练好的分类器模型、分类器性能指标(如准确率、ROC、F1 等) |
| 4. I-Genes 评分计算 | 聚合、加权和归一化每个分类器对特征的重要性评分,得出每个基因的 I-Genes 评分 | 训练好的分类器模型、测试集数据 | 每个生物标志物的 I-Genes 评分,包括其在疾病预测中的重要性和表达方向 |
| 5. 结果输出与可视化 | 输出疾病预测结果、分类器性能指标、可视化图表(如 ROC 曲线、PR 曲线、SHAP 值图)以及 I-Genes 评分 | I-Genes 评分、分类器性能指标 | 患者的疾病预测结果、可视化图表、I-Genes 评分列表 |
1. 输入数据
- 输入数据格式:Clinically Integrated Genomics and Transcriptomics (CIGT) 格式,包括患者的年龄、性别、种族和民族背景、诊断信息以及 RNA-seq 驱动的基因表达数据。
- 数据来源:多组学数据,包括全基因组测序(WGS)、RNA-seq、临床和人口统计学信息。
2. 特征选择
- 方法:使用三种经典统计方法(Pearson 相关性、卡方检验、ANOVA)和一种机器学习分类器(递归特征消除,RFE)来提取与疾病显著相关的生物标志物。
- 结果:生成一组显著的疾病相关生物标志物列表。
- 目的:从大量的多组学数据中筛选出与疾病预测相关的特征,减少数据维度,提高后续模型训练的效率和准确性。
3. 模型训练
- 方法:应用七种机器学习分类器(随机森林、支持向量机、XGBoost、k-最近邻、多层感知器、软投票分类器、硬投票分类器)来计算基于多组学数据的特征重要性,并对患者进行疾病预测。
- 结果:生成每个分类器的性能指标(如准确率、ROC、F1、精确率、召回率、敏感性、特异性),并保存 ROC 和 PR 曲线的可视化结果。
- 目的:通过多种分类器的组合,提高疾病预测的准确性和鲁棒性。
4. I-Genes 评分计算
- 方法:使用 Shapley Additive exPlanations (SHAP) 和 Herfindahl-Hirschman Index (HHI) 来计算每个生物标志物的 I-Genes 评分。SHAP 值用于评估特征在疾病预测中的重要性,HHI 用于衡量分类器对高影响力生物标志物的依赖程度。
- 结果:生成每个生物标志物的 I-Genes 评分,包括其在疾病中的表达方向(过表达或低表达)。
- 目的:通过 I-Genes 评分,量化每个生物标志物在疾病预测中的重要性,并提供可解释的生物标志物排名。
5. 输出结果
- 输出内容:包括每个患者的疾病预测结果、分类器的性能指标、可视化图表(如 ROC 曲线、PR 曲线、SHAP 值图)以及 I-Genes 评分。
- 目的:提供一个全面的分析报告,帮助研究人员和临床医生理解多组学数据在疾病预测中的作用,并为后续的生物学验证和临床应用提供依据。
IntelliGenesR
IntelliGenesR 实现了 IntelliGenes 流程的核心模块,用于利用转录组和多组学数据进行可解释的疾病预测和特征评分(DeGroat, William, et al. “IntelliGenes: a novel machine learning pipeline for biomarker discovery and predictive analysis using multi-genomic profiles.” Bioinformatics 39.12 (2023): btad755)。该R软件包支持:
- 特征选择:使用多种统计检验 (
FeatureSelection函数)。 - 模型训练:使用各种机器学习分类器,并基于 SHAP 进行解释 (
run_classifiers函数)。 - I-Genes 评分:用于可解释的生物标志物优先级排序 (
compute_igenes_scores函数)。
IntelliGenesR的目录结构:
├── _pkgdown.yml
├── codecov.yml
├── data
├── data-raw
├── DESCRIPTION
├── inst
├── IntelliGenes.Rproj
├── LICENSE
├── LICENSE.md
├── man
├── NAMESPACE
├── NEWS.md
├── R
├── README.md
├── README.Rmd
├── src
└── vignettes
安装包
install.packages("IntelliGenesR_1.0.0.tar.gz", repos = NULL, type = "source") 是一个 R 命令,用于从本地的源代码包安装 R 软件包。可以通过以下百度网盘链接下载:
- 链接: 百度网盘链接
- 提取码: 前往购买R版IntelliGenes用于生物标志物发现的可解释机器学习
install.packages("IntelliGenesR_1.0.0.tar.gz", repos = NULL, type = "source")library(IntelliGenesR)
library(tidyverse)
1. 特征选择
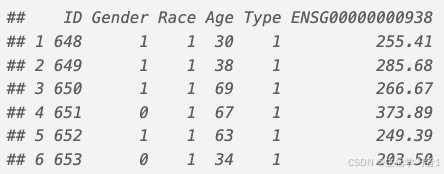
本教程使用软件包中包含的 ExampleData 数据集演示 IntelliGenesR 的工作流程。
我们首先应用 FeatureSelection() 函数,使用 Pearson、卡方、ANOVA 和 RFE 识别共识特征(通过?FeatureSelection()查看函数帮助文档)。
data("ExampleData")
head(ExampleData[, 1:6])feature_res <- FeatureSelection(data = ExampleData,target = "Type",id_col = "ID",pval_thresh = 0.05,use_rfe = TRUE
)head(feature_res$common_features)

解释:
- 返回的列表包括单独方法选择的特征及其交集。
common_features将用于下一阶段的模型构建(每一列是统计方法筛选两组差异标记物)。
2. 模型训练和评估
使用 run_classifiers() 函数训练一组分类器(通过?run_classifiers()查看函数帮助文档)。
res <- run_classifiers(inputDF = ExampleData |> column_to_rownames("ID"),target = "Type",features = feature_res$common_features$feature
)head(res$metrics)

解释:单个机器学习或集成机器学习模型的评估指标结果。
- 这返回一个包含训练模型和性能指标(准确率、ROC、F1、精确率、召回率、敏感性、特异性)的列表。
- ROC 和 PR 曲线的可视化已保存。
- 每个模型的 SHAP 值和 I-Genes 信息已存储。
3. I-Genes 评分计算
最后,我们使用 compute_igenes_scores() 计算特征级别的可解释性评分(通过?compute_igenes_scores()查看函数帮助文档)。
igenes_df <- compute_igenes_scores(classifiers = res$models,X_test = res$X_test,y_test = res$pred_label$trueLabel
)head(igenes_df)

解释:I-Gene引入了一种新的度量,即I-Gene评分来衡量个体生物标志物对复杂性状预测的重要性。这个表格提供了 IntelliGenes 流程中识别的生物标志物的详细信息,包括它们的标识符、I-Genes 评分、对疾病预测的贡献方向、表达模式以及排名。这些信息可以帮助研究人员理解哪些基因在疾病预测中起关键作用,并为后续的生物学验证和临床应用提供依据。
Feature:这一列显示了基因或特征的标识符,通常是基因的 Ensembl ID。Ensembl ID 是一个唯一的标识符,用于识别特定的基因。I_Genes_Score:这一列显示了每个基因的 I-Genes 评分。I-Genes 评分是 IntelliGenes 流程中计算的一个指标,用于衡量单个生物标志物对疾病预测的重要性。评分越高,表示该生物标志物在预测疾病中的重要性越大。Prediction:这一列显示了每个基因对疾病预测的贡献方向。Controls:表示该基因在对照组(健康个体)中的表达水平较高。Cases:表示该基因在病例组(患病个体)中的表达水平较高。
Expression:这一列描述了基因表达的模式。Overexpression:表示该基因在对照组中过表达。Inconclusive:表示该基因的表达模式不明确,无法确定其在对照组或病例组中的表达水平是否显著不同。Neutral:表示该基因的表达模式对疾病预测没有显著影响。
Ranking:这一列显示了基因的排名,根据 I-Genes 评分对基因进行排序。排名越高,表示该基因在预测疾病中的重要性越大。
总结
IntelliGenesR 是一个基于 R 语言的软件包,它实现了 IntelliGenes 流程的核心模块,用于利用转录组和多组学数据进行可解释的疾病预测和特征评分。这个流程结合了传统的统计方法和先进的机器学习算法,通过整合多组学数据来发现新的生物标志物并预测疾病。IntelliGenesR 的目的是提高疾病预测的准确性,并为个性化医疗提供支持,帮助发现新的治疗靶点和干预措施。
IntelliGenesR 的工作流程包括五个主要步骤:数据准备、特征选择、模型训练、I-Genes 评分计算和结果输出与可视化。数据准备阶段涉及整理 RNA 测序、临床和人口统计学信息。特征选择使用统计测试和机器学习分类器来识别与疾病相关的生物标志物。模型训练阶段应用多种机器学习分类器来构建预测模型。I-Genes 评分计算通过聚合和加权每个分类器对特征的重要性评分,得出每个基因的 I-Genes 评分。最后,结果输出与可视化阶段提供疾病预测结果、分类器性能指标和 I-Genes 评分。
IntelliGenesR 支持特征选择、模型训练和 I-Genes 评分等关键功能,使用户能够识别关键预测特征、训练多样化的分类器,并生成按排名排序的 I-Genes 列表,用于生物学解释。这个软件包的实现使得研究人员能够更深入地理解多组学数据在疾病预测中的作用,并为后续的生物学验证和临床应用提供依据。通过 IntelliGenesR,研究人员可以更有效地进行生物标志物的发现和疾病预测,为个性化医疗和精准治疗提供科学依据。
系统信息
## R version 4.4.3 (2025-02-28)
## Platform: aarch64-apple-darwin20
## Running under: macOS Sequoia 15.5
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## time zone: Asia/Shanghai
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] caret_7.0-1 lattice_0.22-6 lubridate_1.9.4
## [4] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4
## [7] purrr_1.0.4 readr_2.1.5 tidyr_1.3.1
## [10] tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0
## [13] IntelliGenesR_1.0.0 BiocStyle_2.34.0
##
## loaded via a namespace (and not attached):
## [1] pROC_1.18.5 rlang_1.1.5 magrittr_2.0.3
## [4] e1071_1.7-16 compiler_4.4.3 systemfonts_1.2.1
## [7] vctrs_0.6.5 reshape2_1.4.4 pkgconfig_2.0.3
## [10] crayon_1.5.3 fastmap_1.2.0 backports_1.5.0
## [13] PRROC_1.4 utf8_1.2.4 rmarkdown_2.29
## [16] tzdb_0.5.0 prodlim_2024.06.25 mlr3_0.23.0
## [19] ragg_1.3.3 xfun_0.51 randomForest_4.7-1.2
## [22] cachem_1.1.0 mlr3misc_0.16.0 jsonlite_2.0.0
## [25] recipes_1.2.0 uuid_1.2-1 parallel_4.4.3
## [28] R6_2.6.1 bslib_0.9.0 stringi_1.8.4
## [31] parallelly_1.43.0 rpart_4.1.24 xgboost_1.7.9.1
## [34] jquerylib_0.1.4 Rcpp_1.0.14 bookdown_0.42
## [37] iterators_1.0.14 knitr_1.50 future.apply_1.11.3
## [40] Matrix_1.7-2 splines_4.4.3 nnet_7.3-20
## [43] timechange_0.3.0 tidyselect_1.2.1 rstudioapi_0.17.1
## [46] yaml_2.3.10 timeDate_4041.110 codetools_0.2-20
## [49] listenv_0.9.1 plyr_1.8.9 withr_3.0.2
## [52] evaluate_1.0.3 future_1.34.0 desc_1.4.3
## [55] survival_3.8-3 proxy_0.4-27 kernlab_0.9-33
## [58] pillar_1.10.1 BiocManager_1.30.25 mlr3filters_0.8.1
## [61] checkmate_2.3.2 foreach_1.5.2 stats4_4.4.3
## [64] generics_0.1.3 hms_1.1.3 munsell_0.5.1
## [67] scales_1.3.0 globals_0.16.3 class_7.3-23
## [70] glue_1.8.0 tools_4.4.3 data.table_1.17.0
## [73] ModelMetrics_1.2.2.2 gower_1.0.2 fastshap_0.1.1
## [76] fs_1.6.5 grid_4.4.3 ipred_0.9-15
## [79] colorspace_2.1-1 paradox_1.0.1 nlme_3.1-167
## [82] patchwork_1.3.0 palmerpenguins_0.1.1 cli_3.6.4
## [85] textshaping_1.0.0 lava_1.8.1 gtable_0.3.6
## [88] sass_0.4.9 digest_0.6.37 lgr_0.4.4
## [91] htmlwidgets_1.6.4 farver_2.1.2 htmltools_0.5.8.1
## [94] pkgdown_2.1.1 caretEnsemble_4.0.1 lifecycle_1.0.4
## [97] mlr3learners_0.10.0 hardhat_1.4.1 MASS_7.3-64
相关文章:
【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...