基于 JMeter API 开发性能测试平台
目录
背景:
常用的 JMeter 类和功能的解释:
JMeter 编写性能测试脚本的大致流程示意图:
源码实现方式:
(1) 环境初始化
(2) 环境初始化
(3) 创建测试计划
(4) 创建 ThreadGroup
(5) 创建循环控制器
(6) 创建 Sampler
(7) 创建结果收集器
(8) 构建 tree,生成 jmx 脚本
(9) 测试执行
(10) 结果收集
背景:
JMeter 是一个功能强大的性能测试工具,若开发一个性能测试平台,用它作为底层执行引擎在合适不过。如要使用其API,就不得不对JMeter 整个执行流程,常见的类有清楚的了解。
常用的 JMeter 类和功能的解释:
-
TestPlan类:代表一个测试计划,它是性能测试的顶级元素。您可以使用它来设置全局的测试属性,如测试名称、线程组、监听器等。 -
ThreadGroup类:代表线程组,它定义了并发执行的线程数、启动延迟时间、循环次数等。线程组是性能测试的基本单位,所有的线程都在线程组内执行。 -
LoopController类:代表循环控制器,它定义了循环的次数或条件。可以将循环控制器添加到线程组中,以便在每个线程中执行多次循环。 -
HTTPSampler类:代表 HTTP 请求采样器,用于发送 HTTP 请求。您可以设置请求的 URL、方法(GET、POST 等)、请求参数、请求头等。 -
StandardJMeterEngine类:代表 JMeter 引擎,负责配置和执行测试计划。通过将测试计划配置给引擎,可以启动和执行性能测试。 -
JMeterUtils类:提供了一些 JMeter 的实用方法和属性。通过加载 JMeter 属性文件并初始化本地设置,可以确保 JMeter API 的正确运行。
为了能够在代码中创建和配置测试计划、线程组、循环控制器和其他元素,以及执行性能测试,这些类的功能和方法是我们必须要熟悉的。掌握了这些类,那么利用jmeter如何编写性能测
试脚本是怎样的,我们也来回顾下:
JMeter 编写性能测试脚本的大致流程示意图:
源码实现方式:
(1) 环境初始化
需要在项目中引入 上述JMeter核心API,这样我们才能使用 JMeter 提供的各种功能和类
import org.apache.jmeter.control.LoopController;
import org.apache.jmeter.engine.StandardJMeterEngine;
import org.apache.jmeter.protocol.http.sampler.HTTPSampler;
import org.apache.jmeter.testelement.TestPlan;
import org.apache.jmeter.threads.ThreadGroup;
import org.apache.jmeter.util.JMeterUtils;(2) 环境初始化
JMeter API 在执行过程中,首先会读取 JMeter 软件安装目录文件下配置文件里的属性,所以我们要通过 JMeter API 读取指定的 JMeter 主配置文件的目录以及 JMeter 的安装目录,
其中环境初始化主要包括以下 2 个步骤:
- 通过 JMeterUtils.loadJMeterProperties 加载 JMeter 主配置文件 JMeter.properties,然后把 jmeter.properties 中的所有属性赋值给 JMeterUtils 对象,以便之后获取所需的配置;
- 设置 JMeter 的安装目录,JMeter API 会根据我们指定的目录加载脚本运行时需要的配置
JMeterUtils.loadJMeterProperties("jmeter.properties");JMeterUtils.setJMeterHome(~/jemter)
JMeterUtils.initLocale();(3) 创建测试计划
使用 TestPlan 类创建一个测试计划,并设置相关属性。
TestPlan testPlan = new TestPlan("My Test Plan");
testPlan.setProperty(TestElement.TEST_CLASS, TestPlan.class.getName());
testPlan.setProperty(TestElement.GUI_CLASS, TestPlanGui.class.getName());(4) 创建 ThreadGroup
使用 ThreadGroup 类创建一个线程组,并设置相关属性,例如线程数、循环次数等
ThreadGroup threadGroup = new ThreadGroup();
threadGroup.setName("My Thread Group");
threadGroup.setNumThreads(10);
threadGroup.setRampUp(5);
threadGroup.setSamplerController(loopController);(5) 创建循环控制器
这一步是一个可选项。我们在实际测试过程中,创建循环控制器是为了模拟一个用户多次进行同样操作的行为,不创建循环控制器则默认是只执行一次操作。循环控制器创建的代码如下:
LoopController loopController = new LoopController();//设置循环次数,1 代表循环 1 次loopController.setLoops(1);loopController.setFirst(true);loopController.setProperty(TestElement.TEST_CLASS, LoopController.class.getName());loopController.setProperty(TestElement.GUI_CLASS, LoopControlPanel.class.getName());loopController.initialize()(6) 创建 Sampler
使用 HTTPSampler 类创建一个 HTTP 请求采样器,并设置请求的 URL、方法等属性
HTTPSampler httpSampler = new HTTPSampler();
httpSampler.setDomain("example.com");
httpSampler.setPort(80);
httpSampler.setPath("/api/endpoint");
httpSampler.setMethod("GET");(7) 创建结果收集器
结果收集器可以保存每次 Sampler 操作完成之后的结果的相关数据,例如,每次接口请求返回的状态、服务器响应的数据。
ResultCollector resultCollector = new ResultCollector();resultCollector.setName(ResultCollector.class.getName());(8) 构建 tree,生成 jmx 脚本
以上步骤其实都是为了创建了一个 HashTree 节点做准备。把创建都添加到 子 HashTree 节点中,然后把子 HashTree 加到 testplan 中,最后再把 tesplan 节点加到构建好的父 HashTree 节点,这样就生成了我们的脚本可执行文件 jmx。代HashTree subTree = new HashTree(
通过以上代码就可以创建出 JMeter 可识别的 HashTree 结构,并且可以通过 saveTree 保存为 test.jmx 文件。如果是现成的jmx文件,可直接通过 HashTree jmxTree =
SaveService.loadTree(file); loadTree 会把 jmx 文件转成内存对象,并返回内存对象中生成的 HashTree。
subTree.add(httpSamplerProxy);subTree.add(loopController);subTree.add(threadGroup);subTree.add(resultCollector);HashTree tree = new HashTree();tree.add(testPlan,subTree);SaveService.saveTree(tree, new FileOutputStream("test.jmx"));} catch (IOException e) {e.printStackTrace();}(9) 测试执行
通过脚本文件的执行(测试执行),我们便可以开始对服务器发起请求,进行性能测试。测试执行主要包括 2 个步骤:
- 把可执行的测试文件加载到 StandardJMeterEngine;
- 通过 StandardJMeterEngine 的 run 方法执行,便实现了 Runable 的接口,其中 engine.run 执行的便是线程的 run 方法
StandardJMeterEngine engine = new StandardJMeterEngine();engine.configure(jmxTree);engine.run();(10) 结果收集
JMeter API 提供了一个结果收集器(ResultCollector),用于收集和处理性能测试结果。它是 SampleListener 接口的一个实现类,可以监听每个测试样本的事件,并对测试结果进行
处理。我们可以重写 sampleOccurred 方法来收集每次 loop 的结果。该方法的参数 SampleEvent 中包含相应的测试结果。然后把测试结果数据存到消息队列里面,比如kafka ,后端获取存
储的实时采集数据,进行相应的计算,生成的数据返回给前端进行绘制展示。
以下是我收集到的比较好的学习教程资源,虽然不是什么很值钱的东西,如果你刚好需要,可以评论区,留言【777】直接拿走就好了


各位想获取资料的朋友请点赞 + 评论 + 收藏,三连!
三连之后我会在评论区挨个私信发给你们~
相关文章:
基于 JMeter API 开发性能测试平台
目录 背景: 常用的 JMeter 类和功能的解释: JMeter 编写性能测试脚本的大致流程示意图: 源码实现方式: (1) 环境初始化 (2) 环境初始化 (3) 创建测试计划 (4) 创建 ThreadGroup (5) 创建循环控制器 (6) 创建 Sampler (…...

HBase-写流程
写流程顺序正如API编写顺序,首先创建HBase的重量级连接 (1)读取本地缓存中的Meta表信息;(第一次启动客户端为空) (2)向ZK发起读取Meta表所在位置的请求; (…...
[mongo]应用场景及选型
应用场景及选型 MongoDB 数据库定位 OLTP 数据库横向扩展能力,数据量或并发量增加时候架构可以自动扩展灵活模型,适合迭代开发,数据模型多变场景JSON 数据结构,适合微服务/REST API基于功能选择 MongoDB 关系型数据库迁移 从基…...

linux c語言之crc16错误检测的使用
一、是什么? CRC16是循环冗余校验的一种,是一种根据数据产生校验码的方法。它是一种比较常用的校验算法,可以用于错误检测和纠正等方面。CRC16是16位的校验码,可以检测出32位以内的错误。在通信协议、网络传输等领域中,CRC16被广泛应用. 二、使用步骤 1.引入库 代码如…...
搭建本地开发服务器
搭建本地开发服务器 :::warning 注意 在上一个案例的基础上添加本地开发服务器,请保留上个案例的代码。如需要请查看 Webpack 使用。 ::: 搭建本地开发服务器这一个环节是非常有必要的,我们不可能每次修改源代码就重新打包一次。这样的操作是不是太繁琐…...

linux脚本
程序后台运行: nohup java -jar xxx.jar &>hello.log & 后台运行java-jar命令,并且将日志输出到hello.log文件 防火墙: 开启防火墙:systemctl start firewalld 开放指定端口:firewall-cmd --zonepublic --…...
企升编辑器word编写插件
面向用户群体招投标人员,用统一的模板来编写标书,并最终合并标书。项目经理,编写项目开发计划书,项目验收文档等。开发人员,编写项目需求规格说明书、设计说明书、技术总结等文档。其他文档编写工作量较多的岗位人员。…...
怎么在JMeter中的实现关联
我们一直用的phpwind这个系统做为演示系统, 如果没有配置好的同学, 请快速配置之后接着往下看哦. phpwind发贴时由于随着登陆用户的改变, verifycode是动态变化的, 因此需要用到关联. LoadRunner的关联函数是reg_save_param, Jmeter的关联则是利用后置处理器来完成. 在需要查…...

算法通关村第六关——如何使用中序和后序来恢复一颗二叉树
1 树的基础知识 1.1 树的定义 树(Tree):表现得是一种层次关系,为 n ( n ≥ 0 ) n(n≥0) n(n≥0)个节点构成的有限集合,当n0时,称为空树,对于任一…...

leetcode算法题--判断是否能拆分数组
原题链接:https://leetcode.cn/problems/check-if-it-is-possible-to-split-array/ 一开始思路想错了。。导致浪费很多时间 其实只要能找到存在一个子数组,子数组长度为2,这个子数组符合条件就一定能拆分。。 func canSplitArray(nums []i…...
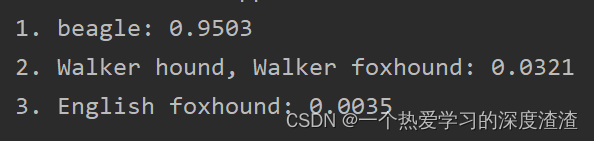
基于Flask的模型部署
基于Flask的模型部署 一、背景 Flask:一个使用Python编写的轻量级Web应用程序框架; 首先需要明确模型部署的两种方式:在线和离线; 在线:就是将模型部署到类似于服务器上,调用需要通过网络传输数据&…...

【资料分享】全志科技T507-H开发板规格书
1 评估板简介 创龙科技TLT507-EVM是一款基于全志科技T507-H处理器设计的4核ARM Cortex-A53国产工业评估板,主频高达1.416GHz,由核心板和评估底板组成。核心板CPU、ROM、RAM、电源、晶振等所有器件均采用国产工业级方案,国产化率100%。同时,评估底板大部分元器件亦采用国产…...
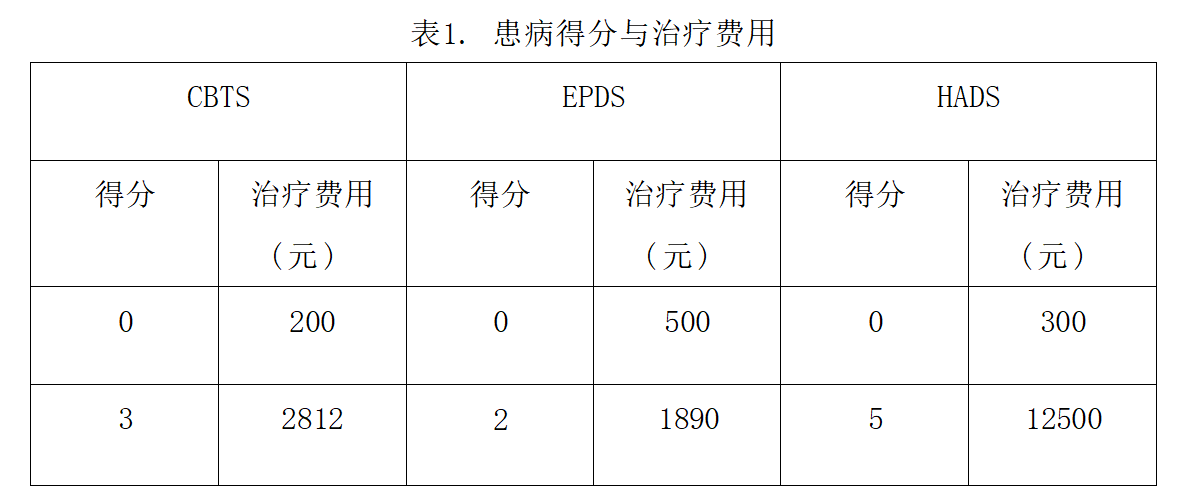
2023华数杯数学建模C题思路 - 母亲身心健康对婴儿成长的影响
# 1 赛题 C 题 母亲身心健康对婴儿成长的影响 母亲是婴儿生命中最重要的人之一,她不仅为婴儿提供营养物质和身体保护, 还为婴儿提供情感支持和安全感。母亲心理健康状态的不良状况,如抑郁、焦虑、 压力等,可能会对婴儿的认知、情…...
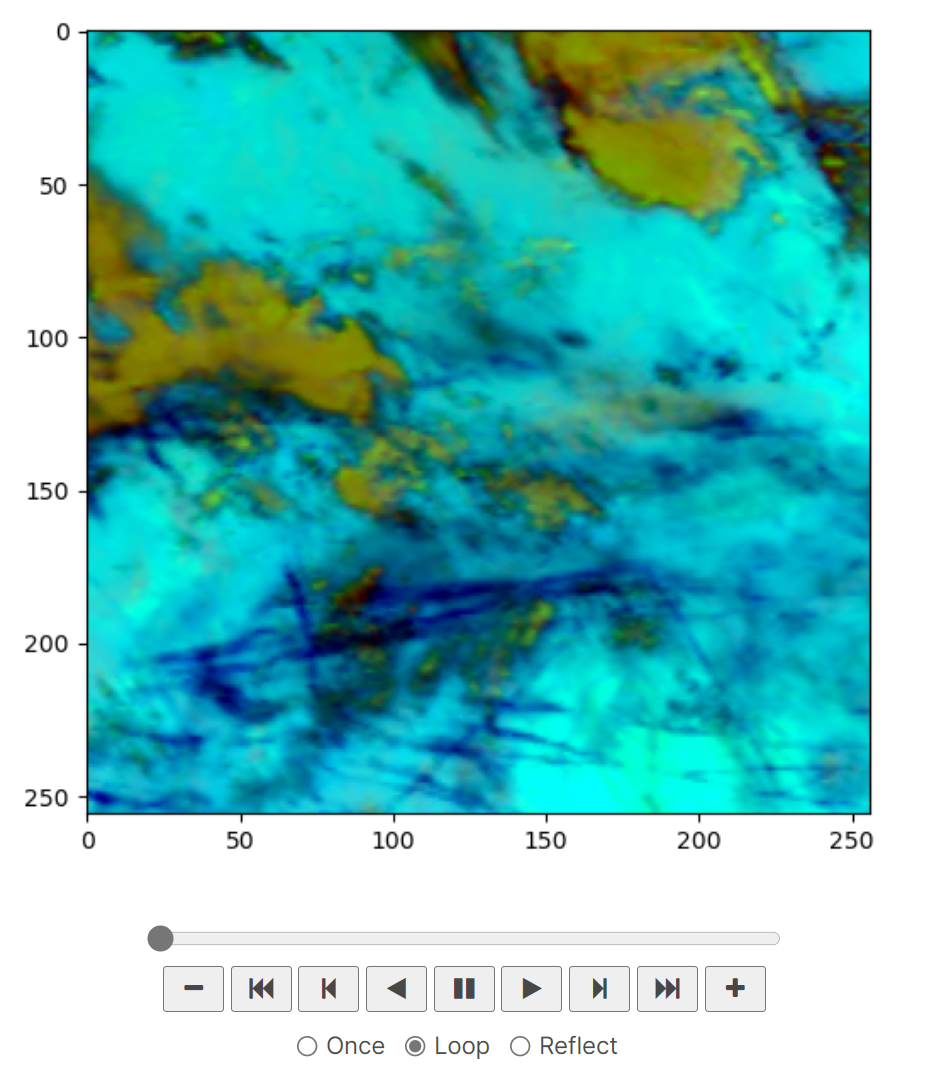
【Kaggle】Identify Contrails to Reduce Global Warming 比赛数据集的可视化(含源代码)
一、数据简单解读 卫星图像最初来自: https://www.goes-r.gov/spacesegment/abi.html高级基线成像仪是GOES-R系列中用于对地球天气、海洋和环境进行成像的主要仪器。ABI用16个不同的光谱波段观察地球(上一代GOES只有<>个),…...
 BeanFactory 和 ApplicationContext 区别)
Spring(12) BeanFactory 和 ApplicationContext 区别
目录 一、BeanFactory 和 ApplicationContext 区别?二、既然 Spring Boot 中使用的是 ApplicationContext 进行应用程序的启动和管理,那么 Spring Boot 会用到 BeanFactory 吗? 一、BeanFactory 和 ApplicationContext 区别? Bea…...
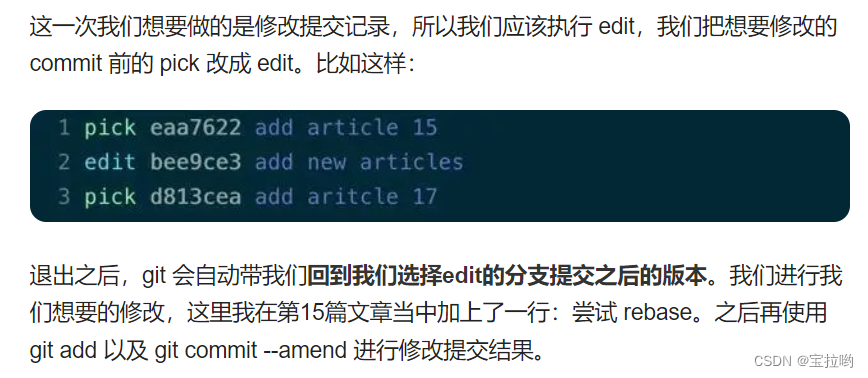
git的日常使用
加入忽略列表:在.gitignore中加入忽略的文件,build/ 表示build文件夹下,*.jar 表示以jar结尾的,用换行符隔开将另一个分支合并到当前分支:git merge xxx冲突出现,可以看看这里:详解Git合并冲突—…...

【Spring Boot】请求参数传json对象,后端采用(pojo)CRUD案例(102)
请求参数传json对象,后端采用(pojo)接收的前提条件: 1.pom.xml文件加入坐标依赖:jackson-databind 2.Spring Boot 的启动类加注解:EnableWebMvc 3.Spring Boot 的Controller接受参数采用:Reque…...
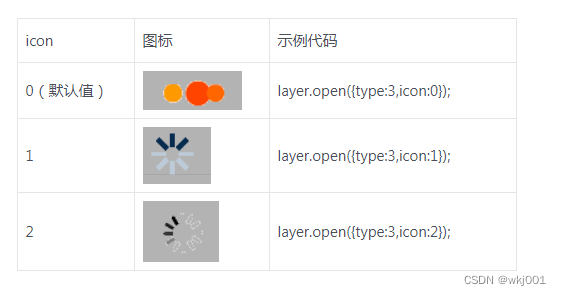
layui之layer弹出层的icon数字及效果展示
layer的icon样式 icon如果在信息提示弹出层值(type为0)可以传入0-6,icon与图标对应关系如下: 如果是加载层(type为3)可以传入0-2,icon与图标对应关系如下:...

Python selenium对应的浏览器chromedriver版本不一致
1、chrome和chromedriver版本不一致导致的,我们只需要升级下chromedriver的版本即可 浏览器版本查看 //打开google浏览器直接访问,查看浏览器版本 chrome://version/ 查看chromedriver的版本 //查看驱动版本 chromedriver chromedriver下载 可看到浏…...
Redis的安装方法与基本操作
目录 前言 一、REDIS概述 二、REDIS安装 1、编译安装 2.yum安装 三、Redis的目录结构 四、基础命令解析 五、在一台服务器上启动多个redis 六、数据库的基本操作 (一)登录数据库 (二)基础命令 七、Redis持久化 (一&…...

深入浅出:拆解Xilinx ERNIC IP的硬件架构,看RoCE v2如何卸载CPU
深入浅出:拆解Xilinx ERNIC IP的硬件架构,看RoCE v2如何卸载CPU 在数据中心和高性能计算领域,RDMA(远程直接内存访问)技术正成为突破网络性能瓶颈的关键。Xilinx的ERNIC IP核作为RoCE v2协议的硬件实现,通过…...

用Matlab给变形镜建模:从高斯函数到贝塞尔曲线,两种响应函数仿真全流程
用Matlab给变形镜建模:从高斯函数到贝塞尔曲线,两种响应函数仿真全流程 光学系统工程师在设计自适应光学系统时,经常需要精确模拟变形镜的响应特性。这种模拟不仅关系到系统性能预测的准确性,也直接影响控制算法的开发效率。本文将…...
)
Zabbix监控华为防火墙丢包?可能是你的SNMP v2c配置没做对(附Python巡检脚本)
Zabbix监控华为防火墙丢包问题的深度排查与自动化解决方案 当Zabbix监控华为防火墙时出现丢包或数据异常,很多工程师的第一反应是检查网络连通性或Zabbix服务器配置,却忽略了防火墙自身SNMP v2c与安全策略的联动机制。本文将揭示这一常见误区的技术根源&…...

MySQL新手必看:Navicat导入SQL文件报错1046?三步搞定数据库选择问题
MySQL图形化工具避坑指南:彻底解决1046报错与数据库选择问题 刚接触MySQL的开发者,十有八九会在第一次导入SQL文件时遇到那个令人困惑的弹窗——"Error Code: 1046. No database selected"。这个看似简单的提示背后,其实隐藏着MySQ…...

模电数电不再怕:用甘晴void的三本笔记法,搞定HNU电路与电子学课堂测验与作业
模电数电不再怕:用甘晴void的三本笔记法,搞定HNU电路与电子学课堂测验与作业 电路与电子学这门课,对很多计算机专业的学生来说就像一座难以逾越的高山。模电的抽象概念、数电的逻辑设计,加上频繁的课堂测验和课后作业,…...

Fluent瞬态计算踩坑记录:时间统计采样设置里的3个关键细节与避坑指南
Fluent瞬态计算时间统计功能深度解析:从原理到实践的3个高阶技巧 在计算流体动力学(CFD)的瞬态仿真中,时间统计功能就像一位隐形的数据分析师,默默记录着流场参数的每一次脉动与演变。许多工程师在使用Fluent进行瞬态计…...

从MSP430到MSPM0L1306:嵌入式工程迁移实战与SDK应用指南
1. 项目概述:从零理解MSPM0L1306的工程迁移最近在帮一个朋友处理一个老项目升级,核心需求是把一个基于TI老款MSP430系列MCU的温控器,迁移到TI新推出的MSPM0L1306这颗芯片上。朋友的原话是:“老芯片快买不到了,新出的MS…...

56、CAN总线RC低通滤波器截止频率计算与实战
CAN总线RC低通滤波器截止频率计算与实战 一、一个让我熬夜三天的CAN通信故障 去年做某车载ECU项目,CAN总线在电机启动瞬间频繁丢帧。示波器抓波形,CAN_H对地毛刺高达8V,持续时间约200ns。团队里有人提议“加磁珠”,有人喊“上共模扼流圈”。我翻出TI的AN-2298应用笔记,发…...

2026年10款论文降AI率平台实测:从90%降至10%的硬核之选
现在学校对 AIGC 的检测越来越严格,降低 AI 率成了毕业生最头疼的问题。我当初写论文的时候,就因为 AI 率太高差点栽跟头,熬夜一遍遍手动修改,结果不仅 AI 率没降下来,查重率还越改越高,整个人都快崩溃了。…...

躲猫猫书店管理系统
选题背景随着互联网技术的飞速发展和电子商务的普及,传统实体书店面临着前所未有的挑战与机遇。一方面,线上购书平台凭借其便捷性、价格优势和海量选择,分流了大量读者;另一方面,实体书店独特的文化氛围、沉浸式阅读体…...