python之prettytable库的使用
文章目录
- 一 什么是prettytable
- 二 prettytable的简单使用
- 1. 添加表头
- 2. 添加行
- 3. 添加列
- 4. 设置对齐方式
- 4. 设置输出表格样式
- 5. 自定义边框样式
- 6. 其它功能
- 三 prettytable在实际中的使用
一 什么是prettytable
prettytable是Python的一个第三方工具库,用于创建漂亮的ASCII表格。它支持带有列标题的表格,还支持颜色和自定义格式。使用prettytable可以轻松地将数据可视化为表格,方便阅读和理解。
因为是第三方工具库,所以要先安装,安装命令如下
pip install prettytable
二 prettytable的简单使用
1. 添加表头
使用field_names来添加表头,传参是一个list对象
from prettytable import PrettyTable#创建Prettytable实例
tb = PrettyTable()
#添加表头
tb.field_names = ['userId', 'name', 'sex', 'age', 'job']
print(tb)>>>
+--------+------+-----+-----+-----+
| userId | name | sex | age | job |
+--------+------+-----+-----+-----+
+--------+------+-----+-----+-----+
2. 添加行
使用add_row()方法来添加行数据,传参是一个list对象
from prettytable import PrettyTable#创建Prettytable实例
tb = PrettyTable()
#添加表头
tb.field_names = ['userId', 'name', 'sex', 'age', 'job']
#添加行数据
tb.add_row(['123', '张三', '男', '25', 'softtest'])
print(tb)
3. 添加列
使用add_column()方法来添加列数据,add_column()有两个参数:第一个是列标题的名称,类型str;第二个是列对应的value,类型list,如下
from prettytable import PrettyTable#创建Prettytable实例
tb = PrettyTable()
#添加表头
tb.field_names = ['userId', 'name', 'sex', 'age', 'job']
#添加行
tb.add_row(['123', '张三', '男', '25', 'softtest'])
#添加列
tb.add_column('address', ['深圳'])
print(tb)
>>>
+--------+------+-----+-----+----------+---------+
| userId | name | sex | age | job | address |
+--------+------+-----+-----+----------+---------+
| 123 | 张三 | 男 | 25 | softtest | 深圳 |
+--------+------+-----+-----+----------+---------+
4. 设置对齐方式
使用align来设置对齐方式,默认居中对齐,其中l是向左对齐,c是居中对齐,r是向右对齐,如下
from prettytable import PrettyTable#创建Prettytable实例
tb = PrettyTable()
#添加表头
tb.field_names = ['userId', 'name', 'sex', 'age', 'job']
#添加行
tb.add_row(['123', '张三', '男', '25', 'softtest'])
tb.add_row(['124', '李四', '男', '25', 'Java'])
#添加列
tb.add_column('address', ['深圳', '北京'])
#设置对齐方式align: l,r,c
tb.align = 'l'
print(tb)>>>
+--------+------+-----+-----+----------+---------+
| userId | name | sex | age | job | address |
+--------+------+-----+-----+----------+---------+
| 123 | 张三 | 男 | 25 | softtest | 深圳 |
| 124 | 李四 | 男 | 25 | Java | 北京 |
+--------+------+-----+-----+----------+---------+
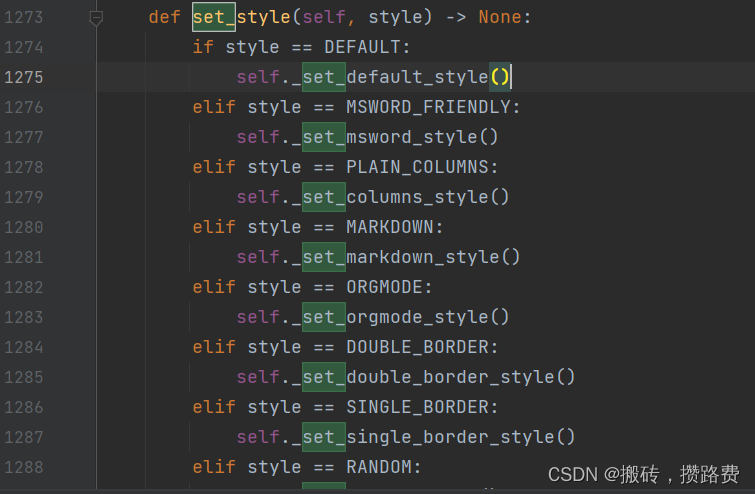
4. 设置输出表格样式
使用set_style()来控制数据表格的样式,set_style()默认参数是DEFAULT,如果需要更换为其它方式,则需要import导入后使用,如下
from prettytable import PrettyTable
from prettytable import MARKDOWN, MSWORD_FRIENDLY#创建Prettytable实例
tb = PrettyTable()
#添加表头
tb.field_names = ['userId', 'name', 'sex', 'age', 'job']
#添加行
tb.add_row(['123', '张三', '男', '25', 'softtest'])
tb.add_row(['124', '李四', '男', '25', 'Java'])
#添加列
tb.add_column('address', ['深圳', '北京'])
#设置对齐方式align: l,r,c
tb.align = 'l'
#设置输出表格的样式
print("DEFAULT表格样式:")
print(tb)
tb.set_style(MSWORD_FRIENDLY)
print("MSWORD_FRIENDLY表格样式:")
print(tb)
tb.set_style(MARKDOWN)
print("MARKDOWN表格样式:")
print(tb)>>>
DEFAULT表格样式:
+--------+------+-----+-----+----------+---------+
| userId | name | sex | age | job | address |
+--------+------+-----+-----+----------+---------+
| 123 | 张三 | 男 | 25 | softtest | 深圳 |
| 124 | 李四 | 男 | 25 | Java | 北京 |
+--------+------+-----+-----+----------+---------+
MSWORD_FRIENDLY表格样式:
| userId | name | sex | age | job | address |
| 123 | 张三 | 男 | 25 | softtest | 深圳 |
| 124 | 李四 | 男 | 25 | Java | 北京 |
MARKDOWN表格样式:
| userId | name | sex | age | job | address |
|:-------|:-----|:----|:----|:---------|:--------|
| 123 | 张三 | 男 | 25 | softtest | 深圳 |
| 124 | 李四 | 男 | 25 | Java | 北京 |
5. 自定义边框样式
在prettyble中表格边框由三部分组成:横边框,竖边框和边框连接符,由以下几个属性控制
table.border 控制是否显示边框,默认是True
table.junction_char 控制边框连接符
table.horizontal_char 控制横边框符号
table.vertical_char 控制竖边框符号
from prettytable import PrettyTable#创建Prettytable实例
tb = PrettyTable()
#添加表头
tb.field_names = ['userId', 'name', 'sex', 'age', 'job']
#添加行
tb.add_row(['123', '张三', '男', '25', 'softtest'])
tb.add_row(['124', '李四', '男', '25', 'Java'])
#添加列
tb.add_column('address', ['深圳', '北京'])
#设置对齐方式align: l,r,c
tb.align = 'l'
#自定义边框样式
print("默认边框:")
print(tb)
tb.horizontal_char = '*' #横边框
tb.vertical_char = '|' #竖边框
tb.junction_char = '|' #边框连接符
print("自定义边框:")
print(tb)
>>>
默认边框:
+--------+------+-----+-----+----------+---------+
| userId | name | sex | age | job | address |
+--------+------+-----+-----+----------+---------+
| 123 | 张三 | 男 | 25 | softtest | 深圳 |
| 124 | 李四 | 男 | 25 | Java | 北京 |
+--------+------+-----+-----+----------+---------+
自定义边框:
|********|******|*****|*****|**********|*********|
| userId | name | sex | age | job | address |
|********|******|*****|*****|**********|*********|
| 123 | 张三 | 男 | 25 | softtest | 深圳 |
| 124 | 李四 | 男 | 25 | Java | 北京 |
|********|******|*****|*****|**********|*********|
6. 其它功能
prettytable还有很多其它功能,可以参考官网或者这篇文章:python用prettytable输出漂亮的表格
三 prettytable在实际中的使用
在实际的接口测试过程中,我们都要对返回的接口进行数据校验,包括但不限于返回状态码,单个字段值。为了能够快速知道,以及美化校验结果,我们可以使用prettytable来进行结果校验输出,如下。
返回接口:
{"HEAD": {"xTypCod": null,"xHdrLen": "203","xSysCod": null,"xDskSys": null,"xWkeCod": "WdcTrfSetBeg","xKeyVal": null,"xIsuCnl": "X86","xEncCod": null,"xDalCod": null,"xCmmTyp": null,"xOrgIsu": null,"xPreIsu": null,"xEntUsr": "","xUsrPwd": null,"xIsuDat": "0","xIsuTim": "0","xMacCod": null,"xRtnLvl": null,"xRtnCod": "WYZQA76","xDevNbr": null,"xTlrNbr": "100025","xRqsNbr": null,"xCmmRsv": null,"xDocSiz": null,"xItvTms": null,"xMsgFlg": null,"xAppRsv": null},"BODY": {"$ERRORMSG$": [{"xErrMsg": "WYZQA76锁查步骤表记录失败,批次D019860641"}]}
}
校验脚本
from prettytable import PrettyTable
import json
import jsonpathresponse_data = """
{"HEAD": {"xTypCod": null,"xHdrLen": "203","xSysCod": null,"xDskSys": null,"xWkeCod": "WdcTrfSetBeg","xKeyVal": null,"xIsuCnl": "X86","xEncCod": null,"xDalCod": null,"xCmmTyp": null,"xOrgIsu": null,"xPreIsu": null,"xEntUsr": "","xUsrPwd": null,"xIsuDat": "0","xIsuTim": "0","xMacCod": null,"xRtnLvl": null,"xRtnCod": "WYZQA76","xDevNbr": null,"xTlrNbr": "100025","xRqsNbr": null,"xCmmRsv": null,"xDocSiz": null,"xItvTms": null,"xMsgFlg": null,"xAppRsv": null},"BODY": {"$ERRORMSG$": [{"xErrMsg": "WYZQA76锁查步骤表记录失败,批次D019860641"}]}
}
"""def validate_data(data: dict, yqz: dict) -> None:""":param data: 要校验的数据:param yqz: 预期值:return: None"""data = json.loads(data)tb = PrettyTable()#添加表头tb.field_names = ['比较字段', '预期值', '实际值', '是否通过']for k, v in yqz.items():#用jsonpath查找预期值字段在返回数据resresponse_data的值res = jsonpath.jsonpath(data, '$..' + k)[0]if v == res:tb.add_row([k, v, res, 'Y'])else:tb.add_row([k, v, res, 'N'])print(tb)#预期值数据
yqz = {'xRtnCod': 'WYZQA76', 'xErrMsg': 'WYZQA76锁查步骤表记录失败,批次D019860641'}
#结果校验
validate_data(response_data, yqz)效果
>>>
+----------+------------------------------------------+------------------------------------------+----------+
| 比较字段 | 预期值 | 实际值 | 是否通过 |
+----------+------------------------------------------+------------------------------------------+----------+
| xRtnCod | WYZQA76 | WYZQA76 | Y |
| xErrMsg | WYZQA76锁查步骤表记录失败,批次D019860641 | WYZQA76锁查步骤表记录失败,批次D019860641 | Y |
+----------+------------------------------------------+------------------------------------------+----------+
上面做了一个简单的演示,实际工作中可以结合自身需求封装成组件或者包,使用效果会更佳。
相关文章:
python之prettytable库的使用
文章目录 一 什么是prettytable二 prettytable的简单使用1. 添加表头2. 添加行3. 添加列4. 设置对齐方式4. 设置输出表格样式5. 自定义边框样式6. 其它功能 三 prettytable在实际中的使用 一 什么是prettytable prettytable是Python的一个第三方工具库,用于创建漂亮…...

google PGS 下一代id
前言:为了进一步增强用户的隐私及其多平台游戏体验,Play 游戏服务(PGS) 正在推出下一代玩家 ID,用户第一次玩游戏时,他们将始终被分配一个唯一的下一代玩家 ID,无论用户在什么设备或平台上玩游戏,该 ID 都将…...

【elasticsearch】关于elasticsearch的max_result_window限制问题的解决方式思考
事情起因:我们使用es作为日志搜索引擎,客户收集到的业务日志非常之大,每次查询后,返回页数较多,由于我们web界面限制每页返回150条,当客户翻到66页之后就会报错。 文章目录 前言 二、实验 1.默认生成20条数…...
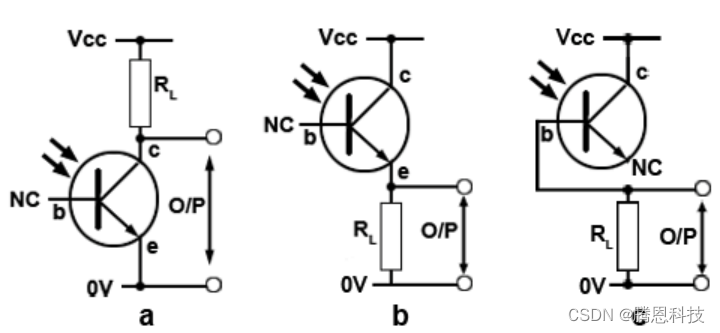
音频光耦合器
音频光耦合器是一种能够将电信号转换为光信号并进行传输的设备。它通常由发光二极管(LED)和光敏电阻(光电二极管或光敏电阻器)组成。 在音频光耦合器中,音频信号经过放大和调节后,被转换为电流信号…...

【C++精华铺】3.C++入门 引用(const)、内联函数
目录 1. 引用 1.1 引用特性 1.2 常引用 1.2.1 权限放大 1.2.2 权限缩小 1.3 使用场景 1.3.1 传参 1.3.2 做返回值 1.4 传值和传引用的效率比较 1.5 引用和指针的区别 2. 内联函数 2.1 inline 2.2 特性 1. 引用 在C中,引入了一个新的概念引用,与…...
生态系统服务(InVEST模型)供给与需求、价值核算技术及人类活动、重大工程项目、自然保护区、碳中和等领域中实际案例分析
对接工作实际项目及论文写作,解决参会者关注的重点及实际项目过程问题,采取逐步延伸的逻辑,不论您是小白亦或是已经能够成功运行InVEST模型生成结果,您可以自由选择课程内容,如果您是小白老师手把手教您,如…...

TiDB Serverless 正式商用,全托管的云服务带来数据管理和应用程序开发的全新体验
八 年 前 ,我们构建了 TiDB,一个开源分布式关系型数据库。 我们的目标是重新定义开发者和企业处理数据的方式,满足不断增长的可扩展性、灵活性和性能需求。 从那时起,PingCAP 便致力于为开发者和企业提供快速、灵活和规模化的数据…...
PXE-kickstart无人值守安装操作系统
PXE的概念: PXE(Pre-boot Execution Environment,预启动执行环境)是由Intel公司开发的最新技术,工作于C/S的网络模式,支持工作站通过网络从远端服务器下载映像,并由此支持通过网络启动操作系统…...
使用Flask.Request的方法和属性,获取get和post请求参数(二)
1、Flask中的request 在Python发送Post、Get等请求时,我们使用到requests库。Flask中有一个request库,有其特有的一些方法和属性,注意跟requests不是同一个。 2、Post请求:request.get_data() 用于服务端获取客户端请求数据。注…...

解决 idea maven依赖引入失效,无法正常导入依赖问题
解决 idea maven依赖引入失效,无法正常导入依赖问题_idea无法导入本地maven依赖_普通网友的博客-CSDN博客 解决 idea maven依赖引入失效,无法正常导入依赖问题 idea是真的好用,不过里面的maven依赖问题有时候还真挺让人头疼,不少小…...
基础知识点)
Python之集合(set)基础知识点
文章目录 1. 创建集合2. 获取集合的元素个数3. 向集合中添加元素4. 从集合中移除元素5. 判断元素是否在集合中6. 遍历集合7. 常用的集合操作7.1 并集7.2 交集7.3 差集 在Python中,集合(Set)是一种无序且不重复的数据结构。它是由一组用花括号…...
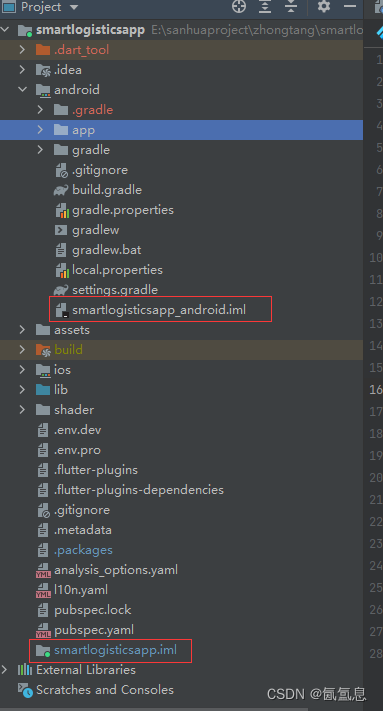
flutter 没有open android module in Android studio 插件代码爆红
参考 1.结论 其实就是缺少这个文件 2.解决方案有两个 2.1 方案一 手动创建一个,命名规则是项目名字‘_android’‘.iml’ 内容如下: <?xml version"1.0" encoding"UTF-8"?> <module type"JAVA_MODULE" version"4">&l…...

计算机网络实验2:网络嗅探
文章目录 1. 主要教学内容2. Wireshark介绍3. Wireshark下载4. 使用Wireshark捕获包4.1 选择网卡4.2 停止抓包4.3 保存数据 5. Wireshark的过滤规则6. Wireshark实例 1. 主要教学内容 实验内容:安装、学习使用网络包分析工具Wireshark。所需学时:1。重难…...
智慧防灾:数字孪生技术的应用
最近的“杜苏芮”“卡努”有没有对大家产生影响呢? 频繁发生的台风和其他自然灾害引起了人们对于灾害预防和应对的高度关注。在这种背景下,数字孪生作为一项前沿技术,为灾害预防领域提供了全新的解决方案。本文就带大家了解一下数字孪生技术…...
)
Google 扫码器(仅限 Android)
Google 扫码器(仅限 Android) Google Code Scanner API 提供了全面的扫描解决方案,无需您的应用请求相机权限,同时保护用户隐私。这是通过将扫描代码委托给 Google Play 服务并仅将扫描结果返回给您的应用来完成的(视…...

pandoc word转markdown之后正则修改
问题 用pandoc工具将doc文件转换为markdown文件后,有关图片的处理会变成: (./url路径){width“3.46875in” height“1.0729166666666667in”} 但是我要展示到前端的,前端组件用的v-md-preview,结果展示的时候,后面的宽…...

使用Python和wxPython将图片转换为草图
导语: 将照片转换为艺术风格的草图是一种有趣的方式,可以为您的图像添加独特的效果。在本文中,我们将介绍如何使用Python编程语言和wxPython图形用户界面库来实现这一目标。我们将探讨如何使用OpenCV库将图像转换为草图,并使用wxPython创建一…...

深入浅出对话系统——闲聊对话系统进阶
引言 本文主要关注生成式闲聊对话系统的进阶技术。 基于Transformer的对话生成模型 本节主要介绍GPT系列文章,这是由OpenAI团队推出的,现在大火的ChatGPT也是它们推出的。 GPT : Improving Language Understanding by Generative Pre-Traini ng 在自…...

List与Set的区别
List与Set的区别 大家好,在我们平时的代码编写过程中,经常会碰到需要使用到集合类型: List与Set。很多时候,我们可能会将它们视为同一种类型进行使用,但是在实际的编程逻辑中,它们之间是存在很大差别的。接下来我们就…...

MyBatis 实战指南:探索灵活持久化的艺术
文章目录 前言一、初识 MyBatis1.1 什么是 MyBatis1.2 为什么学习 MyBatis 二、MyBatis 在软件开发框架中的定位三、基于 Spring Boot 创建 MyBatis 项目3.1 添加 MyBatis 框架的支持3.2 配置数据库连接信息和映射文件的保存路径(Mapper XML) 四、MyBati…...

5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能
5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 想要在没有物理显示器的情况下畅享4K游…...
)
手把手教你用Verilog在FPGA上实现Sobel边缘检测(附完整Matlab图片转TXT流程)
从图像到硬件加速:FPGA实现Sobel边缘检测全流程实战指南 在计算机视觉领域,边缘检测作为基础预处理步骤,直接影响着后续特征提取和目标识别的精度。传统基于CPU的算法实现往往难以满足实时性要求,而FPGA凭借其并行计算能力和低延迟…...

ChatGPT对技术从业者的影响:机遇与挑战
在人工智能技术飞速发展的当下,ChatGPT这类大语言模型的横空出世,无疑在科技领域投下了一颗重磅炸弹。对于软件测试从业者而言,这既是一场前所未有的机遇,也是一次严峻的挑战。它不仅重塑了测试工作的模式与效率,更对从…...

2026降AI率工具红黑榜:降AIGC工具怎么选?照着用就行!
2026年论文降AI率工具竞争激烈,千笔AI、ThouPen、豆包凭借精准适配国内高校AI率检测规范成为红榜首选。黑榜需警惕低质免费工具、无正规检测对接、改写痕迹生硬的产品。选择时应综合考量(降AI效果 - 学术合规性 - 使用成本)三维模型ÿ…...

Tomcat 超精简总结
1. 定位轻量级 Java Web 服务器 / Servlet 容器只跑 Java 项目(jsp、servlet、springboot 内嵌)处理 动态请求,不擅长静态资源2. 核心作用解析 Servlet、JSP监听端口,接收浏览器请求调用 Java 代码执行业务返回页面 / 数据给客户端…...

给UR5e机械臂动力学建模做减法:一个简化模型在C++中的实现与验证
UR5e机械臂动力学建模的工程实践:从理论简化到C实现 在工业机器人领域,UR5e作为Universal Robots的经典协作机械臂,以其轻量化设计和安全性能广泛应用于装配、检测等场景。然而,当我们需要为其开发高级控制算法时,完整…...
)
Sora 2时间轴与Blender NLA编辑器深度对齐指南(2024.06.12 Blender官方补丁前最后兼容方案)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与Blender整合的底层架构演进 Sora 2并非独立运行的视频生成引擎,而是以模块化推理服务(Modular Inference Service, MIS)为核心构建的分布式计算框架。其与Bl…...

告别.osa!用PCL玩转ORB-SLAM3点云地图:保存、加载与二次开发实战
告别.osa!用PCL玩转ORB-SLAM3点云地图:保存、加载与二次开发实战 当ORB-SLAM3完成环境建图后,.osa格式的地图文件就像被锁在保险箱里的宝藏——虽然安全,却难以直接利用。本文将带你突破这一限制,通过PCL(P…...

深度解析Real-ESRGAN:6B轻量模型实现专业级图像超分辨率
深度解析Real-ESRGAN:6B轻量模型实现专业级图像超分辨率 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN Real-ESRGAN_…...

二层与三层交换机核心差异解析:从MAC地址到IP路由的实战指南
1. 项目概述:从“傻”到“聪明”的进化之路如果你刚接触网络设备,看到“二层交换机”和“三层交换机”这两个名词,可能会有点懵。它们长得都差不多,都是方方正正的铁盒子,前面板一堆网口,后面插着电源和风扇…...