Clickhouse 存储引擎
一、常用存储引擎分类
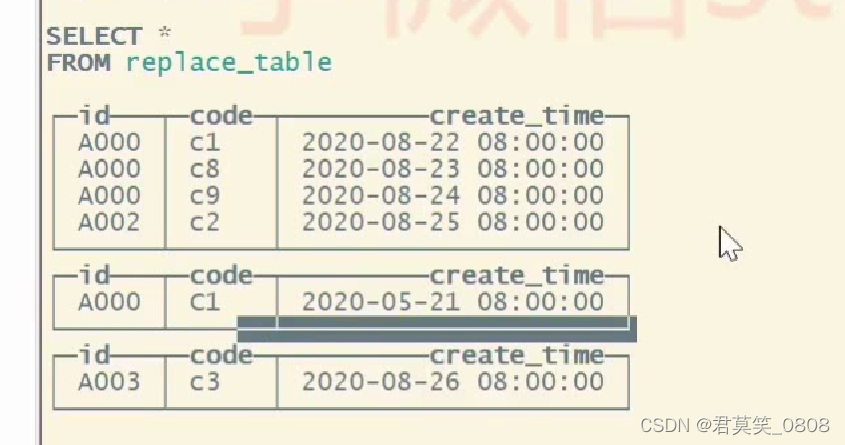
1.1 ReplacingMergeTree
这个引擎是在 MergeTree 的基础上,添加了”处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。
特点:
1使用ORDERBY排序键作为判断重复的唯一键
2.数据的去重只会在合并的过程中触发
3.以数据分区为单位删除重复数据,不同分区的的重复数据不会被删除
4找到重复数据的方式依赖数据已经ORDER BY排好序了
5.如果没有ver版本号,则保留重复数据的最后一行
6.如果设置了ver版本号,则保留重复数据中ver版本号最大的数据
1.2 建表语句示例
create table replace_table(
id string,
code String,
create_time DateTime
)ENGINE=RepTacingMergeTree() PARTITION BY toYYYYMM(create_time)ORDER BY (id,code) PRIMARY KEY id;
order by 数据做主键,进行数据去重,但是不同分区数据不会去重
1.2 SummingMergeTree
该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有有相同聚合数据的条件Key的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果聚合数据的条件Key的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加的列,会取一个最先出现的值。
特征:
1用DRDERBY排序键作为聚合数据的条件Key
2合并分区的时候触发汇总逻辑
3.以数据分区为单位聚合数据,不同分区的数据不会被汇总
4如果在定义引擎时指定了Columns汇总列(非主键)则SUM汇总这些字段
5.如果没有指定,则汇总所有非主键的数值类型字段
6.SUM汇总相同的聚合Key的数据,依赖ORDER BY排序
7.同一分区的SUM汇总过程中,非汇总字段的数据保留第一行取值8.支持嵌套结构,但列字段名称必须以Map后缀结束。
1.3 AggregateMergeTree
说明: 逻辑。 clickHouse 会将相同主键的所有行(在一个数据片该引擎继承自 MergeTree,并改变了数据片段的合并段内)替换为单个存储一系列聚合函数状态的行。
可以使用AggregatingMergeTree 表来做增量数据计聚合,包括物化视图的数据聚合引擎需使用AggregateFunction 类型来处理所有列
如果要按一组规则来合并减少行数,则使用AggregaingMergeTree 是合适的对于AggregatingMergeTree不能直接使用insert来查询写入数据。一般是用insert select。但更常用的是创建物化视图。
提前聚合数据,形成数据立方体,数据提前预处理聚合。
1.3.1 先创建一个MergeTree引擎的基表

1.3.2 创建一个AggregatingMergeTree的物化视图

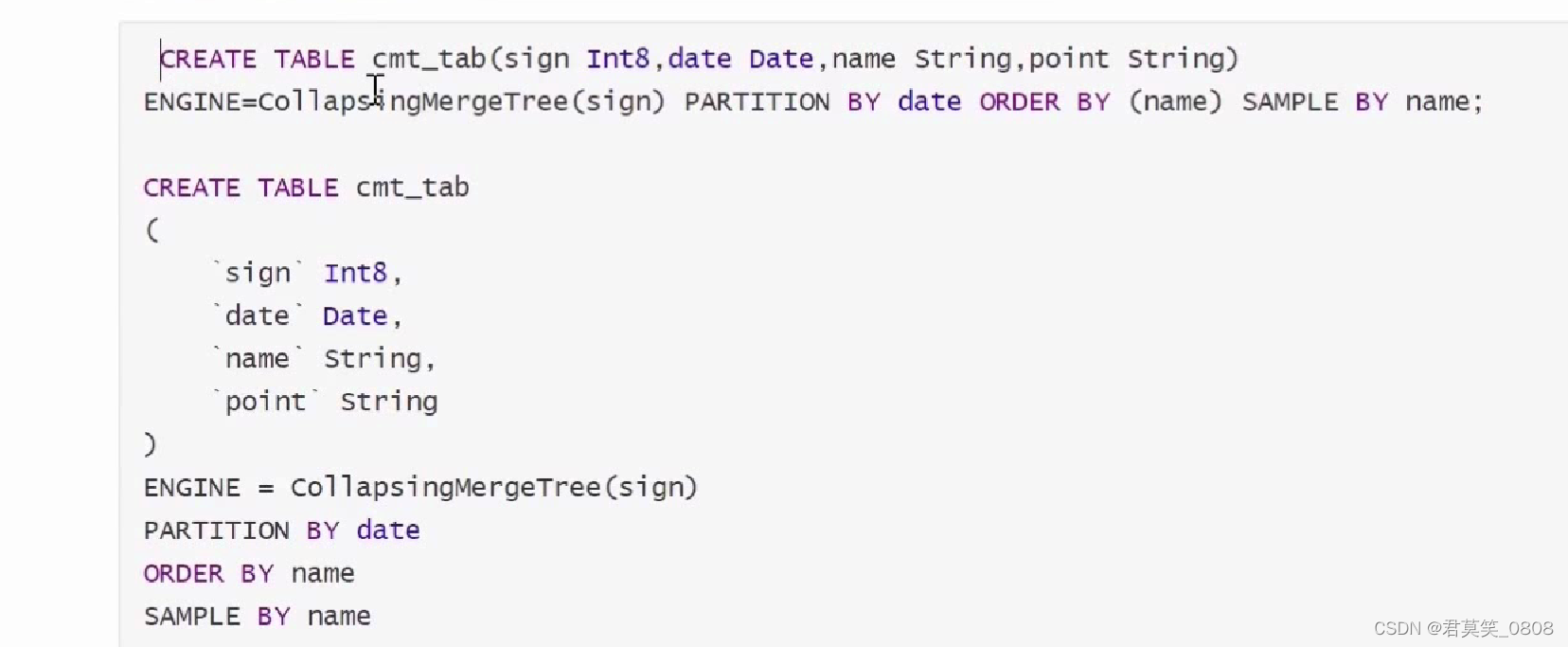
1.4 CollapsingMergeTree
以增代删
yandex官方给出的介绍是CollapsingMergeTree 会异步的除(折叠)这些除了特定列 ign有1和-1的值外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。该引擎可以显著的降低存储量并提高 SELEC查询效率。
CollapsingMergeTree引擎有个状态列sign,这个值1为”状态”行,1为”取消”行,对于数据只关心状态列为状的数据,不关心状态列为取消的数据。
1.5 VersionedCollapsingMergeTree
这个引擎和collapsingMergeTree差不多,只是对collapsingMergeTree引擎加了一个版本,比如可以适于非实时用户在线统计,统计每个节点用户在在线业务
CREATE TABLE [IF NOT EXISTS] [db,jtable_name [ON CLUSTER cluster]
name1 [type1][DEFAULTIMATERIALIZEDIALIAS expr1].name2 [type2][DEFAULTIMATERIALIZEDALIAS expr2]
ENGINE = VersionedCollapsingMergeTree(sign, version)IPARTITION BY expr)
[ORDER BY expr][SAMPLE BY expr]
[SETTINGS name=value, ...]
二、clickhouse 连接其他存储引擎
2.1 连接mysql
mysql建表语句

2.2 连接kafka
Kafka SETTINGS
kafka_broker_list = 'localhost:9092',
kafka_topic_list ='topic1,topic2',
kafka_group_name ='group1',
kafka format = 'JSONEachRow',
kafka_row_delimiter = '\n'
kafka_schema = '',
kafka num_consumers = 2
kafka引擎表写入后会删除,需要建一个物化视图
三、数据备份
分区写入数据后,写入数据记录到zk节点,被其他副本消费

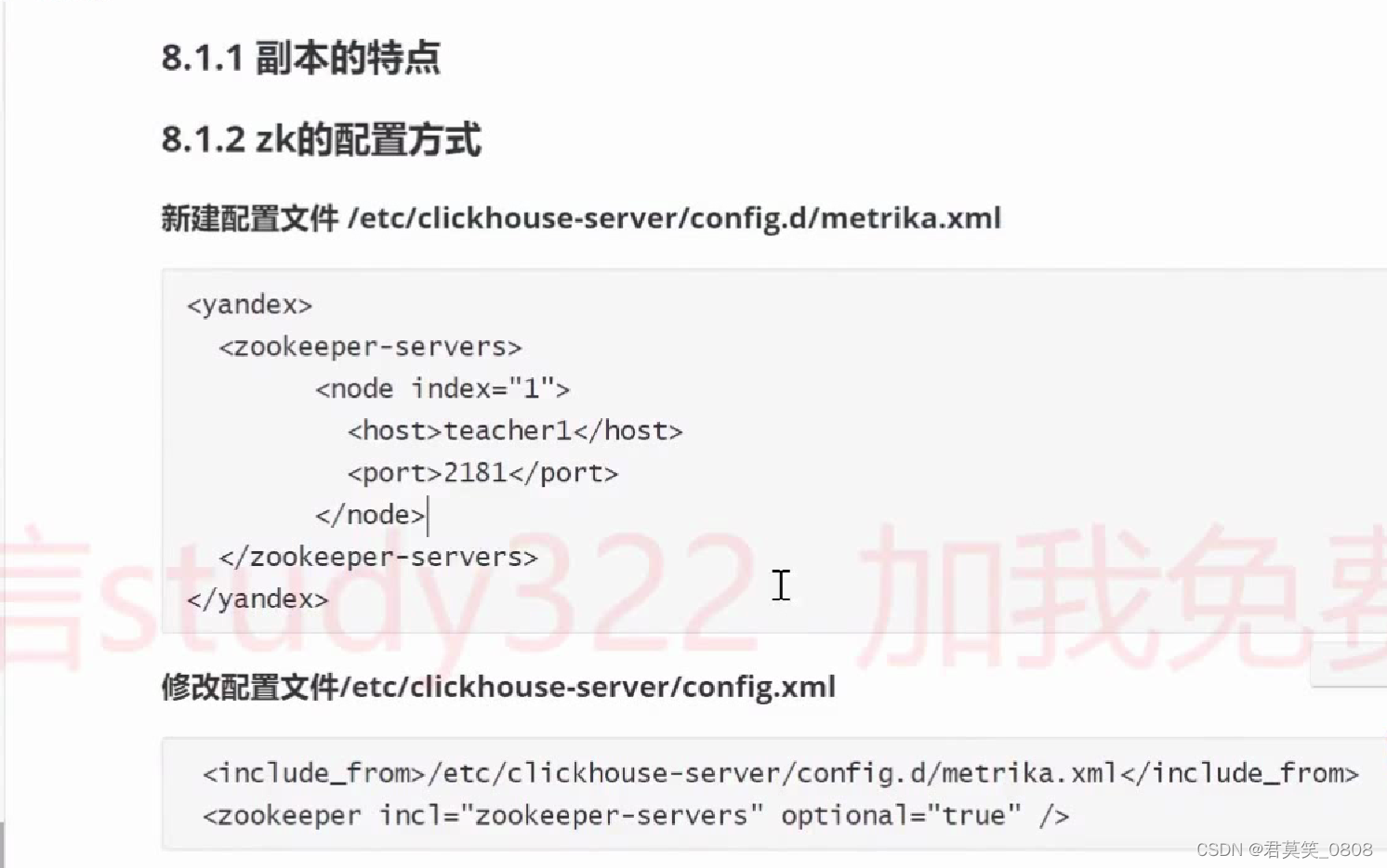

zk节点信息




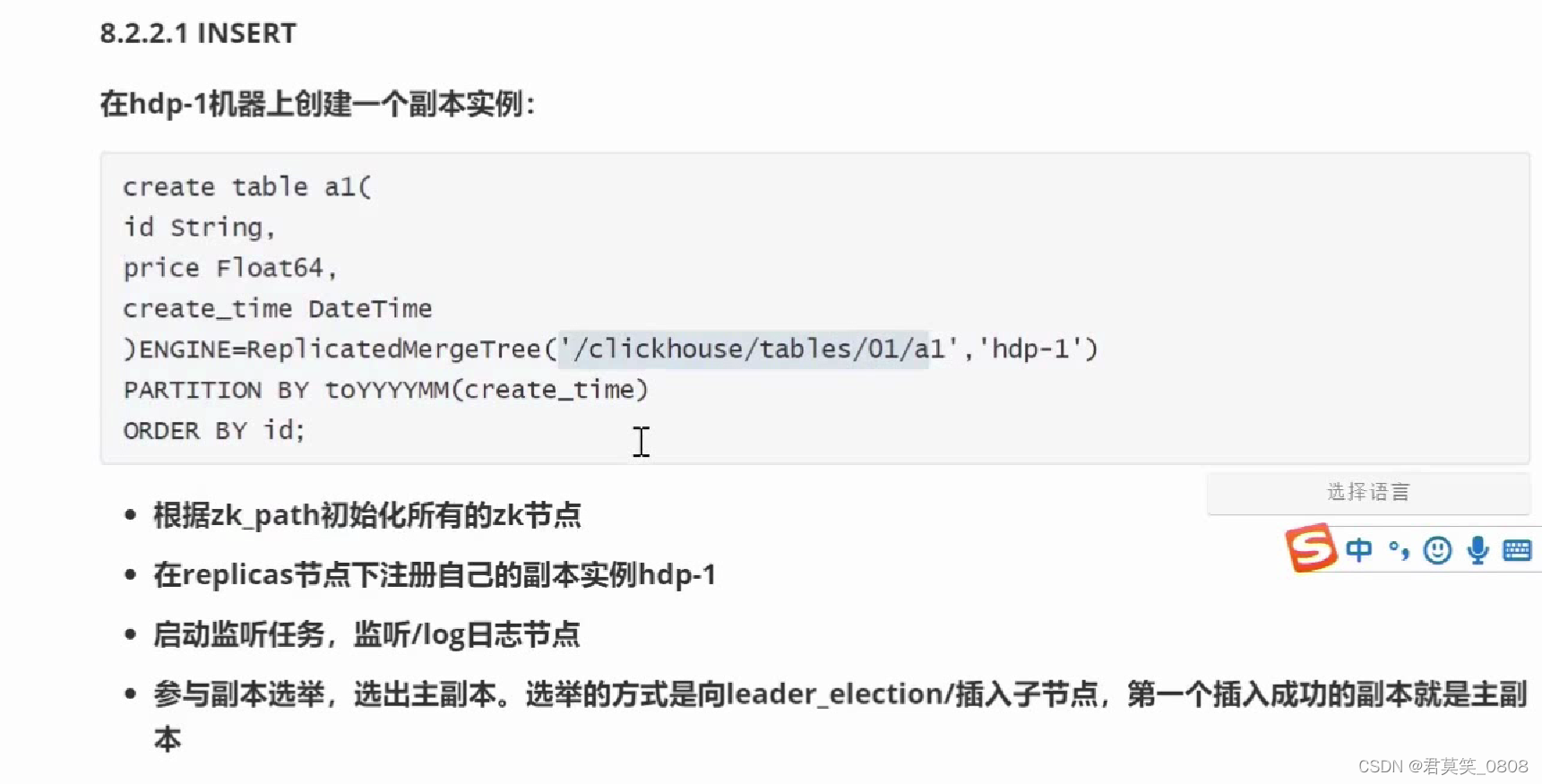

四、分布式表



相关文章:
Clickhouse 存储引擎
一、常用存储引擎分类 1.1 ReplacingMergeTree 这个引擎是在 MergeTree 的基础上,添加了”处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。 特点: 1使用ORDERBY排序键作为判断重复的唯一键 2.数据的去重只会在合并…...

基于golang多消息队列中间件的封装nsq,rabbitmq,kafka
基于golang多消息队列中间件的封装nsq,rabbitmq,kafka 场景 在创建个人的公共方法库中有这样一个需求,就是不同的项目会用到不同的消息队列中间件,我的思路把所有的消息队列中间件进行封装一个消息队列接口(MQer)有两个方法一个…...
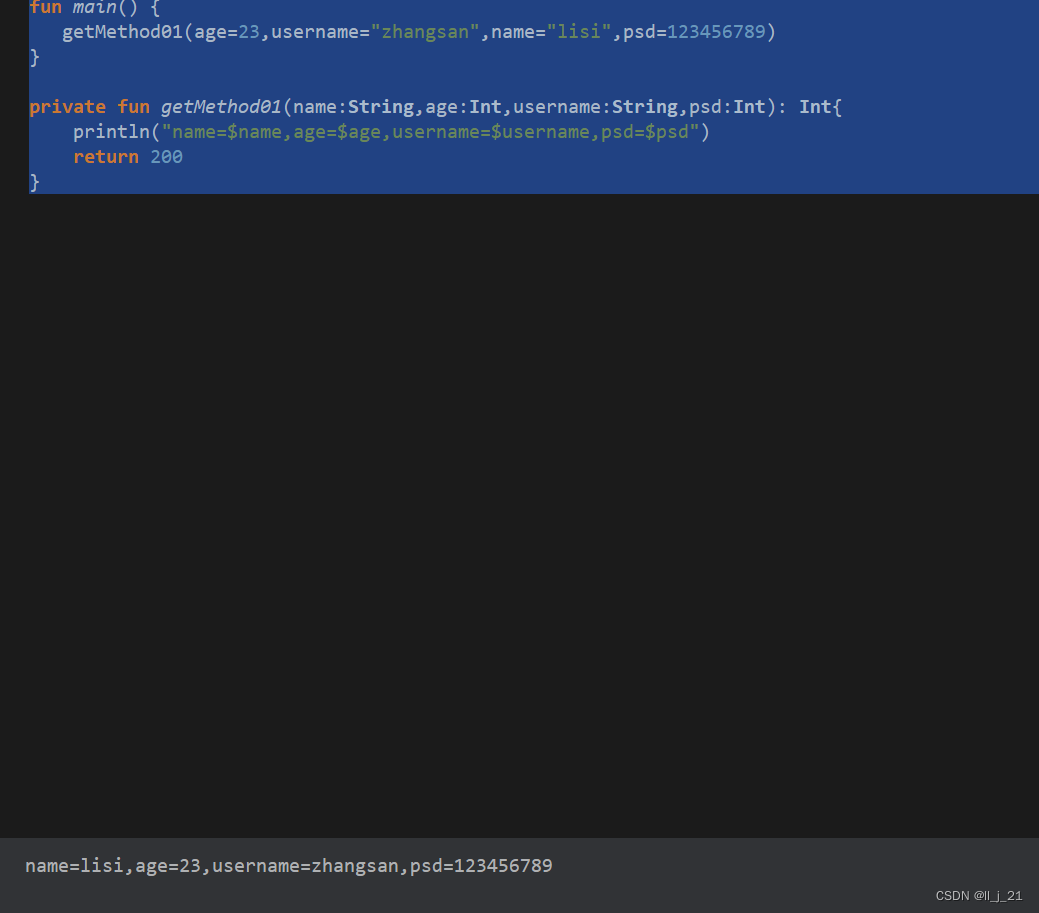
【第一阶段】kotlin的函数
函数头 fun main() {getMethod("zhangsan",22) }//kotlin语言默认是public,kotlin更规范,先有输入( getMethod(name:String,age:Int))再有输出(Int[返回值]) private fun getMethod(name:String,age:Int): Int{println("我叫…...

PAM安全配置-用户密码锁定策略
PAM是一个用于实现身份验证的模块化系统,可以在操作系统中的不同服务和应用程序中使用。 pam_faillock模块 pam_faillock模块用来实现账号锁定功能,它可以在一定的认证失败次数后锁定用户账号,防止暴力破解密码攻击。 常见选项 deny&…...

AndroidManifest.xml日常笔记
1 Bundle介绍 Bundle主要用于传递数据;它保存的数据,是以key-value(键值对)的形式存在的。 我们经常使用Bundle在Activity之间传递数据,传递的数据可以是boolean、byte、int、long、float、double、string等基本类型或它们对应的数组…...
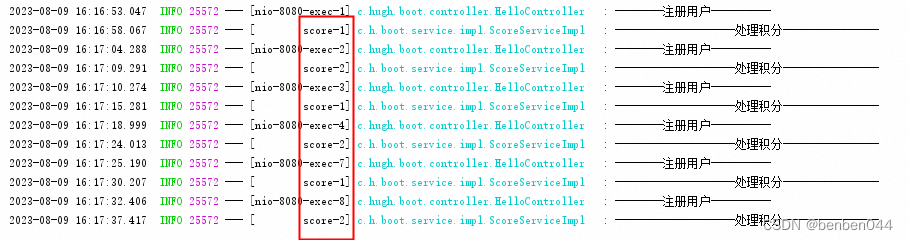
SpringBoot异步框架
参考:解剖SpringBoot异步线程池框架_哔哩哔哩_bilibili 1、 为什么要用异步框架,它解决什么问题? 在SpringBoot的日常开发中,一般都是同步调用的。但经常有特殊业务需要做异步来处理,例如:注册新用户&…...
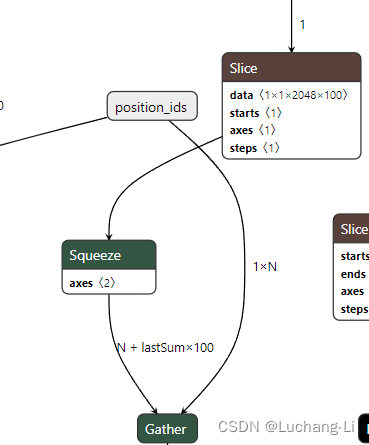
导出LLaMA ChatGlm2等LLM模型为onnx
通过onnx模型可以在支持onnx推理的推理引擎上进行推理,从而可以将LLM部署在更加广泛的平台上面。此外还可以具有避免pytorch依赖,获得更好的性能等优势。 这篇博客(大模型LLaMa及周边项目(二) - 知乎)进行…...

C++项目:在线五子棋对战网页版--匹配对战模块开发
玩家匹配是根据自己的天梯分数进行匹配的,而服务器中将玩家天梯分数分为三个档次: 1. 普通:天梯分数小于2000分 2. 高手:天梯分数介于2000~3000分之间 3. 大神:天梯分数大于3000分 当玩家进行对战匹配时,服…...
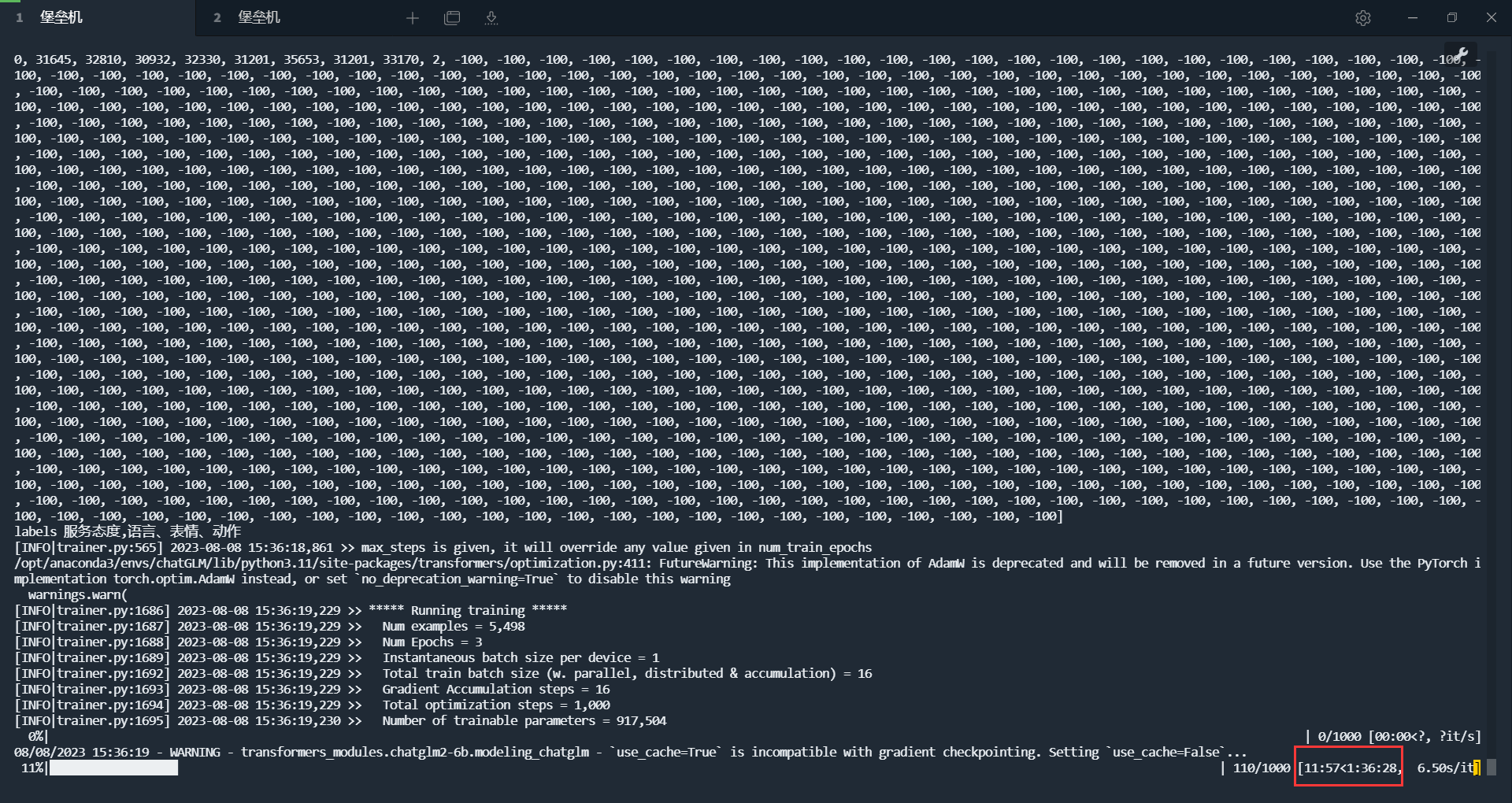
ssh 连接断开,正在执行的shell脚本也被中断了
背景 最近在训练chatGLM,一次训练经常要花掉近2个小时,但是由于网络不稳定,经常ssh莫名的断开,导致训练不得不重新开启,这就很浪费时间了 解决方案 下面教大家一种在后台执行命令的方案,即使你ssh连接断…...

UML 用例图,类图,时序图,活动图
UML之用例图,类图,时序图,活动图_用例图 时序图_siyan985的博客-CSDN博客 https://www.cnblogs.com/GumpYan/p/14734357.html 用例图与类图 - 简书...

Java 面试题2023
Java core JVM 1、JVM内存模型 2、JVM运行时内存分配 3、如何确定当前对象是个垃圾 4、GCrooot 包括哪些? 5、JVM对象头包含哪些部分 6、GC算法有哪些 7、JVM中类的加载机制 8、分代收集算法 9、JDK1.8 和 1.7做了哪些优化 10、内存泄漏和内存溢出有什么区别 11、J…...

【CSS3】CSS3 动画 ④ ( 使用动画制作地图热点图 )
文章目录 一、需求说明二、动画代码分析1、地图背景设置2、热点动画位置测量3、热点动画布局分析4、动画定义5、小圆点实现6、波纹效果盒子实现7、延迟动画设置 三、代码示例 一、需求说明 实现如下效果 , 在一张地图上 , 以某个位置为中心点 , 向四周发散 ; 核心 是实现 向四周…...
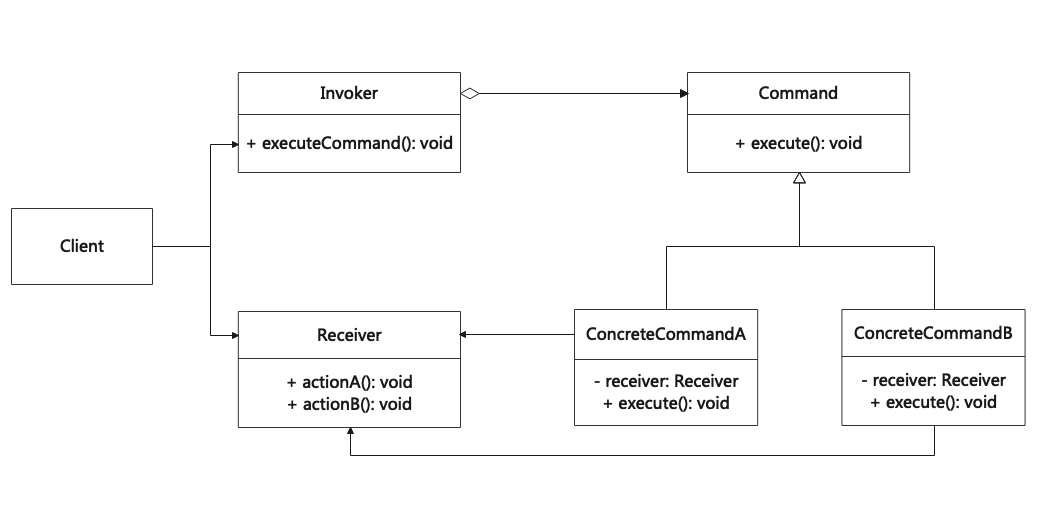
命令模式(Command)
命令模式是一种行为设计模式,可将一个请求封装为一个对象,用不同的请求将方法参数化,从而实现延迟请求执行或将其放入队列中或记录请求日志,以及支持可撤销操作。其别名为动作(Action)模式或事务(Transaction)模式。 Command is …...

Dapper 微型orm的光
介绍 Dapper是一个轻量级的ORM(对象关系映射)框架,它可以方便地将数据库查询结果映射到.NET对象上,同时也支持执行原生SQL查询。下面我将详细介绍Dapper的使用方法。 安装Dapper 首先,你需要通过NuGet包管理器将Dap…...

Mysql随心记--第一篇
MylSAM:查询速度快,有较好的索引优化和数据压缩技术,但是它不支持事务 InnoDB:它支持事务,并且提供行级的锁定,应用也相当广泛 docker ps -a --filter "ancestormysql" 查看linux中创建了多少个d…...

使用dockerfile安装各种服务组件
使用dockerfile安装各种服务组件 elasticsearch、minio、mongodb、nacos、redis 一、使用dockerfile安装elasticsearch:7.8.0 1、Dockerfile文件 FROM elasticsearch:7.8.0 #添加分词器 ADD elasticsearch-analysis-ik /usr/share/elasticsearch/plugins/elasticsearch-anal…...

如何简单的无人直播
环境搭建 ffmpeg安装,我这里用的是centos搭建的,其他平台可以自己百度 yum -y install wgetwget --no-check-certificate https://www.johnvansickle.com/ffmpeg/old-releases/ffmpeg-4.0.3-64bit-static.tar.xztar -xJf ffmpeg-4.0.3-64bit-static.ta…...

【基于HBase和ElasticSearch构建大数据实时检索项目】
基于HBase和ElasticSearch构建大数据实时检索项目 一、项目说明二、环境搭建三、编写程序四、测试流程 一、项目说明 利用HBase存储海量数据,解决海量数据存储和实时更新查询的问题;利用ElasticSearch作为HBase索引,加快大数据集中实时查询数…...
ProComponent 用法学习
相信很多同学都用过 Ant Design 这一 react 著名组件库,而 ProComponents 则是在 antd 之上进行封装的页面级组件库(指一个组件就可以搞定一个页面)。它同时也是 Ant Design Pro 中后台框架所用的主要组件库。如果你手上有要用 react 开发的中…...

巨人互动|Google海外户Google Analytics的优缺点是什么?
Google Analytics是一个由谷歌开发的网站分析工具,旨在帮助网站和移动应用程序运营者收集和分析数据,以更好地了解用户行为和改进业务。虽然Google Analytics具有许多优势,但也存在一些缺点。在本文中,我们将探讨Google Analytics…...

如何在Windows 11上轻松安装Android应用?APK安装器完整教程
如何在Windows 11上轻松安装Android应用?APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行Android应用却不想安装笨…...

AMD游戏本ChinaJoy三连发:从3D V-Cache到性价比旗舰的全面解析
1. 项目概述:ChinaJoy 2023上的AMD游戏本盛宴每年ChinaJoy不仅是游戏玩家的狂欢,更是硬件厂商展示肌肉的舞台。今年,这个舞台的主角无疑是AMD。当大家还在讨论移动端处理器核心数大战时,AMD直接甩出了“缓存为王”的王炸ÿ…...

华硕笔记本性能优化神器:3步掌握G-Helper轻量级控制中心
华硕笔记本性能优化神器:3步掌握G-Helper轻量级控制中心 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, …...
)
从USB2.0到USB3.0:硬件工程师必须知道的电源管理与布线升级要点(含电平转换案例)
从USB2.0到USB3.0:硬件工程师必须掌握的电源管理与布线升级实战指南 在硬件设计领域,接口技术的迭代往往带来性能的飞跃,但同时也伴随着设计复杂度的显著提升。USB3.0作为当前主流的高速接口标准,其传输速率相比USB2.0提升了近10倍…...
到底怎么选?)
IPv6网络规划必看:华为设备上DHCPv6与SLAAC(无状态地址分配)到底怎么选?
IPv6网络规划实战:华为设备地址分配方案深度解析 在IPv6网络部署的浪潮中,地址分配策略的选择往往成为困扰网络架构师的首要难题。当传统IPv4的DHCP方式遇上IPv6全新的SLAAC(无状态地址自动配置)机制,技术决策的复杂性…...

为什么天下工厂能直接给到工厂老板 / 厂长手机号
做工业品销售的人都有过这种经历:在网上查到了一家目标工厂,拨过去,接电话的是前台。“您好,请问有什么事?” “我想找一下您们老板。” “老板不在,您要不要留个电话?” 电话留了,没…...

VSLAM与VIO技术解析:从3D建图到重定位的工程实践
1. 项目概述:从传感器融合到环境认知的跨越在机器人、自动驾驶和增强现实这些前沿领域,让机器“看见”并“理解”它所处的三维世界,是赋予其自主行动能力的基石。这背后,视觉SLAM(Simultaneous Localization and Mappi…...

百度网盘Mac版SVIP破解终极指南:三步解锁高速下载限制
百度网盘Mac版SVIP破解终极指南:三步解锁高速下载限制 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的龟速下载而烦恼…...
与0x28通信控制服务:搞懂主从节点,精准控制子总线流量)
AutoSar网络管理(NM)与0x28通信控制服务:搞懂主从节点,精准控制子总线流量
AutoSar网络管理中0x28服务的拓扑控制艺术:主从架构与子总线流量精准调度 在车载电子系统日益复杂的今天,一条CAN总线上可能挂着十几个ECU节点,而网关则需要管理多条这样的总线。想象一下,当某个子总线上的节点需要软件更新时&…...

极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍
极域电子教室破解指南:3分钟重获电脑自主权,学习效率翻倍 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在机房上课时,面对老师全屏广…...