基于Selenium模块实现无界面模式 执行JS脚本
此篇文章主要介绍如何使用 Selenium 模块实现 无界面模式 & 执行JS脚本(把滚动条拉到底部),并以具体的示例进行展示。
1、Selenium 设置无界面模式
创建浏览器对象之前,创建 options 功能对象 :options = webdriver.ChromeOptions()
添加无界面功能参数:options.add_argument("--headless")
构造浏览器对象,打开浏览器,并设置 options 参数:
browser = webdriver.Chrome(options=options)
from selenium import webdriver
options = webdriver.ChromeOptions() # 创建浏览器对象之前,创建options功能对象
options.add_argument("--headless") # 添加无界面功能参数
browser = webdriver.Chrome(options=options) # 构造浏览器对象,打开浏览器
2、Selenium 执行JS脚本
创建浏览器对象:browser = webdriver.Chrome()
执行JS脚本:browser.execute_script()
最常用脚本 - 把滚动条拉到底部:browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
from selenium import webdriver
browser = webdriver.Chrome() # 创建浏览器对象
browser.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'
) # 把滚动条拉到最底部
3、Selenium 设置无界面模式 & 执行JS脚本 案例
3.1 需求分析
基于 Selenium + Chrome 抓取 `http://www.jd.com/` 下 “python书籍” 的信息
3.2 爬虫思路
打开浏览器输入主页地址:https://www.jd.com/
使用 Selenium 的 Xpath 找到 信息输入框 和 点击搜索 节点:'//*[@id="key"]' & '//*[@id="search"]/div/div[2]/button'
输入 “python书籍” 并点击 点击搜索按钮;
使用 Selenium 的 Xpath 找到 书籍信息 节点对象列表: '//*[@id="J_goodsList"]/ul/li';
依次遍历每个元素,并依次提取每本书籍信息;
爬取完一页信息后,需要判断是否是最后一页
可以看到:
最后一页的节点信息为:pn-next disabled
非最后一页的节点信息为:pn-next
如果不是最后一页,点击下一页继续进行爬取:'//*[@id="J_bottomPage"]/span[1]/a[9]'
3.3 程序实现
初始化函数
def __init__(self):
# 设置为无界面
self.options = webdriver.ChromeOptions() # 创建浏览器对象之前,创建options功能对象
self.options.add_argument('--headless') # 添加无界面功能参数
self.driver = webdriver.Chrome(options=self.options) # 构造浏览器对象,打开浏览器
self.driver.get(url="http://www.jd.com/") # 进入主页
# 搜索框发送:python书籍,点击搜索按钮
self.inputJD = self.driver.find_element(By.XPATH, '//*[@id="key"]') # 搜索框xpath://*[@id="key"]
self.inputJD.send_keys("python书籍")
self.driver.find_element(By.XPATH,
'//*[@id="search"]/div/div[2]/button').click() # 搜索按钮xpath://*[@id="search"]/div/div[2]/button 并点击
time.sleep(1) # 要给页面元素加载预留时间
提取数据函数
def parse_html(self):
"""
function: 具体提取数据方法
in: None
out: None
return: None
others: Data Extraction Func
"""
self.driver.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'
) # 先把滚动条拉到最底部,等待所有商品加载完成再进行数据爬取
time.sleep(3) # 给页面元素加载预留时间
# 具体提取数据
li_list = self.driver.find_elements(By.XPATH,
'//*[@id="J_goodsList"]/ul/li') # 基准xpath://*[@id="J_goodsList"]/ul/li 每一个商品对应一个li节点
item = {} # 定义一个空字典
for li in li_list:
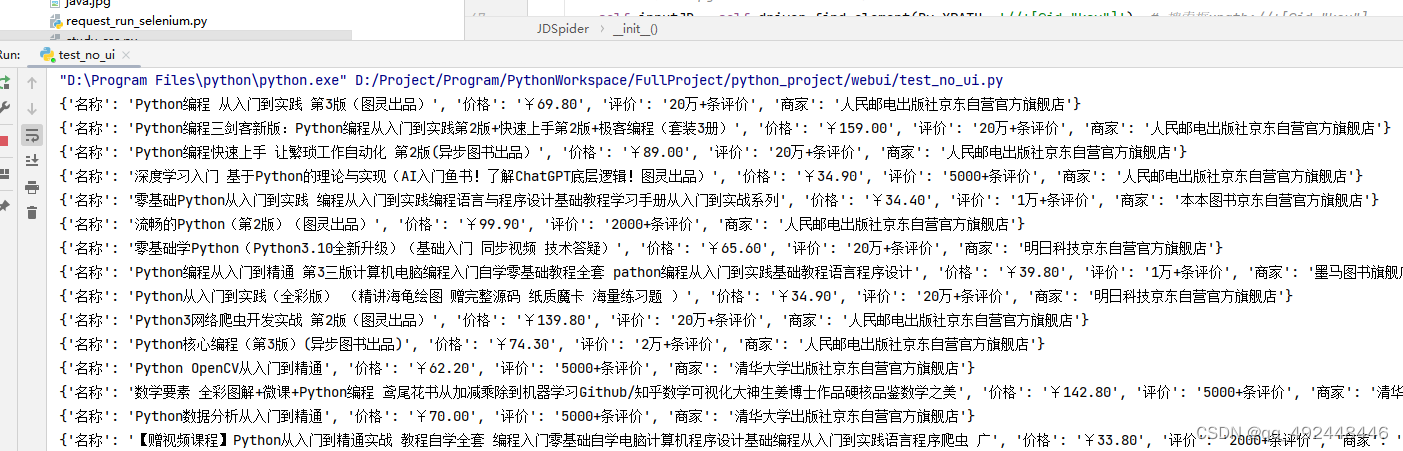
item["名称"] = li.find_element(By.XPATH, './/div[@class="p-name"]/a/em').text.strip()
item["价格"] = li.find_element(By.XPATH, './/div[@class="p-price"]/strong').text.strip()
item["评价"] = li.find_element(By.XPATH, './/div[@class="p-commit"]/strong').text.strip()
item["商家"] = li.find_element(By.XPATH, './/div[@class="p-shopnum"]').text.strip()
print(item) # 打印
程序入口函数
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
while True:
self.parse_html()
# 不是最后一页:pn-next
# 最后一页:pn-next disabled
if self.driver.page_source.find("pn-next disabled") == -1: # 没有找到 pn-next disabled,说明不是最后一页
self.driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]').click()
time.sleep(1)
else:
self.driver.quit()
break
3.4 完整代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class JDSpider:
def __init__(self):
# 设置为无界面
self.options = webdriver.ChromeOptions() # 创建浏览器对象之前,创建options功能对象
self.options.add_argument('--headless') # 添加无界面功能参数
self.driver = webdriver.Chrome(options=self.options) # 构造浏览器对象,打开浏览器
self.driver.get(url="http://www.jd.com/") # 进入主页
# 搜索框发送:python书籍,点击搜索按钮
self.inputJD = self.driver.find_element(By.XPATH, '//*[@id="key"]') # 搜索框xpath://*[@id="key"]
self.inputJD.send_keys("python书籍")
self.driver.find_element(By.XPATH,
'//*[@id="search"]/div/div[2]/button').click() # 搜索按钮xpath://*[@id="search"]/div/div[2]/button 并点击
time.sleep(1) # 要给页面元素加载预留时间
def parse_html(self):
"""
function: 具体提取数据方法
in: None
out: None
return: None
others: Data Extraction Func
"""
self.driver.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'
) # 先把滚动条拉到最底部,等待所有商品加载完成再进行数据爬取
time.sleep(3) # 给页面元素加载预留时间
# 具体提取数据
li_list = self.driver.find_elements(By.XPATH,
'//*[@id="J_goodsList"]/ul/li') # 基准xpath://*[@id="J_goodsList"]/ul/li 每一个商品对应一个li节点
item = {} # 定义一个空字典
for li in li_list:
item["名称"] = li.find_element(By.XPATH, './/div[@class="p-name"]/a/em').text.strip()
item["价格"] = li.find_element(By.XPATH, './/div[@class="p-price"]/strong').text.strip()
item["评价"] = li.find_element(By.XPATH, './/div[@class="p-commit"]/strong').text.strip()
item["商家"] = li.find_element(By.XPATH, './/div[@class="p-shopnum"]').text.strip()
print(item) # 打印
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
while True:
self.parse_html()
# 不是最后一页:pn-next
# 最后一页:pn-next disabled
if self.driver.page_source.find("pn-next disabled") == -1: # 没有找到 pn-next disabled,说明不是最后一页
self.driver.find_element(By.XPATH, '//*[@id="J_bottomPage"]/span[1]/a[9]').click()
time.sleep(1)
else:
self.driver.quit()
break
if __name__ == '__main__':
spider = JDSpider()
spider.run()
3.5 实现效果
相关文章:
基于Selenium模块实现无界面模式 执行JS脚本
此篇文章主要介绍如何使用 Selenium 模块实现 无界面模式 & 执行JS脚本(把滚动条拉到底部),并以具体的示例进行展示。 1、Selenium 设置无界面模式 创建浏览器对象之前,创建 options 功能对象 :options webdriver.ChromeOptions() 添加…...
【LangChain学习】基于PDF文档构建问答知识库(二)创建项目
这里我们使用到 fastapi 作为项目的web框架,它是一个快速(高性能)的 web 框架,上手简单。 一.创建 FastAPI 项目 我们在IDE中,左侧选择 FastAPI ,右侧选择创建一个新的虚拟环境。 创建成功,会有…...

【Kubernetes】Kubernetes之kubectl详解
kubectl 一、陈述式资源管理1. 陈述式资源管理方法2. 基本信息查看3. 项目周期管理3.1 创建 kubectl create 命令3.2 发布 kubectl expose命令3.3 更新 kubectl set3.4 回滚 kubectl rollout3.5 删除 kubectl delete 4. kubectl 的发布策略4.1 蓝绿发布4.2 红黑发布4.3 灰度发布…...

【torch.nn.PixelShuffle】和 【torch.nn.UnpixelShuffle】
文章目录 torch.nn.PixelShuffle直观解释官方文档 torch.nn.PixelUnshuffle直观解释官方文档 torch.nn.PixelShuffle 直观解释 PixelShuffle是一种上采样方法,它将形状为 ( ∗ , C r 2 , H , W ) (∗, C\times r^2, H, W) (∗,Cr2,H,W)的张量重新排列转换为形状为…...

Rocky9 KVM网桥的配置
KVM的默认网络模式为NAT,借助宿主机模式上网,现在我们来改成桥接模式,这样外界就可以直接和宿主机里的虚拟机通讯了。 Bridge方式即虚拟网桥的网络连接方式,是客户机和子网里面的机器能够互相通信。可以使虚拟机成为网络中具有独立IP的主机。 桥接网络(也叫物理设备共享…...

爬虫013_函数的定义_调用_参数_返回值_局部变量_全局变量---python工作笔记032
然后再来看函数,可以避免重复代码 可以看到定义函数以及调用函数...
将.doc文档的默认打开方式从WPS修改为word office打开方式的具体方法(以win 10 操作系统为例)
将.doc文档的默认打开方式从WPS修改为word office打开方式的具体方法(以win 10 操作系统为例) 随着近几年WPS软件的不断完善和丰富,在某些方面取得了具有特色的优势。在平时编辑.doc文档时候也常常用到wps软件,不过WPS文献也存在…...
如何搭建个人的GPT网页服务
写在前面 在创建个人的 GPT网页之前,我登录了 Git 并尝试了一些开源项目,但是没有找到满足我个性化需求的设计。虽然许多收费的 GPT网页提供了一些免费额度,足够我使用,但是公司的安全策略会屏蔽这些网页。因此,我决定…...

[QCM6125][Android13] 默认关闭SELinux权限
文章目录 开发平台基本信息问题描述解决方法 开发平台基本信息 芯片: QCM6125 版本: Android 13 kernel: msm-4.14 问题描述 正常智能硬件设备源码开发,到手的第一件事就是默认关闭SELinux权限,这样能够更加方便于调试功能。 解决方法 --- a/QSSI.1…...

【jvm】jvm发展历程
目录 一、Sun Classic VM二、Exact VM三、HotSpot VM四、JRockit五、J9六、KVM、CDC、CLDC七、Azul VM八、Liquid VM九、Apache Harmony十、Microsoft JVM十一、Taobao JVM十二、Dalvik VM 一、Sun Classic VM 1.1996年java1.0版本,sun公司发布了sun classic vm虚拟…...
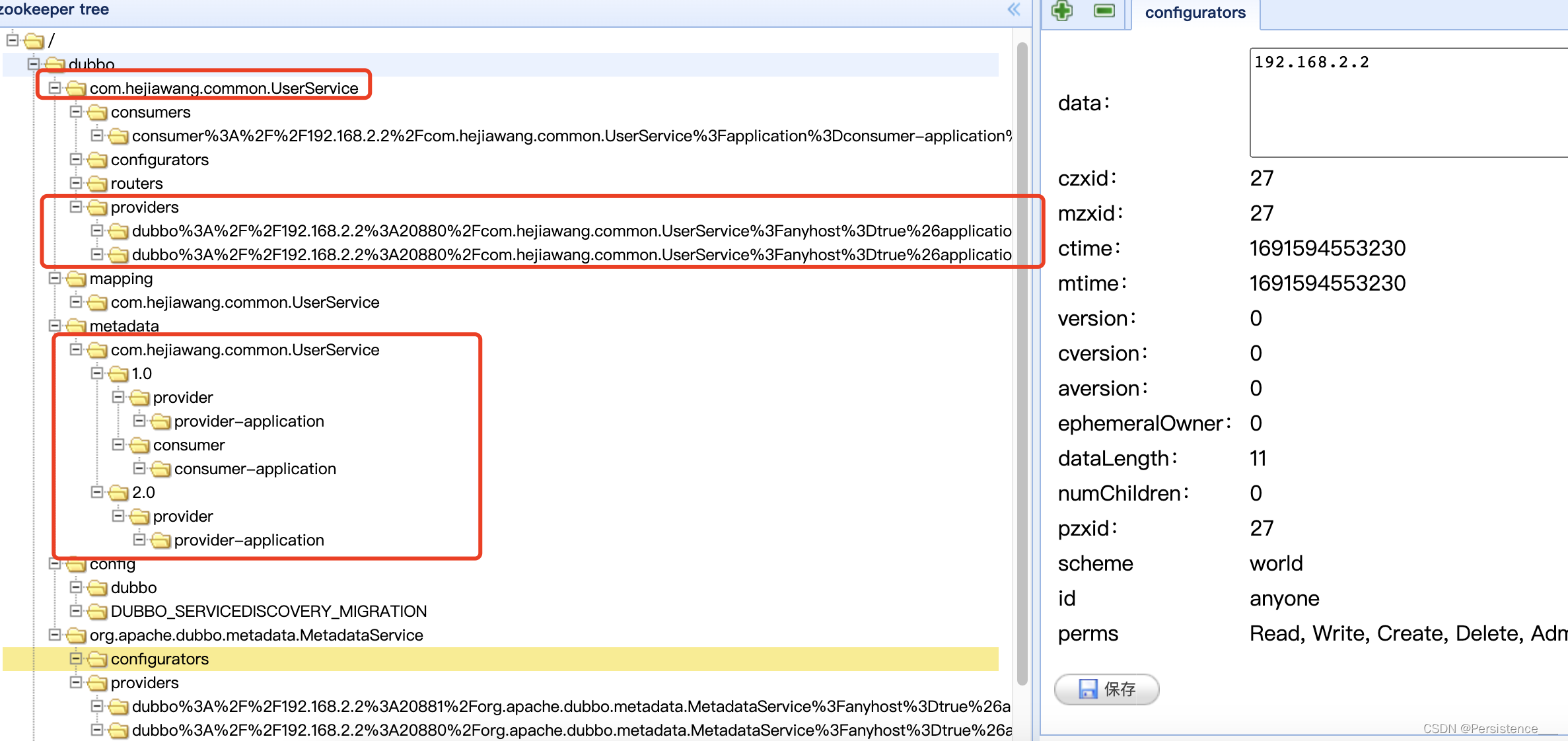
Dubbo3.0 Demo
将SpringBoot工程集成Dubbo 1.创建父工程 2.创建子工程consumer,provider 3.初始化工程 4.引入依赖 在provider和consumer中引入dubbo依赖 <dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo-spring-boot-starter</a…...
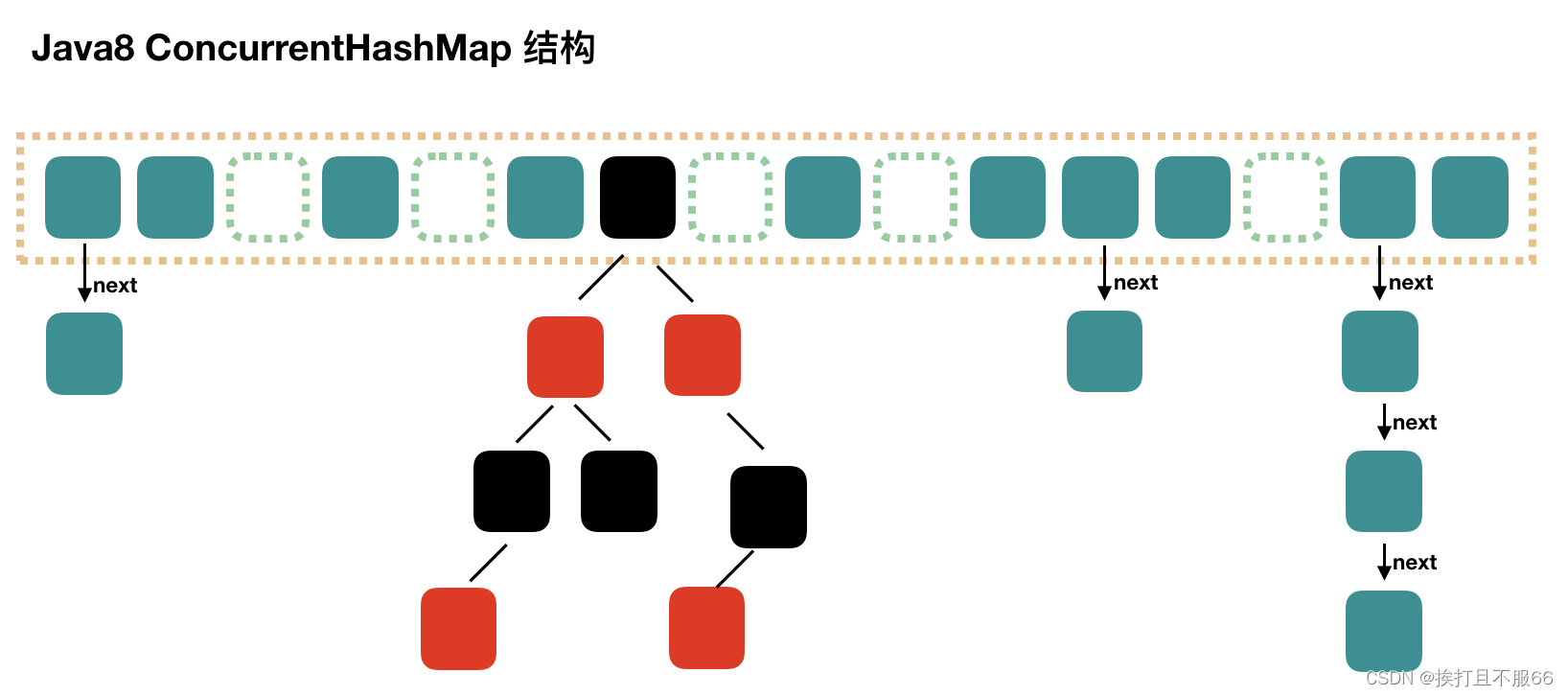
源码分析——ConcurrentHashMap源码+底层数据结构分析
文章目录 1. ConcurrentHashMap 1.71. 存储结构2. 初始化3. put4. 扩容 rehash5. get 2. ConcurrentHashMap 1.81. 存储结构2. 初始化 initTable3. put4. get 3. 总结 1. ConcurrentHashMap 1.7 1. 存储结构 Java 7 中 ConcurrentHashMap 的存储结构如上图,Concurr…...

R语言中的函数25:paste,paste0
文章目录 介绍paste0()实例 paste()实例 介绍 paste0()和paste()函数都可以实现对字符串的连接,paste0是paste的简化版。 paste0() paste (..., sep " ", collapse NULL, recycle0 FALSE)… one or more R objects, to be converted to character …...

(八)穿越多媒体奇境:探索Streamlit的图像、音频与视频魔法
文章目录 1 前言2 st.image:嵌入图像内容2.1 图像展示与描述2.2 调整图像尺寸2.3 使用本地文件或URL 3 st.audio:嵌入音频内容3.1 播放音频文件3.2 生成音频数据播放 4 st.video:嵌入视频内容4.1 播放视频文件4.2 嵌入在线视频 5 结语&#x…...
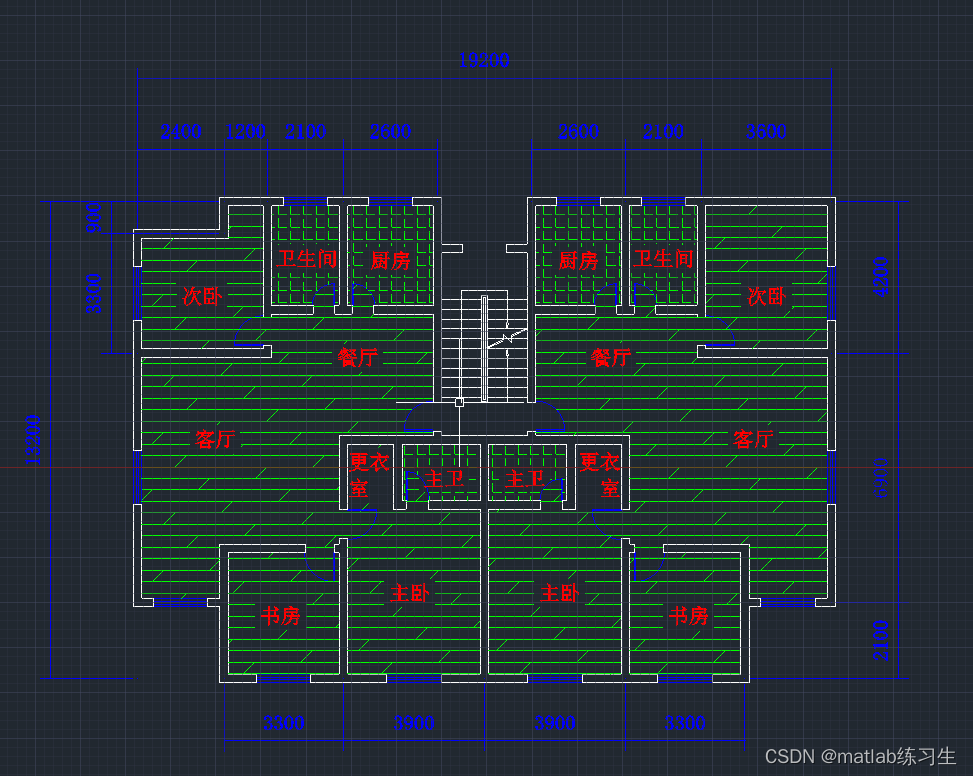
CAD练习——绘制房子平面图
首先还是需要设置图层、标注、文字等 XL:构造线 用构造线勾勒大致的轮廓: 使用多线命令:ML 绘制墙壁 可以看到有很多交叉点的位置 用多线编辑工具将交叉点处理 有一部分处理不了的,先讲多线分解,然后用修剪打理&…...
spring 面试题
一、Spring面试题 专题部分 1.1、什么是spring? Spring是一个轻量级Java开发框架,最早有Rod Johnson创建,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题。它是一个分层的JavaSE/JavaEE full-stack(一站式)轻量…...
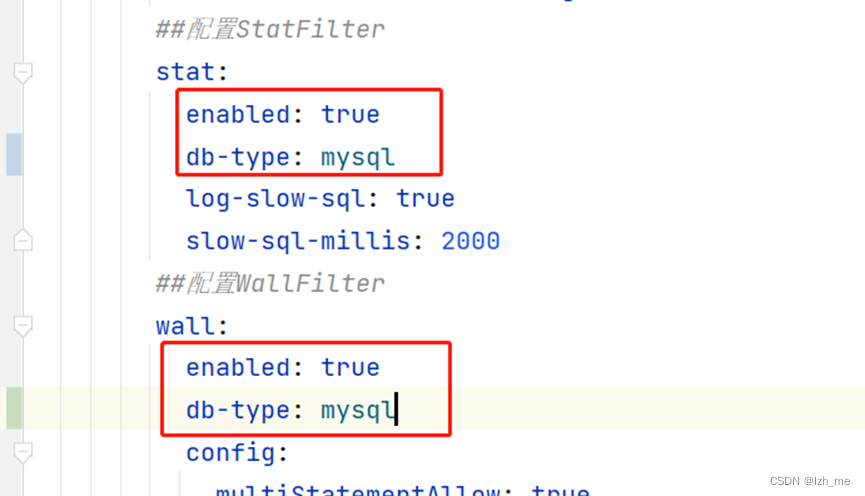
Springboot项目集成Durid数据源和P6Spy以及dbType not support问题
项目开发阶段,mybatis的SQL打印有占位符,调试起来还是有点麻烦,随想整合P6Spy打印可以直接执行的SQL,方便调试,用的Durid连接池。 Springboot项目集成Durid <dependency><groupId>com.alibaba</group…...
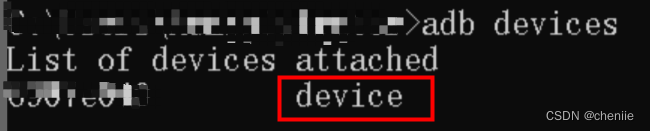
安卓如何卸载应用
卸载系统应用 首先需要打开手机的开发者选项,启动usb调试。 第二步需要在电脑上安装adb命令,喜欢的话还可以将它加入系统path。如果不知道怎么安装,可以从这里下载免安装版本。 第三步将手机与电脑用数据线连接,注意是数据线&a…...

【云原生|Kubernetes】14-DaemonSet资源控制器详解
【云原生|Kubernetes】14-DaemonSet资源控制器详解 文章目录 【云原生|Kubernetes】14-DaemonSet资源控制器详解简介典型用法DaemonSet语法规则Pod模板Pod 选择算符在选定的节点上运行 Pod DaemonSet的 Pods 是如何被调度的污点和容忍度DaemonSet更新和回滚DaemonSet更新策略执…...

基于 Guava Retry 在Spring封装一个重试功能
pom依赖 <dependency><groupId>com.github.rholder</groupId><artifactId>guava-retrying</artifactId><version>2.0.0</version> </dependency> <dependency><groupId>org.springframework.boot</groupId>…...

新手必看:UDOP-large文档理解模型从部署到实战全流程
新手必看:UDOP-large文档理解模型从部署到实战全流程 1. 引言:文档理解的新选择 在数字化办公时代,我们每天都要处理大量文档——论文、合同、发票、报告...传统的人工处理方式不仅效率低下,还容易出错。想象一下,如…...

从‘单向导电’到‘电流引导’:重新理解GPIO保护二极管的真实工作模式
从‘单向导电’到‘电流引导’:重新理解GPIO保护二极管的真实工作模式 在嵌入式硬件设计中,GPIO保护二极管常被简化为"防反接开关"的角色,这种认知掩盖了其作为动态电流路径选择器的本质。当我们用阻抗网络和分流原理重新审视这个经…...

从OBD到UDS:一文搞懂ISO14229 0x19服务中排放与非排放DTC的查询差异与实战
从OBD到UDS:深度解析ISO14229 0x19服务中排放与非排放DTC的差异化处理 在汽车电子控制单元(ECU)的开发与测试中,诊断故障码(DTC)的管理一直是工程师面临的核心挑战之一。特别是随着全球排放法规的日益严格&…...

如何用P 21 软件产生define.xml
XML是描述在临床试验过程中收集的数据的结构和内容的文档。虽然临床研究的元数据的定义可能不是最难创建的交付物,但是将这些规范转换为XML文件就是一件比较令人畏惧的经历了,下面我介绍下我做这个文档的一点点经验: XML包含FDA提交数据集的元…...

YimMenu终极指南:5步掌握GTA5最强免费防崩溃辅助工具
YimMenu终极指南:5步掌握GTA5最强免费防崩溃辅助工具 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...

VibeVoice语音助手搭建教程:支持10分钟长文本,会议纪要秒变语音
VibeVoice语音助手搭建教程:支持10分钟长文本,会议纪要秒变语音 你有没有过这样的经历?深夜加班整理完一份长达十几页的会议纪要,领导突然发来消息:“小王,把会议重点录个语音版,明早发给团队。…...

终极Resemble.js图像分析指南:从基础API到高级功能详解
终极Resemble.js图像分析指南:从基础API到高级功能详解 【免费下载链接】Resemble.js Image analysis and comparison 项目地址: https://gitcode.com/gh_mirrors/re/Resemble.js Resemble.js是一款强大的图像分析与比较工具,能够帮助开发者轻松实…...

春联生成模型-中文-base应用案例:家庭布置、店铺营销、内容创作全搞定
春联生成模型-中文-base应用案例:家庭布置、店铺营销、内容创作全搞定 1. 春联生成模型能为你做什么? 春节贴春联是中国传统文化的重要组成部分,一副好的春联既要讲究对仗工整,又要蕴含美好寓意。但对于大多数人来说,…...

如何使用 .NET MAUI 构建 iOS 小部件礁
一、环境准备 Free Spire.Doc for Python 是免费 Python 文档处理库,无需依赖 Microsoft Word,支持 Word 文档的创建、编辑、转换等操作,其中内置的 Markdown 解析能力,能高效实现 Markdown 到 Doc/Docx 格式的转换,且…...

避坑指南:VS2022安装的NuGet包在Unity里不识别?3种解决方案实测
深度解析:Unity与VS2022中NuGet包兼容性问题的终极解决方案 当你在Unity项目中尝试使用Visual Studio 2022安装的NuGet包时,是否遇到过"未找到命名空间"的红色波浪线?这种开发环境间的割裂感让许多中级开发者陷入困境。本文将彻底剖…...