python爬虫相关
目录
初识爬虫
爬虫分类
网络爬虫原理
爬虫基本工作流程
搜索引擎获取新网站的url
robots.txt
HTHP协议
Resquests模块
前言:
安装
普通请求
会话请求
response的常用方法
简单案例
aiohttp模块
使用前安装模块
具体案例
数据解析
re解析
bs4解析
bs4的主要解析器
具体使用方法
bs4中常用的四种对象
获取Tag对象常用方法
获取属性以及字符串内容方法
Xpath解析
前言
xpath节点关系
xpath语法
具体使用
使用的xml
获取etree对象
通过etree对象获取元素
理解上面语法的案例
初识爬虫
爬虫:通过编写代码,模拟正常用户使用浏览器的过程,使其能够在互联网上自动进行数据抓取
爬虫分类
- 通用爬虫:通用网络爬虫是搜索引擎抓取系统的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份
- 聚焦爬虫:针对某一类数据进行采集的爬虫
网络爬虫原理
网络爬虫从互联网中搜索网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定了整个引擎系统是否内容丰富,信息是否及时,因此其性能优劣直接影响着搜索引擎的效果
爬虫基本工作流程
- 首先选取一部分种子URL,将这些url放入待抓取的队列
- 取出待抓取队列的url,解析DNS得到主机IP,并将URL对应的网页下载下来,存储到已下载的网页库中,并将这些url放入已抓取的url队列
- 分析已抓取的url队列中的url,分析其中的其他url,并且将该url放入待抓取的url队列中,进入下一个循环
搜索引擎获取新网站的url
- 新网站搜索引擎主动提交网址(如百度:http://zhanzhang.baidu.com/linksubmit/url)
- 在其他网站上设置新的网站外链
- 搜索引擎和DNS服务商合作,新网站域名被迅速抓取
robots.txt
前言:
- robots.txt是存放在网站根目录下的文本文件,比如https://www.baidu.com/robots.txt
- robots.txt用来告诉爬虫,那些内容是不应该被爬取的,那些是可以被爬取的
注意:
- 因为一些系统中的url是大小写敏感的,所以robots.txt的文件名应统一为小写
- 它并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私(只能防君子,不能防小人)
HTHP协议
前言:http协议为下面的requests模块学习做基础
http协议入口:http协议
Resquests模块
前言:
- 在python3中常用的网络模块有两个(urllib、requests)虽然在python标准库中urllib模块已经包含了平常我们使用的大多数功能,但是他的API使用起来让人感觉不太好,而requests自称"http for humans"说明使用更简洁方便
- requests继承了urllib2的所有特性,requests支持http链接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化url和post数据自动编码
- requests是唯一一个非转基因的python的http库,人类可以安全使用,其底层实现就是urllib3
安装
打开命令行:pip install requests
注意:使用时先导入requests模块:import requests
普通请求
get:response=request.get(url="url地址",headers={"key":"value"},params={"key":"value"},proxies={"协议":"协议://代理IP:端口号"})
post:response=requests.post(url="url地址",headers={"key":"value"},data={"key":"value"},proxies={"协议":"协议://代理IP:端口号"})
会话请求
获取session对象:session=requests.session()
get:response=session.get(url="url地址",headers={"key":"value"},params={"key":"value"},proxies={"协议":"协议://代理IP:端口号"})
post:response=session.post(url="url地址",headers={"key":"value"},data={"key":"value"},proxies={"协议":"协议://代理IP:端口号"})
注意:
- 上面的传递参数由于url后面参数顺序不同,因此要用关键字传参方式
- get请求的url地址需要加?,而post请求的url地址不需要加?
- 使用同一个session进行请求,那么浏览器就知道一直请求的是你
- 若设置请求头的cookie,那么不用session对象也可以达到相同效果
- 代理的协议与自己访问url的协议保持一致
- 代理原理,将自己发的请求先发给代理后代理帮你把请求发给目标地址
response的常用方法
设置编码格式为UTF-8:reponse.encoding="UTF-8"
查看返回的文本数据:变量=response.text
查看具有的cookie:变量=response.cookies
拿到响应内容:变量=response.content(这里拿到的是字节)
查看完整的url地址:变量=response.url
查看响应头部的字节编码:变量=response.encoding
查看响应状态码:变量=response.status_code
关闭response:response.close()
简单案例
#导入网络请求的第三方模块
import requests
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188"
}
kw={"wd":"python"
}
#通过requests模拟发送网络请求params=kw
response=requests.get("https://www.baidu.com/?",headers=headers,params=kw)
#手动设置编码格式
response.encoding="UTF-8"
#查看文本数据,返回的是Unicode数据
print(response.text)
#查看相应内容,返回的是字节流数据
print(response.content)
#查看完整的url地址
print(response.url)
#查看响应头部的字节编码
print(response.encoding)
#查看响应状态码
print(response.status_code)
#关掉response
response.close()aiohttp模块
前言:我们之前使用的requests.get()等方法都是同步的方法,如今我们需要执行异步操作
使用前安装模块
导入asyncio模块:import asyncio
导入aiohttp模块:import aiohttp
具体案例
import aiohttp
import asyncio
async def main():async with aiohttp.ClientSession() as session:async with session.get('https://limestart.cn/') as resp:#打印状态码print(resp.status)#注意text有括号说明是个函数调用所以加awaitprint(await resp.text())#打印内容print(await resp.content.read())
asyncio.run(main())注意:
- with语句作用:加了with后就会有上下文的管理器,有了上下文管理,那么当我们的with操作完事后,就会自动的关流。
- 异步请求和同步请求的步骤大同小异,可以相互借鉴(传递参数,请求头,以及相应resp方法)
数据解析
re解析
理解:re解析即正则表达式解析,对于具体正则表达事,请详见我另一篇文章
正则表达式入口:python之正则表达式
bs4解析
前言:bs4即BeautifulSoup,是python中的一种库,其可以从html或者xml文件中提取数据,他能够通过你喜欢的转换器实现惯用文档导航,查找、修改、文档的方式,beautiful soup会帮你节省数小时甚至数天的工作时间
使用前需要安装:pip install bs4
安装后需要导入模块:from bs4 import BeautifulSoup
bs4的主要解析器
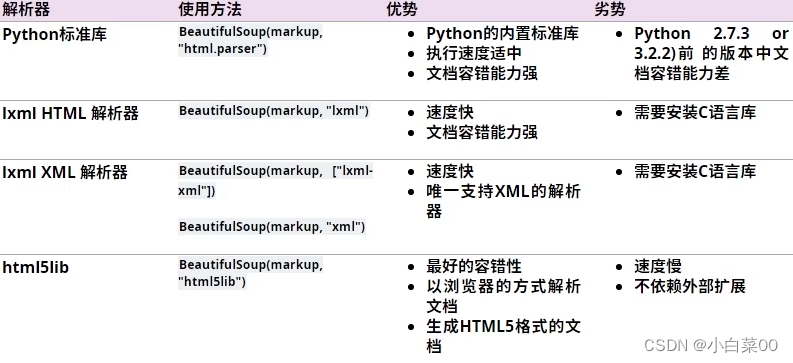
注意:解析器的主要作用是将前面的文件用什么方式进行解析
具体使用方法
创建soup对象:soup=BeautifulSoup("html文本","解析器")
注意:python默认的解析器为html.parser
bs4中常用的四种对象
- Tag:标签,html中的标签
- NavigableString:字符串,主要是标签内的字符串
- BeautifulSoup:最先生成的Soup对象
- Comment:注释部分,一般用不到
获取Tag对象常用方法
Tag对象=find("标签名",attrs={"属性名":"属性值"})
作用:返回匹配到的第一个标签
ResultSet对象=find_all("标签名",attrs={"属性名":"属性值"})
作用:返回所有的匹配值
注意:find两个函数主要是通过html的标签和属性名共同确定一个要查找的对象,但是也可以仅用标签名来查找。
获取属性以及字符串内容方法
字符串=Tag对象.text
作用:拿到被标签标记的内容(就是被标签夹着的字符串)
字符串=Tag对象.get("属性名")
作用:从Tag对象中拿到拿到对应属性的值
Xpath解析
前言
- xpath是一门在html/xml文档中查找信息的一门语言,可用来在html/xml文档中对元素和属性进行遍历
- html是xml的一个子集
含义:xpath全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索
xpath节点关系
节点:每个html标签我们都称之为节点(根节点、子节点,兄弟节点)
<html><!--根节点--><head><!--子节点--><title>节点的关系</title></head><body><div>实验</div></body>
</html>
<!--注意,head标签和body标签同属于兄弟节点-->xpath语法
前言:xpath使用路径表达式来选取xml文档中节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式十分相似
| 表达式 | 描述 |
| nodename | 选中该元素 |
| / | 从根节点选取,或者是元素和元素间的过度 |
| // | 可以跨节点获取标签 |
| .(点) | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| nodename[@属性名='属性值'] | 选取特定属性的nodename元素 |
| @属性名 | 获取元素属性的值 |
| text() | 选取元素文本内容 |
| nodename[n] | 得到的多个节点中选取第n个节点 |
| * | 通配符 |
注意:点方法需要对标签进行第一次提取,获取标签对象之后,通过点的方式获取当前标签的方法可以获得他的下一级标签
具体使用
使用前安装:pip install lxml
安装后导入:from lxml import etree
使用的xml
<book><id>1</id><name>野花遍地香</name><price>1.23</price><nick>臭豆腐</nick><author><nick id="10086">周大强</nick><nick id="10010">周芷若</nick><nick class="joy">周杰伦</nick><nick class="jolin">蔡依林</nick><div><nick>刘谦</nick></div><span><nick>高达</nick></span></author><partner><nick id="ppc">胖胖不沉</nick><nick id="ppbc">陈陈不胖</nick></partner>
</book>获取etree对象
etree对象=etree.XML("xml内容")
etree对象=etree.HTML("html内容")
etree对象=etree.parse("文件名")
通过etree对象获取元素
变量=etree对象.xpath("路径表达式")
理解上面语法的案例
获取book元素
book1=tree.xpath("/book")
print(book1)#[<Element book at 0x135b5575f00>]
book2=tree.xpath("/book/author/..")
print(book2)#[<Element book at 0x135b5575f00>]
book3=tree.xpath("/book/.")
print(book3)#[<Element book at 0x135b5575f00>]获取book里的name元素的文本
text=tree.xpath("/book/name/text()")
print(text)#['野花遍地香']获取author下面的所有nick元素文本
nick=tree.xpath("/book/author//nick/text()")
print(nick)#['周大强', '周芷若', '周杰伦', '蔡依林', '刘谦', '高达']获取author和partner元素之下一级的nick元素文本
nickname=tree.xpath("/book/*/nick/text()")
print(nickname)#['周大强', '周芷若', '周杰伦', '蔡依林', '胖胖不沉', '陈陈不胖']获取author下的第一个nick的元素文本
nick_one=tree.xpath("/book/author/nick[1]/text()")
print(nick_one)#['周大强']获取id为10010元素的内容
nick_id=tree.xpath("//nick[@id='10010']/text()")
print(nick_id)#['周芷若']获取周芷若id的值
nick_id_name=tree.xpath("/book/author/nick[2]/@id")
print(nick_id_name)#['10010']相关文章:
python爬虫相关
目录 初识爬虫 爬虫分类 网络爬虫原理 爬虫基本工作流程 搜索引擎获取新网站的url robots.txt HTHP协议 Resquests模块 前言: 安装 普通请求 会话请求 response的常用方法 简单案例 aiohttp模块 使用前安装模块 具体案例 数据解析 re解析 bs4…...
PAT(Advanced Level) Practice(with python)——1023 Have Fun with Numbers
Code N int(input()) D_N 2*N # print(Yes)if len(str(D_N))>len(str(N)):print(No) else:for s in str(D_N):if s not in str(N) or str(D_N).count(s)!str(N).count(s):print("No")breakelse:print(Yes) print(D_N)...

springboot vue 初步集成onlyoffice
文章目录 前言一、vue ts1. 安装依赖2. onlyoffice组件实现(待优化)3. 使用组件4. 我的配置文件 二、springboot 回调代码1. 本地存储 三、效果展示踩坑总结问题1问题2 前言 对接onlyoffice,实现文档的预览和在线编辑功能。 一、vue ts …...
Win10语言设置 - 显示语言和应用语言
前言 Win10的语言设置可以设置显示语言和应用语言。其中,显示语言用于显示系统文字;应用语言用于应用程序显示文字。下文介绍如何设置。 显示语言 打开系统设置,选择时间和语言,如下图: 修改Windows显示语言即可更…...

RxJava的前世【RxJava系列之设计模式】
一. 前言 学习RxJava,少不了介绍它的设计模式。但我看大部分文章,都是先将其用法介绍一通,然后再结合其用法,讲解其设计模式。这样当然有很多好处,但我个人觉得,这种介绍方式,对于没有接触过Rx…...

sql 语句 字段字符串操作
substring_index() 函数 字符串截取 表达式:substring_index(column,str,count) 释义:截取字符串column,str出现从前往后数第count次,之前的所有字符 示例语句:SELECT substring_index(‘www.baidu.com’,‘.’,2) 结…...
【网络工程】网络流量分析工具 Wireshark
文章目录 第一章:WireShark介绍第二章:WireShark应用第三章:Wireshark 实战 第一章:WireShark介绍 Wireshark (前身 Ethereal):它是一个强大的网络封包分析软件工具 ! 此工具使用WinPCAP作为接口,直接与网卡…...
数据库总结
第一章绪论 一、数据库系统概述 1. 数据库的4个基本概念 1.数据:数据库中存储的基本对象,描述事物的符号记录。 2.数据库:长期储存在计算机内、有组织的、可共享的大量数据的集合。较小的冗余度、较高的数据独立性、易扩展性 3.数据库管…...

虹科方案 | 成都大运会进行时,保障大型活动无线电安全需要…
成都大运会 7月28日,备受关注的第31届世界大学生夏季运动会在成都正式开幕。据悉,这是全球首个5G加持的智慧大运会,也是众多成熟信息技术的综合“应用场”。使用基于5G三千兆、云网、8K超高清视频等技术,在比赛现场搭建多路8K摄像…...
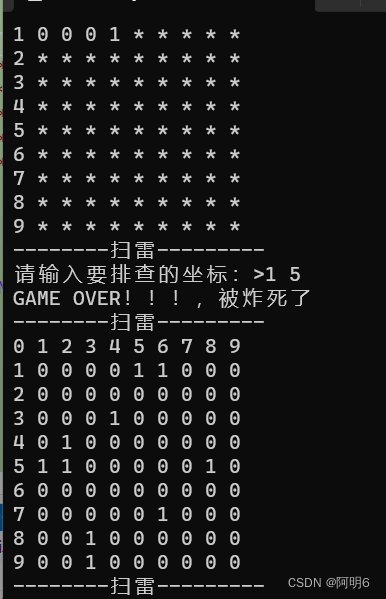
【C语言】扫雷 小游戏
文章目录 一、游戏规则二、 代码逻辑三、游戏实现1. 游戏菜单设计2.设计雷区并随机布置雷(1) 设置雷区(2) 布置雷 3.排查雷 四、源码 一、游戏规则 1. 在9*9的小格子中,任意选取一个坐标(格子),选择后发现,如果没点中雷…...

Jmeter(六) - 从入门到精通 - 建立数据库测试计划(详解教程)
1.简介 在实际工作中,我们经常会听到数据库的性能和稳定性等等,这些有时候也需要测试工程师去评估和测试,因此这篇文章主要介绍了jmeter连接和创建数据库测试计划的过程,在文中通过示例和代码非常详细地介绍给大家,希望对各位小伙…...
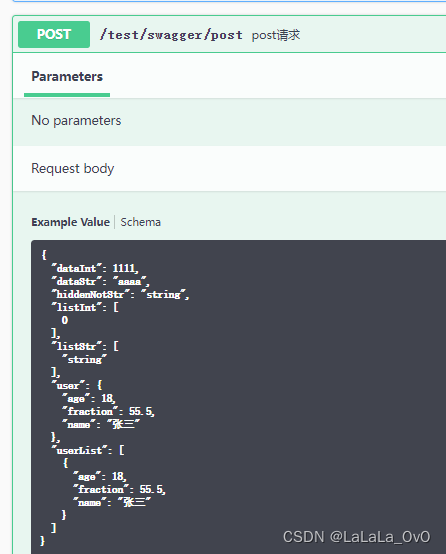
swagger 3.0 学习笔记
引入pom <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter</artifactId><version>3.0.0</version></dependency>配置 import io.swagger.models.auth.In; import io.swagger.v3.oas.annotati…...

07 |「异步任务」
前言 实践是最好的学习方式,技术也如此。 文章目录 前言一、进程与线程1、进程2、线程 二、实现 一、进程与线程 1、进程 进程(Process)是操作系统分配资源的基本单位,它是一个执行中的程序实例;每个进程都有自己独立的内存空间,不同进程的内存是相互独…...

LoRaWan网关设计之入门指南
快速开始 以下是在目标平台本身上构建和运行 LoRaWan网关 的三步快速入门指南。 第 1 步:克隆 网关源码库 git clone https://github.com/lorabasics/basicstation.git...
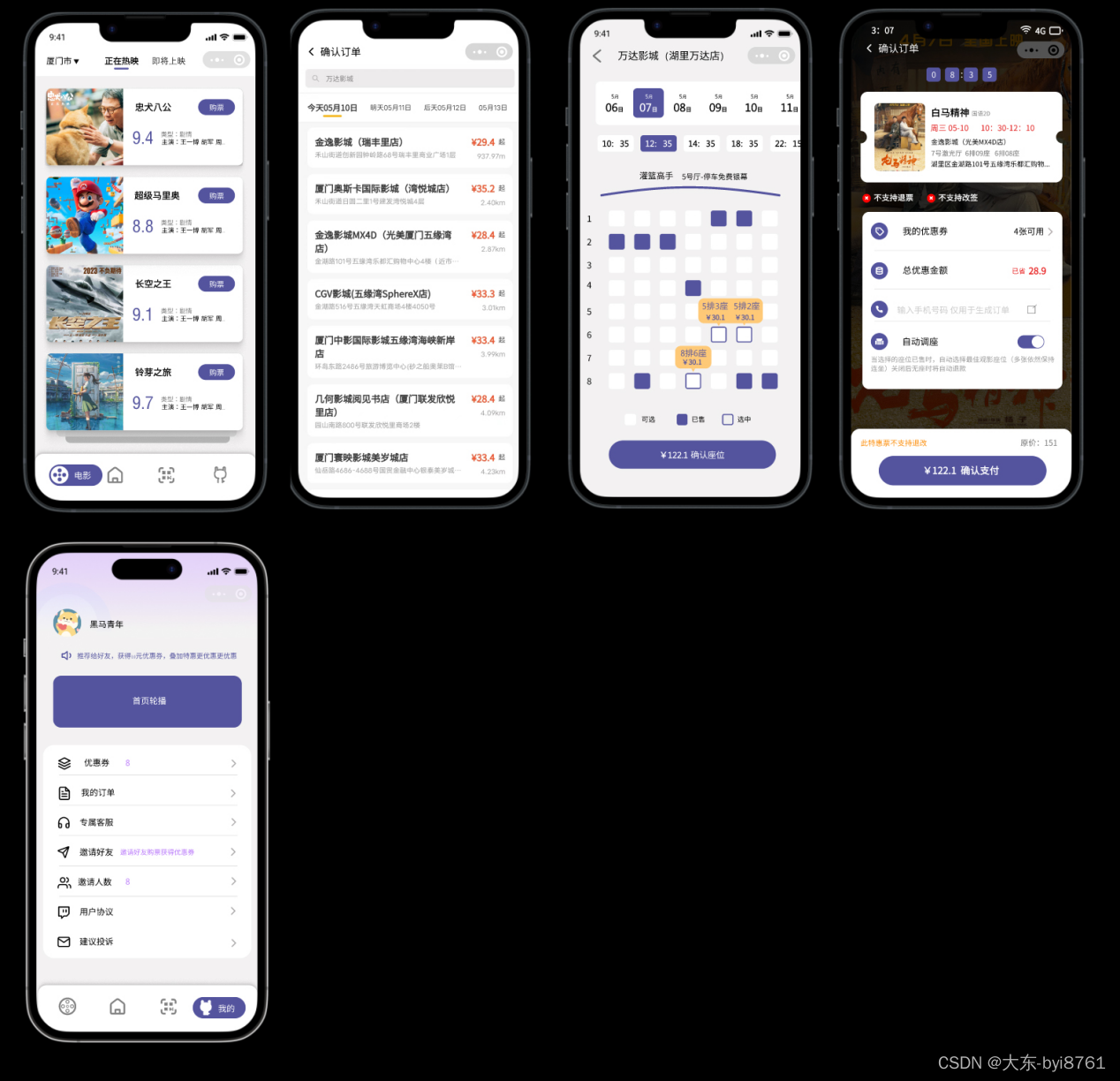
互联网电影购票选座后台管理系统源码开发
搭建一个互联网电影购票选座后台管理系统需要进行以下步骤: 1. 需求分析:首先要明确系统的功能和需求,包括电影列表管理、场次管理、座位管理、订单管理等。 2. 技术选型:选择适合的技术栈进行开发,包括后端开发语言…...

[ K8S ] yaml文件讲解
目录 查看 api 资源版本标签写一个yaml文件demo创建资源对象查看创建的pod资源创建service服务对外提供访问并测试//创建资源对象查看创建的service写yaml太累怎么办? Kubernetes 支持 YAML 和 JSON 格式管理资源对象 JSON 格式:主要用于 api 接口之间消…...
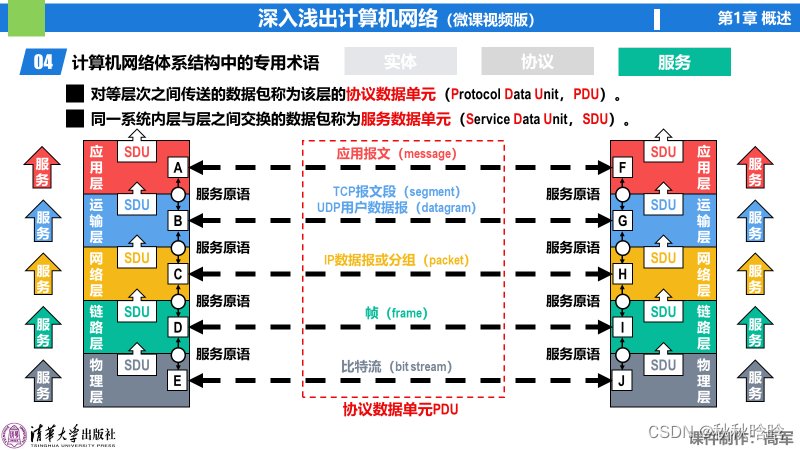
【《深入浅出计算机网络》学习笔记】第1章 概述
内容来自b站湖科大教书匠《深入浅出计算机网络》视频和《深入浅出计算机网络》书籍 目录 1.1 信息时代的计算机网络 1.1.1 计算机网络的各类应用 1.1.2 计算机网络带来的负面问题 1.2 因特网概述 1.2.1 网络、互联网与因特网的区别与关系 1.2.1.1 网络 1.2.1.2 互联网 …...
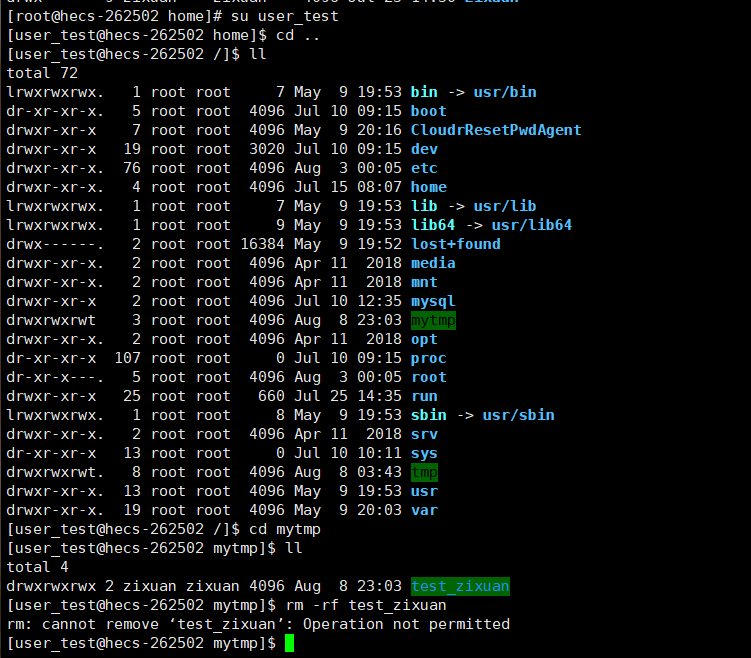
二、Linux中权限、shell命令及运行原理
shell命令及运行原理 我们使用Linux时,并不是直接访问操作系统,为什么不是直接访问操作系统呢? 如果用户直接访问操作系统,不仅使用难度大,而且不安全,容易把系统文件损坏。 那么我们通常是如何访问操作系统…...
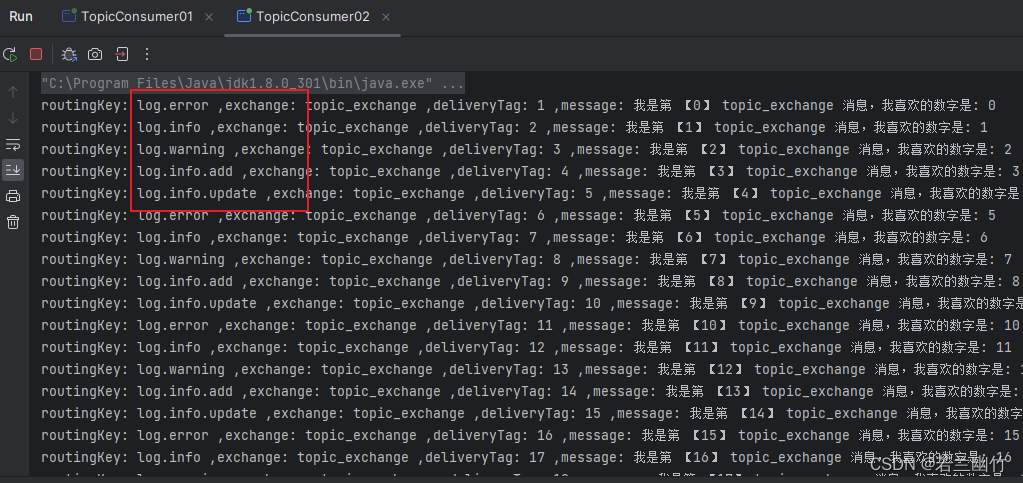
【RabbitMQ上手——单实例安装5种简单模式实现通讯过程】
【RabbitMQ入门-单实例安装&5种简单模式实现通讯过程】 一、环境说明二、安装RabbitMQ三、用户权限及Virtual Host设置四、5种简单模式实现通讯过程的实现五、小结 一、环境说明 安装环境:虚拟机VMWare Centos7.6 Maven3.6.3 JDK1.8RabbitMQ版本:…...

python+pytest接口自动化之HTTP协议基础
HTTP协议简介 HTTP 即 HyperText Transfer Protocol(超文本传输协议),是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。 设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。HTTP 协议在 OSI 模型…...

WorkshopDL终极指南:如何免费下载1000+款Steam创意工坊模组
WorkshopDL终极指南:如何免费下载1000款Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为GOG或Epic平台游戏无法使用Steam创意工坊模组而烦恼…...

WarcraftHelper 2024终极指南:让经典魔兽争霸III在现代电脑完美运行
WarcraftHelper 2024终极指南:让经典魔兽争霸III在现代电脑完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典魔兽争霸II…...

UnrealPakViewer终极指南:如何快速分析虚幻引擎Pak文件资源
UnrealPakViewer终极指南:如何快速分析虚幻引擎Pak文件资源 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer 你是否曾经面对数十GB的虚幻…...

五年磨剑与二十年深耕:5 年与 20 年程序员的差距,远不止代码本身
在信息技术飞速迭代的今天,程序员这一职业始终站在时代前沿。有人说,程序员是吃 “青春饭” 的行业,年轻意味着精力充沛、学习速度快、能熬夜加班;也有人说,真正的技术高手,往往藏在十几年甚至二十余年的行…...

蓝桥杯10天备战-day3基础算法
二分:int xxlower_bound(a,an,x)-a;返回>x的指针,减去a才是下标int yyupper_bound(a,an,x)-a;二分万能模板:#include<bits/stdc.h> using namespace std; #define int long long int a[10000]; int n, m; bool isblue(int mid) {if …...
的边框颜色)
bootstrap怎么修改折叠面板(Accordion)的边框颜色
Accordion默认边框颜色来自.accordion-item的border-color,继承自Sass变量$border-color或$accordion-border-color,作用于border-top和border-bottom。Accordion 默认边框颜色从哪来bootstrap 的 accordion 边框颜色默认由 .accordion-item 的 border-c…...

Pixel Aurora Engine参数详解:CFG值对像素锐度/噪点/色块分布的影响
Pixel Aurora Engine参数详解:CFG值对像素锐度/噪点/色块分布的影响 1. 认识Pixel Aurora Engine Pixel Aurora Engine是一款基于AI扩散模型的高端像素艺术生成工具。它将现代AI技术与复古像素美学完美结合,让用户能够通过简单的文字描述生成具有8-bit…...

Apache Iceberg:开源数据湖表格式的革新力量
Apache Iceberg:开源数据湖表格式的革新力量 在当今数字化时代,数据量呈爆炸式增长,企业对数据的存储、管理和分析需求也日益复杂。在这样的背景下,Apache Iceberg 作为一款开源的数据湖表格式,逐渐在数据领域崭露头角…...

如何配置分区表的行迁移_ENABLE ROW MOVEMENT允许更新分区键跨区移动
必须开启ENABLE ROW MOVEMENT才能UPDATE分区键并跨分区移动行,否则报ORA-14402;该DDL解禁行迁移能力,实际迁移发生在后续UPDATE时,且需注意全局索引失效、锁影响及提交验证。ALTER TABLE ... ENABLE ROW MOVEMENT 为什么必须开不开…...

AutoGen Studio步骤详解:Qwen3-4B在AssiantAgent中Base URL与模型绑定
AutoGen Studio步骤详解:Qwen3-4B在AssiantAgent中Base URL与模型绑定 1. 了解AutoGen Studio与Qwen3-4B模型 AutoGen Studio是一个低代码界面,专门帮助开发者快速构建AI代理应用。通过这个平台,你可以轻松创建AI代理、为它们添加工具功能、…...