python实现简单的爬虫功能
前言
Python是一种广泛应用于爬虫的高级编程语言,它提供了许多强大的库和框架,可以轻松地创建自己的爬虫程序。在本文中,我们将介绍如何使用Python实现简单的爬虫功能,并提供相关的代码实例。

如何实现简单的爬虫
1. 导入必要的库和模块
在编写Python爬虫时,我们需要使用许多库和模块,其中最重要的是requests和BeautifulSoup。Requests库可以帮助我们发送HTTP请求,并从网站上获取数据,而BeautifulSoup可以帮助我们从HTML文件中提取所需的信息。因此,我们需要首先导入这两个库。
import requests
from bs4 import BeautifulSoup
2. 发送HTTP请求
在爬虫程序中,我们需要向网站发送HTTP请求,通常使用GET方法。Requests库提供了一个get()函数,我们可以使用它来获取网站的HTML文件。这个函数需要一个网站的URL作为参数,并返回一个包含HTML文件的响应对象。我们可以使用text属性来访问HTML文件的文本内容。
url = "https://www.example.com"
response = requests.get(url)
html = response.text在发送HTTP请求时,我们需要注意是否需要添加用户代理和头信息。有些网站会检查用户代理和头信息,如果没有正确的值,它们就会拒绝我们的请求。为了避免这种情况,我们可以在HTTP请求中添加用户代理和头信息。我们可以使用requests库的headers选项来添加头信息。
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}response = requests.get(url, headers=headers)3. 解析HTML文件
在获取了网站的HTML文件之后,我们需要从中提取我们想要的信息。为此,我们需要使用BeautifulSoup库,它提供了许多强大的函数和方法,可以轻松地解析HTML文件。
我们可以使用BeautifulSoup函数将HTML文件转换为BeautifulSoup对象。然后,我们可以使用find()、find_all()等方法来查找HTML文件中的元素。这些方法需要一个标签名称作为参数,并返回一个包含所选元素的列表或单个元素。
soup = BeautifulSoup(html, "html.parser")
title = soup.find("title").text
为了从HTML文件中提取更多的信息,我们需要了解CSS选择器。CSS选择器是一种用于选择HTML元素的语法,类似于CSS中的样式选择器。我们可以使用CSS选择器来获取HTML文件中特定元素的信息。例如,我们可以使用select()方法和一个CSS选择器来选择一个类别的所有元素。
items = soup.select(".item")
for item in items:title = item.select(".title")[0].textprice = item.select(".price")[0].text
4. 存储数据
在爬取数据后,我们可能需要将数据存储到本地文件或数据库中。Python提供了许多方式来实现这一点,例如使用CSV、JSON或SQLite等格式来存储数据。
如果我们要将数据保存到CSV文件中,我们可以使用csv库。这个库提供了一个writer()函数,我们可以使用它来创建一个CSV写入器。然后,我们可以使用writerow()方法向CSV文件中写入数据。
import csvwith open("data.csv", "w", newline="") as file:writer = csv.writer(file)writer.writerow(["Title", "Price"])for item in items:title = item.select(".title")[0].textprice = item.select(".price")[0].textwriter.writerow([title, price])如果我们要将数据保存到SQLite数据库中,我们可以使用sqlite3库。这个库提供了一个链接到数据库的函数connect()和一个游标对象,我们可以使用它来执行SQL查询。
import sqlite3conn = sqlite3.connect("data.db")
cursor = conn.cursor()
cursor.execute("CREATE TABLE items (title TEXT, price TEXT)")for item in items:title = item.select(".title")[0].textprice = item.select(".price")[0].textcursor.execute("INSERT INTO items VALUES (?, ?)", (title, price))conn.commit()
conn.close()
完整的代码示例:
import requests
from bs4 import BeautifulSoup
import csv
import sqlite3def get_data():url = "https://www.example.com"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}response = requests.get(url, headers=headers)html = response.textsoup = BeautifulSoup(html, "html.parser")title = soup.find("title").textitems = soup.select(".item")data = []for item in items:title = item.select(".title")[0].textprice = item.select(".price")[0].textdata.append((title, price))return title, datadef save_csv(title, data):with open("data.csv", "w", newline="") as file:writer = csv.writer(file)writer.writerow(["Title", "Price"])for item in data:writer.writerow(item)def save_sqlite(title, data):conn = sqlite3.connect("data.db")cursor = conn.cursor()cursor.execute("CREATE TABLE items (title TEXT, price TEXT)")for item in data:cursor.execute("INSERT INTO items VALUES (?, ?)", item)conn.commit()conn.close()title, data = get_data()
save_csv(title, data)
save_sqlite(title, data)
总结
本文介绍了如何使用Python实现简单的爬虫功能,并提供了相关的代码示例。使用这些代码,您可以轻松地从网站上获取所需的数据,并将它们存储到本地文件或数据库中。在编写爬虫程序时,请务必尊重网站的使用规则,并避免过度频繁地发出HTTP请求,以避免对网站造成不必要的负担。
相关文章:
python实现简单的爬虫功能
前言 Python是一种广泛应用于爬虫的高级编程语言,它提供了许多强大的库和框架,可以轻松地创建自己的爬虫程序。在本文中,我们将介绍如何使用Python实现简单的爬虫功能,并提供相关的代码实例。 如何实现简单的爬虫 1. 导入必要的…...

AI文档识别技术之表格识别 (一)
AI文档识别技术之表格识别(一) 文章目录 文章目录 AI文档识别技术之表格识别(一)1. 表格识别原理介绍1.1 表格类型分类1.2 识别原理 2. 整体识别流程2.1 流程图2.2 图像处理部分大致流程 3. 将表格转换为html与json格式输出3.1 html格式3.2 json格式3.3 表格识别实例 前言 此文…...

uni-app 支持 app端, h5端,微信小程序端 图片转换文件格式 和 base64
uni-app 支持 app端 h5端,微信小程序端 图片转换文件格式 和 base64,下方是插件市场的地址app端 h5端,微信小程序端 图片转换文件格式 和 base64 - DCloud 插件市场 https://ext.dcloud.net.cn/plugin?id13926...

云计算——存储虚拟化简介 与 存储模式及方法
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前期回顾 前言 一.存储虚拟化介绍 1.云计算存储基本概念 2.云计算存储模型 3.创…...

数据资产目录建设之数据分类全解
01 数据治理“洗澡论” 其实他们之前做过数据一轮数据资产盘点,做了一个分类,也挂到系统上了,但是后来就没有后来了。治理做一半,等于啥也没干。 我之前在群里开了一个玩笑,数据治理这种事情,就跟洗澡一…...

大模型的数据隐私问题有解了,浙江大学提出联邦大语言模型
作者 | 小戏、Python 理想化的 Learning 的理论方法作用于现实世界总会面临着诸多挑战,从模型部署到模型压缩,从数据的可获取性到数据的隐私问题。而面对着公共领域数据的稀缺性以及私有领域的数据隐私问题,联邦学习(Federated Le…...

flask-sqlalchemy使用
# sqlalchemy 集成到flask中 # 第三方: flask-sqlalchemy 封装了用起来,更简洁 安装 pip install flask-sqlalchemy 使用 # 使用flask-sqlalchemy集成1 导入 from flask_sqlalchemy import SQLAlchemy2 实例化得到对象db SQLAlchemy()3 将db注册到app中db.in…...

flask处理token的装饰器
以下是在 Flask 中基于 token 实现的登录验证装饰器的示例代码: import jwt from functools import wraps from flask import request, jsonify, current_appdef login_required(f):wraps(f)def decorated_function(*args, **kwargs):token request.headers.get(A…...

【Express.js】页面渲染
页面渲染 常见的页面分为两种,一种是静态页面,比如用 Vue、React 等写好的静态页面,另一种是动态模板页面,如 Thymeleaf,JSP 等。 本节将简要介绍如何在 express 中渲染静态页面,以及适用于 express 的模…...
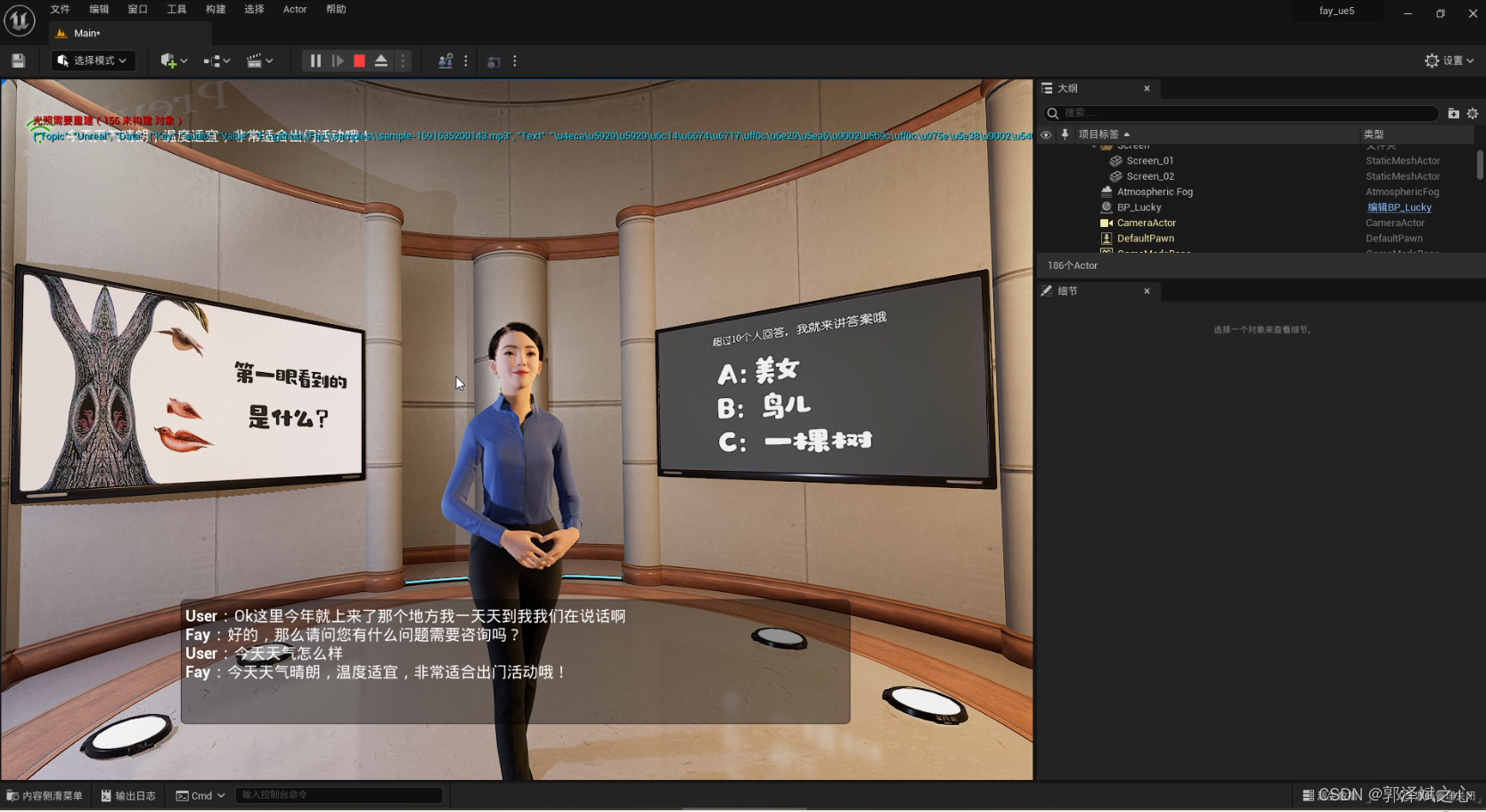
2.UE数字人语音交互(UE数字人系统教程)
上一篇:1.Fay-UE5数字人工程导入 2.UE数字人语音交互(UE数字人系统教程) 1、启动ue数字人 2、下载Fay数字人控制器 Fay数字人控制器下载地址 3、依照说明配置运行Fay 4、启动Fay控制器 5、切换到UE界面开始说话 6、完成了…...
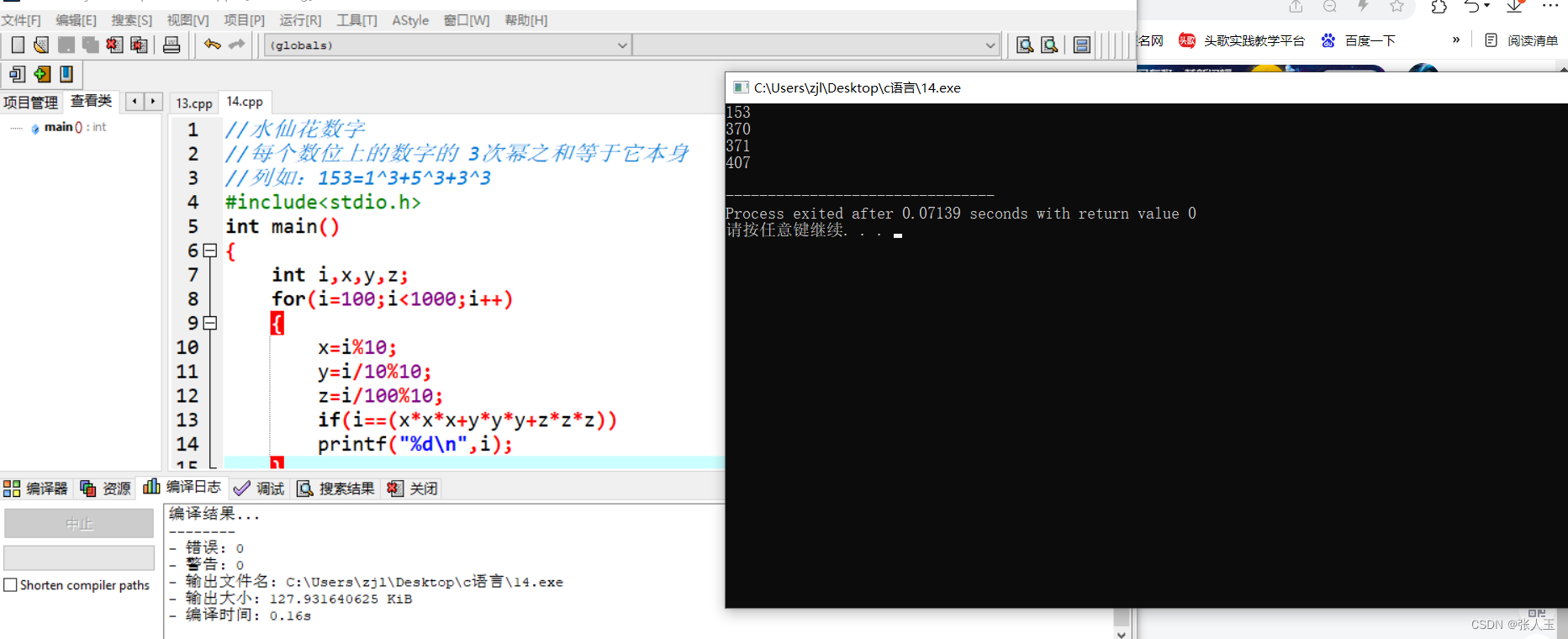
C语言——水仙花数字
//水仙花数字 //每个数位上的数字的 3次幂之和等于它本身 //列如:1531^35^33^3 #include<stdio.h> int main() {int i,x,y,z;for(i100;i<1000;i){xi%10;yi/10%10;zi/100%10;if(i(x*x*xy*y*yz*z*z))printf("%d\n",i);}return 0; } //输出100-1000…...

java中list对象拷贝至新的list对象并保持两个对象独立的方法
在Java中,如果你想拷贝一个List对象到一个新的List对象,并且修改原来的List不影响新的List中的内容,有几种方法可以实现:使用构造函数: 可以使用List的构造函数,传递原始List作为参数来创建一个新的List对象…...
使用AI工具Lama Cleaner一键去除水印、人物、背景等图片里的内容
使用AI工具Lama Cleaner一键去除水印、人物、背景等图片里的内容 前言前提条件相关介绍Lama Cleaner环境要求安装Lama Cleaner启动Lama CleanerCPU方式启动GPU方式启动 使用Lama Cleaner测试结果NO.1 检测框NO.2 水印NO.3 广州塔NO.4 人物背景 参考 前言 由于本人水平有限&…...
瑞数系列及顶像二次验证LOGS
瑞数商标局药监局专利局及顶像二次验证 日期:20230808 瑞数信息安全是一个专注于信息安全领域的公司,致力于为企业和个人提供全面的信息安全解决方案。他们的主要业务包括网络安全、数据安全、应用安全、云安全等方面的服务和产品。瑞数信息安全拥有一支…...
)
Anaconda版本和Python版本对应关系(持续更新...)
简介 Anaconda是包管理工具,是专注于数据分析的Python发行版本,其包含Python和许多常用软件包,不同的Anaconda版本里面也配备了不同的Python版本,并且Python的出现时间比Anaconda早很多;相对而言,python原生的pip安装方…...
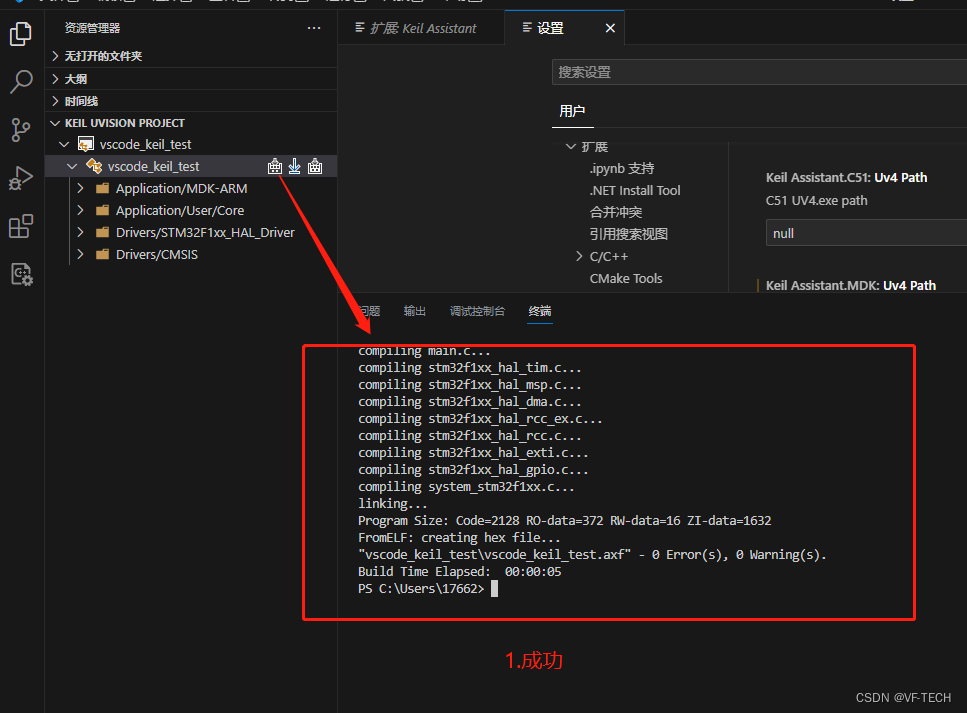
vscode 搭建STM32开发环境
1.需要软件 1.1 vscode 1.2 STM32CubeMX,这个不是必须的,我是为了方便生成STM32代码 2.vscode配置 2.1安装keil Assistant 2.2配置keil Assistant 3.STMCUBE生成个STM32代码 ,如果有自己的代码可以忽略 4.代码添加到vscode,并…...

6款好用的思维导图在线制作网站盘点,拒绝低效、探索创意!
思维导图以其直观、系统的特性,成为了我们理清思路、整理信息的强大助手。利用好思维导图,我们可以更好地理解信息、链接概念,进一步提高我们的学习和工作效率。 在众多制作思维导图的软件中,在线思维导图制作网站更是因其…...

js的Promise
目录 异步任务回调地域Promise Promise的三种状态resolve传入值 Promise的实例方法thenthen的返回值返回Promise的状态 catchcatch的返回值 finally Promise的类方法resolverejectallallSettledraceany 异步任务 在js中,有些任务并不是立即执行的,如set…...
2.4g无线芯片G350规格书详细介绍
G350是一款高度集成的2.4GHz无线收发芯片,旨在为各种应用提供低成本、高性能的无线通信解决方案。该芯片通过降低功耗,在保持寄存器值条件下,实现最低电流为5μA,从而显著提高了电池寿命。它内置了发射接收FIFO寄存器,…...
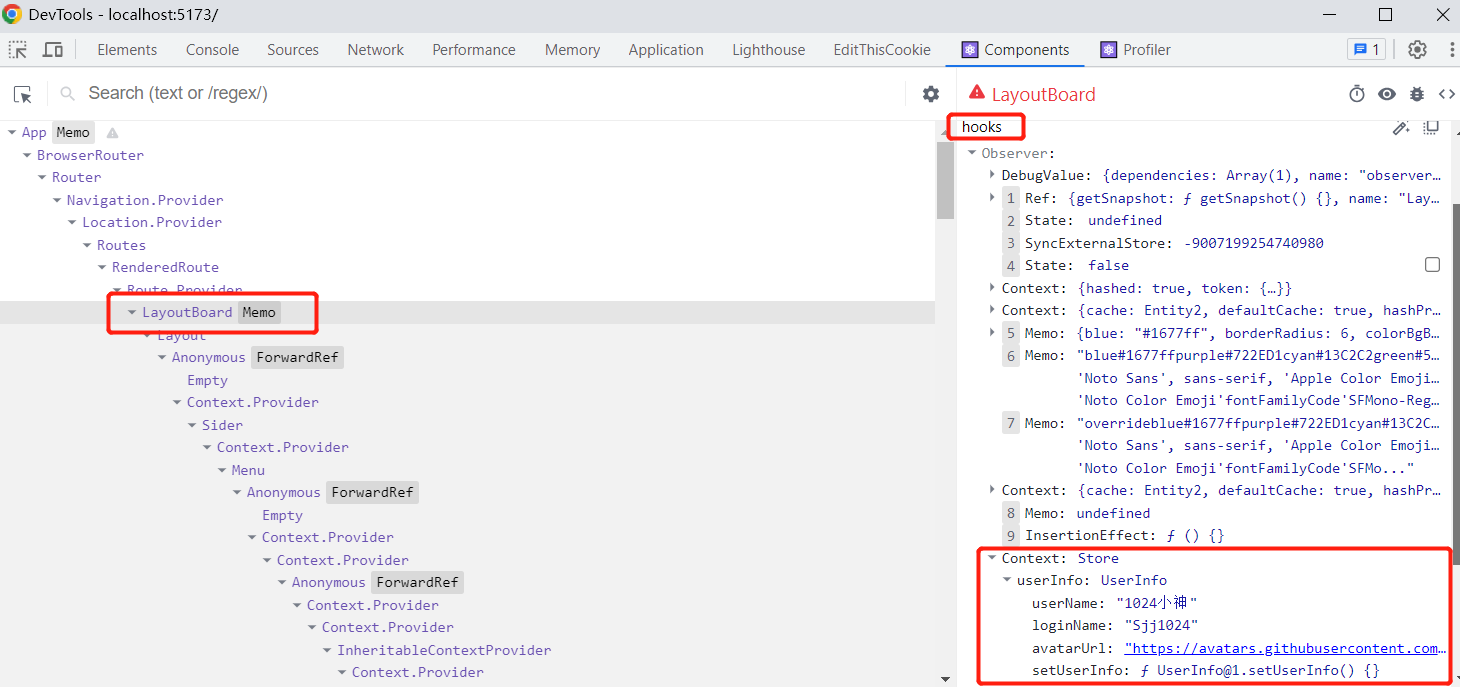
React中使用mobx管理状态数据使用样例
MobX 是一个身经百战的库,它通过运用透明的函数式响应编程(Transparent Functional Reactive Programming,TFRP)使状态管理变得简单和可扩展。官网地址:关于 MobX | MobX中文文档 | MobX中文网 安装依赖 mobx-react-…...

7 种将照片从手机传输到笔记本电脑的巧妙方法
我们许多人更喜欢用智能手机拍摄照片,而非专业数码相机。在这个时代,不断更新的智能手机拥有可观的存储空间,但手机内存耗尽的情况仍时有发生。 因此,有些人会想在笔记本电脑上保留精选照片的副本,还有些人则需要在电脑…...
,立即自查你的Agent集群)
AIAgent协议一致性危机爆发前夜:4步诊断法+3类协议健康度SLI指标(P99延迟、语义丢失率、Schema漂移频次),立即自查你的Agent集群
第一章:AIAgent架构中的通信协议设计 2026奇点智能技术大会(https://ml-summit.org) 在多智能体协同系统中,通信协议是决定Agent间语义对齐、时序可控与容错能力的核心基础设施。不同于传统微服务间RESTful或gRPC调用,AIAgent需支持异步事件…...
)
卡梅德生物技术快报|多肽文库合成和筛选全流程技术实现(含参数与质控)
【技术干货】本文为卡梅德生物技术快报专属内容,聚焦多肽文库合成和筛选的工程化实现,基于生物载体展示技术,提供可复现、可落地的全流程方案,包含实验参数、质控标准、筛选逻辑,适合生物信息、合成生物学、高通量筛选…...
)
别再手动拼接Prompt了!用ChatML结构化你的大模型对话(以Llama 2/3为例)
别再手动拼接Prompt了!用ChatML结构化你的大模型对话(以Llama 2/3为例) 当你在深夜调试代码时,是否曾被这样的场景折磨:为了构造一个多轮对话的prompt,不得不反复拼接user:、assistant:等字符串,…...
)
解密昇腾ACL事件机制:如何用Event实现多Stream精准调度(避坑指南)
昇腾ACL事件机制深度解析:多Stream协同避坑实战 当你在昇腾平台上处理8路高清视频流分析时,是否遇到过这样的困境——明明硬件算力充足,但实际吞吐量却只有理论值的60%?问题的根源往往不在算法本身,而在于对ACL事件机制…...

Windows系统下MacBook Pro Touch Bar高效解锁指南:一键开启智能触控显示功能
Windows系统下MacBook Pro Touch Bar高效解锁指南:一键开启智能触控显示功能 【免费下载链接】DFRDisplayKm Windows infrastructure support for Apple DFR (Touch Bar) 项目地址: https://gitcode.com/gh_mirrors/df/DFRDisplayKm 还在为Windows系统下MacB…...

OpCore Simplify终极指南:5步轻松搞定Hackintosh配置,新手也能快速上手
OpCore Simplify终极指南:5步轻松搞定Hackintosh配置,新手也能快速上手 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为…...

awesome-design-systems 中的电子商务设计系统:Shopify Polaris到Magento的案例
awesome-design-systems 中的电子商务设计系统:Shopify Polaris到Magento的案例 【免费下载链接】awesome-design-systems 💅🏻 ⚒ A collection of awesome design systems 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-des…...

Spring_couplet_generation 项目环境配置:Anaconda虚拟环境管理详解
Spring_couplet_generation 项目环境配置:Anaconda虚拟环境管理详解 你是不是也遇到过这种情况?在电脑上跑一个Python项目,结果因为包版本冲突,或者依赖关系混乱,项目死活跑不起来。更头疼的是,这个项目需…...
)
PlatformIO里找不到我的ESP32-S3开发板?手把手教你自定义一个(附完整JSON配置)
PlatformIO找不到ESP32-S3开发板?三步打造专属板型配置文件 刚拿到一块小众ESP32-S3开发板时,最令人沮丧的莫过于打开PlatformIO准备大展身手,却发现官方板型列表里根本没有自己的设备。别急着退货或换板子,其实只需15分钟就能为…...