【LangChain学习】基于PDF文档构建问答知识库(三)实战整合 LangChain、OpenAI、FAISS等
接下来,我们开始在web框架上整合 LangChain、OpenAI、FAISS等。
一、PDF库
因为项目是基于PDF文档的,所以需要一些操作PDF的库,我们这边使用的是PyPDF2
from PyPDF2 import PdfReader# 获取pdf文件内容
def get_pdf_text(pdf):text = ""pdf_reader = PdfReader(pdf)for page in pdf_reader.pages:text += page.extract_text()return text传入 pdf 文件路径,返回 pdf 文档的文本内容。
二、LangChain库
1、文本拆分器
首先我们需要将第一步拿到的本文内容拆分,我们使用的是 RecursiveCharacterTextSplitter ,默认使用 ["\n\n","\n"," "] 来分割文本。
from langchain.text_splitter import RecursiveCharacterTextSplitter# 拆分文本
def get_text_chunks(text):text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,# chunk_size=768,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)return chunks其中这里 chunk_size 参数要注意,这里是指文本块的最大尺寸,如果用chatgpt3.5会在问答的时候容易出现token长度超过4096的异常,这个后面会说如何调整,只需要换一下模型就好了。
这个参数对于向量化来说,比较重要,因为到时候喂给OpenAI去分析的时候,携带的上下文内容就会比较多,这样准备性和语义分析上也有不少的帮助。
2、向量库
项目使用 FAISS,就是将 pdf 读取到的文本向量化以后,通过 FAISS 保存到本地,后续就不需要再执行向量化,就可以读取之前的备份。
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings# 保存
def save_vector_store(textChunks):db = FAISS.from_texts(textChunks, OpenAIEmbeddings())db.save_local('faiss')# 加载
def load_vector_store():return FAISS.load_local('faiss', OpenAIEmbeddings())其中 faiss 参数为保存的目录名称,默认在项目同级目录下生成。
这里使用 OpenAI 的方法 OpenAIEmbeddings 来进行向量化。
3、检索型问答链
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate# 获取检索型问答链
def get_qa_chain(vector_store):prompt_template = """基于以下已知内容,简洁和专业的来回答用户的问题。如果无法从中得到答案,清说"根据已知内容无法回答该问题"答案请使用中文。已知内容:{context}问题:{question}"""prompt = PromptTemplate(template=prompt_template,input_variables=["context", "question"])return RetrievalQA.from_llm(llm=ChatOpenAI(model_name='gpt-3.5-turbo-16k'), retriever=vector_store.as_retriever(), prompt=prompt)1)RetrievalQA 检索行问答链
这里使用 RetrievalQA,这种链的缺点是一问一答,是没有history的,是单轮问答。
2)自定义提示 PromptTemplate
这里还是使用到自定义提示 PromptTemplate,主要作用是使 OpenAI 能根据我们传入的向量文本为蓝本,限制它的回答范围,并要求使用中文回答。这样的好处在于,如果我们问一些非 pdf 涉及的内容,OpenAI 会返回无法作答,而不是根据自己的大模型数据来回答问题。
3)llm 模型
我们还是用 Chat 模型作为 llm 的输入模型,这里可以看到,我们使用的 model 为 gpt-3.5-turbo-16k,它可以支持 16384 个tokens,而 gpt-3.5-turbo 只支持 4096 个tokens
所以这里就回答了上面文本拆分器 chunk_size 参数,如果使用 gpt-3.5-turbo 模型,笔者尝试过,最大可能就是只能到 768,不过这个具体要看向量化以后,携带的文本的大小tokens而定。
不过使用 gpt-3.5-turbo-16k 也是有代价的,就是它比 gpt-3.5-turbo 要贵,大概是2倍的价格。
三、路由整合
我们将上面实现的三个工具方法整合到路由,主要实现 pdf 文件的本地向量初始化,还有基于向量化的 pdf 文档内容进行问答。
from fastapi import APIRouter, Body
from ..util import pdf, langchain, fassrouter = APIRouter(prefix="/chat"
)# 初始化pdf文件
@router.get("/init_pdf")
async def init_pdf():# pfd文件路径pdf_doc = "xxx.pdf"# get pdf textraw_text = pdf.get_pdf_text(pdf_doc)# get the text chunkstext_chunks = openai.get_text_chunks(raw_text)# savefass.save_vector_store(text_chunks)return {'success': True}# 问答
@router.post("/question")
async def question(text: str = Body(embed=True)
):vector_store = fass.load_vector_store()chain = langchain.get_qa_chain(vector_store)response = chain({"query": text})return {'success': True, "code": 0, "reply": response}1)初始化 pdf 文件
执行接口不报错的话,会看到项目同级目录下会多了一个 faiss 目录,里面包括两个索引文件。
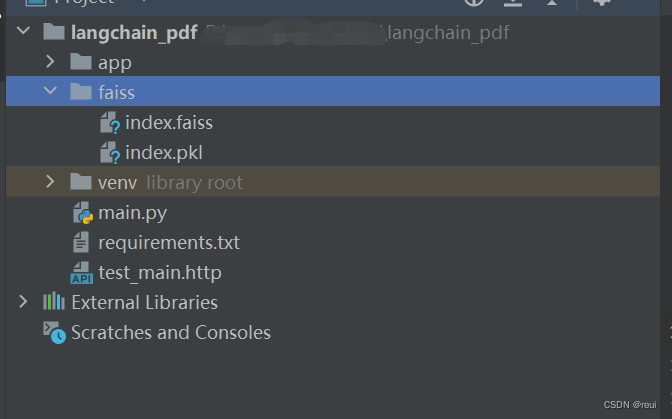
2)配置 OpenAI
因为项目使用到 OpenAI 的接口,所以我们这边需要全局配置 api-key,还有我们云函数上的代理地址。
from fastapi import FastAPI
from app.routers import chat
import sys
import os
from dotenv import load_dotenv, find_dotenv
import openaiload_dotenv(find_dotenv())
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.api_base = os.getenv("OPENAI_API_BASE")# 防止相对路径导入出错
sys.path.append(os.path.join(os.path.dirname(__file__)))app = FastAPI()# 将其余单独模块进行整合
app.include_router(chat.router)调整后的 main.py 文件如上图,项目中需要加入 .env 文件
OPENAI_API_KEY=
OPENAI_API_BASE=https://xxxxxx/v1要注意api_base的地址后面,一般云函数地址的后面要加上 /v1
四、运行和测试
至此,一个简单的基于 LangChain 库的 PDF文档问答就完成了,我们随便拿一份网上能找到保险pdf做个实验,看看效果如何
我们就来问 pdf 中的这段内容,问题是 "风险的特征有哪些?"

我们来看看回复,几个大的要点也基本答上来了,效果也算可以了。
{"success": true,"code": 0,"reply": {"query": "风险的特征有哪些?","result": "风险的特征包括以下几个方面:\n1. 风险的客观性:风险是一种客观存在,与人的意志无关,独立于人的意识之外的客观存在。\n2. 风险的普遍性:在社会经济生活中,人们面临各种各样的风险,从个人、企业到国家和政府机关都无处不在。\n3. 风险的损害性:风险与人们的经济利益密切相关,会给人们的经济造成损失以及对人的生命造成伤害。\n4. 某一风险发生的不确定性:虽然风险是客观存在的,但对某一具体风险而言,其发生是偶然的,是一种随机现象。\n5. 总体风险发生的可测性:虽然个别风险事故的发生是偶然的,但大量风险事故往往呈现出明显的规律性,可以通过统计方法进行准确测量。"}
}我们再尝试问一些不在 pdf 里的问题,"如何评价中国足球"
{"success": true,"code": 0,"reply": {"query": "如何评价中国足球","result": "根据已知内容无法回答该问题。"}
}这跟我们上面 自定义提示 PromptTemplate 的内容是一致的。
最后附上 仓库地址
相关文章:
【LangChain学习】基于PDF文档构建问答知识库(三)实战整合 LangChain、OpenAI、FAISS等
接下来,我们开始在web框架上整合 LangChain、OpenAI、FAISS等。 一、PDF库 因为项目是基于PDF文档的,所以需要一些操作PDF的库,我们这边使用的是PyPDF2 from PyPDF2 import PdfReader# 获取pdf文件内容 def get_pdf_text(pdf):text "…...

阿里云国际站对象储存OSS的常见问题?
1.什么是阿里云OSS? 阿里云对象存储服务OSS(Object Storage Service),是阿里云提供的海量、安全、低成本、高持久性的云存储服务,并可无限扩展。其数据设计持久性不低于99.9999999999%(12个9)&a…...
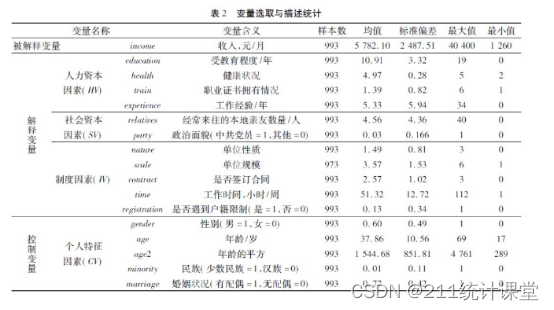
spss什么是描述性分析,以及如何去处理。
描述性分析是数据分析的第一步,是了解和认识数据基本特征和结构的方法,只有在完成了描述性统计分析,充分的了解和认识数据特征后,才能更好地开展后续更复杂的数据分析。因此,描述性分析是开展数据分析过程中最基础且必…...
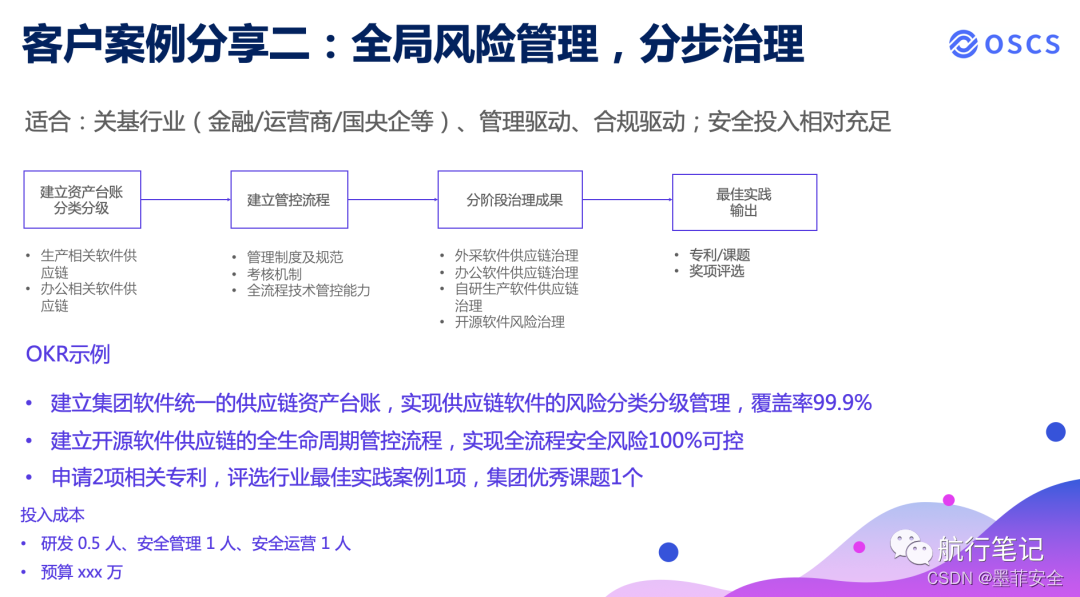
OSCS 闭门研讨第一期实录:软件供应链安全建设价值
2023 年 7 月 18 日晚 19:30,软件供应链安全技术交流群(OSCS)组织了第一次线上的闭门研讨会,本次研讨会我们收到 71 个来自各个企业关注软件供应链安全的技术专家的报名,根据研讨会参与规则要求,我们对报名…...
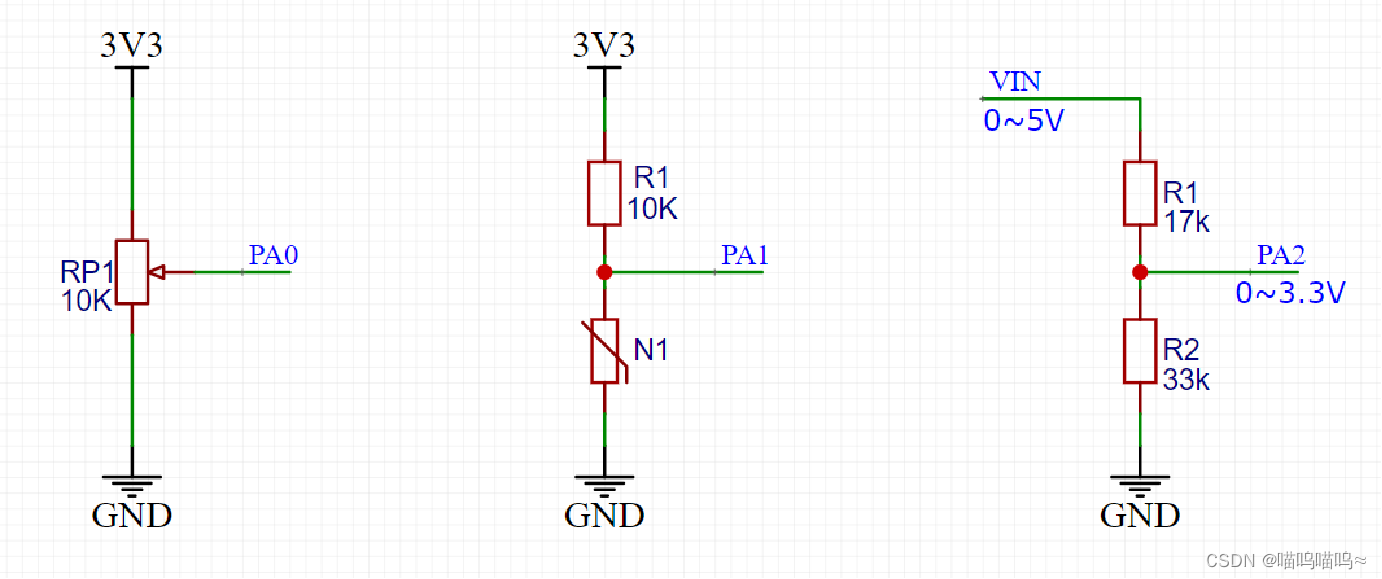
STM32入门——ADC模数转换
ADC简介 ADC(Analog-Digital Converter)模拟-数字转换器ADC可以将引脚上连续变化的模拟电压转换为内存中存储的数字变量,建立模拟电路到数字电路的桥梁12位逐次逼近型ADC,1us转换时间输入电压范围:0~3.3V,…...
)
【Fegin技术专题】「原生态」打开Fegin之RPC技术的开端,你会使用原生态的Fegin吗?(下)
内容简介 在项目开发中,除了考虑正常的调用之外,负载均衡和故障转移也是关注的重点,这也是feign ribbon的优势所在,基于上面两篇文章的基础,接下来我们开展最后一篇原生态fegin结合ribbon服务进行服务远程调用且实现负…...
)
【leetcode】454. 四数相加 II(medium)
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < nnums1[i] nums2[j] nums3[k] nums4[l] 0 思路:如果要暴力,那么时间复杂…...

PHP先等比缩放再无损裁剪图片【实例源码】
很多人在使用程序裁剪图片时,是在原图上直接裁剪,这样的裁剪结果是使得图片变得不完整了,理想的做法是先等比缩小图片,再把多余的部分裁掉,这样会保留更多的图片信息。 实现代码: <?php/*** 说明:函数功能是把一个图像裁剪为任意大小的图像,图像不变形** @param …...

共享广告主项目:广告也能共享?全民广告时代来袭
科思创业汇 大家好,这里是科思创业汇,一个轻资产创业孵化平台。赚钱的方式有很多种,我希望在科思创业汇能够给你带来最快乐的那一种! 广告是我们日常生活中在衣食住行中可以看到的一种宣传方式。广告作为互联网社会的信息传播方…...

Flink-间隔联结
间隔联结只支持事件时间间隔联结如果遇到迟到数据,则会关联不上,比如来了一个5秒的数据,它可以关联前2秒的数据,后3秒的数据,就是可以关联3秒到8秒的数据,然后又来了一个6秒的数据,可以关联4秒到…...
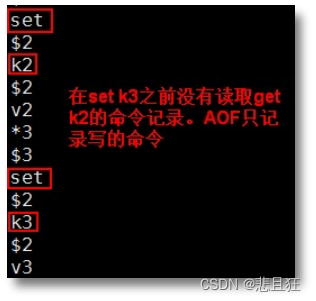
redis的持久化
第一章、redis的持久化 1.1)持久化概述 ①持久化可以理解为将数据存储到一个不会丢失的地方,Redis 的数据存储在内存中,电脑关闭数据就会丢失,所以放在内存中的数据不是持久化的,而放在磁盘就算是一种持久化。 ②为…...
藏语翻译器:多功能翻译软件
这是是一款能够将藏语翻译成其他语言或将其他语言翻译成藏语的软件。该软件能够识别并翻译藏语中的常用词汇和短语,并且支持多种常见语言的翻译,例如英语、汉语、法语、德语等等。此外,藏语翻译器还具有简单易用的用户界面,方便用…...

Java课题笔记~ JavaWeb概述/开发基础
JavaWeb概述/开发基础 1.XML基础 (1)XML概述 (2)XML语法 (3)DTD约束 (4)Schema约束(XML Schema 比 DTD 更强大) 2.Web基础知识 Web是一个分布式的超媒…...

【解放ipad生产力】如何在平板上使用免费IDE工具完成项目开发
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code3o19zyy2pneoo 前言 很多人应该会像我一样吧,有时候身边没电脑突然要写项目,发现自己的平板没有一点作用&…...

IDEA快捷键总结
切换窗口 Alt(1-9) Alt1 打开或者关闭左侧project Alt4 Run窗口 Alt5 Debug窗口 Alt7 类结构窗口 生成构造函数、get、set等方法 Altinsert 快速生成输出语句 Soutenter键 运行程序 chtlshiftf10 运行程序 shiftf9 debug方式运行程序 代码…...

OpenJDK Maven 编译出错: package jdk.nashorn.internal.runtime.logging does not exist
前言 OpenJDK 1.8.0Maven 3.8.5TencentOS Server 3.1 错误信息 [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.1:compile (default-compile) on project tour-common: Compilation failure: Compilation failure: [ERROR] /opt/tour-c…...

.Net Framework请求外部Api
要在.NET Framework 4.5中进行外部API的POST请求,你可以使用HttpClient类。 1. Post请求 using System; using System.Net.Http; using System.Threading.Tasks;class Program {static async Task Main(string[] args){// 创建一个HttpClient实例using (HttpClien…...
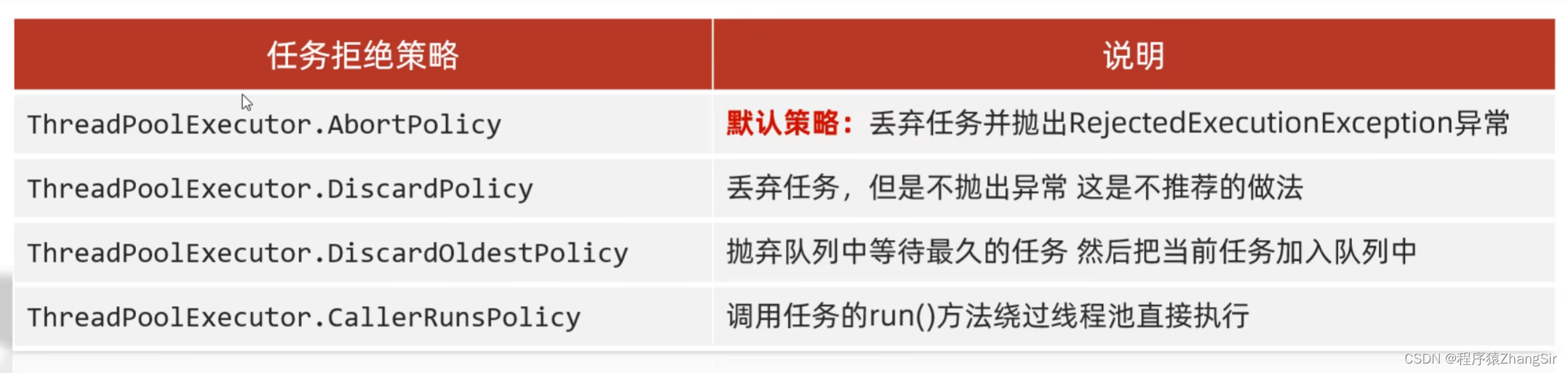
线程池工作原理深入解析
目录 1. 线程正常的生命周期 2. 为什么要用线程池? 3. 线程池的核心原理 4. 怎样创建线程池? 5.线程池的代码实现 6. ThreadPoolExecutor 源码分析 7. ThreadPoolExecutor 工作原理展示(重点) 1. 线程正常的生命周期 我们知…...

chatGPT小白快速入门课程大纲
以下是关于ChatGPT的培训课程大纲,分为7部分,我们会在后续写一个系列的相关文章: 1. 介绍 ChatGPT是什么?ChatGPT是由谁开发的?ChatGPT是一个什么样的语言模型? 2. 功能与特点 ChatGPT可以做什么?ChatGPT有哪些特点?ChatGPT与传统语言模型的区别? 3. 使用方法 如何…...

网络编程——多路复用——epoll机制
理解 epoll:高效的 Linux I/O 多路复用机制 在网络编程中,处理多个并发连接是一个常见的挑战。传统的方式通常使用阻塞式 I/O 或者多线程/多进程来处理并发连接,但这些方法都存在一些性能和资源管理的问题。为了解决这些问题,Lin…...

Deepin 23虚拟机里装Windows软件?实测WPS/微信/QQ/钉钉/迅雷安装与避坑指南
Deepin 23虚拟机中运行Windows办公软件的完整实践指南 对于许多Linux用户而言,Deepin系统以其优雅的界面和丰富的本地化功能成为替代Windows的理想选择。然而在实际办公场景中,我们仍不可避免地需要依赖某些仅支持Windows平台的国产办公和通讯软件。本文…...

5分钟快速上手:MAA明日方舟小助手一键自动化游戏日常完整指南
5分钟快速上手:MAA明日方舟小助手一键自动化游戏日常完整指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: http…...

操作系统层优化:为 Stable Yogi 模型部署调优 Linux 内核参数
操作系统层优化:为 Stable Yogi 模型部署调优 Linux 内核参数 如果你已经成功部署了 Stable Yogi 模型,但总觉得它的推理速度还能再快一点,或者在高并发请求下系统偶尔会卡顿、报错,那么问题可能不在模型本身,而在于它…...

Unity 3D游戏性能优化全攻略:如何让你的游戏在低配设备上也能流畅运行
Unity 3D游戏性能优化全攻略:如何让你的游戏在低配设备上也能流畅运行 当你的游戏在高端设备上运行如丝般顺滑,却在低配手机上卡成幻灯片时,那种挫败感每个开发者都深有体会。性能优化不是锦上添花,而是决定游戏生死的关键战役。本…...

如何彻底摆脱Windows系统中顽固的Microsoft Edge浏览器?
如何彻底摆脱Windows系统中顽固的Microsoft Edge浏览器? 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover 你…...

百考通:AI精准赋能,让零散的想法智能生成为结构化内容
在学术写作与论文发表的过程中,重复率过高、AI生成痕迹明显,是困扰无数学生与科研工作者的核心难题。不仅可能导致查重不通过,更会影响学术诚信与成果认可度。百考通(https://www.baikaotongai.com) 凭借智能文本优化技…...

QQ音乐加密文件终极解放指南:用qmcdump实现音乐自由播放
QQ音乐加密文件终极解放指南:用qmcdump实现音乐自由播放 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是…...

还在为音乐管理发愁?这款开源神器让你零成本畅享音乐
还在为音乐管理发愁?这款开源神器让你零成本畅享音乐 【免费下载链接】lx-music-desktop 一个基于 Electron 的音乐软件 项目地址: https://gitcode.com/GitHub_Trending/lx/lx-music-desktop 你是否厌倦了在不同音乐平台之间来回切换?每个月支付…...

从零开始:使用Retinaface+CurricularFace实现Python爬虫人脸数据采集
从零开始:使用RetinafaceCurricularFace实现Python爬虫人脸数据采集 1. 引言 在当今数字化时代,人脸数据已成为许多智能应用的核心基础。无论是人脸识别门禁系统、智能相册分类,还是虚拟试妆应用,都需要大量高质量的人脸数据作为…...

解放你的PlayStation手柄:DS4Windows让PC游戏体验全面升级
解放你的PlayStation手柄:DS4Windows让PC游戏体验全面升级 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为你的PS4/PS5手柄在Windows电脑上无法使用而烦恼吗?…...